Learn Bash error handling by example
Posted: June 29, 2021 |

In this article, I present a few tricks to handle error conditions—Some strictly don’t fall under the category of error handling (a reactive way to handle the unexpected) but also some techniques to avoid errors before they happen.
Case study: Simple script that downloads a hardware report from multiple hosts and inserts it into a database.
Say that you have a cron job on each one of your Linux systems, and you have a script to collect the hardware information from each:
If everything goes well, then you collect your files in parallel because you don’t have more than ten systems. You can afford to ssh to all of them at the same time and then show the hardware details of each one.
Here are some possibilities of why things went wrong:
- Your report didn’t run because the server was down
- You couldn’t create the directory where the files need to be saved
- The tools you need to run the script are missing
- You can’t collect the report because your remote machine crashed
- One or more of the reports is corrupt
The current version of the script has a problem—It will run from the beginning to the end, errors or not:
Next, I demonstrate a few things to make your script more robust and in some times recover from failure.
The nuclear option: Failing hard, failing fast
The proper way to handle errors is to check if the program finished successfully or not, using return codes. It sounds obvious but return codes, an integer number stored in bash $? or $! variable, have sometimes a broader meaning. The bash man page tells you:
For the shell’s purposes, a command which exits with a zero exit
status has succeeded. An exit status of zero indicates success.
A non-zero exit status indicates failure. When a command
terminates on a fatal signal N, bash uses the value of 128+N as
the exit status.
More Linux resources
As usual, you should always read the man page of the scripts you’re calling, to see what the conventions are for each of them. If you’ve programmed with a language like Java or Python, then you’re most likely familiar with their exceptions, different meanings, and how not all of them are handled the same way.
If you add set -o errexit to your script, from that point forward it will abort the execution if any command exists with a code != 0 . But errexit isn’t used when executing functions inside an if condition, so instead of remembering that exception, I rather do explicit error handling.
Take a look at version two of the script. It’s slightly better:
Here’s what changed:
- Lines 11 and 12, I enable error trace and added a ‘trap’ to tell the user there was an error and there is turbulence ahead. You may want to kill your script here instead, I’ll show you why that may not be the best.
- Line 20, if the directory doesn’t exist, then try to create it on line 21. If directory creation fails, then exit with an error.
- On line 27, after running each background job, I capture the PID and associate that with the machine (1:1 relationship).
- On lines 33-35, I wait for the scp task to finish, get the return code, and if it’s an error, abort.
- On line 37, I check that the file could be parsed, otherwise, I exit with an error.
So how does the error handling look now?
As you can see, this version is better at detecting errors but it’s very unforgiving. Also, it doesn’t detect all the errors, does it?
When you get stuck and you wish you had an alarm
The code looks better, except that sometimes the scp could get stuck on a server (while trying to copy a file) because the server is too busy to respond or just in a bad state.
Another example is to try to access a directory through NFS where $HOME is mounted from an NFS server:
And you discover hours later that the NFS mount point is stale and your script is stuck.
A timeout is the solution. And, GNU timeout comes to the rescue:
Here you try to regularly kill (TERM signal) the process nicely after 10.0 seconds after it has started. If it’s still running after 20.0 seconds, then send a KILL signal ( kill -9 ). If in doubt, check which signals are supported in your system ( kill -l , for example).
If this isn’t clear from my dialog, then look at the script for more clarity.
Back to the original script to add a few more options and you have version three:
What are the changes?:
- Between lines 16-22, check if all the required dependency tools are present. If it cannot execute, then ‘Houston we have a problem.’
- Created a remote_copy function, which uses a timeout to make sure the scp finishes no later than 45.0s—line 33.
- Added a connection timeout of 5 seconds instead of the TCP default—line 37.
- Added a retry to scp on line 38—3 attempts that wait 1 second between each.
There other ways to retry when there’s an error.
Waiting for the end of the world-how and when to retry
You noticed there’s an added retry to the scp command. But that retries only for failed connections, what if the command fails during the middle of the copy?
