Software testing is the process of testing and verifying that a software product or application is doing what it is supposed to do. The benefits of testing include preventing distractions, reducing development costs, and improving performance. There are many different types of software testing, each with specific goals and strategies. Some of them are below:
- Acceptance Testing: Ensuring that the whole system works as intended.
- Integration Testing: Ensuring that software components or functions work together.
- Unit Testing: To ensure that each software unit is operating as expected. The unit is a testable component of the application.
- Functional Testing: Evaluating activities by imitating business conditions, based on operational requirements. Checking the black box is a common way to confirm tasks.
- Performance Testing: A test of how the software works under various operating loads. Load testing, for example, is used to assess performance under real-life load conditions.
- Re-Testing: To test whether new features are broken or degraded. Hygiene checks can be used to verify menus, functions, and commands at the highest level when there is no time for a full reversal test.
What is a Bug?
A malfunction in the software/system is an error that may cause components or the system to fail to perform its required functions. In other words, if an error is encountered during the test it can cause malfunction. For example, incorrect data description, statements, input data, design, etc.
Reasons Why Bugs Occur?
1. Lack of Communication: This is a key factor contributing to the development of software bug fixes. Thus, a lack of clarity in communication can lead to misunderstandings of what the software should or should not do. In many cases, the customer may not fully understand how the product should ultimately work. This is especially true if the software is designed for a completely new product. Such situations often lead to many misinterpretations from both sides.
2. Repeated Definitions Required: Constantly changing software requirements creates confusion and pressure in both software development and testing teams. Usually, adding a new feature or deleting an existing feature can be linked to other modules or software components. Observing such problems causes software interruptions.
3. Policy Framework Does Not Exist: Also, debugging a software component/software component may appear in a different or similar component. Lack of foresight can cause serious problems and increase the number of distractions. This is one of the biggest problems because of what interruptions occur as engineers are often under pressure related to timelines; constantly changing needs, increasing the number of distractions, etc. Addition, Design and redesign, UI integration, module integration, database management all add to the complexity of the software and the system as a whole.
4. Performance Errors: Significant problems with software design and architecture can cause problems for systems. Improved software tends to make mistakes as programmers can also make mistakes. As a test tester, data/announcement reference errors, control flow errors, parameter errors, input/output errors, etc.
5. Lots of Recycling: Resetting resources, redoing or discarding a finished work, changes in hardware/software requirements may also affect the software. Assigning a new developer to a project in the middle of nowhere can cause software interruptions. This can happen if proper coding standards are not followed, incorrect coding, inaccurate data transfer, etc. Discarding part of existing code may leave traces on other parts of the software; Ignoring or deleting that code may cause software interruptions. In addition, critical bugs can occur especially with large projects, as it becomes difficult to pinpoint the location of the problem.
Life Cycle of a Bug in Software Testing
Below are the steps in the lifecycle of the bug in software testing:
- Open: The editor begins the process of analyzing bugs here, where possible, and works to fix them. If the editor thinks the error is not enough, the error for some reason can be transferred to the next four regions, Reject or No, i.e. Repeat.
- New: This is the first stage of the distortion of distractions in the life cycle of the disorder. In the later stages of the bug’s life cycle, confirmation and testing are performed on these bugs when a new feature is discovered.
- Shared: The engineering team has been provided with a new bug fixer recently built at this level. This will be sent to the designer by the project leader or team manager.
- Pending Review: When fixing an error, the designer will give the inspector an error check and the feature status will remain pending ‘review’ until the tester is working on the error check.
- Fixed: If the Developer completes the debugging task by making the necessary changes, the feature status can be called “Fixed.”
- Confirmed: If the tester had no problem with the feature after the designer was given the feature on the test device and thought that if it was properly adjusted, the feature status was given “verified”.
- Open again / Reopen: If there is still an error, the editor will then be instructed to check and the feature status will be re-opened.
- Closed: If the error is not present, the tester changes the status of the feature to ‘Off’.
- Check Again: The inspector then begins the process of reviewing the error to check that the error has been corrected by the engineer as required.
- Repeat: If the engineer is considering a factor similar to another factor. If the developer considers a feature similar to another feature, or if the definition of malfunction coincides with any other malfunction, the status of the feature is changed by the developer to ‘duplicate’.
Few more stages to add here are:
- Rejected: If a feature can be considered a real factor the developer will mean “Rejected” developer.
- Duplicate: If the engineer finds a feature similar to any other feature or if the concept of the malfunction is similar to any other feature the status of the feature is changed to ‘Duplicate’ by the developer.
- Postponed: If the developer feels that the feature is not very important and can be corrected in the next release, however, in that case, he can change the status of the feature such as ‘Postponed’.
- Not a Bug: If the feature does not affect the performance of the application, the corrupt state is changed to “Not a Bug”.

Fig 1.1 Diagram of Bug Life Cycle
Bug Report
- Defect/ Bug Name: A short headline describing the defect. It should be specific and accurate.
- Defect/Bug ID: Unique identification number for the defect.
- Defect Description: Detailed description of the bug including the information of the module in which it was detected. It contains a detailed summary including the severity, priority, expected results vs actual output, etc.
- Severity: This describes the impact of the defect on the application under test.
- Priority: This is related to how urgent it is to fix the defect. Priority can be High/ Medium/ Low based on the impact urgency at which the defect should be fixed.
- Reported By: Name/ ID of the tester who reported the bug.
- Reported On: Date when the defect is raised.
- Steps: These include detailed steps along with the screenshots with which the developer can reproduce the same defect.
- Status: New/ Open/ Active
- Fixed By: Name/ ID of the developer who fixed the defect.
- Data Closed: Date when the defect is closed.
Factors to be Considered while Reporting a Bug:
- The whole team should clearly understand the different conditions of the trauma before starting research on the life cycle of the disability.
- To prevent future confusion, a flawed life cycle should be well documented.
- Make sure everyone who has any work related to the Default Life Cycle understands his or her best results work very clearly.
- Everyone who changes the status quo should be aware of the situation which should provide sufficient information about the nature of the feature and the reason for it so that everyone working on that feature can easily see the reason for that feature.
- A feature tracking tool should be carefully handled in the course of a defective life cycle work to ensure consistency between errors.
Bug Tracking Tools
Below are some of the bug tracking tools–
1. KATALON TESTOPS: Katalon TestOps is a free, powerful orchestration platform that helps with your process of tracking bugs. TestOps provides testing teams and DevOps teams with a clear, linked picture of their testing, resources, and locations to launch the right test, in the right place, at the right time.
Features:
- Applies to Cloud, Desktop: Window and Linux program.
- Compatible with almost all test frames available: Jasmine, JUnit, Pytest, Mocha, etc .; CI / CD tools: Jenkins, CircleCI, and management platforms: Jira, Slack.
- Track real-time data for error correction, and for accuracy.
- Live and complete performance test reports to determine the cause of any problems.
- Plan well with Smart Scheduling to prepare for the test cycle while maintaining high quality.
- Rate release readiness to improve release confidence.
- Improve collaboration and enhance transparency with comments, dashboards, KPI tracking, possible details – all in one place.
2. KUALITEE: Collection of specific results and analysis with solid failure analysis in any framework. The Kualitee is for development and QA teams look beyond the allocation and tracking of bugs. It allows you to build high-quality software using tiny bugs, fast QA cycles, and better control of your build. The comprehensive suite combines all the functions of a good error management tool and has a test case and flow of test work built into it seamlessly. You would not need to combine and match different tools; instead, you can manage all your tests in one place.
Features:
- Create, assign, and track errors.
- Tracing between disability, needs, and testing.
- Easy-to-use errors, test cases, and test cycles.
- Custom permissions, fields, and reporting.
- Interactive and informative dashboard.
- Integration of external companies and REST API.
- An intuitive and easy-to-use interface.
3. QA Coverage: QACoverage is the place to go for successfully managing all your testing processes so that you can produce high-quality and trouble-free products. It has a disability control module that will allow you to manage errors from the first diagnostic phase until closed. The error tracking process can be customized and tailored to the needs of each client. In addition to negative tracking, QACoverage has the ability to track risks, issues, enhancements, suggestions, and recommendations. It also has full capabilities for complex test management solutions that include needs management, test case design, test case issuance, and reporting.
Features:
- Control the overall workflow of a variety of Tickets including risk, issues, tasks, and development management.
- Produce complete metrics to identify the causes and levels of difficulty.
- Support a variety of information that supports the feature with email attachments.
- Create and set up a workflow for enhanced test visibility with automatic notifications.
- Photo reports based on difficulty, importance, type of malfunction, disability category, expected correction date, and much more.
4. BUG HERD: BugHerd is an easy way to track bugs, collect and manage webpage responses. Your team and customers search for feedback on web pages, so they can find the exact problem. BugHerd also scans the information you need to replicate and resolve bugs quickly, such as browser, CSS selector data, operating system, and screenshot. Distractions and feedback, as well as technical information, are submitted to the Kanban Style Task Board, where distractions can be assigned and managed until they are eliminated. BugHerd can also integrate with your existing project management tools, helping to keep your team on the same page with bug fixes.
Software testing is the process of testing and verifying that a software product or application is doing what it is supposed to do. The benefits of testing include preventing distractions, reducing development costs, and improving performance. There are many different types of software testing, each with specific goals and strategies. Some of them are below:
- Acceptance Testing: Ensuring that the whole system works as intended.
- Integration Testing: Ensuring that software components or functions work together.
