Содержание
- Unrecoverable medium error during recovery on pd
- Проверка дисков Chkdsk в Windows Server 2012 R2
- Кажись, все.. LSI Megaraid 9260-16i Raid6 и КД с архивом
- Кажись, все.. LSI Megaraid 9260-16i Raid6 и КД с архивом
- Unrecoverable medium error during recovery on pd
Unrecoverable medium error during recovery on pd

Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-01
Всем привет сегодня расскажу про сообщение Corrected medium error during recovery на IBM ServeRAID M5015. Ситуация следующая, пишет базист и сообщает что у него есть проблема на сервере с MS SQL 2014. MS SQL 2014 испытывает проблемы с выполнением запросов, SQL сервер генерит Exception. Стал разбираться в чем дело.
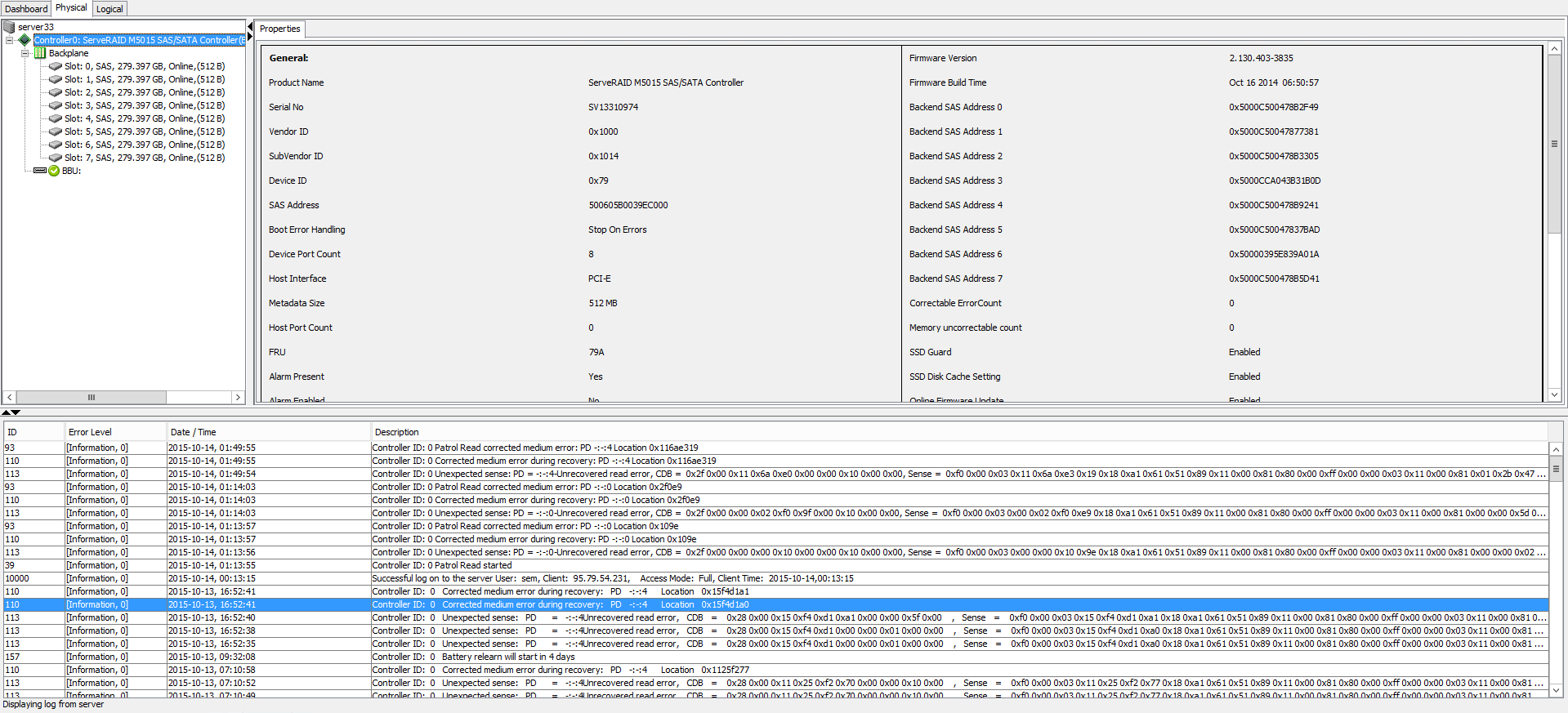
Ранее с этим сервером была проблема на уровне RAID контроллера о ней я писал тут (Код события 55, Структура файловой системы на диске повреждена и непригодна к использованию. Запустите программу CHKDSK на томе DeviceHarddiskVolume2). Первым делом полез на RAID контроллер через утилиты msm (megaraid storage manager). напомню megaraid storage manager это утилита для настройки RAID контроллера LSI. Внешне было все зеленым, но глаз привлекло вот такое информационное сообщение:
и после этого предупреждения об ошибке было, что ошибка исправлена функцией Read Patrol
Controller ID:0 Corrected medium error during recovery:PD -:-:4 Location 0x15f4d1a0
Почитав форум LSI было понятно что в этом сообщение если оно не warning и не fatal error, ничего страшного нет. Просто были ошибки при записи RAID контроллер их исправил сам.