Sometimes you want to just fail because there’s very little chance to recover from an issue. A system that requires hardware fixes, for example, or you can just fail back to a degraded mode—meaning that you’re able to continue your system work without the updated data. In those cases, it makes no sense to wait forever but only for a specific amount of time.
Here are the changes to the remote_copy , to keep this brief (version four):
How does it look now? In this run, I have one system down (mac-pro-1-1) and one system without the file (macmini2). You can see that the copy from server dmaf5 works right away, but for the other two, there’s a retry for a random time between 1 and 60 seconds before exiting:
If I fail, do I have to do this all over again? Using a checkpoint
Suppose that the remote copy is the most expensive operation of this whole script and that you’re willing or able to re-run this script, maybe using cron or doing so by hand two times during the day to ensure you pick up the files if one or more systems are down.
You could, for the day, create a small ‘status cache’, where you record only the successful processing operations per machine. If a system is in there, then don’t bother to check again for that day.
Some programs, like Ansible, do something similar and allow you to retry a playbook on a limited number of machines after a failure ( —limit @/home/user/site.retry ).
A new version (version five) of the script has code to record the status of the copy (lines 15-33):
Did you notice the trap on line 22? If the script is interrupted (killed), I want to make sure the whole cache is invalidated.
And then, add this new helper logic into the remote_copy function (lines 52-81):
The first time it runs, a new new message for the cache directory is printed out:
If you run it again, then the script knows that dma5f is good to go, no need to retry the copy:
Imagine how this speeds up when you have more machines that should not be revisited.
Leaving crumbs behind: What to log, how to log, and verbose output
If you’re like me, I like a bit of context to correlate with when something goes wrong. The echo statements on the script are nice but what if you could add a timestamp to them.
If you use logger , you can save the output on journalctl for later review (even aggregation with other tools out there). The best part is that you show the power of journalctl right away.
So instead of just doing echo , you can also add a call to logger like this using a new bash function called ‘ message ’:
You can see that you can store separate fields as part of the message, like the priority, the script that produced the message, etc.
So how is this useful? Well, you could get the messages between 1:26 PM and 1:27 PM, only errors ( priority=0 ) and only for our script ( collect_data_from_servers.v6.sh ) like this, output in JSON format:
Because this is structured data, other logs collectors can go through all your machines, aggregate your script logs, and then you not only have data but also the information.
You can take a look at the whole version six of the script.
Don’t be so eager to replace your data until you’ve checked it.
If you noticed from the very beginning, I’ve been copying a corrupted JSON file over and over:
That’s easy to prevent. Copy the file into a temporary location and if the file is corrupted, then don’t attempt to replace the previous version (and leave the bad one for inspection. lines 99-107 of version seven of the script):
Choose the right tools for the task and prep your code from the first line
One very important aspect of error handling is proper coding. If you have bad logic in your code, no amount of error handling will make it better. To keep this short and bash-related, I’ll give you below a few hints.
You should ALWAYS check for error syntax before running your script:
Seriously. It should be as automatic as performing any other test.
Read the bash man page and get familiar with must-know options, like:
Use ShellCheck to check your bash scripts
It’s very easy to miss simple issues when your scripts start to grow large. ShellCheck is one of those tools that saves you from making mistakes.
If you’re wondering, the final version of the script, after passing ShellCheck is here. Squeaky clean.
You noticed something with the background scp processes
Career advice
You probably noticed that if you kill the script, it leaves some forked processes behind. That isn’t good and this is one of the reasons I prefer to use tools like Ansible or Parallel to handle this type of task on multiple hosts, letting the frameworks do the proper cleanup for me. You can, of course, add more code to handle this situation.
This bash script could potentially create a fork bomb. It has no control of how many processes to spawn at the same time, which is a big problem in a real production environment. Also, there is a limit on how many concurrent ssh sessions you can have (let alone consume bandwidth). Again, I wrote this fictional example in bash to show you how you can always improve a program to better handle errors.
1. You must check the return code of your commands. That could mean deciding to retry until a transitory condition improves or to short-circuit the whole script.
