- class torch.nn.MSELoss(size_average=None, reduce=None, reduction=‘mean’)[source]¶
-
Creates a criterion that measures the mean squared error (squared L2 norm) between
each element in the input xx and target yy.The unreduced (i.e. with
reductionset to'none') loss can be described as:ℓ(x,y)=L={l1,…,lN}⊤,ln=(xn−yn)2,ell(x, y) = L = {l_1,dots,l_N}^top, quad
l_n = left( x_n — y_n right)^2,where NN is the batch size. If
reductionis not'none'
(default'mean'), then:ℓ(x,y)={mean(L),if reduction=‘mean’;sum(L),if reduction=‘sum’.ell(x, y) =
begin{cases}
operatorname{mean}(L), & text{if reduction} = text{`mean’;}\
operatorname{sum}(L), & text{if reduction} = text{`sum’.}
end{cases}xx and yy are tensors of arbitrary shapes with a total
of nn elements each.The mean operation still operates over all the elements, and divides by nn.
The division by nn can be avoided if one sets
reduction = 'sum'.- Parameters:
-
-
size_average (bool, optional) – Deprecated (see
reduction). By default,
the losses are averaged over each loss element in the batch. Note that for
some losses, there are multiple elements per sample. If the fieldsize_average
is set toFalse, the losses are instead summed for each minibatch. Ignored
whenreduceisFalse. Default:True -
reduce (bool, optional) – Deprecated (see
reduction). By default, the
losses are averaged or summed over observations for each minibatch depending
onsize_average. WhenreduceisFalse, returns a loss per
batch element instead and ignoressize_average. Default:True -
reduction (str, optional) – Specifies the reduction to apply to the output:
'none'|'mean'|'sum'.'none': no reduction will be applied,
'mean': the sum of the output will be divided by the number of
elements in the output,'sum': the output will be summed. Note:size_average
andreduceare in the process of being deprecated, and in the meantime,
specifying either of those two args will overridereduction. Default:'mean'
-
- Shape:
-
-
Input: (∗)(*), where ∗* means any number of dimensions.
-
Target: (∗)(*), same shape as the input.
-
Examples:
>>> loss = nn.MSELoss() >>> input = torch.randn(3, 5, requires_grad=True) >>> target = torch.randn(3, 5) >>> output = loss(input, target) >>> output.backward()
Loss functions are fundamental in ML model training, and, in most machine learning projects, there is no way to drive your model into making correct predictions without a loss function. In layman terms, a loss function is a mathematical function or expression used to measure how well a model is doing on some dataset. Knowing how well a model is doing on a particular dataset gives the developer insights into making a lot of decisions during training such as using a new, more powerful model or even changing the loss function itself to a different type. Speaking of types of loss functions, there are several of these loss functions which have been developed over the years, each suited to be used for a particular training task.
In this article, we are going to explore these different loss functions which are part of the PyTorch nn module. We will further take a deep dive into how PyTorch exposes these loss functions to users as part of its nn module API by building a custom one.
Now that we have a high-level understanding of what loss functions are, let’s explore some more technical details about how loss functions work.
What are loss functions?
We stated earlier that loss functions tell us how well a model does on a particular dataset. Technically, how it does this is by measuring how close a predicted value is close to the actual value. When our model is making predictions that are very close to the actual values on both our training and testing dataset, it means we have a quite robust model.
Although loss functions give us critical information about the performance of our model, that is not the primary function of loss function, as there are more robust techniques to assess our models such as accuracy and F-scores. The importance of loss functions is mostly realized during training, where we nudge the weights of our model in the direction that minimizes the loss. By doing so, we increase the probability of our model making correct predictions, something which probably would not have been possible without a loss function.

Different loss functions suit different problems, each carefully crafted by researchers to ensure stable gradient flow during training.
Sometimes, the mathematical expressions of loss functions can be a bit daunting, and this has led to some developers treating them as black boxes. We are going to uncover some of PyTorch’s most used loss functions later, but before that, let us take a look at how we use loss functions in the world of PyTorch.
Loss functions in PyTorch
PyTorch comes out of the box with a lot of canonical loss functions with simplistic design patterns that allow developers to easily iterate over these different loss functions very quickly during training. All PyTorch’s loss functions are packaged in the nn module, PyTorch’s base class for all neural networks. This makes adding a loss function into your project as easy as just adding a single line of code. Let’s look at how to add a Mean Square Error loss function in PyTorch.
import torch.nn as nn
MSE_loss_fn = nn.MSELoss()The function returned from the code above can be used to calculate how far a prediction is from the actual value using the format below.
#predicted_value is the prediction from our neural network
#target is the actual value in our dataset
#loss_value is the loss between the predicted value and the actual value
Loss_value = MSE_loss_fn(predicted_value, target)Now that we have an idea of how to use loss functions in PyTorch, let’s dive deep into the behind the scenes of several of the loss functions PyTorch offers.
Which loss functions are available in PyTorch?
A lot of these loss functions PyTorch comes with are broadly categorised into 3 groups — Regression loss, Classification loss and Ranking loss.
Regression losses are mostly concerned with continuous values which can take any value between two limits. One example of this would be predictions of the house prices of a community.
Classification loss functions deal with discrete values, like the task of classifying an object as a box, pen or bottle.
Ranking losses predict the relative distances between values. An example of this would be face verification, where we want to know which face images belong to a particular face, and can do so by ranking which faces do and do not belong to the original face-holder via their degree of relative approximation to the target face scan.
L1 loss function
The L1 loss function computes the mean absolute error between each value in the predicted tensor and that of the target. It first calculates the absolute difference between each value in the predicted tensor and that of the target, and computes the sum of all the values returned from each absolute difference computation. Finally, it computes the average of this sum value to obtain the Mean Absolute Error (MAE). The L1 loss function is very robust for handling noise.

import torch.nn as nn
#size_average and reduce are deprecated
#reduction specifies the method of reduction to apply to output. Possible values are 'mean' (default) where we compute the average of the output, 'sum' where the output is summed and 'none' which applies no reduction to output
Loss_fn = nn.L1Loss(size_average=None, reduce=None, reduction='mean')
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss_fn(input, target)
print(output) #tensor(0.7772, grad_fn=<L1LossBackward>)The single value returned is the computed loss between two tensors with dimension 3 by 5.
Mean Square Error
The Mean Square Error shares some striking similarities with the Mean Absolute Error. Instead of computing the absolute difference between values in the prediction tensor and target, as is the case with Mean Absolute Error, it computes the square difference between values in the prediction tensor and that of the target tensor. By doing so, relatively large differences are penalized more, while relatively small differences are penalized less. MSE is considered less robust at handling outliers and noise than MAE, however.

import torch.nn as nn
loss = nn.MSELoss(size_average=None, reduce=None, reduction='mean')
#L1 loss function parameters explanation applies here.
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
print(output) #tensor(0.9823, grad_fn=<MseLossBackward>)Cross Entropy Loss
Cross Entropy loss is used in classification problems involving a number of discrete classes. It measures the difference between two probability distributions for a given set of random variables. Usually, when using Cross Entropy Loss, the output of our network is a Softmax layer, which ensures that the output of the neural network is a probability value (value between 0-1).
The softmax layer consists of two parts — the exponent of the prediction for a particular class.

yi is the output of the neural network for a particular class. The output of this function is a number close to zero, but never zero, if yi is large and negative, and closer to 1 if yi is positive and very large.
import numpy as np
np.exp(34) #583461742527454.9
np.exp(-34) #1.713908431542013e-15The second part is a normalization value and is used to ensure that the output of the softmax layer is always a probability value.
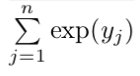
This is obtained by summing all the exponents of each class value. The final equation of softmax looks like this:

In PyTorch’s nn module, cross-entropy loss combines log-softmax and Negative Log-Likelihood Loss into a single loss function.

Notice how the gradient function in the printed output is a Negative Log-Likelihood loss (NLL). This actually reveals that Cross-Entropy loss combines NLL loss under the hood with a log-softmax layer.
Negative Log-Likelihood Loss
The NLL loss function works quite similarly to the Cross-Entropy Loss function. As mentioned earlier in the Cross Entropy section, Cross-Entropy Loss combines a log-softmax layer and NLL loss to obtain the value of the Cross Entropy loss. This means that NLL loss can be used to obtain the Cross Entropy loss value by having the last layer of the neural network be a log-softmax layer instead of a normal softmax layer.

m = nn.LogSoftmax(dim=1)
loss = nn.NLLLoss()
# input is of size N x C = 3 x 5
input = torch.randn(3, 5, requires_grad=True)
# each element in target has to have 0 <= value < C
target = torch.tensor([1, 0, 4])
output = loss(m(input), target)
output.backward()
# 2D loss example (used, for example, with image inputs)
N, C = 5, 4
loss = nn.NLLLoss()
# input is of size N x C x height x width
data = torch.randn(N, 16, 10, 10)
conv = nn.Conv2d(16, C, (3, 3))
m = nn.LogSoftmax(dim=1)
# each element in target has to have 0 <= value < C
target = torch.empty(N, 8, 8, dtype=torch.long).random_(0, C)
output = loss(m(conv(data)), target)
print(output) #tensor(1.4892, grad_fn=<NllLoss2DBackward>)
#credit NLLLoss — PyTorch 1.9.0 documentationBinary Cross Entropy Loss
Binary Cross-Entropy loss is a special class of Cross-Entropy losses used for the special problem of classifying data points into only two classes. Labels for this type of problem are usually binary, and our goal is therefore to push the model to predict a number close to zero for a zero label and a number close to one for a one label. Usually when using BCE loss for binary classification, the output of the neural network is a Sigmoid layer to ensure that the output is either a value close to zero or a value close to one.


import torch.nn as nn
m = nn.Sigmoid()
loss = nn.BCELoss()
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
output = loss(m(input), target)
print(output) #tensor(0.4198, grad_fn=<BinaryCrossEntropyBackward>)Binary Cross Entropy Loss with Logits
I mentioned in the previous section that a Binary Cross Entropy loss is usually output as a sigmoid layer to ensure that output is between 0 and 1. A Binary Cross-Entropy Loss with Logits combines these two layers into just one layer. According to the PyTorch documentation, this is a more numerically stable version as it takes advantage of the log-sum exp trick.
import torch
import torch.nn as nn
target = torch.ones([10, 64], dtype=torch.float32) # 64 classes, batch size = 10
output = torch.full([10, 64], 1.5) # A prediction (logit)
pos_weight = torch.ones([64]) # All weights are equal to 1
criterion = torch.nn.BCEWithLogitsLoss(pos_weight=pos_weight)
loss = criterion(output, target) # -log(sigmoid(1.5))
print(loss) #tensor(0.2014)Bring this project to life
Smooth L1 Loss
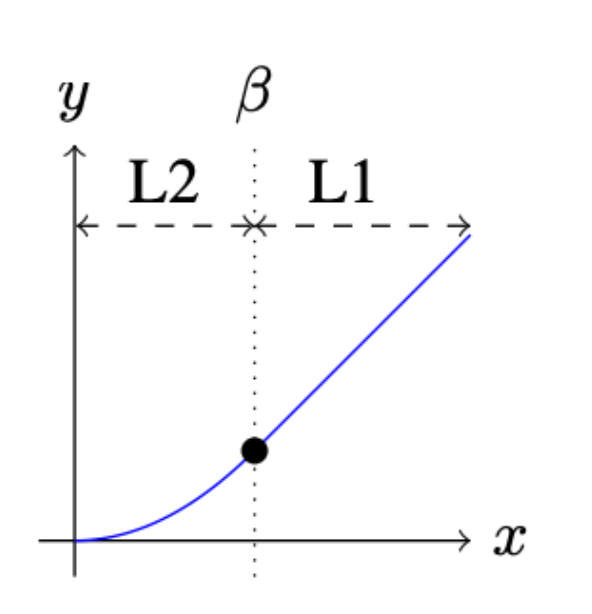
The smooth L1 loss function combines the benefits of MSE loss and MAE loss through a heuristic value beta. This criterion was introduced in the Fast R-CNN paper. When the absolute difference between the ground truth value and the predicted value is below beta, the criterion uses a squared difference, much like MSE loss. The graph of MSE loss is a continuous curve, which means the gradient at each loss value varies and can be derived everywhere. Moreover, as the loss value reduces the gradient diminishes, which is convenient during gradient descent. However for very large loss values the gradient explodes, hence the criterion switching to a Mean Absolute Error, whose gradient is almost constant for every loss value, when the absolute difference becomes larger than beta and the potential gradient explosion is eliminated.
import torch.nn as nn
loss = nn.SmoothL1Loss()
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
output = loss(input, target)
print(output) #tensor(0.7838, grad_fn=<SmoothL1LossBackward>)Hinge Embedding Loss
Hinge Embedding Loss is mostly used in semi-supervised learning tasks to measure the similarity between two inputs. It’s used when there is an input tensor and a label tensor containing values of 1 or -1. It is mostly used in problems involving non-linear embeddings and semi-supervised learning.