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-02
для надежности сохранил логи msm, делается это просто либо правым кликом снизу и выбором пункта Save asd text.
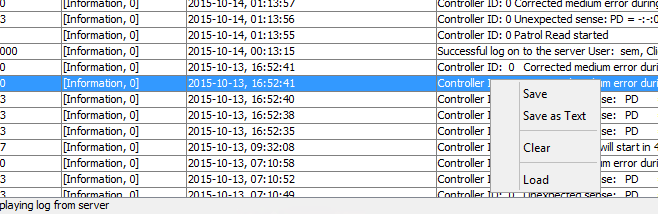
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-03
Либо пункт megaraid storage manager log-save as text
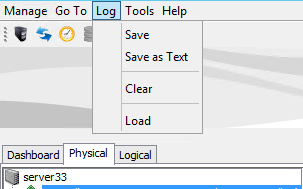
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-04
megaraid storage manager больше нам не понадобится, на RAID больше не грешим. Следующим пунктом проверим Windows Server 2012 R2 в моем случае.
Проверка дисков Chkdsk в Windows Server 2012 R2
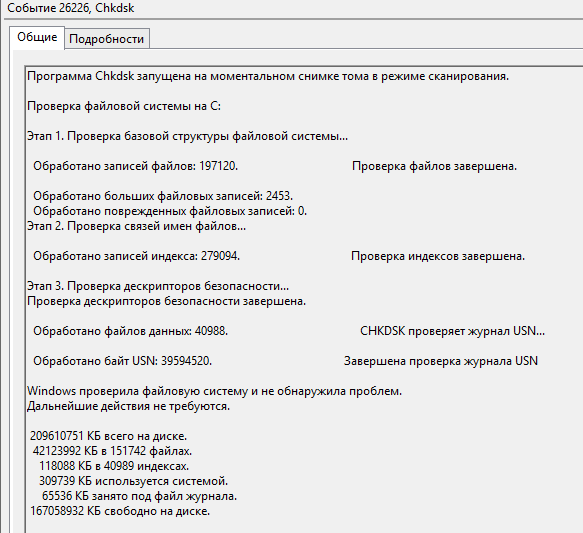
Далее проверим файловую систему NTFS с помощью утилиты Chkdsk, подробнее тут я уже описывал. У меня все с файловой системой было отлично вывод результатов был приблизительно таким. Посмотреть его можно в просмотре событий в журнале приложения код 26226.
Программа Chkdsk запущена на моментальном снимке тома в режиме сканирования.
Проверка файловой системы на C:
Этап 1. Проверка базовой структуры файловой системы.
Обработано записей файлов: 197120. Проверка файлов завершена.
Обработано больших файловых записей: 2453.
Обработано поврежденных файловых записей: 0.
Этап 2. Проверка связей имен файлов.
Обработано записей индекса: 279094. Проверка индексов завершена.
Этап 3. Проверка дескрипторов безопасности.
Проверка дескрипторов безопасности завершена.
Обработано файлов данных: 40988. CHKDSK проверяет журнал USN.
Обработано байт USN: 39594520. Завершена проверка журнала USN
Windows проверила файловую систему и не обнаружила проблем.
Дальнейшие действия не требуются.
209610751 КБ всего на диске.
42123992 КБ в 151742 файлах.
118088 КБ в 40989 индексах.
309739 КБ используется системой.
65536 КБ занято под файл журнала.
167058932 КБ свободно на диске.
Видим Chkdsk ничего плохого не показал.
