Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
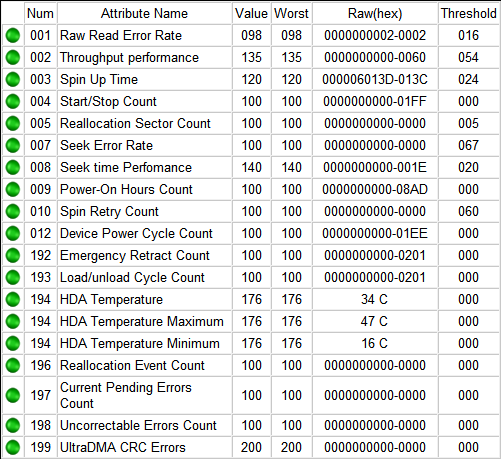
S.M.A.R.T. в HDDScan 3.3
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 10 | 11 | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | BD | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | BF | С0 | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 | СА | CB | DC | F0 | FE |
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
Атрибут: 01 Raw Read Error Rate
| Тип | текущий, может быть накапливающим для WD и старых Hitachi |
| Описание | содержит частоту возникновения ошибок при чтении с пластин |
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
| Тип | текущий |
| Описание | содержит значение средней производительности диска и измеряется в каких-то «попугаях». Обычно его ненулевое значение отмечается на винчестерах Hitachi. На них он может изменяться после изменения параметров ААМ, а может и сам по себе по неизвестному алгоритму |
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
| Тип | текущий |
| Описание | содержит время, за которое шпиндель диска в последний раз разогнался из состояния покоя до номинальной скорости. Может содержать два значения — последнее и, например, минимальное время раскрутки. Может измеряться в миллисекундах, десятках миллисекунд и т. п. — это зависит от производителя и модели диска |
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
| Тип | накапливающий |
| Описание | содержит количество раз включения диска. Бывает ненулевым на только что купленном диске, находившемся в запаянной упаковке, что может говорить о тестировании диска на заводе. Или ещё о чём-то, мне не известном  |
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
| Тип | накапливающий |
| Описание | содержит количество секторов, переназначенных винчестером в резервную область. Практически ключевой параметр в оценке состояния |
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение, а используемый вместо повреждённого сектор — переназначенным. Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при позиционировании блока магнитных головок (БМГ) |
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
| Тип | текущий |
| Описание | содержит среднюю производительность операций позиционирования головок, измеряется в «попугаях». Как и параметр 02 Throughput Performance, ненулевое значение обычно отмечается на дисках Hitachi и может изменяться после изменения параметров ААМ, а может и само по себе по неизвестному алгоритму |
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
| Тип | накапливающий |
| Описание | содержит количество часов, в течение которых винчестер был включён |
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
| Тип | накапливающий |
| Описание | содержит количество повторов запуска шпинделя, если первая попытка оказалась неудачной |
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Тип | накапливающий |
| Описание | содержит количество повторных попыток сброса накопителя (установки БМГ на нулевую дорожку) при неудачной первой попытке |
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов «включение-отключение» диска |
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
| Тип | накапливающий |
| Описание | содержит количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута |
Не говорит о здоровье накопителя.
Атрибут: 184 (B8) End-to-End Error
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче данных через кэш винчестера |
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Тип | накапливающий |
| Описание | содержит количество секторов, которые были признаны кандидатами на переназначение (см. атрибут 197) за всю историю жизни диска. Причём если сектор становится кандидатом повторно, значение атрибута тоже увеличивается |
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
| Тип | накапливающий |
| Описание | содержит количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика |
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
| Тип | накапливающий |
| Описание | содержит количество зафиксированных случаев записи при высоте полета головки выше рассчитанной — скорее всего, из-за внешних воздействий, например вибрации |
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
| Тип | текущий |
| Описание | содержит температуру винчестера для дисков Hitachi, Samsung, WD и значение «100 − [RAW-значение атрибута 194]» для Seagate |