2. Speaking of transitory conditions, you don’t need to start from scratch. You can save the status of successful tasks and then retry from that point forward.
3. Bash ‘trap’ is your friend. Use it for cleanup and error handling.
4. When downloading data from any source, assume it’s corrupted. Never overwrite your good data set with fresh data until you have done some integrity checks.
5. Take advantage of journalctl and custom fields. You can perform sophisticated searches looking for issues, and even send that data to log aggregators.
6. You can check the status of background tasks (including sub-shells). Just remember to save the PID and wait on it.
7. And finally: Use a Bash lint helper like ShellCheck. You can install it on your favorite editor (like VIM or PyCharm). You will be surprised how many errors go undetected on Bash scripts.
Источник
Linux and Unix exit code tutorial with examples
Tutorial on using exit codes from Linux or UNIX commands. Examples of how to get the exit code of a command, how to set the exit code and how to suppress exit codes.
Estimated reading time: 3 minutes
Table of contents
What is an exit code in the UNIX or Linux shell?
An exit code, or sometimes known as a return code, is the code returned to a parent process by an executable. On POSIX systems the standard exit code is 0 for success and any number from 1 to 255 for anything else.
Exit codes can be interpreted by machine scripts to adapt in the event of successes of failures. If exit codes are not set the exit code will be the exit code of the last run command.
How to get the exit code of a command
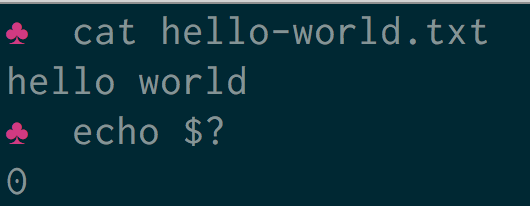
To get the exit code of a command type echo $? at the command prompt. In the following example a file is printed to the terminal using the cat command.
The command was successful. The file exists and there are no errors in reading the file or writing it to the terminal. The exit code is therefore 0 .
In the following example the file does not exist.
The exit code is 1 as the operation was not successful.
How to use exit codes in scripts
To use exit codes in scripts an if statement can be used to see if an operation was successful.
If the command was successful the exit code will be 0 and ‘The script ran ok’ will be printed to the terminal.
How to set an exit code
To set an exit code in a script use exit 0 where 0 is the number you want to return. In the following example a shell script exits with a 1 . This file is saved as exit.sh .
Executing this script shows that the exit code is correctly set.
What exit code should I use?
The Linux Documentation Project has a list of reserved codes that also offers advice on what code to use for specific scenarios. These are the standard error codes in Linux or UNIX.
- 1 — Catchall for general errors
- 2 — Misuse of shell builtins (according to Bash documentation)
- 126 — Command invoked cannot execute
- 127 — “command not found”
- 128 — Invalid argument to exit
- 128+n — Fatal error signal “n”
- 130 — Script terminated by Control-C
- 255* — Exit status out of range
How to suppress exit statuses
Sometimes there may be a requirement to suppress an exit status. It may be that a command is being run within another script and that anything other than a 0 status is undesirable.
In the following example a file is printed to the terminal using cat. This file does not exist so will cause an exit status of 1 .
To suppress the error message any output to standard error is sent to /dev/null using 2>/dev/null .
If the cat command fails an OR operation can be used to provide a fallback — cat file.txt || exit 0 . In this case an exit code of 0 is returned even if there is an error.
Combining both the suppression of error output and the OR operation the following script returns a status code of 0 with no output even though the file does not exist.
Further reading
Have an update or suggestion for this article? You can edit it here and send me a pull request.
Recent Posts
About the author
George Ornbo is a UK based human.
He is interested in people, music, food and writing. In a previous version of himself he wrote books on technology.
Источник
9 More Discussions You Might Find Interesting
1. UNIX for Dummies Questions & Answers
What does this Error Message Mean
Hi I found the following error message in my logs:
warning: /etc/hosts.deny, line 6: can’t verify hostname: getaddrinfo(localhost) didn’t return ::ffff:222.255.28.33
What is the error message trying to indicate? That there is a problem with line 6 (2 Replies)
Discussion started by: mojoman
2. UNIX for Dummies Questions & Answers
Error Message
I keep getting an error message in a script im writing, this line is allways pointed out.
if
and this is the message i keep getting.
line 32: [: 8: unary operator expected
Whats wrong with it?