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-05
Поизучав еще более детально логи просмотра событий параллельно решил еще вот такую ошибку
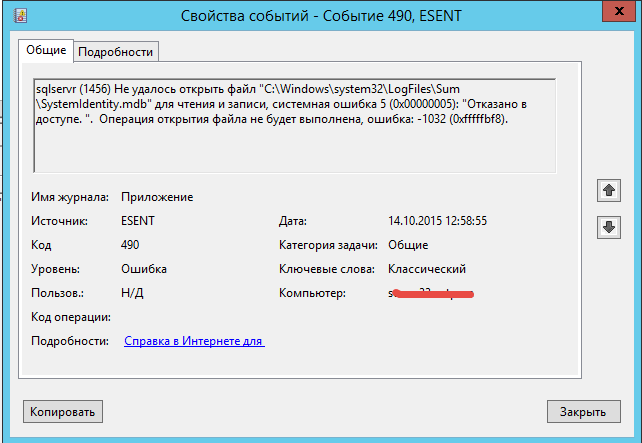
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-06
Проблема решается довольно просто нужно просто дать права на запись учетной записи от имени которой работает SQl на папку C:Windowssystem32LogFilesSum, но меня это натолкнуло посмотреть возможно ли проблема с SQL 2014.
Выскакивала еще вот такая вот ошибка
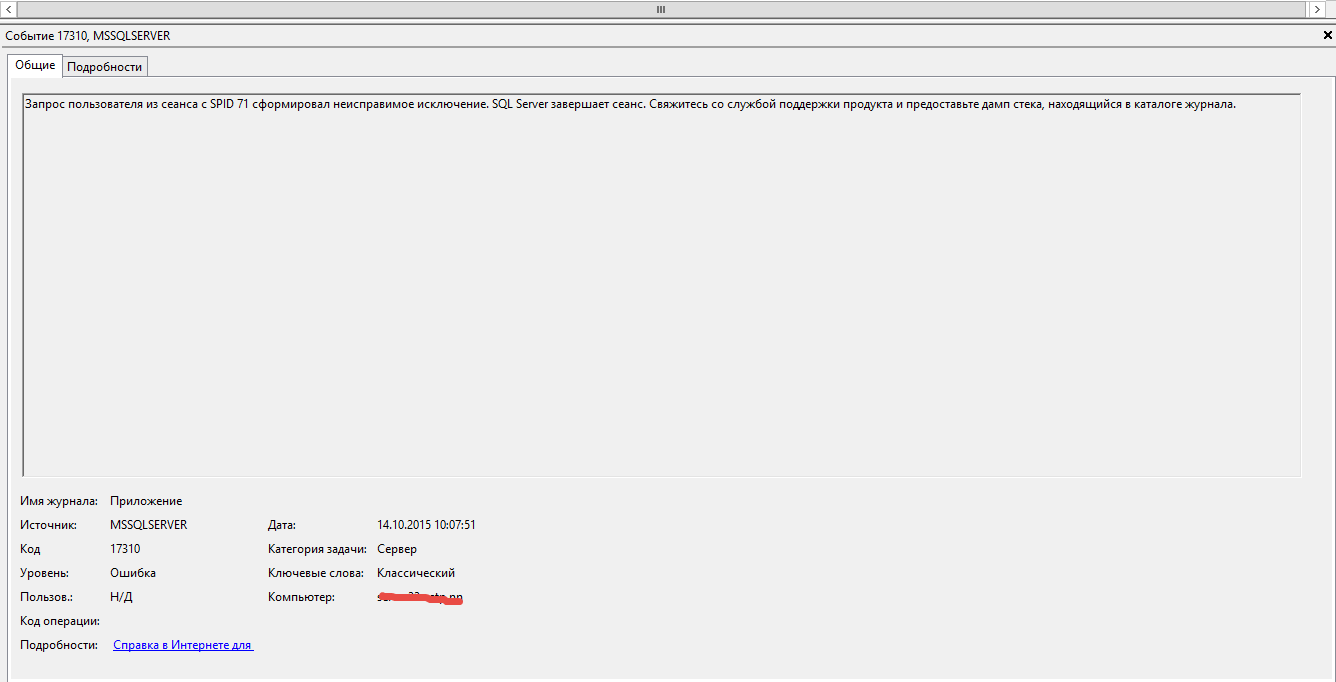
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-07
В итоге надыбал вот это Error messages are logged when you execute a non-cacheable auto-parameterized query in SQL Server 2012 or 2014, где Microsoft предлагало поставить последний CU для SQL 2014. Скачиваем устанавливаем радуемся жизни, что ошибка ушла.