- Unit Testing: To ensure that each software unit is operating as expected. The unit is a testable component of the application.
- Functional Testing: Evaluating activities by imitating business conditions, based on operational requirements. Checking the black box is a common way to confirm tasks.
- Performance Testing: A test of how the software works under various operating loads. Load testing, for example, is used to assess performance under real-life load conditions.
- Re-Testing: To test whether new features are broken or degraded. Hygiene checks can be used to verify menus, functions, and commands at the highest level when there is no time for a full reversal test.
What is a Bug?
A malfunction in the software/system is an error that may cause components or the system to fail to perform its required functions. In other words, if an error is encountered during the test it can cause malfunction. For example, incorrect data description, statements, input data, design, etc.
Reasons Why Bugs Occur?
1. Lack of Communication: This is a key factor contributing to the development of software bug fixes. Thus, a lack of clarity in communication can lead to misunderstandings of what the software should or should not do. In many cases, the customer may not fully understand how the product should ultimately work. This is especially true if the software is designed for a completely new product. Such situations often lead to many misinterpretations from both sides.
2. Repeated Definitions Required: Constantly changing software requirements creates confusion and pressure in both software development and testing teams. Usually, adding a new feature or deleting an existing feature can be linked to other modules or software components. Observing such problems causes software interruptions.
3. Policy Framework Does Not Exist: Also, debugging a software component/software component may appear in a different or similar component. Lack of foresight can cause serious problems and increase the number of distractions. This is one of the biggest problems because of what interruptions occur as engineers are often under pressure related to timelines; constantly changing needs, increasing the number of distractions, etc. Addition, Design and redesign, UI integration, module integration, database management all add to the complexity of the software and the system as a whole.
4. Performance Errors: Significant problems with software design and architecture can cause problems for systems. Improved software tends to make mistakes as programmers can also make mistakes. As a test tester, data/announcement reference errors, control flow errors, parameter errors, input/output errors, etc.
5. Lots of Recycling: Resetting resources, redoing or discarding a finished work, changes in hardware/software requirements may also affect the software. Assigning a new developer to a project in the middle of nowhere can cause software interruptions. This can happen if proper coding standards are not followed, incorrect coding, inaccurate data transfer, etc. Discarding part of existing code may leave traces on other parts of the software; Ignoring or deleting that code may cause software interruptions. In addition, critical bugs can occur especially with large projects, as it becomes difficult to pinpoint the location of the problem.
Life Cycle of a Bug in Software Testing
Below are the steps in the lifecycle of the bug in software testing:
- Open: The editor begins the process of analyzing bugs here, where possible, and works to fix them. If the editor thinks the error is not enough, the error for some reason can be transferred to the next four regions, Reject or No, i.e. Repeat.
- New: This is the first stage of the distortion of distractions in the life cycle of the disorder. In the later stages of the bug’s life cycle, confirmation and testing are performed on these bugs when a new feature is discovered.
- Shared: The engineering team has been provided with a new bug fixer recently built at this level. This will be sent to the designer by the project leader or team manager.
- Pending Review: When fixing an error, the designer will give the inspector an error check and the feature status will remain pending ‘review’ until the tester is working on the error check.
- Fixed: If the Developer completes the debugging task by making the necessary changes, the feature status can be called “Fixed.”
- Confirmed: If the tester had no problem with the feature after the designer was given the feature on the test device and thought that if it was properly adjusted, the feature status was given “verified”.
- Open again / Reopen: If there is still an error, the editor will then be instructed to check and the feature status will be re-opened.
- Closed: If the error is not present, the tester changes the status of the feature to ‘Off’.
- Check Again: The inspector then begins the process of reviewing the error to check that the error has been corrected by the engineer as required.
- Repeat: If the engineer is considering a factor similar to another factor. If the developer considers a feature similar to another feature, or if the definition of malfunction coincides with any other malfunction, the status of the feature is changed by the developer to ‘duplicate’.
Few more stages to add here are:
- Rejected: If a feature can be considered a real factor the developer will mean “Rejected” developer.
- Duplicate: If the engineer finds a feature similar to any other feature or if the concept of the malfunction is similar to any other feature the status of the feature is changed to ‘Duplicate’ by the developer.
- Postponed: If the developer feels that the feature is not very important and can be corrected in the next release, however, in that case, he can change the status of the feature such as ‘Postponed’.
- Not a Bug: If the feature does not affect the performance of the application, the corrupt state is changed to “Not a Bug”.
Fig 1.1 Diagram of Bug Life Cycle
Bug Report
- Defect/ Bug Name: A short headline describing the defect. It should be specific and accurate.
- Defect/Bug ID: Unique identification number for the defect.
- Defect Description: Detailed description of the bug including the information of the module in which it was detected. It contains a detailed summary including the severity, priority, expected results vs actual output, etc.
- Severity: This describes the impact of the defect on the application under test.
- Priority: This is related to how urgent it is to fix the defect. Priority can be High/ Medium/ Low based on the impact urgency at which the defect should be fixed.
- Reported By: Name/ ID of the tester who reported the bug.
- Reported On: Date when the defect is raised.
- Steps: These include detailed steps along with the screenshots with which the developer can reproduce the same defect.
- Status: New/ Open/ Active
- Fixed By: Name/ ID of the developer who fixed the defect.
- Data Closed: Date when the defect is closed.
Factors to be Considered while Reporting a Bug:
- The whole team should clearly understand the different conditions of the trauma before starting research on the life cycle of the disability.
- To prevent future confusion, a flawed life cycle should be well documented.
- Make sure everyone who has any work related to the Default Life Cycle understands his or her best results work very clearly.
- Everyone who changes the status quo should be aware of the situation which should provide sufficient information about the nature of the feature and the reason for it so that everyone working on that feature can easily see the reason for that feature.
- A feature tracking tool should be carefully handled in the course of a defective life cycle work to ensure consistency between errors.
Bug Tracking Tools
Below are some of the bug tracking tools–
1. KATALON TESTOPS: Katalon TestOps is a free, powerful orchestration platform that helps with your process of tracking bugs. TestOps provides testing teams and DevOps teams with a clear, linked picture of their testing, resources, and locations to launch the right test, in the right place, at the right time.
Features:
- Applies to Cloud, Desktop: Window and Linux program.
- Compatible with almost all test frames available: Jasmine, JUnit, Pytest, Mocha, etc .; CI / CD tools: Jenkins, CircleCI, and management platforms: Jira, Slack.
- Track real-time data for error correction, and for accuracy.
- Live and complete performance test reports to determine the cause of any problems.
- Plan well with Smart Scheduling to prepare for the test cycle while maintaining high quality.
- Rate release readiness to improve release confidence.
- Improve collaboration and enhance transparency with comments, dashboards, KPI tracking, possible details – all in one place.
2. KUALITEE: Collection of specific results and analysis with solid failure analysis in any framework. The Kualitee is for development and QA teams look beyond the allocation and tracking of bugs. It allows you to build high-quality software using tiny bugs, fast QA cycles, and better control of your build. The comprehensive suite combines all the functions of a good error management tool and has a test case and flow of test work built into it seamlessly. You would not need to combine and match different tools; instead, you can manage all your tests in one place.
Features:
- Create, assign, and track errors.
- Tracing between disability, needs, and testing.
- Easy-to-use errors, test cases, and test cycles.
- Custom permissions, fields, and reporting.
- Interactive and informative dashboard.
- Integration of external companies and REST API.
- An intuitive and easy-to-use interface.
3. QA Coverage: QACoverage is the place to go for successfully managing all your testing processes so that you can produce high-quality and trouble-free products. It has a disability control module that will allow you to manage errors from the first diagnostic phase until closed. The error tracking process can be customized and tailored to the needs of each client. In addition to negative tracking, QACoverage has the ability to track risks, issues, enhancements, suggestions, and recommendations. It also has full capabilities for complex test management solutions that include needs management, test case design, test case issuance, and reporting.
Features:
- Control the overall workflow of a variety of Tickets including risk, issues, tasks, and development management.
- Produce complete metrics to identify the causes and levels of difficulty.
- Support a variety of information that supports the feature with email attachments.
- Create and set up a workflow for enhanced test visibility with automatic notifications.
- Photo reports based on difficulty, importance, type of malfunction, disability category, expected correction date, and much more.
4. BUG HERD: BugHerd is an easy way to track bugs, collect and manage webpage responses. Your team and customers search for feedback on web pages, so they can find the exact problem. BugHerd also scans the information you need to replicate and resolve bugs quickly, such as browser, CSS selector data, operating system, and screenshot. Distractions and feedback, as well as technical information, are submitted to the Kanban Style Task Board, where distractions can be assigned and managed until they are eliminated. BugHerd can also integrate with your existing project management tools, helping to keep your team on the same page with bug fixes.
Дефекты программного обеспечения можно обнаружить на каждом этапе разработки и тестирования продукта. Чтобы гарантировать исправление наиболее серьезных дефектов программного обеспечения, тестировщикам важно иметь хорошее представление о различных типах дефектов, которые могут возникнуть.

В этой статье мы обсудим самые распространенные типы ПО дефекты и способы их выявления.
Что такое дефект?
Дефект программного обеспечения — это ошибка, изъян, сбой или неисправность в компьютерной программе, из-за которой она выдает неправильный или неожиданный результат или ведет себя непреднамеренным образом. Программная ошибка возникает, когда фактические результаты не совпадают с ожидаемыми. Разработчики и программисты иногда допускают ошибки, которые создают ошибки, называемые дефектами. Большинство ошибок возникает из-за ошибок, которые допускают разработчики или программисты.
