Наряду с
характеристиками адекватности модели
при оценивании качества модели необходимо
учитывать ее точность.
Как
правило, о точности модели и прогноза
судят по величине погрешности (ошибки).
Ошибка прогноза
это расхождение между
фактическим
и прогнозируемым значением исследуемого
показателя. Использование данного
подхода к оценке точности возможно
только в том случае, когда период
упреждения закончился, и исследователи
имеют фактические значения на период
упреждения или когда разрабатывается
ретропрогноз.
Ретроспективное
прогнозирование разрабатывается для
некоторого момента времени в прошлом,
для которого имеются фактические данные.
В этом случае имеющаяся информация
делится на две части. Первая часть,
включающая более ранние данные,
используется для подбора математической
модели. По построенной математической
модели дается прогноз на последующий
оставшийся период времени. Прогнозные
качества модели оцениваются по более
поздним данным второй части ряда.
Полученные ошибки прогноза в какой-то
мере характеризуют точность подобранных
моделей и могут использоваться при
сопоставлении различных моделей
прогнозирования. В то же время при
использовании ошибки ретроспективного
прогноза в качестве меры точности
необходимо учитывать, что она получена
при использовании только части имеющихся
данных. При использовании полного объема
имеющихся данных трансформируется вид
подобранной модели, и изменяются значения
критериев точности и качества.
Отметим,
что если ретроспективное прогнозирование
осуществляется по модели, содержащей
одну или несколько экзогенных переменных,
точность прогноза будет определяться
точностью определения значения этих
переменных на период упреждения. В
этом случае возможны два способа
определения значений экзогенных
переменных: либо воспользоваться
фактическими известными значениями
экзогенных переменных либо ожидаемыми
их значениями. Естественно, что точность
прогноза в первом случае будет выше.
Наличие данных о
реализации прогнозов дает возможность
оценить качество прогнозов величиной:
![]() ,
,
где
р – число
прогнозов, подтвержденных фактическими
данными (фактическая реализация охвачена
интервальным прогнозом);
q
– число прогнозов, не подтвержденных
фактическими данными.
Использование
коэффициентов
![]()
для разных моделей имеет смысл в том
случае, если доверительные вероятности
прогнозов приняты одинаковыми.
В том случае, если
прогноз дается в виде точечной оценки,
в качестве показателей точности прогноза
могут использоваться такие статистические
характеристики как средняя абсолютная
и среднеквадратическая ошибка прогноза.
Г.
Тейлом предложен в качестве меры качества
прогноза коэффициент расхождения (или
коэффициент несоответствия):
 ,
,
где
![]()
— соответственно предсказанное и
фактическое значение переменной.
Коэффициент
![]() ,
,
когда
![]() (случай совершенного
(случай совершенного
прогнозирования). Коэффициент
![]() ,
,
когда экстраполяция строится исходя
из неизменности приростов. Коэффициент
![]() ,
,
прогноз дает худшие результаты, чем
прогноз методом
простой экстраполяции.
Рассмотренные
выше показатели точности прогноза можно
использовать только
в случае наличия истинных значений
величин, оцениваемых при разработке
прогноза. Согласно этому различают
апостериорную
точность моделей, которая
может быть определена только после
практического использования модели,
и априорную
точность моделей. Априорную или
предполагаемую точность оценивают
в условиях отсутствия информации о
результатах эксплуатации модели.
Исследуя априорную точность модели, мы
охарактеризуем только точность
аппроксимации.
Чаще
всего в качестве показателей точности
применяются следующие показатели:
абсолютная ошибка
![]() ,
,
средняя абсолютная ошибка
![]() ,
,
средняя квадратическая ошибка
![]() ,
,
относительная ошибка
![]() ,
,
средняя относительная ошибка
![]() ,
,
коэффициент сходимости, коэффициент
детерминации
Абсолютная
ошибка прогноза определяется как
разность между фактическим значением
и его оценкой, полученной расчетным
путем по модели:
![]() ,
,
среднее
абсолютное значение ошибки:
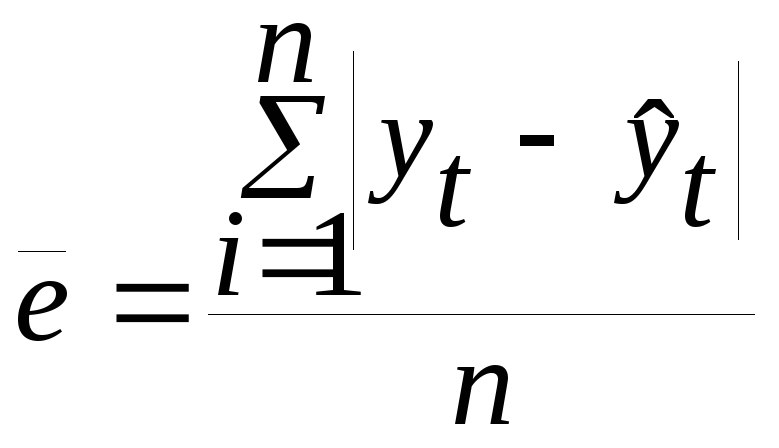 .
.