Источник
Кажись, все.. LSI Megaraid 9260-16i Raid6 и КД с архивом
Кажись, все.. LSI Megaraid 9260-16i Raid6 и КД с архивом
Сообщение JagO » 05 май 2016, 22:10
Как неоднократно говорилось всеми умными людьми — «Пока гром не грянет. «, ну а дальше и так всем уже понятно.
На работе есть сервер на Windows Server 2008 R2 являющийся одновременно главным контроллером домена и файловым сервером.
Собран на базе контроллера LSI Megaraid 9260-16i и восьми 2Тб жестких дисков Seagate ST2000DM001.
Диски объединены в массив RAID6.
Некоторое время назад практически одновременно два диска вылетели из массива — в логах были сообщения вида Uncorrectable Media Errors со ссылками на эти два диска, затем были сообщения об их отключении и включении по питанию, а затем оба диска перешли в состояние Failed, а состояние массива стало Degraded.
Данные с массива при этом были доступны, система нормально работала, при перезапуске сервера — он без проблем стартовал.
Были заказаны да аналогичных жестких диска. Немногим больше одной недели их закупали, потом еще примерно неделю я выжидал подходящего момента для замены. В праздники приступил к замене. Сменил статус двух «больных» дисков на — «подготовка к замене». По данным установленной в ОС программы MegaRaid Storage Manager эти диски в вышли из Virtual Drive, спустились ниже и стали Unconfigured Bad. Я извлек их из машины. Через некоторое время последовательно установил два диска им на замену. При этом контроллер самостоятельно не начинал процедуру «ребилда», и по этому я, перевел оба новых диска в состояние Global Hot Spare, затем обновил программу управления контроллером (в смысле refresh) — и увидел, что оба диска «подтянулись» в Virtual Drive и на них начался процесс Rebuild’а. Шел он последовательно, сперва прогресс-бар заполнился на одном винте, затем начался на другом. Я не стал дожидаться окончания процедуры. По журналу контроллера примерно через 6 часов оба диска уже были «в строю». И все пришло в норму.
Но, как выяснилось, не на долго. Неприятности ждали меня в первый рабочий день после праздников.
В журнале мониторинга MSM были строчки с руганью как раз на два новых жестких диска, вида:
Controller ID: 0 Puncturing bad block: PD -:-:12 Location 0xa6cbad78 Event ID:97
Controller ID: 0 Puncturing bad block: PD -:-:14 Location 0xa6cbad78 Event ID:97
а через некоторое время (по тому же журналу за прошлый день), к ним добавились строки вида:
Controller ID: 0 Unrecoverable medium error during recovery: PD -:-:12 Location 0xa6cbad7e Event ID:111
и Controller ID: 0 Unrecoverable medium error during recovery: PD -:-:8 Location 0xa6cbad78 Event ID:111
То есть, «задурил» еще один жесткий диск. При этом, он очень быстро пришел в «негодность» — проскочило сообщения о том, что он перешел в состояние Unconfired Bad и он окрасился рыже-красным значком.
То есть, когда я утром запустил MSM и увидел все эти события в логе, состояние массива было Partially degraded.
Так как я не достаточно знаком с терминологией и особенностями работы raid-массивов, в частности, очень редко посещал этот форум и не читал обязательной и рекомендованной тут литературы, первым делом принялся искать на просторах всемирной сети информацию о том, что собственно произошло, и чем это все может грозить.
Но было уже поздно. Сотрудники фирмы сообщили о проблемах с доступам к некоторым расположенным на этом сервере сетевым папкам и файлам. Я проверил права доступа — там все было в норме, но и с самого сервера (локально) я не мог открыть эти директории. Затем почти сразу отовсюду посыпались ошибки системы, ошибки с адресами в ОЗУ и ошибки доступа к системным файлам Windows. Буквально через пару минут моя терминальная сессия повисла, а затем закрылась. Сервер ушел на перезагрузку, и ОС с него уже не загружалась. И вот тут, я запаниковал, и сделал единственное что пришло в голову после поверхностного прочтения информации об ошибках их журнала с контроллера — нужно сделать Consistency Check. Я запустил эту процедуру из БИОСа контроллера. Спустя сутки она была завершена, но не принесла положительного результата — ОС так и не загружалась.
