Обновлено 13.08.2016

Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-01
Всем привет сегодня расскажу про сообщение Corrected medium error during recovery на IBM ServeRAID M5015. Ситуация следующая, пишет базист и сообщает что у него есть проблема на сервере с MS SQL 2014. MS SQL 2014 испытывает проблемы с выполнением запросов, SQL сервер генерит Exception. Стал разбираться в чем дело.
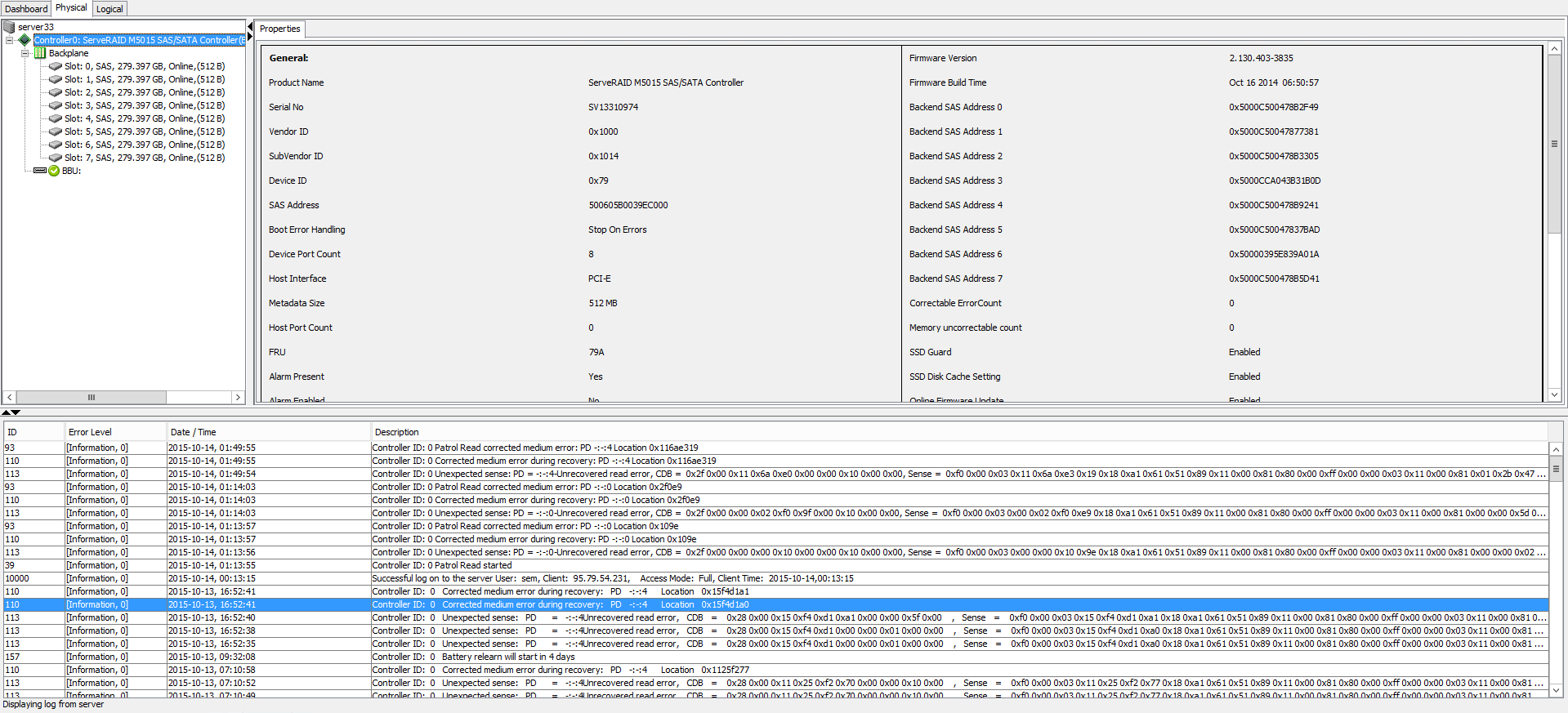
Ранее с этим сервером была проблема на уровне RAID контроллера о ней я писал тут (Код события 55, Структура файловой системы на диске повреждена и непригодна к использованию. Запустите программу CHKDSK на томе DeviceHarddiskVolume2). Первым делом полез на RAID контроллер через утилиты msm (megaraid storage manager). напомню megaraid storage manager это утилита для настройки RAID контроллера LSI. Внешне было все зеленым, но глаз привлекло вот такое информационное сообщение:
Controller ID: 0 Unexpected sense: PD = -:-:4Unrecovered read error, CDB = 0x28 0x00 0x15 0xf4 0xd1 0xa1 0x00 0x00 0x5f 0x00 , Sense = 0xf0 0x00 0x03 0x15 0xf4 0xd1 0xa1 0x18 0xa1 0x61 0x51 0x89 0x11 0x00 0x81 0x80 0x00 0xff 0x00 0x00 0x03 0x11 0x00 0x81 0x01 0x85 0xcc 0x01 0x05 0x92 0x00 0x00
и после этого предупреждения об ошибке было, что ошибка исправлена функцией Read Patrol
Controller ID: 0 Corrected medium error during recovery:PD-:-:4 Location 0x15f4d1a1
Controller ID:0 Corrected medium error during recovery:PD -:-:4 Location 0x15f4d1a0
Почитав форум LSI было понятно что в этом сообщение если оно не warning и не fatal error, ничего страшного нет. Просто были ошибки при записи RAID контроллер их исправил сам.
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-02
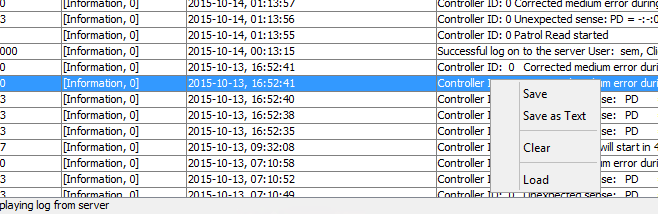
для надежности сохранил логи msm, делается это просто либо правым кликом снизу и выбором пункта Save asd text.
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-03
Либо пункт megaraid storage manager log-save as text
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-04
megaraid storage manager больше нам не понадобится, на RAID больше не грешим. Следующим пунктом проверим Windows Server 2012 R2 в моем случае.
Проверка дисков Chkdsk в Windows Server 2012 R2
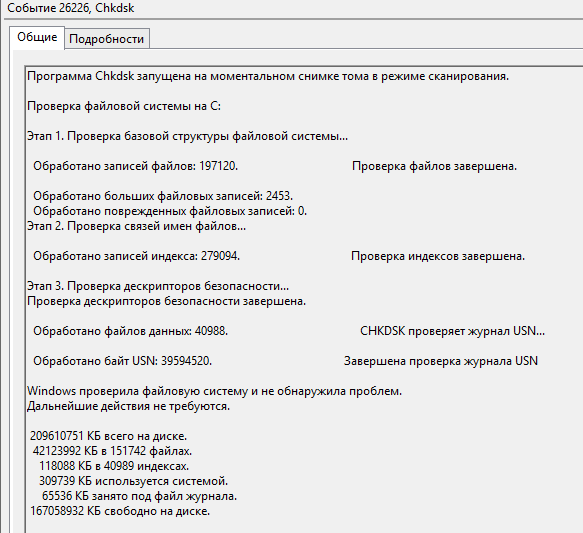
Далее проверим файловую систему NTFS с помощью утилиты Chkdsk, подробнее тут я уже описывал. У меня все с файловой системой было отлично вывод результатов был приблизительно таким. Посмотреть его можно в просмотре событий в журнале приложения код 26226.
Программа Chkdsk запущена на моментальном снимке тома в режиме сканирования.
Проверка файловой системы на C:
Этап 1. Проверка базовой структуры файловой системы…
Обработано записей файлов: 197120. Проверка файлов завершена.
Обработано больших файловых записей: 2453.
Обработано поврежденных файловых записей: 0.
Этап 2. Проверка связей имен файлов…Обработано записей индекса: 279094. Проверка индексов завершена.
Этап 3. Проверка дескрипторов безопасности…
Проверка дескрипторов безопасности завершена.Обработано файлов данных: 40988. CHKDSK проверяет журнал USN…
Обработано байт USN: 39594520. Завершена проверка журнала USN
Windows проверила файловую систему и не обнаружила проблем.
Дальнейшие действия не требуются.209610751 КБ всего на диске.
42123992 КБ в 151742 файлах.
118088 КБ в 40989 индексах.
309739 КБ используется системой.
65536 КБ занято под файл журнала.
167058932 КБ свободно на диске.
Видим Chkdsk ничего плохого не показал.
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-05
Поизучав еще более детально логи просмотра событий параллельно решил еще вот такую ошибку
sqlservr (1456) Не удалось открыть файл «C:Windowssystem32LogFilesSumSystemIdentity.mdb» для чтения и записи, системная ошибка 5 (0x00000005): «Отказано в доступе. «. Операция открытия файла не будет выполнена, ошибка: -1032 (0xfffffbf8).
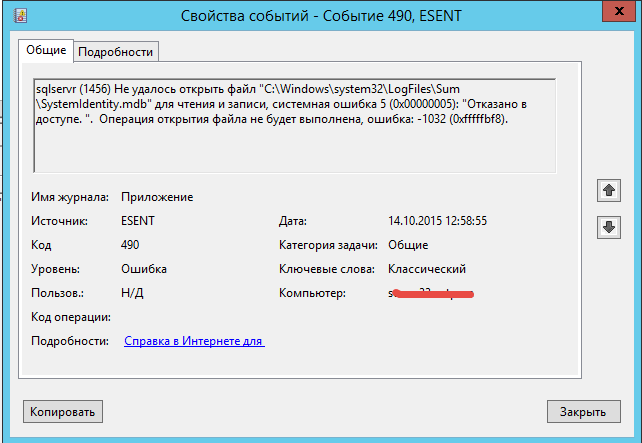
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-06
Проблема решается довольно просто нужно просто дать права на запись учетной записи от имени которой работает SQl на папку C:Windowssystem32LogFilesSum, но меня это натолкнуло посмотреть возможно ли проблема с SQL 2014.