Средняя
квадратическая ошибка прогноза
рассчитывается по формуле:
 ,
,
где
п
— период
упреждения,
k
– число оцениваемых параметров модели.
Недостатком
рассмотренных характеристик является
их зависимость от масштаба измерения
значений исследуемого показателя.
В
связи с этим более удобными являются
относительные значения этих величин.
Относительная ошибка рассчитывается
следующим образом:
![]() ,
,
а средняя
относительная ошибка определяется
следующим образом:
![]() .
.
Последний
показатель чаще других используется
при сравнении точности прогнозов,
осуществляемых по различным методикам.
Обычно лучшим признается тот прогноз,
который имеет меньшее значение этого
показателя. Принято считать, что если
значение средней относительной ошибки
менее 3-5%, то точность хорошая; если
значение средней относительной ошибки
не превышает 10%, то точность хорошая; от
10% до 15% точность удовлетворительная.
Коэффициент
сходимости определяется по следующей
формуле:
 ,
,
чем меньше значение
коэффициента сходимости, чем лучше
точность модели.
Коэффициент
детерминации определяется по формуле:
![]() ,
,
и поэтому чем
больше значение коэффициента детерминации,
тем лучше точность модели.
Для
выбора лучшей модели можно использовать
один из рассмотренных показателей либо
воспользоваться обобщенным критерием.
Пример.
Оценить адекватность и точность модели
Хольта, построенной в параграфе 5.3.
Решение. В таблице
5.2 приведены ошибки аппроксимации
![]() ,
,
на основе которых будет оцениваться
адекватность модели. Проверку
случайности колебаний уровней остаточной
компоненты проведем, используя критерий
поворотных точек. На рис. 6.2 представлен
ряд остатков, количество поворотных
точек равно 15.
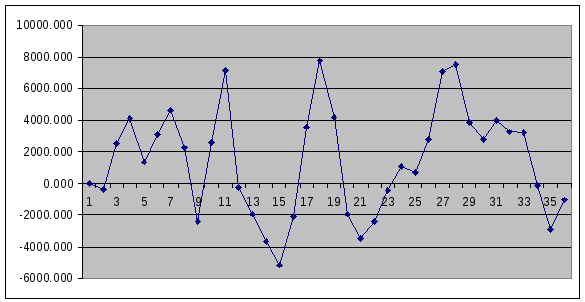
Рис. 6.2. Оценка
адекватности модели. Ряд остатков.
При
n=36:
![]() .
.
Неравенства 15>17 не выполняется,
следовательно, ряд остатков не является
случайным.
Анализ
соответствия ряда остатков нормальному
закону распределения проведем по RS
– критерию:
![]() .
.
Расчетное
значение RS
– критерия сравним с табличными
значениями RS
– критерия (таб. 6.1) . Расчетное RS
– критерия попадает в интервал,
ограниченный табличными значениями
(3,6; 5,06), и с уровнем значимости α=0,05
гипотеза о
нормальности распределения остаточной
компоненты принимается.
Так
как остаточная компонента распределена
по нормальному закону, то осуществим
проверку равенства математического
ожидания остаточной компоненты нулю
с помощью t-критерия
Стьюдента:
Р![]() асчетное
асчетное
значениеt-критерия
больше табличного
значения tα
статистики
Стьюдента
![]() ,
,
следовательно,гипотеза
о равенстве нулю математического
ожидания уровней ряда остатков не
принимается.
Независимость уровней в ряде остатков
проверим по критерию Дарбина–Уотсона
(таб. 6.3).
Таблица 6.3
Расчет d—значенияДарбина–Уотсона
|
t |
|
|
|
|
|
1 |
-23.500 |
552.25 |
||
|
2 |
-415.390 |
-391.890 |
153577.772 |
172548.852 |
|
3 |
2553.781 |
2969.171 |
8815978.8 |
6521799.44 |
|
4 |
4108.015 |
1554.234 |
2415642.82 |
16875789.2 |
|
5 |
1357.017 |
-2750.998 |
7567992.09 |
1841494.74 |
|
6 |
3047.488 |
1690.471 |
2857692.36 |
9287182.51 |
|
7 |
4611.776 |
1564.288 |
2446997.23 |
21268477.8 |
|
8 |
2226.788 |
-2384.988 |
5688168.37 |
4958584.19 |
|
9 |
-2442.290 |
-4669.078 |
21800286 |
5964779.36 |
|
10 |
2620.809 |
5063.099 |
25634971.3 |
6868640.89 |
|
11 |
7156.526 |
4535.717 |
20572724.5 |
51215860.7 |
|
12 |
-255.774 |
-7412.299 |
54942183.2 |
65420.1907 |
|
13 |
-1964.630 |
-1708.857 |
2920190.74 |
3859772.09 |
|