Через некоторое время, после подбора загрузочного диска с дистрибутивом Windows 2008 Server R2, и его записи на флешку с поддержкой UEFI (в противном случае другие дистрибутивы и загрузочные носители ругались на то, что Восстановление системы с этого диска невозможно, видимо, не определяя GPT структуру разделов в массиве), удалось с нее загрузиться и запустить Восстановление системы. Там было всего три пункта для выбора, и верхний из них предлагал восстановление системы из резервной копии образа. Так как регулярные бэкапы на сетевое хранилище выполнялись только для файлового хранилища, судя по всему, не неся в себе System State и другую информацию для восстановления ОС, я попробовал посмотреть резервную копию на локальном диске С. Но, открывшейся проводник не смог получить доступ в разделы C и D (раздел под установленную ОС и раздел с файловым архивом), и выставив Вид в проводнике в Таблицу — я увидел, что файловая система этих разделов с массива — RAW.
Собственно, в этот момент я понял, что могу дальше необдуманными действиями совсем все поломать или сделать еще хуже.
Подскажите, пожалуйста, как мне быть? Как вы считаете, что можно в сложившейся ситуации предпринять? Какими должны быть мои действия для восстановления данных и работоспособности сервера?
P.S. Мысли и вопросы на данную тему..
а) так как массив Partially degraded — будет ли ему (и данным на нем) лучше или хуже, если я доставлю еще один такой же диск на 2Тб и запущу процесс пересборки массива? Как это может сказаться на нем?
б) может, мне с установочного дистрибутива ОС запустить CHKDSK /F для системного раздела и файловая система и структура будут восстановлены? Читал, что есть мнения, о том, что для проблемных RAID5 этого лучше не делать, так как это может совсем испортить данные на диске. Но у меня проблемный массив RAID6 ([хотя, в текущем состоянии, он, наверное, ближе к проблемного RAID5), да и верно ли это утверждение о вреде CHKDSK для RAID массивов созданных на аппаратном контроллере с кэшем, памятью, батареей и тп?
в) начинаю с бэкапов восстанавливать данные на отдельный диск на другом ПК, что бы к ним доступ появился у сотрудников. Затем новый КД соберу и введу его в эксплуатацию. верная последовательность действий?
г) я так понимаю, что в любом случае, раз уж массив поврежден, сыпал указанными выше ошибками, то вне зависимости от того, получится с него данные восстановить и перенести в другое место, или не получится, я могу смело на этом же контроллере к оставшимся незадействованными портам подключать новые диски и создавать новый дисковый массив, что бы в дальнейшем его использовать, а поврежденный массив вывести из эксплуатации и забрать диски?
Источник
Unrecoverable medium error during recovery on pd
 Профиль | Отправить PM | Цитировать
Профиль | Отправить PM | Цитировать
Вложения
 |
Логи.zip |
| (23.2 Kb, 0 просмотров) |
Комрады, нужна помощь в лечении RAID.
Raid 5 не хочет восстанавливаться, после вылета одного из винтов. Подсовывал разные винчестера, менял все SATA провода. На всех попытках, их было около 4-5, ребилд прерывался в разных местах. Лог в архиве целиком, а тут в сообщении последний строчки.
Конфигурация: Мать Intel Vernonia S5000XVN
SERVER—
OS name: Windows 2003
OS Version: 5.2
OS Architecture: x86_64
Driver Name: LSI MegaSR RAID5
Driver Version: 09.21.0914.2007
Application Version: RAID Web Console 2 — 14.08.01.04
HARDWARE—
Controller: Intel Embedded Server RAID Technology II(Bus 0,Dev 31)
Status: Needs attention
Firmware Package Version:
Firmware Version: null
BBU: NO
Enclosure(s): 0
Drive(s): 6
Virtual Drive(s): 1
Drives:—
PRODUCT ID VENDOR ID STATE DISK TYPE CAPACITY POWER STATE
ST3500320AS 5QM00GCF Online SATA 464.729 GB On
ST3500320AS 5QM008GE Online SATA 464.729 GB On
WDCWD5000AAKS0 WD-WCAS Online SATA 464.729 GB On
ST3500418AS 5VM3NZSW Online SATA 464.729 GB On
