PEP: Python3 and UnicodeDecodeError
This is a PEP describing the behaviour of Python3 on UnicodeDecodeError. It’s a draft, don’t hesitate to comment it. This document suppose that my patch to allow bytes filenames is accepted which is not the case today.
While I was writing this document I found poential problems in Python3. So here is a TODO list (things to be checked):
- FIXME: When bytearray is accepted or not?
- FIXME: Allow bytes/str mix for shutil.copy*()? The ignore callback will get bytes or unicode?
Can anyone write a section about bytes encoding in Unicode using escape sequence?
What is the best tool to work on a PEP? I hate email threads, and I would prefer SVN / Mercurial / anything else.
Python3 and UnicodeDecodeError for the command line, environment variables and filenames
Introduction
Python3 does its best to give you texts encoded as a valid unicode characters strings. When it hits an invalid bytes sequence (according to the used charset), it has two choices: drops the value or raises an UnicodeDecodeError. This document present the behaviour of Python3 for the command line, environment variables and filenames.
Example of an invalid bytes sequence: ::
>>> str(b'xff', 'utf8') UnicodeDecodeError: 'utf8' codec can't decode byte 0xff (...)
whereas the same byte sequence is valid in another charset like ISO-8859-1: ::
>>> str(b'xff', 'iso-8859-1') 'ÿ'
Default encoding
Python uses «UTF-8» as the default Unicode encoding. You can read the default charset using sys.getdefaultencoding(). The «default encoding» is used by PyUnicode_FromStringAndSize().
A function sys.setdefaultencoding() exists, but it raises a ValueError for charset different than UTF-8 since the charset is hardcoded in PyUnicode_FromStringAndSize().
Command line
Python creates a nice unicode table for sys.argv using mbstowcs(): ::
$ ./python -c 'import sys; print(sys.argv)' 'Ho hé !' ['-c', 'Ho hé !']
On Linux, mbstowcs() uses LC_CTYPE environement variable to choose the encoding. On an invalid bytes sequence, Python quits directly with an exit code 1. Example with UTF-8 locale:
$ python3.0 $(echo -e 'invalid:xff') Could not convert argument 1 to string
Environment variables
Python uses «_wenviron» on Windows which are contains unicode (UTF-16-LE) strings. On other OS, it uses «environ» variable and the UTF-8 charset. It drops a variable if its key or value is not convertible to unicode. Example:
env -i HOME=/home/my PATH=$(echo -e "xff") python
>>> import os; list(os.environ.items())
[('HOME', '/home/my')]
Both key and values are unicode strings. Empty key and/or value are allowed.
Python ignores invalid variables, but values still exist in memory. If you run a child process (eg. using os.system()), the «invalid» variables will also be copied.
Filenames
Introduction
Python2 uses byte filenames everywhere, but it was also possible to use unicode filenames. Examples:
- os.getcwd() gives bytes whereas os.getcwdu() always returns unicode
-
os.listdir(unicode) creates bytes or unicode filenames (fallback to bytes on UnicodeDecodeError), os.readlink() has the same behaviour
- glob.glob() converts the unicode pattern to bytes, and so create bytes filenames
- open() supports bytes and unicode
Since listdir() mix bytes and unicode, you are not able to manipulate easily filenames:
>>> path=u'.'
>>> for name in os.listdir(path):
... print repr(name)
... print repr(os.path.join(path, name))
...
u'valid'
u'./valid'
'invalidxff'
Traceback (most recent call last):
...
File "/usr/lib/python2.5/posixpath.py", line 65, in join
path += '/' + b
UnicodeDecodeError: 'ascii' codec can't decode byte 0xff (...)
Python3 supports both types, bytes and unicode, but disallow mixing them. If you ask for unicode, you will always get unicode or an exception is raised.
You should only use unicode filenames, except if you are writing a program fixing file system encoding, a backup tool or you users are unable to fix their broken system.
Windows
Microsoft Windows since Windows 95 only uses Unicode (UTF-16-LE) filenames. So you should only use unicode filenames.
Non Windows (POSIX)
POSIX OS like Linux uses bytes for historical reasons. In the best case, all filenames will be encoded as valid UTF-8 strings and Python creates valid unicode strings. But since system calls uses bytes, the file system may returns an invalid filename, or a program can creates a file with an invalid filename.
An invalid filename is a string which can not be decoded to unicode using the default file system encoding (which is UTF-8 most of the time).
A robust program will have to use only the bytes type to make sure that it can open / copy / remove any file or directory.
Filename encoding
Python use:
- «mbcs» on Windows
- or «utf-8» on Mac OS X
- or nl_langinfo(CODESET) on OS supporting this function
- or UTF-8 by default
«mbcs» is not a valid charset name, it’s an internal charset saying that Python will use the function MultiByteToWideChar() to decode bytes to unicode. This function uses the current codepage to decode bytes string.
You can read the charset using sys.getfilesystemencoding(). The function may returns None if Python is unable to determine the default encoding.
PyUnicode_DecodeFSDefaultAndSize() uses the default file system encoding, or UTF-8 if it is not set.
On UNIX (and other operating systems), it’s possible to mount different file systems using different charsets. sys.getdefaultencoding() will be the same for the different file systems since this encoding is only used between Python and the Linux kernel, not between the kernel and the file system which may uses a different charset.
Display a filename
Example of a function formatting a filename to display it to human eyes: ::
from sys import getfilesystemencoding
def format_filename(filename):
return str(filename, getfilesystemencoding(), 'replace')
Example: format_filename(‘rxffport.doc’) gives ‘r�port.doc’ with the UTF-8 encoding.
Functions producing filenames
Policy: for unicode arguments: drop invalid bytes filenames; for bytes arguments: return bytes
- os.listdir()
- glob.glob()
This behaviour (drop silently invalid filenames) is motivated by the fact to if a directory of 1000 files only contains one invalid file, listdir() fails for the whole directory. Or if your directory contains 1000 python scripts (.py) and just one another document with an invalid filename (eg. r�port.doc), glob.glob(‘*.py’) fails whereas all .py scripts have valid filename.