Выскакивала еще вот такая вот ошибка
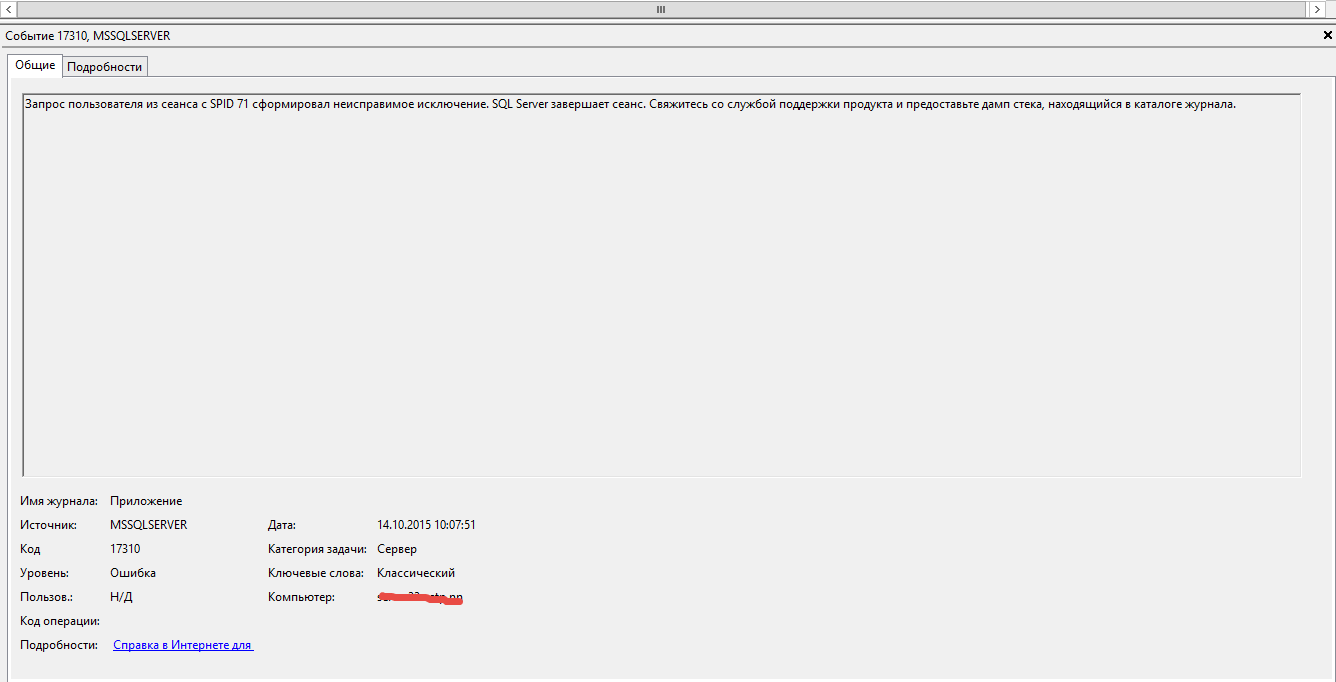
Сообщение Corrected medium error during recovery на IBM ServeRAID M5015-07
В итоге надыбал вот это Error messages are logged when you execute a non-cacheable auto-parameterized query in SQL Server 2012 or 2014, где Microsoft предлагало поставить последний CU для SQL 2014. Скачиваем устанавливаем радуемся жизни, что ошибка ушла.
Материал сайта pyatilistnik.org
Долгое время не выдавалось интересных задачек, которые можно было бы освятить в заметке. Вчера всё-таки нашлась интересная с моей точки зрения.
В исходных данных имеем RAID1 массив, построенный на mdadm, оба диска в котором имеют ошибки на чтение в нескольких секторах. Система говорит о том, что в обоих из них Unrecovered read error — auto reallocate failed:
Aug 21 21:53:11 one kernel: [112350.663076] sd 2:0:0:0: [sda] Unhandled sense code
Aug 21 21:53:11 one kernel: [112350.663081] sd 2:0:0:0: [sda] Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
Aug 21 21:53:11 one kernel: [112350.663089] sd 2:0:0:0: [sda] Sense Key : Medium Error [current] [descriptor]
Aug 21 21:53:11 one kernel: [112350.663133] sd 2:0:0:0: [sda] Add. Sense: Unrecovered read error - auto reallocate failed
Aug 21 21:53:11 one kernel: [112350.663144] sd 2:0:0:0: [sda] CDB: Read(10): 28 00 3a 38 53 b0 00 00 08 00
Aug 21 21:53:11 one kernel: [112350.663160] end_request: I/O error, dev sda, sector 976769972
Попытки пройти long тест в S.M.A.R.T не увенчиваются успехом. Вырезки из S.M.A.R.T
# smartctl -a /dev/sda ... Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed: read failure 90% 32520 976769972 ... # smartctl -a /dev/sdb ... Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed: read failure 90% 32519 55084971
Таким образом становиться ясно, что пока в массиве представлено 2-а жестких диска он «малость» работает исправно. Перекидывая неудачные попытки чтения с одного диска на другой диск. Это выражается в следующих сообщениях:
Aug 22 09:12:18 one kernel: [153097.501298] end_request: I/O error, dev sdb, sector 750558140 Aug 22 09:12:18 one kernel: [153097.508526] raid1: sdb4: rescheduling sector 695471160 Aug 22 09:12:18 one kernel: [153097.515736] raid1: sdb4: rescheduling sector 695471408 Aug 22 09:12:30 one kernel: [153109.603257] sd 4:0:0:0: [sdb] Unhandled sense code Aug 22 09:12:30 one kernel: [153109.603259] sd 4:0:0:0: [sdb] Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE Aug 22 09:12:30 one kernel: [153109.603262] sd 4:0:0:0: [sdb] Sense Key : Medium Error [current] [descriptor] Aug 22 09:12:30 one kernel: [153109.603277] sd 4:0:0:0: [sdb] Add. Sense: Unrecovered read error - auto reallocate failed Aug 22 09:12:30 one kernel: [153109.603281] sd 4:0:0:0: [sdb] CDB: Read(10): 28 00 2c bc 9b b5 00 00 08 00 Aug 22 09:12:30 one kernel: [153109.603287] end_request: I/O error, dev sdb, sector 750558140 Aug 22 09:12:30 one kernel: [153109.610682] raid1:md3: read error corrected (8 sectors at 695471248 on sdb4) Aug 22 09:12:30 one kernel: [153110.033913] raid1: sda4: redirecting sector 695471160 to another mirror Aug 22 09:12:31 one kernel: [153110.177597] raid1: sda4: redirecting sector 695471408 to another mirror
В случае окончательного выхода из строя одного из дисков массив никогда не сможет восстановиться, потому что чтение с любого диска заканчивается провалом.
# dd if=/dev/sda of=/dev/null bs=1M dd: reading `/dev/sda': Input/output error 476938+1 records in 476938+1 records out 500106223616 bytes (500 GB) copied, 5724.82 s, 87.4 MB/s
Разумеется, существует вариант сделать копию системы штатным tar архивом. После этого заменить жесткие диски и развернуть ранее сохраненную систему. Еще один из вариантов попытаться заменить один жесткий диск, создать на нем изначально RAID1 массив с одним missing диском, после этого попытаться синхронизировать систему с оставшегося диска с помощью tar или rsync.
Однако было замечено, что у дисков недоступные для чтения сектора находятся в различных местах. Таким образом возникла идея попытаться форсировать remapping испорченных секторов на одном из дисков и попытаться после этого восстановить данные в них с использованием другого полудохлого диска. В ходе этой операции мы получим один диск с полной копией наших данных, с которого можно эти данные полностью прочитать без ошибок. Останется заменить второй полудохлый диск новым, mdadm автоматически прочитает данные и синхронизирует их с новым диском. При желании после синхронизации можно заменить диск, на котором произвели remapping секторов.
Для того, чтобы форсировать жесткий диск произвести remapping секторов необходимо произвести запись в указанный сектор. С минимальной математической частью можно ознакомиться в статье Forcing a hard disk to reallocate bad sectors. В нашем случае эмпирическим путем было выяснено, что сектора с 976769972 по 976769979 имеют проблемы на жестком диске sda
# hdparm --read-sector 976769972 /dev/sda /dev/sda: reading sector 976769972: FAILED: Input/output error ... # hdparm --read-sector 976769979 /dev/sda /dev/sda: reading sector 976769979: FAILED: Input/output error #
Таким образом производим фиктивную запись в указанный диапазон секторов
for sector in $(seq 976769972 976769979); do hdparm --write-sector $sector --yes-i-know-what-i-am-doing /dev/sda; done
После этого можно убедиться, что данные сектора доступны для чтения (предыдущей командой командой мы их полностью обнулили)
for sector in $(seq 976769972 976769979); do hdparm --read-sector $sector /dev/sda; done
Теперь необходимо в указанные области записать информацию с соседнего диска из зеркала. Так как нам известно смещение 976769972 и что количество поврежденных секторов равно 8 копируем указанную область целым блоком. Обратите внимание копируем область с диска sdb, записываем на диск sda:
# dd if=/dev/sdb of=copy skip=976769972 count=8 8+0 records in 8+0 records out 4096 bytes (4.1 kB) copied, 9.3381e-05 s, 43.9 MB/s # dd if=copy of=/dev/sda seek=976769972 oflag=direct count=8 8+0 records in 8+0 records out 4096 bytes (4.1 kB) copied, 0.000874658 s, 4.7 MB/s
Обнуление через вызов hdparm не является обязательным. Можно напрямую записать сектора требуемыми данными через dd командой
for sector in $(seq 976769972 976769979); do dd if=/dev/sdb of=/dev/sda skip=$sector seek=$sector oflag=direct count=1 done
Осталось убедиться, что все данные с диска можно прочитать
dd if=/dev/sda of=/dev/null bs=1M 476940+1 records in 476940+1 records out 500107862016 bytes (500 GB) copied, 5622.88 s, 88.9 MB/s
Таким образом в ходе описанных манипуляций у нас есть условно рабочий жесткий диск sda, который мы оставляем в системе и меняем жесткий диск sdb. По завершении синхронизации на диск sdb производим замену sda. По завершении синхронизации имеем полностью исправный массив с целостными данными.