Обязательно прочтите: Разница между дефектом, ошибкой, ошибкой и сбоем
Типы программных ошибок при тестировании программного обеспечения
Существует множество различных типов дефектов программного обеспечения, и тестировщикам важно знать наиболее распространенные из них, чтобы они могут эффективно тестировать их.
Ошибки программного обеспечения подразделяются на три типа:
- Дефекты программного обеспечения по своей природе
- Дефекты программного обеспечения по их приоритету
- Дефекты программного обеспечения по их серьезности
Обычно мы можем видеть приоритет и серьезность классификаторов в большинстве инструментов отслеживания ошибок. Если мы настроим классификатор в соответствии с характером ошибки, а также приоритетом и серьезностью, это поможет легко управлять распределением обязанностей по исправлению ошибок соответствующим командам.
#1. Дефекты программного обеспечения по своей природе
Ошибки в программном обеспечении имеют широкий спектр природы, каждая из которых имеет свой собственный набор симптомов. Несмотря на то, что таких багов много, сталкиваться с ними можно не часто. Вот наиболее распространенные ошибки программного обеспечения, классифицированные по характеру, с которыми вы, скорее всего, столкнетесь при тестировании программного обеспечения.
#1. Функциональные ошибки
Как следует из названия, функциональные ошибки — это те, которые вызывают сбои в работе программного обеспечения. Хорошим примером этого может служить кнопка, при нажатии на которую должно открываться новое окно, но вместо этого ничего не происходит.
Функциональные ошибки можно исправить, выполнив функциональное тестирование.
#2. Ошибки на уровне модуля
Ошибки на уровне модуля — это дефекты, связанные с функциональностью отдельного программного модуля. Программный модуль — это наименьшая тестируемая часть приложения. Примеры программных модулей включают классы, методы и процедуры. Ошибки на уровне подразделения могут существенно повлиять на общее качество программного обеспечения.
Ошибки на уровне модуля можно исправить, выполнив модульное тестирование.
#3. Ошибки уровня интеграции
Ошибки уровня интеграции — это дефекты, возникающие при объединении двух или более программных модулей. Эти дефекты может быть трудно найти и исправить, потому что они часто требуют координации между несколькими командами. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки интеграции можно исправить, выполнив интеграционное тестирование.
#4. Дефекты юзабилити
Ошибки юзабилити — это дефекты, влияющие на работу пользователя с программным обеспечением и затрудняющие его использование. Дефект юзабилити — это дефект пользовательского опыта программного обеспечения, который затрудняет его использование. Ошибки юзабилити — это такие ошибки, как если веб-сайт сложен для доступа или обойти, или процесс регистрации сложен для прохождения.
Во время тестирования удобства использования тестировщики программного обеспечения проверяют приложения на соответствие требованиям пользователей и Руководству по доступности веб-контента (WCAG) для выявления таких проблем. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки, связанные с удобством использования, можно исправить, выполнив тестирование удобства использования.
#5. Дефекты производительности
Ошибки производительности — это дефекты, влияющие на производительность программного обеспечения. Это может включать в себя такие вещи, как скорость программного обеспечения, объем используемой памяти или количество потребляемых ресурсов. Ошибки уровня производительности сложно отследить и исправить, поскольку они могут быть вызваны рядом различных факторов.
Ошибки юзабилити можно исправить, выполнив тестирование производительности.
#6. Дефекты безопасности
Ошибки безопасности — это тип дефекта программного обеспечения, который может иметь серьезные последствия, если его не устранить. Эти дефекты могут позволить злоумышленникам получить доступ к конфиденциальным данным или системам или даже позволить им получить контроль над уязвимым программным обеспечением. Таким образом, очень важно, чтобы ошибкам уровня безопасности уделялось первоочередное внимание и устранялись как можно скорее.
Ошибки безопасности можно исправить, выполнив тестирование безопасности.
#7. Дефекты совместимости
Дефекты совместимости — это те ошибки, которые возникают, когда приложение несовместимо с оборудованием, на котором оно работает, или с другим программным обеспечением, с которым оно должно взаимодействовать. Несовместимость программного и аппаратного обеспечения может привести к сбоям, потере данных и другому непредсказуемому поведению. Тестировщики должны знать о проблемах совместимости и проводить соответствующие тесты. Программное приложение, имеющее проблемы с совместимостью, не работает последовательно на различных видах оборудования, операционных системах, веб-браузерах и устройствах при подключении к определенным программам или работе в определенных сетевых условиях.
Ошибки совместимости можно исправить, выполнение тестирования совместимости.
#8. Синтаксические ошибки
Синтаксические ошибки являются самым основным типом дефекта. Они возникают, когда код нарушает правила языка программирования. Например, использование неправильной пунктуации или забывание закрыть скобку может привести к синтаксической ошибке. Синтаксические ошибки обычно мешают запуску кода, поэтому их относительно легко обнаружить и исправить.
#9. Логические ошибки
Логические ошибки — это дефекты, из-за которых программа выдает неправильные результаты. Эти ошибки может быть трудно найти и исправить, потому что они часто не приводят к каким-либо видимым ошибкам. Логические ошибки могут возникать в любом типе программного обеспечения, но они особенно распространены в приложениях, требующих сложных вычислений или принятия решений.
Общие симптомы логических ошибок включают:
- Неверные результаты или выходные данные
- Неожиданное поведение
- Сбой или зависание программного обеспечения
Чтобы найти и исправить логические ошибки, тестировщикам необходимо иметь четкое представление о коде программы и о том, как она должна работать. Часто лучший способ найти такие ошибки — использовать инструменты отладки или пошаговое выполнение, чтобы отслеживать выполнение программы и видеть, где что-то идет не так.
#2. Дефекты программного обеспечения по степени серьезности
Уровень серьезности присваивается дефекту по его влиянию. В результате серьезность проблемы отражает степень ее влияния на функциональность или работу программного продукта. Дефекты серьезности классифицируются как критические, серьезные, средние и незначительные в зависимости от степени серьезности.
#1. Критические дефекты
Критический дефект — это программная ошибка, имеющая серьезные или катастрофические последствия для работы приложения. Критические дефекты могут привести к сбою, зависанию или некорректной работе приложения. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение критическим дефектам, поскольку их необходимо исправить как можно скорее.
#2. Серьезные дефекты
Серьезный дефект — это программная ошибка, существенно влияющая на работу приложения. Серьезные дефекты могут привести к замедлению работы приложения или другому неожиданному поведению. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение серьезным дефектам, поскольку их необходимо исправить как можно скорее.
#3. Незначительные дефекты
Незначительный дефект — это программная ошибка, которая оказывает небольшое или незначительное влияние на работу приложения. Незначительные дефекты могут привести к тому, что приложение будет работать немного медленнее или демонстрировать другое неожиданное поведение. Разработчики и тестировщики часто не придают незначительным дефектам приоритет, потому что их можно исправить позже.
#4. Тривиальные дефекты
Тривиальный дефект – это программная ошибка, не влияющая на работу приложения. Тривиальные дефекты могут привести к тому, что приложение отобразит сообщение об ошибке или проявит другое неожиданное поведение. Разработчики и тестировщики часто присваивают тривиальным дефектам самый низкий приоритет, потому что они могут быть исправлены позже.
#3. Дефекты программного обеспечения по приоритету
#1. Дефекты с низким приоритетом
Дефекты с низким приоритетом, как правило, не оказывают серьезного влияния на работу программного обеспечения и могут быть отложены для исправления в следующей версии или выпуске. В эту категорию попадают косметические ошибки, такие как орфографические ошибки, неправильное выравнивание и т. д.
#2. Дефекты со средним приоритетом
Дефекты со средним приоритетом — это ошибки, которые могут быть исправлены после предстоящего выпуска или в следующем выпуске. Приложение, возвращающее ожидаемый результат, которое, однако, неправильно форматируется в конкретном браузере, является примером дефекта со средним приоритетом.
#3. Дефекты с высоким приоритетом
Как следует из названия, дефекты с высоким приоритетом — это те, которые сильно влияют на функционирование программного обеспечения. В большинстве случаев эти дефекты необходимо исправлять немедленно, так как они могут привести к серьезным нарушениям нормального рабочего процесса. Дефекты с высоким приоритетом обычно классифицируются как непреодолимые, так как они могут помешать пользователю продолжить выполнение поставленной задачи.
Некоторые распространенные примеры дефектов с высоким приоритетом включают:
- Дефекты, из-за которых приложение не работает. сбой
- Дефекты, препятствующие выполнению задачи пользователем
- Дефекты, приводящие к потере или повреждению данных
- Дефекты, раскрывающие конфиденциальную информацию неавторизованным пользователям
- Дефекты, делающие возможным несанкционированный доступ к системе
- Дефекты, приводящие к потере функциональности
- Дефекты, приводящие к неправильным результатам или неточным данным
- Дефекты, вызывающие проблемы с производительностью, такие как чрезмерное использование памяти или медленное время отклика
#4. Срочные дефекты
Срочные дефекты — это дефекты, которые необходимо устранить в течение 24 часов после сообщения о них. В эту категорию попадают дефекты со статусом критической серьезности. Однако дефекты с низким уровнем серьезности также могут быть классифицированы как высокоприоритетные. Например, опечатка в названии компании на домашней странице приложения не оказывает технического влияния на программное обеспечение, но оказывает существенное влияние на бизнес, поэтому считается срочной.