Policy: for an unicode argument: raise an UnicodeDecodeError on invalid filename; for an bytes argument: return bytes
- os.readlink()
Policy: create unicode directory or raise an UnicodeDecodeError
- os.getcwd()
Policy: always returns bytes
- os.getcwdb()
Functions for filename manipulation
Policy: raise TypeError on bytes/str mix
- os.path.*(), eg. os.path.join()
- fnmatch.*()
Functions accessing files
Policy: accept both bytes and str
- io.open()
- os.open()
- os.chdir()
- os.stat(), os.lstat()
- os.rename()
- os.unlink()
- shutil.*()
os.rename(), shutil.copy*(), shutil.move() allow to use bytes for an argment, and unicode for the other argument
bytearray
In most cases, bytearray() can be used as bytes for a filename.
Unicode normalisation
Unicode characters can be normalized in 4 forms: NFC, NFD, NFKC or NFKD. Python does never normalize strings (nor filenames). No operating system does normalize filenames. So the users using different norms will be unable to retrieve their file. Don’t panic! All users use the same norm.
Use unicodedata.normalize() to normalize an unicode string.
Several errors can arise when an attempt to decode a byte string from a certain coding scheme is made. The reason is the inability of some encoding schemes to represent all code points. One of the most common errors during these conversions is UnicodeDecode Error which occurs when decoding a byte string by an incorrect coding scheme. This article will teach you how to resolve a UnicodeDecodeError for a CSV file in Python.
Why does the UnicodeDecodeError error arise?
The error occurs when an attempt to represent code points outside the range of the coding is made. To solve the issue, the byte string should be decoded using the same coding scheme in which it was encoded. i.e., The encoding scheme should be the same when the string is encoded and decoded.
For demonstration, the same error would be reproduced and then fixed. In the below code, firstly the character a (byte string) is decoded using ASCII encoding successfully. Then an attempt to decode the byte string axf1 is made, which led to an error. This is because the ASCII encoding standard only allows representation of the characters within the range 0 to 127. Any attempt to address a character outside this range would lead to the ordinal not-in-range error.
Python3
t = b"a".decode("ascii")
t1 = b"axf1".decode("ascii")
Output:
Traceback (most recent call last):
File "C:/Users/Sauleyayan/PycharmProjects/untitled1/venv/mad philes.py", line 5, in <module>
t1 = b"axf1".decode("ascii")
UnicodeDecodeError: 'ascii' codec can't decode byte 0xf1 in position 1: ordinal not in range(128)
To rectify the error, an encoding scheme would be used that would be sufficient to represent the xf1 code point. In this case, the unicode_escape coding scheme would be used:
Python3
t1 = b"axf1".decode("unicode_escape")
print(t1)
Output:
añ
How to Resolve a UnicodeDecodeError for a CSV file
It is common to encounter the error mentioned above when processing a CSV file. This is because the CSV file may have a different encoding than the one used by the Python program. To fix such an error, the encoding used in the CSV file would be specified while opening the file. If the encoding standard of the CSV file is known, the Python interpreter could be instructed to use a specific encoding standard while that CSV file is being opened. This method is only usable if the encoding of the CSV is known.
To demonstrate the occurrence of the error, the following CSV file will be used:
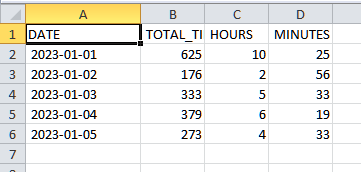
The encoding of the CSV file is UTF-16
Generating UnicodeDecodeError for a CSV file
The following code attempts to open the CSV file for processing. The above code, upon execution, led to the following error:
Python3
import pandas as pd
path = "test.csv"
file = pd.read_csv(path)
print(file.head())
Output:

Understanding the Problem
The error occurred as the read_csv method could not decode the contents of the CSV file by using the default encoding, UTF-8. This is because the encoding of the file is UTF-16. Hence the encoding of the CSV file needs to be mentioned while opening the CSV file to fix the error and allow the processing of the CSV file.
Solution
Firstly, the pandas‘ library is imported, and the path to the CSV file is specified. Then the program calls the read_csv function to read the contents of the CSV file specified by the path and also passes the encoding through which the CSV file must be decoded (UTF-16 in this case). Since the decoding scheme mentioned in the argument is the one with which the CSV file was originally encoded, the file gets decoded successfully.
Python3
import pandas as pd
path = "test.csv"
file = pd.read_csv(path, encoding="utf-16")
print(file.head())
Output:

Alternate Method to Solve UnicodeDecodeError
Another way of resolving the issue is by changing the encoding of the CSV file itself. For that, firstly, open the CSV file as a text file (using notepad or Wordpad):

Now go to file and select Save as:

A prompt would appear, and from there, select the encoding option and change it to UTF-8 (the default for Python and pandas), and select Save.
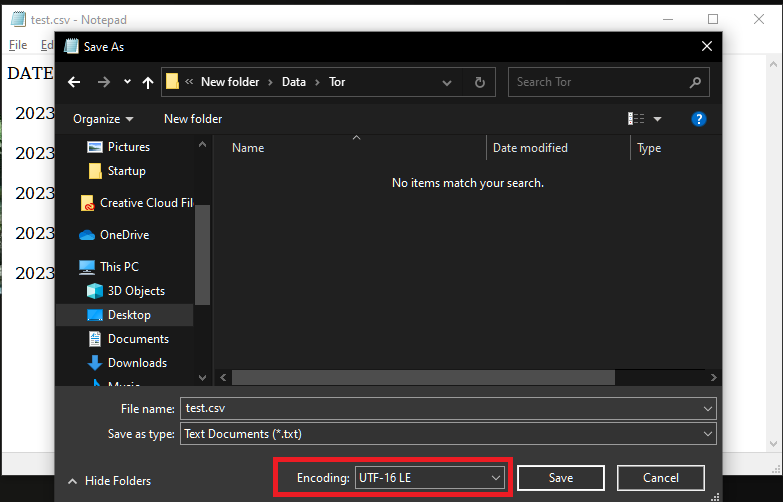

Now the following code would run without errors
The code ran without errors. This is because the default encoding of the CSV file was changed to UTF-8 before opening it with pandas. Since the default encoding used by pandas is UTF-8, the CSV file opened without error.
Python3
import pandas as pd
path = "test.csv"
file = pd.read_csv(path)
print(file.head())
Output:
- Unicode Decode Error in Python
- How to Solve the Unicode Decode Error in Python

In this article, we will learn how to resolve the UnicodeDecodeError that occurs during the execution of the code. We will look at the different reasons that cause this error.
We will also find ways to resolve this error in Python. Let’s begin with what the UnicodeDecodeError is in Python.