В заключении хочется отметить, что в поиске неисправных секторов незаменимой может оказаться команда
dd if=/dev/sda of=/dev/null bs=512 conv=sync,noerror
При желании можно перенаправить сохранение бинарной копии системы на отдельный носитель в этом случае ключ sync просто незаменим. В случае ошибок сбойные сектора на копии будут заполнены NUL (нулями). Таким образом полученная копия будет полностью соответствовать с точки зрения размера оригиналу.
Вторым незаменимым помощником может служить команда badblocks. Важно помнить, что для ее вызова необходимо указать размер блока равный 512 байтам. По умолчанию программа используется значение 1024. Таким образом вызов будет выглядеть следующим образом
badblocks -v -b 512 /dev/sda
Программа будет считывать сектор за сектором и отображать информацию о секторах, которые не удалось прочитать. Например,
# badblocks -v -b 512 /dev/sda Checking blocks 0 to 1565565871 Checking for bad blocks (read-only test): 578915880 578915881 578915882 578915883 578915884 578915885 578915886 578915887 578915888 578915889 578915890 578915891 578915892 578915893 578915894 578915895
В этом случае остается сохранить вывод программы в файл и последовательно перезаписать полученные сектора с другого диска.
Интересные материалы для ознакомления:
- Bad block HOWTO for smartmontools
- Forcing a hard disk to reallocate bad sectors
- Linux — Repairing bad blocks on a RAID1 array with GPT
Introduction
The following material is intended to serve as an example and a reference guide to help spot when disk input/output errors coming from the hardware are creating problems for the backup agent, with somewhat varying error messages shown in the backup console and in PCS logs. The existence of hardware disk errors is not only a problem for the creation of backups — it can pose a hidden yet significant danger to the stability and operability of the customer’s machine, and can easily lead to data loss — so spotting those on time can be crucial.
Symptoms
Error messages in the Backup Console
Backup fails with «Common I/O error.»
Backup fails with «Cannot read the snapshot of the volume.»
Error messages in the mms and/or pcs logs:
Example:
————————
Error code: 21561347
Fields: {«$module»:»disk_bundle_lxa64_26077″}
Message: Backup has failed.
————————
Error code: 66596
Fields: {«$module»:»disk_bundle_lxa64_26077″}
Message: Failed to commit operations.
————————
Error code: 458755
Fields: {«$module»:»disk_bundle_lxa64_26077″}
Message: Read error.
————————
Error code: 5832708
Fields: {«$module»:»disk_bundle_lxa64_26077″,»device»:»/dev/mapper/pve-root»}
Message: Cannot read the snapshot of the volume.
————————
Error messages in the Linux kernel logs ( /var/log/messages files, outputs of dmesg command):
Some examples of I/O-related errors are listed below. This list is not exhaustive.
Keywords to look for
While disk, input-output and storage subsystem errors vary a lot depending on multiple factors (such as the version of the Linux kernel, the exact type of storage controller and storage attachment — some of those would look slightly different if e.g. virtual disks are used inside a hypervisor, or if a disk/volume is attached via iSCSI or Fibre Channel), there are several strings/messages and patterns to look for. This is not an exclusive list:
- ata x.yz … DRDY
- ata x.yz failed command
- WRITE FPDMA QUEUED
- READ FPDMA QUEUED
- print_req_error
- I/O error … <device is normally named, e.g. sda or sdb or sdc disk ID…> < sector(s) NNNN which cannot be read/written is usually mentioned>
- hostbyte
- driverbyte
- DRIVER_SENSE
- Sense Key : Medium Error
- Add. Sense: Unrecovered read error — auto reallocate failed
- ata <ID>: EH complete
Impact on backup and/or restore activities
Impact on backup and recovery activities varies, depending on what operation fails, how it fails, whether it fails every time or only occasionally: e.g. a bad area or sector on disk may not always be permanently bad — sometimes the hardware can recover/repair the lighter errors on its own, in the background; sometimes these errors only occur during unfavorable physical conditions such as excessive vibration in the server/computer/datacenter. It does matter what is stored in the problematic sectors or areas of disk — some parts containing critical LVM or file system metadata, or the OS bootloader and kernel, or the system swap partition/file/area, are usually more important than others.
If the issues are smaller, and do not affect critical areas, the backup agent’s engine may be able to automatically switch into sector-by-sector mode: this can be controlled via the Options sub-menu in the Backup Plan.
However, in practice, in most cases, the I/O errors are serious enough to make even sector-by-sector backups fail (always or intermittently).
Backup creation activities are affected during either the snapshot creation stage by snapapi26 kernel module, or during the actual reading of data from the snapshot in order to send it to the backup.
Restoring backups to problematic disks usually fails when data in the exact bad spots need to be overwritten, but if critical metadata of the LVM ort FS is corrupted/non-readable/non-writable, a wide variety of errors and messages may appear.
What to do (reactively AND proactively)
- Fix or replace the faulty hardware.
- Repair/resync hardware or software array (if using one).
- Periodically run fsck in a mode that checks the entire disk surface (all blocks). Consult Linux manpages (man fsck) on how to do this. Use the «badblocks» Linux utility.
- If using hardware or software RAID solutions, configure them to periodically scrub or do patrol reads to detect bad/unstable sectors and disks as early as possible.
- Use advanced file systems like ZFS and BTRFS which have native features to detect and (if configured properly) self-heal some of such errors.
- Take Entire-machine backups frequently enough.
Key takeaways
- It is often important to check the Linux kernel logs ( /var/log/messages files, dmesg output) for hardware errors when creating backups fails with snapshot errors, unspecified I/O errors, «cannot read…» errors, and similar. The kernel logs are, in such cases, much more precise than the fairly high-level (and often generic) error messages which the backup agent can and does report — it is a user-space application after all, and it cannot always «see» nor interpret low-level errors of the I/O subsystem.
- If the hardware cannot read it (reliably), then the Linux kernel/the OS will not be able to read it, then the backup agent will not be able to process the data correctly and thus the backup will keep failing until the hardware problems get fixed (most often, until the bad disk(s), cable(s), or HBA/RAID card/adapter card get replaced).
- The backup engine is NOT designed to be able to backup barely functioning/marginal storage hardware; it is NOT a specialized data recovery/disk repair software tool. Specialized data recovery tools can sometimes extract data from very unstable sectors, using specialized techniques like retrying a non-responding sector tens or hundreds of times.
I just rebooted my monitoring server for the first time in a while, and the following starting filling the screen:
Jul 11 23:52:30 monit kernel: [ 25.255908] ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x0
Jul 11 23:52:30 monit kernel: [ 25.256170] ata1.00: BMDMA stat 0x24
Jul 11 23:52:30 monit kernel: [ 25.256278] ata1.00: failed command: READ DMA
Jul 11 23:52:30 monit kernel: [ 25.256410] ata1.00: cmd c8/00:c0:20:68:35/00:00:00:00:00/e0 tag 0 dma 98304 in
Jul 11 23:52:30 monit kernel: [ 25.256416] res 51/40:9f:41:68:35/00:00:00:00:00/e0 Emask 0x9 (media error)
Jul 11 23:52:30 monit kernel: [ 25.256809] ata1.00: status: { DRDY ERR }
Jul 11 23:52:30 monit kernel: [ 25.256933] ata1.00: error: { UNC }
Jul 11 23:52:30 monit kernel: [ 25.304388] ata1.00: configured for UDMA/66
Jul 11 23:52:30 monit kernel: [ 25.304430] ata1: EH complete
. . .
Jul 11 23:52:30 monit kernel: [ 25.552451] sd 0:0:0:0: [sda] Unhandled sense code
Jul 11 23:52:30 monit kernel: [ 25.552462] sd 0:0:0:0: [sda] Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
Jul 11 23:52:30 monit kernel: [ 25.552475] sd 0:0:0:0: [sda] Sense Key : Medium Error [current] [descriptor]
Jul 11 23:52:30 monit kernel: [ 25.552490] Descriptor sense data with sense descriptors (in hex):
Jul 11 23:52:30 monit kernel: [ 25.552498] 72 03 11 04 00 00 00 0c 00 0a 80 00 00 00 00 00
Jul 11 23:52:30 monit kernel: [ 25.552529] 00 35 68 41
Jul 11 23:52:30 monit kernel: [ 25.552543] sd 0:0:0:0: [sda] Add. Sense: Unrecovered read error - auto reallocate failed
Jul 11 23:52:30 monit kernel: [ 25.552559] sd 0:0:0:0: [sda] CDB: Read(10): 28 00 00 35 68 20 00 00 c0 00
Jul 11 23:52:30 monit kernel: [ 25.552587] end_request: I/O error, dev sda, sector 3500097
Jul 11 23:52:30 monit kernel: [ 25.556607] ata1: EH complete
I already know I need to replace the HDD (Cost of Data > Cost of HDD), but I want to know for my own knowledge what’s actually wrong with it.
Yes, our monitoring server has no RAID, just one HDD… Don’t look at me…
![]()
Randall
3072 silver badges17 bronze badges
asked Jul 12, 2012 at 5:07
![]()
3
sd 0:0:0:0: [sda] Add. Sense: Unrecovered read error - auto reallocate failed
Looks like the drive has bad sectors and is unable to reallocate these (possibly because it’s run out of spare sectors). The output of smartctl -a /dev/sda would give you more information on the state of the drive.
answered Jul 12, 2012 at 5:12
![]()
mgorvenmgorven
30.3k7 gold badges77 silver badges121 bronze badges
2
Lassie’s saying «arf! arf arf! arf!». Which is dumb, because this has nothing to do with Timmy or wells. This is why you don’t take sysadmin advice from dogs.