Please Help. (5 Replies)
Discussion started by: chapmana
3. UNIX for Dummies Questions & Answers
Error Message
What does this means?
— ERROR OPENING FILE — KEY LENGHT MISMATCH (2 Replies)
Discussion started by: RDM00
4. Shell Programming and Scripting
Error message
I am new to scripting.
I am using the following script . BART.dat contains the string ‘Y’ .
#!/bin/ksh
cd /work/TCI/data_out
file=`cat BART.dat`
echo «$file»
if ; then
echo «true»
fi
When i am executing the above script i am getting the following error
./s.ksh: : not found
… (2 Replies)
Discussion started by: ammu
5. UNIX for Advanced & Expert Users
Error message
Hi,
My Solaris 5.8 system keeps getting this error at boot —
«Can’t set vol root to /vol»
then
/usr/sbin/vold: can’t set vol root to /vol: Resource temporarily unavailiable
Any idea what is wrong, and how do I fix it? (1 Reply)
Discussion started by: ghuber
6. Solaris
Error message
Hi,
My Solaris 5.8 system keeps getting this error at boot —
«Can’t set vol root to /vol»
then
/usr/sbin/vold: can’t set vol root to /vol: Resource temporarily unavailiable
Any idea what is wrong, and how do I fix it? (0 Replies)
Discussion started by: ghuber
7. UNIX for Advanced & Expert Users
Error message
I’m getting an error — symbol referencing errors. No output written to, etc
Can anybody tell me why this is? (2 Replies)
Discussion started by: Dan Rooney
8. UNIX for Dummies Questions & Answers
Error Message
Hi everyone,
Can anyone explain what the following error refers to…and perhaps a solution?
vxfs: vx_nospace -/tmp file system full (8 block extent)
Thanks,
Uni (2 Replies)
Discussion started by: Uni
9. UNIX for Dummies Questions & Answers
error message
Hi All,
occasionally my server gives this error messages
«NOTICE:HTFS Out of inodes on HTFS dev hd (1/42)»
why ??
Alice. (3 Replies)
Discussion started by: alisev
Working on Linux applications we have several ways to get information from outside and to put it inside: command line args, environment variables, files. All of these sources are legal and good. But it has a finite size. Another way to establish communication is standard streams: input stream (stdin) used for getting data from outside of the app, output stream (stdout) to put data outside of the app, and error to put data outside of the app (stderr).
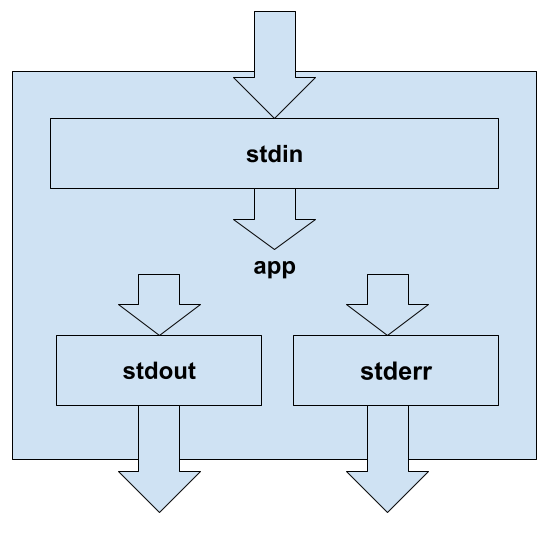
standard Linux application stream at sh
Each stream acts like a pipe: It has the same buffer to write and read the data. This buffer is available for reading from one application and available for writing from another one. On reading, the occupied buffer size will be reduced and it will be increased on writing. If the average rate of reading and writing is equal – then data passed over the stream can be any number of bytes long.