Unicode Decode Error in Python
If you are facing a recurring UnicodeDecodeError and are unsure of why it is happening or how to resolve it, this is the article for you.
In this article, we go in-depth about why this error comes up and a simple approach to resolving it.
Causes of Unicode Decode Error in Python
In Python, the UnicodeDecodeError comes up when we use one kind of codec to try and decode bytes that weren’t even encoded using this codec. To be more specific, let’s understand this problem with the help of a lock and key analogy.
Suppose we created a lock that can only be opened using a unique key made specifically for that lock.
What happens when you would try and open this lock with a key that wasn’t made for this lock? It wouldn’t fit.
Let’s create the file example.txt with the following contents.
Let’s attempt to decode this file using the ascii codec using the following code.
Example 1:
with open('example.txt', 'r', encoding='ascii') as f:
lines = f.readlines()
print(lines)
The output of the code:
Traceback (most recent call last):
File "/home/fatina/PycharmProjects/examples/main.py", line 2, in <module>
lines = f.readlines()
File "/usr/lib/python3.10/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xf0 in position 0: ordinal not in range(128)
Let’s look at another more straightforward example of what happens when you encode a string using one codec and decode using a different one.
Example 2:
string = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ'
encoded_string = string.encode('utf-8')
decoded_string = encoded_string.decode('ascii')
print(decoded_string)
In this example, we have a string encoded using the utf-8 codec, and in the following line, we try to decode this string using the ascii codec.
The output of the code:
Traceback (most recent call last):
File "/home/fatina/PycharmProjects/examples/main.py", line 4, in <module>
decoded_string = encoded_string.decode('ascii')
UnicodeDecodeError: 'ascii' codec can't decode byte 0xf0 in position 0: ordinal not in range(128)
This happens because the contents of the file in example 1 and the string in example 2 were not encoded using the ascii codec, but we tried decoding these scripts using it. This results in the UnicodeDecodeError.
How to Solve the Unicode Decode Error in Python
Resolving this issue is rather straightforward. If we explore Python’s documentation, we will see several standard codecs available to help you decode bytes.
So if we were to replace ascii with the utf-8 codec in the example codes above, it would have successfully decoded the bytes in example.txt.
Example code:
with open('example.txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
print(lines)
The output of the code:
['𝘈Ḇ𝖢𝕯٤ḞԍНǏn', 'hello world']
As for the second example, you need only to do the same thing.
Example code:
string = '𝘈Ḇ𝖢𝕯٤ḞԍНǏ'
encoded_string = string.encode('utf-8')
decoded_string = encoded_string.decode('utf-8')
print(decoded_string)
The output of the code:
It is important to mention that sometimes a string may not be completely decoded using one codec.
So if the need arrives, you can develop your program to ignore any characters that it cannot decode by simply adding the ignore argument like this:
with open('example.txt', 'r', encoding='utf-8', errors='ignore') as f:
lines = f.readlines()
print(lines)
While this will skip any errors the compiler encounters while decoding some characters, it is important to mention that this can result in data loss.
We hope you find this article helpful in understanding how to resolve the UnicodeDecodeError in Python.
In this post, you can find several solutions for:
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
While this error can appear in different situations the reason for the error is one and the same:
- there are special characters( escape sequence — characters starting with backslash — » ).
- From the error above you can recognize that the culprit is ‘U’ — which is considered as unicode character.
- another possible errors for SyntaxError: (unicode error) ‘unicodeescape’ will be raised for ‘x’, ‘u’
- codec can’t decode bytes in position 2-3: truncated xXX escape
- codec can’t decode bytes in position 2-3: truncated uXXXX escape
- another possible errors for SyntaxError: (unicode error) ‘unicodeescape’ will be raised for ‘x’, ‘u’
Step #1: How to solve SyntaxError: (unicode error) ‘unicodeescape’ — Double slashes for escape characters
Let’s start with one of the most frequent examples — windows paths. In this case there is a bad character sequence in the string:
import json
json_data=open("C:Userstest.txt").read()
json_obj = json.loads(json_data)
The problem is that U is considered as a special escape sequence for Python string. In order to resolved you need to add second escape character like:
import json
json_data=open("C:\Users\test.txt").read()
json_obj = json.loads(json_data)
Step #2: Use raw strings to prevent SyntaxError: (unicode error) ‘unicodeescape’
If the first option is not good enough or working then raw strings are the next option. Simply by adding r (for raw string literals) to resolve the error. This is an example of raw strings:
import json
json_data=open(r"C:Userstest.txt").read()
json_obj = json.loads(json_data)
If you like to find more information about Python strings, literals
2.4.1 String literals
In the same link we can find:
When an r' or R’ prefix is present, backslashes are still used to quote the following character, but all backslashes are left in the string. For example, the string literal r»n» consists of two characters: a backslash and a lowercase `n’.
Step #3: Slashes for file paths -SyntaxError: (unicode error) ‘unicodeescape’
Another possible solution is to replace the backslash with slash for paths of files and folders. For example:
«C:Userstest.txt»
will be changed to:
«C:/Users/test.txt»
Since python can recognize both I prefer to use only the second way in order to avoid such nasty traps. Another reason for using slashes is your code to be uniform and homogeneous.
The picture below demonstrates how the error will look like in PyCharm. In order to understand what happens you will need to investigate the error log.