14 |
-3692.014 |
-1727.384 |
2983855.54 |
13630969.5 |
|
15 |
-5152.421 |
-1460.407 |
2132789.2 |
26547447.2 |
|
16 |
-2101.028 |
3051.394 |
9311004.57 |
4414317.05 |
|
17 |
3571.246 |
5672.274 |
32174688.1 |
12753798.1 |
|
18 |
7739.490 |
4168.244 |
17374260.7 |
59899710.6 |
|
19 |
4171.509 |
-3567.981 |
12730490.5 |
17401487.7 |
|
20 |
-1955.050 |
-6126.559 |
37534730.7 |
3822222.1 |
|
21 |
-3465.610 |
-1510.560 |
2281790.33 |
12010452.8 |
|
22 |
-2395.256 |
1070.354 |
1145657.1 |
5737252.69 |
|
23 |
-445.847 |
1949.410 |
3800197.94 |
198779.235 |
|
24 |
1050.970 |
1496.817 |
2240461.18 |
1104538.71 |
|
25 |
694.152 |
-356.818 |
127319.3 |
481847.09 |
|
26 |
2752.621 |
2058.469 |
4237296.08 |
7576924.68 |
|
27 |
7090.334 |
4337.713 |
18815752.4 |
50272839.5 |
|
28 |
7485.321 |
394.987 |
156014.473 |
56030029 |
|
29 |
3824.177 |
-3661.144 |
13403973.2 |
14624331.3 |
|
30 |
2773.655 |
-1050.522 |
1103597.19 |
7693161.27 |
|
31 |
3953.251 |
1179.597 |
1391448.08 |
15628196.9 |
|
32 |
3253.170 |
-700.082 |
490114.569 |
10583112.5 |
|
33 |
3170.670 |
-82.500 |
6806.172 |
10053148.7 |
|
34 |
-134.635 |
-3305.305 |
10925041.8 |
18126.5898 |
|
35 |
-2869.411 |
-2734.776 |
7478999.31 |
8233519.15 |
|
36 |
-1039.034 |
1830.377 |
3350281.25 |
1079590.8 |
|
сумма |
341012975 |
468696705 |
Расчетное
d—значение
равно:
![]() .
.
Расчетное
значение
d—критерия
сравним с двумя табличными значениями
Дарбина—Уотсона
(1,41; 1,52). Так как расчетное d-значение
меньше нижнего табличного значения
d1=1,41,
то гипотеза о
независимости ряда остатков отвергается
и модель неадекватна.
Результаты оценки
модели на адекватность приведены в
таблице 6.4.
Таблица 6.4
Результаты
оценки модели на адекватность
-
Проверяемое
свойствовывод
Случайность
неадекватна
Нормальность
адекватна
Среднее
неадекватна
Независимость
неадекватна
Вывод:
модель статистически неадекватна
Средняя
относительная ошибка равна (таб. 5.2):
![]() .
.
Оцениваемая модель
не является адекватной, и несмотря на
хорошую точность не может использоваться
для прогнозирования.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
 Существует множество моделей прогноза, но как выбрать среди них ту, которая наиболее точно сделает прогноз?
Существует множество моделей прогноза, но как выбрать среди них ту, которая наиболее точно сделает прогноз?
Из данной статьи вы узнаете:
- Какие способы оценки прогноза вы можете использовать?
- Как выбрать оптимальную модель, которая поможет вам сделать максимально точный прогноз?
- Как рассчитать показатель «Точность прогноза»?
Какие способы оценки прогнозной модели вы можете использовать:
1. Оценить отношение фактических продаж к прогнозу;
2. Расчет показателя точность прогноза — оценка на сколько точно выбранная модель описывает анализируемые данные;
3. Графический анализ — строим график и визуально оцениваем адекватность модели прогноза относительно фактических продаж за последний период ;
1-й способ — Расчет отношения фактических продаж к прогнозу.
Сначала рассчитываем прогноз разными способами и оцениваем отношение фактических продаж к прогнозу. ВАЖНО протестировать модели не по одному товару или направлению продаж, а сразу взять 10 и более товарных позиций или направлений продаж и рассчитать прогноз по ним на минимум на 3 периода вперед (количество периодов и направления прогноза зависят от ваших задач. Если задача — сделать точный прогноз на 6 месяцев, то рассчитываем прогноз на 6 месяцев несколькими вариантами и оцениваем отношение факта к прогнозу по сумме полугода).