The drive is giving you an «Unrecovered read error — auto reallocate failed», which basically means «I tried to read, I failed, I tried to recover (read the sector a few more times, apply some ECC, and move the data to a sector that isn’t broken), and it didn’t work». This probably means (as mgorven says) that the disk is chock full of reallocated sectors already, because the disk’s been dying for a while, but I also think it can mean that it wasn’t able to recover the sector at all (repeated reads + ECC failed to get a good-looking data block).
Either way, yeah, the drive’s very, very cactus. Your data isn’t looking real healthy, either.
answered Jul 12, 2012 at 5:15
![]()
womble♦womble
95.6k29 gold badges173 silver badges229 bronze badges
1
I know this is old, but just in case someone is still reading this post: «DD will also try to read the broken sector(s)» — gddrescue is useful here. It doesn’t (okay, it does, but only once).
answered Apr 10, 2014 at 19:08
![]()
Make a dd image or rsync copy of that disk now++, unless you have a full backup allowing a convenient restore of that box. And start looking for a compatible and working replacement disk.
BTW, UDMA/66, is that a ten year old PATA disk?
answered Jul 12, 2012 at 7:25
![]()
3
As already mentioned it likely means your drive is nearing its end of life but not necessarily immediately — you should run an fsck on the disk and try to repair the errors (see smartmontools wiki for advice fixing bad blocks) and the disk may be ok for a while longer.
But you should start running smartd (which comes as part of the smartmontools package) and keep an eye on its reports and/or set up email notifications. Also you can add custom notifications of your own by creating scripts (in /etc/smartmontools/run.d/) that are called by the smartd-runner.
answered Oct 25, 2017 at 19:44
![]()
PierzPierz
5837 silver badges9 bronze badges

Although not an answer maybe it can steer you in the right direction —
Type ‘Dell SAS Raid Storage Manager Error? experts exchange’ into Google and choose the experts Exchange link. Scroll to the bottom
You will see the below comments:
Many manufacturers use LSi products. Intel is one.
Here is the document that interprets all of those codes:
http:/ Opens a new window/download.intel.com/support/motherboards/server/sb/intelraidcontrollersassataloggedalertdecodev10.pdf Opens a new window
Philip
by: charlestassePosted on 2011-05-09 at 10:14:49ID: 35722187
You are getting Sense Key 3 Errors, this is an indication of bad blocks at either the logical or physical layer.
You should look at replacing drive 0 as soon as possible once you have a full backup
by: dlethePosted on 2011-05-09 at 10:20:21ID: 35722225
3/11 sense information means that you have an unrecoverable READ error. Your USB-attached disk has officially lost some data. If you do a chkdsk and click off the options to do a full media scan then at least it will force a read and tell you (if you are lucky) what you have lost.
But at this point, all backups are suspect, and if this is your only backup device, then I suggest purchasing another one, and immediately performing a full backup
by: charlestassePosted on 2011-05-09 at 10:40:37ID: 35722338
Although there may be something going on with the USB
Controller ID: 0 Unexpected sense: PD= 0:0, CDB
Sense = 0x70 0x00 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x11 0x00
This message is being generated by the Raid Controller and reporting it on Physical Disk 0 attached to the raid controller
by: vivektvijayanPosted on 2011-05-11 at 12:39:27ID: 35741210
3 11 00 Medium Error — unrecovered read error. Its better to replace hard drive PD 0:0.
Check the controller logs. there might be more media errors.
by: dlethePosted on 2011-05-11 at 13:13:44ID: 35741518
One clarification … if this is a one off, i.e, you only have a few, and haven’t seen a dozen of them just crop up out of nowhere on this one disk, then no need to replace the drive. Just keep an eye on it, and RUN data consistency checks often.
Drives have thousands of spare sectors. A single NRE error is a statistical certainty, not some obscure thing that isn’t ever supposed to happen. You can get this from an improper shutdown while the disk is writing, as a matter of fact.
by: charlestassePosted on 2011-05-11 at 17:50:08ID: 35743150
Your much better off being proactive about this issue than assuming that it is a minor block reallocation issue. Run the Dell Online Diagnostics or the offline 32-Bit diagnostics to verify and keep yourself out of a potential data loss situation
Was this post helpful?
thumb_up
thumb_down
Dear all,
our MSA2324fc (firmware M113R11) with 3 expansion bays MSA70 (firmware 2.28) reports the following messages in the event log which indicate a broken disk to me (the disk is a HP DH0146FAQRE with firmware HPDC):
2013-04-11 23:56:45 B23950 58 An error was detected by a disk drive. (disk: channel: 0, ID: 49, SN: 3TB0G0EH00009007S9AP, enclosure: 2, slot: 18)(Key,Code,Qual:0x3,0x11,0x0)(CDB:Rd 000000cf 0001)(Info:0x000000CF)(CmdSpc:0x0, FRU:0x81, SnsKeySpc:0x97)(Medium Error, unrecovered read error)
2013-04-11 23:56:42 B23949 58 An error was detected by a disk drive. (disk: channel: 0, ID: 49, SN: 3TB0G0EH00009007S9AP, enclosure: 2, slot: 18)(Key,Code,Qual:0x3,0x11,0x0)(CDB:Rd 000000cf 0001)(Info:0x000000CF)(CmdSpc:0x0, FRU:0x81, SnsKeySpc:0x97)(Medium Error, unrecovered read error)
2013-04-11 23:56:41 B23948 58 An error was detected by a disk drive. (disk: channel: 0, ID: 49, SN: 3TB0G0EH00009007S9AP, enclosure: 2, slot: 18)(Key,Code,Qual:0x3,0x11,0x0)(CDB:Rd 00009280 0080)(Info:0x000092F9)(CmdSpc:0x0, FRU:0x81, SnsKeySpc:0x97)(Medium Error, unrecovered read error)
2013-04-11 23:53:53 B23947 58 An error was detected by a disk drive. (disk: channel: 0, ID: 49, SN: 3TB0G0EH00009007S9AP, enclosure: 2, slot: 18)(Key,Code,Qual:0x3,0x11,0x0)(CDB:Rd 000000cf 0001)(Info:0x000000CF)(CmdSpc:0x0, FRU:0x81, SnsKeySpc:0x97)(Medium Error, unrecovered read error)
2013-04-11 23:53:52 B23946 58 An error was detected by a disk drive. (disk: channel: 0, ID: 49, SN: 3TB0G0EH00009007S9AP, enclosure: 2, slot: 18)(Key,Code,Qual:0x3,0x11,0x0)(CDB:Rd 000000cf 0001)(Info:0x000000CF)(CmdSpc:0x0, FRU:0x81, SnsKeySpc:0x97)(Medium Error, unrecovered read error)
2013-04-11 23:53:49 B23945 58 An error was detected by a disk drive. (disk: channel: 0, ID: 49, SN: 3TB0G0EH00009007S9AP, enclosure: 2, slot: 18)(Key,Code,Qual:0x3,0x11,0x0)(CDB:Rd 00009100 0078)(Info:0x0000912A)(CmdSpc:0x0, FRU:0x81, SnsKeySpc:0x97)(Medium Error, unrecovered read error)
2013-04-11 23:34:27 B23944 58 An error was detected by a disk drive. (disk: channel: 0, ID: 49, SN: 3TB0G0EH00009007S9AP, enclosure: 2, slot: 18)(Key,Code,Qual:0x3,0x11,0x0)(CDB:Rd 000000cf 0001)(Info:0x000000CF)(CmdSpc:0x0, FRU:0x81, SnsKeySpc:0x97)(Medium Error, unrecovered read error)
2013-04-11 23:34:26 B23943 58 An error was detected by a disk drive. (disk: channel: 0, ID: 49, SN: 3TB0G0EH00009007S9AP, enclosure: 2, slot: 18)(Key,Code,Qual:0x3,0x11,0x0)(CDB:Rd 000000cf 0001)(Info:0x000000CF)(CmdSpc:0x0, FRU:0x81, SnsKeySpc:0x97)(Medium Error, unrecovered read error)
2013-04-11 23:34:24 B23942 58 An error was detected by a disk drive. (disk: channel: 0, ID: 49, SN: 3TB0G0EH00009007S9AP, enclosure: 2, slot: 18)(Key,Code,Qual:0x3,0x11,0x0)(CDB:Rd 00008180 0080)(Info:0x00008190)(CmdSpc:0x0, FRU:0x81, SnsKeySpc:0x97)(Medium Error, unrecovered read error)
These messages appear as «Informational» messages, not «Critical» or «Warning». The disk LED is green and the vdisk, which the disk 2.18 belongs to, is also green. The most recent background scrub completed without error messages:
2013-04-11 23:09:52B23938207A scrub-vdisk job completed. No errors were found. (vdisk: vd-sokrates-spool, SN: 00c0ffd89e3b0000ae7b604b00000000)
We are concerned about the fact that the MSA does not report this situation as an error and prompt us to replace the disk. Would it be safe to replace this disk? Can we configure the MSA to report this situation as an error / warning instead of a purely informational message?
Best Regards,
Peter
I have an IBM 5015 which has been crossed flashed to LSI 9260-8i. It is installed in a re-purposed PC that is now being used as an esxi server in a home lab. I have four SATA drives configured in RAID10.