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Тип | накапливающий |
| Описание | содержит количество критических ускорений, зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. |
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
| Тип | накапливающий |
| Описание | для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок БМГ диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т. п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi) |
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов парковки/распарковки БМГ. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (столь любимая, например, компанией Western Digital): если его содержимое превосходит (обычно — многократно) содержимое атрибута 09 — счётчик отработанных часов, — то парковка включена |
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
| Тип | текущий/накапливающий |
| Описание | содержит текущую температуру диска. Температура считывается с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера |
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
| Тип | накапливающий |
| Описание | содержит количество ошибок, которые были скорректированы аппаратными средствами ECC диска |
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
| Тип | накапливающий |
| Описание | содержит количество операций переназначения секторов |
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
| Тип | текущий |
| Описание | содержит количество секторов-кандидатов на переназначение в резервную область |
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.
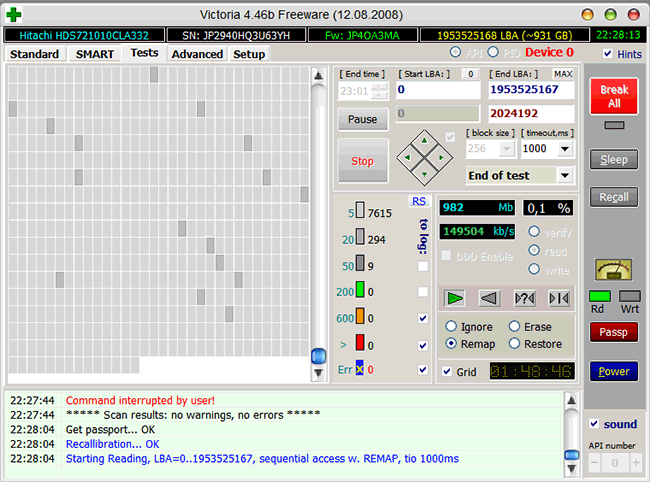
Идёт последовательное чтение с ремапом в Victoria 4.46b
В случае неудачи чтения как с remap, так и с Advanced remap, стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!
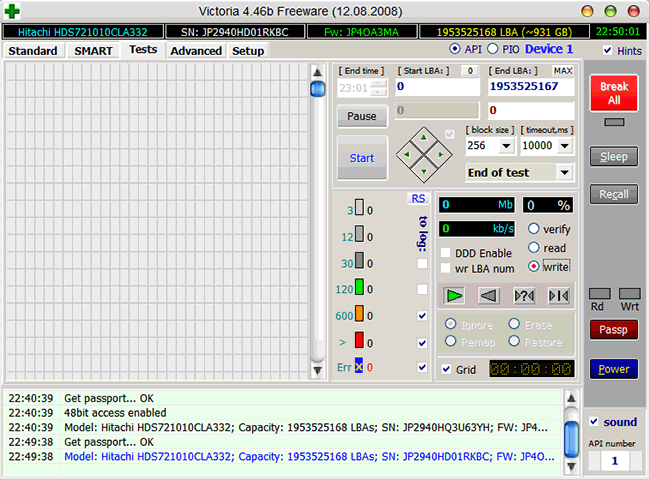
Запуск последовательной записи в Victoria 4.46b
Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Тип | текущий |
| Описание | означает то же самое, что и атрибут 197, но отличие в том, что данный атрибут содержит количество секторов-кандидатов, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой |
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
Атрибут: 199 (С7) UltraDMA CRC Error Count
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска |
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при записи |
Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать «умирающие» головки.
Атрибут: 201 (С9) Soft Read Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок чтения, произошедших по вине программного обеспечения |
Влияние на здоровье неизвестно.
Атрибут: 202 (СА) Data Address Mark Error
| Тип | неизвестно |
| Описание | содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо |
Атрибут: 203 (CB) Run Out Cancel
| Тип | текущий |
| Описание | содержит количество ошибок ECC |
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
| Тип | текущий |
| Описание | содержит измеренный в неизвестных единицах сдвиг пластин диска относительно оси шпинделя |
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
| Тип | накапливающий |
| Описание | содержит время, затраченное на позиционирование БМГ. Счётчик может содержать несколько значений в одном поле |
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
| Тип | накапливающий |
| Описание | содержит зафиксированное электроникой количество ускорений свободного падения диска, которым он подвергался, т. е., проще говоря, показывает, сколько раз диск падал |
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения:
- атрибутов 01, 07, 195 — вызывают подозрения в «болезни» у некоторых моделей дисков;
- атрибутов 10, 11, 188, 196, 199, 202 — вызывают подозрения у всех дисков;
- и, наконец, атрибутов 05, 184, 187, 197, 198, 200 — прямо говорят о неполадках.
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
![]()
Атрибут 01 в Victoria 4.46b
А так выглядит он же в «правильной» HDDScan 3.3:
![]()
Атрибут 01 в HDDScan 3.3
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина.
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:
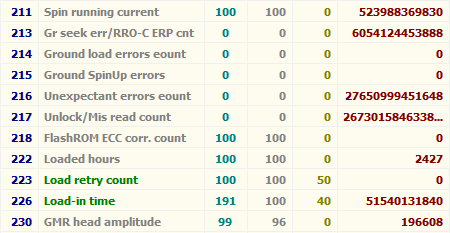
«Страшные» значения в Victoria 4.46b
Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах. При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (работает в Windows, бесплатная), CrystalDiskInfo (Windows, бесплатная), Hard Disk Sentinel (платная для Windows, бесплатная для DOS), HD Tune (Windows, платная, есть бесплатная старая версия).
И наконец, мощнейшие программы для тестирования: Victoria (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).
Одной из главных проблем в устранении ошибок «синего экрана смерти» является трудность установления их подлинных причин. Одно и то же описание и один и тот же код ошибки может указывать на разные причины. Примером такой трудной для диагностики неполадки является достаточно распространенная ошибка WHEA UNCORRECTABLE ERROR с кодом 0x0000124, которая может быть вызвана сбоями в работе оперативной памяти, жестких дисков, драйверов, неисправностями блока питания и ряда других аппаратных компонентов компьютера.
Поэтому, если вам доведется столкнуться с этой ошибкой, действовать придется последовательно перебирая все возможные решения. Во-первых, для начала следует мысленно воссоздать историю действий, которые вы выполняли на компьютере – это может дать подсказку, с чего начинать поиск причины. Например, если вы недавно обновили драйвер, пожалуй, стоит начать с отката/переустановки драйвера; если до этого наблюдались проблемы с жестким диском – необходимо заняться диагностикой диска и так далее.
Если никаких действий по обновлению ПО и установке новых компонентов не проводилось, попробуйте для начала откатить систему к ближайшей точке восстановления. Это простое решение может оказаться эффективным в тех случаях, когда ошибка была вызвана повреждением важных системных файлов и ключей реестра.
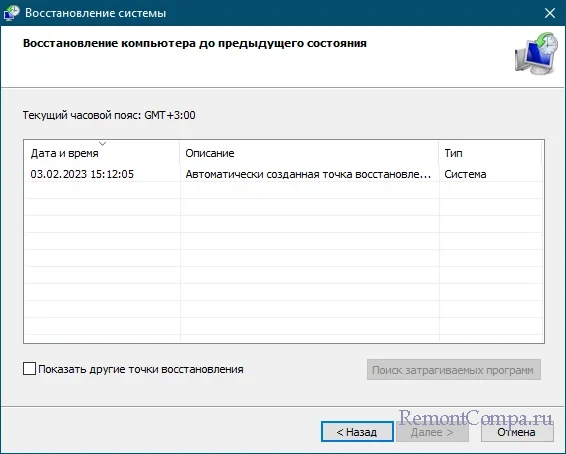
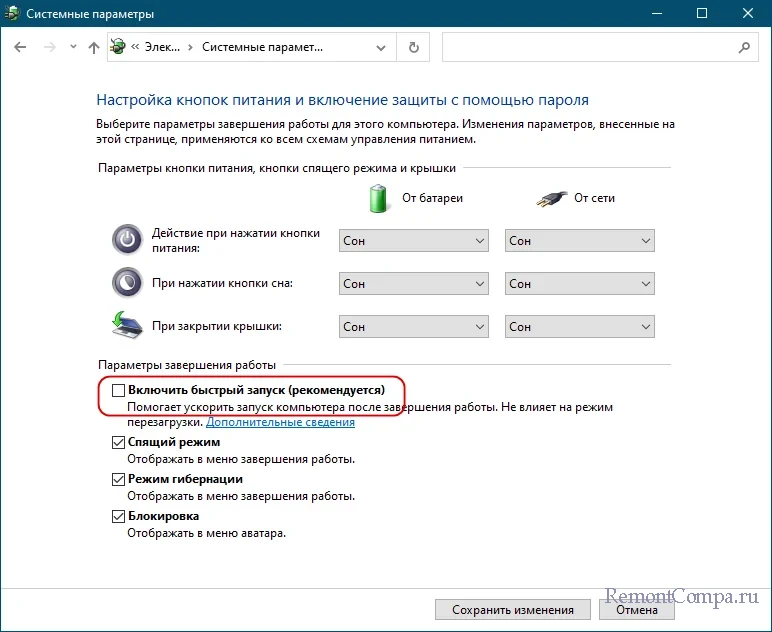
Если BSOD появляется при первом включении ПК, а при повторном включении или перезагрузке система запускается без ошибки, скорее всего, неправильно работает функция быстрого запуска. Отключите ее в настройках электропитания.
Так как ошибка WHEA UNCORRECTABLE ERROR часто указывает на проблемы с жестким диском, выполните диагностику последнего средствами штатной утилиты chkdsk. Для этого в запущенной от имени администратора командной строке или PowerShell необходимо выполнить команду chkdsk C:, где C – это буква раздела.
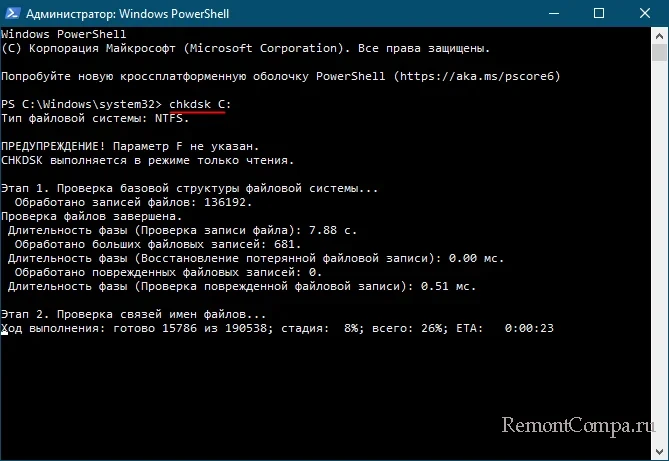
В случае обнаружения ошибок команду необходимо повторить, добавив параметры /f и /r, вот так: chkdsk C: /f /r. Такую проверку лучше всего проводить из-под загрузочной флешки или сняв и подключив жесткий диск к рабочему компьютеру. Вместо chkdsk для проверки диска на предмет bad-блоков можно использовать такую программу как Victoria.
На предмет ошибок следует проверить и оперативную память. Сделать это можно штатными средствами, выполнив команду mdsched.exe или более продвинутыми сторонними утилитами, например, memtest86+. В случае обнаружения ошибок, методом исключения нужно будет определить, какая именно планка памяти повреждена и заменить ее.
Если незадолго до возникновения проблем вы производили разгон процессора, оперативной памяти или видеокарты, отмените все внесенные в конфигурацию изменения. Рекомендуется также сбросить настройки BIOS/UEFI, если в них вносились какие-то изменения.
Вызывать ошибку может стороннее программное обеспечение, работающее в режиме ядра, например, антивирусы и драйвера. Также нельзя исключать, что ошибка WHEA UNCORRECTABLE ERROR могла быть вызвана содержащими баги системными обновлениями. В таких случаях рекомендуется удалить подозрительное программное обеспечения, выполнить откат к предыдущим версиям драйверов (если обновлялся драйвер).
Если имеется такая возможность, убедитесь в исправности блока питания и прочих комплектующих, в частности кабелей и разъемов, осмотрите материнскую плату на предмет наличия загрязнений, пыли, вздувшихся конденсаторов и подгоревших радиодеталей. Это минимум, что вы можете сделать, а вообще, полноценную диагностику аппаратуры лучше доверить квалифицированным специалистам.
Наконец, вы можете выполнить сброс или переустановку Windows и посмотреть, как поведет себя «чистая» система. Если ошибка не появится, скорее всего, проблема скрывалась где-то в программной части, в противном случае все внимание следуют уделить железу и конфигурации BIOS/UEFI.
Summary: The WHEA UNCORRECTABLE ERROR can lead to grave situations such as permanent data loss due to drive errors and file corruption caused by a sudden system crash. To recover your data in this scenario download Stellar Data Recovery Professional software to recover your lost data. Get the software now!

Contents
- What Causes WHEA_UNCORRECTABLE_ERROR
- Steps to Fix and Recover Data from WHEA_UNCORRECTABLE_ERROR
- Conclusion
WHEA_UNCORRECTABLE_ERROR is a fatal Blue Screen of Death (BSOD) error that occurs due to the failure of critical system hardware or software. While BSOD can occur due to various hardware errors, the WHEA UNCORRECTABLE ERROR generally happens due to a problem with the processor. Most importantly, the error indicates an imminent system or hardware failure and thus, requires immediate attention and fix.

A system that suffers from WHEA UNCORRECTABLE ERROR Blue Screen of Death error may fail to boot or crash again, as it restarts.
What Causes WHEA_UNCORRECTABLE_ERROR
The WHEA UNCORRECTABLE ERROR may occur due to various reasons such as:
- Faulty Hard drive, RAM, Graphics Card, or Processor.
- Low CPU Voltage.
- Overheating CPU due to Over-Clocking or Inefficient Cooling System.
- Corrupt System File(s).
- Damaged Device Drivers.
Steps to Fix and Recover Data from WHEA_UNCORRECTABLE_ERROR
Step 1: Check Hard Drive SMART Status
If the system fails to boot after BSOD, disconnect the hard drive from your PC or laptop and connect it to a different working Windows PC via SATA connector or by using a SATA to USB converter cable.
Then download and install Stellar Data Recovery Professional software. It’s free to download. Launch the software and click ‘Monitor Drive’ under the ‘Waffle icon’.

Now check your hard disk health status. For deeper insights, click ‘SMART Status’ button on the left pane.

This will display all critical SMART parameters and their attributes. If you see a warning sign in SMART parameter(s), you should immediately back up your data.
To do so, you may manually copy each file from the drive and paste it in an external drive. Alternatively, you can also clone your failing drive with a new replacement drive. Cloning keeps the Windows OS, program files, and all other data intact including partitions.
Use the ‘Clone Disk’ option to clone your affected hard drive immediately.

After the clone, you can install the cloned drive and resume work on your laptop or PC – no need to re-install and re-configure Windows OS and software.
Step 2: Recover Lost Data
Close the ‘Drive Monitor’ utility and keep the drive connected to the system. Click ‘Recover Data’ and follow the instructions as mentioned in the following video:
Watch this video to recover deleted data from Windows PC with Stellar Data Recovery Professional
Step 3: Use Windows Blue Screen Troubleshooter
- In Windows 10, go to ‘Settings>Updates & Security>Troubleshoot’.
- Click on the ‘Blue Screen’ option and then click ‘Run the troubleshooter.’

- The troubleshooter identifies the issue and tries to fix the error, causing BSOD. It also provides you with additional steps to fix the error.
- Use suggestions and steps to fix the problem and restart the system. Then use your system for a while to observe if the BSOD screen issue is fixed.
Step 4: Disconnect USB Devices
Sometimes external USB devices can cause blue screen error.
A famous BSOD incident happened back in 1998 when Bill Gates was demonstrating ‘Plug and Play’ feature in Windows 98 Beta. As soon as the Scanner was connected to the PC, the system crashed and displayed a blue screen of death. Watch the video.
So try disconnecting USB devices or newly installed hardware component from the system. Then reboot and keep the system under observation for a while. Do not perform any critical task on such PC unless you are sure that the error has been resolved.
Step 5: Repair System Files
Run System File Checker (SFC) scan on your Windows PC, if it boots after the crash. The SFC scan checks system files for corruption and replaces a damaged or missing system file from the cache.
Follow these steps to run an SFC scan on a Windows PC:
- Open Command Prompt windows as an administrator
- Type the following command and then press ‘Enter.’
sfc /scannow

Step 6: Update Device Drivers
Corrupt, damaged, or outdated device drivers can also lead to various blue screen errors. Thus, regularly updating device drivers is as important as installing Windows updates.
To update drivers, you may use third-party software such as one from IObit®. Alternatively, you can open the Device Manager and update each device driver manually. All you have to do is follow these steps:
- In Device Manager, expand the device to see hardware information.
- Right-click on the hardware and choose ‘Update Driver.’

- Then click ‘Search automatically for updated driver software’ to let the system check and install a new device driver update.

- Alternatively, you may choose the second option and manually download and then install the drivers from the device manufacturer’s website.

Step 7: Disable Overclock Profile
Overclocking processor can significantly boost system performance. However, the overclocked system tends to crash and display BSOD such as WHEA UNCORRECTABLE ERROR BSOD more than a normal system.
The crash and BSOD may occur due to improperly configured overclocking, low voltage, and overheating CPU, because of overclocking.

So disable the overclocking profile from BIOS to fix this BSOD error. And instead of overclocking the CPU, buy a better processor for your system.
Step 8: Factory Reset BIOS Configuration
In case you are not able to disable Overclock Profile, reset BIOS configuration. Also, sometimes incorrect BIOS settings lead to system crash and BSOD. Thus, resetting BIOS settings to default can help you fix the ‘WHEA UNCORRECTABLE ERROR’.
To reset BIOS to default, visit your motherboard or system manufacturer’s support website to see instructions.
Step 9: Update BIOS
You may also check for BIOS update on your system or motherboard manufacturer’s support website. Updating BIOS resolves some critical errors that may cause the WHEA UNCORRECTABLE ERROR BSOD.
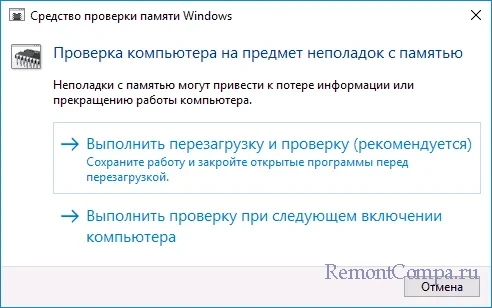
Step 10: Check RAM for Problems
To check for faulty RAM, use the Windows Memory Diagnostic tool.
- Press Windows + S and type memory diagnostic. Click on the ‘Windows Memory Diagnostic’ result to open the tool.

- Close all other program windows and save any open file. Then click ‘Restart now and check for problems (recommended)’.

After the scan, also inspect the RAM physically by opening the system case. You may swap the RAM port and check for any physical damage.
Alternatively, you may also use a MemTest86 RAM testing tool if your system fails to boot. The MemTest86 tool boots via USB drive.
Step 11: Inspect Cooling System
Overheating may also occur due to the inefficient or clogged cooling system. Inspect the cooling system and ventilation for proper functioning. Ensure all fans are working and CPU cooler is blowing away hot air.

Also, keep an adequate gap between the CPU heat exhaust and other critical components such as the hard drive to prevent drive errors and system failure, including BSOD error like WHEA UNCORRECTABLE ERROR.
Step 12: Replace Faulty Hardware or Buy New Machine
Finally, when nothing works and fixes the WHEA UNCORRECTABLE ERROR BSOD, go ahead, and purchase new hardware component. The damage could be on the motherboard, chipset, hard drive, graphics card, or processor due to overheating. In such a case, the only option you have is to replace the hardware with the new.
You can take the help of someone experienced in hardware replacement. They can help you find the faulty hardware and fix the error. In case it’s a laptop with a damaged processor, graphics card, or motherboard—buy a new one.
Conclusion
WHEA UNCORRECTABLE ERROR is a common BSOD error that may occur due to a faulty hardware component. However, the most common cause is low voltage to the processor and overheating CPU due to overclocking and inefficient cooling system.
A system crash and BSOD can cause grave situations such as system failure and permanent data loss. If the problem lies with the system drive, you should immediately clone it and backup all your data before the drive fails.
Follow the steps we explained in this guide to carefully recover files lost due to BSOD and fix WHEA UNCORRECTABLE ERROR. We have tried to list every possible cause with their fixes. However, in case we missed one, please let us know via comments down below.
About The Author
Satyeshu Kumar
Satyeshu is a Windows blogger and data recovery expert. He is having good technical knowledge and experience in Windows data recovery. He writes about latest technical tips, Windows issues and tutorials.
Best Selling Products

Stellar Data Recovery Premium
Stellar Data Recovery Premium for Window
Read More

Stellar Data Recovery Technician
Stellar Data Recovery Technician intelli
Read More

Stellar Data Recovery Toolkit
Stellar Data Recovery Toolkit is an adva
Read More

BitRaser File Eraser
BitRaser File Eraser is a 100% secure so
Read More
Gsmartcontrol gives errors («uncorrectable error in data»)
-
Thread starterWienna
-
Start dateMar 3, 2013
-
#1
smartctl 5.41 2011-06-09 r3365 [i686-linux-3.5.0-23-generic] (local build)
Copyright (C) 2002-11 by Bruce Allen, http://smartmontools.sourceforge.net=== START OF INFORMATION SECTION ===
Model Family: Hitachi Travelstar 5K320
Device Model: Hitachi HTS543232L9A300
Serial Number: 090205FB2406LEDBWJHC
LU WWN Device Id: 5 000cca 564d37ef0
Firmware Version: FB4OC40C
User Capacity: 320,072,933,376 bytes [320 GB]
Sector Size: 512 bytes logical/physical
Device is: In smartctl database [for details use: -P show]
ATA Version is: 8
ATA Standard is: ATA-8-ACS revision 3f
Local Time is: Sun Mar 3 23:17:04 2013 CET
SMART support is: Available — device has SMART capability.
SMART support is: Enabled=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSEDGeneral SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 120) The previous self-test completed having
the read element of the test failed.
Total time to complete Offline
data collection: ( 645) seconds.
Offline data collection
capabilities: (0x5b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
No Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 127) minutes.
SCT capabilities: (0x003d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000b 085 085 062 Pre-fail Always — 1573078
2 Throughput_Performance 0x0005 100 100 040 Pre-fail Offline — 0
3 Spin_Up_Time 0x0007 253 253 033 Pre-fail Always — 0
4 Start_Stop_Count 0x0012 099 099 000 Old_age Always — 3009
5 Reallocated_Sector_Ct 0x0033 087 087 005 Pre-fail Always — 0
7 Seek_Error_Rate 0x000b 100 100 067 Pre-fail Always — 0
8 Seek_Time_Performance 0x0005 100 100 040 Pre-fail Offline — 0
9 Power_On_Hours 0x0012 066 066 000 Old_age Always — 15321
10 Spin_Retry_Count 0x0013 100 100 060 Pre-fail Always — 0
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always — 2980
191 G-Sense_Error_Rate 0x000a 100 100 000 Old_age Always — 0
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always — 50
193 Load_Cycle_Count 0x0012 099 099 000 Old_age Always — 12214
194 Temperature_Celsius 0x0002 144 144 000 Old_age Always — 38 (Min/Max 8/49)
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always — 486
197 Current_Pending_Sector 0x0022 098 098 000 Old_age Always — 535
198 Offline_Uncorrectable 0x0008 100 100 000 Old_age Offline — 0
199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always — 0
223 Load_Retry_Count 0x000a 100 100 000 Old_age Always — 0SMART Error Log Version: 1
ATA Error Count: 5378 (device log contains only the most recent five errors)
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It «wraps» after 49.710 days.Error 5378 occurred at disk power-on lifetime: 15270 hours (636 days + 6 hours)
When the command that caused the error occurred, the device was active or idle.After command completion occurred, registers were:
ER ST SC SN CL CH DH
— — — — — — —
40 51 14 1b df 57 e0 Error: UNC 20 sectors at LBA = 0x0057df1b = 5758747Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
— — — — — — — — —————- ———————
25 ff 2f 00 df 57 e0 00 04:38:23.200 READ DMA EXT
25 ff 10 f0 de 57 e0 00 04:38:23.200 READ DMA EXT
25 ff 30 c0 de 57 e0 00 04:38:23.200 READ DMA EXT
25 ff 0f b1 de 57 e0 00 04:38:23.200 READ DMA EXT
25 ff 31 80 de 57 e0 00 04:38:23.200 READ DMA EXTError 5377 occurred at disk power-on lifetime: 15209 hours (633 days + 17 hours)
When the command that caused the error occurred, the device was active or idle.After command completion occurred, registers were:
ER ST SC SN CL CH DH
— — — — — — —
40 51 0a c6 0e a1 e1 Error: UNC 10 sectors at LBA = 0x01a10ec6 = 27332294Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
— — — — — — — — —————- ———————
25 ff 10 c0 0e a1 e0 00 00:03:22.000 READ DMA EXT
29 ff 10 c0 0e a1 e0 00 00:03:16.900 READ MULTIPLE EXT
25 ff 10 c0 0e a1 e0 00 00:03:12.800 READ DMA EXT
29 ff 10 c0 0e a1 e0 00 00:03:07.800 READ MULTIPLE EXT
25 ff 10 c0 0e a1 e0 00 00:03:03.800 READ DMA EXTError 5376 occurred at disk power-on lifetime: 15209 hours (633 days + 17 hours)
When the command that caused the error occurred, the device was active or idle.After command completion occurred, registers were:
ER ST SC SN CL CH DH
— — — — — — —
40 51 0a c6 0e a1 e1 Error: UNC at LBA = 0x01a10ec6 = 27332294Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
— — — — — — — — —————- ———————
29 ff 10 c0 0e a1 e0 00 00:03:16.900 READ MULTIPLE EXT
25 ff 10 c0 0e a1 e0 00 00:03:12.800 READ DMA EXT
29 ff 10 c0 0e a1 e0 00 00:03:07.800 READ MULTIPLE EXT
25 ff 10 c0 0e a1 e0 00 00:03:03.800 READ DMA EXT
29 ff 10 c0 0e a1 e0 00 00:02:58.700 READ MULTIPLE EXTError 5375 occurred at disk power-on lifetime: 15209 hours (633 days + 17 hours)
When the command that caused the error occurred, the device was active or idle.After command completion occurred, registers were:
ER ST SC SN CL CH DH
— — — — — — —
40 51 0a c6 0e a1 e1 Error: UNC 10 sectors at LBA = 0x01a10ec6 = 27332294Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
— — — — — — — — —————- ———————
25 ff 10 c0 0e a1 e0 00 00:03:12.800 READ DMA EXT
29 ff 10 c0 0e a1 e0 00 00:03:07.800 READ MULTIPLE EXT
25 ff 10 c0 0e a1 e0 00 00:03:03.800 READ DMA EXT
29 ff 10 c0 0e a1 e0 00 00:02:58.700 READ MULTIPLE EXT
25 ff 10 c0 0e a1 e0 00 00:02:54.700 READ DMA EXTError 5374 occurred at disk power-on lifetime: 15209 hours (633 days + 17 hours)
When the command that caused the error occurred, the device was active or idle.After command completion occurred, registers were:
ER ST SC SN CL CH DH
— — — — — — —
40 51 0a c6 0e a1 e1 Error: UNC at LBA = 0x01a10ec6 = 27332294Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
— — — — — — — — —————- ———————
29 ff 10 c0 0e a1 e0 00 00:03:07.800 READ MULTIPLE EXT
25 ff 10 c0 0e a1 e0 00 00:03:03.800 READ DMA EXT
29 ff 10 c0 0e a1 e0 00 00:02:58.700 READ MULTIPLE EXT
25 ff 10 c0 0e a1 e0 00 00:02:54.700 READ DMA EXT
29 ff 10 c0 0e a1 e0 00 00:02:49.600 READ MULTIPLE EXTSMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed: read failure 80% 15321 25836754
# 2 Short offline Completed: read failure 80% 15321 28246515
# 3 Short offline Completed: read failure 90% 15320 26274896SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
In the GUI the 5 last errors show up as «uncorrectable error in data».
Now as you can see this HDD is old as heck, and I can’t seem to get Ubuntu to work for one consecutive week — do you think that the HDD is the culprit here?
Thanks!
-
#2
-
- Sep 22, 2010
-
- 8,598
-
- 545
-
- 36,390
- 986
-
#3
1 Raw_Read_Error_Rate 0x000b 085 085 062 Pre-fail Always — 1573078
5 Reallocated_Sector_Ct 0x0033 087 087 005 Pre-fail Always — 0
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always — 486
197 Current_Pending_Sector 0x0022 098 098 000 Old_age Always — 535
Strangely, the raw value of the Reallocated_Sector_Ct is still at 0 even though the normalised value has dropped significantly from 100. This would suggest that there is a SMART firmware bug, especially since the other attributes show read problems. This is also confirmed by the UNCorrectable errors in the SMART log.
-
#4
1 Raw_Read_Error_Rate 0x000b 085 085 062 Pre-fail Always — 1573078
5 Reallocated_Sector_Ct 0x0033 087 087 005 Pre-fail Always — 0
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always — 486
197 Current_Pending_Sector 0x0022 098 098 000 Old_age Always — 535
Strangely, the raw value of the Reallocated_Sector_Ct is still at 0 even though the normalised value has dropped significantly from 100. This would suggest that there is a SMART firmware bug, especially since the other attributes show read problems. This is also confirmed by the UNCorrectable errors in the SMART log.
Thanks for the reply,
So does that mean that the hardware might be a OK and it’s just the firmware that is wacky?
-
- Sep 22, 2010
-
- 8,598
-
- 545
-
- 36,390
- 986
-
#5
Normally when the normalised value (87) of the Reallocated Sector Count drops from its initial value of 100, this should be reflected in a significant non-zero raw value for the same attribute. The normalised value is a kind of «health» score, whereas the raw value represents the actual data for that attribute.
In short, I wouldn’t trust your HDD with your data.
| Thread starter | Similar threads | Forum | Replies | Date |
|---|---|---|---|---|
|
T
|
Question adding a new M.2 SSD to my motherboard causes PC to receive a boot error | Storage | 6 | Feb 1, 2023 |
|
|
[SOLVED] Repairing Disc Errors This May Take Over an Hour to Complete? | Storage | 22 | Jan 31, 2023 |
|
R
|
Question Seagate HDD in intermittent state (can’t initialize) (I/O ERROR) after I cancelled their software’s sanitization progress | Storage | 0 | Jan 26, 2023 |
|
D
|
Question Standard NVM Express Controller error — NVMe drive not detected in BIOS ? | Storage | 2 | Jan 14, 2023 |
|
S
|
[SOLVED] Is there a way to fix HDD CRC error | Storage | 1 | Jan 2, 2023 |
|
J
|
Question Really struggling to clone my hard disk on to SSD with Macrium Reflect , Error 0 and 23 | Storage | 9 | Dec 8, 2022 |
|
I
|
Question Why do we erratically get BSOD 14c error only on multiple HDD/SSD, with M.2 SSD as Boot drive ? | Storage | 5 | Dec 2, 2022 |
|
|
Question HDD i/o error | Storage | 2 | Nov 29, 2022 |
|
P
|
Question GSmartControl HDD error | Storage | 9 | Oct 25, 2022 |
|
|
[SOLVED] question bout hdd health and monitoring tools | Storage | 10 | Aug 29, 2022 |



- Advertising
- Cookies Policies
- Privacy
- Term & Conditions
- Topics
Skip to content
Что делать с «0xBB Reported Uncorrectable Errors»?
При загрузке компьютера или ноутбука возникает S.M.A.R.T. ошибка «0xBB Reported Uncorrectable Errors» жесткого диска или SSD? После данной ошибки компьютер не работает как прежде, и вы опасаетесь о сохранности ваших данных? Не знаете как исправить «0xBB Reported Uncorrectable Errors»?
Что означает «0xBB»: Reported Uncorrectable Errors? Допустимые значения атрибута «Reported Uncorrectable Errors» отличаются для различных производителей жестких дисков WD (Western Digital), Samsung, Seagate, HGST (Hitachi), Toshiba.
Актуально для ОС: Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows Home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
Программа для восстановления данных
Способ 2: Восстановите удаленные данные диска
В случае возникновения SMART ошибки не всегда требуется восстановление данных с диска. В случае ошибки рекомендуется незамедлительно
создать копию важных данных, так как диск может выйти из строя в любой момент. Но бывают ошибки при которых скопировать данные уже не представляется возможным.
В таком случае можно использовать программу для восстановления данных жесткого диска — Hetman Partition Recovery.

Для этого:
- Загрузите программу, установите и запустите её.
- По умолчанию, пользователю будет предложено воспользоваться Мастером восстановления файлов. Нажав кнопку «Далее», программа предложит выбрать диск, с которого необходимо восстановить файлы.
- Дважды кликните на сбойном диске и выберите необходимый тип анализа. Выбираем «Полный анализ» и ждем завершения процесса сканирования диска.
- После окончания процесса сканирования вам будут предоставлены файлы для восстановления. Выделите нужные файлы и нажмите кнопку «Восстановить».
- Выберите один из предложенных способов сохранения файлов. Не сохраняйте восстановленные файлы на диск с ошибкой «0xBB Reported Uncorrectable Errors».
Программа для восстановления данных
Способ 4: Снизьте температуру диска

Иногда, причиной возникновения «S M A R T» ошибки может быть превышение максимально допустимой температуры работы диска.
Такая ошибка может быть устранена путём улучшения вентиляции компьютера.
Во-первых, проверьте оборудован ли ваш компьютер достаточной вентиляцией и все ли вентиляторы исправны.
Если вами обнаружена и устранена проблема с вентиляцией, после чего температура работы диска снизилась
до нормального уровня, то SMART ошибка может больше не возникнуть.
Способ 6: Ошибка «Reported Uncorrectable Errors» для SSD диска

Даже если у вас не претензий к работе SSD диска, его работоспособность постепенно снижается. Причиной этому служит факт того,
что ячейки памяти SSD диска имеют ограниченное количество циклов перезаписи. Функция износостойкости минимизирует данный эффект, но не устраняет его полностью.
SSD диски имеют свои специфические SMART атрибуты, которые сигнализируют о состоянии ячеек памяти диска.
Например, «209 Remaining Drive Life», «231 SSD life left» и т.д. Данные ошибки могут возникнуть в случае снижения работоспособности ячеек,
и это означает, что сохранённая в них информация может быть повреждена или утеряна.
Ячейки SSD диска в случае выхода из строя не восстанавливаются и не могут быть заменены.
Способ 8: Приобретите новый жесткий диск
Целесообразен ли ремонт HDD?
Важно понимать, что любой из способов устранения SMART ошибки – это самообман.
Невозможно полностью устранить причину возникновения ошибки, так как основной причиной её возникновения
часто является физический износ механизма жесткого диска.
Для устранения или замены неправильно работающих составляющих жесткого диска,
можно обратится в сервисный центр специальной лабораторией для работы с жесткими дисками.
Но стоимость работы в таком случае будет выше стоимости нового устройства.
Поэтому, ремонт имеет смысл делать только в случае необходимости восстановления данных с уже неработоспособного диска.
Как выбрать новый накопитель?
Если вы столкнулись со SMART ошибкой жесткого диска то, приобретение нового диска – это только вопрос времени.
То, какой жесткий диск нужен вам зависит от вашего стиля работы за компьютером, а также цели с которой его используют.
На что обратить внимание приобретая новый диск:
- Тип диска: HDD, SSD или SSHD. Каждому типу присущи свои плюсы и минусы, которые не имеют решающего значения для одних пользователей и очень важны для других. Основные из них — это скорость чтения и записи информации, объём и устойчивость к многократной перезаписи.
- Размер. Два основных форм-фактора дисков: 3,5 дюймов и 2,5 дюймов. Размер диска определяется в соответствии с установочным местом конкретного компьютера или ноутбука.
- Интерфейс. Основные интерфейсы жестких дисков: SATA, IDE, ATAPI, ATA, SCSI, Внешний диск (USB, FireWire и.т.д.).
- Технические характеристики и производительность:
- Вместимость;
- Скорость чтения и записи;
- Размер буфера памяти или cache;
- Время отклика;
- Отказоустойчивость.
- S.M.A.R.T. Наличие в диске данной технологи поможет определить возможные ошибки его работы и вовремя предупредить утерю данных.
- Комплектация. К данному пункту можно отнести возможное наличие кабелей интерфейса или питания, а также гарантии и сервиса.