Рассчитаем прогноз 4 способами на полгода. Протестируем следующие модели:
-
Линейный тренд + сезонность — лист «Линейный» в приложенном файле (см. статью «Как рассчитать прогноз с учетом роста и сезонности в Excel»)
-
Логарифмический тренд + сезонность — лист «Логарифмический» в приложенном файле (см. статью «5 способов расчета значений логарифмического тренда»)
-
Скользящая средняя с сезонностью к 2-м месяцам — лист «Скользящая к 2-м» (см. статью «Как рассчитать прогноз по методу скользящей средней»);
-
Скользящяя средняя с сезонностью к 3-м месяцам — лист «Скользящая к 3-м»;
Для каждой из 4-х прогнозных моделей в листе «Оценка моделей»:
-
Суммируем прогноз по каждой модели за 6 месяцев;
-
Суммируем фактические продажи, которые мы будем сравнивать с прогнозом;
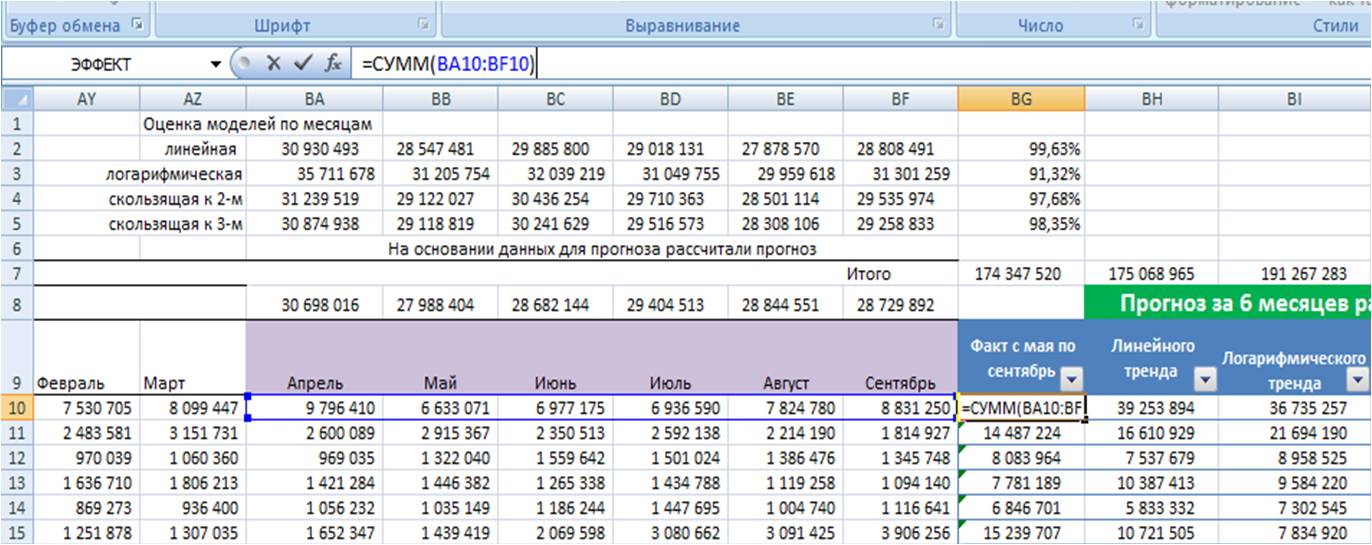
-
Рассчитываем отношение факта к прогнозу по каждой позиции для каждой модели;
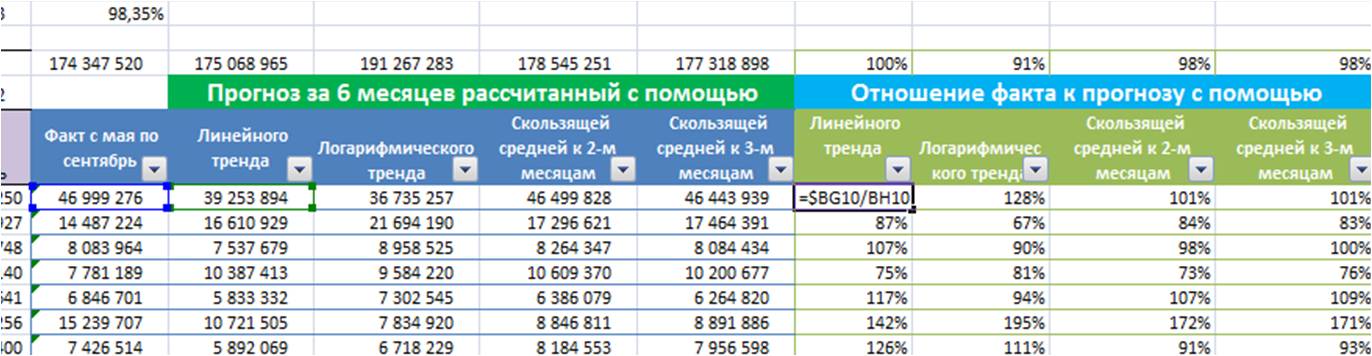
-
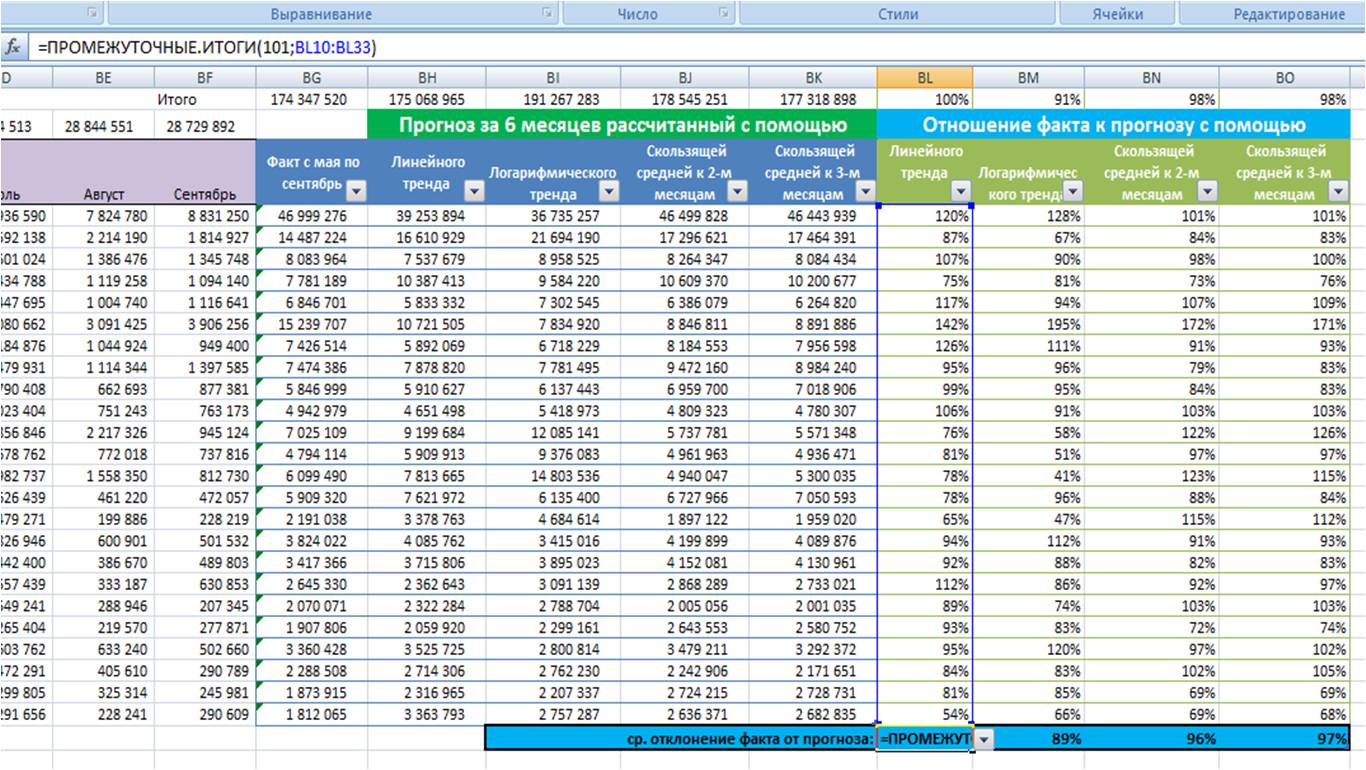
Рассчитываем по каждой модели среднее отношение факта к прогнозу;
-
Выбираем модель прогноза, которая по показателю «среднее отношение факта к прогнозу» оказалась максимально приближена к 100%;