import torch
import torch.nn as nn
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
hinge_loss = nn.HingeEmbeddingLoss()
output = hinge_loss(input, target)
output.backward()
print('input: ', input)
print('target: ', target)
print('output: ', output)
#input: tensor([[ 1.4668e+00, 2.9302e-01, -3.5806e-01, 1.8045e-01, #1.1793e+00],
# [-6.9471e-05, 9.4336e-01, 8.8339e-01, -1.1010e+00, #1.5904e+00],
# [-4.7971e-02, -2.7016e-01, 1.5292e+00, -6.0295e-01, #2.3883e+00]],
# requires_grad=True)
#target: tensor([[-0.2386, -1.2860, -0.7707, 1.2827, -0.8612],
# [ 0.6747, 0.1610, 0.5223, -0.8986, 0.8069],
# [ 1.0354, 0.0253, 1.0896, -1.0791, -0.0834]])
#output: tensor(1.2103, grad_fn=<MeanBackward0>)Margin Ranking Loss
Margin Ranking loss belongs to the ranking losses whose main objective, unlike other loss functions, is to measure the relative distance between a set of inputs in a dataset. The margin Ranking loss function takes two inputs and a label containing only 1 or -1. If the label is 1, then it is assumed that the first input should have a higher ranking than the second input and if the label is -1, it is assumed that the second input should have a higher ranking than the first input. This relationship is shown by the equation and code below.

import torch.nn as nn
loss = nn.MarginRankingLoss()
input1 = torch.randn(3, requires_grad=True)
input2 = torch.randn(3, requires_grad=True)
target = torch.randn(3).sign()
output = loss(input1, input2, target)
print('input1: ', input1)
print('input2: ', input2)
print('output: ', output)
#input1: tensor([-1.1109, 0.1187, 0.9441], requires_grad=True)
#input2: tensor([ 0.9284, -0.3707, -0.7504], requires_grad=True)
#output: tensor(0.5648, grad_fn=<MeanBackward0>)Triplet Margin loss
This criterion measures similarity between data points by using triplets of the training data sample. The triplets involved are an anchor sample, a positive sample and a negative sample. The objective is 1) to get the distance between the positive sample and the anchor as minimal as possible, and 2) to get the distance between the anchor and the negative sample to have greater than a margin value plus the distance between the positive sample and the anchor. Usually, the positive sample belongs to the same class as the anchor, but the negative sample does not. Hence, by using this loss function, we aim to use triplet margin loss to predict a high similarity value between the anchor and the positive sample and a low similarity value between the anchor and the negative sample.

import torch.nn as nn
triplet_loss = nn.TripletMarginLoss(margin=1.0, p=2)
anchor = torch.randn(100, 128, requires_grad=True)
positive = torch.randn(100, 128, requires_grad=True)
negative = torch.randn(100, 128, requires_grad=True)
output = triplet_loss(anchor, positive, negative)
print(output) #tensor(1.1151, grad_fn=<MeanBackward0>)Cosine Embedding loss
Cosine Embedding loss measures the loss given inputs x1, x2, and a label tensor y containing values 1 or -1. It is used for measuring the degree to which two inputs are similar or dissimilar.

The criterion measures similarity by computing the cosine distance between the two data points in space. The cosine distance correlates to the angle between the two points which means that the smaller the angle, the closer the inputs and hence the more similar they are.

import torch.nn as nn
loss = nn.CosineEmbeddingLoss()
input1 = torch.randn(3, 6, requires_grad=True)
input2 = torch.randn(3, 6, requires_grad=True)
target = torch.randn(3).sign()
output = loss(input1, input2, target)
print('input1: ', input1)
print('input2: ', input2)
print('output: ', output)
#input1: tensor([[ 1.2969e-01, 1.9397e+00, -1.7762e+00, -1.2793e-01, #-4.7004e-01,
# -1.1736e+00],
# [-3.7807e-02, 4.6385e-03, -9.5373e-01, 8.4614e-01, -1.1113e+00,
# 4.0305e-01],
# [-1.7561e-01, 8.8705e-01, -5.9533e-02, 1.3153e-03, -6.0306e-01,
# 7.9162e-01]], requires_grad=True)
#input2: tensor([[-0.6177, -0.0625, -0.7188, 0.0824, 0.3192, 1.0410],
# [-0.5767, 0.0298, -0.0826, 0.5866, 1.1008, 1.6463],
# [-0.9608, -0.6449, 1.4022, 1.2211, 0.8248, -1.9933]],
# requires_grad=True)
#output: tensor(0.0033, grad_fn=<MeanBackward0>)Kullback-Leibler Divergence loss
Given two distributions, P and Q, Kullback Leibler Divergence (KLD) loss measures how much information is lost when P (assumed to be the true distributions) is replaced with Q. By measuring how much information is lost when we use Q to approximate P, we are able to obtain the similarity between P and Q and hence drive our algorithm to produce a distribution very close to the true distribution, P. The information loss when Q is used to approximate P is not the same when P is used to approximate Q, and thus KL Divergence is not symmetric.

import torch.nn as nn
loss = nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False)
input1 = torch.randn(3, 6, requires_grad=True)
input2 = torch.randn(3, 6, requires_grad=True)
output = loss(input1, input2)
print('output: ', output) #tensor(-0.0284, grad_fn=<KlDivBackward>)Building your own custom loss function
PyTorch provides us with two popular ways to build our own loss function to suit our problem; these are namely using a class implementation and using a function implementation. Let’s see how we can implement both methods starting with the function implementation.
Custom loss with functions
This is easily the simplest way to write your own custom loss function. It’s just as easy as creating a function, passing into it the required inputs and other parameters, performing some operation using PyTorch’s core API or Functional API, and returning a value. Let’s see a demonstration with Custom Mean Square Error.
def custom_mean_square_error(y_predictions, target):
square_difference = torch.square(y_predictions - target)
loss_value = torch.mean(square_difference)
return loss_valueIn the code above, we define a custom loss function to calculate the mean square error given a prediction tensor and a target sensor
y_predictions = torch.randn(3, 5, requires_grad=True);
target = torch.randn(3, 5)
pytorch_loss = nn.MSELoss();
p_loss = pytorch_loss(y_predictions, target)
loss = custom_mean_square_error(y_predictions, target)
print('custom loss: ', loss)
print('pytorch loss: ', p_loss)
#custom loss: tensor(2.3134, grad_fn=<MeanBackward0>)
#pytorch loss: tensor(2.3134, grad_fn=<MseLossBackward>)We can compute the loss using our custom loss function and PyTorch’s MSE loss function to observe that we have obtained the same results.
Custom loss with Python classes
This approach is probably the standard and recommended method of defining custom losses in PyTorch. The loss function is created as a node in the neural network graph by subclassing the nn module. This means that our Custom loss function is a PyTorch layer exactly the same way a convolutional layer is. Let’s see a demonstration of how this works with a custom MSE loss.
class Custom_MSE(nn.Module):
def __init__(self):
super(Custom_MSE, self).__init__();
def forward(self, predictions, target):
square_difference = torch.square(predictions - target)
loss_value = torch.mean(square_difference)
return loss_value
# def __call__(self, predictions, target):
# square_difference = torch.square(y_predictions - target)
# loss_value = torch.mean(square_difference)
# return loss_valueWe can define the actual implementation of the loss inside the ‘forward’ function call or inside ‘__call__’. See the IPython notebook on Gradient to see the custom MSE function used in practice.
Final Thoughts
We have discussed a lot about loss functions available in PyTorch and also taken a deep dive into the inner workings of most of these loss functions. Choosing the right loss function for a particular problem can be an overwhelming task. Hopefully, this tutorial alongside the official PyTorch documentation serves as a guideline when trying to understand which loss function suits your problem well.
Your neural networks can do a lot of different tasks. Whether it’s classifying data, like grouping pictures of animals into cats and dogs, regression tasks, like predicting monthly revenues, or anything else. Every task has a different output and needs a different type of loss function.
The way you configure your loss functions can make or break the performance of your algorithm. By correctly configuring the loss function, you can make sure your model will work how you want it to.
Luckily for us, there are loss functions we can use to make the most of machine learning tasks.
In this article, we’ll talk about popular loss functions in PyTorch, and about building custom loss functions. Once you’re done reading, you should know which one to choose for your project.
Check how you can monitor your PyTorch model training and keep track of all model-building metadata with Neptune + PyTorch integration.
What are the loss functions?
Before we jump into PyTorch specifics, let’s refresh our memory of what loss functions are.
Loss functions are used to gauge the error between the prediction output and the provided target value. A loss function tells us how far the algorithm model is from realizing the expected outcome. The word ‘loss’ means the penalty that the model gets for failing to yield the desired results.
For example, a loss function (let’s call it J) can take the following two parameters:
- Predicted output (y_pred)
- Target value (y)