I encounter disc latency issues and the following errors in MSM:
Code:
110 [Information, 0] 2016-09-28, 22:10:24 Controller ID: 0 Event From : 192.168.0.100 Corrected medium error during recovery: PD Port 0 - 3:0:2 Location 0x562db028 127
113 [Information, 0] 2016-09-28, 22:10:23 Controller ID: 0 Event From : 192.168.0.100 Unexpected sense: PD
= Port 0 - 3:0:2Unrecovered read error, CDB = 0x28 0x00 0x56 0x2d 0xb0 0x00 0x00 0x00 0xcf 0x00 , Sense = 0xf0 0x00 0x03 0x56 0x2d 0xb0 0x28 0x0a 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x00 0x00 0x00 126
113 [Information, 0] 2016-09-28, 22:10:14 Controller ID: 0 Event From : 192.168.0.100 Unexpected sense: PD
= Port 0 - 3:0:2Unrecovered read error, CDB = 0x28 0x00 0x56 0x2d 0xb0 0x00 0x00 0x00 0xcf 0x00 , Sense = 0xf0 0x00 0x03 0x56 0x2d 0xb0 0x09 0x0a 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x00 0x00 0x00 125
110 [Information, 0] 2016-09-28, 18:05:25 Controller ID: 0 Event From : 192.168.0.100 Corrected medium error during recovery: PD Port 0 - 3:0:2 Location 0x562e374c 124
113 [Information, 0] 2016-09-28, 18:05:24 Controller ID: 0 Event From : 192.168.0.100 Unexpected sense: PD
= Port 0 - 3:0:2Unrecovered read error, CDB = 0x28 0x00 0x56 0x2e 0x37 0x3f 0x00 0x00 0xc1 0x00 , Sense = 0xf0 0x00 0x03 0x56 0x2e 0x37 0x4c 0x0a 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x00 0x00 0x00 123
113 [Information, 0] 2016-09-28, 18:05:19 Controller ID: 0 Event From : 192.168.0.100 Unexpected sense: PD
= Port 0 - 3:0:2Unrecovered read error, CDB = 0x28 0x00 0x56 0x2e 0x37 0x3f 0x00 0x00 0xc1 0x00 , Sense = 0xf0 0x00 0x03 0x56 0x2e 0x37 0x4b 0x0a 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x00 0x00 0x00 122
110 [Information, 0] 2016-09-28, 18:05:15 Controller ID: 0 Event From : 192.168.0.100 Corrected medium error during recovery: PD Port 0 - 3:0:2 Location 0x562e3729 121
113 [Information, 0] 2016-09-28, 18:05:14 Controller ID: 0 Event From : 192.168.0.100 Unexpected sense: PD
= Port 0 - 3:0:2Unrecovered read error, CDB = 0x28 0x00 0x56 0x2e 0x37 0x00 0x00 0x00 0x3f 0x00 , Sense = 0xf0 0x00 0x03 0x56 0x2e 0x37 0x29 0x0a 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x00 0x00 0x00 120
113 [Information, 0] 2016-09-28, 18:05:09 Controller ID: 0 Event From : 192.168.0.100 Unexpected sense: PD
= Port 0 - 3:0:2Unrecovered read error, CDB = 0x28 0x00 0x56 0x2e 0x37 0x00 0x00 0x00 0x3f 0x00 , Sense = 0xf0 0x00 0x03 0x56 0x2e 0x37 0x29 0x0a 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x00 0x00 0x00 119
113 [Information, 0] 2016-09-28, 18:04:49 Controller ID: 0 Event From : 192.168.0.100 Unexpected sense: PD
= Port 0 - 3:0:2Unrecovered read error, CDB = 0x28 0x00 0x56 0x2d 0xc3 0x00 0x00 0x00 0xdf 0x00 , Sense = 0xf0 0x00 0x03 0x56 0x2d 0xc3 0x20 0x0a 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x00 0x00 0x00 118I’m assuming one of the four discs is failing??? How do I identify the bad one without shutting the server down, pulling each drive, attaching each drive to another machine and running a drive scanning utility?


Как не надо восстанавливать данные, или чтобы вам тоже так везло
Время прочтения
15 мин
Просмотры 34K
Все мы периодически сталкиваемся с отказами устройств хранения. В интернете написаны сотни инструкций, как без специального оборудования прочитать все что только возможно с устройств, еще отвечающих на обычные запросы ОС. Но мне долгие годы не везло, диски либо умирали совсем-совсем, либо файловая система была еще доступна и я просто читал все то, что читалось в обычном режиме. И ждал. Должно же было случиться, чтобы умирающий диск попал мне именно в состоянии, требующем большего, чем самые элементарные действия?
И вот этот день настал. На разделе поверх софтового raid0, хранившем, откровенно говоря, всякую ерунду, файлы оказались недоступны, а причина — долгожданный I/O Error. Неожиданным было то, что устройства-носителя второй половинки рэйда вообще не оказалось в выводе fdisk, хотя список файлов был доступен. Перезагрузка — и массив собрался, а файлы прекрасно читаются. В отчете SMART видно огромное количество переназначенных секторов. Как раз то, что нужно. Отключаю диски и начинаю продумывать стратегию восстановления.
Для вычитывания уцелевших секторов решено было использовать GNU ddrescue — специализированную версию dd для чтения данных с умирающих дисков, которая позволяет выбирать стратегию чтения и умеет строить карту диска для продолжения работы после сбоев, а они обязательно будут, работаю ведь с неисправными устройством.
Итак, подключаю первый диск к своему десктопу, и POST торжественно сообщает, что один из подключенных дисков совсем плох. Загрузка ОС прошла штатно, если не считать пару сообщений о каких-то ошибках ata устройства. После успешной загрузки fdisk -l пациента видит, ну наконец-то я буду восстанавливать целостность данных raid0.
ddrescue -ndAvv /dev/sdd1 bad mapbad
Процесс пошел довольно резво, 80 МБ/с. Из-за шума охлаждающего диски вентилятора, изъятого специально по такому случаю из списанного сервера, леденящих кровь звуков чтения умирающего диска было бы не слышно, даже если бы они были. Возможно, не слышать их даже лучше. Меньше знаешь — крепче спишь.
К утру работа ddrescue завершилась, и на новеньком диске лежали образ и карта погибающего товарища. Но повторный запуск ddrescue почему-то завершался подозрительно быстро, а карта
стала такой.
# Rescue Logfile. Created by GNU ddrescue version 1.19
# Command line: ddrescue -ndAvv /dev/sdd1 bad mapbad
# Start time: 2016-02-12 09:05:07
# Current time: 2016-02-12 09:06:45
# Finished
# current_pos current_status
0xAA7A800000 +
# pos size status
0x00000000 0xA6FF000000 +
0xA6FF000000 0x00810000 -
0xA6FF810000 0x0D7F0000 +
0xA70D000000 0x00810000 -
0xA70D810000 0x2887F0000 +
0xA996000000 0x01020000 -
0xA997020000 0x147E0000 +
0xA9AB800000 0x00810000 -
0xA9AC010000 0x4D7F0000 +
0xA9F9800000 0x00810000 -
0xA9FA010000 0x7AFF0000 +
0xAA75000000 0x01840000 -
0xAA76840000 0x03FC0000 +
0xAA7A800000 0x42E258400 -
«Что-то очевидно пошло не так», — подсказал сонный внутренний голос. «А попробуй-ка fdisk -l» — вот, и разум уже подключился. /dev/sdd в выводе не оказалось. — Как такое вообще возможно?, — Ах да, на сервере было тоже самое, — Значит, не все еще пропало: примерно такие мысли обитали в голове весь рабочий день.
Вечером подопытный диск опять подавал признаки жизни, а передо мной стояла непростая задача: что делать с полученным образом, ведь ddrescue c финализированной картой что-либо читать отказывался, оставив мне файл образа меньше размера раздела.
С одной стороны, ddrescue умеет заполнять — блоки произвольными данными, чтобы потом определить битые файлы. С другой стороны, я не просил его делать спарс-файл (параметр -S), и усиленное гугление вопроса о том, как именно будет заполняться меньший-чем-раздел файл образа, осталось без ответа.
Что сделать, чтобы так не переживать
На самом деле нужно было внимательно прочитать инструкцию и найти в ней параметр -p, который резервирует место на диске перед созданием обычного файла.
Полагаться на случай крайне не хотелось, и я решил с калькулятором в руках изучить карту диска. Оказалось, что 96% содержимого диска успешно прочиталось и попало в первый + блок. Но к сожалению, сумма всех + блоков не давала размер считанного образа, что окончательно спутало мне все карты. По-этому я пошел другим путем: раз у меня есть хорошее начало и черт знает что в конце, почему бы не достать старый добрый dd и не слепить из непонятного образа как раз то, с чем можно спокойно работать?
dd if=bad of=bad_new bs=16M count=42751
dd if=/dev/zero of=bad_new bs=1024 seek=700432384 count=32139617
Результат — новенький образ, который теперь в точности такого же размера, как и умирающий раздел, а именно 750153729024 байт. Теперь займемся ноликами в конце. Делаю вручную
такую карту
# Rescue Logfile. Created by GNU ddrescue version 1.19
# Command line: ddrescue -ndAvv /dev/sdd1 bad mapbad
# Start time: 2016-02-12 09:05:07
# Current time: 2016-02-12 09:06:45
# Finished
# current_pos current_status
0xA6FF810000 ?
# pos size status
0x00000000 0xA6FF000000 +
0xA6FF000000 0x00810000 -
0xA6FF810000 0x0D7F0000 ?
0xA70D000000 0x00810000 -
0xA70D810000 0x2887F0000 ?
0xA996000000 0x01020000 -
0xA997020000 0x147E0000 ?
0xA9AB800000 0x00810000 -
0xA9AC010000 0x4D7F0000 ?
0xA9F9800000 0x00810000 -
0xA9FA010000 0x7AFF0000 ?
0xAA75000000 0x01840000 -
0xAA76840000 0x03FC0000 ?
0xAA7A800000 0x42E258400 -
и запускаю:
ddrescue -ndAvv /dev/sdd1 bad_new mapbadУра! Теперь все хорошо. Читающиеся блоки с диска переехали на пустое место нового образа по нужным адресам, а карта опять финализировалась, и мои приключения подходят к концу. Но может быть сделать последний рывок и перечитать — блоки по одному сектору? Теперь даю ddrescue
такую карту
# Rescue Logfile. Created by GNU ddrescue version 1.19
# Command line: ddrescue -ndAvv /dev/sdd1 bad mapbad
# Start time: 2016-02-12 09:05:07
# Current time: 2016-02-12 09:06:45
# Finished
# current_pos current_status
0xA6FF000000 ?
# pos size status
0x00000000 0xA6FF000000 +
0xA6FF000000 0x00810000 ?
0xA6FF810000 0x0D7F0000 +
0xA70D000000 0x00810000 ?