Для наших данных самой точной моделью оказалась скользящая средняя к 3-м месяцам с сезонностью, среднее отклонение факта от прогноза 97%.
Мы протестировали каждую модель прогноза на реальных данных и выбрали для себя оптимальную, которая в среднем показала минимальное отклонение от факлических продаж.
2-й способ оценки модели прогноза — расчет показателя точность прогноза.
Показатель точность прогноза показывает, на сколько точно выбранная модель прогноза описывает данные. Идея в том, чем точнее выбранная модель описывает фактические данные, тем точнее она сделает прогноз.
Как рассчитать точность прогноза? Рассмотрим на примере расчета для модели прогноза с линейным трендом и сезонностью.
1. Рассчитываем значения прогнозной модели для каждого анализируемого момента времени в прошлом.
Для этого значения тренда для анализируемых периодов умножаем на выровненные коэффициенты сезонности (см. файл с примером)
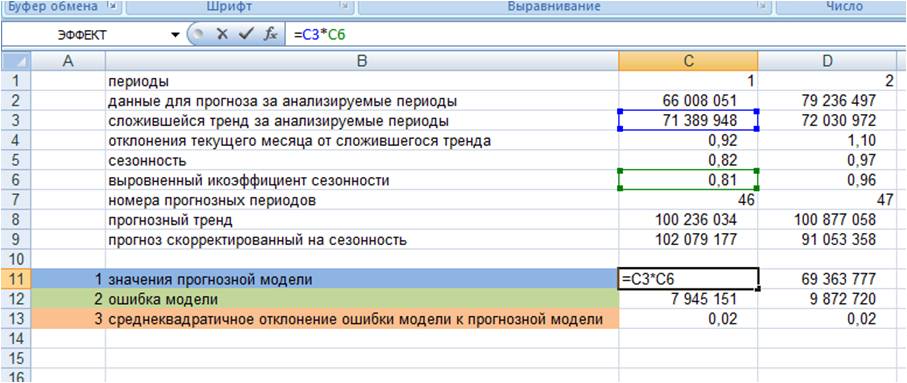
2. Рассчитываем ошибку прогнозной модели. Для этого за каждый период от фактических значений вычитаем значения прогнозной модели.