#4. Дополнительные дефекты
#1. Отсутствующие дефекты
Отсутствующие дефекты возникают из-за требований, которые не были включены в продукт. Они также считаются несоответствиями спецификации проекта и обычно негативно сказываются на пользовательском опыте или качестве программного обеспечения.
#2. Неправильные дефекты
Неправильные дефекты — это те дефекты, которые удовлетворяют требованиям, но не должным образом. Это означает, что хотя функциональность достигается в соответствии с требованиями, но не соответствует ожиданиям пользователя.
#3. Дефекты регрессии
Дефект регрессии возникает, когда изменение кода вызывает непреднамеренное воздействие на независимую часть программного обеспечения.
Часто задаваемые вопросы — Типы программных ошибок< /h2>
Почему так важна правильная классификация дефектов?
Правильная классификация дефектов важна, поскольку она помогает эффективно использовать ресурсы и управлять ими, правильно приоритизировать дефекты и поддерживать качество программного продукта.
Команды тестирования программного обеспечения в различных организациях используют различные инструменты отслеживания дефектов, такие как Jira, для отслеживания дефектов и управления ими. Несмотря на то, что в этих инструментах есть несколько вариантов классификации дефектов по умолчанию, они не всегда могут наилучшим образом соответствовать конкретным потребностям организации.
Следовательно, важно сначала определить и понять типы дефектов программного обеспечения, которые наиболее важны для организации, а затем соответствующим образом настроить инструмент управления дефектами.
Правильная классификация дефектов также гарантирует, что команда разработчиков сможет сосредоточиться на критических дефектах и исправить их до того, как они повлияют на конечных пользователей.
Кроме того, это также помогает определить потенциальные области улучшения в процессе разработки программного обеспечения, что может помочь предотвратить появление подобных дефектов в будущих выпусках.
Таким образом, отслеживание и устранение дефектов программного обеспечения может показаться утомительной и трудоемкой задачей. , правильное выполнение может существенно повлиять на качество конечного продукта.
Как найти лежащие в основе ошибки программного обеспечения?
Определение основной причины программной ошибки может быть сложной задачей даже для опытных разработчиков. Чтобы найти лежащие в основе программные ошибки, тестировщики должны применять систематический подход. В этот процесс входят различные этапы:
1) Репликация. Первым этапом является воспроизведение ошибки. Это включает в себя попытку воспроизвести тот же набор шагов, в котором возникла ошибка. Это поможет проверить, является ли ошибка реальной или нет.
2) Изоляция. После того, как ошибка воспроизведена, следующим шагом будет попытка ее изоляции. Это включает в себя выяснение того, что именно вызывает ошибку. Для этого тестировщики должны задать себе несколько вопросов, например:
– Какие входные данные вызывают ошибку?
– При каких различных условиях возникает ошибка?
– Каковы различные способы проявления ошибки?
3) Анализ: после Изолируя ошибку, следующим шагом будет ее анализ. Это включает в себя понимание того, почему возникает ошибка. Тестировщики должны задать себе несколько вопросов, таких как:
– Какова основная причина ошибки?
– Какими способами можно исправить ошибку?
– Какое исправление было бы наиболее эффективным? эффективно?
4) Отчет. После анализа ошибки следующим шагом является сообщение о ней. Это включает в себя создание отчета об ошибке, который включает всю соответствующую информацию об ошибке. Отчет должен быть четким и кратким, чтобы разработчики могли его легко понять.
5) Проверка. После сообщения об ошибке следующим шагом является проверка того, была ли она исправлена. Это включает в себя повторное тестирование программного обеспечения, чтобы убедиться, что ошибка все еще существует. Если ошибка исправлена, то тестер может подтвердить это и закрыть отчет об ошибке. Если ошибка все еще существует, тестировщик может повторно открыть отчет об ошибке.
Заключение
В индустрии программного обеспечения дефекты — неизбежная реальность. Однако благодаря тщательному анализу и пониманию их характера, серьезности и приоритета дефектами можно управлять, чтобы свести к минимуму их влияние на конечный продукт.
Задавая правильные вопросы и применяя правильные методы, тестировщики могут помочь обеспечить чтобы дефекты обнаруживались и исправлялись как можно раньше в процессе разработки.
TAG: qa
Обработка исключительных ситуаций. Методы и способы идентификации сбоев и ошибок.
Конструкция try..catch..finally
Иногда при выполнении программы возникают ошибки, которые трудно предусмотреть или предвидеть, а иногда и вовсе невозможно. Например, при передачи файла по сети может неожиданно оборваться сетевое подключение. такие ситуации называются исключениями. Язык C# предоставляет разработчикам возможности для обработки таких ситуаций. Для этого в C# предназначена конструкция try…catch…finally.
try { } catch { } finally { }
При использовании блока try…catch..finally вначале пытаются выполниться инструкции в блоке try. Если в этом блоке не возникло исключений, то после его выполнения начинает выполняться блок finally. И затем конструкция try..catch..finally завершает свою работу.
Если же в блоке try вдруг возникает исключение, то обычный порядок выполнения останавливается, и среда CLR (Common Language Runtime) начинает искать блок catch, который может обработать данное исключение. Если нужный блок catch найден, то он выполняется, и после его завершения выполняется блок finally.
Если нужный блок catch не найден, то при возникновении исключения программа аварийно завершает свое выполнение.
Рассмотрим следующий пример:
class Program { static void Main(string[] args) { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); Console.WriteLine("Конец программы"); Console.Read(); } }
В данном случае происходит деление числа на 0, что приведет к генерации исключения. И при запуске приложения в режиме отладки мы увидим в Visual Studio окошко, которое информирует об исключении:

В этом окошке мы видим, что возникло исключение, которое представляет тип System.DivideByZeroException, то есть попытка деления на ноль. С помощью пункта View Details можно посмотреть более детальную информацию об исключении.
И в этом случае единственное, что нам остается, это завершить выполнение программы.
Чтобы избежать подобного аварийного завершения программы, следует использовать для обработки исключений конструкцию try…catch…finally. Так, перепишем пример следующим образом:
class Program { static void Main(string[] args) { try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch { Console.WriteLine("Возникло исключение!"); } finally { Console.WriteLine("Блок finally"); } Console.WriteLine("Конец программы"); Console.Read(); } }
В данном случае у нас опять же возникнет исключение в блоке try, так как мы пытаемся разделить на ноль. И дойдя до строки
выполнение программы остановится. CLR найдет блок catch и передаст управление этому блоку.
После блока catch будет выполняться блок finally.
Возникло исключение!
Блок finally
Конец программы
Таким образом, программа по-прежнему не будет выполнять деление на ноль и соответственно не будет выводить результат этого деления, но теперь она не будет аварийно завершаться, а исключение будет обрабатываться в блоке catch.
Следует отметить, что в этой конструкции обязателен блок try. При наличии блока catch мы можем опустить блок finally:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch { Console.WriteLine("Возникло исключение!"); }
И, наоборот, при наличии блока finally мы можем опустить блок catch и не обрабатывать исключение:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } finally { Console.WriteLine("Блок finally"); }
Однако, хотя с точки зрения синтаксиса C# такая конструкция вполне корректна, тем не менее, поскольку CLR не сможет найти нужный блок catch, то исключение не будет обработано, и программа аварийно завершится.
Обработка исключений и условные конструкции
Ряд исключительных ситуаций может быть предвиден разработчиком. Например, пусть программа предусматривает ввод числа и вывод его квадрата:
static void Main(string[] args) { Console.WriteLine("Введите число"); int x = Int32.Parse(Console.ReadLine()); x *= x; Console.WriteLine("Квадрат числа: " + x); Console.Read(); }
Если пользователь введет не число, а строку, какие-то другие символы, то программа выпадет в ошибку. С одной стороны, здесь как раз та ситуация, когда можно применить блок try..catch, чтобы обработать возможную ошибку. Однако гораздо оптимальнее было бы проверить допустимость преобразования:
static void Main(string[] args) { Console.WriteLine("Введите число"); int x; string input = Console.ReadLine(); if (Int32.TryParse(input, out x)) { x *= x; Console.WriteLine("Квадрат числа: " + x); } else { Console.WriteLine("Некорректный ввод"); } Console.Read(); }
Метод Int32.TryParse() возвращает true, если преобразование можно осуществить, и false — если нельзя. При допустимости преобразования переменная x будет содержать введенное число. Так, не используя try…catch можно обработать возможную исключительную ситуацию.
С точки зрения производительности использование блоков try..catch более накладно, чем применение условных конструкций. Поэтому по возможности вместо try..catch лучше использовать условные конструкции на проверку исключительных ситуаций.
Блок catch и фильтры исключений
Определение блока catch
За обработку исключения отвечает блок catch, который может иметь следующие формы:
-
Обрабатывает любое исключение, которое возникло в блоке try. Выше уже был продемонстрирован пример подобного блока.
catch { // выполняемые инструкции }
-
Обрабатывает только те исключения, которые соответствуют типу, указаному в скобках после оператора catch.
catch (тип_исключения) { // выполняемые инструкции }
Например, обработаем только исключения типа DivideByZeroException:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch(DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); }
Однако если в блоке try возникнут исключения каких-то других типов, отличных от DivideByZeroException, то они не будут обработаны.