This function will determine your model’s performance by comparing its predicted output with the expected output. If the deviation between y_pred and y is very large, the loss value will be very high.
If the deviation is small or the values are nearly identical, it’ll output a very low loss value. Therefore, you need to use a loss function that can penalize a model properly when it is training on the provided dataset.
Loss functions change based on the problem statement that your algorithm is trying to solve.
How to add PyTorch loss functions?
PyTorch’s torch.nn module has multiple standard loss functions that you can use in your project.
To add them, you need to first import the libraries:
import torch import torch.nn as nn
Next, define the type of loss you want to use. Here’s how to define the mean absolute error loss function:
loss = nn.L1Loss()
After adding a function, you can use it to accomplish your specific task.
Which loss functions are available in PyTorch?
Broadly speaking, loss functions in PyTorch are divided into two main categories: regression losses and classification losses.
Regression loss functions are used when the model is predicting a continuous value, like the age of a person.
Classification loss functions are used when the model is predicting a discrete value, such as whether an email is spam or not.
Ranking loss functions are used when the model is predicting the relative distances between inputs, such as ranking products according to their relevance on an e-commerce search page.
Now we’ll explore the different types of loss functions in PyTorch, and how to use them:
- Mean Absolute Error Loss
- Mean Squared Error Loss
- Negative Log-Likelihood Loss
- Cross-Entropy Loss
- Hinge Embedding Loss
- Margin Ranking Loss
- Triplet Margin Loss
- Kullback-Leibler divergence
1. PyTorch Mean Absolute Error (L1 Loss Function)
torch.nn.L1Loss
The Mean Absolute Error (MAE), also called L1 Loss, computes the average of the sum of absolute differences between actual values and predicted values.
It checks the size of errors in a set of predicted values, without caring about their positive or negative direction. If the absolute values of the errors are not used, then negative values could cancel out the positive values.
The Pytorch L1 Loss is expressed as:
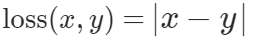
x represents the actual value and y the predicted value.
When could it be used?
- Regression problems, especially when the distribution of the target variable has outliers, such as small or big values that are a great distance from the mean value. It is considered to be more robust to outliers.
Example
import torch import torch.nn as nn input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) mae_loss = nn.L1Loss() output = mae_loss(input, target) output.backward() print('input: ', input) print('target: ', target) print('output: ', output)
###################### OUTPUT ###################### input: tensor([[ 0.2423, 2.0117, -0.0648, -0.0672, -0.1567], [-0.2198, -1.4090, 1.3972, -0.7907, -1.0242], [ 0.6674, -0.2657, -0.9298, 1.0873, 1.6587]], requires_grad=True) target: tensor([[-0.7271, -0.6048, 1.7069, -1.5939, 0.1023], [-0.7733, -0.7241, 0.3062, 0.9830, 0.4515], [-0.4787, 1.3675, -0.7110, 2.0257, -0.9578]]) output: tensor(1.2850, grad_fn=<L1LossBackward>)
2. PyTorch Mean Squared Error Loss Function
torch.nn.MSELoss
The Mean Squared Error (MSE), also called L2 Loss, computes the average of the squared differences between actual values and predicted values.
Pytorch MSE Loss always outputs a positive result, regardless of the sign of actual and predicted values. To enhance the accuracy of the model, you should try to reduce the L2 Loss—a perfect value is 0.0.
The squaring implies that larger mistakes produce even larger errors than smaller ones. If the classifier is off by 100, the error is 10,000. If it’s off by 0.1, the error is 0.01. This punishes the model for making big mistakes and encourages small mistakes.
The Pytorch L2 Loss is expressed as:
x represents the actual value and y the predicted value.
When could it be used?
- MSE is the default loss function for most Pytorch regression problems.
Example
import torch import torch.nn as nn input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) mse_loss = nn.MSELoss() output = mse_loss(input, target) output.backward() print('input: ', input) print('target: ', target) print('output: ', output)
###################### OUTPUT ###################### input: tensor([[ 0.3177, 1.1312, -0.8966, -0.0772, 2.2488], [ 0.2391, 0.1840, -1.2232, 0.2017, 0.9083], [-0.0057, -3.0228, 0.0529, 0.4084, -0.0084]], requires_grad=True) target: tensor([[ 0.2767, 0.0823, 1.0074, 0.6112, -0.1848], [ 2.6384, -1.4199, 1.2608, 1.8084, 0.6511], [ 0.2333, -0.9921, 1.5340, 0.3703, -0.5324]]) output: tensor(2.3280, grad_fn=<MseLossBackward>)
3. PyTorch Negative Log-Likelihood Loss Function
torch.nn.NLLLoss
The Negative Log-Likelihood Loss function (NLL) is applied only on models with the softmax function as an output activation layer. Softmax refers to an activation function that calculates the normalized exponential function of every unit in the layer.
The Softmax function is expressed as:
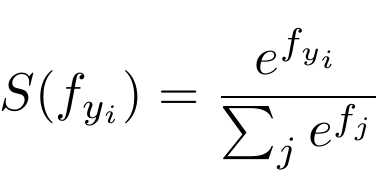
The function takes an input vector of size N, and then modifies the values such that every one of them falls between 0 and 1. Furthermore, it normalizes the output such that the sum of the N values of the vector equals to 1.
NLL uses a negative connotation since the probabilities (or likelihoods) vary between zero and one, and the logarithms of values in this range are negative. In the end, the loss value becomes positive.
In NLL, minimizing the loss function assists us get a better output. The negative log likelihood is retrieved from approximating the maximum likelihood estimation (MLE). This means that we try to maximize the model’s log likelihood, and as a result, minimize the NLL.
In NLL, the model is punished for making the correct prediction with smaller probabilities and encouraged for making the prediction with higher probabilities. The logarithm does the punishment.
NLL does not only care about the prediction being correct but also about the model being certain about the prediction with a high score.
The Pytorch NLL Loss is expressed as:
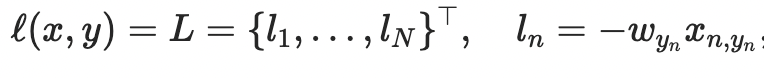
where x is the input, y is the target, w is the weight, and N is the batch size.
When could it be used?
- Multi-class classification problems
Example
import torch import torch.nn as nn input = torch.randn(3, 5, requires_grad=True) target = torch.tensor([1, 0, 4]) m = nn.LogSoftmax(dim=1) nll_loss = nn.NLLLoss() output = nll_loss(m(input), target) output.backward() print('input: ', input) print('target: ', target) print('output: ', output)
input: tensor([[ 1.6430, -1.1819, 0.8667, -0.5352, 0.2585], [ 0.8617, -0.1880, -0.3865, 0.7368, -0.5482], [-0.9189, -0.1265, 1.1291, 0.0155, -2.6702]], requires_grad=True) target: tensor([1, 0, 4]) output: tensor(2.9472, grad_fn=<NllLossBackward>)
4. PyTorch Cross-Entropy Loss Function
torch.nn.CrossEntropyLoss
This loss function computes the difference between two probability distributions for a provided set of occurrences or random variables.
It is used to work out a score that summarizes the average difference between the predicted values and the actual values. To enhance the accuracy of the model, you should try to minimize the score—the cross-entropy score is between 0 and 1, and a perfect value is 0.
Other loss functions, like the squared loss, punish incorrect predictions. Cross-Entropy penalizes greatly for being very confident and wrong.
Unlike the Negative Log-Likelihood Loss, which doesn’t punish based on prediction confidence, Cross-Entropy punishes incorrect but confident predictions, as well as correct but less confident predictions.
The Cross-Entropy function has a wide range of variants, of which the most common type is the Binary Cross-Entropy (BCE). The BCE Loss is mainly used for binary classification models; that is, models having only 2 classes.
The Pytorch Cross-Entropy Loss is expressed as:
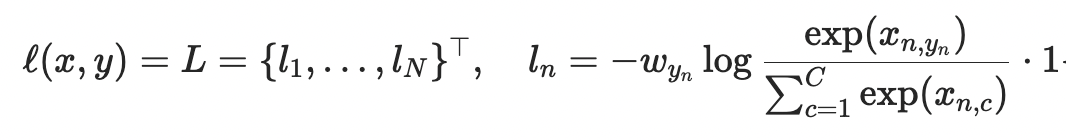
Where x is the input, y is the target, w is the weight, C is the number of classes, and N spans the mini-batch dimension.
When could it be used?
- Binary classification tasks, for which it’s the default loss function in Pytorch.
- Creating confident models—the prediction will be accurate and with a higher probability.
Example
import torch import torch.nn as nn input = torch.randn(3, 5, requires_grad=True) target = torch.empty(3, dtype=torch.long).random_(5) cross_entropy_loss = nn.CrossEntropyLoss() output = cross_entropy_loss(input, target) output.backward() print('input: ', input) print('target: ', target) print('output: ', output)
input: tensor([[ 0.1639, -1.2095, 0.0496, 1.1746, 0.9474], [ 1.0429, 1.3255, -1.2967, 0.2183, 0.3562], [-0.1680, 0.2891, 1.9272, 2.2542, 0.1844]], requires_grad=True) target: tensor([4, 0, 3]) output: tensor(1.0393, grad_fn=<NllLossBackward>)
5. PyTorch Hinge Embedding Loss Function
torch.nn.HingeEmbeddingLoss
The Hinge Embedding Loss is used for computing the loss when there is an input tensor, x, and a labels tensor, y. Target values are between {1, -1}, which makes it good for binary classification tasks.
With the Hinge Loss function, you can give more error whenever a difference exists in the sign between the actual class values and the predicted class values. This motivates examples to have the right sign.
The Hinge Embedding Loss is expressed as:
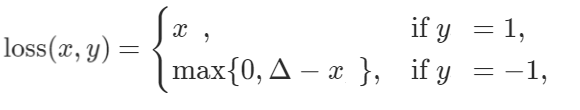
When could it be used?
- Classification problems, especially when determining if two inputs are dissimilar or similar.
- Learning nonlinear embeddings or semi-supervised learning tasks.
Example
import torch import torch.nn as nn input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) hinge_loss = nn.HingeEmbeddingLoss() output = hinge_loss(input, target) output.backward() print('input: ', input) print('target: ', target) print('output: ', output)
###################### OUTPUT ###################### input: tensor([[ 0.1054, -0.4323, -0.0156, 0.8425, 0.1335], [ 1.0882, -0.9221, 1.9434, 1.8930, -1.9206], [ 1.5480, -1.9243, -0.8666, 0.1467, 1.8022]], requires_grad=True) target: tensor([[-1.0748, 0.1622, -0.4852, -0.7273, 0.4342], [-1.0646, -0.7334, 1.9260, -0.6870, -1.5155], [-0.3828, -0.4476, -0.3003, 0.6489, -2.7488]]) output: tensor(1.2183, grad_fn=<MeanBackward0>)
6. PyTorch Margin Ranking Loss Function
torch.nn.MarginRankingLoss
The Margin Ranking Loss computes a criterion to predict the relative distances between inputs. This is different from other loss functions, like MSE or Cross-Entropy, which learn to predict directly from a given set of inputs.
With the Margin Ranking Loss, you can calculate the loss provided there are inputs x1, x2, as well as a label tensor, y (containing 1 or -1).
When y == 1, the first input will be assumed as a larger value. It’ll be ranked higher than the second input. If y == -1, the second input will be ranked higher.
The Pytorch Margin Ranking Loss is expressed as:

When could it be used?
- Ranking problems
Example
import torch import torch.nn as nn input_one = torch.randn(3, requires_grad=True) input_two = torch.randn(3, requires_grad=True) target = torch.randn(3).sign() ranking_loss = nn.MarginRankingLoss() output = ranking_loss(input_one, input_two, target) output.backward() print('input one: ', input_one) print('input two: ', input_two) print('target: ', target) print('output: ', output)
input one: tensor([1.7669, 0.5297, 1.6898], requires_grad=True) input two: tensor([ 0.1008, -0.2517, 0.1402], requires_grad=True) target: tensor([-1., -1., -1.]) output: tensor(1.3324, grad_fn=<MeanBackward0>)
7. PyTorch Triplet Margin Loss Function
torch.nn.TripletMarginLoss
The Triplet Margin Loss computes a criterion for measuring the triplet loss in models. With this loss function, you can calculate the loss provided there are input tensors, x1, x2, x3, as well as margin with a value greater than zero.
A triplet consists of a (anchor), p (positive examples), and n (negative examples).
The Pytorch Triplet Margin Loss is expressed as:

When could it be used?
- Determining the relative similarity existing between samples.
- It is used in content-based retrieval problems
Example
import torch import torch.nn as nn anchor = torch.randn(100, 128, requires_grad=True) positive = torch.randn(100, 128, requires_grad=True) negative = torch.randn(100, 128, requires_grad=True) triplet_margin_loss = nn.TripletMarginLoss(margin=1.0, p=2) output = triplet_margin_loss(anchor, positive, negative) output.backward() print('anchor: ', anchor) print('positive: ', positive) print('negative: ', negative) print('output: ', output)
anchor: tensor([[ 0.6152, -0.2224, 2.2029, ..., -0.6894, 0.1641, 1.7254], [ 1.3034, -1.0999, 0.1705, ..., 0.4506, -0.2095, -0.8019], [-0.1638, -0.2643, 1.5279, ..., -0.3873, 0.9648, -0.2975], ..., [-1.5240, 0.4353, 0.3575, ..., 0.3086, -0.8936, 1.7542], [-1.8443, -2.0940, -0.1264, ..., -0.6701, -1.7227, 0.6539], [-3.3725, -0.4695, -0.2689, ..., 2.6315, -1.3222, -0.9542]], requires_grad=True) positive: tensor([[-0.4267, -0.1484, -0.9081, ..., 0.3615, 0.6648, 0.3271], [-0.0404, 1.2644, -1.0385, ..., -0.1272, 0.8937, 1.9377], [-1.2159, -0.7165, -0.0301, ..., -0.3568, -0.9472, 0.0750], ..., [ 0.2893, 1.7894, -0.0040, ..., 2.0052, -3.3667, 0.5894], [-1.5308, 0.5288, 0.5351, ..., 0.8661, -0.9393, -0.5939], [ 0.0709, -0.4492, -0.9036, ..., 0.2101, -0.8306, -0.6935]], requires_grad=True) negative: tensor([[-1.8089, -1.3162, -1.7045, ..., 1.7220, 1.6008, 0.5585], [-0.4567, 0.3363, -1.2184, ..., -2.3124, 0.7193, 0.2762], [-0.8471, 0.7779, 0.1627, ..., -0.8704, 1.4201, 1.2366], ..., [-1.9165, 1.7768, -1.9975, ..., -0.2091, -0.7073, 2.4570], [-1.7506, 0.4662, 0.9482, ..., 0.0916, -0.2020, -0.5102], [-0.7463, -1.9737, 1.3279, ..., 0.1629, -0.3693, -0.6008]], requires_grad=True) output: tensor(1.0755, grad_fn=<MeanBackward0>)
8. PyTorch Kullback-Leibler Divergence Loss Function
torch.nn.KLDivLoss
The Kullback-Leibler Divergence, shortened to KL Divergence, computes the difference between two probability distributions.
With this loss function, you can compute the amount of lost information (expressed in bits) in case the predicted probability distribution is utilized to estimate the expected target probability distribution.
Its output tells you the proximity of two probability distributions. If the predicted probability distribution is very far from the true probability distribution, it’ll lead to a big loss. If the value of KL Divergence is zero, it implies that the probability distributions are the same.
KL Divergence behaves just like Cross-Entropy Loss, with a key difference in how they handle predicted and actual probability. Cross-Entropy punishes the model according to the confidence of predictions, and KL Divergence doesn’t. KL Divergence only assesses how the probability distribution prediction is different from the distribution of ground truth.
The KL Divergence Loss is expressed as:
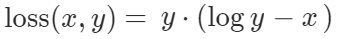
x represents the true label’s probability and y represents the predicted label’s probability.
When could it be used?
- Approximating complex functions
- Multi-class classification tasks
- If you want to make sure that the distribution of predictions is similar to that of training data
Example
import torch import torch.nn as nn input = torch.randn(2, 3, requires_grad=True) target = torch.randn(2, 3) kl_loss = nn.KLDivLoss(reduction = 'batchmean') output = kl_loss(input, target) output.backward() print('input: ', input) print('target: ', target) print('output: ', output)
###################### OUTPUT ###################### input: tensor([[ 1.4676, -1.5014, -1.5201], [ 1.8420, -0.8228, -0.3931]], requires_grad=True) target: tensor([[ 0.0300, -1.7714, 0.8712], [-1.7118, 0.9312, -1.9843]]) output: tensor(0.8774, grad_fn=<DivBackward0>)
How to create a custom loss function in PyTorch?
PyTorch lets you create your own custom loss functions to implement in your projects.
Here’s how you can create your own simple Cross-Entropy Loss function.
Creating custom loss function as a python function
def myCustomLoss(my_outputs, my_labels): my_batch_size = my_outputs.size()[0] my_outputs = F.log_softmax(my_outputs, dim=1) my_outputs = my_outputs[range(my_batch_size), my_labels] return -torch.sum(my_outputs)/number_examples
You can also create other advanced PyTorch custom loss functions.
Creating custom loss function with a class definition
Let’s modify the Dice coefficient, which computes the similarity between two samples, to act as a loss function for binary classification problems:
class DiceLoss(nn.Module): def __init__(self, weight=None, size_average=True): super(DiceLoss, self).__init__() def forward(self, inputs, targets, smooth=1): inputs = F.sigmoid(inputs) inputs = inputs.view(-1) targets = targets.view(-1) intersection = (inputs * targets).sum() dice = (2.*intersection + smooth)/(inputs.sum() + targets.sum() + smooth) return 1 - dice
How to monitor PyTorch loss functions?
It is quite obvious that while training a model, one needs to keep an eye on the loss function values to track the model’s performance. As the loss value keeps decreasing, the model keeps getting better. There are a number of ways that we can do this. Let’s take a look at them.
For this, we will be training a simple Neural Network created in PyTorch which will perform classification on the famous Iris dataset.
Making the required imports for getting the dataset.
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler
Loading the dataset.
iris = load_iris() X = iris['data'] y = iris['target'] names = iris['target_names'] feature_names = iris['feature_names']
Scaling the dataset to have mean=0 and variance=1, gives quick model convergence.
scaler = StandardScaler() X_scaled = scaler.fit_transform(X)
Splitting the dataset into train and test in an 80-20 ratio.
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=2)
Making the necessary imports for our Neural Network and its training.
import torch import torch.nn.functional as F import torch.nn as nn import matplotlib.pyplot as plt import numpy as np plt.style.use('ggplot')
Defining our network.
class PyTorch_NN(nn.Module): def __init__(self, input_dim, output_dim): super(PyTorch_NN, self).__init__() self.input_layer = nn.Linear(input_dim, 128) self.hidden_layer = nn.Linear(128, 64) self.output_layer = nn.Linear(64, output_dim) def forward(self, x): x = F.relu(self.input_layer(x)) x = F.relu(self.hidden_layer(x)) x = F.softmax(self.output_layer(x), dim=1) return x
Defining functions for getting accuracy and training the network.
def get_accuracy(pred_arr,original_arr): pred_arr = pred_arr.detach().numpy() original_arr = original_arr.numpy() final_pred= [] for i in range(len(pred_arr)): final_pred.append(np.argmax(pred_arr[i])) final_pred = np.array(final_pred) count = 0 for i in range(len(original_arr)): if final_pred[i] == original_arr[i]: count+=1 return count/len(final_pred)*100 def train_network(model, optimizer, criterion, X_train, y_train, X_test, y_test, num_epochs): train_loss=[] train_accuracy=[] test_accuracy=[] for epoch in range(num_epochs): output_train = model(X_train) train_accuracy.append(get_accuracy(output_train, y_train)) loss = criterion(output_train, y_train) train_loss.append(loss.item()) optimizer.zero_grad() loss.backward() optimizer.step() with torch.no_grad(): output_test = model(X_test) test_accuracy.append(get_accuracy(output_test, y_test)) if (epoch + 1) % 5 == 0: print(f"Epoch {epoch+1}/{num_epochs}, Train Loss: {loss.item():.4f}, Train Accuracy: {sum(train_accuracy)/len(train_accuracy):.2f}, Test Accuracy: {sum(test_accuracy)/len(test_accuracy):.2f}") return train_loss, train_accuracy, test_accuracy
Creating model, optimizer, and loss function object.
input_dim = 4 output_dim = 3 learning_rate = 0.01 model = PyTorch_NN(input_dim, output_dim) criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
1. Monitoring PyTorch loss in the notebook
Now you must have noticed the print statements in the train_network function to monitor the loss as well as accuracy. This is one way to do it.
X_train = torch.FloatTensor(X_train)
X_test = torch.FloatTensor(X_test)
y_train = torch.LongTensor(y_train)
y_test = torch.LongTensor(y_test)
train_loss, train_accuracy, test_accuracy = train_network(model=model, optimizer=optimizer, criterion=criterion, X_train=X_train, y_train=y_train, X_test=X_test, y_test=y_test, num_epochs=100)
We get an output like this.

If we want we can also plot these values using Matplotlib.
fig, (ax1, ax2, ax3) = plt.subplots(3, figsize=(12, 6), sharex=True) ax1.plot(train_accuracy) ax1.set_ylabel("training accuracy") ax2.plot(train_loss) ax2.set_ylabel("training loss") ax3.plot(test_accuracy) ax3.set_ylabel("test accuracy") ax3.set_xlabel("epochs")
We would see a graph like this indicating the correlation between loss and accuracy.

This method is not bad and does the job. But we must remember that the more complex our problem statement and model get, the more sophisticated monitoring technique it would require.
2. Monitoring PyTorch loss with neptune.ai
A simpler way to monitor your metrics would be to log them in a service like Neptune, and focus on more important tasks, such as building and training the model.
To do this, we just need to follow a couple of small steps.
Note: For the most up-to-date code examples, please refer to the Neptune-PyTorch integration docs.
First, let’s install the required stuff.
pip install neptune-clientNow let’s initialize a Neptune run.
import neptune.new as neptune
run = neptune.init_run()We can also assign config variables such as:
run["config/model"] = type(model).__name__
run["config/criterion"] = type(criterion).__name__
run["config/optimizer"] = type(optimizer).__name__Here’s how it looks in the UI.
Finally, we can log our loss by adding just a couple of lines to our train_network function. Notice the ‘run’ associated lines.
def train_network(model, optimizer, criterion, X_train, y_train, X_test, y_test, num_epochs): train_loss=[] train_accuracy=[] test_accuracy=[] for epoch in range(num_epochs): output_train = model(X_train) acc = get_accuracy(output_train, y_train) train_accuracy.append(acc) run["training/epoch/accuracy"].log(acc) loss = criterion(output_train, y_train) run["training/epoch/loss"].log(loss) train_loss.append(loss.item()) optimizer.zero_grad() loss.backward() optimizer.step() with torch.no_grad(): output_test = model(X_test) test_acc = get_accuracy(output_test, y_test) test_accuracy.append(test_acc) run["test/epoch/accuracy"].log(test_acc) if (epoch + 1) % 5 == 0: print(f"Epoch {epoch+1}/{num_epochs}, Train Loss: {loss.item():.4f}, Train Accuracy: {sum(train_accuracy)/len(train_accuracy):.2f}, Test Accuracy: {sum(test_accuracy)/len(test_accuracy):.2f}") return train_loss, train_accuracy, test_accuracy
Here’s what we get in the dashboard. Absolutely seamless.
You can view this run here in the Neptune app. Needless to say, you can do this with any loss function.
Note: For the most up-to-date code examples, please refer to the Neptune-PyTorch integration docs.
Final thoughts
We went through the most common loss functions in PyTorch. You can choose any function that will fit your project, or create your own custom function.
Hopefully, this article will serve as your quick start guide to using PyTorch loss functions in your machine learning tasks.
If you want to immerse yourself more deeply into the subject or learn about other loss functions, you can visit the PyTorch official documentation.
Mean squared error is computed as the mean of the squared differences between the input and target (predicted and actual) values. To compute the mean squared error in PyTorch, we apply the MSELoss() function provided by the torch.nn module. It creates a criterion that measures the mean squared error. It is also known as the squared L2 norm.
Both the actual and predicted values are torch tensors having the same number of
elements. Both tensors may have any number of dimensions. This function returns
a tensor of a scalar value. It is a type of loss function provided by the torch.nn
module. The loss functions are used to optimize a deep neural network by
minimizing the loss.
Syntax
torch.nn.MSELoss()
Steps
To measure the mean squared error, one could follow the steps given below
-
Import the required library. In all the following examples, the required Python library is torch. Make sure you have already installed it.
import torch
-
Create the input and target tensors and print them.
input = torch.tensor([0.10, 0.20, 0.40, 0.50]) target = torch.tensor([0.09, 0.2, 0.38, 0.52])
-
Create a criterion to measure the mean squared error
mse = nn.MSELoss()
-
Compute the mean squared error (loss) and print it.
output = mse(input, target)
print("MSE loss:", output)
Example 1
In this program, we measure the mean squared error between the input and target
tensors. Both the input and target tensors are 1D torch tensors.
# Import the required libraries
import torch
import torch.nn as nn
# define the input and target tensors
input = torch.tensor([0.10, 0.20, 0.40, 0.50])
target = torch.tensor([0.09, 0.2, 0.38, 0.52])
# print input and target tensors
print("Input Tensor:
", input)
print("Target Tensor:
", target)
# create a criterion to measure the mean squared error
mse = nn.MSELoss()
# compute the loss (mean squared error)
output = mse(input, target)
# output.backward()
print("MSE loss:", output)
Output
Input Tensor: tensor([0.1000, 0.2000, 0.4000, 0.5000]) Target Tensor: tensor([0.0900, 0.2000, 0.3800, 0.5200]) MSE loss: tensor(0.0002)
Notice that the mean squared error is a scalar value.
Example 2
In this program, we measure the mean squared error between the input and target
tensors. Both the input and target tensors are 2D torch tensors.
# Import the required libraries
import torch
import torch.nn as nn
# define the input and target tensors
input = torch.randn(3, 4)
target = torch.randn(3, 4)
# print input and target tensors
print("Input Tensor:
", input)
print("Target Tensor:
", target)
# create a criterion to measure the mean squared error
mse = nn.MSELoss()
# compute the loss (mean squared error)
output = mse(input, target)
# output.backward()
print("MSE loss:", output)
Output
Input Tensor: tensor([[-1.6413, 0.8950, -1.0392, 0.2382], [-0.3868, 0.2483, 0.9811, -0.9260], [-0.0263, -0.0911, -0.6234, 0.6360]]) Target Tensor: tensor([[-1.6068, 0.7233, -0.0925, -0.3140], [-0.4978, 1.3121, -1.4910, -1.4643], [-2.2589, 0.3073, 0.2038, -1.5656]]) MSE loss: tensor(1.6209)
Example 3
In this program, we measure the mean squared error between the input and target tensors. Both the input and target tensors are 2D torch tensors. The input tensor takes the parameter requires_grad=true. So, we also compute the gradients of
this function w.r.t. the input tensor.
# Import the required libraries
import torch
import torch.nn as nn
# define the input and target tensors
input = torch.randn(4, 5, requires_grad = True)
target = torch.randn(4, 5)
# print input and target tensors
print("Input Tensor:
", input)
print("Target Tensor:
", target)
# create a criterion to measure the mean squared error
loss = nn.MSELoss()
# compute the loss (mean squared error)
output = loss(input, target)
output.backward()
print("MSE loss:", output)
print("input.grad:
", input.grad)
Output
Input Tensor: tensor([[ 0.1813, 0.4199, 1.1768, -0.7068, 0.2960], [ 0.7950, 0.0945, -0.0954, -1.0170, -0.1471], [ 1.2264, 1.7573, 0.9099, 1.3720, -0.9087], [-1.0122, -0.8649, -0.7797, -0.7787, 0.9944]], requires_grad=True) Target Tensor: tensor([[-0.6370, -0.8421, 1.2474, 0.4363, -0.1481], [-0.1500, -1.3141, 0.7349, 0.1184, -2.7065], [-1.0776, 1.3530, 0.6939, -1.3191, 0.7406], [ 0.2058, 0.4765, 0.0695, 1.2146, 1.1519]]) MSE loss: tensor(1.9330, grad_fn=<MseLossBackward>) input.grad: tensor([[ 0.0818, 0.1262, -0.0071, -0.1143, 0.0444], [ 0.0945, 0.1409, -0.0830, -0.1135, 0.2559], [ 0.2304, 0.0404, 0.0216, 0.2691, -0.1649], [-0.1218, -0.1341, -0.0849, -0.1993, -0.0158]])
Содержание
- How to measure the mean squared error(squared L2 norm) in PyTorch?
- Syntax
- Steps
- Example 1
- Output
- Example 2
- MSELoss¶
- Mean Squared Error (MSE)В¶
- Module Interface¶
- Functional Interface¶
- PyTorch MSELoss – Detailed Guide
- PyTorch MSELoss
- PyTorch MSELoss code
- PyTorch MSELoss implementation
- PyTorch MSELoss Weighted
- PyTorch MSELoss ignore index
- PyTorch MSELoss batch size
- PyTorch MSELoss with regularization
- torch.nn¶
- Containers¶
- Convolution Layers¶
- Pooling layers¶
- Padding Layers¶
- Non-linear Activations (weighted sum, nonlinearity)¶
- Non-linear Activations (other)¶
- Normalization Layers¶
- Recurrent Layers¶
- Transformer Layers¶
- Linear Layers¶
- Dropout Layers¶
- Sparse Layers¶
- Distance Functions¶
- Loss Functions¶
- Vision Layers¶
- Shuffle Layers¶
- DataParallel Layers (multi-GPU, distributed)¶
- Utilities¶
- Quantized Functions¶
- Lazy Modules Initialization¶
- Tutorials
- Resources
How to measure the mean squared error(squared L2 norm) in PyTorch?
Mean squared error is computed as the mean of the squared differences between the input and target (predicted and actual) values. To compute the mean squared error in PyTorch, we apply the MSELoss() function provided by the torch.nn module. It creates a criterion that measures the mean squared error. It is also known as the squared L2 norm.
Both the actual and predicted values are torch tensors having the same number of elements. Both tensors may have any number of dimensions. This function returns a tensor of a scalar value. It is a type of loss function provided by the torch.nn module. The loss functions are used to optimize a deep neural network by minimizing the loss.
Syntax
Steps
To measure the mean squared error, one could follow the steps given below
Import the required library. In all the following examples, the required Python library is torch. Make sure you have already installed it.
Create the input and target tensors and print them.
Create a criterion to measure the mean squared error
Compute the mean squared error (loss) and print it.
Example 1
In this program, we measure the mean squared error between the input and target tensors. Both the input and target tensors are 1D torch tensors.
Output
Notice that the mean squared error is a scalar value.
Example 2
In this program, we measure the mean squared error between the input and target tensors. Both the input and target tensors are 2D torch tensors.
Источник
MSELoss¶
Creates a criterion that measures the mean squared error (squared L2 norm) between each element in the input x x x and target y y y .
The unreduced (i.e. with reduction set to ‘none’ ) loss can be described as:
The mean operation still operates over all the elements, and divides by n n n .
size_average (bool, optional) – Deprecated (see reduction ). By default, the losses are averaged over each loss element in the batch. Note that for some losses, there are multiple elements per sample. If the field size_average is set to False , the losses are instead summed for each minibatch. Ignored when reduce is False . Default: True
reduce (bool, optional) – Deprecated (see reduction ). By default, the losses are averaged or summed over observations for each minibatch depending on size_average . When reduce is False , returns a loss per batch element instead and ignores size_average . Default: True
reduction (str, optional) – Specifies the reduction to apply to the output: ‘none’ | ‘mean’ | ‘sum’ . ‘none’ : no reduction will be applied, ‘mean’ : the sum of the output will be divided by the number of elements in the output, ‘sum’ : the output will be summed. Note: size_average and reduce are in the process of being deprecated, and in the meantime, specifying either of those two args will override reduction . Default: ‘mean’
Источник
Mean Squared Error (MSE)В¶
Module Interface¶

Where  is a tensor of target values, and
is a tensor of target values, and  is a tensor of predictions.
is a tensor of predictions.
squared¶ ( bool ) – If True returns MSE value, if False returns RMSE value.
kwargs¶ ( Any ) – Additional keyword arguments, see Advanced metric settings for more info.
Initializes internal Module state, shared by both nn.Module and ScriptModule.
Computes mean squared error over state.
Update state with predictions and targets.
preds¶ ( Tensor ) – Predictions from model
target¶ ( Tensor ) – Ground truth values
Functional Interface¶
Computes mean squared error.
preds¶ ( Tensor ) – estimated labels
target¶ ( Tensor ) – ground truth labels
squared¶ ( bool ) – returns RMSE value if set to False
Tensor with MSE
© Copyright Copyright (c) 2020-2022, Lightning-AI et al. Revision bc057d49 .
Источник
PyTorch MSELoss – Detailed Guide

In this Python tutorial, we will learn about PyTorch MSELoss in Python and we will also cover different examples related to it. And, we will cover these topics.
- PyTorch MSELoss
- PyTorch MSELoss code
- PyTorch MSELoss implementation
- PyTorch MSELoss weighted
- PyTorch MSELoss nan
- PyTorch MSELoss batch size
- PyTorch MSELoss with regularization
Table of Contents
PyTorch MSELoss
In this section, we will learn about how PyTorch MSELoss works in python.
Before moving forward we should have a piece of knowledge about MSELoss.
- Mse stands for mean square error which is the most commonly used loss function for regression.
- The loss is the mean supervised data square difference between true and predicted values.
- PyTorch MSELoss is a process that measures the average of the square difference between actual value and predicted value.
Code:
In the following code, we will import the torch library for which we can measure the mean square error between each element.
- nn.MSELoss() is used to measure the mean square error.
- torch.randn(5, 7, requires_grad=True) is used to generate the random numbers.
- loss(inputs, targets) is used to calculate the loss.
- print(output) is used to print the output on the screen.
Output:
After running the above code, we get the following output in which we can see that the mean square error loss is printed on the screen.
PyTorch MSELoss code
In this section, we will learn about the PyTorch MSELoss code in python.
PyTorch MSELoss code is defined as a process to measure the average of the square difference between the actual value and predicted value.
Code:
In the following code, we will import a torch module from which we can calculate the MSELoss.
- torch.randn(2, 4, requires_grad=True) is used to generate the random numbers.
- nn.MSELoss() is used to calculate the mean square error.
- mseloss(inputs, targets) is used to get the output value.
- print(‘input: ‘, inputs) is used to print the input value.
- print(‘target: ‘, targets) is used to print the target value.
- print(‘output: ‘, outputs) is used to print the output value.
Output:
In the following output, we can see that the mean square error loss value is printed on the screen.
PyTorch MSELoss implementation
In this section, we will learn about how to implement the MSELoss in python.
PyTorch MSELoss implementation is done to calculate the average of the square difference between the actual value and the predicted value.
Code:
In the following code, we will import the torch module from which we implement the MSELoss.
- target = torch.randn(3, 5) is used to generate the random numbers for the target variable.
- nn.MSELoss() is used to calculate the mean square loss error.
- mseloss(input, target) is used to calculate the output value.
- print(‘input_value : ‘, input) is used to print the input variables.
- print(‘target_value : ‘, target) is used to print the target variables.
- print(‘output_value : ‘, outputval) is used to print the output value.
Output:
After running the above code, we get the following output where we get the average square difference between the input value. And the target value is printed on the screen.
PyTorch MSELoss Weighted
In this section, we will learn about Pytorch MSELoss weighted in Python.
- PyTorch MSELoss weighted is defined as the process to calculate the mean of the square difference between the input variable and target variable.
- The MSELoss is most commonly used for regression and in linear regression, every target variable is evaluated to be a weighted sum of the input variable.
Code:
In the following code, we will import some libraries from which we can calculate the mean of the square difference between the input variable and target variable.
- torch.from_numpy(input_vals) is used as an input variables.
- torch.from_numpy(target_vals) is used as an target variables.
- print(input_vals) is used to print the input variables.
- print(target_vals) is used to print the target variables.
- weights = torch.randn(4, 5, requires_grad=True) is used to generate the random weights.
- biases = torch.randn(4, requires_grad=True) is used to generate the random biases.
- predictions = model(input_vals) is used to make predictions.
Output:
After running the above code, we get the following output in which we can see that PyTorch MSELoss weighted is printed on the screen.
PyTorch MSELoss ignore index
In this section, we will learn about the PyTorch MSELoss ignore index in python.
Before moving forward we should have a piece of knowledge about ignore index. Ignore index is a parameter that specifies a target variable that is ignored and does not donate to the input gradients.
Syntax:
Parameters:
- size_average is the losses are mean over every loss element in the batch.
- reduce is the losses are mean and summed over observation for each mini-batch depending upon size_average.
- ignore_index is a parameter that specifies a target variable that is ignored and does not donate to input gradients.
- reduction is that specifies the reductions is applied to the output.
PyTorch MSELoss batch size
In this section, we will learn about how to implement PyTorch MSELoss batch size in python.
PyTorch MSELoss batch size is defined as the process in which a number of training examples are used in one iteration.
Code:
In the following code, we will import some libraries from which we can maintain the batch size.
- torch.from_numpy(input_var) is used as an input variables.
- torch.from_numpy(target_var) is used as target variables.
- train_dataset = TensorDataset(input_var, target_var) is used to train dataset.
- batchsize = 3 is used to define size of batch.
- train_dl = DataLoader(train_dataset, batchsize, shuffle=True) is used to load the data.
- nn.Linear(3, 2) is used to create the feed forward network.
- print(model.weight) is used to printthe model weights.
- predictions = model(input_var) is used to generate the predictions.
Output:
In the following output, we break the large dataset into smaller ones with a batch size of 3, and the PyTorch mse bach size values are printed on the screen.
PyTorch MSELoss with regularization
In this section, we will learn about PyTorch MSELoss with regularization in python.
PyTorch MSELoss with regularization is a process that puts sum of the absolute values of all the weights in the model.
Code:
In the following code, we will import the torch library from which we can calculate the PyTorch MSELoss with regularization.
- nn.MSELoss() is used to calculate the mean square error loss.
- input_var = torch.randn(10, 12, requires_grad=True) is used to generate the random input variables.
- target_var = torch.randn(10, 12) is used to generate the random target variables.
- MSE_loss(input_var, target_var) is used to puts the sum of the absolute value of weights.
- print(“Output: “, output_var) is used to print the output variables.
Output:
After running the above code we get the following output in which we can see that the PyTorch MSELoss regularization variable is printed on the screen.
You may like the following PyTorch tutorials:
So, in this tutorial, we discussed PyTorch MSELoss and we have also covered different examples related to its implementation. Here is the list of examples that we have covered.
- PyTorch MSELoss
- PyTorch MSELoss code
- PyTorch MSELoss implementation
- PyTorch MSELoss weighted
- PyTorch MSELoss nan
- PyTorch MSELoss batch size
- PyTorch MSELoss with regularization

Python is one of the most popular languages in the United States of America. I have been working with Python for a long time and I have expertise in working with various libraries on Tkinter, Pandas, NumPy, Turtle, Django, Matplotlib, Tensorflow, Scipy, Scikit-Learn, etc… I have experience in working with various clients in countries like United States, Canada, United Kingdom, Australia, New Zealand, etc. Check out my profile.
Источник
torch.nn¶
These are the basic building blocks for graphs:
A kind of Tensor that is to be considered a module parameter.
A parameter that is not initialized.
A buffer that is not initialized.
Containers¶
Base class for all neural network modules.
A sequential container.
Holds submodules in a list.
Holds submodules in a dictionary.
Holds parameters in a list.
Holds parameters in a dictionary.
Global Hooks For Module
Registers a forward pre-hook common to all modules.
Registers a global forward hook for all the modules
Registers a backward hook common to all the modules.
Registers a backward hook common to all the modules.
Convolution Layers¶
Applies a 1D convolution over an input signal composed of several input planes.
Applies a 2D convolution over an input signal composed of several input planes.
Applies a 3D convolution over an input signal composed of several input planes.
Applies a 1D transposed convolution operator over an input image composed of several input planes.
Applies a 2D transposed convolution operator over an input image composed of several input planes.
Applies a 3D transposed convolution operator over an input image composed of several input planes.
A torch.nn.Conv1d module with lazy initialization of the in_channels argument of the Conv1d that is inferred from the input.size(1) .
A torch.nn.Conv2d module with lazy initialization of the in_channels argument of the Conv2d that is inferred from the input.size(1) .
A torch.nn.Conv3d module with lazy initialization of the in_channels argument of the Conv3d that is inferred from the input.size(1) .
A torch.nn.ConvTranspose1d module with lazy initialization of the in_channels argument of the ConvTranspose1d that is inferred from the input.size(1) .
A torch.nn.ConvTranspose2d module with lazy initialization of the in_channels argument of the ConvTranspose2d that is inferred from the input.size(1) .
A torch.nn.ConvTranspose3d module with lazy initialization of the in_channels argument of the ConvTranspose3d that is inferred from the input.size(1) .
Extracts sliding local blocks from a batched input tensor.
Combines an array of sliding local blocks into a large containing tensor.
Pooling layers¶
Applies a 1D max pooling over an input signal composed of several input planes.
Applies a 2D max pooling over an input signal composed of several input planes.
Applies a 3D max pooling over an input signal composed of several input planes.
Computes a partial inverse of MaxPool1d .
Computes a partial inverse of MaxPool2d .
Computes a partial inverse of MaxPool3d .
Applies a 1D average pooling over an input signal composed of several input planes.
Applies a 2D average pooling over an input signal composed of several input planes.
Applies a 3D average pooling over an input signal composed of several input planes.
Applies a 2D fractional max pooling over an input signal composed of several input planes.
Applies a 3D fractional max pooling over an input signal composed of several input planes.
Applies a 1D power-average pooling over an input signal composed of several input planes.
Applies a 2D power-average pooling over an input signal composed of several input planes.
Applies a 1D adaptive max pooling over an input signal composed of several input planes.
Applies a 2D adaptive max pooling over an input signal composed of several input planes.
Applies a 3D adaptive max pooling over an input signal composed of several input planes.
Applies a 1D adaptive average pooling over an input signal composed of several input planes.
Applies a 2D adaptive average pooling over an input signal composed of several input planes.
Applies a 3D adaptive average pooling over an input signal composed of several input planes.
Padding Layers¶
Pads the input tensor using the reflection of the input boundary.
Pads the input tensor using the reflection of the input boundary.
Pads the input tensor using the reflection of the input boundary.
Pads the input tensor using replication of the input boundary.
Pads the input tensor using replication of the input boundary.
Pads the input tensor using replication of the input boundary.
Pads the input tensor boundaries with zero.
Pads the input tensor boundaries with a constant value.
Pads the input tensor boundaries with a constant value.
Pads the input tensor boundaries with a constant value.
Non-linear Activations (weighted sum, nonlinearity)¶
Applies the Exponential Linear Unit (ELU) function, element-wise, as described in the paper: Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs).
Applies the Hard Shrinkage (Hardshrink) function element-wise.
Applies the Hardsigmoid function element-wise.
Applies the HardTanh function element-wise.
Applies the Hardswish function, element-wise, as described in the paper: Searching for MobileNetV3.
Applies the element-wise function:
Applies the element-wise function:
Allows the model to jointly attend to information from different representation subspaces as described in the paper: Attention Is All You Need.
Applies the element-wise function:
Applies the rectified linear unit function element-wise:
Applies the element-wise function:
Applies the randomized leaky rectified liner unit function, element-wise, as described in the paper:
Applied element-wise, as:
Applies the element-wise function:
Applies the Gaussian Error Linear Units function:
Applies the element-wise function:
Applies the Sigmoid Linear Unit (SiLU) function, element-wise.
Applies the Mish function, element-wise.
Applies the soft shrinkage function elementwise:
Applies the element-wise function:
Applies the Hyperbolic Tangent (Tanh) function element-wise.
Applies the element-wise function:
Thresholds each element of the input Tensor.
Non-linear Activations (other)¶
Applies the Softmin function to an n-dimensional input Tensor rescaling them so that the elements of the n-dimensional output Tensor lie in the range [0, 1] and sum to 1.
Applies the Softmax function to an n-dimensional input Tensor rescaling them so that the elements of the n-dimensional output Tensor lie in the range [0,1] and sum to 1.
Applies SoftMax over features to each spatial location.
Normalization Layers¶
Applies Batch Normalization over a 4D input (a mini-batch of 2D inputs with additional channel dimension) as described in the paper Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift .
Applies Batch Normalization over a 5D input (a mini-batch of 3D inputs with additional channel dimension) as described in the paper Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift .
A torch.nn.BatchNorm1d module with lazy initialization of the num_features argument of the BatchNorm1d that is inferred from the input.size(1) .
A torch.nn.BatchNorm2d module with lazy initialization of the num_features argument of the BatchNorm2d that is inferred from the input.size(1) .
A torch.nn.BatchNorm3d module with lazy initialization of the num_features argument of the BatchNorm3d that is inferred from the input.size(1) .
Applies Group Normalization over a mini-batch of inputs as described in the paper Group Normalization
Applies Batch Normalization over a N-Dimensional input (a mini-batch of [N-2]D inputs with additional channel dimension) as described in the paper Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift .
Applies Instance Normalization over a 2D (unbatched) or 3D (batched) input as described in the paper Instance Normalization: The Missing Ingredient for Fast Stylization.
Applies Instance Normalization over a 4D input (a mini-batch of 2D inputs with additional channel dimension) as described in the paper Instance Normalization: The Missing Ingredient for Fast Stylization.
Applies Instance Normalization over a 5D input (a mini-batch of 3D inputs with additional channel dimension) as described in the paper Instance Normalization: The Missing Ingredient for Fast Stylization.
A torch.nn.InstanceNorm1d module with lazy initialization of the num_features argument of the InstanceNorm1d that is inferred from the input.size(1) .
A torch.nn.InstanceNorm2d module with lazy initialization of the num_features argument of the InstanceNorm2d that is inferred from the input.size(1) .
A torch.nn.InstanceNorm3d module with lazy initialization of the num_features argument of the InstanceNorm3d that is inferred from the input.size(1) .
Applies Layer Normalization over a mini-batch of inputs as described in the paper Layer Normalization
Applies local response normalization over an input signal composed of several input planes, where channels occupy the second dimension.
Recurrent Layers¶
Applies a multi-layer long short-term memory (LSTM) RNN to an input sequence.
Applies a multi-layer gated recurrent unit (GRU) RNN to an input sequence.
An Elman RNN cell with tanh or ReLU non-linearity.
A long short-term memory (LSTM) cell.
A gated recurrent unit (GRU) cell
Transformer Layers¶
A transformer model.
TransformerEncoder is a stack of N encoder layers.
TransformerDecoder is a stack of N decoder layers
TransformerEncoderLayer is made up of self-attn and feedforward network.
TransformerDecoderLayer is made up of self-attn, multi-head-attn and feedforward network.
Linear Layers¶
A placeholder identity operator that is argument-insensitive.
Applies a linear transformation to the incoming data: y = x A T + b y = xA^T + b y = x A T + b
Applies a bilinear transformation to the incoming data: y = x 1 T A x 2 + b y = x_1^T A x_2 + b y = x 1 T A x 2 + b
A torch.nn.Linear module where in_features is inferred.
Dropout Layers¶
During training, randomly zeroes some of the elements of the input tensor with probability p using samples from a Bernoulli distribution.
Applies Alpha Dropout over the input.
Randomly masks out entire channels (a channel is a feature map, e.g.
Sparse Layers¶
A simple lookup table that stores embeddings of a fixed dictionary and size.
Computes sums or means of ‘bags’ of embeddings, without instantiating the intermediate embeddings.
Distance Functions¶
Returns cosine similarity between x 1 x_1 x 1 and x 2 x_2 x 2 , computed along dim .
Computes the pairwise distance between input vectors, or between columns of input matrices.
Loss Functions¶
Creates a criterion that measures the mean absolute error (MAE) between each element in the input x x x and target y y y .
Creates a criterion that measures the mean squared error (squared L2 norm) between each element in the input x x x and target y y y .
This criterion computes the cross entropy loss between input logits and target.
The Connectionist Temporal Classification loss.
The negative log likelihood loss.
Negative log likelihood loss with Poisson distribution of target.
Gaussian negative log likelihood loss.
The Kullback-Leibler divergence loss.
Creates a criterion that measures the Binary Cross Entropy between the target and the input probabilities:
This loss combines a Sigmoid layer and the BCELoss in one single class.
Measures the loss given an input tensor x x x and a labels tensor y y y (containing 1 or -1).
Creates a criterion that optimizes a multi-class multi-classification hinge loss (margin-based loss) between input x x x (a 2D mini-batch Tensor ) and output y y y (which is a 2D Tensor of target class indices).
Creates a criterion that uses a squared term if the absolute element-wise error falls below delta and a delta-scaled L1 term otherwise.
Creates a criterion that uses a squared term if the absolute element-wise error falls below beta and an L1 term otherwise.
Creates a criterion that optimizes a two-class classification logistic loss between input tensor x x x and target tensor y y y (containing 1 or -1).
Creates a criterion that optimizes a multi-label one-versus-all loss based on max-entropy, between input x x x and target y y y of size ( N , C ) (N, C) ( N , C ) .
Creates a criterion that measures the loss given input tensors x 1 x_1 x 1 , x 2 x_2 x 2 and a Tensor label y y y with values 1 or -1.
Creates a criterion that measures the triplet loss given an input tensors x 1 x1 x 1 , x 2 x2 x 2 , x 3 x3 x 3 and a margin with a value greater than 0 0 0 .
Vision Layers¶
Upsamples a given multi-channel 1D (temporal), 2D (spatial) or 3D (volumetric) data.
Applies a 2D nearest neighbor upsampling to an input signal composed of several input channels.
Applies a 2D bilinear upsampling to an input signal composed of several input channels.
Shuffle Layers¶
DataParallel Layers (multi-GPU, distributed)¶
Implements data parallelism at the module level.
Implements distributed data parallelism that is based on torch.distributed package at the module level.
Utilities¶
From the torch.nn.utils module
Clips gradient norm of an iterable of parameters.
Clips gradient of an iterable of parameters at specified value.
Convert parameters to one vector
Convert one vector to the parameters
Abstract base class for creation of new pruning techniques.
Container holding a sequence of pruning methods for iterative pruning.
Utility pruning method that does not prune any units but generates the pruning parametrization with a mask of ones.
Prune (currently unpruned) units in a tensor at random.
Prune (currently unpruned) units in a tensor by zeroing out the ones with the lowest L1-norm.
Prune entire (currently unpruned) channels in a tensor at random.
Prune entire (currently unpruned) channels in a tensor based on their L n -norm.
Applies pruning reparametrization to the tensor corresponding to the parameter called name in module without actually pruning any units.
Prunes tensor corresponding to parameter called name in module by removing the specified amount of (currently unpruned) units selected at random.
Prunes tensor corresponding to parameter called name in module by removing the specified amount of (currently unpruned) units with the lowest L1-norm.
Prunes tensor corresponding to parameter called name in module by removing the specified amount of (currently unpruned) channels along the specified dim selected at random.
Prunes tensor corresponding to parameter called name in module by removing the specified amount of (currently unpruned) channels along the specified dim with the lowest L n -norm.
Globally prunes tensors corresponding to all parameters in parameters by applying the specified pruning_method .
Prunes tensor corresponding to parameter called name in module by applying the pre-computed mask in mask .
Removes the pruning reparameterization from a module and the pruning method from the forward hook.
Check whether module is pruned by looking for forward_pre_hooks in its modules that inherit from the BasePruningMethod .
Applies weight normalization to a parameter in the given module.
Removes the weight normalization reparameterization from a module.
Applies spectral normalization to a parameter in the given module.
Removes the spectral normalization reparameterization from a module.
Given a module class object and args / kwargs, instantiates the module without initializing parameters / buffers.
Parametrizations implemented using the new parametrization functionality in torch.nn.utils.parameterize.register_parametrization() .
Applies an orthogonal or unitary parametrization to a matrix or a batch of matrices.
Applies spectral normalization to a parameter in the given module.
Utility functions to parametrize Tensors on existing Modules. Note that these functions can be used to parametrize a given Parameter or Buffer given a specific function that maps from an input space to the parametrized space. They are not parameterizations that would transform an object into a parameter. See the Parametrizations tutorial for more information on how to implement your own parametrizations.
Adds a parametrization to a tensor in a module.
Removes the parametrizations on a tensor in a module.
Context manager that enables the caching system within parametrizations registered with register_parametrization() .
Returns True if module has an active parametrization.
A sequential container that holds and manages the original or original0 , original1 , .
Utility functions to calls a given Module in a stateless manner.
Performs a functional call on the module by replacing the module parameters and buffers with the provided ones.
Utility functions in other modules
Holds the data and list of batch_sizes of a packed sequence.
Packs a Tensor containing padded sequences of variable length.
Pads a packed batch of variable length sequences.
Pad a list of variable length Tensors with padding_value
Packs a list of variable length Tensors
Flattens a contiguous range of dims into a tensor.
Unflattens a tensor dim expanding it to a desired shape.
Quantized Functions¶
Quantization refers to techniques for performing computations and storing tensors at lower bitwidths than floating point precision. PyTorch supports both per tensor and per channel asymmetric linear quantization. To learn more how to use quantized functions in PyTorch, please refer to the Quantization documentation.
Lazy Modules Initialization¶
A mixin for modules that lazily initialize parameters, also known as «lazy modules.»
© Copyright 2022, PyTorch Contributors.
Access comprehensive developer documentation for PyTorch
Tutorials
Get in-depth tutorials for beginners and advanced developers
Resources
Find development resources and get your questions answered
© Copyright The Linux Foundation. The PyTorch Foundation is a project of The Linux Foundation. For web site terms of use, trademark policy and other policies applicable to The PyTorch Foundation please see www.linuxfoundation.org/policies/. The PyTorch Foundation supports the PyTorch open source project, which has been established as PyTorch Project a Series of LF Projects, LLC. For policies applicable to the PyTorch Project a Series of LF Projects, LLC, please see www.lfprojects.org/policies/.
To analyze traffic and optimize your experience, we serve cookies on this site. By clicking or navigating, you agree to allow our usage of cookies. As the current maintainers of this site, Facebook’s Cookies Policy applies. Learn more, including about available controls: Cookies Policy.
Источник
| title | date | categories | tags | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
How to use PyTorch loss functions |
2021-07-19 |
|
|
Loss functions are an important component of a neural network. Interfacing between the forward and backward pass within a Deep Learning model, they effectively compute how poor a model performs (how big its loss) is. In this article, we’re going to cover how to use a variety of PyTorch loss functions for classification and regression.
After reading this article, you will…
- Understand what the role of a loss function in a neural network is.
- Be familiar with a variety of PyTorch based loss functions for classification and regression.
- Be able to use these loss functions in your Deep Learning models.
Are you ready? Let’s take a look! 😎
[toc]
What is a loss function?
Training a Deep Learning model involves what I call a high-level training process. This process is visualized below. It all starts with a training dataset, which — in the case of classification and regression — contains a set of descriptive variables (features) that jointly are capable of predicting some target variable.
Training the Deep Learning model, which often is a neural network, involves sequentially performing a forward pass and a backward pass, followed by optimization. In the forward pass, the dataset is fed to the network (in a batched fashion). This leads to predictions for the targets, which can then be compared with the true labels. No prediction is perfect, and hence there will be an error value. Using this error value, the error can be computed backwards into the neural network using backpropagation. Subsequently, with an optimizer, the model can be changed slightly in the hope that it performs better next time. By repeating this process over and over again, the model can improve and learn to generate accurate predictions.
Let’s get back to this error value. As the name suggests, it is used to illustrate how poorly the model performs. In Deep Learning jargon, this value is also called a loss value. It is computed by means of a loss function. There are many functions that can be used for this purpose. Choosing one depends on the problem you are solving (i.e. classification or regression), the characteristics of your dataset, and quite frequently on trial and error. In the rest of this article, we’re going to walk through a lot of loss functions available in PyTorch. Let’s take a look!

PyTorch Classification loss function examples
The first category of loss functions that we will take a look at is the one of classification models.
Binary Cross-entropy loss, on Sigmoid (nn.BCELoss) example
Binary cross-entropy loss or BCE Loss compares a target [latex]t[/latex] with a prediction [latex]p[/latex] in a logarithmic and hence exponential fashion. In neural network implementations, the value for [latex]t[/latex] is either 0 or 1, while [latex]p[/latex] can take any value between 0 and 1. This is the formula for binary cross-entropy loss:

When visualizing BCE loss for a target value of 1, you can see that loss increases exponentially when the prediction approaches the opposite — 0, in our case.
This suggests that small deviations are punished albeit lightly, whereas big prediction errors are punished significantly.

This makes binary cross-entropy loss a good candidate for binary classification problems, where a classifier has two classes.
Implementing binary cross-entropy loss with PyTorch is easy. It involves the following steps:
- Ensuring that the output of your neural network is a value between 0 and 1. Recall that the Sigmoid activation function can be used for this purpose. This is why we apply
nn.Sigmoid()in our neural network below. - Ensuring that you use
nn.BCELoss()as your loss function of choice during the training loop.
A full example of using binary cross-entropy loss is given next, using the torchvision.datasets.FakeData dataset:
import os
import torch
from torch import nn
from torchvision.datasets import FakeData
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 3, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1),
nn.Sigmoid()
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare FakeData dataset
dataset = FakeData(size=15000, image_size=(3, 28, 28), num_classes=2, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True, num_workers = 4, pin_memory = True)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.BCELoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# Prepare targets
targets = targets
.type(torch.FloatTensor)
.reshape((targets.shape[0], 1))
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 10 == 0:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Binary Cross-entropy loss, on logits (nn.BCEWithLogitsLoss)
Simple binary cross-entropy loss (represented by nn.BCELoss in PyTorch) computes BCE loss on the predictions [latex]p[/latex] generated in the range [0, 1].
However, it is possible to generate more numerically stable variant of binary cross-entropy loss by combining the Sigmoid and the BCE Loss into one loss function:
This version is more numerically stable than using a plain Sigmoid followed by a BCELoss as, by combining the operations into one layer, we take advantage of the log-sum-exp trick for numerical stability.
PyTorch (n.d.)
This trick is summarized here.
In PyTorch, this is combined into the **nn.BCEWithLogitsLoss** function. The difference between nn.BCEWithLogitsLoss and nn.BCELoss is that BCE with Logits loss adds the Sigmoid function into the loss function. With simple BCE Loss, you will have to add Sigmoid to the neural network, whereas with BCE With Logits Loss you will not.
Here is an example demonstrating nn.BCEWithLogitsLoss using the torchvision.datasets.FakeData dataset:
import os
import torch
from torch import nn
from torchvision.datasets import FakeData
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 3, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1)
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare FakeData dataset
dataset = FakeData(size=15000, image_size=(3, 28, 28), num_classes=2, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True, num_workers = 4, pin_memory = True)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# Prepare targets
targets = targets
.type(torch.FloatTensor)
.reshape((targets.shape[0], 1))
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 10 == 0:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Negative log likelihood loss (nn.NLLLoss)
The previous two loss functions involved binary classification. In other words, they can be used for a classifier that works with two possible targets only — a class 0 and a class 1.
However, many classification problems involve more than two classes. The MNIST dataset (torchvision.datasets.MNIST) is a good example of such a classification problem: in MNIST, there is one class per digit, and hence there are 10 classes.
Negative log likelihood loss (represented in PyTorch as nn.NLLLoss) can be used for this purpose. Sometimes also called categorical cross-entropy, it computes the negative log likelihood of each prediction, and multiplies each log prediction with the true target value.
For example, if we have a three-class classification problem with a sample where the third target class is the true target class, our target vector is as follows: [0 0 1].
Say that our model predicts a 60% likelihood that it’s the second class: [0.3 0.6 0.1]. In that case, our negative log likelihood loss is as follows:
-(0 * log(0.3) + 0 * log(0.6) + 1 * log(0.1)) = 1
Now suppose that after a few more epochs, it successfully starts predicting the third: [0.3 0.2 0.5]. Ensure that loss now becomes 0.30. When it is even more confident (say [0.05 0.05 0.90]), loss is 0.045. In other words, using this loss, you can create a multiclass classifier

Note as well that by consequence, you can also model a binary classification problem this way: it is then a multiclass classification problem with two classes.
As you can see above, the prediction of our classifier should be a pseudo probability distribution over all the target classes. The softmax activation function serves this purpose. Using nn.NLLLoss therefore requires that we use a Softmax activated output in our neural network. nn.LogSoftmax is faster than pure nn.Softmax, however; that’s why we are using nn.LogSoftmax in the nn.NLLLoss example for PyTorch below.
import os
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10),
nn.LogSoftmax(dim = 1)
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare MNIST dataset
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.NLLLoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 500 == 499:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Cross-entropy loss (nn.CrossEntropyLoss)
Recall that nn.NLLLoss requires the application of a Softmax (or LogSoftmax) layer. As with the difference between BCELoss and BCEWithLogitsLoss, combining the Softmax and the NLLLoss into one likely allows you to benefit from computational benefits (PyTorch, n.d.). That’s why you can also choose to use nn.CrossEntropyLoss instead.
This is an example of nn.CrossEntropyLoss with a PyTorch neural network. Note that the final layer does not use any Softmax related loss; this is already built into the loss function!
import os
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare MNIST dataset
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 500 == 499:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Poisson Negative log likelihood loss (nn.PoissonNLLLoss)
Suppose that your multiclass classification targets are drawn from a Poisson distribution (PyTorch, n.d.); that you already know this fact from your exploratory data analysis. You can then use the Poisson Negative log likelihood loss instead of regular nn.NLLLoss. In PyTorch (n.d.), this loss is described as follows:

An example using Poisson Negative log likelihood loss with PyTorch is as follows:
import os
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10),
nn.LogSoftmax(dim = 1)
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare MNIST dataset
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.PoissonNLLLoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 500 == 499:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Gaussian Negative log likelihood loss (nn.GaussianNLLLoss)
Suppose that your multiclass classification targets are drawn from a Gaussian distribution (PyTorch, n.d.). Loss can then be computed differently — by using the Gaussian Negative log likelihood loss. This loss function is represented within PyTorch (n.d.) as nn.GaussianNLLLoss.