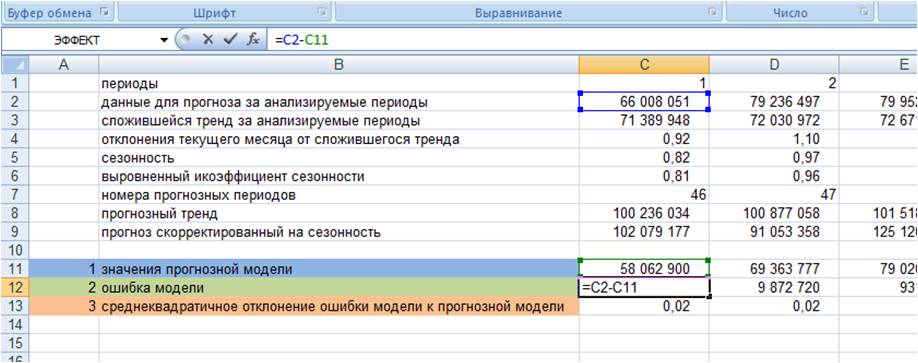
3. Рассчитываем квадратическое отклонение ошибки от значений прогнозной модели (см. файл с примером);
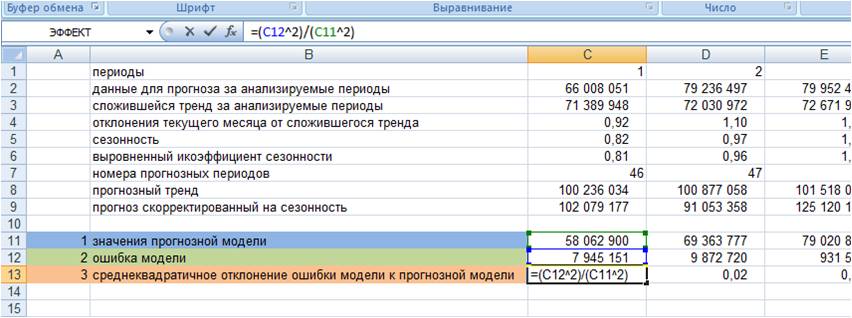
4. Рассчитываем среднее значение квадратического отклонения, т.е. среднеквадратическое отклонение
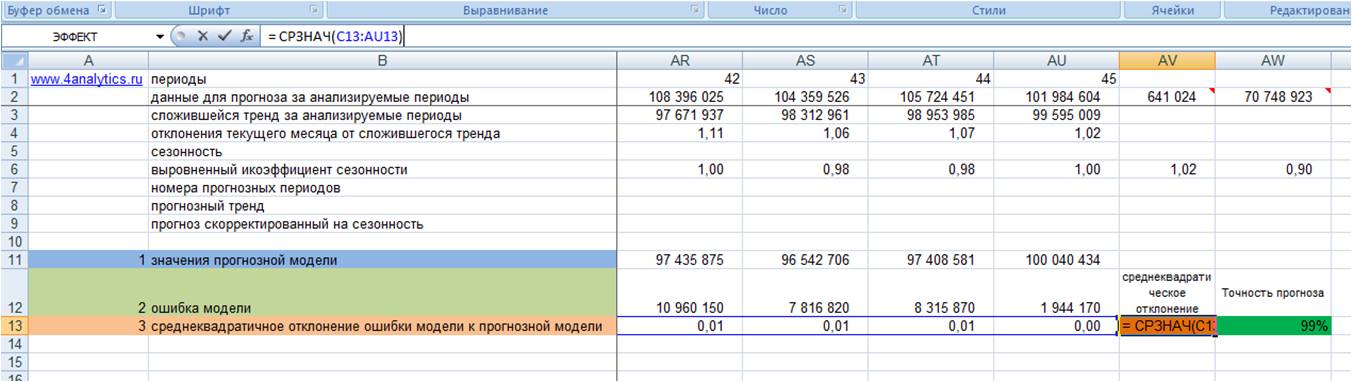
5. Точность прогноза = (1- среднеквадратическое отклонение ошибки прогнозной модели)*100 (см. файл с примером).
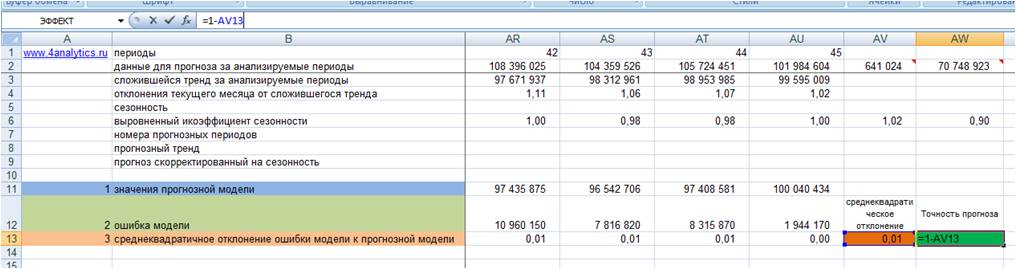
Показатель точности прогноза выражается в процентах:
-
Если точность прогноза равна 100%, то выбранная модель описывает фактические значения на 100%, т.е. очень точно.
-
Если 0% или отрицательное число, то совсем не описывает, и данной модели доверять не стоит.
Выбрать подходящую модель прогноза можно с помощью расчета показателя точность прогноза. Модель прогноза, у которой показатель точность прогноза будет ближе к 100%, с большей вероятностью сделает более точный прогноз. Такую модель можно назвать оптимальной для выбранного временного ряда.
3. Способ оценки прогнозной модели — визуальный.