-
Обрабатывает только те исключения, которые соответствуют типу, указаному в скобках после оператора catch. А вся информация об исключении помещается в переменную данного типа.
catch (тип_исключения имя_переменной) { // выполняемые инструкции }
Например:
try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch(DivideByZeroException ex) { Console.WriteLine($"Возникло исключение {ex.Message}"); }
Фактически этот случай аналогичен предыдущему за тем исключением, что здесь используется переменная. В данном случае в переменную ex, которая представляет тип DivideByZeroException, помещается информация о возникшем исключени. И с помощью свойства Message мы можем получить сообщение об ошибке.
Если нам не нужна информация об исключении, то переменную можно не использовать как в предыдущем случае.
Фильтры исключений
Фильтры исключений позволяют обрабатывать исключения в зависимости от определенных условий. Для их применения после выражения catch идет выражение when, после которого в скобках указывается условие:
В этом случае обработка исключения в блоке catch производится только в том случае, если условие в выражении when истинно. Например:
int x = 1; int y = 0; try { int result = x / y; } catch(DivideByZeroException) when (y==0 && x == 0) { Console.WriteLine("y не должен быть равен 0"); } catch(DivideByZeroException ex) { Console.WriteLine(ex.Message); }
В данном случае будет выброшено исключение, так как y=0. Здесь два блока catch, и оба они обрабатывают исключения типа DivideByZeroException, то есть по сути все исключения, генерируемые при делении на ноль. Но поскольку для первого блока указано условие y == 0 && x == 0, то оно не будет обрабатывать исключение — условие, указанное после оператора when возвращает false. Поэтому CLR будет дальше искать соответствующие блоки catch далее и для обработки исключения выберет второй блок catch. В итоге если мы уберем второй блок catch, то исключение вобще не будет обрабатываться.
Типы исключений. Класс Exception
Базовым для всех типов исключений является тип Exception. Этот тип определяет ряд свойств, с помощью которых можно получить информацию об исключении.
-
InnerException: хранит информацию об исключении, которое послужило причиной текущего исключения
-
Message: хранит сообщение об исключении, текст ошибки
-
Source: хранит имя объекта или сборки, которое вызвало исключение
-
StackTrace: возвращает строковое представление стека вызывов, которые привели к возникновению исключения
-
TargetSite: возвращает метод, в котором и было вызвано исключение
Например, обработаем исключения типа Exception:
static void Main(string[] args) { try { int x = 5; int y = x / 0; Console.WriteLine($"Результат: {y}"); } catch (Exception ex) { Console.WriteLine($"Исключение: {ex.Message}"); Console.WriteLine($"Метод: {ex.TargetSite}"); Console.WriteLine($"Трассировка стека: {ex.StackTrace}"); } Console.Read(); }

Однако так как тип Exception является базовым типом для всех исключений, то выражение catch (Exception ex) будет обрабатывать все исключения, которые могут возникнуть.
Но также есть более специализированные типы исключений, которые предназначены для обработки каких-то определенных видов исключений. Их довольно много, я приведу лишь некоторые:
-
DivideByZeroException: представляет исключение, которое генерируется при делении на ноль
-
ArgumentOutOfRangeException: генерируется, если значение аргумента находится вне диапазона допустимых значений
-
ArgumentException: генерируется, если в метод для параметра передается некорректное значение
-
IndexOutOfRangeException: генерируется, если индекс элемента массива или коллекции находится вне диапазона допустимых значений
-
InvalidCastException: генерируется при попытке произвести недопустимые преобразования типов
-
NullReferenceException: генерируется при попытке обращения к объекту, который равен null (то есть по сути неопределен)
И при необходимости мы можем разграничить обработку различных типов исключений, включив дополнительные блоки catch:
static void Main(string[] args) { try { int[] numbers = new int[4]; numbers[7] = 9; // IndexOutOfRangeException int x = 5; int y = x / 0; // DivideByZeroException Console.WriteLine($"Результат: {y}"); } catch (DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); } catch (IndexOutOfRangeException ex) { Console.WriteLine(ex.Message); } Console.Read(); }
В данном случае блоки catch обрабатывают исключения типов IndexOutOfRangeException, DivideByZeroException и Exception. Когда в блоке try возникнет исключение, то CLR будет искать нужный блок catch для обработки исключения. Так, в данном случае на строке
происходит обращение к 7-му элементу массива. Однако поскольку в массиве только 4 элемента, то мы получим исключение типа IndexOutOfRangeException. CLR найдет блок catch, который обрабатывает данное исключение, и передаст ему управление.
Следует отметить, что в данном случае в блоке try есть ситуация для генерации второго исключения — деление на ноль. Однако поскольку после генерации IndexOutOfRangeException управление переходит в соответствующий блок catch, то деление на ноль int y = x / 0 в принципе не будет выполняться, поэтому исключение типа DivideByZeroException никогда не будет сгенерировано.
Однако рассмотрим другую ситуацию:
static void Main(string[] args) { try { object obj = "you"; int num = (int)obj; // InvalidCastException Console.WriteLine($"Результат: {num}"); } catch (DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); } catch (IndexOutOfRangeException) { Console.WriteLine("Возникло исключение IndexOutOfRangeException"); } Console.Read(); }
В данном случае в блоке try генерируется исключение типа InvalidCastException, однако соответствующего блока catch для обработки данного исключения нет. Поэтому программа аварийно завершит свое выполнение.
Мы также можем определить для InvalidCastException свой блок catch, однако суть в том, что теоретически в коде могут быть сгенерированы сами различные типы исключений. А определять для всех типов исключений блоки catch, если обработка исключений однотипна, не имеет смысла. И в этом случае мы можем определить блок catch для базового типа Exception:
static void Main(string[] args) { try { object obj = "you"; int num = (int)obj; // InvalidCastException Console.WriteLine($"Результат: {num}"); } catch (DivideByZeroException) { Console.WriteLine("Возникло исключение DivideByZeroException"); } catch (IndexOutOfRangeException) { Console.WriteLine("Возникло исключение IndexOutOfRangeException"); } catch (Exception ex) { Console.WriteLine($"Исключение: {ex.Message}"); } Console.Read(); }
И в данном случае блок catch (Exception ex){} будет обрабатывать все исключения кроме DivideByZeroException и IndexOutOfRangeException. При этом блоки catch для более общих, более базовых исключений следует помещать в конце — после блоков catch для более конкретный, специализированных типов. Так как CLR выбирает для обработки исключения первый блок catch, который соответствует типу сгенерированного исключения. Поэтому в данном случае сначала обрабатывается исключение DivideByZeroException и IndexOutOfRangeException, и только потом Exception (так как DivideByZeroException и IndexOutOfRangeException наследуется от класса Exception).
Создание классов исключений
Если нас не устраивают встроенные типы исключений, то мы можем создать свои типы. Базовым классом для всех исключений является класс Exception, соответственно для создания своих типов мы можем унаследовать данный класс.
Допустим, у нас в программе будет ограничение по возрасту:
class Program { static void Main(string[] args) { try { Person p = new Person { Name = "Tom", Age = 17 }; } catch (Exception ex) { Console.WriteLine($"Ошибка: {ex.Message}"); } Console.Read(); } } class Person { private int age; public string Name { get; set; } public int Age { get { return age; } set { if (value < 18) { throw new Exception("Лицам до 18 регистрация запрещена"); } else { age = value; } } } }
В классе Person при установке возраста происходит проверка, и если возраст меньше 18, то выбрасывается исключение. Класс Exception принимает в конструкторе в качестве параметра строку, которое затем передается в его свойство Message.
Но иногда удобнее использовать свои классы исключений. Например, в какой-то ситуации мы хотим обработать определенным образом только те исключения, которые относятся к классу Person. Для этих целей мы можем сделать специальный класс PersonException:
class PersonException : Exception { public PersonException(string message) : base(message) { } }
По сути класс кроме пустого конструктора ничего не имеет, и то в конструкторе мы просто обращаемся к конструктору базового класса Exception, передавая в него строку message. Но теперь мы можем изменить класс Person, чтобы он выбрасывал исключение именно этого типа и соответственно в основной программе обрабатывать это исключение:
class Program { static void Main(string[] args) { try { Person p = new Person { Name = "Tom", Age = 17 }; } catch (PersonException ex) { Console.WriteLine("Ошибка: " + ex.Message); } Console.Read(); } } class Person { private int age; public int Age { get { return age; } set { if (value < 18) throw new PersonException("Лицам до 18 регистрация запрещена"); else age = value; } } }
Однако необязательно наследовать свой класс исключений именно от типа Exception, можно взять какой-нибудь другой производный тип. Например, в данном случае мы можем взять тип ArgumentException, который представляет исключение, генерируемое в результате передачи аргументу метода некорректного значения:
class PersonException : ArgumentException { public PersonException(string message) : base(message) { } }
Каждый тип исключений может определять какие-то свои свойства. Например, в данном случае мы можем определить в классе свойство для хранения устанавливаемого значения:
class PersonException : ArgumentException { public int Value { get;} public PersonException(string message, int val) : base(message) { Value = val; } }
В конструкторе класса мы устанавливаем это свойство и при обработке исключения мы его можем получить:
class Person { public string Name { get; set; } private int age; public int Age { get { return age; } set { if (value < 18) throw new PersonException("Лицам до 18 регистрация запрещена", value); else age = value; } } } class Program { static void Main(string[] args) { try { Person p = new Person { Name = "Tom", Age = 13 }; } catch (PersonException ex) { Console.WriteLine($"Ошибка: {ex.Message}"); Console.WriteLine($"Некорректное значение: {ex.Value}"); } Console.Read(); } }
Поиск блока catch при обработке исключений
Если код, который вызывает исключение, не размещен в блоке try или помещен в конструкцию try..catch, которая не содержит соответствующего блока catch для обработки возникшего исключения, то система производит поиск соответствующего обработчика исключения в стеке вызовов.