WDCWD5000AAKS0 WD-WCAS Unconfigured Good SATA 464.729 GB On
ST31000528AS 9VP95HXH Offline SATA 930.391 GB On
Virtual Drive(s):—
TARGET ID NAME CAPACITY STATE RAID LEVEL MegaRAID RECOVERY
0 — 1.815 TB Degraded RAID 5 NO
251 [Critical, 2] 2015-07-27, 04:38:13 Controller ID: 0 VD is now DEGRADED VD
0 2984
81 [Information, 0] 2015-07-27, 04:38:13 Controller ID: 0 State change on VD: 0
Previous = Offline Current =
Degraded 2983
0 [Information, 0] 2015-07-27, 04:38:13 Controller ID: 0 Firmware initialization started:
( PCI ID 0x2682/ 0x8086/ 0x3473 / 0x8086) 2982
114 [Information, 0] 2015-07-26, 03:38:06 Controller ID: 0 State change: PD
= -:-:5 Previous = Offline
Current = Failed 2981
114 [Information, 0] 2015-07-26, 03:38:06 Controller ID: 0 State change: PD
= -:-:5 Previous = Rebuild
Current = Offline 2980
197 [Fatal, 3] 2015-07-26, 03:38:06 Controller ID: 0 Bad block table is full; unable to log block: PD
= -:-:5, Block =
0x308f385c 2979
109 [Fatal, 3] 2015-07-26, 03:38:06 Controller ID: 0 Unrecoverable medium error during rebuild: PD 0 Location 0x308f385c 2978
109 [Fatal, 3] 2015-07-26, 03:38:04 Controller ID: 0 Unrecoverable medium error during rebuild: PD 0 Location 0x308f385b 2977
109 [Fatal, 3] 2015-07-26, 03:38:02 Controller ID: 0 Unrecoverable medium error during rebuild: PD 0 Location 0x308f385a 2976
109 [Fatal, 3] 2015-07-26, 03:38:00 Controller ID: 0 Unrecoverable medium error during rebuild: PD 0 Location 0x308f3859 2975
109 [Fatal, 3] 2015-07-26, 03:37:58 Controller ID: 0 Unrecoverable medium error during rebuild: PD 0 Location 0x308f3856 2974
109 [Fatal, 3] 2015-07-26, 03:37:56 Controller ID: 0 Unrecoverable medium error during rebuild: PD 0 Location 0x308f3855 2973
109 [Fatal, 3] 2015-07-26, 03:37:54 Controller ID: 0 Unrecoverable medium error during rebuild: PD 0 Location 0x308f26e3 2972
109 [Fatal, 3] 2015-07-26, 03:37:52 Controller ID: 0 Unrecoverable medium error during rebuild: PD 0 Location 0x308f26e2 2971
Источник
Доброго дня!
Как неоднократно говорилось всеми умными людьми — «Пока гром не грянет…», ну а дальше и так всем уже понятно.
На работе есть сервер на Windows Server 2008 R2 являющийся одновременно главным контроллером домена и файловым сервером.
Собран на базе контроллера LSI Megaraid 9260-16i и восьми 2Тб жестких дисков Seagate ST2000DM001.
Диски объединены в массив RAID6.
Некоторое время назад практически одновременно два диска вылетели из массива — в логах были сообщения вида Uncorrectable Media Errors со ссылками на эти два диска, затем были сообщения об их отключении и включении по питанию, а затем оба диска перешли в состояние Failed, а состояние массива стало Degraded.
Данные с массива при этом были доступны, система нормально работала, при перезапуске сервера — он без проблем стартовал.
Были заказаны да аналогичных жестких диска. Немногим больше одной недели их закупали, потом еще примерно неделю я выжидал подходящего момента для замены. В праздники приступил к замене. Сменил статус двух «больных» дисков на — «подготовка к замене». По данным установленной в ОС программы MegaRaid Storage Manager эти диски в вышли из Virtual Drive, спустились ниже и стали Unconfigured Bad. Я извлек их из машины. Через некоторое время последовательно установил два диска им на замену. При этом контроллер самостоятельно не начинал процедуру «ребилда», и по этому я, перевел оба новых диска в состояние Global Hot Spare, затем обновил программу управления контроллером (в смысле refresh) — и увидел, что оба диска «подтянулись» в Virtual Drive и на них начался процесс Rebuild’а. Шел он последовательно, сперва прогресс-бар заполнился на одном винте, затем начался на другом. Я не стал дожидаться окончания процедуры. По журналу контроллера примерно через 6 часов оба диска уже были «в строю». И все пришло в норму.
Но, как выяснилось, не на долго. Неприятности ждали меня в первый рабочий день после праздников.