0xA70D810000 0x2887F0000 +
0xA996000000 0x01020000 ?
0xA997020000 0x147E0000 +
0xA9AB800000 0x00810000 ?
0xA9AC010000 0x4D7F0000 +
0xA9F9800000 0x00810000 ?
0xA9FA010000 0x7AFF0000 +
0xAA75000000 0x01840000 ?
0xAA76840000 0x03FC0000 +
0xAA7A800000 0x42E258400 ?
и запускаю так:
ddrescue -ndAvv /dev/sdd1 -с1 bad_new mapbad
В общем, он повел себя совсем не так, как я рассчитывал. Наткнувшись на плохой сектор в — блоке, он переходил к следующему — блоку, пока не зацепился за уверенное чтение из последнего — блока. Час спустя я остановил это безобразие с помощью CTRL-C и запустил чтение на нормальной скорости. Еще несколько гигабайт из конца раздела прочитались, пока ddrescue снова не напоролся на сбойные сектора, что почему-то опять привело к пропаданию /dev/sdd из системы и финализации карты, которая сильно распухла и представляла собой месиво из +, — и ? блоков. Разбирать все это не было уже никакого смысла, и я решил прекратить мучить умирающего и заняться, наконец, сборкой массива. Но перед этим захотелось выяснить, что было бы, если бы я использовал режим заполнения. Готовлю заполнитель и включаю режим заполнения, не забыв заменить карту на первоначальную:
printf "BADSECTOR" > tmpfile
ddrescue --fill-mode=- tmpfile bad mapbad
И получаю еще один образ правильного размера! Как он это сделал для меня осталось загадкой, ведь я несколько раз пересчитал сумму размеров + блоков из карты, и она не совпадала с размером готового файла.
И вот на месте отдающего магнитную душу богу уже его здоровый собрат, а я выполняю команды:
losetup /dev/loop1 bad_new
mdadm --assemble -o /dev/md12 /dev/loop1 /dev/sdd1
Но результат, мягко говоря, не тот, что я ожидал после 24 часов надежды на успех:
mdadm: no RAID superblock on /dev/loop1
mdadm: /dev/loop1 has no superblock - assembly aborted
Что делать, попробуем теперь пообщаться с гуглом и разделами:
#mdadm --examine /dev/loop1
mdadm: No md superblock detected on /dev/loop1.
— То есть как это no md superblock detected?
— А у этого, который пока здоров?
#mdadm --examine /dev/sdd1
/dev/sdd1:
Magic : a92b4efc
Version : 0.90.00
UUID : 64d38efd:b8e92c8c:f5292846:21864477
Creation Time : Fri Oct 10 20:22:23 2008
Raid Level : raid0
Raid Devices : 2
Total Devices : 2
Preferred Minor : 2
Update Time : Fri Oct 10 20:22:23 2008
State : active
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Checksum : 6f768a67 - correct
Events : 1
Chunk Size : 4K
— Версия 0.90.00? А где должен быть суперблок у mdadm 0.90.00?
— В конце раздела.
— А как его прочитать с помощью mdadm?
— Никак.
— То есть как это никак? Ну ладно, так где там он поточнее?
— Не дальше 128K но не ближе 64К от конца раздела, выровнен по границе 64К, размер 4К.
Н-да, беру dd и проверяю:
dd if=/dev/sdd1 of=last128 bs=1024 skip=732571873 count=128
dd if=last128 of=bad_new bs=1024 seek=732571873 count=128
Да, суперблок записался в конец раздела по правильному адресу, но собираться массив с двумя одинаковыми суперблоками все равно не хочет, значит надо дать ему именно тот суперблок, с помирающего.
Снова замена диска, только бы прочитался:
#dd if=/dev/sdd1 of=last128 bs=1024 skip=732571873 count=128
dd: reading `/dev/sdd1': Input/output error
0+0 records in
0+0 records out
«Да, такого удара Великий комбинатор не испытывал никогда», — почему-то в памяти всплыла именно эта бессмертная цитата.
Ну ладно, так легко мы не сдаемся. А мы вот так:
dd if=/dev/sdd1 of=last128 bs=1024 skip=732571873 count=128 conv=noerror
Эх, размер last128 >0 но <128К. И где там что? Как с этим работать? А как сделать нолики-то вместо убитых секторов? А вот так:
dd if=/dev/sdd1 of=last128 bs=1024 skip=732571873 count=128 conv=noerror,sync
Как на самом деле нужно было читать суперблок с раздела raid версии 0.9 (и 1.0)
Делим размер раздела на 64К: 750153729024/(1024*64)=11446437.5
От целой части убираем один блок, это и будет адрес начала суперблока 11446436*64*1024=750153629696
Приводим адрес к блоку 4К: 750153629696/(1024*4)=183142976 и выполняем
dd if=/dev/sdd1 of=superblock bs=4k skip=183142976 count=1
Вот они, последние 128К. Прописываю их в конец образа, перезагружаюсь со здоровым диском, и массив собрался!
Осталась простая команда и:
#mount -o ro /dev/md11 /srv/old/
mount: wrong fs type, bad option, bad superblock on /dev/md11,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so
Ну вот это уже как-то совсем обидно. Последний раз на сервере массив собирался и ext3 монтировалась. Вывод dumpe2fs подозрений не вызывает, статус раздела clean, адреса альтернативных суперблоков видны, но с ними почему-то тоже не монтируется. Надо бы ее полечить, но в таком виде и с половиной данных без бэкапа лечить нельзя. Эх, придется перекинуть еще полтора терабайта. Конечно, по-хорошему надо бы сделать образ с теперь уже условно рабочего диска с помощью ddrescue, но все это уже сильно надоело и поэтому делаю так:
dd if=/dev/md11 of=ext3 bs=16M conv=noerror,sync
И спать, а наутро пробую:
losetup /dev/loop2 ext3
mount -o ro /dev/loop2 /srv/old/
И оно монтируется! Структура каталогов на первый взгляд не изменилась, а файлы, от которых у меня есть хэши, прочитались без ошибок. На восстановленном разделе свободно всего 20 ГБ, поэтому его loop-файл получил заслуженный атрибут:
chattr +i ext3
и запись в fstab:
/srv/ext3 /srv/old ext3 ro,loop 0 0
В качестве заключения дочитавшему до сюда рекомендую:
- настроить автоматическое резервное копирование важных и не очень данных,
- периодически просматривать отчеты SMART,
- использовать для восстановления устройство USB to SATA, или аналогичное для вашего диска,
- относиться к любому диску, с которого нужно снять образ, как к умирающему и использовать GNU ddrescue,
- помнить, что если дело дойдет до восстановления действительно важных данных, то такого везения точно не будет.
Маленький бонус: что ядро linux думало все это время о темной стороне /dev/sdd
Feb 11 23:25:08 vlad kernel: [ 1.966762] ata4.00: configured for UDMA/133
Feb 11 23:25:08 vlad kernel: [ 1.967027] scsi 3:0:0:0: Direct-Access ATA ST3750640AS D PQ: 0 ANSI: 5
Feb 11 23:25:08 vlad kernel: [ 1.999957] sd 3:0:0:0: Attached scsi generic sg3 type 0
Feb 11 23:25:08 vlad kernel: [ 1.999959] sd 3:0:0:0: [sdd] 1465149168 512-byte logical blocks: (750 GB/699 GiB)
Feb 11 23:25:08 vlad kernel: [ 1.999975] sd 3:0:0:0: [sdd] Write Protect is off
Feb 11 23:25:08 vlad kernel: [ 1.999977] sd 3:0:0:0: [sdd] Mode Sense: 00 3a 00 00
Feb 11 23:25:08 vlad kernel: [ 2.000004] sd 3:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
Feb 11 23:25:08 vlad kernel: [ 2.014841] sdd: sdd1
Feb 11 23:25:08 vlad kernel: [ 2.014974] sd 3:0:0:0: [sdd] Attached SCSI removable disk
Feb 11 23:25:08 vlad kernel: [ 6.668531] ata4.00: exception Emask 0x0 SAct 0x20 SErr 0x0 action 0x0
Feb 11 23:25:08 vlad kernel: [ 6.668577] ata4.00: irq_stat 0x40000008
Feb 11 23:25:08 vlad kernel: [ 6.668604] ata4.00: failed command: READ FPDMA QUEUED
Feb 11 23:25:08 vlad kernel: [ 6.668638] ata4.00: cmd 60/08:28:b0:66:54/00:00:57:00:00/40 tag 5 ncq 4096 in
Feb 11 23:25:08 vlad kernel: [ 6.668638] res 51/40:08:b0:66:54/00:00:57:00:00/00 Emask 0x409 (media error) Feb 11 23:25:08 vlad kernel: [ 6.668673] ata4.00: status: { DRDY ERR }
Feb 11 23:25:08 vlad kernel: [ 6.668685] ata4.00: error: { UNC }
Feb 11 23:25:08 vlad kernel: [ 6.756422] ata4.00: configured for UDMA/133
Feb 11 23:25:08 vlad kernel: [ 6.756438] sd 3:0:0:0: [sdd] tag#5 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
Feb 11 23:25:08 vlad kernel: [ 6.756443] sd 3:0:0:0: [sdd] tag#5 Sense Key : Medium Error [current] [descriptor]
Feb 11 23:25:08 vlad kernel: [ 6.756447] sd 3:0:0:0: [sdd] tag#5 Add. Sense: Unrecovered read error - auto reallocate failed
Feb 11 23:25:08 vlad kernel: [ 6.756451] sd 3:0:0:0: [sdd] tag#5 CDB: Read(10) 28 00 57 54 66 b0 00 00 08 00
Feb 11 23:25:08 vlad kernel: [ 6.756454] blk_update_request: I/O error, dev sdd, sector 1465149104