Например, рассмотрим следующую программу:
using System; namespace HelloApp { class Program { static void Main(string[] args) { try { TestClass.Method1(); } catch (DivideByZeroException ex) { Console.WriteLine($"Catch в Main : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Main"); } Console.WriteLine("Конец метода Main"); Console.Read(); } } class TestClass { public static void Method1() { try { Method2(); } catch (IndexOutOfRangeException ex) { Console.WriteLine($"Catch в Method1 : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Method1"); } Console.WriteLine("Конец метода Method1"); } static void Method2() { try { int x = 8; int y = x / 0; } finally { Console.WriteLine("Блок finally в Method2"); } Console.WriteLine("Конец метода Method2"); } } }
В данном случае стек вызовов выглядит следующим образом: метод Main вызывает метод Method1, который, в свою очередь, вызывает метод Method2. И в методе Method2 генерируется исключение DivideByZeroException. Визуально стек вызовов можно представить следующим образом:

Внизу стека метод Main, с которого началось выполнение, и на самом верху метод Method2.
Что будет происходить в данном случае при генерации исключения?
-
Метод Main вызывает метод Method1, а тот вызывает метод Method2, в котором генерируется исключение DivideByZeroException.
-
Система видит, что код, который вызывал исключение, помещен в конструкцию try..catch
try { int x = 8; int y = x / 0; } finally { Console.WriteLine("Блок finally в Method2"); }
Система ищет в этой конструкции блок catch, который обрабатывает исключение DivideByZeroException. Однако такого блока catch нет.
-
Система опускается в стеке вызовов в метод Method1, который вызывал Method2. Здесь вызов Method2 помещен в конструкцию try..catch
try { Method2(); } catch (IndexOutOfRangeException ex) { Console.WriteLine($"Catch в Method1 : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Method1"); }
Система также ищет в этой конструкции блок catch, который обрабатывает исключение DivideByZeroException. Однако здесь также подобный блок catch отсутствует.
-
Система далее опускается в стеке вызовов в метод Main, который вызывал Method1. Здесь вызов Method1 помещен в конструкцию try..catch
try { TestClass.Method1(); } catch (DivideByZeroException ex) { Console.WriteLine($"Catch в Main : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Main"); }
Система снова ищет в этой конструкции блок catch, который обрабатывает исключение DivideByZeroException. И в данном случае ткой блок найден.
-
Система наконец нашла нужный блок catch в методе Main, для обработки исключения, которое возникло в методе Method2 — то есть к начальному методу, где непосредственно возникло исключение. Но пока данный блок catch НЕ выполняется. Система поднимается обратно по стеку вызовов в самый верх в метод Method2 и выполняет в нем блок finally:
finally { Console.WriteLine("Блок finally в Method2"); }
-
Далее система возвращается по стеку вызовов вниз в метод Method1 и выполняет в нем блок finally:
finally { Console.WriteLine("Блок finally в Method1"); }
-
Затем система переходит по стеку вызовов вниз в метод Main и выполняет в нем найденный блок catch и последующий блок finally:
catch (DivideByZeroException ex) { Console.WriteLine($"Catch в Main : {ex.Message}"); } finally { Console.WriteLine("Блок finally в Main"); }
-
Далее выполняется код, который идет в методе Main после конструкции try..catch:
Console.WriteLine("Конец метода Main");
Стоит отметить, что код, который идет после конструкции try…catch в методах Method1 и Method2, не выполняется, потому что обработчик исключения найден именно в методе Main.
Консольный вывод программы:
Блок finally в Method2
Блок finally в Method1
Catch в Main: Попытка деления на нуль.
Блок finally в Main
Конец метода Main
Генерация исключения и оператор throw
Обычно система сама генерирует исключения при определенных ситуациях, например, при делении числа на ноль. Но язык C# также позволяет генерировать исключения вручную с помощью оператора throw. То есть с помощью этого оператора мы сами можем создать исключение и вызвать его в процессе выполнения.
Например, в нашей программе происходит ввод строки, и мы хотим, чтобы, если длина строки будет больше 6 символов, возникало исключение:
static void Main(string[] args) { try { Console.Write("Введите строку: "); string message = Console.ReadLine(); if (message.Length > 6) { throw new Exception("Длина строки больше 6 символов"); } } catch (Exception e) { Console.WriteLine($"Ошибка: {e.Message}"); } Console.Read(); }
После оператора throw указывается объект исключения, через конструктор которого мы можем передать сообщение об ошибке. Естественно вместо типа Exception мы можем использовать объект любого другого типа исключений.
Затем в блоке catch сгенерированное нами исключение будет обработано.
Подобным образом мы можем генерировать исключения в любом месте программы. Но существует также и другая форма использования оператора throw, когда после данного оператора не указывается объект исключения. В подобном виде оператор throw может использоваться только в блоке catch:
try { try { Console.Write("Введите строку: "); string message = Console.ReadLine(); if (message.Length > 6) { throw new Exception("Длина строки больше 6 символов"); } } catch { Console.WriteLine("Возникло исключение"); throw; } } catch (Exception ex) { Console.WriteLine(ex.Message); }
В данном случае при вводе строки с длиной больше 6 символов возникнет исключение, которое будет обработано внутренним блоком catch. Однако поскольку в этом блоке используется оператор throw, то исключение будет передано дальше внешнему блоку catch.
Методы поиска ошибок в программах
Международный стандарт ANSI/IEEE-729-83 разделяет все ошибки в разработке программ на следующие типы.
Ошибка (error) — состояние программы, при котором выдаются неправильные результаты, причиной которых являются изъяны (flaw) в операторах программы или в технологическом процессе ее разработки, что приводит к неправильной интерпретации исходной информации, следовательно, и к неверному решению.
Дефект (fault) в программе — следствие ошибок разработчика на любом из этапов разработки, которая может содержаться в исходных или проектных спецификациях, текстах кодов программ, эксплуатационной документация и т.п. В процессе выполнения программы может быть обнаружен дефект или сбой.
Отказ (failure) — это отклонение программы от функционирования или невозможность программы выполнять функции, определенные требованиями и ограничениями, что рассматривается как событие, способствующее переходу программы в неработоспособное состояние из-за ошибок, скрытых в ней дефектов или сбоев в среде функционирования [7.6, 7.11]. Отказ может быть результатом следующих причин:
- ошибочная спецификация или пропущенное требование, означающее, что спецификация точно не отражает того, что предполагал пользователь;
- спецификация может содержать требование, которое невозможно выполнить на данной аппаратуре и программном обеспечении;
- проект программы может содержать ошибки (например, база данных спроектирована без средств защиты от несанкционированного доступа пользователя, а требуется защита);
- программа может быть неправильной, т.е. она выполняет несвойственный алгоритм или он реализован не полностью.
Таким образом, отказы, как правило, являются результатами одной или более ошибок в программе, а также наличия разного рода дефектов.
Ошибки на этапах процесса тестирования. Приведенные типы ошибок распределяются по этапам ЖЦ и им соответствуют такие источники их возникновения:
- непреднамеренное отклонение разработчиков от рабочих стандартов или планов реализации;
- спецификации функциональных и интерфейсных требований выполнены без соблюдения стандартов разработки, что приводит к нарушению функционирования программ;
- организации процесса разработки — несовершенная или недостаточное управление руководителем проекта ресурсами (человеческими, техническими, программными и т.д.) и вопросами тестирования и интеграции элементов проекта.
Рассмотрим процесс тестирования, исходя из рекомендаций стандарта ISO/IEC 12207, и приведем типы ошибок, которые обнаруживаются на каждом процессе ЖЦ.
Процесс разработки требований. При определении исходной концепции системы и исходных требований к системе возникают ошибки аналитиков при спецификации верхнего уровня системы и построении концептуальной модели предметной области.
Характерными ошибками этого процесса являются:
- неадекватность спецификации требований конечным пользователям;
- некорректность спецификации взаимодействия ПО со средой функционирования или с пользователями;
- несоответствие требований заказчика к отдельным и общим свойствам ПО;
- некорректность описания функциональных характеристик;
- необеспеченность инструментальными средствами всех аспектов реализации требований заказчика и др.
Процесс проектирования. Ошибки при проектировании компонентов могут возникать при описании алгоритмов, логики управления, структур данных, интерфейсов, логики моделирования потоков данных, форматов ввода-вывода и др. В основе этих ошибок лежат дефекты спецификаций аналитиков и недоработки проектировщиков. К ним относятся ошибки, связанные:
- с определением интерфейса пользователя со средой;
- с описанием функций (неадекватность целей и задач компонентов, которые обнаруживаются при проверке комплекса компонентов);
- с определением процесса обработки информации и взаимодействия между процессами (результат некорректного определения взаимосвязей компонентов и процессов);
- с некорректным заданием данных и их структур при описании отдельных компонентов и ПС в целом;
- с некорректным описанием алгоритмов модулей;
- с определением условий возникновения возможных ошибок в программе;
- с нарушением принятых для проекта стандартов и технологий.
