Страница 1 из 2
-

Vasulyi
Новичок- Регистрация:
- 30 окт 2021
- Сообщения:
- 15
- Имя пользователя:
- Василий
здравствуйте. купил программатор для ключей key prog 4в1 для Меган2. и при запуске программы TrueCode, которая была на диске у меня высвечивается ошибка Path not found. т.к. я не могу заменить файл в папке system32 «msvbvm60». на нем защита от записи.
как снять эту защиту? помогите пожалуйста.запуск файлового менеджера от имени администротора и изменение параметвов безопасности в свойствах не помог
-
Vasulyi
Новичок- Регистрация:
- 30 окт 2021
- Сообщения:
- 15
- Имя пользователя:
- Василий
— получилось заменить файл. но ошибка не исчезла

-
В пути запуска программы кириллица исключена?
-
Vasulyi
Новичок- Регистрация:
- 30 окт 2021
- Сообщения:
- 15
- Имя пользователя:
- Василий
-
Под хр или 10? Синий ключ был в комплекте?
— Сообщение объединено, 15 янв 2022 —
https://disk.yandex.ru/d/cx14qZuN3Y4GEL
Попробуй этот дистрибутив. Да и напиши из какого города, может кому пригодится— Сообщение объединено, 15 янв 2022 —
Ну и установку делать от имени администратора
-
Vasulyi
Новичок- Регистрация:
- 30 окт 2021
- Сообщения:
- 15
- Имя пользователя:
- Василий
windows 7. синий ключ есть в комплекте, все делал по инструкции и от имени администратора
-
Насколько знаю, 7 не катит
-
Кстати, да. Если речь об этом
то в описании сказано
-
alegiko
Только зашел- Регистрация:
- 18 янв 2020
- Сообщения:
- 1
В ютубе есть видео установки
проще!У меня получилось
-
Vasulyi
Новичок- Регистрация:
- 30 окт 2021
- Сообщения:
- 15
- Имя пользователя:
- Василий
спасибо всем за ответы.
в общем проблема запуска программы решилась, если открывать файл ford code.exe
высвечивается вот такое окно и там уже можно выбрать Ренохотя я переустанавливал программу еще раз, с синим ключом в юсб ноутбука.
и все работает на виндовс7
когда испытаю на машине — отпишу -
Василий, так из какого города? Одноклубникам нет нет да и нужно ключи шить, будешь полезен.
-
Vasulyi
Новичок- Регистрация:
- 30 окт 2021
- Сообщения:
- 15
- Имя пользователя:
- Василий
Харьков.
разве что когда испытаю на своей
я в этом деле новичок -
Если вылетает ошибка при прошивке, закрыть программу, машину кнопкой или пультом закрыть открыть , хлопнуть водительской дверью и пробовать заново
-
Vasulyi
Новичок- Регистрация:
- 30 окт 2021
- Сообщения:
- 15
- Имя пользователя:
- Василий
Всем привет. Получилось запустить и прошить ключ на windows 7. Запускал программу через файл Ford code от имени администратора, далее выбирал Renault. Ключи прошились успешно
-
Эльбрус
Только зашел- Регистрация:
- 26 апр 2022
- Сообщения:
- 10
- Имя пользователя:
- Эльбрус
Всем привет, купил программатор и ключ карту. Установилась нормально на windows XP. При прошивки, как видео с ютуба, вылетает ошибка: Run-time error ‘8002’: Invalid port number. Подскажите кто знает, что дальше делать или это тупик.
-
Сделай скрин. А эта ошибка вылетает до того как ты прочитал количество карт и пин-код или уже когда просит вставить карту? порты не перепутал? «флешку» и приблуду вставлял в те же разъемы что и при установке ПО?
менял разные года >2007 или <2007? Еще важно сделать! закрыть тачку родными пультом или изнутри кнопкой на панели, открыть так же и открыть/закрыть водительскую дверь -
Эльбрус
Только зашел- Регистрация:
- 26 апр 2022
- Сообщения:
- 10
- Имя пользователя:
- Эльбрус
эта ошибка вылетает после того как требует вытащит родную карту. года выпуска менял. Порты не помню, может и перепутал и еще не пробовал манипуляции с дверью и открывание закрывание машины.
Вложения:
-
Эльбрус
Только зашел- Регистрация:
- 26 апр 2022
- Сообщения:
- 10
- Имя пользователя:
- Эльбрус
все попробовал — не помогло. Помогите советом, что куда дальше копать.
-
с начала. снести всё, потом установить (отключив навсегда антивирус), подключить как было при установке и пробовать снова.
Порт правильно назначил? а машину как закрывал, кнопкой или пультом? всё четко делал: закрыл все двери, закрыл машину кнопкой или пультом, затем ими же открыл, хлопнул дверью и начал шить не вставляя карту пока не попросил?



Страница 1 из 2
Поделиться этой страницей
![]()

Код состояния 422 (HTTP 422 Unprocessable Entity) обозначает ошибку со стороны пользователя, а не API. Сервер понимает запрос со стороны клиента и может работать с типом содержимого, который ему предоставили. Однако логическая ошибка делает выполнение невозможным.
Например, документ XML построен синтаксически грамотно, но со стороны семантики в инструкции содержится погрешность.
- вы отправляете полезные данные, которые недействительны в формате JSON;
- вы отправляете заголовки HTTP, такие как Content-Type или Accept, которые указывают значение, отличное от application / json;
- запрос может быть валиден по отношению к JSON, но что-то не так с содержимым. Например, указание API обновить кластер до несуществующего варианта;
- в теле или запросе содержится лишний символ или пробел (в первую очередь стоит проверить пробелы перед заголовком) или напротив, не хватает кавычек/проставлен неправильный тип. Самая актуальная проблема при работе с JSON, при которой может перестать работать весь код.
Проблема ошибка 422 через Ajax Post с использованием Laravel
В ajax этот код может выдаваться как ошибка по умолчанию, когда проверка не выполняется. Либо возвращаться Laravel при запросе, в котором допущена опечатка. Можно попробовать сделать запрос в консоли браузера: он должен выдать JSON с ошибками, возникшими во время проверки запроса. Есть вероятность, что код просто отправляет атрибуты формы не так, как вы запланировали. В любом случае, проблему решать программисту или вебмастеру.
Дополнительная информация
К сожалению, дать универсальный совет по исправлению ошибки 422 Unprocessable Entity непросто. Путь разрешения может сильно отличаться для каждой частной ситуации.
В первую очередь, попробуйте просмотреть свои данные и сделать запрос по вызывающему сомнения участку кода. Нужно убедиться, что вы правильно определили фрагмент данных, в котором содержится причина ошибки.
Если вы все еще не можете найти, где закралась ошибка 422 или вышеописанные способы не помогли выявить описанных причин сбоя функционирования, попробуйте спросить совет у общества веб-разработчиков, показав пример фрагмента вашего кода, чтобы узнать, могут ли другие определить, в чем проблема.
Дальше по теме…
HTTP response status codes indicate whether a specific HTTP request has been successfully completed.
Responses are grouped in five classes:
- Informational responses (
100–199) - Successful responses (
200–299) - Redirection messages (
300–399) - Client error responses (
400–499) - Server error responses (
500–599)
The status codes listed below are defined by RFC 9110.
Note: If you receive a response that is not in this list, it is a non-standard response, possibly custom to the server’s software.
Information responses
100 Continue-
This interim response indicates that the client should continue the request or ignore the response if the request is already finished.
101 Switching Protocols-
This code is sent in response to an
Upgraderequest header from the client and indicates the protocol the server is switching to. 102 Processing(WebDAV)-
This code indicates that the server has received and is processing the request, but no response is available yet.
103 Early Hints-
This status code is primarily intended to be used with the
Linkheader, letting the user agent start preloading resources while the server prepares a response.
Successful responses
200 OK-
The request succeeded. The result meaning of «success» depends on the HTTP method:
GET: The resource has been fetched and transmitted in the message body.HEAD: The representation headers are included in the response without any message body.PUTorPOST: The resource describing the result of the action is transmitted in the message body.TRACE: The message body contains the request message as received by the server.
201 Created-
The request succeeded, and a new resource was created as a result. This is typically the response sent after
POSTrequests, or somePUTrequests. 202 Accepted-
The request has been received but not yet acted upon.
It is noncommittal, since there is no way in HTTP to later send an asynchronous response indicating the outcome of the request.
It is intended for cases where another process or server handles the request, or for batch processing. -
This response code means the returned metadata is not exactly the same as is available from the origin server, but is collected from a local or a third-party copy.
This is mostly used for mirrors or backups of another resource.
Except for that specific case, the200 OKresponse is preferred to this status. 204 No Content-
There is no content to send for this request, but the headers may be useful.
The user agent may update its cached headers for this resource with the new ones. 205 Reset Content-
Tells the user agent to reset the document which sent this request.
206 Partial Content-
This response code is used when the
Rangeheader is sent from the client to request only part of a resource. 207 Multi-Status(WebDAV)-
Conveys information about multiple resources, for situations where multiple status codes might be appropriate.
208 Already Reported(WebDAV)-
Used inside a
<dav:propstat>response element to avoid repeatedly enumerating the internal members of multiple bindings to the same collection. 226 IM Used(HTTP Delta encoding)-
The server has fulfilled a
GETrequest for the resource, and the response is a representation of the result of one or more instance-manipulations applied to the current instance.
Redirection messages
300 Multiple Choices-
The request has more than one possible response. The user agent or user should choose one of them. (There is no standardized way of choosing one of the responses, but HTML links to the possibilities are recommended so the user can pick.)
301 Moved Permanently-
The URL of the requested resource has been changed permanently. The new URL is given in the response.
302 Found-
This response code means that the URI of requested resource has been changed temporarily.
Further changes in the URI might be made in the future. Therefore, this same URI should be used by the client in future requests. 303 See Other-
The server sent this response to direct the client to get the requested resource at another URI with a GET request.
304 Not Modified-
This is used for caching purposes.
It tells the client that the response has not been modified, so the client can continue to use the same cached version of the response. 305 Use Proxy
Deprecated
-
Defined in a previous version of the HTTP specification to indicate that a requested response must be accessed by a proxy.
It has been deprecated due to security concerns regarding in-band configuration of a proxy. 306 unused-
This response code is no longer used; it is just reserved. It was used in a previous version of the HTTP/1.1 specification.
307 Temporary Redirect-
The server sends this response to direct the client to get the requested resource at another URI with same method that was used in the prior request.
This has the same semantics as the302 FoundHTTP response code, with the exception that the user agent must not change the HTTP method used: if aPOSTwas used in the first request, aPOSTmust be used in the second request. 308 Permanent Redirect-
This means that the resource is now permanently located at another URI, specified by the
Location:HTTP Response header.
This has the same semantics as the301 Moved PermanentlyHTTP response code, with the exception that the user agent must not change the HTTP method used: if aPOSTwas used in the first request, aPOSTmust be used in the second request.
Client error responses
400 Bad Request-
The server cannot or will not process the request due to something that is perceived to be a client error (e.g., malformed request syntax, invalid request message framing, or deceptive request routing).
401 Unauthorized-
Although the HTTP standard specifies «unauthorized», semantically this response means «unauthenticated».
That is, the client must authenticate itself to get the requested response. 402 Payment Required
Experimental
-
This response code is reserved for future use.
The initial aim for creating this code was using it for digital payment systems, however this status code is used very rarely and no standard convention exists. 403 Forbidden-
The client does not have access rights to the content; that is, it is unauthorized, so the server is refusing to give the requested resource.
Unlike401 Unauthorized, the client’s identity is known to the server. 404 Not Found-
The server cannot find the requested resource.
In the browser, this means the URL is not recognized.
In an API, this can also mean that the endpoint is valid but the resource itself does not exist.
Servers may also send this response instead of403 Forbiddento hide the existence of a resource from an unauthorized client.
This response code is probably the most well known due to its frequent occurrence on the web. 405 Method Not Allowed-
The request method is known by the server but is not supported by the target resource.
For example, an API may not allow callingDELETEto remove a resource. 406 Not Acceptable-
This response is sent when the web server, after performing server-driven content negotiation, doesn’t find any content that conforms to the criteria given by the user agent.
407 Proxy Authentication Required-
This is similar to
401 Unauthorizedbut authentication is needed to be done by a proxy. 408 Request Timeout-
This response is sent on an idle connection by some servers, even without any previous request by the client.
It means that the server would like to shut down this unused connection.
This response is used much more since some browsers, like Chrome, Firefox 27+, or IE9, use HTTP pre-connection mechanisms to speed up surfing.
Also note that some servers merely shut down the connection without sending this message. 409 Conflict-
This response is sent when a request conflicts with the current state of the server.
410 Gone-
This response is sent when the requested content has been permanently deleted from server, with no forwarding address.
Clients are expected to remove their caches and links to the resource.
The HTTP specification intends this status code to be used for «limited-time, promotional services».
APIs should not feel compelled to indicate resources that have been deleted with this status code. 411 Length Required-
Server rejected the request because the
Content-Lengthheader field is not defined and the server requires it. 412 Precondition Failed-
The client has indicated preconditions in its headers which the server does not meet.
413 Payload Too Large-
Request entity is larger than limits defined by server.
The server might close the connection or return anRetry-Afterheader field. 414 URI Too Long-
The URI requested by the client is longer than the server is willing to interpret.
415 Unsupported Media Type-
The media format of the requested data is not supported by the server, so the server is rejecting the request.
416 Range Not Satisfiable-
The range specified by the
Rangeheader field in the request cannot be fulfilled.
It’s possible that the range is outside the size of the target URI’s data. 417 Expectation Failed-
This response code means the expectation indicated by the
Expectrequest header field cannot be met by the server. 418 I'm a teapot-
The server refuses the attempt to brew coffee with a teapot.
421 Misdirected Request-
The request was directed at a server that is not able to produce a response.
This can be sent by a server that is not configured to produce responses for the combination of scheme and authority that are included in the request URI. 422 Unprocessable Entity(WebDAV)-
The request was well-formed but was unable to be followed due to semantic errors.
423 Locked(WebDAV)-
The resource that is being accessed is locked.
424 Failed Dependency(WebDAV)-
The request failed due to failure of a previous request.
425 Too Early
Experimental
-
Indicates that the server is unwilling to risk processing a request that might be replayed.
426 Upgrade Required-
The server refuses to perform the request using the current protocol but might be willing to do so after the client upgrades to a different protocol.
The server sends anUpgradeheader in a 426 response to indicate the required protocol(s). 428 Precondition Required-
The origin server requires the request to be conditional.
This response is intended to prevent the ‘lost update’ problem, where a clientGETs a resource’s state, modifies it andPUTs it back to the server, when meanwhile a third party has modified the state on the server, leading to a conflict. 429 Too Many Requests-
The user has sent too many requests in a given amount of time («rate limiting»).
-
The server is unwilling to process the request because its header fields are too large.
The request may be resubmitted after reducing the size of the request header fields. 451 Unavailable For Legal Reasons-
The user agent requested a resource that cannot legally be provided, such as a web page censored by a government.
Server error responses
500 Internal Server Error-
The server has encountered a situation it does not know how to handle.
501 Not Implemented-
The request method is not supported by the server and cannot be handled. The only methods that servers are required to support (and therefore that must not return this code) are
GETandHEAD. 502 Bad Gateway-
This error response means that the server, while working as a gateway to get a response needed to handle the request, got an invalid response.
503 Service Unavailable-
The server is not ready to handle the request.
Common causes are a server that is down for maintenance or that is overloaded.
Note that together with this response, a user-friendly page explaining the problem should be sent.
This response should be used for temporary conditions and theRetry-AfterHTTP header should, if possible, contain the estimated time before the recovery of the service.
The webmaster must also take care about the caching-related headers that are sent along with this response, as these temporary condition responses should usually not be cached. 504 Gateway Timeout-
This error response is given when the server is acting as a gateway and cannot get a response in time.
505 HTTP Version Not Supported-
The HTTP version used in the request is not supported by the server.
506 Variant Also Negotiates-
The server has an internal configuration error: the chosen variant resource is configured to engage in transparent content negotiation itself, and is therefore not a proper end point in the negotiation process.
507 Insufficient Storage(WebDAV)-
The method could not be performed on the resource because the server is unable to store the representation needed to successfully complete the request.
508 Loop Detected(WebDAV)-
The server detected an infinite loop while processing the request.
510 Not Extended-
Further extensions to the request are required for the server to fulfill it.
511 Network Authentication Required-
Indicates that the client needs to authenticate to gain network access.
Browser compatibility
BCD tables only load in the browser
See also
Детерминированные исключения и обработка ошибок в «C++ будущего» +21
Программирование, C++
Рекомендация: подборка платных и бесплатных курсов PR-менеджеров — https://katalog-kursov.ru/
Странно, что на Хабре до сих пор не было упомянуто о наделавшем шуму предложении к стандарту C++ под названием «Zero-overhead deterministic exceptions». Исправляю это досадное упущение.
Если вас беспокоит оверхед исключений, или вам приходилось компилировать код без поддержки исключений, или просто интересно, что будет с обработкой ошибок в C++2b (отсылка к недавнему посту), прошу под кат. Вас ждёт выжимка из всего, что сейчас можно найти по теме, и пара опросов.
Разговор далее будет вестись не только про статические исключения, но и про связанные предложения к стандарту, и про всякие другие способы обработки ошибок. Если вы зашли сюда поглядеть на синтаксис, то вот он:
double safe_divide(int x, int y) throws(arithmetic_error) {
if (y == 0) {
throw arithmetic_error::divide_by_zero;
} else {
return as_double(x) / y;
}
}
void caller() noexcept {
try {
cout << safe_divide(5, 2);
} catch (arithmetic_error e) {
cout << e;
}
}Если конкретный тип ошибки неважен/неизвестен, то можно использовать просто throws и catch (std::error e).
Полезно знать
std::optional и std::expected
Пусть мы решили, что ошибка, которая потенциально может возникнуть в функции, недостаточно «фатальная», чтобы бросать из неё исключение. Традиционно информацию об ошибке возвращают с помощью выходного параметра (out parameter). Например, Filesystem TS предлагает ряд подобных функций:
uintmax_t file_size(const path& p, error_code& ec);(Не бросать же исключение из-за того, что файл не найден?) Тем не менее, обработка кодов ошибок громоздкая и подвержена багам. Код ошибки легко забыть проверить. Современные стили кода запрещают использование выходных параметров, вместо них рекомендуется возвращать структуру, содержащую весь результат.
Boost вот уже некоторое время предлагает изящное решение для обработки таких «не-фатальных» ошибок, которые в определённых сценариях могут происходить сотнями в корректной программе:
expected<uintmax_t, error_code> file_size(const path& p);Тип expected похож на variant, но предоставляет удобный интерфейс для работы с «результатом» и «ошибкой». По умолчанию, в expected хранится «результат». Реализация file_size может выглядеть как-то так:
file_info* info = read_file_info(p);
if (info != null) {
uintmax_t size = info->size;
return size; // <==
} else {
error_code error = get_error();
return std::unexpected(error); // <==
}Если причина ошибки нам неинтересна, или ошибка может заключаться только в «отсутствии» результата, то можно использовать optional:
optional<int> parse_int(const std::string& s);
optional<U> get_or_null(map<T, U> m, const T& key);В C++17 из Boost в std попал optional (без поддержки optional<T&>); в C++20, возможно, добавят expected (это только Proposal, спасибо RamzesXI за поправку).
Contracts
Контракты (не путать с концептами) — новый способ наложить ограничения на параметры функции, добавленный в C++20. Добавлены 3 аннотации:
- expects проверяет параметры функции
- ensures проверяет возвращаемое значение функции (принимает его в качестве аргумента)
- assert — цивилизованная замена макросу assert
double unsafe_at(vector<T> v, size_t i) [[expects: i < v.size()]];
double sqrt(double x) [[expects: x >= 0]] [[ensures ret: ret >= 0]];
value fetch_single(key e) {
vector<value> result = fetch(vector<key>{e});
[[assert result.size() == 1]];
return v[0];
}Можно настроить, чтобы нарушение контрактов:
- Вызывало Undefined Behaviour, или
- Проверялось и вызывало пользовательский обработчик, после чего
std::terminate
Продолжать работу программы после нарушения контракта никак нельзя, потому что компиляторы используют гарантии из контрактов для оптимизации кода функции. Если есть малейшее сомнение в том, что контракт выполнится, стоит добавить дополнительную проверку.
std::error_code
Библиотека <system_error>, добавленная в C++11, позволяет унифицировать обработку кодов ошибок в вашей программе. std::error_code состоит из кода ошибки типа int и указателя на объект какого-нибудь класса-наследника std::error_category. Этот объект, по сути, играет роль таблицы виртуальных функций и определяет поведение данного std::error_code.
Чтобы создавать свои std::error_code, вы должны определить свой класс-наследник std::error_category и реализовать виртуальные методы, самым важным из которых является:
virtual std::string message(int c) const = 0;Нужно также создать глобальную переменную вашего std::error_category. Обработка ошибок при помощи error_code + expected выглядит как-то так:
template <typename T>
using result = expected<T, std::error_code>;
my::file_handle open_internal(const std::string& name, int& error);
auto open_file(const std::string& name) -> result<my::file>
{
int raw_error = 0;
my::file_handle maybe_result = open_internal(name, &raw_error);
std::error_code error{raw_error, my::filesystem_error};
if (error) {
return unexpected{error};
} else {
return my::file{maybe_result};
}
}Важно, что в std::error_code значение 0 означает отсутствие ошибки. Если для ваших кодов ошибок это не так, то перед тем, как конвертировать системный код ошибки в std::error_code, надо заменить код 0 на код SUCCESS, и наоборот.
Все системные коды ошибок описаны в errc и system_category. Если на определённом этапе ручной проброс кодов ошибки становится слишком муторным, то всегда можно завернуть код ошибки в исключение std::system_error и выбросить.
Destructive move / Trivially relocatable
Пусть вам нужно создать очередной класс объектов, владеющих какими-нибудь ресурсами. Скорее всего, вы захотите сделать его некопируемым, но перемещаемым (moveable), потому что с unmoveable объектами неудобно работать (до C++17 их нельзя было вернуть из функции).
Но вот беда: перемещённый объект в любом случае нужно удалить. Поэтому необходимо особое состояние «moved-from», то есть «пустого» объекта, который ничего не удаляет. Получается, каждый класс C++ обязан иметь пустое состояние, то есть невозможно создать класс с инвариантом (гарантией) корректности, от конструктора до деструктора. Например, невозможно создать корректный класс open_file файла, который открыт на всём протяжении времени жизни. Странно наблюдать это в одном из немногих языков, активно использующих RAII.
Другая проблема — зануление старых объектов при перемещении добавляет оверхед: заполнение std::vector<std::unique_ptr<T>> может быть до 2 раз медленнее, чем std::vector<T*> из-за кучи занулений старых указателей при перемещении, с последующим удалением пустышек.
Разработчики C++ давно облизываются на Rust, где у перемещённых объектов не вызываются деструкторы. Эта фича называется Destructive move. К сожалению, Proposal Trivially relocatable не предлагает добавить её в C++. Но проблему оверхеда решит.
Класс считается Trivially relocatable, если две операции: перемещения и удаления старого объекта — эквивалентны memcpy из старого объекта в новый. Старый объект при этом не удаляется, авторы называют это «drop it on the floor».
Тип является Trivially relocatable с точки зрения компилятора, если выполняется одно из следующих (рекурсивных) условий:
- Он trivially moveable + trivially destructible (например,
intили POD структура) - Это класс, помеченный атрибутом
[[trivially_relocatable]] - Это класс, все члены которого являются Trivially relocatable
Использовать эту информацию можно с помощью std::uninitialized_relocate, которая исполняет move init + delete обычным способом, или ускоренным, если это возможно. Предлагается пометить как [[trivially_relocatable]] большинство типов стандартной библиотеки, включая std::string, std::vector, std::unique_ptr. Оверхед std::vector<std::unique_ptr<T>> с учётом этого Proposal исчезнет.
Что не так с исключениями сейчас?
Механизм исключений C++ разрабатывался в 1992 году. Были предложены различные варианты реализации. Из них в итоге был выбран механизм таблиц исключений, которые гарантируют отсутствие оверхеда для основного пути выполнения программы. Потому что с самого момента их создания создания предполагалось, что исключения должны выбрасываться очень редко.
Недостатки динамических (то есть обычных) исключений:
- В случае выброшенного исключения оверхед составляет в среднем порядка 10000-100000 циклов CPU, а в худшем случае может достигать порядка миллисекунд
- Увеличение размера бинарного файла на 15-38%
- Несовместимость с программным интерфейсом С
- Неявная поддержка проброса исключений во всех функциях, кроме
noexcept. Исключение может быть выброшено практически в любом месте программы, даже там, где автор функции его не ожидает
Из-за этих недостатков существенно ограничивается область применения исключений. Когда исключения не могут применяться:
- Там, где важен детерминизм, то есть там, где недопустимо, чтобы код «иногда» работал в 10, 100, 1000 раз медленнее, чем обычно
- Когда они не поддерживаются в ABI, например, в микроконтроллерах
- Когда значительная часть кода написана на С
- В компаниях с большим грузом легаси-кода (Google Style Guide, Qt). Если в коде есть хоть одна не exception-safe функция, то по закону подлости через неё рано или поздно прокинут исключение и создадут баг
- В компаниях, набирающих программистов, которые понятия не имеют об exception safety
По опросам, на местах работы 52% (!) разработчиков исключения запрещены корпоративными правилами.
Но исключения — неотъемлемая часть C++! Включая флаг -fno-exceptions, разработчики теряют возможность использовать значительную часть стандартной библиотеки. Это дополнительно подстрекает компании насаждать собственные «стандартные библиотеки» и да, изобретать свой класс строки.
Но и это ещё не конец. Исключения — единственный стандартный способ отменить создание объекта в конструкторе и выдать ошибку. Когда они отключены, появляется такая мерзость, как двухфазная инициализация. Операторы тоже не могут использовать коды ошибок, поэтому они заменяются функциями вроде assign.
Proposal: исключения будущего
Новый механизм передачи исключений
Герб Саттер (Herb Sutter) в P709 описал новый механизм передачи исключений. Идейно, функция возвращает std::expected, однако вместо отдельного дискриминатора типа bool, который вместе с выравниванием будет занимать до 8 байт на стеке, этот бит информации передаётся каким-то более быстрым способом, например, в Carry Flag.
Функции, которые не трогают CF (таких большинство), получат возможность использовать статические исключения бесплатно — и в случае обычного возврата, и в случае проброса исключения! Функции, которые вынуждены будут его сохранять и восстанавливать, получат минимальный оверхед, и это всё равно будет быстрее, чем std::expected и любые обычные коды ошибок.
Выглядят статические исключения следующим образом:
int safe_divide(int i, int j) throws(arithmetic_errc) {
if (j == 0)
throw arithmetic_errc::divide_by_zero;
if (i == INT_MIN && j == -1)
throw arithmetic_errc::integer_divide_overflows;
return i / j;
}
double foo(double i, double j, double k) throws(arithmetic_errc) {
return i + safe_divide(j, k);
}
double bar(int i, double j, double k) {
try {
cout << foo(i, j, k);
} catch (erithmetic_errc e) {
cout << e;
}
}В альтернативной версии предлагается обязать ставить ключевое слово try в том же выражении, что вызов throws функции: try i + safe_divide(j, k). Это сведёт число случаев использования throws функций в коде, не безопасном для исключений, практически к нулю. В любом случае, в отличие от динамических исключений, у IDE будет возможность как-то выделять выражения, бросающие исключения.
То, что выброшенное исключение не сохраняется отдельно, а кладётся прямо на место возвращаемого значения, накладывает ограничения на тип исключения. Во-первых, он должен быть Trivially relocatable. Во-вторых, его размер должен быть не очень большим (но это может быть что-то вроде std::unique_ptr), иначе все функции будут резервировать больше места на стеке.
status_code
Библиотека <system_error2>, разработанная Найл Дуглас (Niall Douglas), будет содержать status_code<T> — «новый, лучший» error_code. Основные отличия от error_code:
status_code— шаблонный тип, который можно использовать для хранения практически любых мыслимых кодов ошибок (вместе с указателем наstatus_code_category), без использования статических исключенийTдолжен быть Trivially relocatable и копируемым (последнее, ИМХО, не должно быть обязательным). При копировании и удалении вызываются виртуальные функции изstatus_code_categorystatus_codeможет хранить не только данные об ошибке, но и дополнительные сведения об успешно завершённой операции- «Виртуальная» функция
code.message()возвращает неstd::string, аstring_ref— довольно тяжёлый тип строки, представляющий собой виртуальный «возможно владеющий»std::string_view. Туда можно запихнутьstring_viewилиstring, илиstd::shared_ptr<string>, или ещё какой-нибудь сумасшедший способ владения строкой. Найл утверждает, что#include <string>сделало бы заголовок<system_error2>непозволительно «тяжёлым»
Далее, вводится errored_status_code<T> — обёртка над status_code<T> со следующим конструктором:
errored_status_code(status_code<T>&& code)
[[expects: code.failure() == true]]
: code_(std::move(code)) {}error
Тип исключения по умолчанию (throws без типа), а также базовый тип исключений, к которому приводятся все остальные (вроде std::exception) — это error. Он определён примерно так:
using error = errored_status_code<intptr_t>;То есть error — это такой «ошибочный» status_code, у которого значение (value) помещается в 1 указатель. Так как механизм status_code_category обеспечивает корректное удаление, перемещение и копирование, то теоретически в error можно сохранить любую структуру данных. На практике это будет один из следующих вариантов:
- Целые числа (int)
std::exception_handle, то есть указатель на выброшенное динамическое исключениеstatus_code_ptr, то естьunique_ptrна произвольныйstatus_code<T>.
Проблема в том, что случае 3 не планируется дать возможность привести error обратно к status_code<T>. Единственное, что можно сделать — получить message() упакованного status_code<T>. Чтобы иметь возможность достать обратно завёрнутое в error значение, надо выбросить его как динамическое исключение (!), потом поймать и завернуть в error. А вообще, Найл считает, что в error должны храниться только коды ошибок и строковые сообщения, чего достаточно для любой программы.
Чтобы различать разные виды ошибок, предлагается использовать «виртуальный» оператор сравнения:
try {
open_file(name);
} catch (std::error e) {
if (e == filesystem_error::already_exists) {
return;
} else {
throw my_exception("Unknown filesystem error, unable to continue");
}
}Использовать несколько catch-блоков или dynamic_cast для выбора типа исключения не получится!
Взаимодействие с динамическими исключениями
Функция может иметь одну из следующих спецификаций:
noexcept: не бросает никаких исключенийthrows(E): бросает только статические исключения- (ничего): бросает только динамические исключения
throws подразумевает noexcept. Если динамическое исключение выбрасывается из «статической» функции, то оно заворачивается в error. Если статическое исключение выбрасывается из «динамической» функции, то оно заворачивается в исключение status_error. Пример:
void foo() throws(arithmetic_errc) {
throw erithmetic_errc::divide_by_zero;
}
void bar() throws {
// Код arithmetic_errc помещается в intptr_t
// Допустимо неявное приведение к error
foo();
}
void baz() {
// error заворачивается в исключение status_error
bar();
}
void qux() throws {
// error достаётся из исключения status_error
baz();
}Исключения в C?!
Предложение предусматривает добавление исключений в один из будущих стандартов C, причём эти исключения будут ABI-совместимы со статическими исключениями C++. Структуру, аналогичную std::expected<T, U>, пользователь должен будет объявлять самостоятельно, хотя избыточность можно убрать с помощью макросов. Синтаксис состоит из (для простоты будем так считать) ключевых слов fails, failure, catch.
int invert(int x) fails(float) {
if (x != 0) return 1 / x;
else return failure(2.0f);
}
struct expected_int_float {
union { int value; float error; };
_Bool failed;
};
void caller() {
expected_int_float result = catch(invert(5));
if (result.failed) {
print_error(result.error);
return;
}
print_success(result.value);
}При этом в C++ тоже можно будет вызывать fails функции из C, объявляя их в блоках extern C. Таким образом, в C++ будет целая плеяда ключевых слов по работе с исключениями:
throw()— удалено в C++20noexcept— спецификатор функции, функция не бросает динамические исключенияnoexcept(expression)— спецификатор функции, функция не бросает динамические исключения при условииnoexcept(expression)— бросает ли выражение динамические исключения?throws(E)— спецификатор функции, функция бросает статические исключенияthrows=throws(std::error)fails(E)— функция, импортированная из C, бросает статические исключения
Итак, в C++ завезли (точнее, завезут) тележку новых инструментов для обработки ошибок. Далее возникает логичный вопрос:
Когда что использовать?
Направление в целом
Ошибки разделяются на несколько уровней:
- Ошибки программиста. Обрабатываются с помощью контрактов. Приводят к сбору логов и завершению работы программы в соответствие с концепцией fail-fast. Примеры: нулевой указатель (когда это недопустимо); деление на ноль; ошибки выделения памяти, не предусмотренные программистом.
- Непоправимые ошибки, предусмотренные программистом. Выбрасываются в миллион раз реже, чем обычный возврат из функции, что делает использование для них динамических исключений оправданным. Обычно в таких случаях требуется перезапустить целую подсистему программы или выдать ошибку при выполнении операции. Примеры: внезапно потеряна связь с базой данных; ошибки выделения памяти, предусмотренные программистом.
- Поправимые (recoverable) ошибки, когда что-то помешало функции выполнить свою задачу, но вызывающая функция, возможно, знает, что с этим делать. Обрабатываются с помощью статических исключений. Примеры: работа с файловой системой; другие ошибки ввода-вывода (IO); некорректные пользовательские данные;
vector::at(). - Функция успешно завершила свою задачу, пусть и с неожиданным результатом. Возвращаются
std::optional,std::expected,std::variant. Примеры:stoi();vector::find();map::insert.
В стандартной библиотеке надёжнее всего будет полностью отказаться от использования динамических исключений, чтобы сделать компиляцию «без исключений» легальной.
errno
Функции, использующие errno для быстрой и минималистичной работы с кодами ошибок C и C++, должны быть заменены на fails(int) и throws(std::errc), соответственно. Некоторое время старый и новый варианты функций стандартной библиотеки будут сосуществовать, потом старые объявят устаревшими.
Out of memory
Ошибки выделения памяти обрабатывает глобальный хук new_handler, который может:
- Устранить нехватку памяти и продолжить выполнение
- Выбросить исключение
- Аварийно завершить программу
Сейчас по умолчанию выбрасывается std::bad_alloc. Предлагается же по умолчанию вызывать std::terminate(). Если вам нужно старое поведение, замените обработчик на тот, который вам нужен, в начале main().
Все существующие функции стандартной библиотеки станут noexcept и будут крашить программу при std::bad_alloc. В то же время, будут добавлены новые API вроде vector::try_push_back, которые допускают ошибки выделения памяти.
logic_error
Исключения std::logic_error, std::domain_error, std::invalid_argument, std::length_error, std::out_of_range, std::future_error сообщают о нарушении предусловия функции. В новой модели ошибок вместо них должны использоваться контракты. Перечисленные типы исключений не будут объявлены устаревшими, но почти все случаи их использования в стандартной библиотеке будут заменены на [[expects: …]].
Текущее состояние Proposal
Proposal сейчас находится в состоянии черновика. Он уже довольно сильно поменялся, и ещё может сильно измениться. Некоторые наработки не успели опубликовать, так что предлагаемый API <system_error2> не совсем актуален.
Предложение описывается в 3 документах:
- P709 — первоначальный документ от Герба Саттера
- P1095 — детерминированные исключения в видении Найла Дугласа, некоторые моменты изменены, добавлена совместимость с языком C
- P1028 — API из тестовой реализации
std::error
На настоящий момент не существует компилятора, который поддерживает статические исключения. Соответственно, сделать их бенчмарки пока невозможно.
При наилучшем раскладе детерминированные исключения будут готовы и попадут в C++23. Если не успеют, то, вероятно, попадут в C++26, так как комитет стандартизации, в целом, заинтересован темой.
Заключение
Многие детали предлагаемого подхода к обработке исключений я опустил или умышленно упростил, зато прошёлся по большинству тем, требующихся для понимания статических исключений. Если возникли дополнительные вопросы, то задайте их в комментариях или обратитесь к документам по ссылкам выше. Любые поправки приветствуются.
И конечно, обещанные опросы ^^
REST API использует строку состояния в HTTP ответе (статус ответа), чтобы информировать Клиентов о результате запроса.
Вообще HTTP определяет 40 стандартных кодов состояния (статусов ответа), которые делятся на пять категорий. Ниже выделены только те коды состояния, которые часто используются в REST API.
| Категория | Описание |
|---|---|
| 1xx: Информация | В этот класс содержит заголовки информирующие о процессе передачи. Это обычно предварительный ответ, состоящий только из Status-Line и опциональных заголовков, и завершается пустой строкой. Нет обязательных заголовков. Серверы НЕ ДОЛЖНЫ посылать 1xx ответы HTTP/1.0 клиентам. |
| 2xx: Успех | Этот класс кодов состояния указывает, что запрос клиента был успешно получен, понят, и принят. |
| 3xx: Перенаправление | Коды этого класса сообщают клиенту, что для успешного выполнения операции необходимо сделать другой запрос, как правило, по другому URI. Из данного класса пять кодов 301, 302, 303, 305 и 307 относятся непосредственно к перенаправлениям. |
| 4xx: Ошибка клиента | Класс кодов 4xx предназначен для указания ошибок со стороны клиента. |
| 5xx: Ошибка сервера | Коды ответов, начинающиеся с «5» указывают на случаи, когда сервер знает, что произошла ошибка или он не может обработать запрос. |
Коды состояний в REST
Звездочкой * помечены популярные (часто используемые) коды ответов.
200 * (OK)
Запрос выполнен успешно. Информация, возвращаемая с ответом зависит от метода, используемого в запросе, например при:
- GET Получен объект, соответствующий запрошенному ресурсу.
- HEAD Получены поля заголовков, соответствующие запрошенному ресурсу, тело ответа пустое.
- POST Запрошенное действие выполнено.
201 * (Created — Создано)
REST API отвечает кодом состояния 201 при каждом создании ресурса в коллекции. Также могут быть случаи, когда новый ресурс создается в результате какого-либо действия контроллера, и в этом случае 201 также будет подходящем ответом.
Ссылка (URL) на новый ресурс может быть в теле ответа или в поле заголовка ответа Location.
Сервер должен создать ресурс перед тем как вернуть 201 статус. Если это невозможно сделать сразу, тогда сервер должен ответить кодом 202 (Accepted).
202 (Accepted — Принято)
Ответ 202 обычно используется для действий, которые занимают много времени для обработки и не могут быть выполнены сразу. Это означает, что запрос принят к обработке, но обработка не завершена.
Его цель состоит в том, чтобы позволить серверу принять запрос на какой-либо другой процесс (возможно, пакетный процесс, который выполняется только один раз в день), не требуя, чтобы соединение агента пользователя с сервером сохранялось до тех пор, пока процесс не будет завершен.
Сущность, возвращаемая с этим ответом, должна содержать указание на текущее состояние запроса и указатель на монитор состояния (расположение очереди заданий) или некоторую оценку того, когда пользователь может ожидать выполнения запроса.
203 (Non-Authoritative Information — Неавторитетная информация)
Предоставленная информация взята не из оригинального источника (а, например, из кэша, который мог устареть, или из резервной копии, которая могла потерять актуальность). Этот факт отражен в заголовке ответа и подтверждается этим кодом. Предоставленная информация может совпадать, а может и не совпадать с оригинальными данными.
204 * (No Content — Нет контента)
Код состояния 204 обычно отправляется в ответ на запрос PUT, POST или DELETE, когда REST API отказывается отправлять обратно любое сообщение о состоянии проделанной работы.
API может также отправить 204 статус в ответ на GET запрос, чтобы указать, что запрошенный ресурс существует, но не имеет данных для добавления их в тело ответа.
Ответ 204 не должен содержать тело сообщения и, таким образом, всегда завершается первой пустой строкой после полей заголовка.
205 — (Reset Content — Сброшенное содержимое)
Сервер успешно обработал запрос и обязывает клиента сбросить введенные пользователем данные. В ответе не должно передаваться никаких данных (в теле ответа). Обычно применяется для возврата в начальное состояние формы ввода данных на клиенте.
206 — (Partial Content — Частичное содержимое)
Сервер выполнил часть GET запроса ресурса. Запрос ДОЛЖЕН был содержать поле заголовка Range (секция 14.35), который указывает на желаемый диапазон и МОГ содержать поле заголовка If-Range (секция 14.27), который делает запрос условным.
Запрос ДОЛЖЕН содержать следующие поля заголовка:
- Либо поле Content-Range (секция 14.16), который показывает диапазон, включённый в этот запрос, либо Content-Type со значением multipart/byteranges, включающими в себя поля Content-Range для каждой части. Если в заголовке запроса есть поле Content-Length, его значение ДОЛЖНО совпадать с фактическим количеством октетов, переданных в теле сообщения.
- Date
- ETag и/или Content-Location, если ранее был получен ответ 200 на такой же запрос.
- Expires, Cache-Control, и/или Vary, если значение поля изменилось с момента отправления последнего такого же запроса
Если ответ 206 — это результат выполнения условного запроса, который использовал строгий кэш-валидатор (подробнее в секции 13.3.3), в ответ НЕ СЛЕДУЕТ включать какие-либо другие заголовки сущности. Если такой ответ — результат выполнения запроса If-Range, который использовал «слабый» валидатор, то ответ НЕ ДОЛЖЕН содержать другие заголовки сущности; это предотвращает несоответствие между закэшированными телами сущностей и обновлёнными заголовками. В противном случае ответ ДОЛЖЕН содержать все заголовки сущностей, которые вернули статус 200 (OK) на тот же запрос.
Кэш НЕ ДОЛЖЕН объединять ответ 206 с другими ранее закэшированными данными, если поле ETag или Last-Modified в точности не совпадают (подробнее в секции 16.5.4)
Кэш, который не поддерживает заголовки Range и Content-Range НЕ ДОЛЖЕН кэшировать ответы 206 (Partial).
300 — (Multiple Choices — Несколько вариантов)
По указанному URI существует несколько вариантов предоставления ресурса по типу MIME, по языку или по другим характеристикам. Сервер передаёт с сообщением список альтернатив, давая возможность сделать выбор клиенту автоматически или пользователю.
Если это не запрос HEAD, ответ ДОЛЖЕН включать объект, содержащий список характеристик и адресов, из которого пользователь или агент пользователя может выбрать один наиболее подходящий. Формат объекта определяется по типу данных приведённых в Content-Type поля заголовка. В зависимости от формата и возможностей агента пользователя, выбор наиболее подходящего варианта может выполняться автоматически. Однако эта спецификация не определяет никакого стандарта для автоматического выбора.
Если у сервера есть предпочтительный выбор представления, он ДОЛЖЕН включить конкретный URI для этого представления в поле Location; агент пользователя МОЖЕТ использовать заголовок Location для автоматического перенаправления к предложенному ресурсу. Этот запрос может быть закэширован, если явно не было указано иного.
301 (Moved Permanently — Перемещено навсегда)
Код перенаправления. Указывает, что модель ресурсов REST API была сильно изменена и теперь имеет новый URL. Rest API должен указать новый URI в заголовке ответа Location, и все будущие запросы должны быть направлены на указанный URI.
Вы вряд ли будете использовать этот код ответа в своем API, так как вы всегда можете использовать версию API для нового API, сохраняя при этом старый.
302 (Found — Найдено)
Является распространенным способом выполнить перенаправление на другой URL. HTTP-ответ с этим кодом должен дополнительно предоставит URL-адрес куда перенаправлять в поле заголовка Location. Агенту пользователя (например, браузеру) предлагается в ответе с этим кодом сделать второй запрос на новый URL.
Многие браузеры реализовали этот код таким образом, что нарушили стандарт. Они начали изменять Тип исходного запроса, например с POST на GET. Коды состояния 303 и 307 были добавлены для серверов, которые хотят однозначно определить, какая реакция ожидается от клиента.
303 (See Other — Смотрите другое)
Ответ 303 указывает, что ресурс контроллера завершил свою работу, но вместо отправки нежелательного тела ответа он отправляет клиенту URI ресурса. Это может быть URI временного сообщения о состоянии ресурса или URI для уже существующего постоянного ресурса.
Код состояния 303 позволяет REST API указать ссылку на ресурс, не заставляя клиента загружать ответ. Вместо этого клиент может отправить GET запрос на URL указанный в заголовке Location.
Ответ 303 не должен кэшироваться, но ответ на второй (перенаправленный) запрос может быть кэшируемым.
304 * (Not Modified — Не изменен)
Этот код состояния похож на 204 (Нет контента), так как тело ответа должно быть пустым. Ключевое различие состоит в том, что 204 используется, когда нет ничего для отправки в теле, тогда как 304 используется, когда ресурс не был изменен с версии, указанной заголовками запроса If-Modified-Since или If-None-Match.
В таком случае нет необходимости повторно передавать ресурс, так как у клиента все еще есть ранее загруженная копия.
Все это экономит ресурсы клиента и сервера, так как только заголовки должны быть отправлены и приняты, и серверу нет необходимости генерировать контент снова, а клиенту его получать.
305 — (Use Proxy — Используйте прокси)
Доступ к запрошенному ресурсу ДОЛЖЕН быть осуществлен через прокси-сервер, указанный в поле Location. Поле Location предоставляет URI прокси. Ожидается, что получатель повторит этот запрос с помощью прокси. Ответ 305 может генерироваться ТОЛЬКО серверами-источниками.
Заметьте: в спецификации RFC 2068 однозначно не сказано, что ответ 305 предназначен для перенаправления единственного запроса, и что он должен генерироваться только сервером-источником. Упущение этих ограничений вызвало ряд значительных последствий для безопасности.
Многие HTTP клиенты (такие, как Mozilla и Internet Explorer) обрабатывают этот статус некорректно прежде всего из соображений безопасности.
307 (Temporary Redirect — Временный редирект)
Ответ 307 указывает, что rest API не будет обрабатывать запрос клиента. Вместо этого клиент должен повторно отправить запрос на URL, указанный в заголовке Location. Однако в будущих запросах клиент по-прежнему должен использоваться исходный URL.
Rest API может использовать этот код состояния для назначения временного URL запрашиваемому ресурсу.
Если метод запроса не HEAD, тело ответа должно содержать короткую заметку с гиперссылкой на новый URL. Если код 307 был получен в ответ на запрос, отличный от GET или HEAD, Клиент не должен автоматически перенаправлять запрос, если он не может быть подтвержден Клиентом, так как это может изменить условия, при которых был создан запрос.
308 — (Permanent Redirect — Постоянное перенаправление) (experimental)
Нужно повторить запрос на другой адрес без изменения применяемого метода.
Этот и все последующие запросы нужно повторить на другой URI. 307 и 308 (как предложено) Схож в поведении с 302 и 301, но не требуют замены HTTP метода. Таким образом, например, отправку формы на «постоянно перенаправленный» ресурс можно продолжать без проблем.
400 * (Bad Request — Плохой запрос)
Это общий статус ошибки на стороне Клиента. Используется, когда никакой другой код ошибки 4xx не уместен. Ошибки могут быть как неправильный синтаксис запроса, неверные параметры запроса, запросы вводящие в заблуждение или маршрутизатор и т.д.
Клиент не должен повторять точно такой же запрос.
401 * (Unauthorized — Неавторизован)
401 сообщение об ошибке указывает, что клиент пытается работать с закрытым ресурсом без предоставления данных авторизации. Возможно, он предоставил неправильные учетные данные или вообще ничего. Ответ должен включать поле заголовка WWW-Authenticate, содержащего описание проблемы.
Клиент может повторить запрос указав в заголовке подходящее поле авторизации. Если это уже было сделано, то в ответе 401 будет указано, что авторизация для указанных учетных данных не работает. Если в ответе 401 содержится та же проблема, что и в предыдущем ответе, и Клиент уже предпринял хотя бы одну попытку проверки подлинности, то пользователю Клиента следует представить данные полученные в ответе, владельцу сайта, так как они могут помочь в диагностике проблемы.
402 — (Payment Required — Требуется оплата)
Этот код зарезервирован для использования в будущем.
Предполагается использовать в будущем. В настоящий момент не используется. Этот код предусмотрен для платных пользовательских сервисов, а не для хостинговых компаний. Имеется в виду, что эта ошибка не будет выдана хостинговым провайдером в случае просроченной оплаты его услуг. Зарезервирован, начиная с HTTP/1.1.
403 * (Forbidden — Запрещено)
Ошибка 403 указывает, что rest API отказывается выполнять запрос клиента, т.е. Клиент не имеет необходимых разрешений для доступа. Ответ 403 не является случаем, когда нужна авторизация (для ошибки авторизации используется код 401).
Попытка аутентификация не поможет, и повторные запросы не имеют смысла.
404 * (Not Found — Не найдено)
Указывает, что rest API не может сопоставить URL клиента с ресурсом, но этот URL может быть доступен в будущем. Последующие запросы клиента допустимы.
404 не указывает, является ли состояние временным или постоянным. Для указания постоянного состояния используется код 410 (Gone — Пропал). 410 использоваться, если сервер знает, что старый ресурс постоянно недоступен и более не имеет адреса.
405 (Method Not Allowed — Метод не разрешен)
API выдает ошибку 405, когда клиент пытался использовать HTTP метод, который недопустим для ресурса. Например, указан метод PUT, но такого метода у ресурса нет.
Ответ 405 должен включать Заголовок Allow, в котором перечислены поддерживаемые HTTP методы, например, Allow: GET, POST.
406 (Not Acceptable — Неприемлемый)
API не может генерировать предпочитаемые клиентом типы данных, которые указаны в заголовке запроса Accept. Например, запрос клиента на данные в формате application/xml получит ответ 406, если API умеет отдавать данные только в формате application/json.
В таких случаях Клиент должен решить проблему данных у себя и только потом отправлять запросы повторно.
407 — (Proxy Authentication Required — Требуется прокси-аутентификация)
Ответ аналогичен коду 401, за исключением того, что аутентификация производится для прокси-сервера. Механизм аналогичен идентификации на исходном сервере.
Пользователь должен сначала авторизоваться через прокси. Прокси-сервер должен вернуть Proxy-Authenticate заголовок, содержащий запрос ресурса. Клиент может повторить запрос вместе с Proxy-Authenticate заголовком. Появился в HTTP/1.1.
408 — (Request Timeout — Таймаут запроса)
Время ожидания сервером передачи от клиента истекло. Клиент не предоставил запрос за то время, пока сервер был готов его принят. Клиент МОЖЕТ повторить запрос без изменений в любое время.
Например, такая ситуация может возникнуть при загрузке на сервер объёмного файла методом POST или PUT. В какой-то момент передачи источник данных перестал отвечать, например, из-за повреждения компакт-диска или потери связи с другим компьютером в локальной сети. Пока клиент ничего не передаёт, ожидая от него ответа, соединение с сервером держится. Через некоторое время сервер может закрыть соединение со своей стороны, чтобы дать возможность другим клиентам сделать запрос.
409 * (Conflict — Конфликт)
Запрос нельзя обработать из-за конфликта в текущем состоянии ресурса. Этот код разрешается использовать только в тех случаях, когда ожидается, что пользователь может самостоятельно разрешить этот конфликт и повторить запрос. В тело ответа СЛЕДУЕТ включить достаточное количество информации для того, чтобы пользователь смог понять причину конфликта. В идеале ответ должен содержать такую информацию, которая поможет пользователю или его агенту исправить проблему. Однако это не всегда возможно и это не обязательно.
Как правило, конфликты происходят во время PUT-запроса. Например, во время использования версионирования, если сущность, к которой обращаются методом PUT, содержит изменения, конфликтующие с теми, что были сделаны ранее третьей стороной, серверу следует использовать ответ 409, чтобы дать понять пользователю, что этот запрос нельзя завершить. В этом случае в ответной сущности должен содержаться список изменений между двумя версиями в формате, который указан в поле заголовка Content-Type.
410 — (Gone — Исчез)
Такой ответ сервер посылает, если ресурс раньше был по указанному URL, но был удалён и теперь недоступен. Серверу в этом случае неизвестно и местоположение альтернативного документа, например, копии. Если у сервера есть подозрение, что документ в ближайшее время может быть восстановлен, то лучше клиенту передать код 404. Появился в HTTP/1.1.
411 — (Length Required — Требуется длина)
Для указанного ресурса клиент должен указать Content-Length в заголовке запроса. Без указания этого поля не стоит делать повторную попытку запроса к серверу по данному URI. Такой ответ естественен для запросов типа POST и PUT. Например, если по указанному URI производится загрузка файлов, а на сервере стоит ограничение на их объём. Тогда разумней будет проверить в самом начале заголовок Content-Length и сразу отказать в загрузке, чем провоцировать бессмысленную нагрузку, разрывая соединение, когда клиент действительно пришлёт слишком объёмное сообщение.
412 — (Precondition Failed — Предварительное условие не выполнено)
Возвращается, если ни одно из условных полей заголовка запроса не было выполнено.
Когда клиент указывает rest API выполнять запрос только при выполнении определенных условий, а API не может выполнить запрос при таких условиях, то возвращается ответ 412.
Этот код ответа позволяет клиенту записывать предварительные условия в метаинформации текущего ресурса, таким образом, предотвращая применение запрошенного метода к ресурсу, кроме того, что ожидается.
413 — (Request Entity Too Large — Сущность запроса слишком большая)
Возвращается в случае, если сервер отказывается обработать запрос по причине слишком большого размера тела запроса. Сервер может закрыть соединение, чтобы прекратить дальнейшую передачу запроса.
Если проблема временная, то рекомендуется в ответ сервера включить заголовок Retry-After с указанием времени, по истечении которого можно повторить аналогичный запрос.
414 — (Request-URI Too Long — Запрос-URI Слишком длинный)
Сервер не может обработать запрос из-за слишком длинного указанного URL. Эту редкую ошибку можно спровоцировать, например, когда клиент пытается передать длинные параметры через метод GET, а не POST, когда клиент попадает в «чёрную дыру» перенаправлений (например, когда префикс URI указывает на своё же окончание), или когда сервер подвергается атаке со стороны клиента, который пытается использовать дыры в безопасности, которые встречаются на серверах с фиксированной длиной буфера для чтения или обработки Request-URI.
415 (Unsupported Media Type — Неподдерживаемый медиа тип)
Сообщение об ошибке 415 указывает, что API не может обработать предоставленный клиентом Тип медиа, как указано в заголовке запроса Content-Type.
Например, запрос клиента содержит данные в формате application/xml, а API готов обработать только application/json. В этом случае клиент получит ответ 415.
Например, клиент загружает изображение как image/svg+xml, но сервер требует, чтобы изображения использовали другой формат.
428 — (Precondition Required — Требуется предварительное условие)
Код состояния 428 указывает, что исходный сервер требует, чтобы запрос был условным.
Его типичное использование — избежать проблемы «потерянного обновления», когда клиент ПОЛУЧАЕТ состояние ресурса, изменяет его и ОТПРАВЛЯЕТ обратно на сервер, когда тем временем третья сторона изменила состояние на сервере, что привело к конфликту. Требуя, чтобы запросы были условными, сервер может гарантировать, что клиенты работают с правильными копиями.
Ответы с этим кодом состояния ДОЛЖНЫ объяснять, как повторно отправить запрос.
429 — (Too Many Requests — Слишком много запросов)
Пользователь отправил слишком много запросов за заданный промежуток времени.
Представления ответа ДОЛЖНЫ включать подробности, объясняющие условие, и МОГУТ включать заголовок Retry-After, указывающий, как долго ждать, прежде чем делать новый запрос.
431 — (Request Header Fields Too Large — Слишком большие поля заголовка запроса)
Код состояния 431 указывает на то, что сервер не желает обрабатывать запрос, поскольку его поля заголовка слишком велики. Запрос МОЖЕТ быть отправлен повторно после уменьшения размера полей заголовка запроса.
Его можно использовать как в случае, когда совокупность полей заголовка запроса слишком велика, так и в случае неисправности одного поля заголовка. В последнем случае представление ответа ДОЛЖНО указывать, какое поле заголовка было слишком большим.
444 — (No Response — Нет ответа) (Nginx)
Код ответа Nginx. Сервер не вернул информацию и закрыл соединение. (полезно в качестве сдерживающего фактора для вредоносных программ)
451 — (Unavailable For Legal Reasons — Недоступен по юридическим причинам)
Доступ к ресурсу закрыт по юридическим причинам. Наиболее близким из существующих является код 403 Forbidden (сервер понял запрос, но отказывается его обработать). Однако в случае цензуры, особенно когда это требование к провайдерам заблокировать доступ к сайту, сервер никак не мог понять запроса — он его даже не получил. Совершенно точно подходит другой код: 305 Use Proxy. Однако такое использование этого кода может не понравиться цензорам. Было предложено несколько вариантов для нового кода, включая «112 Emergency. Censorship in action» и «460 Blocked by Repressive Regime»
500 * (Internal Server Error — Внутренняя ошибка сервера)
Общий ответ при ошибке в коде. Универсальное сообщение о внутренней ошибке сервера, когда никакое более определенное сообщение не подходит.
Большинство веб-платформ автоматически отвечают этим кодом состояния, когда при выполнении кода обработчика запроса возникла ошибка.
Ошибка 500 никогда не зависит от клиента, поэтому для клиента разумно повторить точно такой же запрос, и надеяться что в этот раз сервер отработает без ошибок.
501 (Not Implemented — Не реализован)
Серверу либо неизвестен метод запроса, или ему (серверу) не хватает возможностей выполнить запрос. Обычно это подразумевает будущую доступность (например, новая функция API веб-сервиса).
Если же метод серверу известен, но он не применим к данному ресурсу, то нужно вернуть ответ 405.
502 — (Bad Gateway — Плохой шлюз)
Сервер, выступая в роли шлюза или прокси-сервера, получил некорректный ответ от вышестоящего сервера, к которому он обратился. Появился в HTTP/1.0.
503 — (Service Unavailable — Служба недоступна)
Сервер не может обработать запрос из-за временной перегрузки или технических работ. Это временное состояние, из которого сервер выйдет через какое-то время. Если это время известно, то его МОЖНО передать в заголовке Retry-After.
504 — (Gateway Timeout — Таймаут шлюза)
Сервер, в роли шлюза или прокси-сервера, не дождался в рамках установленного таймаута ответа от вышестоящего сервера текущего запроса.
505 — (HTTP Version Not Supported — Версия HTTP не поддерживается)
Сервер не поддерживает или отказывается поддерживать указанную в запросе версию протокола HTTP.
510 — (Not Extended — Не расширен)
В запросе не соблюдена политика доступа к ресурсу. Сервер должен отправить обратно всю информацию, необходимую клиенту для отправки расширенного запроса. Указание того, как расширения информируют клиента, выходит за рамки данной спецификации.
—
Источники и более подробная информация:
- https://restapitutorial.ru/httpstatuscodes.html
- https://www.restapitutorial.com/httpstatuscodes.html
- https://restfulapi.net/http-status-codes/
- https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/428
Продолжаем разговор об исключениях в C++.
- Гарантии безопасности
- Спецификации исключений в C++
- Стоит ли избегать исключений
- Как работают исключения
- Заключение
- Полезные ссылки

Георгий Осипов
Один из авторов курса «Разработчик C++» в Яндекс Практикуме, разработчик в Лаборатории компьютерной графики и мультимедиа ВМК МГУ
В первой части мы разобрали, как создавать исключения и работать с ними, а также какими они бывают. Разобрали ключевые слова try, catch и throw, синтаксис выбрасывания и обработки исключений, а ещё особые случаи, связанные с исключениями.
Вторая часть статьи больше подойдёт продвинутым программистам, которые хотят глубже разобраться в теме исключений. Однако никаких специальных знаний не требуется. Во второй части мы разберём:
- гарантии безопасности;
- спецификации исключений;
- как исключения влияют на скорость выполнения;
- как устроены исключения в C++ и как они работают.
Также рассмотрим философский вопрос о нужности исключений и альтернативных подходах, запустим три бенчмарка и в результате увидим, что иногда исключения не только не замедляют программу, а даже ускоряют.
Углубить и систематизировать знания C++ поможет курс «Разработчик C++» в Яндекс Практикуме. Для тех, кто знает C++, но желает изучить работу по сети, Docker, Linux и множество вспомогательных инструментов, есть курс «C++ для бэкенда».
Гарантии безопасности
Исключения — ситуация нештатная. Но они существуют для того, чтобы как-то обработать эту ситуацию и продолжить выполнение программы.
Чтобы было ясно, как исключительная ситуация может повлиять на работу, существует специальное понятие — гарантия безопасности исключений. Это описание вреда, который может нанести исключение, приводимое в документации к функции или методу.
Выделяют четыре уровня безопасности исключений:
- Гарантия отсутствия исключения. Самая сильная гарантия. Означает, что исключение возникнуть не может, а значит, ничего не сломает.
- Строгая гарантия безопасности. Исключение может возникнуть, но в этом случае всё будет возвращено к тому, как было до вызова соответствующей функции. Иными словами, операция не удалась, но можно сделать вид, как будто её и не было.
- Базовая гарантия безопасности. При возникновении ошибки мы не можем вернуть всё как было, но всё равно останемся в корректном состоянии. Все инварианты будут сохранены, все ненужные ресурсы освобождены, ничего не утечёт. С объектом, из-за которого возникло исключение, можно продолжать работать.
- Отсутствие безопасности. Не можем гарантировать ничего. Если исключение произошло, лучше поскорее завершить работу программы.
Рассмотрим пример. Напишем собственную операцию push_back для вставки в вектор.
Гарантия отсутствия безопасности
template<class T>
class Vector {
public:
void push_back_no_guarantee(T elem) {
T* old = mem;
// Возможное исключение в new не опасное:
// мы ещё ничего не успели испортить
mem = new T[size + 1];
size_t old_size = size++;
// Используем алгоритм move для перемещения всех
// элементов из старой памяти в новую.
// Тут может возникнуть исключение.
std::move(old, old + old_size, mem);
mem[old_size] = std::move(elem);
delete[] old;
}
private:
T* mem = nullptr;
size_t size = 0;
};
Вызов new не опасен в отличие от перемещения элементов: мы ничего не знаем про конструктор перемещения неизвестного объекта T. Он может выбрасывать исключение.
Эта реализация метода не даёт гарантий. Если во время перемещения объектов возникло исключение, то мы как минимум получим утечку памяти. Кроме того, у вектора будет неправильный размер, например, если перемещение прервалось на середине.
В примере мы использовали new для простоты и наглядности. Реальный вектор должен выделять сырую память без инициализации.
Базовая гарантия безопасности
Улучшим нашу функцию, чтобы подняться с четвёртого уровня безопасности на третий. Это минимальный уровень, который допустимо использовать в программах.
void push_back_basic_guarantee(T elem) {
T* old = mem;
mem = new T[size + 1];
size_t old_size = size;
size = 0;
try {
// Используем цикл, чтобы постоянно знать актуальный размер.
for (size_t i = 0; i < old_size; ++i) {
mem[i] = std::move(old[i]);
size++;
}
mem[old_size] = std::move(elem);
size++;
}
catch(...) {
// Предотвратим утечку ресурсов в случае исключения
delete[] old;
throw;
}
delete[] old;
}Уже лучше: размер вектора будет корректен, и мы не допустим утечки. Однако такая вставка может привести, например, к обнулению вектора, если исключение возникло в самом первом перемещении.
Строгая гарантия безопасности
Над строгой гарантией нужно потрудиться.
void push_back_strong_guarantee(T elem) {
// Идём другим путём: аллоцируем память, но не будем
// менять this->mem пока копирование не закончено.
T* new_mem = new T[size + 1];
try {
for (size_t i = 0; i < size; ++i) {
// Мы должны быть готовы всё вернуть как было, а значит,
// не можем перемещать элементы, чтобы не испортить
// старую память — придётся их копировать.
new_mem[i] = mem[i];
}
// Последний элемент можно переместить:
new_mem[size] = std::move(elem);
}
catch(...) {
delete[] new_mem;
throw;
}
// Выше мы вообще не меняли this.
// Теперь, когда всё точно готово, сделаем это.
T* old = mem;
mem = new_mem;
size++;
// Считаем, что деструктор не выбрасывает.
delete[] old;
}У строгой гарантии есть неприятный эффект: нам пришлось отказаться от перемещений в пользу копирований. Таким образом, она отрицательно влияет на эффективность.
Можно сделать всё эффективно, если есть уверенность, что перемещение объектов типа T не выбрасывает исключений. Стандартный std::vector так и делает.
Гарантия отсутствия исключения
И наконец, достигнем вершины — напишем метод без исключений:
// Теперь метод возвращает bool:
// true показывает, что вставка удалась,
// false свидетельствует об ошибке.
bool push_back_no_exception(T elem) {
T* new_mem;
// Теперь нужно поймать возможный std::bad_alloc или
// исключение в конструкторе
try {
new_mem = new T[size + 1];
}
catch(...) {
return false;
}
try {
for (size_t i = 0; i < size; ++i) {
new_mem[i] = mem[i];
}
new_mem[size] = std::move(elem);
}
catch(...) {
delete[] new_mem;
return false;
}
T* old = mem;
mem = new_mem;
size++;
// По-прежнему считаем, что деструктор не выбрасывает.
delete[] old;
return true;
}Возврат флага успеха — альтернатива исключениям. Функция очень похожа на предыдущий вариант. Однако при такой реализации мы ничего не сможем узнать о том, какая именно ошибка произошла.
Такой разный noexcept
Как говорилось выше, вставка в вектор может работать эффективнее, если есть гарантия, что перемещение объекта не выбрасывает исключений. Такую гарантию можно дать для произвольной функции, если пометить её словом noexcept:
// Функция извлечения корня будет возвращать пустое значение
// а не выбрасывать исключение. Чтобы показать, что она не выбрасывает
// мы пометили её как noexcept:
std::optional<double> SafeSqrt(double arg) noexcept {
return arg >= 0 ? sqrt(arg) : std::nullopt;
}Если же мы хотим явно сказать, что функция выбрасывает исключение, можно написать noexcept(false):
double UnsafeSqrt(double arg) noexcept(false) {
return arg >= 0
? sqrt(arg)
: throw std::invalid_argument("Попытка извлечь корень из отрицательного числа");
}Но это лишнее, ведь выбрасывающими по умолчанию считаются все функции, кроме деструкторов. Зато можно поместить внутрь скобок содержательное выражение времени компиляции:
int f() noexcept { return 42; }
int g() { throw 42; }
constexpr bool f_is_noexcept = true;
constexpr bool g_is_noexcept = false;
// h является noexcept, только когда и f и g таковые:
int h() noexcept(f_is_noexcept && g_is_noexcept) {
return f() + g();
}Тут мы явно написали, какая функция noexcept, а какая — нет, хотя могли бы вычислить. noexcept допустимо использовать как операцию, определяющую, может ли выбрасывать содержимое скобок:
#include <iostream>
int f() noexcept { return 42; }
int g() { throw 42; }
constexpr bool f_is_noexcept = noexcept(f());
constexpr bool g_is_noexcept = noexcept(g());
int h() noexcept(f_is_noexcept && g_is_noexcept) {
return f() + g();
}
int main() {
std::cout << "Функция f может выбрасывать исключения? " << (noexcept(f()) ? "нет" : "да") << std::endl;
std::cout << "Функция g может выбрасывать исключения? " << (noexcept(g()) ? "нет" : "да") << std::endl;
std::cout << "Функция h может выбрасывать исключения? " << (noexcept(h()) ? "нет" : "да") << std::endl;
std::cout << "Выражение f() + g() может выбрасывать исключения? " << (noexcept(f() + g()) ? "нет" : "да") << std::endl;
}Вывод программы будет таким:
Функция f может выбрасывать исключения? нет
Функция g может выбрасывать исключения? да
Функция h может выбрасывать исключения? да
Выражение f() + g() может выбрасывать исключения? даЗаметьте, что мы пишем noexcept(g()), а не noexcept(g). Последнее выражение всегда false, поскольку само по себе выражение g ничего не делает, а значит, ничего не выбрасывает.
Если в функции, помеченной как noexcept, всё же возникло исключение, то оно приведёт к вызову std::terminate и завершению программы.
А нужен ли noexcept?
Вряд ли что-то может ответить на поставленный вопрос красноречивее бенчмарка. В этом бенчмарке, который мы провели в сервисе QuickBench, созданы три практически одинаковых класса:
F_except, у которого есть обычный конструктор перемещения;
F_noexcept, у которого конструктор перемещения помечен какnoexcept;F_noexcept2— какF_noexcept, но с деструктором, помеченным какnoexcept(false). Деструктор нужно явно помечать какnoexcept(false), иначе он считается невыбрасывающим.
Объекты этих классов добавляются в std::vector. Его метод push_back обеспечивает строгую гарантию исключений. Как вы уже знаете, в этом случае перемещение вектора возможно только тогда, когда перемещение его элементов не выбрасывает исключений.
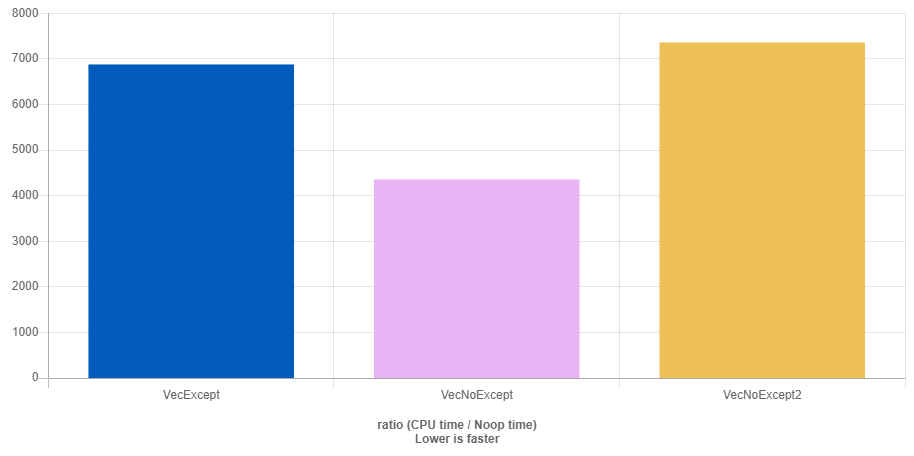
Добавление элемента в вектор в среднем в 1,6 раза быстрее, если конструктор перемещения элементов помечен как noexcept. Добавление замедляется, если деструктор элементов может выбрасывать
Отличие заметное, хотя не такое существенное из-за оптимизаций в std::vector. noexcept позволил выбрать более эффективный алгоритм, но только в том случае, когда он применялся и для конструктора перемещения, и для деструктора.
Волшебный default
Рассмотрим три класса:
class T1 {
public:
};
class T2 {
public:
T2() {}
};
class T3 {
public:
T4() = default;
};Казалось бы, разницы между ними нет, но попробуем изучить конструкцию T*() на предмет выбрасывания исключений:
class T1 {
public:
};
class T2 {
public:
T2() {}
};
class T3 {
public:
T4() = default;
};
class T4 {
public:
T4() noexcept {}
};
int main() {
std::cout << std::boolalpha;
std::cout << "T1() noexcept: " << noexcept(T1()) << std::endl;
std::cout << "T2() noexcept: " << noexcept(T2()) << std::endl;
std::cout << "T3() noexcept: " << noexcept(T3()) << std::endl;
std::cout << "T4() noexcept: " << noexcept(T4()) << std::endl;
}В этом примере мы также добавили четвёртый класс. Вывод программы такой:
T1() noexcept: true
T2() noexcept: false
T3() noexcept: true
T4() noexcept: trueНас подвёл только один вариант, в котором конструктор объявлен как T2() {}. Такой конструктор будет считаться выбрасывающим, хотя на вид он аналогичен записи T2() = default.
Невыбрасывающий конструктор часто позволяет получить более эффективный код и применить больше оптимизаций. В легковесных классах он вообще может не генерировать никаких инструкций, в то время как выбрасывающий потребует лишней работы. Предпочитайте конструкцию = default пустым скобкам.
Список исключений
В некоторых языках программирования c исключениями всё строже. Каждая функция снабжается списком исключений, которые она может выбрасывать. Была такая попытка и в C++ с самого момента его стандартизации:
#include <iostream>
#include <cmath>
class MyException{};
// Спецификация исключений для функции.
// Компилировать с флагом -std=c++03 или иным
// в зависимости от компилятора
int f(int x) throw(MyException) {
if (x < 0)
throw MyException();
return sqrt(x);
}
int main() {
f(15);
f(-3);
}У такого подхода есть преимущества:
- компилятор может убедиться, что все исключения обрабатываются;
- вы видите, что может, а что не может выбрасывать функция по её сигнатуре;
- обработчик можно искать в compile-time.
Однако на деле не всё так радужно. Всплыл ряд недостатков:
- Некоторые исключения, например,
std::bad_allocможет выбрасывать почти любая функция. Везде писатьthrow(std::bad_alloc)утомительно. - Непонятно, как быть с указателями на функции и
std::function. Если мы хотим заранее всё знать об исключениях, то спецификации исключений должны быть в типе функции. Тогда неясно, как их преобразовывать. - Можно сделать спецификации нестрогими, но тогда непонятно, что они дают.
С похожими недостатками сталкиваются и в других языках программирования. В C++ недостатки перевесили, и комитет по стандартизации решил от явных спецификаций отказаться, оставляя только noexcept. В Стандарте C++11 они объявлены устаревшими (deprecated), а позже вовсе исключены из языка.
Стоит ли избегать исключений
«Мы не используем исключения в C++», — cтайлгайд Google.
Не нужны или незаменимы
Исключения в C++ — удобный инструмент, не лишённый недостатков. Может быть, самый существенный из них — в том, что исключения прозрачны. Глядя на сигнатуру функции, нельзя понять, какие исключения она выбрасывает. Это можно понять, глядя в документацию. Но документация не проверяется автоматически, а значит, может ошибаться.
Код с исключениями иногда трудней читать и модифицировать. Может, где-то через функцию пролетает исключение, задуманное разработчиком, но узнать об этом, глядя на код, невозможно. Вы модифицируете функцию, внося, казалось бы, несущественные изменения, но тем самым нарушаете гарантии безопасности.
Вспомните пример с четырьмя реализациями push_back. Программисту, который не знал нашей мотивации — обеспечение гарантий безопасности, — будет совершенно неочевидно, почему мы обновили поле mem в начале функции, а не в другом месте. Ему покажется это прихотью, и он изменит способ на противоположный — просто для красоты кода. При этом корректная обработка исключений перестанет работать.
Но если пользоваться исключениями аккуратно, то данного недостатка можно избежать.
В некоторых местах без исключений трудно: например, это единственный способ прервать конструктор. Можно, конечно, ввести для объекта невалидное состояние, указывающее, что во время конструктора произошла ошибка. Но это будет усложнением класса.
Помимо конструкторов исключения практически незаменимы, когда вы делаете много похожих действий, каждое из которых может завершиться неудачей:
std::optional<PersonCard> ParseJSON(json raw_json, int idx) {
PersonCard result;
try {
result.first_name = raw_json["persons"][idx]["name"]["first"].as_string();
result.last_name = raw_json["persons"][idx]["name"]["last"].as_string();
result.phone = parse_phone(raw_json["persons"][idx]["phone"].as_string());
result.address = raw_json["persons"][idx]["address"];
}
catch(json::error e) {
std::cout << "Error in JSON at " << e.where() << ": " << e.what() << std::endl;
return std::nulltopt;
}
return result;
}Без исключений только первая строка блока try записывалась бы так:
if (!raw_json.is_object()) return std::nullopt;
if (!raw_json.has_key("persons")) return std::nullopt;
if (!raw_json["persons"].is_array()) return std::nullopt;
if (raw_json["persons"].length() >= idx) return std::nullopt;
if (!raw_json["persons"][idx].is_object()) return std::nullopt;
if (!raw_json["persons"][idx].has_key("name")) return std::nullopt;
if (!raw_json["persons"][idx]["name"].is_object()) return std::nullopt;
if (!raw_json["persons"][idx]["name"].has_key("first")) return std::nullopt;
if (!raw_json["persons"][idx]["name"]["first"].is_string()) return std::nullopt;При этом мы опустили вывод диагностики о местоположении ошибки и её сути. Конечно, можно было придумать сложный прокси-объект, который ведёт себя как JSON, но на самом деле находится в ошибочном состоянии и не выполняет никаких действий, и тем самым сократить количество строк.
Но решайте сами, следовать ли стайлгайду Google в этой части. Ещё один аргумент в пользу исключений в C++ вы найдёте ниже.
Строгий запрет
Некоторые компании и программисты предпочитают вообще не использовать исключения. Об этом лучше сказать компилятору специальной опцией. Это развяжет оптимизатору руки и позволит генерировать более простой и эффективный код в очень многих случаях.
Для GCC и clang это опция -fno-exceptions. Её использование не значит, что исключений не возникнет. В частности, никто не может избавить вас от std::bad_alloc и других исключений, выбрасываемых из библиотек. Однако чаще всего исключение будет приводить к вызову std::terminate.
Если на радикальные меры идти не хочется, ваш друг — noexcept. Он работает не хуже, чем -fno-exceptions, если его поставить везде, где нужно. noexcept также хорошо помогает оптимизатору и убирает оверхед при вызове функций, помеченных этим ключевым словом.
Назад в будущее
У исключений есть альтернатива, известная ещё корифеям, — возврат флага или ошибки из функции. Если вы пишете процедуру, то проще всего вернуть флаг успеха:
bool DoSomeOperation() {
if (!CanDoOperation())
return false;
DoUnchecked();
return true;
}Чтобы компилятор проверял, что вызывающая функция точно обрабатывает ошибку, добавим [[nodiscard]]:
[[nodiscard]] bool DoSomeOperation() …Подобного сервиса — проверки, что ошибка обрабатывается, — нет даже у исключений. Если булевого флага недостаточно, функция может возвращать объект ошибки, содержащий информацию о её причинах. В этом случае [[nodiscard]] можно поставить прямо в класс:
struct [[nodiscard]] ErrorInfo {
// Операция вернёт false, если ошибки не было.
operator bool() const {
return error_code != 0;
}
std::string what() const;
int error_code = 0;
}
ErrorInfo DoOperation();
int main() {
auto err = DoOperation();
if (err) {
std::cout << err.what() << std::endl;
return EXIT_FAILURE;
}
}Когда функция должна сама по себе вернуть значение, такой способ не подходит. Решение есть — специальный тип std::expected, но он будет добавлен в язык только в 2023 году. Предполагается, что этот объект будет хранить либо возвращённое значение, либо код ошибки, когда операция не удалась.
Универсальный солдат
Если ждать до 2023-го не хочется, можно реализовать expected самостоятельно или использовать простую замену: передать функции объект ошибки по ссылке, предлагая записать в него информацию.
Это самый универсальный и удобный способ для пользователя функции. Так мы предлагаем ему выбор: хочет ли он ловить исключение или предпочитает обрабатывать объект ошибки. Такой способ предусмотрен во многих библиотеках, в том числе в std. Рассмотрим примеры.
- std::filesystem. Функции работы с файловой системой часто могут завершаться с ошибкой. Например, вы хотите переименовать файл, но его только что удалили. В этом и подобных случаях выбрасывается
std::filesystem::filesystem_error, подклассstd::system_error, который в свою очередь расширяет подклассstd::runtime_errorиstd::exception.
Но если вы указали дополнительный параметр типаstd::error_code&, то исключение не будет выброшено — вместо этого ошибка запишется в переданный объект:std::error_code ec; std::filesystem::rename(old_path, new_path, ec); if (!ec) { std::cerr << "Ошибка переименования" << std::endl; } - Потоки ввода-вывода. Для них используется немного другой механизм. По умолчанию потоки не выбрасывают, и вы вынуждены проверять все операции на корректность.
Если вызвать метод потокаexceptions, то можно попросить поток сигнализировать при появлении флагов ошибок. Будет выбрасываться исключениеstd::ios_base::failure(также подвидstd::system_error). У метода есть эффект, даже если он вызван уже после возникновения ошибки:#include <iostream> #include <fstream> int main() { std::ifstream f("abracadabra"); try { f.exceptions(f.failbit); } catch (const std::ios_base::failure& e) { std::cout << "Ошибка потока: " << e.what() << 'n' << "Код: " << e.code() << 'n'; } }Передавать в метод
exceptionsфлагeofbitне рекомендуется. Достижение конца файла — штатная, а не исключительная ситуация. Последующие чтения всё равно установят флагfail.
А что со скоростью?
Бытует мнение, что исключения — это всегда медленно. Ведь у всех этих конструкций try наверняка большой оверхед. Даже если try-блоков нет, компилятор всё равно должен быть в любой момент готов обработать исключение при вызове любой функции, не помеченной как noexcept.
Проверим, так ли это. Лучший способ — бенчмарк. Будем измерять две функции, выполняющие похожую работу:
void f()— не помечена какnoexcept. Рекурсивно вызывает себя. После 10 миллионов вызовов выбрасывает исключение.bool g()— помечена какnoexcept. Рекурсивно вызывает себя. После 10 миллионов вызовов возвращаетfalse,и цепочка вызовов прерывается.
Результат во многом зависит от компилятора, оптимизаций и наличия у функций атрибута noinline. Но в большинстве случаев версия с исключениями по крайней мере не хуже. Вот бенчмарк, где версия с исключениями работает в полтора раза быстрее. При использовании clang преимущество скромнее — всего 10%.
Может показаться, что пример искусственный. В какой-то степени так и есть, но это не меняет тенденции. Без исключений в C++ нам нужно было проверять каждый результат возврата, а это дорогостоящая инструкция условного перехода. Трудно поверить, но при использовании исключений такая инструкция при вызове не требуется. Иногда это может дать неплохой выигрыш.
Сравним дизассемблер. Для наглядности добавим больше рекурсивных вызовов в каждую функцию. Так выглядит вариант с исключениями:

Каждый рекурсивный вызов превратился в одну инструкцию call, последний — в jmp
А вот начало функции с проверками. Не будем приводить код полностью:

Каждый рекурсивный вызов превратился в три инструкции — call, test и условный переход
Неудивительно, что исключения в этом случае победили. Однако не нужно думать, что так будет всегда. Главный минус исключений с точки зрения производительности — в том, что они мешают оптимизации.
Профессионалы советуют: везде, где можно, ставьте noexcept. Иначе производительность может сильно пострадать. Это причина, почему многие крупные компании вообще не используют исключения.
Как работают исключения
Исключения в компиляторах можно реализовать по-разному. Реализации стремятся к нулевому оверхеду, который формулируется так:
Мы не должны платить производительностью до тех пор, пока исключение не выбрасывается. Код, в котором исключение не произошло, должен работать так же быстро, как если бы исключение не могло произойти.
Современные компиляторы (а вернее, генераторы кода) в полной мере этому принципу не следуют, в чём можно убедиться, изучив ассемблерный код, который они выдают. Но возникающий оверхед минимальный, а где-то отсутствует вовсе. Подумаем, что обязан делать процессор для того, чтобы обеспечить возможность исключений.
Посадочные площадки
Исключение может возникнуть практически где угодно, а именно при любом вызове функции, не помеченной как noexcept. Во всех этих случаях компилятор должен знать, что ему делать дальше. Рассмотрим две строчки:
std::string s = "Имя гостя номер " + std::to_string(N) + " - " + guest_names.at(N);
std::cout << s << std::endl;Они могут прерваться в девяти местах:
- два раза — при конвертации
const char* в std::string; возможное исключениеbad_alloc; - три раза — при сложении строк; возможное исключение
bad_alloc; - один раз — в
std::to_string; возможное исключениеbad_alloc; - один раз — в
std::vector::at; возможное исключениеstd::out_of_range; - два раза — в
std::ostream::operator <<; возможное исключениеstd::ios_base::failure. Даже если мы не устанавливали для потока флаг выброса исключений, компилятор всё равно должен быть готов к такому повороту событий — операция<<не помечена какnoexcept.
Для этих девяти мест компилятор должен предусмотреть пути отхода. А именно установить, какие временные объекты он должен удалить в каждом случае и что делать дальше. Для этого в бинарном коде программы создаётся посадочная площадка (landing pad). Процессор приземляется на ней только в случае исключения.
Вызов функции обычно превращается в процессорную инструкцию call. При этом в стек кладётся адрес места, куда нужно вернуться после инструкции ret, завершающей вызов. Если вызываемая функция помечена как noexcept, то этого достаточно. Если нет, процессору нужно знать, куда идти, если в процессе выполнения вызова произошло непойманное исключение. Он идёт на посадочную площадку.
Таким образом для возможности обработки исключений каждый вызов требует максимум одну дополнительную инструкцию — запоминание адреса экстренной посадочной площадки. Сущая мелочь.
Выбор обработчика
Мы так увлеклись оверхедом, что совсем забыли: исключения нужны, чтобы их ловить. А ловят их обработчики. Чтобы исключение нашло свой обработчик, при выполнении raise нужно сохранить информацию о типе. Причём эта информация будет обрабатываться во время выполнения программы (run-time).
В C++ для этого есть свой механизм — динамическая идентификация типа данных, или RTTI. Чтобы мы могли поймать исключение по базовому типу, в run-time должна быть доступна информация обо всех предках выброшенного исключения.
Таким образом, raise делает следующее:
- сохраняет объект исключения;
- сохраняет информацию о типе;
- возможно, сохраняет что-то ещё (например, ссылку на деструктор объекта исключения);
- если надо, запускает
terminate; - если не надо, запускает раскрутку стека.
Раскрутка стека делает следующее:
- приземляется на посадочную площадку;
- удаляет временные и автоматические объекты;
- проверяет все доступные обработчики на соответствие типа;
- если надо, запускает
terminate; - если не надо (и обработчик не найден), продолжает раскрутку стека.
Обработчик делает следующее:
- выполняет пользовательский код;
- если исключение не переброшено, то деаллоцирует его.
И снова бенчмарк
Чтобы проверить, что информация о типе действительно обрабатывается в run-time, проведём ещё один любопытный бенчмарк. Создадим тип F очень простого вида:
struct F{};А также шаблон template<int> struct G. Его особенность — в том, что у типа G<0> очень много потомков, 2048 штук. В функции f всё просто: будем бросать исключение типа F и затем ловить исключение типа F. В функции g будем бросать исключение типа G<0>, а ловить по типу одного из его многочисленных потомков — G<1111>.
Если наше предположение верно, то программе потребуется гораздо меньше времени для поиска обработчика исключения типа F. Напротив, чтобы убедиться, что обработчик типа G<1111> соответствует выброшенному исключению типа G<0>, придётся потрудиться.
Запустим бенчмарк и убедимся в своей правоте:
Слева обработка исключения типа G<0>, справа — типа F
Поимка объекта по глубокому производному классу заняла в 32 раза больше времени. Таким образом мы убедились, что проверка исключения на соответствие типу действительно происходит в run-time.
Мы рассмотрели подкапотную исключений и увидели, что часть важной работы происходит в run-time, что несвойственно для C++. Может быть, это даже не очень эффективно, но, как было сказано выше, при обработке исключений эффективность отодвигается на второй план. Ведь это исключительная ситуация, и в том, чтобы потратить несколько десятков тысяч лишних инструкций, нет ничего страшного.
Заключение
Мы проделали большую работу. Разобрались в тонкостях исключений в C++, гарантиях, спецификациях. Узнали, что, вопреки распространённому мнению, исключения — не всегда медленно.
Да, исключения мешают оптимизатору, но если не забыть noexcept для критически важных функций, то этот эффект сведётся к минимуму.
Некоторые компании избегают исключений в своём коде. Но только вам решать, отказываться от них или нет. При умелом использовании исключения не принесут вреда, а польза может быть огромна. В одном можете быть уверены: после прочтения этой статьи умелое использование исключений — в ваших руках.
Полезные ссылки
- Курс «Разработчик C++» в Яндекс Практикуме
- Дополнительный курс «C++ для бэкенда» в Яндекс Практикуме
- Блок try в энциклопедии cppreference
- Конструкция throw в энциклопедии cppreference
- Спецификации исключений в энциклопедии cppreference
- Стандартные типы исключений в энциклопедии cppreference
- Доклад «Исключения C++ через призму компиляторных оптимизаций» на конференции C++ Russia 2019 Piter
- Сервис микробенчмарков Quick C++ Benchmark
- Раздел «Исключения» стайлгайда Google