В журнале мониторинга MSM были строчки с руганью как раз на два новых жестких диска, вида:
Controller ID: 0 Puncturing bad block: PD -:-:12 Location 0xa6cbad78 Event ID:97
Controller ID: 0 Puncturing bad block: PD -:-:14 Location 0xa6cbad78 Event ID:97
а через некоторое время (по тому же журналу за прошлый день), к ним добавились строки вида:
Controller ID: 0 Unrecoverable medium error during recovery: PD -:-:12 Location 0xa6cbad7e Event ID:111
и Controller ID: 0 Unrecoverable medium error during recovery: PD -:-:8 Location 0xa6cbad78 Event ID:111
То есть, «задурил» еще один жесткий диск. При этом, он очень быстро пришел в «негодность» — проскочило сообщения о том, что он перешел в состояние Unconfired Bad и он окрасился рыже-красным значком.
То есть, когда я утром запустил MSM и увидел все эти события в логе, состояние массива было Partially degraded.
Так как я не достаточно знаком с терминологией и особенностями работы raid-массивов, в частности, очень редко посещал этот форум и не читал обязательной и рекомендованной тут литературы, первым делом принялся искать на просторах всемирной сети информацию о том, что собственно произошло, и чем это все может грозить.
Но было уже поздно. Сотрудники фирмы сообщили о проблемах с доступам к некоторым расположенным на этом сервере сетевым папкам и файлам. Я проверил права доступа — там все было в норме, но и с самого сервера (локально) я не мог открыть эти директории. Затем почти сразу отовсюду посыпались ошибки системы, ошибки с адресами в ОЗУ и ошибки доступа к системным файлам Windows. Буквально через пару минут моя терминальная сессия повисла, а затем закрылась. Сервер ушел на перезагрузку, и ОС с него уже не загружалась. И вот тут, я запаниковал, и сделал единственное что пришло в голову после поверхностного прочтения информации об ошибках их журнала с контроллера — нужно сделать Consistency Check. Я запустил эту процедуру из БИОСа контроллера. Спустя сутки она была завершена, но не принесла положительного результата — ОС так и не загружалась.
Через некоторое время, после подбора загрузочного диска с дистрибутивом Windows 2008 Server R2, и его записи на флешку с поддержкой UEFI (в противном случае другие дистрибутивы и загрузочные носители ругались на то, что Восстановление системы с этого диска невозможно, видимо, не определяя GPT структуру разделов в массиве), удалось с нее загрузиться и запустить Восстановление системы. Там было всего три пункта для выбора, и верхний из них предлагал восстановление системы из резервной копии образа. Так как регулярные бэкапы на сетевое хранилище выполнялись только для файлового хранилища, судя по всему, не неся в себе System State и другую информацию для восстановления ОС, я попробовал посмотреть резервную копию на локальном диске С. Но, открывшейся проводник не смог получить доступ в разделы C и D (раздел под установленную ОС и раздел с файловым архивом), и выставив Вид в проводнике в Таблицу — я увидел, что файловая система этих разделов с массива — RAW.
Собственно, в этот момент я понял, что могу дальше необдуманными действиями совсем все поломать или сделать еще хуже.
Подскажите, пожалуйста, как мне быть? Как вы считаете, что можно в сложившейся ситуации предпринять? Какими должны быть мои действия для восстановления данных и работоспособности сервера?
P.S. Мысли и вопросы на данную тему..
а) так как массив Partially degraded — будет ли ему (и данным на нем) лучше или хуже, если я доставлю еще один такой же диск на 2Тб и запущу процесс пересборки массива? Как это может сказаться на нем?
б) может, мне с установочного дистрибутива ОС запустить CHKDSK /F для системного раздела и файловая система и структура будут восстановлены? Читал, что есть мнения, о том, что для проблемных RAID5 этого лучше не делать, так как это может совсем испортить данные на диске. Но у меня проблемный массив RAID6 ([хотя, в текущем состоянии, он, наверное, ближе к проблемного RAID5), да и верно ли это утверждение о вреде CHKDSK для RAID массивов созданных на аппаратном контроллере с кэшем, памятью, батареей и тп?
в) начинаю с бэкапов восстанавливать данные на отдельный диск на другом ПК, что бы к ним доступ появился у сотрудников. Затем новый КД соберу и введу его в эксплуатацию… верная последовательность действий?
г) я так понимаю, что в любом случае, раз уж массив поврежден, сыпал указанными выше ошибками, то вне зависимости от того, получится с него данные восстановить и перенести в другое место, или не получится, я могу смело на этом же контроллере к оставшимся незадействованными портам подключать новые диски и создавать новый дисковый массив, что бы в дальнейшем его использовать, а поврежденный массив вывести из эксплуатации и забрать диски?