Этап кодирования. На данном этапе возникают ошибки, которые являются результатом дефектов проектирования, ошибок программистов и менеджеров в процессе разработки и отладки системы. Причиной ошибок являются:
- бесконтрольность значений входных параметров, индексов массивов, параметров циклов, выходных результатов, деления на 0 и др.;
- неправильная обработка нерегулярных ситуаций при анализе кодов возврата от вызываемых подпрограмм, функций и др.;
- нарушение стандартов кодирования (плохие комментарии, нерациональное выделение модулей и компонент и др.);
- использование одного имени для обозначения разных объектов или разных имен одного объекта, плохая мнемоника имен;
- несогласованное внесение изменений в программу разными разработчиками и др.
Процесс тестирования. На этом процессе ошибки допускаются программистами и тестировщиками при выполнении технологии сборки и тестирования, выбора тестовых наборов и сценариев тестирования и др. Отказы в программном обеспечении, вызванные такого рода ошибками, должны выявляться, устраняться и не отражаться на статистике ошибок компонент и программного обеспечения в целом.
Процесс сопровождения. На процессе сопровождения обнаруживаются ошибки, причиной которых являются недоработки и дефекты эксплуатационной документации, недостаточные показатели модифицируемости и удобочитаемости, а также некомпетентность лиц, ответственных за сопровождение и/или усовершенствование ПО. В зависимости от сущности вносимых изменений на этом этапе могут возникать практически любые ошибки, аналогичные ранее перечисленным ошибкам на предыдущих этапах.
Все ошибки, которые возникают в программах, принято подразделять на следующие классы:
- логические и функциональные ошибки;
- ошибки вычислений и времени выполнения;
- ошибки вводавывода и манипулирования данными;
- ошибки интерфейсов;
- ошибки объема данных и др.
Логические ошибки являются причиной нарушения логики алгоритма, внутренней несогласованности переменных и операторов, а также правил программирования. Функциональные ошибки — следствие неправильно определенных функций, нарушения порядка их применения или отсутствия полноты их реализации и т.д.
Ошибки вычислений возникают по причине неточности исходных данных и реализованных формул, погрешностей методов, неправильного применения операций вычислений или операндов. Ошибки времени выполнения связаны с необеспечением требуемой скорости обработки запросов или времени восстановления программы.
Ошибки ввода-вывода и манипулирования данными являются следствием некачественной подготовки данных для выполнения программы, сбоев при занесении их в базы данных или при выборке из нее.
Ошибки интерфейса относятся к ошибкам взаимосвязи отдельных элементов друг с другом, что проявляется при передаче данных между ними, а также при взаимодействии со средой функционирования.
Ошибки объема относятся к данным и являются следствием того, что реализованные методы доступа и размеры баз данных не удовлетворяют реальным объемам информации системы или интенсивности их обработки.
Приведенные основные классы ошибок свойственны разным типам компонентов ПО и проявляются они в программах по разному. Так, при работе с БД возникают ошибки представления и манипулирования данными, логические ошибки в задании прикладных процедур обработки данных и др. В программах вычислительного характера преобладают ошибки вычислений, а в программах управления и обработки — логические и функциональные ошибки. В ПО, которое состоит из множества разноплановых программ, реализующих разные функции, могут содержаться ошибки разных типов. Ошибки интерфейсов и нарушение объема характерны для любого типа систем.
Анализ типов ошибок в программах является необходимым условием создания планов тестирования и методов тестирования для обеспечения правильности ПО.
На современном этапе развития средств поддержки разработки ПО (CASE-технологии, объектно-ориентированные методы и средства проектирования моделей и программ) проводится такое проектирование, при котором ПО защищается от наиболее типичных ошибок и тем самым предотвращается появление программных дефектов.
Связь ошибки с отказом. Наличие ошибки в программе, как правило, приводит к отказу ПО при его функционировании. Для анализа причинно-следственных связей «ошибкаотказ» выполняются следующие действия:
- идентификация изъянов в технологиях проектирования и программирования;
- взаимосвязь изъянов процесса проектирования и допускаемых человеком ошибок;
- классификация отказов, изъянов и возможных ошибок, а также дефектов на каждом этапе разработки;
- сопоставление ошибок человека, допускаемых на определенном процессе разработки, и дефектов в объекте, как следствий ошибок спецификации проекта, моделей программ;
- проверка и защита от ошибок на всех этапах ЖЦ, а также обнаружение дефектов на каждом этапе разработки;
- сопоставление дефектов и отказов в ПО для разработки системы взаимосвязей и методики локализации, сбора и анализа информации об отказах и дефектах;
- разработка подходов к процессам документирования и испытания ПО.
Конечная цель причинно-следственных связей «ошибка-отказ» заключается в определении методов и средств тестирования и обнаружения ошибок определенных классов, а также критериев завершения тестирования на множестве наборов данных; в определении путей совершенствования организации процесса разработки, тестирования и сопровождения ПО.
Приведем следующую классификацию типов отказов:
- аппаратный, при котором общесистемное ПО не работоспособно;
- информационный, вызванный ошибками во входных данных и передаче данных по каналам связи, а также при сбое устройств ввода (следствие аппаратных отказов);
- эргономический, вызванный ошибками оператора при его взаимодействии с машиной (этот отказ — вторичный отказ, может привести к информационному или функциональному отказам);
- программный, при наличии ошибок в компонентах и др.
Некоторые ошибки могут быть следствием недоработок при определении требований, проекта, генерации выходного кода или документации. С другой стороны, они порождаются в процессе разработки программы или при разработке интерфейсов отдельных элементов программы (нарушение порядка параметров, меньше или больше параметров и т.п.).
Источники ошибок. Ошибки могут быть порождены в процессе разработки проекта, компонентов, кода и документации. Как правило, они обнаруживаются при выполнении или сопровождении программного обеспечения в самых неожиданных и разных ее точках.
Некоторые ошибки в программе могут быть следствием недоработок при определении требований, проекта, генерации кода или документации. С другой стороны, ошибки порождаются в процессе разработки программы или интерфейсов ее элементов (например, при нарушении порядка задания параметров связи — меньше или больше, чем требуется и т.п.).
Причиной появления ошибок — непонимание требований заказчика; неточная спецификация требований в документах проекта и др. Это приводит к тому, что реализуются некоторые функции системы, которые будут работать не так, как предлагает заказчик. В связи с этим проводится совместное обсуждение заказчиком и разработчиком некоторых деталей требований для их уточнения.
Команда разработчиков системы может также изменить синтаксис и семантику описания системы. Однако некоторые ошибки могут быть не обнаружены (например, неправильно заданы индексы или значения переменных этих операторов).
7.3.2. Классификация ошибок и тестов
Каждая организация, разрабатывающая ПО общесистемного назначения, сталкивается с проблемами нахождения ошибок. Поэтому приходится классифицировать типы обнаруживаемых ошибок и определять свое отношение к устранению этих ошибок.
На основе многолетней деятельности в области создания ПО разные фирмы создали свою классификацию ошибок, основанную на выявлении причин их появления в процессе разработки, в функциях и в области функциональной деятельности ПО.
Известно много различных подходов к классификации ошибок, рассмотрим некоторые из них.
Фирма IВМ разработала подход к классификации ошибок, называемый ортогональной классификацией дефектов [7.4]. Подход предусматривает разбиение ошибок по категориям с соответствующей ответственностью разработчиков за них.
Схема классификации не зависит от продукта, организации разработки и может применяться ко всем стадиям разработки ПО разного назначения. табл. 7.1 дает список ошибок согласно данной классификации. Используя эту таблицу, разработчик имеет возможность идентифицировать не только типы ошибок, но и места, где пропущены или совершены ошибки. Предусмотрены ситуации, когда найдена неинициализированная переменная или инициализированной переменной присвоено неправильное значение.
Ортогональность схемы классификации заключается в том, что любой ее термин принадлежит только одной категории.
| Контекст ошибки | Классификация дефектов |
|---|---|
| Функция | Ошибки интерфейсов конечных пользователей ПО, вызванные аппаратурой или связаны с глобальными структурами данных |
| Интерфейс | Ошибки во взаимодействии с другими компонентами, в вызовах, макросах, управляющих блоках или в списке параметров |
| Логика | Ошибки в программной логике, неохваченной валидацией, а также в использовании значений переменных |
| Присваивание | Ошибки в структуре данных или в инициализации переменных отдельных частей программы |
| Зацикливание | Ошибки, вызванные ресурсом времени, реальным временем или разделением времени |
| Среда | Ошибки в репозитории, в управлении изменениями или в контролируемых версиях проекта |
| Алгоритм | Ошибки, связанные с обеспечением эффективности, корректности алгоритмов или структур данных системы |
| Документация | Ошибки в записях документов сопровождения или в публикациях |
Другими словами, прослеживаемая ошибка в системе должна находиться в одном из классов, что дает возможность разным разработчикам классифицировать ошибки одинаковым способом.
Фирма Hewlett-Packard использовала классификацию Буча, установив процентное соотношение ошибок, обнаруживаемых в ПО на разных стадиях разработки (рис. 7.2) [7.12].
Это соотношение — типичное для многих фирм, производящих ПО, имеет некоторые отклонения.
Исследования фирм IBM показали, чем позже обнаруживается ошибка в программе, тем дороже обходится ее исправление, эта зависимость близка к экспоненциальной. Так военновоздушные силы США оценили стоимость разработки одной инструкции в 75 долларов, а ее стоимость сопровождения составляет около 4000 долларов.