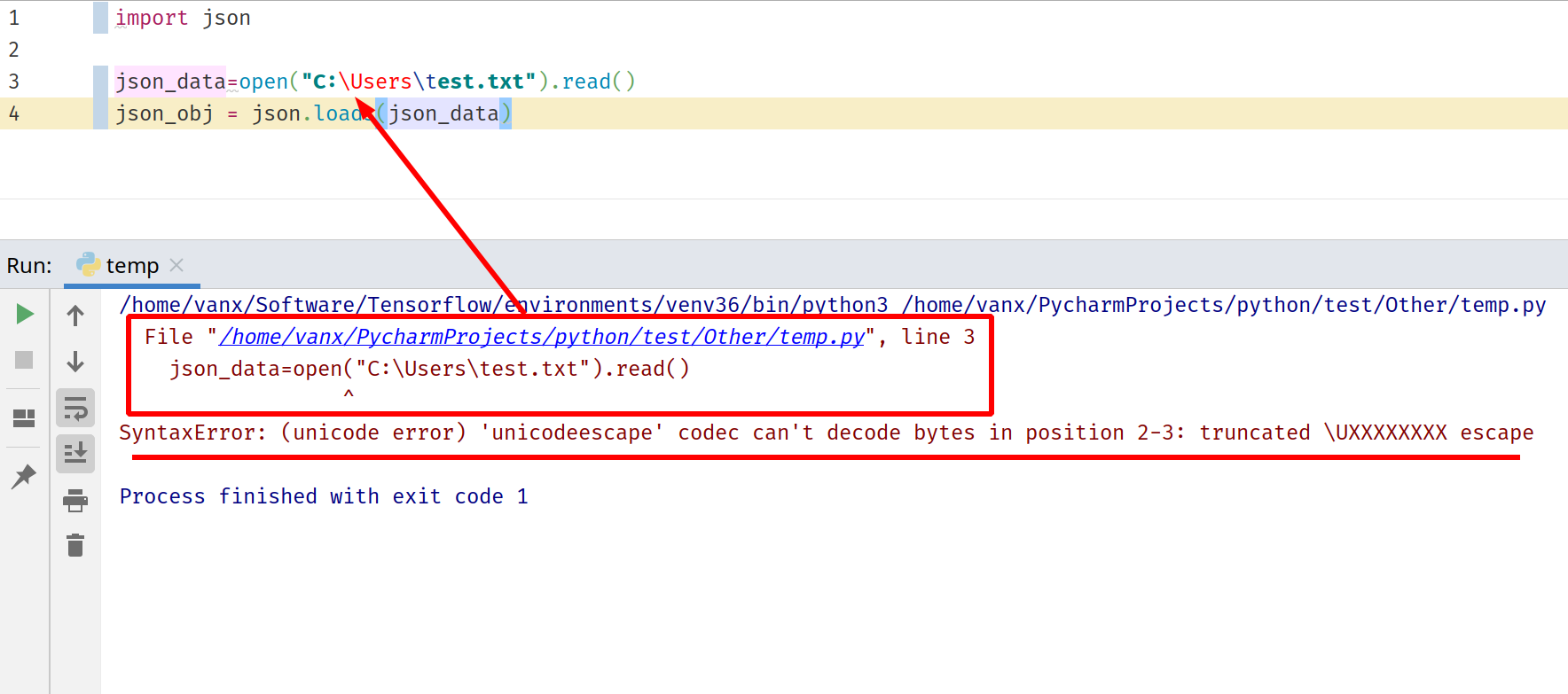
The error log will have information for the program flow as:
/home/vanx/Software/Tensorflow/environments/venv36/bin/python3 /home/vanx/PycharmProjects/python/test/Other/temp.py
File "/home/vanx/PycharmProjects/python/test/Other/temp.py", line 3
json_data=open("C:Userstest.txt").read()
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated UXXXXXXXX escape
You can see the latest call which produces the error and click on it. Once the reason is identified then you can test what could solve the problem.
От переводчика: Armin Ronacher довольно известный разработчик в Python-сообществе(Flask,jinja2,werkzeug).
Он довольно давно начал своеобразный крестовый поход против Python3, но обвинить его в истерике и ретроградстве не так-то просто: его возражения продиктованы серьезным опытом разработки, он довольно подробно аргументирует свою точку зрения. Немного о терминологии:
coercion я перевел как принудительное преобразование кодировок, а byte string как байтовые строки, так как термин «сырые» строки(raw string) все же означает несколько иное.
«Историческое» примечание: в 2012 г. Армин предложил PEP 414, который содержал ряд мер по устранению проблем с Unicode, PEP подтвердили довольно быстро, однако воз и ныне там, так как нижеприведенный текст написан 5 января 2014 года
Все труднее становиться вести обоснованную дискуссию о различиях между Python 2 и 3, так как один язык уже мертв,
а второй активно развивается. Когда кто-либо начинает обсуждение поддержки Unicode в двух ветках Python — это весьма сложная тема. Вместо рассмотрения поддержки Unicode в двух версиях языка, я рассмотрю базовую модель обработки текста и байтовых строк.
В данном посте я покажу на примере решений разработчиков языка и стандартной библиотеки,
что Python 2 лучше подходит для работы с текстом и байтовыми строками.
С тех пор как мне пришлось сопровождать большое количество кода, который напрямую работал с преобразованием между байтовыми строками и Unicode, ухудшения, произошедшие в Python3, вызвали у меня много печали. Особенно меня раздражают материалы основной команды разработчиков python, которые призывают меня верить, что python 3 лучше 2.7.
Модель представления текста
Главное различие между Python 2 и Python 3 —базовые типы, существующие для работы со строками и байтовыми строками. В Python 3 мы имеем один строковый тип: str, который хранит данные в Unicode, и два байтовых типа: bytes и bytearray.
С другой стороны, в Python 2 у нас есть два строковых типа: str, который достаточен для любых целей и задач, ограниченных строками в кодировке ASCII + некоторыми неопределенными данными, превышающими интервал в 7 бит. Вместе с типом str у Python2 есть тип данныхunicode, эквивалентный типу данных str Python 3. Для работы с байтами в Python 2 есть один тип:bytearray, взятый из Python 3. Присмотревшись к ситуации, вы можете заметить, что из Python 3 кое-что удалили: поддержку строковых данных не в юникоде.Компенсацией жертвоприношения стал хешируемый байтовый тип данных(bytes). Тип данных bytarray изменяемый, а поэтому он не может быть хеширован. Я очень редко, использую бинарные данные как ключи словаря, а потому возможность или невозможность хеширования бинарных данных не кажется мне очень серьезной. Особенно в Python 2, так как байты могут быть без каких-либо проблем помещены в переменную типа str.
Потерянный тип
Из Python 3 исключают поддержку байтовых строк, которые в ветке 2.x были типом str. На бумаге в этом решении нет ничего плохого. С академической точки зрения строки, всегда представленные в юникоде, это прекрасно. И это действительно так, если целый мир — это ваш интерпретатор. К сожалению, в реальном мире, все происходит по-другому: вы вынуждены регулярно работать с разными кодировками, в этом случае подход Python 3 к работе со строками трещит по швам.
Буду честен перед вами: то как Python 2 обрабатывает Unicode провоцирует ошибки, и я полностью одобряю улучшения обработки Unicode. Моя позиция в том, что, то как это делается в Python 3, является шагом назад и порождает еще больше ошибок, а потому я абсолютно ненавижу работать с Python 3.