На график выводим анализируемые данные, тренд, значение модели и прогноз (см. вложенный файл). Обычно визуально видно, какая модель адекватнее строит прогноз . 3-й способ по своей сути схож с 1-м и вторым, только мы верим не цифрам, а тому что мы видим на графике.
Линейная модель:
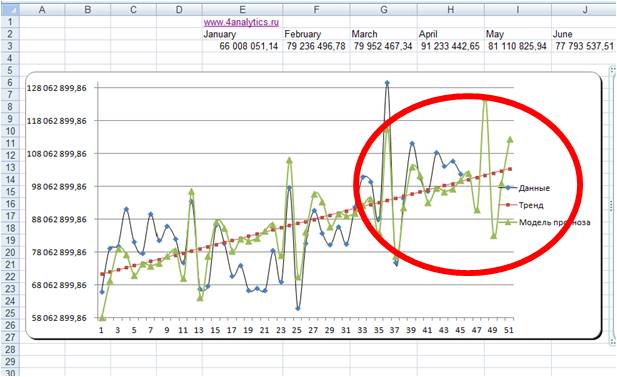
Логарифмическая модель:
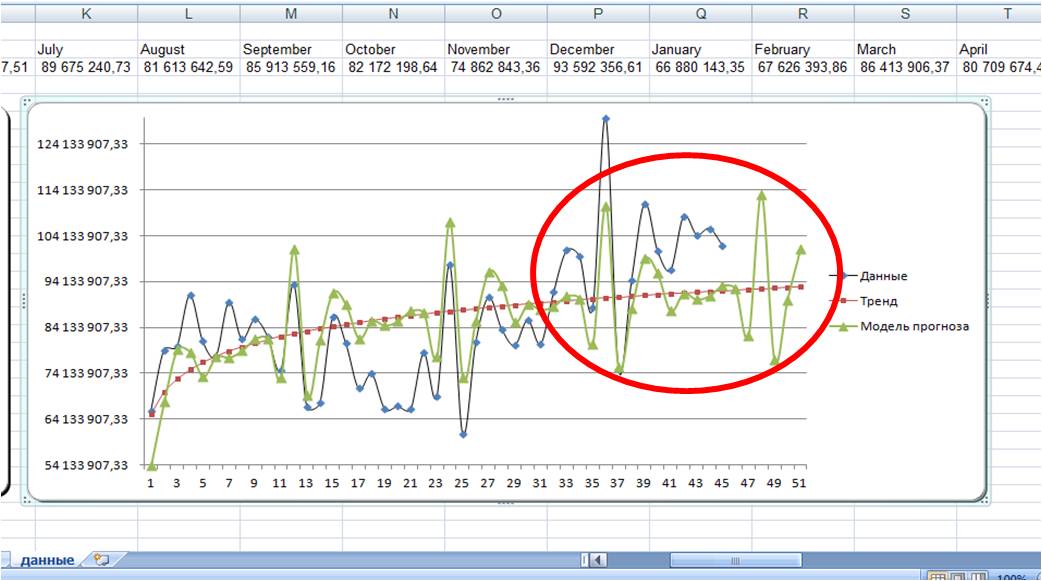
По последним периодам видно, что линейная модель более точно описывает данные за последние месяцы, и она, вероятнее всего, сделает более точный прогноз.
Какую модель прогноза выбрать?
1. Которая на основании тестирования на реальных данных для выбранного промежутка времени (месяца, 3-х месяцев, полугода, года) будет делать максимально точный прогноз, т.е. отношение факта к прогнозу будет близко к 1 или 100%.
2. Модель, которая будет максимально точно описывать фактические данные, т.е. показатель точность прогноза будет приближаться к 1, но не всегда модели точно описывающие данные делают адекватные прогнозы (это надо понимать и оценивать графически).
3. Модель, которой визуально вы больше доверяете с точки зрения описания входящих данных и продления прогнозной модели в будущее.
Для повышения точности прогноза я в своей практике стараюсь использовать 3 этих способа параллельно:
-
По завершении прогнозного периода и в промежутках всегда оцениваю отношение фактических продаж к прогнозу.
-
При построении прогноза анализирую показатель «среднеквадратическое отклонение» и рассчитываю показатель «точность прогноза» для оценки данных и модели.
-
А также на график вывожу анализируемые данные и прогнозную модель, для визуального контроля.
Оценивая прогноз по факту или в промежуточные периоды в случае значительных отклонений фактических продаж от прогнозных, разбираю ситуацию и выясняю причины, в случае необходимости вношу корректировки в прогнозную модель.
С помощью программы Forecast4AC PRO вы можете рассчитать показатель точность прогноза автоматически.
Также Forecast4AC умеет автоматически выбирать оптимальную модель прогноза для каждого временного ряда.
+ одним нажатием строить график «Анализируемые данные + модель прогноза», на котором вы можете оценить, как соотносятся между собой:
-
анализируемые данные;
-
выбранный тренд;
-
модель прогноза;
как в анализируемом периоде, так и в будущем.
Точных прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения
Статья полезная? Поделитесь с друзьями
Точность прогнозирования
Любому человеку, который занимается прогнозированием продаж, важно и необходимо оценивать корректность своих прогнозов. Для этого существует такой показатель, как «Точность прогнозирования». В данной статье именно о нем я и расскажу.