Feb 11 23:25:08 vlad kernel: [ 6.756504] ata4: EH complete
Feb 11 23:25:08 vlad kernel: [ 10.446467] ata4.00: exception Emask 0x0 SAct 0x1 SErr 0x0 action 0x0
Feb 11 23:25:08 vlad kernel: [ 10.446510] ata4.00: irq_stat 0x40000008
Feb 11 23:25:08 vlad kernel: [ 10.446537] ata4.00: failed command: READ FPDMA QUEUED
Feb 11 23:25:08 vlad kernel: [ 10.446570] ata4.00: cmd 60/08:00:b0:66:54/00:00:57:00:00/40 tag 0 ncq 4096 in
Feb 11 23:25:08 vlad kernel: [ 10.446570] res 51/40:08:b0:66:54/00:00:57:00:00/00 Emask 0x409 (media error) Feb 11 23:25:08 vlad kernel: [ 10.446606] ata4.00: status: { DRDY ERR }
Feb 11 23:25:08 vlad kernel: [ 10.446617] ata4.00: error: { UNC }
Feb 11 23:25:08 vlad kernel: [ 10.554902] ata4.00: configured for UDMA/133
Feb 11 23:25:08 vlad kernel: [ 10.554915] sd 3:0:0:0: [sdd] tag#0 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
Feb 11 23:25:08 vlad kernel: [ 10.554920] sd 3:0:0:0: [sdd] tag#0 Sense Key : Medium Error [current] [descriptor]
Feb 11 23:25:08 vlad kernel: [ 10.554923] sd 3:0:0:0: [sdd] tag#0 Add. Sense: Unrecovered read error - auto reallocate failed
Feb 11 23:25:08 vlad kernel: [ 10.554926] sd 3:0:0:0: [sdd] tag#0 CDB: Read(10) 28 00 57 54 66 b0 00 00 08 00
Feb 11 23:25:08 vlad kernel: [ 10.554929] blk_update_request: I/O error, dev sdd, sector 1465149104
Feb 11 23:25:08 vlad kernel: [ 10.554971] Buffer I/O error on dev sdd, logical block 183143638, async page read
Feb 11 23:25:08 vlad kernel: [ 10.555011] ata4: EH complete
Feb 11 23:25:08 vlad kernel: [ 10.641458] md: bindFeb 11 23:25:08 vlad kernel: [ 10.653880] md: linear personality registered for level -1
Feb 11 23:25:08 vlad kernel: [ 10.655703] md: multipath personality registered for level -4
Feb 11 23:25:08 vlad kernel: [ 10.659291] md: raid1 personality registered for level 1
Feb 12 03:41:06 vlad kernel: [15370.712691] ata4.00: status: { DRDY ERR }
Feb 12 03:41:06 vlad kernel: [15370.712693] ata4.00: error: { UNC }
Feb 12 03:41:06 vlad kernel: [15370.808463] ata4.00: configured for UDMA/133
Feb 12 03:41:06 vlad kernel: [15370.808501] sd 3:0:0:0: [sdd] tag#4 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE
Feb 12 03:41:06 vlad kernel: [15370.808505] sd 3:0:0:0: [sdd] tag#4 Sense Key : Medium Error [current] [descriptor]
Feb 12 03:41:06 vlad kernel: [15370.808509] sd 3:0:0:0: [sdd] tag#4 Add. Sense: Unrecovered read error - auto reallocate failed
Feb 12 03:41:06 vlad kernel: [15370.808513] sd 3:0:0:0: [sdd] tag#4 CDB: Read(10) 28 00 55 3b 11 3f 00 08 00 00
Feb 12 03:41:06 vlad kernel: [15370.808515] blk_update_request: I/O error, dev sdd, sector 1429935476
Feb 12 03:41:06 vlad kernel: [15370.808529] ata4: EH complete
Feb 12 03:41:39 vlad kernel: [15403.451737] ata4.00: exception Emask 0x0 SAct 0x7e SErr 0x0 action 0x6 frozen
Feb 12 03:41:39 vlad kernel: [15403.451745] ata4.00: failed command: READ FPDMA QUEUED
Feb 12 03:41:39 vlad kernel: [15403.451751] ata4.00: cmd 60/50:08:3f:68:3d/05:00:55:00:00/40 tag 1 ncq 696320 in
Feb 12 03:41:39 vlad kernel: [15403.451751] res 40/00:48:29:02:3b/00:00:55:00:00/00 Emask 0x4 (timeout)
Feb 12 03:41:39 vlad kernel: [15403.451754] ata4.00: status: { DRDY }
Feb 12 03:41:39 vlad kernel: [15403.451756] ata4.00: failed command: READ FPDMA QUEUED
Feb 12 03:41:39 vlad kernel: [15403.451762] ata4.00: cmd 60/b0:10:8f:6d:3d/02:00:55:00:00/40 tag 2 ncq 352256 in
Feb 12 03:41:39 vlad kernel: [15403.451762] res 40/00:b8:ac:06:3b/00:00:55:00:00/00 Emask 0x4 (timeout)
Feb 12 03:41:39 vlad kernel: [15403.451764] ata4.00: status: { DRDY }
Feb 12 03:41:39 vlad kernel: [15403.451766] ata4.00: failed command: READ FPDMA QUEUED
Feb 12 03:41:39 vlad kernel: [15403.451771] ata4.00: cmd 60/50:18:3f:70:3d/05:00:55:00:00/40 tag 3 ncq 696320 in
Feb 12 03:41:39 vlad kernel: [15403.451771] res 40/00:00:84:09:3b/00:00:55:00:00/00 Emask 0x4 (timeout)
Feb 12 03:41:39 vlad kernel: [15403.451774] ata4.00: status: { DRDY }
Feb 12 03:41:39 vlad kernel: [15403.451776] ata4.00: failed command: READ FPDMA QUEUED
Feb 12 03:41:39 vlad kernel: [15403.451781] ata4.00: cmd 60/b0:20:8f:75:3d/02:00:55:00:00/40 tag 4 ncq 352256 in
Feb 12 03:41:39 vlad kernel: [15403.451781] res 40/00:00:74:15:3b/00:00:55:00:00/00 Emask 0x4 (timeout)
Feb 12 03:41:39 vlad kernel: [15403.451783] ata4.00: status: { DRDY }
Feb 12 03:41:39 vlad kernel: [15403.451785] ata4.00: failed command: READ FPDMA QUEUED
Feb 12 03:41:39 vlad kernel: [15403.451790] ata4.00: cmd 60/18:28:3f:78:3d/07:00:55:00:00/40 tag 5 ncq 929792 in
Feb 12 03:41:39 vlad kernel: [15403.451790] res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout)
Feb 12 03:41:39 vlad kernel: [15403.451793] ata4.00: status: { DRDY }
Feb 12 03:41:39 vlad kernel: [15403.451795] ata4.00: failed command: READ FPDMA QUEUED
Feb 12 03:41:39 vlad kernel: [15403.451800] ata4.00: cmd 60/e8:30:57:7f:3d/00:00:55:00:00/40 tag 6 ncq 118784 in
Feb 12 03:41:39 vlad kernel: [15403.451800] res 40/00:00:00:00:00/00:00:00:00:00/00 Emask 0x4 (timeout)
Feb 12 03:41:39 vlad kernel: [15403.451802] ata4.00: status: { DRDY }
Feb 12 03:41:39 vlad kernel: [15403.451807] ata4: hard resetting link
Feb 12 03:41:44 vlad kernel: [15408.799827] ata4: link is slow to respond, please be patient (ready=0)
Feb 12 03:41:49 vlad kernel: [15413.463949] ata4: COMRESET failed (errno=-16)
Feb 12 03:41:49 vlad kernel: [15413.463958] ata4: hard resetting link
Feb 12 03:41:54 vlad kernel: [15418.816093] ata4: link is slow to respond, please be patient (ready=0)
Feb 12 03:41:59 vlad kernel: [15423.476229] ata4: COMRESET failed (errno=-16)
Feb 12 03:41:59 vlad kernel: [15423.476238] ata4: hard resetting link
Feb 12 03:42:04 vlad kernel: [15428.840370] ata4: link is slow to respond, please be patient (ready=0)
Feb 12 03:42:34 vlad kernel: [15458.509128] ata4: COMRESET failed (errno=-16)
Feb 12 03:42:34 vlad kernel: [15458.509137] ata4: limiting SATA link speed to 1.5 Gbps
Feb 12 03:42:34 vlad kernel: [15458.509139] ata4: hard resetting link
Feb 12 03:42:39 vlad kernel: [15463.525279] ata4: COMRESET failed (errno=-16)
Feb 12 03:42:39 vlad kernel: [15463.525288] ata4: reset failed, giving up
Feb 12 03:42:39 vlad kernel: [15463.525291] ata4.00: disabled
Feb 12 03:42:39 vlad kernel: [15463.525313] ata4.00: device reported invalid CHS sector 0
Feb 12 03:42:39 vlad kernel: [15463.525316] ata4.00: device reported invalid CHS sector 0
Feb 12 03:42:39 vlad kernel: [15463.525328] ata4: EH complete
Feb 12 03:42:39 vlad kernel: [15463.525358] sd 3:0:0:0: [sdd] tag#1 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Feb 12 03:42:39 vlad kernel: [15463.525363] sd 3:0:0:0: [sdd] tag#1 CDB: Read(10) 28 00 55 3d 68 3f 00 05 50 00
Feb 12 03:42:39 vlad kernel: [15463.525366] blk_update_request: I/O error, dev sdd, sector 1430087743
Feb 12 03:42:39 vlad kernel: [15463.525378] sd 3:0:0:0: [sdd] tag#2 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Feb 12 03:42:39 vlad kernel: [15463.525381] sd 3:0:0:0: [sdd] tag#2 CDB: Read(10) 28 00 55 3d 6d 8f 00 02 b0 00
Feb 12 03:42:39 vlad kernel: [15463.525383] blk_update_request: I/O error, dev sdd, sector 1430089103
Feb 12 03:42:39 vlad kernel: [15463.525394] sd 3:0:0:0: [sdd] tag#3 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Feb 12 03:42:39 vlad kernel: [15463.525397] sd 3:0:0:0: [sdd] tag#3 CDB: Read(10) 28 00 55 3d 70 3f 00 05 50 00
Feb 12 03:42:39 vlad kernel: [15463.525399] blk_update_request: I/O error, dev sdd, sector 1430089791
Feb 12 03:42:39 vlad kernel: [15463.525407] sd 3:0:0:0: [sdd] tag#4 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Feb 12 03:42:39 vlad kernel: [15463.525410] sd 3:0:0:0: [sdd] tag#4 CDB: Read(10) 28 00 55 3d 75 8f 00 02 b0 00
Feb 12 03:42:39 vlad kernel: [15463.525412] blk_update_request: I/O error, dev sdd, sector 1430091151