Рис.
7.2.
Процентное соотношение ошибок при разработке ПО
Согласно данным [7.6, 7.11] стоимость анализа и формирования требований, внесения в них изменений составляет примерно 10%, аналогично оценивается стоимость спецификации продукта. Стоимость кодирования оценивается более чем 20%, а стоимость тестирования продукта составляет более 45% от его общей стоимости. Значительную часть стоимости составляет сопровождение готового продукта и исправление обнаруженных в нем ошибок.
Определение теста.Для проверки правильности программ специально разрабатываются тесты и тестовые данные. Под тестом понимается некоторая программа, предназначенная для проверки работоспособности другой программы и обнаружения в ней ошибочных ситуаций. Тестовую проверку можно провести также путем введения в проверяемую программу отладочных операторов, которые будут сигнализировать о ходе ее выполнения и получения результатов.
Тестовые данные служат для проверки работы системы и составляются разными способами: генератором тестовых данных, проектной группой на основе внемашинных документов или имеющихся файлов, пользователем по спецификациям требований и др. Очень часто разрабатываются специальные формы входных документов, в которых отображается процесс выполнения программы с помощью тестовых данных [7.11].
Создаются тесты, проверяющие:
- полноту функций;
- согласованность интерфейсов;
- корректность выполнения функций и правильность функционирования системы в заданных условиях;- надежность выполнения системы;
- защиту от сбоев аппаратуры и не выявленных ошибок и др.
Тестовые данные готовятся как для проверки отдельных программных элементов, так и для групп программ или комплексов на разных стадиях процесса разработки. На рис. 7.3. приведена классификация тестов проверки по объектам тестирования на основных этапах разработки.
Многие типы тестов готовятся заказчиком для проверки работы программной системы. Структура и содержание тестов зависят от вида тестируемого элемента, которым может быть модуль, компонент, группа компонентов, подсистема или система. Некоторые тесты зависят от цели и необходимости знать: работает ли система в соответствии с ее проектом, удовлетворены ли требования и участвует ли заказчик в проверке работы тестов и т.п.
В зависимости от задач, которые ставятся перед тестированием программ, составляются тесты проверки промежуточных результатов проектирования элементов на этапах ЖЦ, а также создаются тесты испытаний окончательного кода системы.
Тесты интегрированной системы.Тесты для проверки отдельных элементов системы и тесты интегрированной системы имеют общие и отличительные черты. Так, на рис. 7.4 в качестве примера приведена схема интеграции готовых оттестированных элементов. В ней заданы связи между разными уровнями тестирования интегрируемой ПС.
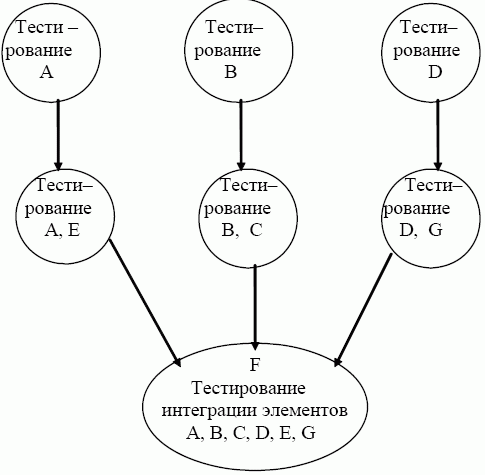
Рис.
7.4.
Интегрированное тестирование компонент
Рассмотрим этот процесс более подробно. Каждый компонент этой схемы тестируется отдельно от других компонентов с помощью тестов, включающих наборы данных и сценарии, составленные в соответствии с их типами и функциями, специфицированные в проекте системы. Тестирование проводится в контрольной операционной среде на предопределенном множестве тестовых данных и операциях, производимых над ними.
Тесты обеспечивают проверку внутренней структуры, логики и граничных условий выполнения для каждого компонента.
Согласно приведенной схеме сначала тестируются компоненты А, В, D независимо друг от друга и каждый с отдельным тестом. После их проверки выполняется проверка интерфейсов для последующей их интеграции, суть которой заключается в анализе выполнения операторов вызова А -> E, B -> C, D -> G, на нижних уровнях графа: компоненты Е, С, G. При этом предполагается, что указанные вызываемые компоненты, так же должны быть отлажены отдельно. Аналогично проверяются все обращения к компоненту F, являющемуся связывающим звеном с вышележащими элементами.
При этом могут возникать ошибки, в случае неправильного задания параметров в операторах вызова или при вычислениях процедур или функций. Возникающие ошибки в связях устраняются, а затем повторно проверяется связь с компонентом F в виде троек: компонентинтерфейскомпонент.Следующим шагом тестирования комплексной системы является проверка функционирования системы с помощью тестов проверки функций и требований к ним. После проверки системы на функциональных тестах происходит проверка на исполнительных и испытательных тестах, подготовленных согласно требованиям к ПО, аппаратуре и выполняемым функциям. Испытательному тесту предшествует верификация и валидация ПО.
Тест испытаний системы в соответствии с требованиями заказчика проверяется в реальной среде, в которой система будет в дальнейшем функционировать.
-
Классификация ошибок
Задача любого
тестировщика заключается в нахождении
наибольшего количества ошибок, поэтому
он должен хорошо знать наиболее часто
допускаемые ошибки и уметь находить их
за минимально короткий период времени.
Остальные ошибки, которые не являются
типовыми, обнаруживаются только тщательно
созданными наборами тестов. Однако из
этого не следует, что для типовых ошибок
не нужно составлять тесты.
Для классификации
ошибок мы должны определить термин
«ошибка».
Ошибка – это
расхождение между вычисленным, наблюдаемым
и истинным, заданным или теоретически
правильным значением.
Итак, по времени
появления ошибки можно разделить на
три вида:
– структурные ошибки
набора;
– ошибки компиляции;
– ошибки периода
выполнения.
Структурные
ошибки
возникают непосредственно при наборе
программы. К данному типу ошибок относятся
такие как: несоответствие числа
открывающих скобок числу закрывающих,
отсутствие парного оператора (например,
try
без catch).
Ошибки
компиляции
возникают из-за ошибок в тексте кода.
Они включают ошибки в синтаксисе,
неверное использование конструкции
языка (оператор else
в операторе for
и т. п.), использование несуществующих
объектов или свойств, методов у объектов,
употребление синтаксических знаков и
т. п.
Ошибки
периода выполнения
возникают, когда программа выполняется
и компилятор (или операционная система,
виртуальная машина) обнаруживает, что
оператор делает попытку выполнить
недопустимое или невозможное действие.
Например, деление на ноль.
Если проанализировать
все типы ошибок согласно первой
классификации, то можно прийти к
заключению, что при тестировании
приходится иметь дело с ошибками периода
выполнения, так как первые два типа
ошибок определяются на этапе кодирования.
В теоретической
информатике программные ошибки
классифицируют по степени нарушения
логики на:
– синтаксические;
–семантические;
– прагматические.
Синтаксические
ошибки
заключаются в нарушении правописания
или пунктуации в записи выражений,
операторов и т. п., т. е. в нарушении
грамматических правил языка. В качестве
примеров синтаксических ошибок можно
назвать:
– пропуск необходимого
знака пунктуации;
– несогласованность
скобок;
– пропуск нужных
скобок;
– неверное написание
зарезервированных слов;
– отсутствие описания
массива.
Все ошибки данного
типа обнаруживаются компилятором.
Семантические
ошибки
заключаются в нарушении порядка
операторов, параметров функций и
употреблении выражений. Например,
параметры у функции add
(на языке Java)
в следующем выражении указаны в
неправильном порядке:
GregorianCalendar.add(1,
Calendar.MONTH).
Параметр, указывающий
изменяемое поле (в примере – месяц),
должен идти первым. Семантические ошибки
также обнаруживаются компилятором.
Надо отметить, что некоторые исследователи
относят семантические ошибки к следующей
группе ошибок.
Прагматические
ошибки (или
логические) заключаются в неправильной
логике алгоритма, нарушении смысла
вычислений и т. п. Они являются самыми
сложными и крайне трудно обнаруживаются.
Компилятор может выявить только следствие
прагматической ошибки.
Таким образом, после
рассмотрения двух классификаций ошибок
можно прийти к выводу, что на этапе
тестирования ищутся прагматические
ошибки периода выполнения, так как
остальные выявляются в процессе
программирования.
На этом можно было
бы закончить рассмотрение классификаций,
но с течением времени накапливался опыт
обнаружения ошибок и сами ошибки,
некоторые из которых образуют характерные
группы, которые могут тоже служить
характерной классификацией.
Ошибка
адресации
– ошибка, состоящая в неправильной
адресации данных (например, выход за
пределы участка памяти).
Ошибка
ввода-вывода
– ошибка, возникающая в процессе обмена
данными между устройствами памяти,
внешними устройствами.
Ошибка
вычисления
– ошибка, возникающая при выполнении
арифметических операций (например,
разнотипные данные, деление на нуль и
др.).
Ошибка
интерфейса
– программная ошибка, вызванная
несовпадением характеристик фактических
и формальных параметров (как правило,
семантическая ошибка периода компиляции,
но может быть и логической ошибкой
периода выполнения).
Ошибка
обращения к данным
– ошибка, возникающая при обращении
программы к данным (например, выход
индекса за пределы массива, не
инициализированные значения переменных
и др.).
Ошибка
описания данных
– ошибка, допущенная в ходе описания
данных.[2]
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #