7.1. Способы локализации
После
того, как с помощью контрольных тестов
(или каким либо другим путем) установлено,
что в программе или в конкретном ее
блоке имеется ошибка, возникает задача
ее локализации, то есть установления
точного места в программе, где находится
ошибка.
Процесс
локализации ошибок состоит из следующих
трех компонент:
1.
Получение на машине тестовых результатов.
2.
Анализ тестовых результатов и сверка
их с эталонными.
3.
Выявление ошибки или формулировка
предположения о характере и месте ошибки
в программе.
По
принципам работы средства локализации
разделяются на 4 типа :
1.
Аварийная печать.
2.
Печать в узлах.
3.
Слежение.
4.
Прокрутка.
АВАРИЙНАЯ
ПЕЧАТЬ
осуществляется один раз при работе
отлаживаемой программы, в момент
возникновения аварийной ситуации в
программе, препятствующей ее нормальному
выполнению. Тем самым, конкретное место
включения в работу аварийной печати
определяется автоматически без
использования информации от программиста,
который должен только определить список
выдаваемых на печать переменных.
ПЕЧАТЬ
В УЗЛАХ
включается в работу в выбранных
программистом местах программы; после
осуществления печати значений данных
переменных продолжается выполнение
отлаживаемой программы.
СЛЕЖЕНИЕ
производится или по всей программе, или
на заданном программистом участке.
Причем слежение может осуществляться
как за переменными (арифметическое
слежение), так и за операторами (логическое
слежение). Если обнаруживается, что
происходит присваивание заданной
переменной или выполнение оператора с
заданной меткой, то производится печать
имени переменной или метки и выполнение
программы продолжается. Отличием от
печати в узлах является то, что место
печати может точно и не определяться
программистом (для арифметического
слежения); отличается также и содержание
печати.
ПРОКРУТКА
производится на заданных участках
программы, и после выполнения каждого
оператора заданного типа (например,
присваивания или помеченного) происходит
отладочная печать.
По
типам печатаемых значений (числовые и
текстовые или меточные) средства
разделяются на арифметические и
логические.
7.2. Классификация средств локализации ошибок
Ниже
дана классификация средств локализации.
ТИПЫ
СРЕДСТВ ЛОКАЛИЗАЦИИ ОШИБОК :
1.
Языковые.
1.1.
Обычные.
1.2.
Специальные.
2.
Системные.
(3.
Пакетные)
СРЕДСТВА
ЛОКАЛИЗАЦИИ:
1.
Аварийная печать (арифметическая).
1.1.
Специальные средства языка.
1.2.
Системные средства.
2.
Печать в узлах (арифметическая).
2.1.
Обычные средства языка.
2.2.
Специальные средства языка.
3.
Слежение (специальные средства).
3.1.
Арифметическое.
3.2.
Логическое.
4.
Прокрутка (специальные средства).
4.1.
Арифметическая.
4.2.
Логическая.
8. Технология отладки программы автоматизации учета движения товаров на складе малого предприятия
При
отладке программы использовались
следующие методы контроля и локализации
ошибок (обзор методов см. в теоретической
части раздела) :
1.
Просмотр текста программы и прокрутка
с целью обнаружения явных синтаксических
и логических ошибок.
2.
Трансляция программы (транслятор выдает
сообщения об обнаруженных им ошибках
в тексте программы).
3.
Тестирование.
Тестирование
проводилось посредством ввода исходных
данных, с дальнейшей их обработкой,
выводом результатов на печать и экран.
Результаты работы программы сравнивались
заданными в техническом задании.
4.
При локализации ошибок преимущественно
использовалась печать в узлах, которыми
являлись в основном глобальные переменные,
переменные, используемые при обмене
данными основной программы с подпрограммами.
Отладка
программы производилась по следующему
алгоритму :
1.
Прогонка программы с набором тестовых
входных данных и выявление наличия
ошибок.
2.
Выделение области программы, в которой
может находиться ошибка. Просмотр
листинга программы с целью возможного
визуального обнаружения ошибок. В
противном случае — установка контрольной
точки примерно в середине выделенной
области.
3.
Новая прогонка программы. Если работа
программы прервалась до обработки
контрольной точки, значит, ошибка
произошла раньше. Контрольная точка
переносится, и процесс отладки возвращается
к шагу 2.
4.
Если контрольная точка программы была
обработана, то далее следует изучение
значений регистров, переменных и
параметров программы с тем, чтобы
убедиться в их правильности. При появлении
ошибки — новый перенос контрольной точки
и возврат к шагу 2.
5.
В случае не обнаружения ошибки продолжение
выполнения программы покомандно, с
контролем правильности выполнения
переходов и содержимого регистров и
памяти в контрольных точках. При
локализации ошибки она исправляется и
процесс возвращается к шагу 1.
В
качестве тестовых входных данных
использовалась последовательность
частотных выборок, генерируемых
имитатором в режиме 1. (Каждому интервалу
соответствует фиксированное значение
выборок.)
Соседние файлы в папке 4Diplom
- #
16.04.201332.77 Кб9A4.vsd
- #
- #
- #
- #
- #
Локализационное тестирование: зачем оно нужно приложению или сайту?
Время прочтения
6 мин
Просмотры 17K

Представьте такую картину: вы разработали приложение, а затем выпустили его сразу на нескольких языках. Но уже после релиза вы обнаружили ошибки в разных языковых версиях:
худший кошмар разработчика. Так вот именно для того и существует тестирование локализации, чтобы избежать таких неприятных ситуаций.
Сегодня США уже больше не является крупнейшим игроком на рынке мобильных приложений. Китай и Индия соревнуются за звание мирового лидера. И сегодня нужно, и даже не один раз, проверять все языковые версии перед релизом. Ведь цена даже крошечной ошибки может быть очень высока.
О тестировании локализации компании-разработчики, как правило, задумываются не сразу. И всё же этот процесс нужно обязательно включить в разработку. Давайте подробнее рассмотрим, что представляет собой тестирование локализации, какие важные этапы оно включает и зачем вообще оно нужно.
Что такое локализационное тестирование?
Если коротко, локализационное тестирование — это проверка содержимого приложения или сайта на соответствие лингвистическим, культурным требованиям, а также специфике конкретной страны или региона.
Тестирование локализации — один из видов контроля качества, который проводится во время разработки продукта. Этот тип тестирования помогает найти баги или ошибки перевода в локализованной версии до того, как конечный продукт попадет к пользователю. Цель тестирования — поиск и устранение ошибок в различных локализованных версиях продукта, предназначенных для разных рынков и локалей.
Важно отметить, что локализация — это не просто перевод на несколько языков, а локализационное и лингвистическое тестирование — не одно и то же. Чем же тестирование локализации отличается от лингвистического? Лингвистическое тестирование в основном состоит из проверки орфографических, грамматических и стилистических ошибок. А тестирование локализации также включает проверку форматов времени и валюты, графических элементов, иконок, фотографий, цветовых схем и десятка других мельчайших деталей.
Почему локализационное тестирование так важно?
Главная задача тестирования заключается в том, чтобы продукт выглядел так, как будто изначально был создан на языке целевой аудитории и полностью соответствовал культурным и региональным особенностям.
Локализация повышает лояльность клиентов к вашему бренду. Вот конкретные цифры: около 72,1% пользователей Интернета предпочитают делать покупки на сайтах на своем родном языке. Даже те, кто хорошо владеет английским, по-прежнему предпочитают просматривать веб-страницы на своем родном языке.
Тестирование локализации обеспечивает высокое качество приложений и сайтов на глобальном рынке. Давайте представим такую ситуацию: вы создали приложение и планируете выпустить его английскую, русскую и немецкую версии. Вы наняли лучших переводчиков, поэтому на 100% уверены в правильности орфографии и грамматики. Но внезапно вы обнаружили, что длина немецких строк превышает лимит символов для некоторых кнопок в приложении или форматы времени и даты на сайте не соответствуют региону. Тестирование локализации как раз и существует для того, чтобы не допустить подобные ситуации, ведь с переводным контентом проблемы могут возникнуть даже в случае, когда тексты грамматически правильные. Если вы хотите, чтобы ваше приложение или сайт выглядели нативными, уделяйте должное внимание контексту и тонкостям местной культуры.
На что следует обратить внимание во время тестирования локализации?
Тестирование локализации — это далеко не только проверка орфографии, грамматики и корректности перевода. Чтобы ничего не упустить в этом процессе, мы сделали чек-лист самых важных вещей. Итак, приступим.
Подготовительный этап
Чтобы тестирование локализации прошло гладко, к нему нужно подготовиться.
- Подготовьте для тестировщиков необходимую документацию и все сведения о сайте или продукте, которые смогут пригодиться.
- Создайте глоссарий и память переводов, чтобы помочь тестировщикам правильно истолковать используемые термины.
- Если приложение или сайт уже переводились раньше, приложите предыдущие версии в целях ознакомления. А ещё можно воспользоваться специализированными сервисами или базами данных для хранения всех версий перевода и организовать к ним доступ.
- Создайте трекер багов — документ или платформу, где вы будете фиксировать все баги, найденные во время тестирования локализации. Так проще контролировать исправление ошибок и общаться с остальными членами команды.
Проверка региональных и культурных особенностей
Это очень важный этап в тестировании локализации. Вам понадобятся скриншоты либо локализованная сборка приложения. Нужно проверить следующее:
- Соответствие формата даты и времени выбранному региону.
- Форматы для телефонных номеров и адресов.
- Цветовые схемы (это важно, так как один и тот же цвет может иметь разные значения в различных культурах). Например, белый цвет символизирует удачу в Западных странах, но в азиатской культуре он ассоциируется с трауром.
- Соответствие названий продуктов региональным стандартам.
- Формат валюты.
- Единицы измерения.
Лингвистическая проверка
На этом этапе проверяются языковые особенности. Нужно убедиться в том, что:
- На всех страницах сайта или экранах приложения используется одинаковая терминология.
- Отсутствуют грамматические ошибки.
- Отсутствуют орфографические ошибки.
- Соблюдены правила пунктуации.
- Используется правильное направление текста (справа налево или слева направо).
- Указаны правильные названия торговых марок, городов, мест, должностей и прочее.
Пользовательский интерфейс или внешний вид
Это нужно для того, чтобы ваш программный продукт смотрелся безукоризненно на любом языке. Обязательно удостоверьтесь в следующем:
- Все текстовые надписи на картинках локализованы.
- Макет языковых версий совпадает с оригиналом.
- Переносы и разрывы строк на страницах/экранах размещены правильно.
- Диалоги, всплывающие окна и уведомления отображаются корректно.
- Длина строк не превышает существующие ограничения и текст отображается правильно (иногда текст перевода длиннее оригинала и не помещается на кнопках).
Пример
Команда Alconost столкнулась с одним таким случаем во время работы с DotEmu и их игрой Blazing Chrome. В испанской версии количество символов в переводе текста кнопок превосходило ограничения для них. Слово «Далее» было слишком длинным на испанском: «Siguiente». Команда Alconost обнаружила эту ошибку во время тестирования локализации и предложила заменить «Siguiente» на «Seguir» для корректного отображения в интерфейсе. Именно благодаря обнаружению подобных проблем и их устранению интерфейс программного продукта и эффективность взаимодействия с пользователем улучшаются.

Функциональность
Это один из завершающих и важнейших этапов, когда нужно проверить правильно ли работает локализованное приложение. Советуем обратить внимание на следующее:
- Функционал локализованного приложения или сайта.
- Гиперссылки (убедитесь, что они работают во всех языковых версиях, легальны для указанного региона и не будут блокироваться местными или региональными файрволами).
- Работу вводных функций.
- Поддержку специальных символов для различных локалей и языков.
- Работу сочетаний клавиш.
- Функцию сортировки списков.
- Поддержку различных шрифтов.
- Поддержку различных разделителей формата.
Какие трудности могут возникнуть во время тестирования локализации?
Процесс тестирования локализации сопровождается своими проблемами и «подводными камнями», и лучше знать о них заранее. Ведь даже известная поговорка гласит: «предупрежден — значит вооружен».
Одна из главных сложностей — это недостаточное знание целевого языка. Естественно, знать все языки мира невозможно. Но есть компании по локализации, интернационализации и переводу. Например, Alconost предлагает своим клиентам полный спектр услуг по локализационному тестированию и оценке качества. Локализованные тексты всегда дополнительно проверяются переводчиками-носителями языка, которые также имеют большой опыт тестирования локализации. И можно быть увереным на 99,99%, что все региональные особенности будут учтены.
Еще один момент, которой может существенно осложнить тестирование локализации, — это плохое знание самого продукта. Это часто становится проблемой, если продукт нишевый. Агентства по локализации обычно имеют опыт работы в различных областях и знают, что команде необходимо заранее изучить продукт и задать клиенту все необходимые вопросы, чтобы полностью понять смысл продукта.
Также нужно учитывать, что тестирование локализации может быть довольно долгим процессом, так как на изучение особенностей различных регионов нужно время. Чтобы упростить этот процесс и уложиться в сроки, советуем интегрировать этап контроля качества локализации в жизненный цикл разработки. Сделайте процесс тестирования локализации непрерывным: переводите новые строки, как только они появляются, и сразу же тестируйте. Если планировать тестирование локализации заранее, это поможет вовремя делать релиз продукта.
И последнее, но не менее важное: компании часто забывают создать документ или аккаунт на облачной платформе для трекинга всех багов во время тестирования локализации. Без этого можно в итоге «потерять» часть ошибок или, хуже того, забыть их исправить. Поэтому нужен четкий механизм для хранения записей об обнаружении и устранении ошибок.
Нужна помощь с локализацией / переводом? — Мы в Alconost всегда рады помочь!
О нас
Alconost профессионально занимается локализацией игр, приложений и сайтов на более 70 языков. Лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджмент проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем видеоролики.
→ Подробнее
В этой статье мы расскажем о том, что делает QA-специалист, когда он находит тот или иной баг. Также рассмотрим, какие бывают дефекты и с чем их «едят».
Основные термины:
Дефект (или баг) — изъян в компоненте или системе, который может привести компонент или систему к невозможности выполнить требуемую функцию. Дефект, обнаруженный во время выполнения, может привести к отказам компонента или системы. Например: невозможно сохранить данные после заполнения анкеты.
Ошибка — действие человека, которое может привести к неправильному результату. Например: ввод букв в поле для ввода даты (должны приниматься только цифры) с последующим сохранением данных.
Отказ (failure) — отклонение компонента или системы от ожидаемого результата, выполнения, эксплуатации. Например: при переходе на следующую страницу анкеты данные предыдущей страницы затираются.
Классификация багов
- Функциональные дефекты — в этом случае приложение функционально работает не так, как задумано. Например:
— не сохраняются изменения данных в профиле;
— не работает добавление комментария;
— не работает удаление товара из корзины;
— не работает поиск.
- Визуальные дефекты — в этом случае приложение выглядит не так, как задумано.
— текст вылезает за границы поля;
— элемент управления сайтом наслаивается на нижестоящий элемент;
— не отображается картинка.
- Логические дефекты — в этом случае приложение работает неправильно с точки зрения логики.
— можно поставить дату рождения «из будущего», а также несуществующие даты — 31 февраля, 32 декабря и т.п.;
— можно сделать заказ, не указав адрес доставки;
— логика поиска работает неправильно.
- Дефекты контента
— орфографические и пунктуационные ошибки;
— картинка товара не соответствует карточке товара;
— конвертация валют идет по неправильному курсу (калькулятор считает правильно, но при программировании указан неверный курс).
- Дефекты удобства использования — в этом случае приложение неудобно в использовании.
— отсутствие подсветки или уведомления об ошибке при некорректно заполненных полях формы;
— сброс всех данных при ошибке заполнения регистрационной формы;
— перегруженный интерфейс.
- Дефекты безопасности — в этом случае могут быть затронуты пользовательские данные, есть риск падения системы и т.п.
— можно получить логин, пароль в результате использования SQL-инъекций;
— неограниченное время жизни сессии после авторизации.
Итак, мы рассмотрели типы и виды дефектов. Теперь расскажем о том, как их документировать.

Документирование ошибок
Отчет об ошибке (Bug Report) — это документ, описывающий ситуацию или последовательность действий, приведшую к некорректной работе объекта тестирования, с указанием причин и ожидаемого результата.
«Следующий этап заключается в документировании ошибок», — могли бы подумать вы, но оказались бы неправы.
Нельзя просто взять и задокументировать найденный дефект. Прежде всего, важно выполнить локализацию.
Например, если дефект может затрагивать другие части системы, то это обязательно нужно отобразить в баг-репорте, предварительно проверив эту гипотезу. Также необходимо очень подробно описать все условия и шаги, чтобы разработчик смог этот баг проверить и в него поверить.
Как же искать ошибки в системе таким образом, чтобы разработчикам было предельно понятно, откуда эти дефекты взялись и как их исправлять? Следует придерживаться определенного плана действий, который мы опишем далее.
Перепроверка дефекта
Нужно проверить себя еще раз: воспроизвести баг снова при тех же условиях. Если ошибка не повторилась при очередном тестировании, то нужно разобраться, точно ли были соблюдены все действия и шаги воспроизведения, приведшие к этому результату. Возможно, дефект появляется только при первоначальной загрузке системы (при первом использовании). Для того, чтобы более точно определить условия воспроизведения ошибки, необходимо эту ошибку локализовать.
Локализация дефекта
Чтобы локализовать баг, необходимо собрать максимальное количество информации о его воспроизведении:
- Выявить причины возникновения дефекта
Например, не проходит восстановление пароля. Необходимо выявить, откуда приходит запрос на сервер в неверном формате — от backend либо frontend.
- Проанализировать возможность влияния найденного дефекта на другие области
Например, в одной из форм, которую редко используют, возникает ошибка при нажатии на кнопку «Редактировать». Если в качестве временного варианта решения проблемы скрыть кнопку, это может повлиять на аналогичную форму в другом окне/вкладке, к которой пользователи обращаются чаще. Для качественного анализа необходимо знать, как работает приложение и какие зависимости могут быть между его частями.
- Отклонение от ожидаемого результата
Нужно проверить, соответствует ли результат тестирования ожидаемому результату. Справиться с этой задачей помогает техническое задание (в частности, требования к продукту), где должна быть задокументирована информация о тестируемом ПО и его функционировании. Пропускать этот шаг при тестировании не следует: если специалист недостаточно опытен, не зная требований, он может ошибаться и неправильно понимать, что относится к багам, а что нет. Внимательное изучение документации позволяет избежать таких ошибок.
- Исследовать окружение
Необходимо воспроизвести баг в разных операционных системах (iOS, Android, Windows и т.д.) и браузерах (Google Chrome, Mozilla, Internet Explorer и др.). При этом нужно проверить требования к продукту, чтобы выяснить, какие системы должны поддерживаться. Некоторые приложения работают только в определенных ОС или браузерах, поэтому проверять другие варианты не нужно.
- Проверить на разных устройствах
Например, desktop-приложение предназначено для использования на компьютерах, поэтому зачастую нет необходимости тестировать его на мобильных устройствах. Для смартфонов в идеале должна быть разработана отдельная мобильная версия, которую, в свою очередь, нет смысла тестировать на компьютерах. Кроме того, есть web-приложения, которые могут работать и на компьютерах, и на мобильных устройствах, а тестировать их нужно на всех типах устройств. Для тестирования можно использовать эмулятор той или иной среды, но в рамках статьи мы не будем затрагивать этот вопрос.
Мобильную версию приложения нужно тестировать на нескольких устройствах с разной диагональю экрана. При этом можно руководствоваться требованиями к ПО, в которых должно быть указано, с какими устройствами это ПО совместимо.
- Проверить в разных версиях ПО
Для того, чтобы не запутаться в реализованных задачах, в разработке используют версионность ПО. Иногда тот или иной баг воспроизводится в одной версии продукта, но не воспроизводится в другой. Этот атрибут обязательно необходимо указывать в баг-репорте, чтобы программист понимал, в какой ветке нужно искать проблему.
- Проанализировать ресурсы системы
Возможно, дефект был найден при нехватке внутренней или оперативной памяти устройства. В таком случае баг может воспроизводиться на идентичных устройствах по-разному.
Для того, чтобы оптимизировать сроки тестирования, мы рекомендуем использовать техники тест-дизайна.
Фиксирование доказательств
Доказательства воспроизведения бага нужно фиксировать при помощи логов, скринов или записи экрана.
- Логи (лог-файлы или журнал) — это файлы, содержащие системную информацию работы сервера или компьютера, в них хранят информацию об определенных действиях пользователя или программы. Опытному разработчику бывает достаточно посмотреть в логи, чтобы понять, в чем заключается ошибка. Обычно логи прикрепляют к баг-репорту в виде .txt-файла.
Live-логирование – это снятие системных логов в режиме реального времени. Для этого можно использовать следующие программы: Fiddler, Visual Studio для Windows, iTools, Xcode для iOS, Android Debug Monitor, Android Studio для Android и др.
- Скрин (снимок) экрана. При ошибках в интерфейсе снимок помогает быстрее разобраться в проблеме. Программ для снятия скриншотов очень много, каждый QA-специалист может использовать те, которые ему наиболее удобны: Jing, ShareX, Lightshot и др.
- Скринкаст (англ. screen – экран, broadcasting – трансляция) – это запись видеоизображения с экрана компьютера или другого цифрового устройства. Это один из самых эффективных способов поделиться тем, что происходит на экране монитора. Таким способом QA-специалисту легко наглядно показать ошибки в работе любого программного продукта. Сделать запись с экрана помогут незаменимые инструменты любого QA-специалиста: Snagit, Monosnap, Movavi Screen Capture, Jing, Reflector, ADB Shell Screenrecord, AZ Screen Recorder и др.
- Рекордер действий. Программные средства дают возможность воспроизвести все записанные движения мышки и действия, производимые на клавиатуре компьютера. Примеры программ – Advanced Key and Mouse Recorder для desktop-платформ.

Оформление баг-репорта
Все найденные дефекты обязательно нужно документировать, чтобы каждый задействованный на проекте специалист мог получить инструкции по воспроизведению обнаруженного дефекта и понять, насколько это критично. Если в команде принято устно передавать разработчику информацию о найденных дефектах, есть риск упустить что-то из вида.
Дефект, который не задокументирован – не найден!
Когда вся необходимая информация собрана, а баг локализован, можно приступать к оформлению баг-репорта в таск-трекере. Чем точнее описание бага, тем меньше времени нужно для его исправления. Список атрибутов для каждого проекта индивидуален, но некоторые из них – например, шаги воспроизведения, ожидаемый результат, фактический результат – присутствуют практически всегда.
Атрибуты баг-репорта:
1. Название
Баг должен быть описан кратко и ёмко, иметь понятное название. Это поможет разработчику разобраться в сути ошибки и в том, может ли он взять этот случай в работу, если занимается соответствующим разделом системы. Также это позволяет упростить подключение новых специалистов на проект, особенно если разработка ведется много лет подряд, а запоминать баги и отслеживать их в таск-трекере становится все сложнее. Название проекта можно составлять по принципу «Где? Что? Когда?» или «Что? Где? Когда?», в зависимости от внутренних правил команды.
Например:
Где происходит? — В карточке клиента (в каком разделе системы).
Что именно происходит? — Не сохраняются данные.
Когда происходит? — При сохранении изменений.
2. Проект (название проекта)
3. Компонент приложения
В какой части функциональности тестируемого продукта найден баг.
4. Номер версии
Версия продукта, ветка разработки, в которой воспроизводится ошибка.
5. Критичность
Этот атрибут показывает влияние дефекта на функциональность системы, например:
· Blocker — дефект, блокирующий использование системы.
· Critical — ошибка, которая нарушает основную бизнес-логику работы системы.
· Major — ошибка, которая нарушает работу определенной функции, но не всей системы.
· Minor — незначительная ошибка, не нарушающая бизнес-логику приложения, например, ошибка пользовательского интерфейса.
· Trivial — малозаметная, неочевидная ошибка. Это может быть опечатка, неправильная иконка и т.п.
6. Приоритет
Приоритет определяет, насколько срочно нужно исправить ошибку. Обычно выделяют следующие виды приоритетов:
High — ошибка должна быть исправлена как можно скорее, является критичной для проекта.
Medium — ошибка должна быть исправлена, но её наличие не является критичным для проекта.
Low — ошибка должна быть исправлена, но не требует срочного решения.
7. Статус
Статус указывает стадию жизненного цикла бага, взят он в работу или уже решен. Примеры: to do, in progress, in testing (on QA), done. В зависимости от особенностей проекта возможны дополнительные статусы (например, аналитика).
8. Автор баг-репорта
9. На кого назначен
Баг-репорт отправляют тимлиду проекта или разработчику, который будет заниматься исправлением дефекта, в зависимости от принятых в команде договоренностей.
10. Окружение
Где найден баг: операционная система, наименование и версия браузера.
11. Предусловие (если необходимо)
Необходимо для описания действий, которые предшествовали воспроизведению бага. Например, клиент авторизован в системе, создана заявка с параметрами ABC и т.д. Баг-репорт может не содержать предусловие, но иногда оно бывает необходимо для того, чтобы проще описать шаги воспроизведения.
12. Шаги воспроизведения
Один из самых важных атрибутов — описание шагов, которые привели к нахождению бага. Оптимально использовать 5-7 понятных и кратких шагов для описания бага, например:
1. Открыть (…)
2. Кликнуть (…)
3. Ввести в поле А значение N1
4. Ввести в поле B значение N2
5. Кликнуть кнопку «Calculate»
13. Фактический результат
Что произошло после воспроизведения указанных выше шагов.
14. Ожидаемый результат
Что должно произойти после воспроизведения шагов тестирования, согласно требованиям.
15. Прикрепленный файл
Логи, скриншоты, видеозапись экрана — всё, что поможет разработчику понять суть ошибки и исправить ее.
После составления баг-репорта обязательно нужно проверить его, чтобы избежать ошибок или опечаток.
Локализация и оформление багов — необходимые составляющие работы QA-специалиста с программным продуктом. Приглашаем подробнее ознакомиться с услугами тестирования и обеспечения качества в SimbirSoft.
Можно предложить следующую методику отладки программного обеспечения, написанного на универсальных языках программирования для выполнения в операционных системах MS DOS и Win32:
1 этап — изучение проявления ошибки — если выдано какое-либо сообщение или выданы неправильные или неполные результаты, то необходимо их изучить и попытаться понять, какая ошибка могла так проявиться. При этом используют индуктивные и дедуктивные методы отладки. В результате выдвигают версии о характере ошибки, которые необходимо проверить. Для этого можно применить методы и средства получения дополнительной информации об ошибке.
Если ошибка не найдена или система просто «зависла», переходят ко второму этапу.
2 этап — локализация ошибки — определение конкретного фрагмента, при выполнении которого произошло отклонение от предполагаемого вычислительного процесса. Локализация может выполняться:
•путем отсечения частей программы, причем, если при отсечении некоторой части программы ошибка пропадает, то это может означать как то, что ошибка связана с этой частью, так и то, что внесенное изменение изменило проявление ошибки;
•с использованием отладочных средств, позволяющих выполнить интересующих нас фрагмент программы в пошаговом режиме и получить дополнительную информацию о месте проявления и характере ошибки, например, уточнить содержимое указанных переменных.
При этом если были получены неправильные результаты, то в пошаговом режиме проверяют ключевые точки процесса формирования данного результата.
Как подчеркивалось выше, ошибка не обязательно допущена в том месте, где она проявилась. Если в конкретном случае это так, то переходят к следующему этапу.
3 этап — определение причины ошибки — изучение результатов второго этапа и формирование версий возможных причин ошибки. Эти версии необходимо проверить, возможно, используя отладочные средства для просмотра последовательности операторов или значений переменных.
4 этап — исправление ошибки — внесение соответствующих изменений во все операторы, совместное выполнение которых привело к ошибке.
5 этап — повторное тестирование — повторение всех тестов с начала, так как при исправлении обнаруженных ошибок часто вносят в программу новые.
Следует иметь в виду, что процесс отладки можно существенно упростить, если следовать основным рекомендациям структурного подхода к программированию:
•программу наращивать «сверху-вниз», от интерфейса к обрабатывающим подпрограммам, тестируя ее по ходу добавления подпрограмм;
•выводить пользователю вводимые им данные для контроля и проверять их на допустимость сразу после ввода;
•предусматривать вывод основных данных во всех узловых точках алгоритма (ветвлениях, вызовах подпрограмм).
Кроме того, следует более тщательно проверять фрагменты программного обеспечения, где уже были обнаружены ошибки, так как вероятность ошибок в этих местах по статистике выше. Это вызвано следующими причинами. Во-первых, ошибки чаще допускают в сложных местах или в тех случаях, если спецификации на реализуемые операции недостаточно проработаны. Вовторых, ошибки могут быть результатом того, что программист устал, отвлекся или плохо себя чувствует. В-третьих, как уже упоминалось выше, ошибки часто появляются в результате исправления уже найденных ошибок.
Возвращаясь к рис. 10.2, можно отметить, что проще всего обычно искать ошибки определения данных и ошибки накопления погрешностей: их причины локализованы в месте проявления. Логические ошибки искать существенно сложнее. Причем обнаружение ошибок проектирования требует возврата на предыдущие этапы и внесения соответствующих изменений в проект. Ошибки кодирования бывают как простые, например, использование неинициализированной переменной, так и очень сложные, например, ошибки, связанные с затиранием памяти.
Затиранием памяти называют ошибки, приводящие к тому, что в результате записи некоторой информации не на свое место в оперативной памяти, затираются фрагменты данных или даже команд программы. Ошибки подобного рода обычно вызывают появление сообщения об ошибке. Поэтому определить фрагмент, при выполнении которого ошибка проявляется, несложно. А вот определение фрагмента программы, который затирает память — сложная задача, причем, чем длиннее программа, тем сложнее искать ошибки такого рода. Именно в этом случае часто прибегают к удалению из программы частей, хотя это и не обеспечивает однозначного ответа на вопрос, в какой из частей программы находится ошибка. Эффективнее попытаться определить операторы, которые записывают данные в память не по имени, а по адресу, и последовательно их проверить. Особое внимание при этом следует обращать на корректное распределение памяти под данные.
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
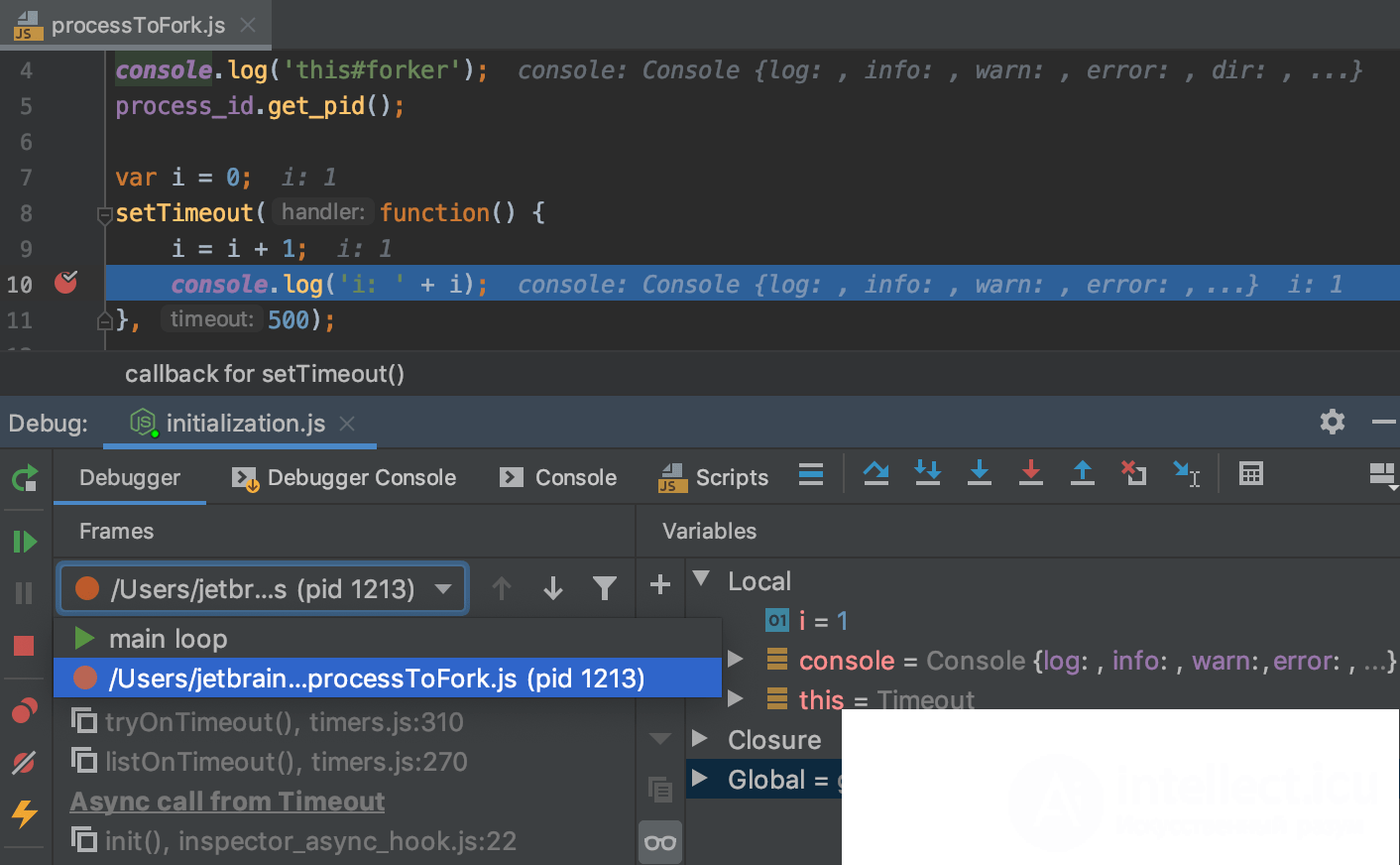 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
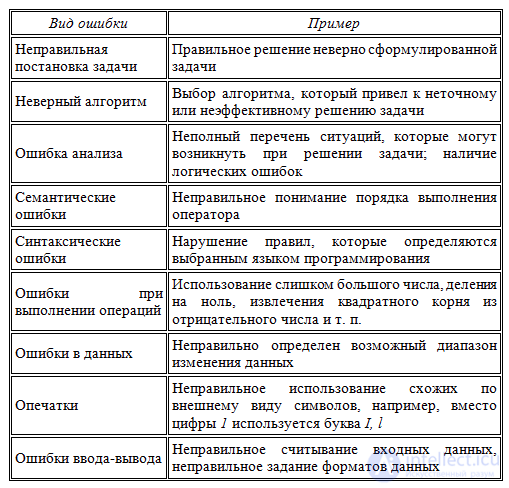
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
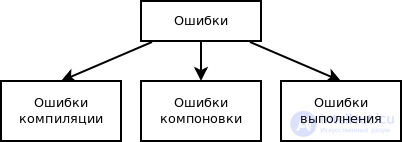
Классификация ошибок по этапу обработки программы
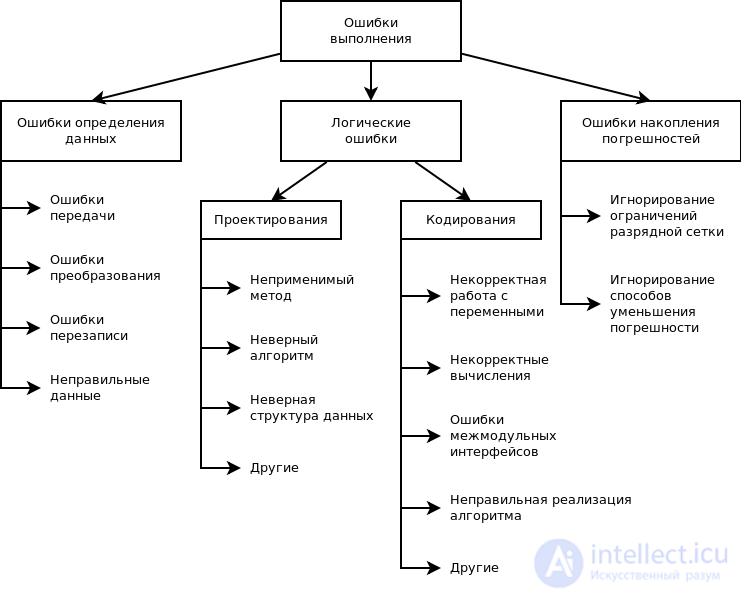
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
 Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
См. также
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
Отладка и локализация ошибок
1. Отладка программы.
Отладка, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
прогоняем программу и получаем результаты;
сверяем результаты с эталонными и анализируем несоответствие;
выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3. Принципы отладки
Принципы локализации ошибок:
Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
Там, где найдена одна ошибка, возможно, есть и другие.
Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
Использование дампа (распечатки) памяти.
Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
Использование отладочной печати в тексте программы — произвольно и в большом количестве.
Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.
Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
использовать отладочную печать в небольших количества и «по делу»;
оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
2009-03-06 • Просмотров [ 11719 ]