Содержание
- Sean Paul’s Blog
- Under promising and overdelivering.
- Uncorrectable PCI Express Error
- Frank’s Tech Support
- Virtualization. Networking. Sandwiches.
- Diagnosing a PSOD
- HP PROLIANT DL180 GEN9 AND PCI Express error
- fireon
- fireon
- HpCISSs2 crashing DL370 G6 with Server 2012
- Popular Topics in HP Hardware
- 19 Replies
Sean Paul’s Blog
Under promising and overdelivering.
Uncorrectable PCI Express Error

We’ve recently re-purposed a Proliant ML350p Gen8 server as a basic file server; after installing the operating system (Windows Server 2016) and the Support Pack for Proliant (SPP) the performance degraded massively. This wasn’t the worst of it…
Once I connected to the server using the ILO Remote Console it caused a Blue Screen of Death instantly with NMI_HARDWARE_FAILURE as the reason.
Naturally this shouldn’t happen – even after getting back in to Windows this happened again after launching the ILO RC.
After checking the IML (Integrated Management Logs) within ILO the following was logged:

As this server had been working perfectly fine for the past number of years it seemed a little strange that it was recommending we replace the processor!
As this seemed to be a little more firmware related I updated the BIOS to the latest version (01/2018) and re-flashed the ILO firmware again just in case. Same happened again but revealed a different error within the IML
Uncorrectable PCI Express Error (Embedded device, Bus 0, Device 28, Function 7, Error status 0x00100000)
After a quick google search I came across an article on the HPE Community Forum which indicated that it could be the Matrox Graphics driver causing the issue. This would make sense as the performance was terrible / choppy at best.
Sure enough after removing this driver and rebooting the system performance was back to normal and the ILO RC wasn’t crashing the server anymore.
Источник
Frank’s Tech Support
Virtualization. Networking. Sandwiches.

Diagnosing a PSOD
Last week, one of my hosts purple-screened. This seems like a bad thing, but it’s really not, and it does happen sometimes. It’s good practice to determine the root cause in case it’s something likely to happen again.
Believe it or not, purple screens are really a good thing. Your system is trying to save you from much worse. What is generally happening when you get a “Purple Screen of Death” is that some piece of hardware or software is misbehaving to the point that you are going to start experiencing data corruption and so the entire system halts to protect it from itself.
In my case, my PSOD came from a non-maskable interrupt. This is a special interrupt that the system is not allowed to ignore. It’s a signal that something critical just happened and Bad Things will ensue unless immediate action is taken. In the short term, it means your system just crashed. In the long term, it just saved you from potentially major data corruption. Bad, and yet good. On my HP server, NMI errors are generated by the hpnmi driver (which you should have installed as part of your VMware HP driver package to all of your HP ESXi hosts). This driver will keep an eye on your HP hardware and generate an NMI in the event of a catastrophic failure.
To begin tracking down the cause of my crash, I first took a complete set of log files via the VMware vCenter console. My generated bundle was about 800MB. To do this, in your vCenter Infrastructure Client, you’d click on File, Export System Logs. Browse through your tree and select your host. Make sure you include vCenter Server and Client as well for a complete picture.

Now that I have a full set of logs, it’s time to start digging into them. If you’re not an experienced log reader, this process can be extremely daunting. You may find tools like the VMware Log Insight tool to be helpful. Unfortunately, this is not a free tool, but it does work very well.
Since I never got to see the actual PSOD screen before my fellow support engineer restarted the host, I wasn’t really sure what I was looking for. However, I had the e-mail alert from when the host went down so I had a target time and date. My PSOD was somewhere around 23:49 UTC. My first stop was /var/log/vmkernel.log, which should tell me everything the vmkernel was up to.
2014-05-30T23:37:30.314Z cpu8:9295)FS3Misc: 1465: Long VMFS rsv time on ‘SANB-ISO1’ (held for 264 msecs). # R: 1, # W: 1 bytesXfer: 9 sectors
VMB: 49: mbMagic: 2badb002, mbInfo 0x101158
VMB: 54: flags a6d
Ok, nothing there. Normal log entries right before the reboot lines. Let’s try vpxa.log. That’s the host agents.
2014-05-30T23:47:16.908Z [3F4D3B90 verbose ‘vpxavpxaInvtHost’ opID=WFU-fe82c6fb] [HostChanged] Found update for tracked MoRef vim.HostSystem:ha-host
2014-05-30T23:47:16.909Z [3F4D3B90 verbose ‘VpxaHalCnxHostagent’ opID=WFU-fe82c6fb] [WaitForUpdatesDone] Starting next WaitForUpdates() call to hostd
2014-05-30T23:47:16.909Z [3F4D3B90 verbose ‘VpxaHalCnxHostagent’ opID=WFU-fe82c6fb] [WaitForUpdatesDone] Completed callback
Section for VMware ESX, pid=9549, version=5.1.0, build=1743533, option=Release
2014-05-31T00:10:15.434Z [FFC066D0 info ‘Default’] Logging uses fast path: false
Still nothing! Normal operation right up until the reboot when it started logging again. Alright, let’s get nasty. We’ll go straight to the dump file at /var/core/vmkernel-zdump. In this case, the log export reconstructed the dump file for me automatically but it still left all of the FRAG parts. Lots and lots of binary data, but what’s this I see right around 23:47, two minutes before my e-mail:
2014-05-30T23:47:38.642Z cpu0:9115)WARNING: NMI: 952: LINT1 motherboard interrupt
That doesn’t look good. Scroll a bit to get passed the stack dumps and I find the actual PSOD:
2014-05-30T23:47:38.819Z cpu0:9115)@BlueScreen: Panic requested by one or more 3rd party NMI handlers
Alright, so I have a purple screen requested by a third party NMI. The only third party NMI installed is HPNMI, as mentioned at the beginning of this post. HPNMI has a useful feature in that it will write logs to the iLO (integrated lights out), which is isolated from the running hypervisor on the host. Let’s go see what iLO has to say! I fire up my web browser and open my iLO Integrated Management Log:

Uh oh. That’s a hardware failure.
Uncorrectable PCI Express Error (Embedded device, Bus 0, Device 9, Function 0, Error status 0x00200000)
Let’s see if we can figure out exactly what failed. I’ll SSH into my host so that I can enumerate the PCI Express bus and figure out what’s on Bus 0 Device 9, built into the motherboard. For this, I’ll use lspci.
# lspci -v
*output suppressed*
00:00:09.0 PCI bridge Bridge: Intel Corporation 7500/5520/5500/X58 I/O Hub PCI Express Root Port 9 [PCIe RP[00:00:09.0]]
Class 0604: 8086:3410
Bus 0 Device 9 is the Intel PCI Express Root Port controller. Dang. This means something on the motherboard itself went south. I was hoping for a bad NIC or something.
According to HP, the only way to be sure about this problem is to replace the entire motherboard. Unfortunately, this host is out of warranty and the HP Care Pack has run out. My only hope now is that this is a one-time error and not a symptom of a serious issue. I have since moved my more critical VMs off of this host and demoted it to “Spare host with non-critical VMs only”. Still usable, but not exactly trustworthy.
I hope this write-up encourages you to dig into your own PSOD’s instead of just rebooting and hoping for the best. The log files can be extremely intimidating but even if you only understand 5% of the information they display, it may be enough to give you insight into your issue. Thanks for reading!
Источник
HP PROLIANT DL180 GEN9 AND PCI Express error
New Member
Hi,
My HP HP Smart Array P440 Controller on PCI Express Slot1 and i am getting below error
Uncorrectable PCI Express Error (Slot 1, Bus 0, Device 3, Function 0, Error status 0x00000020)
Unrecoverable System Error (NMI) has occurred. System Firmware will log additional details in a separate IML entry if possible
PCI Bus Error (Slot 0, Bus 0, Device 3, Function 0)
i want to know that is that about proxmox driver or other than this.
need any advice.

fireon
Famous Member
What says the IML log? You can read this easy with the HPtools.
apt-key adv —recv-keys —keyserver keyserver.ubuntu.com 527BC53A2689B887
apt-key adv —recv-keys —keyserver keyserver.ubuntu.com FADD8D64B1275EA3
apt-get update
apt-get dist-upgrade
apt-get install hp-health hpssacli hponcfg
Or you can read important things in ILO.
Best Regards
Fireon
Deutsch PVE Dokumentation: http://deepdoc.at
DEEPDOC.AT — enjoy your brain
New Member
thanks for your reply.
i wrote what ILO said.
Critical PCI Bus 12/29/2015 18:15 12/29/2015 18:15 1 PCI Bus Error (Slot 0, Bus 0, Device 3, Function 0)
above lines from my HP DL180 GEN9 ILO.
fireon
Famous Member
Sorry, your 3 images are not visible in your post. Is in the ILO generally an HW Error? When yes. You should contact HP Support for warranty. Can you post Screenshot from ILO status and IML?
Does the system is running normaly or is only this message in IML your problem? Or you are not able to install the system?
Best Regards
Fireon
Deutsch PVE Dokumentation: http://deepdoc.at
DEEPDOC.AT — enjoy your brain
New Member
No image inmy post!?
my system works perfectly, but some times 4-5 days period, proxmox and also al my Virtual Apliance down, theni chack ILO i see these error linesa my P440 Smart Array controller and its pci controller
PCI-E Slot 1 HP Smart Array P440 Controller 749797-001 PDNMF0ARH7U2BX B 3.52
error is :
Critical PCI Bus 12/29/2015 18:15 12/29/2015 18:15 1 Uncorrectable PCI Express Error (Slot 1, Bus 0, Device 3, Function 0, Error status 0x00000020)
Critical System Error 12/29/2015 18:15 12/29/2015 18:15 1 Unrecoverable System Error (NMI) has occurred. System Firmware will log additional details in a separate IML entry if possible
Critical PCI Bus 12/29/2015 18:15 12/29/2015 18:15 1 PCI Bus Error (Slot 0, Bus 0, Device 3, Function 0)
Источник
HpCISSs2 crashing DL370 G6 with Server 2012
So before anyone says it I know the DL370 G6 doesn’t officially support Server 2012 but the P410i are the same in the G7’s and that appears to be the issue.
Anyway, every now and then my both my DL370 G6’s BSOD / what ever Microsoft call it now and the a bug check shows:
Probably caused by : HpCISSs2.sys ( HpCISSs2+4c74 )
After doing some googling, I found lots of places saying check the BIOS version, controller firmware etc. which are all up-to-date.
I’ve looked and looked but can’t work out why its doing it, it hadn’t done it for about two weeks then last night one of them died and then again this morning.
No reason, backups wern’t running, no updates installed, no llamas eating cables in the server room, it just doesn’t make sense and its making me crazzzzzyyy and look bad 🙁
Anyone got any thoughts?

akp982 is an IT service provider.
Popular Topics in HP Hardware
akp982 is an IT service provider.
Full Bug Check
DRIVER_IRQL_NOT_LESS_OR_EQUAL (d1)
An attempt was made to access a pageable (or completely invalid) address at an
interrupt request level (IRQL) that is too high. This is usually
caused by drivers using improper addresses.
If kernel debugger is available get stack backtrace.
Arguments:
Arg1: fffffa88193a2110, memory referenced
Arg2: 000000000000000b, IRQL
Arg3: 0000000000000000, value 0 = read operation, 1 = write operation
Arg4: fffff88000e1ec74, address which referenced memory
Page 7d306f not present in the dump file. Type «.hh dbgerr004» for details
Page 7d3000 not present in the dump file. Type «.hh dbgerr004» for details
Page 7d3000 not present in the dump file. Type «.hh dbgerr004» for details
Page 7d3000 not present in the dump file. Type «.hh dbgerr004» for details
Page 7d3000 not present in the dump file. Type «.hh dbgerr004» for details
Page 7d3000 not present in the dump file. Type «.hh dbgerr004» for details
Page 7d3000 not present in the dump file. Type «.hh dbgerr004» for details
Page 7d3000 not present in the dump file. Type «.hh dbgerr004» for details
Page 7d3000 not present in the dump file. Type «.hh dbgerr004» for details
READ_ADDRESS: fffffa88193a2110 Nonpaged pool
FAULTING_IP:
HpCISSs2+4c74
fffff880`00e1ec74 4c8b3cc8 mov r15,qword ptr [rax+rcx*8]
TRAP_FRAME: fffff88003a564b0 — (.trap 0xfffff88003a564b0)
NOTE: The trap frame does not contain all registers.
Some register values may be zeroed or incorrect.
rax=fffffa80193a2118 rbx=0000000000000000 rcx=00000000ffffffff
rdx=0000000000000001 rsi=0000000000000000 rdi=0000000000000000
rip=fffff88000e1ec74 rsp=fffff88003a56640 rbp=0000000000000000
r8=00000000000003b7 r9=fffffa80193a4118 r10=0000000000000000
r11=00000000000002e3 r12=0000000000000000 r13=0000000000000000
r14=0000000000000000 r15=0000000000000000
iopl=0 nv up ei ng nz ac po nc
HpCISSs2+0x4c74:
fffff880`00e1ec74 4c8b3cc8 mov r15,qword ptr [rax+rcx*8] ds:fffffa88`193a2110=.
Resetting default scope
EXCEPTION_RECORD: fffff8027ce230e0 — (.exr 0xfffff8027ce230e0)
ExceptionAddress: 0b74f68445a472c7
ExceptionCode: 73c53b48
ExceptionFlags: dc034903
NumberParameters: 608996680
Parameter[0]: 40244c8b480002b1
Parameter[1]: 00018c10e8cc3348
Parameter[2]: 5b8b4950245c8d4c
Parameter[3]: e38b49506b8b4948
Parameter[4]: 5c415d415e415f41
Parameter[5]: 90909090c3595e5f
Parameter[6]: 9090909090909090
Parameter[7]: 9090909090909090
Parameter[8]: 6c894808245c8948
Parameter[9]: 5718247489481024
Parameter[10]: 48ea8b4820ec8348
Parameter[11]: 0000d8be8b48f18b
Parameter[12]: 000000d09e8b4800
Parameter[13]: 4c7856ff504e8b48
Parameter[14]: 4800240c83f0d88b
LAST_CONTROL_TRANSFER: from fffff8027ceca769 to fffff8027cecb440
STACK_TEXT:
fffff880`03a56368 fffff802`7ceca769 : 00000000`0000000a fffffa88`193a2110 00000000`0000000b 00000000`00000000 : nt!KeBugCheckEx
fffff880`03a56370 fffff802`7cec8fe0 : 00000000`00000000 fffffa80`19395010 00000000`00000000 fffff880`03a564b0 : nt!KiBugCheckDispatch+0x69
fffff880`03a564b0 fffff880`00e1ec74 : 00000000`00000246 00000000`00f088db fffff880`03a56740 fffff780`00000320 : nt!KiPageFault+0x260
fffff880`03a56640 fffff880`00e2024c : fffffa80`00000000 00000000`00000000 fffffa80`00000000 fffff802`00000000 : HpCISSs2+0x4c74
fffff880`03a56770 fffff802`7cec3c66 : fffde635`1845368c 00000000`00000100 fffde632`4d41c43c fffff880`03a56860 : HpCISSs2+0x624c
fffff880`03a567e0 fffff802`7ce30be2 : fffff802`7ce230e0 00000000`00000000 00000000`00000000 00000000`00000000 : nt!KiInterruptDispatch+0x1d6
fffff880`03a56978 fffff802`7ce230e0 : 00000000`00000000 00000000`00000000 00000000`00000000 00000000`00000000 : hal!HalpTscQueryCounter+0x2
fffff880`03a56980 fffff880`01f94ae8 : 00000000`00000001 00000000`00000001 00000000`00000000 00000000`00000000 : hal!HalpTimerStallExecutionProcessor+0x131
fffff880`03a56a10 fffff880`01f94d52 : fffffa80`19934af0 00000000`00000001 fffffa80`18cb5000 00000000`00000000 : hpqilo2+0x6ae8
fffff880`03a56a40 fffff880`01f95055 : fffff880`03a56af8 fffffa80`19934b73 00000000`00000000 00000000`00000000 : hpqilo2+0x6d52
fffff880`03a56a70 fffff880`01f965ba : 00000000`00000001 00000000`00000000 fffffa80`18cb5000 fffffa80`19836280 : hpqilo2+0x7055
fffff880`03a56ad0 fffff880`01f90c13 : fffffa80`19934b48 00000000`00000000 00000000`00000080 00000000`484c5200 : hpqilo2+0x85ba
fffff880`03a56c70 fffff802`7ce9e045 : f919479b`0410f00d 304a19e2`d4101e53 3b2bb69b`82818ad5 e87a9567`edc931a6 : hpqilo2+0x2c13
fffff880`03a56d50 fffff802`7cf52766 : fffff880`017e5180 fffffa80`19836280 fffff880`017f1540 fffffa80`189c4980 : nt!PspSystemThreadStartup+0x59
fffff880`03a56da0 00000000`00000000 : fffff880`03a57000 fffff880`03a51000 00000000`00000000 00000000`00000000 : nt!KiStartSystemThread+0x16
FOLLOWUP_IP:
HpCISSs2+4c74
fffff880`00e1ec74 4c8b3cc8 mov r15,qword ptr [rax+rcx*8]
Источник
-
#1
Добрый день! Есть сервер HP DL 560 Gen9, работающий на windows server 2016. Там живет Microsoft SQL server 2016 и сервер 1с предприятия. В выходные на емэйл пришли ошибки от ilo, сервер перестал пинговаться и видимо завис. Ошибки такие:
— PCI Bus 01/26/2021 15:15 01/26/2021 15:15 1 PCI Bus Error (Slot 0, Bus 0, Device 0, Function 0)
— System Error 01/26/2021 15:15 01/26/2021 15:15 1 Unrecoverable System Error (NMI) has occurred. System Firmware will log additional details in a separate IML entry if possible
— PCI Bus 01/26/2021 15:15 01/26/2021 15:15 1 Uncorrectable PCI Express Error (Embedded device, Bus 0, Device 0, Function 0, Error status 0x00000000)
— PCI Bus 01/26/2021 15:15 [NOT SET] 1 Uncorrectable PCI Express Error (Embedded device, Bus 0, Device 0, Function 0, Error status 0x00000000)
Перезагрузил сервер удаленно через ilo — вроде он ожил. Но на долго ли.. Помогите понять что за ошибка и что сломалось ?
-
#2
HP ProLiant Servers — How to Decode Uncorrectable PCI Express Error
Information
This document will help user in decoding the Uncorrectable PCI Express Error.
Ex: Uncorrectable PCI Express Error (Embedded device, Bus 0, Device 8, Function 0, Error status 0x00000000
Details
This particular PCI Express Error could be decoded by using the logs mentioned below.
- Advanced Survey Report.
- lspci Output from a Linux Machine or ESX Machine.
Advanced Survey Report:

NOTE: Use the Vendor ID and the Device ID to determine the hardware device.
LSPCI Output:
If the server is running Linux or ESX, collect the OS logs from the server.
Check the lspci.txt in the OS logs. User should be able to find the information as listed in the screenshot below:
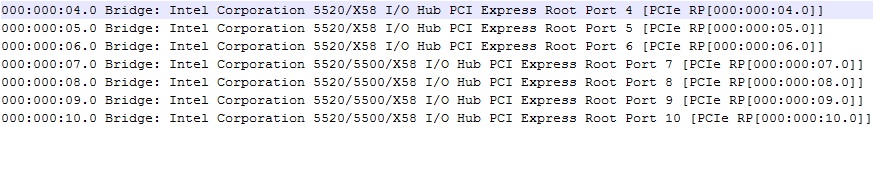
In this Example, check the numbers listed before the word Bridge.
000:000:08.0 Bridge: Intel Corporation 5520/5500/X58 I/O Hub PCI Express Root Port 8.
000 —> Represents PCI Domain (Every PCI Domain could have 256 PCI Buses).
000 —> Bus
08 —> Device
0 —> Function
By using either of these logs, the PCI Express Error could be narrowed down to the hardware device causing the error.
NOTE: The Values mentioned in the IML Logs are Decimal Values. The values in the Advanced Survey Report is in the decimal Value. However the values in the lspci command output is in hexadecimal value. Everytime the values has to be converted to hexadecimal when comparing the values in the lspci output.
-
#3
Если не последняя версия прошивки то можно попробовать вылечить через сервисный пак SPP Gen9 Production Version *: 2021.10.0
Подобного рода алерты как правило часто вызваны устарвшими версиями прошивок таких компонентов как System Rom и ILO.
-
#4
Если не последняя версия прошивки то можно попробовать вылечить через сервисный пак SPP Gen9 Production Version *: 2021.10.0
Подобного рода алерты как правило часто вызваны устарвшими версиями прошивок таких компонентов как System Rom и ILO.
Попробую но не думаю что это поможет, позже напишу. Сейчас нет возможности перезагрузить сервер

-
#5
Если не последняя версия прошивки то можно попробовать вылечить через сервисный пак SPP Gen9 Production Version *: 2021.10.0
Подобного рода алерты как правило часто вызваны устарвшими версиями прошивок таких компонентов как System Rom и ILO.
Хьюлеты при обращении в саппорт или в другой любой непонятной ситуации выдают стандартный ответ — обновите прошивку
-
#6
Обновил все firmware. Пока полет нормальный. Думаю помогло.
About Lenovo
-
Our Company
-
News
-
Investor Relations
-
Sustainability
-
Product Compliance
-
Product Security
-
Lenovo Open Source
-
Legal Information
-
Jobs at Lenovo
Shop
-
Laptops & Ultrabooks
-
Tablets
-
Desktops & All-in-Ones
-
Workstations
-
Accessories & Software
-
Servers
-
Storage
-
Networking
-
Laptop Deals
-
Outlet
Support
-
Drivers & Software
-
How To’s
-
Warranty Lookup
-
Parts Lookup
-
Contact Us
-
Repair Status Check
-
Imaging & Security Resources
Resources
-
Where to Buy
-
Shopping Help
-
Sales Order Status
-
Product Specifications (PSREF)
-
Forums
-
Registration
-
Product Accessibility
-
Environmental Information
-
Gaming Community
-
LenovoEDU Community
-
LenovoPRO Community
©
Lenovo.
|
|
|
|
Server is HP DL360 G7 with P410i disk controller. 2xE5620 CPU’s. 16GB RAM. Linux mysql 2.6.32-5-amd64 #1 SMP Mon Feb 25 00:26:11 UTC 2013 x86_64 GNU/Linux (Debian 6.0.7)
hpacucli «ctrl all show status»
Smart Array P410i in Slot 0 (Embedded)
Controller Status: OK
Cache Status: OK
Battery/Capacitor Status: OK
hpacucli «ctrl all show config»
Smart Array P410i in Slot 0 (Embedded) (sn: 5001438014555B80)
array A (SAS, Unused Space: 0 MB)
logicaldrive 1 (136.7 GB, RAID 1+0, OK)
physicaldrive 1I:1:1 (port 1I:box 1:bay 1, SAS, 72 GB, OK)
physicaldrive 1I:1:2 (port 1I:box 1:bay 2, SAS, 72 GB, OK)
physicaldrive 1I:1:3 (port 1I:box 1:bay 3, SAS, 72 GB, OK)
physicaldrive 1I:1:4 (port 1I:box 1:bay 4, SAS, 72 GB, OK)
SEP (Vendor ID PMCSIERA, Model SRC 8x6G) 250 (WWID: 5001438014555B8F)
hpacucli «ctrl slot=0 ld all show»
Smart Array P410i in Slot 0 (Embedded)
array A
logicaldrive 1 (136.7 GB, RAID 1+0, OK)
I run fallowing script via night:
#!/bin/bash
mkdir -p /isotest
for i in {1..200}; do
for j in {1..55}; do cp -v /root/ubuntu.iso /isotest/ubuntu.iso${j}; done
rm /isotest/ubuntu.iso*;
done
/root/ubuntu.iso size is abou 2 GB.
in syslog has some errors. I think that it is related to disk controller:
Mar 28 06:59:17 mysql kernel: [850337.524306] INFO: task mandb:25565 blocked for more than 120 seconds.
Mar 28 06:59:17 mysql kernel: [850337.524337] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Mar 28 06:59:17 mysql kernel: [850337.524381] mandb D ffff88022740fa20 0 25565 25197 0x00000000
Mar 28 06:59:17 mysql kernel: [850337.524385] ffff88041ec4b880 0000000000000082 0000000000000000 000000009d778d11
Mar 28 06:59:17 mysql kernel: [850337.524388] ffffea000defe260 ffffea000defe260 000000000000f9e0 ffff88014d913fd8
Mar 28 06:59:17 mysql kernel: [850337.524390] 00000000000157c0 00000000000157c0 ffff88013228a350 ffff88013228a648
Mar 28 06:59:17 mysql kernel: [850337.524393] Call Trace:
Mar 28 06:59:17 mysql kernel: [850337.524404] [<ffffffff810168ec>] ? read_tsc+0xa/0x20
Mar 28 06:59:17 mysql kernel: [850337.524408] [<ffffffff8106bdca>] ? timekeeping_get_ns+0xe/0x2e
Mar 28 06:59:17 mysql kernel: [850337.524412] [<ffffffff810b4761>] ? sync_page+0x0/0x46
Mar 28 06:59:17 mysql kernel: [850337.524416] [<ffffffff812fc8f2>] ? io_schedule+0x73/0xb7
Mar 28 06:59:17 mysql kernel: [850337.524418] [<ffffffff810b47a2>] ? sync_page+0x41/0x46
Mar 28 06:59:17 mysql kernel: [850337.524421] [<ffffffff812fcd02>] ? __wait_on_bit_lock+0x3f/0x84
Mar 28 06:59:17 mysql kernel: [850337.524423] [<ffffffff810b472e>] ? __lock_page+0x5d/0x63
Mar 28 06:59:17 mysql kernel: [850337.524426] [<ffffffff810652e0>] ? wake_bit_function+0x0/0x23
Mar 28 06:59:17 mysql kernel: [850337.524428] [<ffffffff810b473d>] ? lock_page+0x9/0x1f
Mar 28 06:59:17 mysql kernel: [850337.524431] [<ffffffff810b4853>] ? find_lock_page+0x25/0x45
Mar 28 06:59:17 mysql kernel: [850337.524433] [<ffffffff810b4e63>] ? filemap_fault+0x1a5/0x2f6
Mar 28 06:59:17 mysql kernel: [850337.524438] [<ffffffff810cadf2>] ? __do_fault+0x54/0x3c3
Mar 28 06:59:17 mysql kernel: [850337.524455] [<ffffffffa01702d2>] ? __ext3_journal_stop+0x1f/0x3d [ext3]
Mar 28 06:59:17 mysql kernel: [850337.524458] [<ffffffff810cd146>] ? handle_mm_fault+0x3b8/0x80f
Mar 28 06:59:17 mysql kernel: [850337.524461] [<ffffffff81101d8e>] ? notify_change+0x2b3/0x2c5
Mar 28 06:59:17 mysql kernel: [850337.524464] [<ffffffff81103eb5>] ? mntput_no_expire+0x23/0xee
Mar 28 06:59:17 mysql kernel: [850337.524467] [<ffffffff81300096>] ? do_page_fault+0x2e0/0x2fc
Mar 28 06:59:17 mysql kernel: [850337.524469] [<ffffffff812fdf35>] ? page_fault+0x25/0x30
There are no other error messages.
Or this error can be related to memory? I already run memtest86+ on that server for several days and there was no errors.
When server was in data center, i cant boot server up. It show all the time error:
Fatal PCI Express Device Error PCI ? B00/D00/F00
After transporting it to my work, it boot up normally. In ILO event log has fallowing errors:
Uncorrectable PCI Express Error (Embedded device, Bus 0, Device 0, Function 0, Error status 0x00000000)
Uncorrectable Memory Error ((Processor 1, Memory Module 2))
Uncorrectable Memory Error ((Processor 1, Memory Module 3))
An Unrecoverable System Error (NMI) has occurred (System error code 0x00000000, 0x00000000)
I already updated bios, disk controller and drive firmwares to latest versions.
Hi Everyone,
Good day,
Could you please help on this.
Model HP ProLiant DL580 G7
VMware : VMware ESXi, 6.0.0, 7967664
We are facing PSOD issue on this Model and server is out of warranty and unable the find issue which hardware failure.
The below mentioned PSOD error message
PSOD Message:: LINT1/NMI (motherboard nonmaskable interrupt), diagnosed as fatal by module «hpe-nmi». This may be a hardware problem; please contact your hardware vendor.
Backtrace for Current CPU: 0
0x438080002c30:[0x41801f6782ea]PanicvPanicInt@vmkernel#nover+0x37e stack: 0x438080002cc8, 0x0, 0x1,
0x438080002cc0:[0x41801f6785b5]Panic_NoSave@vmkernel#nover+0x4d stack: 0x438080002d20, 0x438080002c
0x438080002d20:[0x41801f674b24]NMI_Interrupt@vmkernel#nover+0x0 stack: 0x0, 0x6800000000000000, 0x6
0x438080002de0:[0x41801f674ccf]NMI_Interrupt@vmkernel#nover+0x1ab stack: 0x0, 0x0, 0x0, 0x41801f905
0x438080002e90:[0x41801f65487a]IDTNMIWork@vmkernel#nover+0x10a stack: 0x0, 0x0, 0x0, 0x0, 0x0
0x438080002f20:[0x41801f655e2d]Int2_NMI@vmkernel#nover+0x19 stack: 0x0, 0x41801f6c8067, 0x10b, 0x0,
0x438080002f40:[0x41801f6c8067]gate_entry_@vmkernel#nover+0x0 stack: 0x0, 0x0, 0x0, 0x0, 0x41804000
0x439243a1bb18:[0x41801f90588a]Power_HaltPCPU@vmkernel#nover+0x1ee stack: 0x417fdf883f20, 0x4180401
0x439243a1bb68:[0x41801f812548]CpuSchedIdleLoopInt@vmkernel#nover+0x2f8 stack: 0xbf1264acd3d18, 0x1
0x439243a1bbe8:[0x41801f815bee]CpuSchedDispatch@vmkernel#nover+0x15fe stack: 0x43935ce27100, 0x1, 0
0x439243a1bd08:[0x41801f8167d4]CpuSchedWait@vmkernel#nover+0x240 stack: 0x0, 0x4314c6667251, 0x3401
0x439243a1bd88:[0x41801f6b708a]WorldWaitInt@vmkernel#nover+0x28e stack: 0x418000002001, 0x4314c6660
0x439243a1be08:[0x41801fbcd76a]UserObj_Poll@<None>#<None>+0x106 stack: 0xcc6684000, 0xbf1264ebd1752
0x439243a1be78:[0x41801fbf2d5e]LinuxFileDesc_Ppoll@<None>#<None>+0x262 stack: 0x3ffec4cb9f8, 0x4314
0x439243a1bef8:[0x41801fbc77fa]User_LinuxSyscallHandler@<None>#<None>+0x26e stack: 0x0, 0x0, 0x0, 0
0x439243a1bf28:[0x41801f68ed11]User_LinuxSyscallHandler@vmkernel#nover+0x1d stack: 0x10b, 0x0, 0x0,
0x439243a1bf38:[0x41801f6c8067]gate_entry_@vmkernel#nover+0x0 stack: 0x0, 0x10f, 0x2ee286b8, 0x3ffe
I have checked the ILO : Integrated Management Log found the below error log
| Severity | Class | Count | Description |
| PCI Bus |
1 | Uncorrectable PCI Express Error (Embedded device, Bus 0, Device 3, Function 0, Error status 0x00040000) |
I have login to SSH and execute the lspci -v command and found the bus details but unable to find out cause with motherboard or PCI SLOT or Any NIC card /HBA card issues / firmware/driver issues
0000:00:03.0 PCI bridge Bridge: Intel Corporation 5520/5500/X58 I/O Hub PCI Express Root Port 3 [PCIe RP[0000:00:03.0]]
Class 0604: 8086:340a
Thanks Advance
Regards,
Johnson.s