Ошибки при работе с Unicode
Прежде чем я погружусь в детали, мы должны понять разницу поддержки Unicode в Python 2 и 3,
а так же то, почему разработчики приняли решение поменять механизм поддержки Unicode.
Изначально Python 2 как и многие иные языки до него создавался без поддержки обработки сток разных кодировок.
Строка и есть строка, она содержит байты. Это требовало от разработчиков корректно работать с различными
кодировками вручную. Это было вполне приемлемо для многих ситуаций. Многие годы веб-фреймворк Django
не работал с Unicode, а использовал исключительно байтовые строки.
Тем временем Python 2 годами улучшал внутреннюю поддержку Unicode. Улучшение поддержки Unicode
позволяло использовать его для единообразного представления данных в различных кодировках.
Подход к обработке строк, использующих определенную кодировку, в Python 2 довольно прост:
вы берете строку (байтовую), которую вы могли получить откуда угодно, а затем преобразуете
ее из той кодировки, которая характерна для источника строки(метаданные, заголовки, иные)
в строку Unicode. Став Unicode строкой, она поддерживает все те же операции
что и байтовая, но теперь она может хранить больший диапазон символов.
Когда вам необходимо передать строку на обработку куда-либо еще, то вы снова
преобразуете ее в ту кодировку, которая используется принимающей стороной,
и перед нами вновь байтовая строка
Какие же особенности связаны с таким подходом? Для того, чтобы это работало на уровне ядра языка,
Python 2 должен предоставлять способ перехода из мира без Unicode в прекрасный мир с Unicode.
Это возможно благодаря принудительному преобразованию байтовых и небайтовых строк. Когда это происходит
и как этот механизм работает?
Основной момент заключается в том, что когда байтовая строка участвует в одной операции с Unicode строкой,
то байтовая строка преобразуется в Unicode строку при помощи неявного процесса декодирования строки, который использует кодировку «по умолчанию». Данной кодировкой по умолчанию считается ASCII. Python предоставлял возможность менять кодировку по умолчанию, используя один модуль, но теперь из модуля site.py удалили функции для изменения кодировки по умолчанию, она устанавливается в ASCII. Если запустить интерпретатор с флагом -s, то функция sys.setdefaultencoding будет вам доступна и вы сможете поэкспериментировать, чтобы выяснить что произойдет, если вы выставите кодировкой по умолчанию UTF-8. В некоторых ситуациях при работе с кодировкой по умолчанию могут возникнуть проблемы:
1. неявное задание и преобразование кодировки при конкатенации:
>>> "Hello " + u"World"
u'Hello World'
Здесь левая строка преобразуется, используя кодировку «по умолчанию», в Unicode строку. Если строка содержит не ASCII символы, то при нормальной ситуации выполнения программы преобразование останавливается с выбросом исключения UnicodeDecodeError, так как кодировка по умолчанию — ASCII
2. Неявное задание и преобразование кодировки при сравнении строк
>>> "Foo" == u"Foo"
True
Это звучит опаснее чем есть на самом деле. Левая часть преобразуется в Unicode, а затем происходит сравнение. В случае, если левая сторона не может быть преобразована, интерпретатор выдает предупреждение, а строки считаются неравными(возвращается False в качестве результата сравнения). Это вполне здравое поведение, если даже при первом знакомстве с ним так не кажется.
3. Явное задание и преобразование кодировки, как часть механизма с использованием кодеков.
Это одна из наиболее зловещих вещей и наиболее распостраненный источник всех неудач и недопониманий Unicode в Python 2. Для предоления проблем в этой области в Python 3 предприняли безумный шаг, удалив метод .decode() у Unicode строк и метод .encode() у байтовых строк, это вызвало наибольшее непонимание и досаду у меня. С моей точки зрения это очень глупое решение, но мне много раз говорили что это я ничего не понимаю, возврата назад не будет.
Явное преобразование кодировки при работе с кодеками выглядит так:
>>> "foo".encode('utf-8')
'foo'
Это строка, очевидно, является байтовой строкой. Мы требуем ее преобразовать в UTF-8. Само по себе эnо бессмысленно, так как UTF-8 кодек преобразует строку из Unicode в байтовую строку с кодировкой UTF-8. Как же это работает? UTF-8 кодек видит, что строка не является Unicode строка, а поэтому сначала выполняется принудительное преобразование к Unicode. Пока «foo» только ASCII данные и кодировка по умолчанию ASCII, принудительное преобразование происходит успешно, а уже после этого Unicode строка u«foo» преобразуется в UTF-8.
Механизм кодеков
Теперь вы знаете что Python 2 имеет два подхода к представлению строк: байтами и Unicode. Преобразование между этими представлениями осуществляется при помощи механизма кодеков. Данный механизм не навязывает схему преобразования Unicode->byte или на нее похожую. Кодек может производить преобразование byte->byte или Unicode->Unicode. Фактически система кодеков может реализовывать преобразование между любыми типами Python. Вы можете иметь JSON кодек, который производит преобразование строки в сложный Python объект на ее основе, если сочтете, что такое преобразование вам необходимо.
Такое положение дел может вызвать проблемы с пониманием механизма, начиная с его основ. Примером этого может быть кодек с названием ‘undefined’, который может быть установлен в качестве кодировки по умолчанию. В этом случае любые принудительные преобразования кодировок строк будут отключены:
>>> import sys
>>> sys.setdefaultencoding('undefined')
>>> "foo" + u"bar"
Traceback (most recent call last):
raise UnicodeError("undefined encoding")
UnicodeError: undefined encoding
И как же в Python 3 решают проблему с кодеками? Python 3 удаляет все кодеки, которые не выполняют преобразования вида: Unicode<->byte, а кроме того уже ненужные сейчас метод байтовых строк .encode() и строковый метод .decode(). Это очень плохое решение, так как было очень
много полезных кодеков. Например очень распространено использовать преобразование с помощью hex кодека в Python 2:
>>> "x00x01".encode('hex')
'0001'
Пока вы можете сказать, что в данном конкретном случае задача может быть решена при помощи модуля подобного binascii, но проблема более глубока, модули с кодеками доступны отдельно. Например библиотеки, реализующие чтение из сокетов, используют кодеки для частичного преобразования данных из потоков данных библиотеки zlib:
>>> import codecs
>>> decoder = codecs.getincrementaldecoder('zlib')('strict')
>>> decoder.decode('xx9cxf3Hxcdxc9xc9Wp')
'Hello '
>>> decoder.decode('xcdKxceOxc9xccK/x06x00+xadx05xaf')
'Encodings'
В конце концов, проблема была признана и в Python 3.3 восстановили эти кодеки. Однако сейчас мы снова вводим пользователя в неразбериху, так как кодеки до вызова функций не предоставляют метаинформации о тех типа, которые они могут обработать. По этой причине Python теперь может выбрасывать следующие исключения:
>>> "Hello World".encode('zlib_codec')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' does not support the buffer interface
(Обратите внимание, что кодек теперь называется zlib_codec вместо zlib, так как Python 3.3 не сохранил старых обозначений для кодеков)
А что произойдет, если мы вернем назад метод .encode() для байтовых строк, например? Это легко проверить даже без хаков интерпретатора Python. Напишем функцию с аналогичным поведением:
import codecs
def encode(s, name, *args, **kwargs):
codec = codecs.lookup(name)
rv, length = codec.encode(s, *args, **kwargs)
if not isinstance(rv, (str, bytes, bytearray)):
raise TypeError('Not a string or byte codec')
return rv
Теперь мы можем использовать эту функцию как замену метода .encode() байтовых строк:
>>> b'Hello World'.encode('latin1')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'bytes' object has no attribute 'encode'
>>> encode(b'Hello World', 'latin1')
Traceback (most recent call last):
File "<stdin>", line 4, in encode
TypeError: Can't convert 'bytes' object to str implicitly
Ага! Python 3 уже умеет работать с такой ситуацией. Мы получаем красивое оповещение об ошибке. Я считаю, что даже “Can’t convert ‘bytes’ object to str implicitly” гораздо лучше и понятней чем “’bytes’ object has no attribute ‘encode’”.
Почему бы не вернуть эти методы преобразования кодировки(encode и decode) назад? Я действительно не знаю и не думаю больше об этом. Мне уже многократно объясняли что я ничего не понимаю и я не понимаю новичков, или, то что «текстовая модель» изменилась и мои требования к ней бессмысленны.
Байтовые строки потеряны
Теперь вслед за регрессией системы кодеков изменились и строковые операции: они определены лишь для строк Unicode. На первый взгляд это выглядит вполне разумно, но на самом деле это не так. Раньше интерпретатор имел реализации для операций над байтовыми и Unicode строками. Этот подход был совершенно очевиден дял программистов, если объекту нужно было иметь представление в виде байтовой или Unicode строки, определялось два метода:__str__ and __unicode__. Да, конечно, использовалось принудительное изменение кодировки, которое смущало новичков, но зато у нас был выбор.
Почему это полезно? Потому что, к примеру, если вы работаете с низкоуровневыми протоколами, вам часто необходимо иметь дело с числами в определенном фоормате внутри байтовой строки.
Собственная система контроля версий, используемая разработчиками Python, не работает на Python 3, потому что годами команда разработки Python не хочет вернуть возможность форматирования для байтовых строк.
Все вышеописанное показывает: модель обработки строковых данных Python 3 не работает в реальном мире. К примеру в Python 3 «обновили» некоторые API, сделав их работающими только с Unicode, а потому они полностью непригодны для применения в реальных рабочих ситуациях. К примеру теперь вы не можете больше анализировать байты с помощью стандартной библиотеки, но только URL. Причина этого в неявном предположении, что все URL представлены лишь в Unicode (при таком положении дел вы уже не сможете работать с почтовыми сообщениями в не Unicode кодировке, если не будете полностью игнорировать существование бинарных вложений в письмо).
Раньше такое было довольно легко исправить, но так как ныне байтовые строки потеряны для разработчиков, библиотека обработки URL имеет ныне две реализации. Одна для Unicode, а вторая для байтовых объектов. Две реализации для одной и той же функции ведут к тому что результат обработки данных может быть очень разным:
>>> from urllib.parse import urlparse
>>> urlparse('http://www.google.com/')
ParseResult(scheme='http', netloc='www.google.com',
path='/', params='', query='', fragment='')
>>> urlparse(b'http://www.google.com/')
ParseResultBytes(scheme=b'http', netloc=b'www.google.com',
path=b'/', params=b'', query=b'', fragment=b'')
Выглядит достаточно похоже? Вовсе нет, потому что в результате мы имеем совершенно разные типы данных у результата операции.
Один из них это кортеж строк, второй больше похож на массив целых чисел. Я уже писал об этом ранее и подобное состояние вызывает у меня страдания. Теперь написание кода на Python доставляет мне серьезный дискомфорт или становится крайне неэффективным, так как вам теперь приходится пройти через большое количество преобразований кодировок данных. Из-за этого становится очень сложно писать код, реализующий все необходимые функции. Идея что все Unicode очень хороша в теории, но полностью неприменима на практике.
Python 3 пронизан кучей костылей для обработки ситуаций, где обрабатывать Unicode невозможно, а у таких как я, которые много работают с такими ситуациями, все это вызывает жуткое раздражение.
Наши костыли не работают
Поддержка Unicode в ветке 2.х неидеальна и далека от идеала. Это отсутсвующие API, проблемы, приходящие с разных сторон, но мы как программисты делали все это рабочим. Многие методы, которыми мы это делали ранее больше невозможно применить в Python 3, а некоторые API будут изменены, чтобы хорошо работать с Python 3.
Мой любимый пример это обработка файловых потоков, которые могли быть как байтовыми, так и текстовыми, но не было надежного метода определить какой перед нами тип потока. Трюк, который я помог популяризировать это чтение нулевого количества байт из потока для определения его типа. Теперь этот трюк не работает. К примеру передача объекта запроса библиотеки urllib функции Flask, которая обрабатывает JSON, не работает в Python 3, но работает в Python 2:
>>> from urllib.request import urlopen
>>> r = urlopen('https://pypi.python.org/pypi/Flask/json')
>>> from flask import json
>>> json.load(r)
Traceback (most recent call last):
File "decoder.py", line 368, in raw_decode
StopIteration
В ходе обработки выбрашенного исключения выбрасывается еще одно:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: No JSON object could be decoded
И что же?
Кроме тех проблем, что я описал выше у Python 3 с поддержкой Unicode есть и куча других проблем. Я начал отписываться от твиттеров разработчиков Python потому что мне надоело читать какой Python 3 замечательный, так как это противоречит моему опыту. Да, в Python 3 много плюшек, но то как поступили с обработкой байтовых строк и Unicode к ним не относится.
(Хуже всего то, что многие действительно крутые возможности Python 3 обычно столь же хорошо работают и в Python 2. Например yield from, nonlocal, поддержка SNI SSL и т.д. )
В свете того, что только 3% разработчиков Python активно используют Python 3, а разработчики Python в Twitter громогласно заъявляют что миграция на Python 3 идет как и планировалось, я испытываю разочарование, так как подробно описывал свой опыт с Python 3 и как от последнего хочется избавиться.
Я не хочу это делать сейчас, но желаю, чтобы команда разработчиков Python 3 чуть больше прислушалась к мнению сообщества. Для 97% из нас, Python 2, уютненький мирок, в котором мы работали годами, а потому довольно болезненно воспринимается ситуация, когда к нам приходят и заъявляют: Python 3 — прекрасен и это не обсуждается. Это и просто не так в свете множества регрессий. Вместе с теми людьми, которые начинают обсуждать Python 2.8 и Stackless Python 2.8 я не знаю что такое провал, если это не он.
Python 2.7. Unicode Errors Simply Explained
I know I’m late with this article for about 5 years or so, but people are still using Python 2.x, so this subject is relevant I think.
Some facts first:
- Unicode is an international encoding standard for use with different languages and scripts
- In python-2.x, there are two types that deal with text.
stris an 8-bit string.unicodeis for strings of unicode code points.
A code point is a number that maps to a particular abstract character. It is written using the notation U+12ca to mean the character with value 0x12ca (4810 decimal)
- Encoding (noun) is a map of Unicode code points to a sequence of bytes. (Synonyms: character encoding, character set, codeset). Popular encodings: UTF-8, ASCII, Latin-1, etc.
- Encoding (verb) is a process of converting
unicodeto bytes ofstr, and decoding is the reverce operation. - Python 2.x uses ASCII as a default encoding. (More about this later)
SyntaxError: Non-ASCII character
When you sees something like this
SyntaxError: Non-ASCII character 'xd0' in file /tmp/p.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
you just need to define encoding in the first or second line of your file.
All you need is to have string coding=utf8 or coding: utf8 somewhere in your comments.
Python doesn’t care what goes before or after those string, so the following will work fine too:
# -*- encoding: utf-8 -*-
Notice the dash in utf-8. Python has many aliases for UTF-8 encoding, so you should not worry about dashes or case sensitivity.
UnicodeEncodeError Explained
>>> str(u'café') Traceback (most recent call last): File "<input>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode character u'xe9' in position 3: ordinal not in range(128)
str() function encodes a string. We passed a unicode string, and it tried to encode it using a default encoding, which is ASCII. Now the error makes sence because ASCII is 7-bit encoding which doesn’t know how to represent characters outside of range 0..128.
Here we called str() explicitly, but something in your code may call it implicitly and you will also get UnicodeEncodeError.
How to fix: encode unicode string manually using .encode('utf8') before passing to str()
UnicodeDecodeError Explained
>>> utf_string = u'café' >>> byte_string = utf_string.encode('utf8') >>> unicode(byte_string) Traceback (most recent call last): File "<input>", line 1, in <module> UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 3: ordinal not in range(128)
Let’s say we somehow obtained a byte string byte_string which contains encoded UTF-8 characters. We could get this by simply using a library that returns str type.
Then we passed the string to a function that converts it to unicode. In this example we explicitly call unicode(), but some functions may call it implicitly and you’ll get the same error.
Now again, Python uses ASCII encoding by default, so it tries to convert bytes to a default encoding ASCII. Since there is no ASCII symbol that converts to 0xc3 (195 decimal) it fails with UnicodeDecodeError.
How to fix: decode str manually using .decode('utf8') before passing to your function.
Rule of Thumb
Make sure your code works only with Unicode strings internally, converting to a particular encoding on output, and decoding str on input.
Learn the libraries you are using, and find places where they return str. Decode str before return value is passed further in your code.
I use this helper function in my code:
def force_to_unicode(text): "If text is unicode, it is returned as is. If it's str, convert it to Unicode using UTF-8 encoding" return text if isinstance(text, unicode) else text.decode('utf8')
Source: https://docs.python.org/2/howto/unicode.html
Agenda
- Understanding the basics of Python ‘unicode’ and ‘str’ type
- Deliberately causing UnicodeEncodeError and UnicodeDecodeError and fixing it.
- A practical example showing how encoding issues can trip you.
To follow along easily, it would help if you understand concept of unicode, encoding and decoding in general. Please refer to our last blog to understand the basics of unicode and encoding.
This post assumes you use Python 2.7 and this will not be useful if you are using Python 3.
Basics
Make sure your terminal encoding is set to utf-8.
As discussed in last post, Unicode is just a standard which gives codepoint for different characters. You cannot store codepoint of a character on disk. Codepoint of the character must be encoded using some encoding scheme before it can be stored in a file.
Codepoints are integers. eg: Codepoint of character ‘a’ is U+0061 which is integer 97. This codepoint has a different binary representation in different encoding schemes. Or other way of saying it is, this codepoint has different byte sequence in different encoding schemes. And the byte sequence gets written to disk when we write ‘a’ to a file.
Codepoint of ‘ä’ is U+00E4, which is integer 228. This codepoint has a different binary representation, or byte sequence, in different encoding schemes.
Usually binary representation will not be shown to you. The binary representation would be converted to a hexadecimal number in the output. eg: In ‘utf-8’ encoding, ‘ä’ is represented by ‘11000011 10100100’. But most of the times you will see it’s hexadecimal equivalent which is ‘c3a4’, written as ‘xc3xa4’.
Python has two different datatypes. One is ‘unicode’ and other is ‘str’. Type ‘unicode’ is meant for working with codepoints of characters. Type ‘str’ is meant for working with encoded binary representation of characters.
A ‘unicode’ object needs to be converted to ‘str’ object before Python can write the character to a file. A ‘unicode’ object needs to be converted to ‘str’ object for the character to be printed.
We will use a character which has different binary representation in different encoding schemes. ä is one such character. This character is called ‘LATIN SMALL LETTER A WITH DIAERESIS’.