Хочу обратить внимание на то, что в некоторых компаниях данный показатель называют «Аккуратность прогнозирования». Не могу сказать, что это неправильно, но в данной статье будет фигурировать именно «Точность прогнозирования». Ведь мы оцениваем насколько точно наш прогноз совпадает с фактическими значениями, а не аккуратность, с которой мы его высчитывали.
Точность прогнозирования — это показатель, который характеризует качество прогноза. Он отражает насколько сформированный прогноз совпадает с истинными фактическими значениями.
«Точность прогнозирования»: формула, разновидности «ошибок прогноза».
Итак, чтобы рассчитать точность прогнозирования, необходимо сначала рассчитать ошибку прогнозирования в процентах, а затем, вычесть ее из 100%:

В качестве основной ошибки для расчета точности прогнозирования мы будем использовать Взвешенную Абсолютную Процентную Ошибку (WAPE — Weighted Absolute Percent Error), которая рассчитывается по формуле:

То есть: сумма всех отклонений прогноза от факта по модулю, деленное на сумму всех фактов и умноженное на 100%.
Важно! Если ошибка прогнозирования больше 100%, то точность прогнозирования всегда будет равна 0%.
Вообще, помимо WAPE (которую также называют MAD-Mean Ratio), существует множество ошибок, которые мы можем использовать в качестве основной ошибки для расчета точности прогнозирования. Например:
- Средняя Абсолютная Процентная Ошибка (MAPE — Mean Absolute Percent Error)
- Средняя Процентная Ошибка (MPE — Mean Percent Error)
- Медиана Абсолютной Процентной Ошибки (MdAPE — Median Absolute Percent Error)
- Средняя Абсолютная Масштабированная Ошибка (MASE — Mean Absolute Scaled Error)
И так далее (более подробно смотрите здесь). Однако при расчете точности прогнозирования, WAPE — наиболее оптимальный вариант ошибки, так как он наименее чувствителен к выбросам и искажениям, а также интуитивно-понятен и прост в расчете. В общем, WAPE — наш выбор!
Итоговая формула примет вид:
 Про другие ошибки здесь я писать не буду, потому что и использовать мы их не будем, но если у Вас есть желание ознакомиться с ними, рекомендую к прочтению статьи «A survey of forecast error measures» и «Another look at measures of forecast accuracy», а также книгу «Forecasting: Principles and Practice». К сожалению, русскоязычной информации на просторах всемирной сети на эту тематику не очень много, поэтому для изучения материала необходимы минимальные знания английского языка.
Про другие ошибки здесь я писать не буду, потому что и использовать мы их не будем, но если у Вас есть желание ознакомиться с ними, рекомендую к прочтению статьи «A survey of forecast error measures» и «Another look at measures of forecast accuracy», а также книгу «Forecasting: Principles and Practice». К сожалению, русскоязычной информации на просторах всемирной сети на эту тематику не очень много, поэтому для изучения материала необходимы минимальные знания английского языка.
Примеры расчета точности прогнозирования:
Итак, формула расчета точности у нас есть, теперь мы перейдем непосредственно к примеру расчета:

Все просто. У нас есть исходные данные: SKU, факт продаж и прогноз продаж. Для каждого SKU мы находим отклонения по модулю (|факт-прогноз|), а затем суммируем их, получаем 126. Затем суммируем все фактические показатели, получаем 468. Находим ошибку прогнозирования: делим сумму отклонений на сумму фактических показателей — 126/468 = 0,269, то есть 27%. И вычитаем значение ошибки прогнозирования из 100% и получаем точность 73%. Средний результат.
Также, бывают ситуации, когда необходимо рассчитать не общую точность по всем номенклатурам, а отдельно по каждому клиенту (или номенклатурной группе, или по каналам продаж и т.д.). На таблице ниже изображен изображен именно такой пример:

Суть расчетов не меняется, только теперь находим сумму отклонений и сумму фактов для каждого из клиентов по отдельности. Для первого клиента ошибка прогнозирования равна 126/468 = 27%, соответственно точность равна 73% (то же самое, что и в первом примере), а для второго клиента ошибка прогнозирования равна 206/662 = 31%, и точность равна 69%.
В общем-то и все. Мы нашли точность прогнозирования отдельно для списка SKU и отдельно по каждому клиенту. Важно(!) помнить некоторые правила:
- Если ошибка прогнозирования (WAPE) больше 100% — точность прогнозирования всегда 0%. Математически можно записать это так: Точность = Maximum of (1 — Ошибка, 0)
- Если сумма фактов равна нулю (ошибка подразумевает деление на сумму фактов, а на ноль делить нельзя), то рассматриваем два случая:
- если прогноз тоже = 0, то точность всегда равна 100%
- если прогноз ≠ 0, то точность всегда равна 0%
- Перед нахождением точности необходимо проконсолидировать данные, то есть просуммировать объемы по одинаковым позициям (для более подробной детализации — просуммировать объемы по одинаковым позициям для каждого элемента детализации).
Файл с примерами из статьи можно скачать здесь.
Об авторе

HeinzBr
Автор статей и создатель сайта SHTEM.RU