This is an example of using Gaussian Negative log likelihood loss with PyTorch.
import os
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10),
nn.LogSoftmax(dim = 1)
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare MNIST dataset
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.GaussianNLLLoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 500 == 499:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Hinge embedding loss (nn.HingeEmbeddingLoss)
In PyTorch, the Hinge Embedding Loss is defined as follows:

It can be used to measure whether two inputs (x and y) are similar, and works only if ys are either 1 or -1.
import os
import torch
from torch import nn
from torchvision.datasets import FakeData
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 3, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1),
nn.Tanh()
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare FakeData dataset
dataset = FakeData(size=15000, image_size=(3, 28, 28), num_classes=2, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True, num_workers = 4, pin_memory = True)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.HingeEmbeddingLoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# For this example, change zero targets into -1
targets[targets == 0] = -1
# Prepare targets
targets = targets
.type(torch.FloatTensor)
.reshape((targets.shape[0], 1))
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 10 == 0:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Two-class soft margin loss (nn.SoftMarginLoss)
The two-class soft margin loss optimizes the following formula (PyTorch, n.d.):

It can be used in binary classification problems as follows:
import os
import torch
from torch import nn
from torchvision.datasets import FakeData
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 3, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1),
nn.Tanh()
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare FakeData dataset
dataset = FakeData(size=15000, image_size=(3, 28, 28), num_classes=2, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=64, shuffle=True, num_workers = 4, pin_memory = True)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.SoftMarginLoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# For this example, change zero targets into -1
targets[targets == 0] = -1
# Prepare targets
targets = targets
.type(torch.FloatTensor)
.reshape((targets.shape[0], 1))
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 10 == 0:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Multi-class margin loss (nn.MultiMarginLoss)
For multiclass classification problems, a multi-class hinge loss can be used represented by nn.MultiMarginLoss (PyTorch, n.d.):

Here is an examplke using nn.MultiMarginLoss with PyTorch for multi-class single-label classification problems:
import os
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10),
nn.LogSoftmax(dim = 1)
)
def forward(self, x):
'''Forward pass'''
return self.layers(x)
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare MNIST dataset
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.MultiMarginLoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 500 == 499:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Multilabel soft margin loss (nn.MultiLabelSoftMarginLoss)
In multilabel classification problems, the neural network learns to predict multiple labels for an input sample. It can also be viewed as solving a tagging problem, as you are essentially assigning multiple tags (instead of just one class) to one input sample.
Multilabel soft margin loss (implemented in PyTorch as nn.MultiLabelSoftMarginLoss) can be used for this purpose. Here is an example with PyTorch. If you look closely, you will see that:
- We use the MNIST dataset for this purpose. By replacing the targets with one of three multilabel Tensors, we are simulating a multilabel classification problem. Note that there is no resemblence whatsoever between targets and inputs, as this is simply an example.
- The final Linear layer outputs a 10-dimensional Tensor, which makes sense since we need 10 logits per sample.
import os
import numpy as np
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
def forward(self, x):
'''
Forward pass
Note that
'''
fp = self.layers(x)
return fp
def draw_label(label):
if label < 5:
return [0, 0, 0, 1, 0, 0, 0, 1, 0, 0]
if label < 8:
return [1, 0, 0, 1, 0, 0, 0, 1, 0, 0]
else:
return [0, 0, 0, 0, 1, 0, 0, 1, 1, 0]
def replace_labels(labels):
''' Randomly replace labels '''
new_labels = []
for label in labels:
new_labels.append(draw_label(label))
return torch.from_numpy(np.array(new_labels))
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare MNIST dataset
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.MultiLabelSoftMarginLoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
targets = replace_labels(targets)
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 500 == 499:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Kullback-Leibler Divergence (KL Divergence) loss (nn.KLDivLoss)
KL Divergence can be used for Variational Autoencoders, multiclass classification and replacing Least Squares regression. Here is an example that uses KL Divergence with PyTorch:
import os
import numpy as np
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
class MLP(nn.Module):
'''
Multilayer Perceptron.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28 * 1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1),
nn.Sigmoid()
)
def forward(self, x):
'''
Forward pass
Note that
'''
fp = self.layers(x)
return fp
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare MNIST dataset
dataset = MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.KLDivLoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get inputs
inputs, targets = data
targets = targets.float()
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 500 == 499:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
PyTorch Regression loss function examples
Let’s now take a look at PyTorch loss functions for regression models.
Mean Absolute Error (MAE) / L1 Loss (nn.L1Loss)
Mean Absolute Error (MAE) is one of the loss functions for regression. This is what it looks like:

As you can see, it simply computes the difference between the input x and the expected value for y, then computing the absolute value (so that the outcome is always positive). It then averages this error.
Below, you will see an example of MAE loss (also called L1 Loss) within PyTorch, using nn.L1Loss and the Boston Housing dataset:
import os
import numpy as np
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
from sklearn.datasets import load_boston
from sklearn.preprocessing import StandardScaler
class BostonDataset(torch.utils.data.Dataset):
'''
Prepare the Boston dataset for regression
'''
def __init__(self, X, y, scale_data=True):
if not torch.is_tensor(X) and not torch.is_tensor(y):
# Apply scaling if necessary
if scale_data:
X = StandardScaler().fit_transform(X)
self.X = torch.from_numpy(X)
self.y = torch.from_numpy(y)
def __len__(self):
return len(self.X)
def __getitem__(self, i):
return self.X[i], self.y[i]
class MLP(nn.Module):
'''
Multilayer Perceptron for regression.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(13, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1)
)
def forward(self, x):
'''
Forward pass
Note that
'''
fp = self.layers(x)
return fp
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Load Boston dataset
X, y = load_boston(return_X_y=True)
# Prepare Boston dataset
dataset = BostonDataset(X, y)
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.L1Loss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get and prepare inputs
inputs, targets = data
inputs, targets = inputs.float(), targets.float()
targets = targets.reshape((targets.shape[0], 1))
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 10 == 0:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Mean Squared Error (MSE) loss (nn.MSELoss)
The Mean Squared Error loss (or nn.MSELoss) essentially performs the same, but then doesn’t compute the absolute value but rather the square of the difference. This also leads to the fact that all negatives are gone (squaring a negative value yields a positive one), but is better when the difference between errors is relatively small. Note that this comes at the cost of being sensitive to outliers.

This is an example of using MSE Loss with PyTorch, which is provided as nn.MSELoss:
import os
import numpy as np
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
from sklearn.datasets import load_boston
from sklearn.preprocessing import StandardScaler
class BostonDataset(torch.utils.data.Dataset):
'''
Prepare the Boston dataset for regression
'''
def __init__(self, X, y, scale_data=True):
if not torch.is_tensor(X) and not torch.is_tensor(y):
# Apply scaling if necessary
if scale_data:
X = StandardScaler().fit_transform(X)
self.X = torch.from_numpy(X)
self.y = torch.from_numpy(y)
def __len__(self):
return len(self.X)
def __getitem__(self, i):
return self.X[i], self.y[i]
class MLP(nn.Module):
'''
Multilayer Perceptron for regression.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(13, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1)
)
def forward(self, x):
'''
Forward pass
Note that
'''
fp = self.layers(x)
return fp
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Load Boston dataset
X, y = load_boston(return_X_y=True)
# Prepare Boston dataset
dataset = BostonDataset(X, y)
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get and prepare inputs
inputs, targets = data
inputs, targets = inputs.float(), targets.float()
targets = targets.reshape((targets.shape[0], 1))
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 10 == 0:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Smooth MAE / L1 Loss (nn.SmoothL1Loss)
Recall from above that in comparison, MAE Loss (L1 Loss) works better when there are many outliers, while MSE Loss works better when there are few outliers and relatively small differences between errors. However, sometimes you want to use a loss function that is precisely in between these two. Smooth MAE Loss can then be used. Being provided as nn.SmoothL1Loss, the error is computed in a squared fashion if the error is smaller than a value for beta (i.e. benefiting from the MSE part). In all other cases, a value similar to the MAE is computed.
The beta parameter is configurable in the nn.SmoothL1Loss(...) initialization.

import os
import numpy as np
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
from sklearn.datasets import load_boston
from sklearn.preprocessing import StandardScaler
class BostonDataset(torch.utils.data.Dataset):
'''
Prepare the Boston dataset for regression
'''
def __init__(self, X, y, scale_data=True):
if not torch.is_tensor(X) and not torch.is_tensor(y):
# Apply scaling if necessary
if scale_data:
X = StandardScaler().fit_transform(X)
self.X = torch.from_numpy(X)
self.y = torch.from_numpy(y)
def __len__(self):
return len(self.X)
def __getitem__(self, i):
return self.X[i], self.y[i]
class MLP(nn.Module):
'''
Multilayer Perceptron for regression.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(13, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1)
)
def forward(self, x):
'''
Forward pass
Note that
'''
fp = self.layers(x)
return fp
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Load Boston dataset
X, y = load_boston(return_X_y=True)
# Prepare Boston dataset
dataset = BostonDataset(X, y)
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.SmoothL1Loss()
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get and prepare inputs
inputs, targets = data
inputs, targets = inputs.float(), targets.float()
targets = targets.reshape((targets.shape[0], 1))
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 10 == 0:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Huber loss (nn.HuberLoss)
Huber loss is another loss function that can be used for regression. Depending on a value for delta, it is computed in a different way — put briefly, when errors are small, the error itself is part of the square, whereas it’s the delta in the case of large errors:

Visually, Huber loss looks as follows given different deltas:

In other words, by tweaking the value for delta, we can adapt the loss function’s sensitivity to outliers. It is therefore also a value that lies somewhere between MSE and MAE loss.
Being available as nn.HuberLoss (with a configurable delta parameter), it can be used in the following way:
import os
import numpy as np
import torch
from torch import nn
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torchvision import transforms
from sklearn.datasets import load_boston
from sklearn.preprocessing import StandardScaler
class BostonDataset(torch.utils.data.Dataset):
'''
Prepare the Boston dataset for regression
'''
def __init__(self, X, y, scale_data=True):
if not torch.is_tensor(X) and not torch.is_tensor(y):
# Apply scaling if necessary
if scale_data:
X = StandardScaler().fit_transform(X)
self.X = torch.from_numpy(X)
self.y = torch.from_numpy(y)
def __len__(self):
return len(self.X)
def __getitem__(self, i):
return self.X[i], self.y[i]
class MLP(nn.Module):
'''
Multilayer Perceptron for regression.
'''
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(13, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1)
)
def forward(self, x):
'''
Forward pass
Note that
'''
fp = self.layers(x)
return fp
if __name__ == '__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Load Boston dataset
X, y = load_boston(return_X_y=True)
# Prepare Boston dataset
dataset = BostonDataset(X, y)
trainloader = torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp = MLP()
# Define the loss function and optimizer
loss_function = nn.HuberLoss(delta=1.0)
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
for epoch in range(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Set current loss value
current_loss = 0.0
# Iterate over the DataLoader for training data
for i, data in enumerate(trainloader, 0):
# Get and prepare inputs
inputs, targets = data
inputs, targets = inputs.float(), targets.float()
targets = targets.reshape((targets.shape[0], 1))
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs = mlp(inputs)
# Compute loss
loss = loss_function(outputs, targets)
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
current_loss += loss.item()
if i % 10 == 0:
print('Loss after mini-batch %5d: %.3f' %
(i + 1, current_loss / 500))
current_loss = 0.0
# Process is complete.
print('Training process has finished.')
Summary
In this article, you have…
- Learned what the role of a loss function in a neural network is.
- Been familiarized with a variety of PyTorch based loss functions for classification and regression.
- Been able to use these loss functions in your Deep Learning models.
I hope that this article was useful to you! If it was, please feel free to drop a comment in the comments section 💬 Feel free to do the same if you have questions or other remarks.
Thank you for reading MachineCurve today and happy engineering! 😎
Sources
PyTorch. (n.d.). BCELoss — PyTorch 1.7.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.BCELoss.html
PyTorch. (n.d.). BCEWithLogitsLoss — PyTorch 1.8.1 documentation. https://pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html
PyTorch. (2019, March 7). Difference between cross-entropy loss or log likelihood loss? PyTorch Forums. https://discuss.pytorch.org/t/difference-between-cross-entropy-loss-or-log-likelihood-loss/38816/2
PyTorch. (n.d.). NLLLoss — PyTorch 1.9.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.NLLLoss.html
PyTorch. (n.d.). CrossEntropyLoss — PyTorch 1.9.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html
PyTorch. (n.d.). SoftMarginLoss — PyTorch 1.9.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.SoftMarginLoss.html
PyTorch. (n.d.). HingeEmbeddingLoss — PyTorch 1.9.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.HingeEmbeddingLoss.html#torch.nn.HingeEmbeddingLoss
PyTorch. (n.d.). MultiMarginLoss — PyTorch 1.9.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.MultiMarginLoss.html
PyTorch. (n.d.). MultiLabelSoftMarginLoss — PyTorch 1.9.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.MultiLabelSoftMarginLoss.html#torch.nn.MultiLabelSoftMarginLoss
PyTorch. (n.d.). MultiLabelMarginLoss — PyTorch 1.9.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.MultiLabelMarginLoss.html#torch.nn.MultiLabelMarginLoss
MachineCurve. (2019, December 22). How to use kullback-leibler divergence (KL divergence) with Keras? https://www.machinecurve.com/index.php/2019/12/21/how-to-use-kullback-leibler-divergence-kl-divergence-with-keras/
PyTorch. (n.d.). HuberLoss — PyTorch 1.9.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.HuberLoss.html#torch.nn.HuberLoss
PyTorch. (n.d.). L1Loss — PyTorch 1.9.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.L1Loss.html#torch.nn.L1Loss
PyTorch. (n.d.). MSELoss — PyTorch 1.9.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.MSELoss.html#torch.nn.MSELoss
PyTorch. (n.d.). SmoothL1Loss — PyTorch 1.9.0 documentation. https://pytorch.org/docs/stable/generated/torch.nn.SmoothL1Loss.html#torch.nn.SmoothL1Loss