Codepoint for this character is U+00E4. You can check it at http://www.utf8-chartable.de/
The way to define a Unicode codepoint is:
>>> uni_latin_a = u'u00e4'
Check it’s type:
>>> type(uni_latin_a)
<type 'unicode'>
A unicode starts with ‘u’ followed by quote and the codepoint has to be preceded by ‘u’.
Let’s define a ‘str’.
Check it’s type:
>>> type(str_normal_a)
<type 'str'>
UnicodeEncodeError
Let’s try to convert ‘unicode’ to ‘str’
>>> str_latin_a = uni_latin_a.encode()
Traceback (most recent call last):
File "<ipython-input-22-b3d11d4d77fd>", line 1, in <module>
str_latin_a = uni_latin_a.encode()
UnicodeEncodeError: 'ascii' codec can't encode character u'xe4' in position 0: ordinal not in range(128)
When ‘encode()’ is called, by default ascii encoding scheme is used. So ‘encode()’ is equivalent to ‘encode(‘ascii’)’. ascii can only encode characters whose codepoint is less than 128. uni_latin_a represents a character whose codepoint is greater than 128. And so we get a UnicodeEncodeError.
utf-8 encoding scheme can encode codepoints greater than 128. Let’s use ‘utf-8’ to encode uni_latin_a.
>>> str_latin_a = uni_latin_a.encode('utf-8')
This passes. Let’s check the type of str_latin_a.
>>> type(str_latin_a)
<type 'str'>
“encode()” is meant to be used on a ‘unicode’ to get a ‘str’. Make sure you are call ‘encode()’ on a ‘unicode’ and never call it on a ‘str’.
Let’s see the hexadecimal representation of str_latin_a.
>>> str_latin_a
'xc3xa4'
So, utf-8 representation of codepoint ‘U+00E4’ is ‘xc3xa4’. You can also verify it at the table provided at http://www.utf8-chartable.de/.
A ‘unicode’ cannot be written to a file.
>>> f = open('uni_latin_a.txt', 'w')
>>> f.write(uni_latin_a)
Traceback (most recent call last):
File "<ipython-input-21-38c6475cde9f>", line 1, in <module>
f.write(uni_latin_a)
UnicodeEncodeError: 'ascii' codec can't encode character u'xe4' in
position 0: ordinal not in range(128)
A ‘unicode’ object must be encoded to get it’s binary representation, and then encoded binary representation gets written to the file.
Python is trying to do implicit encoding here. Python can only write ‘str’ to a file. Since we are passing a ‘unicode’ to write, python tries to convert the ‘unicode’ into ‘str’. Internally Python runs f.write(uni_latin_a.encode(‘ascii’)).
ascii encoding scheme can only encode characters whose codepoint is less than 128. uni_latin_a represents a character whose codepoint is greater than 128. And so we get a UnicodeEncodeError.
Encode uni_latin_a using utf-8 so it can be written:
>>> str_latin_a = uni_latin_a.encode('utf-8')
>>> f.write(str_latin_a)
>>> f.close()
Check uni_latin_a.txt in your editor. If your editor understands utf-8 encoded strings, it will show the expected character.
UnicodeDecodeError
UnicodeDecodeError will usually happen when you try to process something read from a file.
We just wrote a utf-8 encoded character to ‘uni_latin_a.txt’. Let’s read this file.
>>> f = open('uni_latin_a.txt')
>>> read_str_latin_a = f.read()
>>> f.close()
>>> print read_str_latin_a
ä
>>> type(read_str_latin_a)
<type 'str'>
‘type()’ verifies that whenever we read from a file, we get an instance of ‘str’, and not an instance of ‘unicode’.
Let’s see the hexadecimal representation of read_str_latin_a
>>> read_str_latin_a
'xc3xa4'
Several times it makes sense to work with Unicode internally and in such case we will need to convert the read value into unicode.
Decoding is the process of converting an encoded representation into Unicode codepoint.
‘.decode()’ is meant to convert from ‘str’ to ‘unicode’. Always use ‘.decode()’ on a ‘str’. Never use it on ‘unicode’ object.
Let’s try converting read_str_latin_a to a ‘unicode’ object.
>>> read_uni_latin_a = read_str_latin_a.decode()
Traceback (most recent call last):
File "<ipython-input-14-adfeb64a792b>", line 1, in <module>
read_uni_latin_a = read_str_latin_a.decode()
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 0: ordinal not in range(128)
When ‘.decode()’ is called, Python default thinks that the string was encoded using ‘ascii’. So it tries to find the Unicode codepoint which corresponds to this encoded representation. In ascii, no Unicode codepoint corrresponds to ‘xc3xa4’ and so an error is raised.
We already know that encoding was done using ‘utf-8’ when writing to the file. So use ‘utf-8’ with decode().
>>> read_uni_latin_a = read_str_latin_a.decode('utf-8')
>>> print read_uni_latin_a
ä
Suppose we did not know that the file content was encoded with ‘utf-8’. In that case, we could have tried decoding it with latin-5 or any other encoding scheme. Suppose we try latin-5.
>>> read_uni_latin_a = read_str_latin_a.decode('8859')
>>> print read_uni_latin_a
ä
What happened here?
See what read_str_latin_a is:
>>> read_str_latin_a
'xc3xa4'
In encoding scheme 8859, U+00C3 when encoded gives hexadecimal ‘xc3’ and U+00A4 when encoded gives hexadecimal ‘xa4’. So when ‘xc3xa4’ is decoded, it gives back codepoints U+00C3 and U+00A4. Codepoint U+00C3 means ‘Ã’ and codepoint U+00A4 means ‘¤’. And that’s what we see in output.
That’s why it’s important to know the encoding of a file otherwise we will read it wrong.
Takeaway
-
Unicode codepoints can be stored in type ‘unicode’. When unicode codepoints are defined, they are stored in ‘unicode’ and haven’t been converted to a particular encoding.
-
Unicodes are prepended with u’’. When we do this, python understands that we want to store the codepoint of the character/string.
-
Make sure you .encode() a unicode and not a string.
-
Make sure you .decode() a string and not a unicode.
This post is becoming big, so I am putting practical example where unicode can trip you in next post.
Thank you for reading the Agiliq blog. This article was written by Akshar on Dec 8, 2014 in
python
.
You can subscribe ⚛ to our blog.
We love building amazing apps for web and mobile for our clients. If you are looking for development help, contact us today ✉.
Would you like to download 10+ free Django and Python books?
Get them here