Input/output streams operating in the example
Let’s look at an example of the “grep” application describing how it interacts with it.
script body:
#!/usr/bin/env bash echo pattern | grep pattern echo pattern | grep pattern
The script running at the console:

script body in the yellow frame, output next
This time we ran 2 commands: “cat stdio1.sh” – to list script body, “./stdio1.sh” to run the script. “echo pattern” forms the standard output stream that is connected to the standard input stream of grep. So all of the data comes to grep. grep is an app that writes from input stream to output stream if it matches the pattern. The first input does not match – no output expected. The Second-string of the script “echo pattern | grep pattern” has appropriate input – it has been passed to grep output and displayed at the console next.
Error stream operating in the example
Stderr is very similar to stdout: with only one difference – it will contain an error report if it will take a place
script body:
#!/usr/bin/env bash ls > /tmp/log cat /tmp/log ls /not/existed_path > /tmp/log cat /tmp/log cat /tmp/log rm /tmp/log
The script running at the console:

script body in the yellow frame, output next
At this script, we make a listing of files in the current directory (“ls”) and redirect standard output to the file (“/tmp/log”). Then we display this file data at the console from the standard output stream of the cat utility that read the file. Next, we try to list files in the not existing folder and store results into the file as above, and display it two times. But there is no effect. Just one output about the error in the console. That is because this error comes from the standard errors stream of ls. We removed the file to clear some space “/tmp/log“.
Streams redirecting
It is possible to manipulate the standard streams: redirect them or use pipes to process them.
script body:
#!/usr/bin/env bash ls /not/existed_path 2>/dev/null ls * /not/existed_path > /tmp/log 2> /tmp/err_log cat /tmp/log rm /tmp/log /tmp/err_log
The script running at the console:

script body in the yellow frame, output next
We use the “>” redirect action in this command. /dev/null – is a stream termination file to drop any input with no processing. “2>” clause redirects standard output stream to file. Now it is possible to look at output and errors later by calling “cat /tmp/log” or “cat /tmp/err_log”.
Discard the output
In some cases, it is useful to drop all of the application output (to save storage space or remove the unimportant sources of data to analyze). We should remember that we should mute not just the standard output stream but the standard error stream also. Let’s look at an example of how does it work.
script body:
#!/usr/bin/env bash ls . unexisted_file > /dev/null ls . unexisted_file > /dev/null 2>&1
The script running at the console:

script body in the yellow frame, output next
In both lines of script standard output stream redirected to file /dev/null. This file is not a file itself: but a special Linux device with a file interface. It has a write function available from shell (that does nothing). So all of the input is just dropped. But the second string of the script has a difference from the first one: “2>&1” at the end of the command. These symbols tell that the second standard stream ( standard error stream ) needs to be directed at the first standard stream (standard output stream) permanently for this command. That is why we see only one error message displayed in the console – at the second command string of the script standard error stream redirected to terminating file device /dev/null in the end.
Pipelined streams
It also can be useful to modify the stream. is able to run several applications connected by the streams.
script body:
#!/usr/bin/env bash touch /tmp/a ls /tmp/* 2> /dev/null | grep -w a rm /tmp/a
The script running at the console:

script body in the yellow frame, output next
Here we collect the listing and set “ls” standard output stream as grep standard input stream by using “|”. On “2>” standard errors stream is redirected to the termination file. The output stream of grep contains the “/tmp/a” filename from listing that matches by grep pattern.
Here document
Here the document is redirection option to fill input stream of application by information native way:
application << delimiter some useful text delimiter
script body:
#!/usr/bin/env bash
grep perfect << EOF
PERFECT STORY
past perfect
is it Perfect?
EOF
The script running at console

script body in the yellow frame, output next
As we can see only the second string from 3 of the strings of text for the grep standard input stream delimited by “EOF” match the grep pattern: that is why it passed to grep standard output stream and be displayed in the console next.
Conclusion
There are several standard utilities to work with streams (cat, cut, grep, sed, tr, …). You can use it or write your own to make a data stream processing pipeline that will match your needs. Under the hood, it will work with stdin, stdout, stderr.