Обновлено 13.08.2016
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-01
Всем привет сегодня расскажу про сообщение Corrected medium error during recovery на IBM ServeRAID M5015. Ситуация следующая, пишет базист и сообщает что у него есть проблема на сервере с MS SQL 2014. MS SQL 2014 испытывает проблемы с выполнением запросов, SQL сервер генерит Exception. Стал разбираться в чем дело.
Ранее с этим сервером была проблема на уровне RAID контроллера о ней я писал тут (Код события 55, Структура файловой системы на диске повреждена и непригодна к использованию. Запустите программу CHKDSK на томе DeviceHarddiskVolume2). Первым делом полез на RAID контроллер через утилиты msm (megaraid storage manager). напомню megaraid storage manager это утилита для настройки RAID контроллера LSI. Внешне было все зеленым, но глаз привлекло вот такое информационное сообщение:
Controller ID: 0 Unexpected sense: PD = -:-:4Unrecovered read error, CDB = 0x28 0x00 0x15 0xf4 0xd1 0xa1 0x00 0x00 0x5f 0x00 , Sense = 0xf0 0x00 0x03 0x15 0xf4 0xd1 0xa1 0x18 0xa1 0x61 0x51 0x89 0x11 0x00 0x81 0x80 0x00 0xff 0x00 0x00 0x03 0x11 0x00 0x81 0x01 0x85 0xcc 0x01 0x05 0x92 0x00 0x00
и после этого предупреждения об ошибке было, что ошибка исправлена функцией Read Patrol
Controller ID: 0 Corrected medium error during recovery:PD-:-:4 Location 0x15f4d1a1
Controller ID:0 Corrected medium error during recovery:PD -:-:4 Location 0x15f4d1a0
Почитав форум LSI было понятно что в этом сообщение если оно не warning и не fatal error, ничего страшного нет. Просто были ошибки при записи RAID контроллер их исправил сам.
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-02
для надежности сохранил логи msm, делается это просто либо правым кликом снизу и выбором пункта Save asd text.
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-03
Либо пункт megaraid storage manager log-save as text
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-04
megaraid storage manager больше нам не понадобится, на RAID больше не грешим. Следующим пунктом проверим Windows Server 2012 R2 в моем случае.
Проверка дисков Chkdsk в Windows Server 2012 R2
Далее проверим файловую систему NTFS с помощью утилиты Chkdsk, подробнее тут я уже описывал. У меня все с файловой системой было отлично вывод результатов был приблизительно таким. Посмотреть его можно в просмотре событий в журнале приложения код 26226.
Программа Chkdsk запущена на моментальном снимке тома в режиме сканирования.
Проверка файловой системы на C:
Этап 1. Проверка базовой структуры файловой системы…
Обработано записей файлов: 197120. Проверка файлов завершена.
Обработано больших файловых записей: 2453.
Обработано поврежденных файловых записей: 0.
Этап 2. Проверка связей имен файлов…Обработано записей индекса: 279094. Проверка индексов завершена.
Этап 3. Проверка дескрипторов безопасности…
Проверка дескрипторов безопасности завершена.Обработано файлов данных: 40988. CHKDSK проверяет журнал USN…
Обработано байт USN: 39594520. Завершена проверка журнала USN
Windows проверила файловую систему и не обнаружила проблем.
Дальнейшие действия не требуются.209610751 КБ всего на диске.
42123992 КБ в 151742 файлах.
118088 КБ в 40989 индексах.
309739 КБ используется системой.
65536 КБ занято под файл журнала.
167058932 КБ свободно на диске.
Видим Chkdsk ничего плохого не показал.
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-05
Поизучав еще более детально логи просмотра событий параллельно решил еще вот такую ошибку
sqlservr (1456) Не удалось открыть файл «C:Windowssystem32LogFilesSumSystemIdentity.mdb» для чтения и записи, системная ошибка 5 (0x00000005): «Отказано в доступе. «. Операция открытия файла не будет выполнена, ошибка: -1032 (0xfffffbf8).
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-06
Проблема решается довольно просто нужно просто дать права на запись учетной записи от имени которой работает SQl на папку C:Windowssystem32LogFilesSum, но меня это натолкнуло посмотреть возможно ли проблема с SQL 2014.
Выскакивала еще вот такая вот ошибка
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-07
В итоге надыбал вот это Error messages are logged when you execute a non-cacheable auto-parameterized query in SQL Server 2012 or 2014, где Microsoft предлагало поставить последний CU для SQL 2014. Скачиваем устанавливаем радуемся жизни, что ошибка ушла.
Материал сайта pyatilistnik.org