Feb 12 03:42:39 vlad kernel: [15463.525422] sd 3:0:0:0: [sdd] tag#5 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Feb 12 03:42:39 vlad kernel: [15463.525425] sd 3:0:0:0: [sdd] tag#5 CDB: Read(10) 28 00 55 3d 78 3f 00 07 18 00
Feb 12 03:42:39 vlad kernel: [15463.525426] blk_update_request: I/O error, dev sdd, sector 1430091839
Feb 12 03:42:39 vlad kernel: [15463.525434] sd 3:0:0:0: [sdd] tag#6 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Feb 12 03:42:39 vlad kernel: [15463.525436] sd 3:0:0:0: [sdd] tag#6 CDB: Read(10) 28 00 55 3d 7f 57 00 00 e8 00
Feb 12 03:42:39 vlad kernel: [15463.525438] blk_update_request: I/O error, dev sdd, sector 1430093655
Feb 12 03:42:39 vlad kernel: [15463.526601] sd 3:0:0:0: [sdd] tag#8 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Feb 12 03:42:39 vlad kernel: [15463.526607] sd 3:0:0:0: [sdd] tag#8 CDB: Read(10) 28 00 55 3d 80 bf 00 05 48 00
Feb 12 03:42:39 vlad kernel: [15463.526610] blk_update_request: I/O error, dev sdd, sector 1430094015
Feb 12 03:42:39 vlad kernel: [15463.526623] sd 3:0:0:0: [sdd] tag#9 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Feb 12 03:42:39 vlad kernel: [15463.526626] sd 3:0:0:0: [sdd] tag#9 CDB: Read(10) 28 00 55 3d 86 07 00 02 b8 00
Feb 12 03:42:39 vlad kernel: [15463.526628] blk_update_request: I/O error, dev sdd, sector 1430095367
Feb 12 03:42:39 vlad kernel: [15463.526644] sd 3:0:0:0: [sdd] tag#10 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Feb 12 03:42:39 vlad kernel: [15463.526647] sd 3:0:0:0: [sdd] tag#10 CDB: Read(10) 28 00 55 3d 88 bf 00 08 00 00
Feb 12 03:42:39 vlad kernel: [15463.526649] blk_update_request: I/O error, dev sdd, sector 1430096063
Feb 12 03:42:39 vlad kernel: [15463.526666] sd 3:0:0:0: [sdd] tag#11 FAILED Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Feb 12 03:42:39 vlad kernel: [15463.526669] sd 3:0:0:0: [sdd] tag#11 CDB: Read(10) 28 00 55 3d 90 bf 00 08 00 00
Feb 12 03:42:39 vlad kernel: [15463.526670] blk_update_request: I/O error, dev sdd, sector 1430098111
Feb 12 09:04:52 vlad kernel: [34796.610216] blk_update_request: 29908 callbacks suppressed
Feb 12 09:04:52 vlad kernel: [34796.610221] blk_update_request: I/O error, dev sdd, sector 1400864832
Feb 12 09:04:52 vlad kernel: [34796.610231] blk_update_request: I/O error, dev sdd, sector 1400866176
Feb 12 09:04:52 vlad kernel: [34796.610240] blk_update_request: I/O error, dev sdd, sector 1400866880
Feb 12 09:04:52 vlad kernel: [34796.610249] blk_update_request: I/O error, dev sdd, sector 1400868928
Feb 12 09:04:52 vlad kernel: [34796.610258] blk_update_request: I/O error, dev sdd, sector 1400870976
Feb 12 09:04:52 vlad kernel: [34796.610268] blk_update_request: I/O error, dev sdd, sector 1400873024
Feb 12 09:04:52 vlad kernel: [34796.610277] blk_update_request: I/O error, dev sdd, sector 1400875072
Feb 12 09:04:52 vlad kernel: [34796.610286] blk_update_request: I/O error, dev sdd, sector 1400877120
Feb 12 09:04:52 vlad kernel: [34796.610295] blk_update_request: I/O error, dev sdd, sector 1400879168
Feb 12 09:04:52 vlad kernel: [34796.610301] blk_update_request: I/O error, dev sdd, sector 1400880512
10.07.2019, 13:40. Показов 4361. Ответов 2

Здравствуйте, последние пару дней начали валиться ошибки:
Код
MegaRAID Storage Manager 13.01.04.00Event Log - Generated on Wed Jul 10 16:30:22 YEKT 2019 ------------------------------------------------------------------------------------------- ID = 10000 TIME = 10-07-2019 16:24:53 LOCALIZED MESSAGE = Successful log on to the server User: администратор, Client: 172.16.3.234, Access Mode: Full, Client Time: 2019-07-10,16:24:53 ID = 110 SEQUENCE NUMBER = 45574 TIME = 08-07-2019 17:09:10 LOCALIZED MESSAGE = Controller ID: 0 Corrected medium error during recovery: PD -:-:0 Location 0x15a15660 ID = 113 SEQUENCE NUMBER = 45573 TIME = 08-07-2019 17:09:10 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x15 0xa1 0x56 0x60 0x00 0x00 0x10 0x00 , Sense = 0xf0 0x00 0x03 0x15 0xa1 0x56 0x60 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x00 0x70 0x7e 0x00 0x01 0xf7 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45572 TIME = 08-07-2019 17:09:09 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x15 0xa1 0x56 0x60 0x00 0x00 0x10 0x00 , Sense = 0xf0 0x00 0x03 0x15 0xa1 0x56 0x60 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x00 0x70 0x7e 0x00 0x01 0xf7 0x00 0x00 ID = 110 SEQUENCE NUMBER = 45571 TIME = 08-07-2019 17:09:08 LOCALIZED MESSAGE = Controller ID: 0 Corrected medium error during recovery: PD -:-:0 Location 0x15a15680 ID = 113 SEQUENCE NUMBER = 45570 TIME = 08-07-2019 17:09:08 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x15 0xa1 0x56 0x80 0x00 0x00 0x40 0x00 , Sense = 0xf0 0x00 0x03 0x15 0xa1 0x56 0x80 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x00 0x70 0x7e 0x00 0x02 0x17 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45569 TIME = 08-07-2019 17:09:07 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x15 0xa1 0x56 0x80 0x00 0x00 0x40 0x00 , Sense = 0xf0 0x00 0x03 0x15 0xa1 0x56 0x80 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x00 0x70 0x7e 0x00 0x02 0x17 0x00 0x00 ID = 110 SEQUENCE NUMBER = 45568 TIME = 08-07-2019 17:09:07 LOCALIZED MESSAGE = Controller ID: 0 Corrected medium error during recovery: PD -:-:0 Location 0x15a15881 ID = 113 SEQUENCE NUMBER = 45567 TIME = 08-07-2019 17:09:07 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x15 0xa1 0x58 0x80 0x00 0x00 0x48 0x00 , Sense = 0xf0 0x00 0x03 0x15 0xa1 0x58 0x81 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x00 0x70 0x7e 0x00 0x04 0x18 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45566 TIME = 08-07-2019 17:09:06 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x15 0xa1 0x58 0x80 0x00 0x00 0x48 0x00 , Sense = 0xf0 0x00 0x03 0x15 0xa1 0x58 0x81 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x00 0x70 0x7e 0x00 0x04 0x18 0x00 0x00 ID = 110 SEQUENCE NUMBER = 45565 TIME = 08-07-2019 14:04:16 LOCALIZED MESSAGE = Controller ID: 0 Corrected medium error during recovery: PD -:-:0 Location 0x15a15880 ID = 113 SEQUENCE NUMBER = 45564 TIME = 08-07-2019 14:04:16 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x15 0xa1 0x58 0x80 0x00 0x00 0x48 0x00 , Sense = 0xf0 0x00 0x03 0x15 0xa1 0x58 0x80 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x00 0x70 0x7e 0x00 0x04 0x17 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45563 TIME = 08-07-2019 14:04:15 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x15 0xa1 0x58 0x80 0x00 0x00 0x48 0x00 , Sense = 0xf0 0x00 0x03 0x15 0xa1 0x58 0x80 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x00 0x70 0x7e 0x00 0x04 0x17 0x00 0x00 ID = 110 SEQUENCE NUMBER = 45562 TIME = 08-07-2019 12:44:07 LOCALIZED MESSAGE = Controller ID: 0 Corrected medium error during recovery: PD -:-:0 Location 0x15a15650 ID = 113 SEQUENCE NUMBER = 45561 TIME = 08-07-2019 12:44:07 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x15 0xa1 0x56 0x50 0x00 0x00 0x20 0x00 , Sense = 0xf0 0x00 0x03 0x15 0xa1 0x56 0x50 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x00 0x70 0x7e 0x00 0x01 0xe7 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45560 TIME = 08-07-2019 12:44:06 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x15 0xa1 0x56 0x50 0x00 0x00 0x20 0x00 , Sense = 0xf0 0x00 0x03 0x15 0xa1 0x56 0x50 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x00 0x70 0x7e 0x00 0x01 0xe7 0x00 0x00 ID = 110 SEQUENCE NUMBER = 45559 TIME = 07-07-2019 20:36:59 LOCALIZED MESSAGE = Controller ID: 0 Corrected medium error during recovery: PD -:-:0 Location 0x12d59c08 ID = 113 SEQUENCE NUMBER = 45558 TIME = 07-07-2019 20:36:59 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x12 0xd5 0x9c 0x00 0x00 0x00 0x10 0x00 , Sense = 0xf0 0x00 0x03 0x12 0xd5 0x9c 0x08 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x00 0x61 0x66 0x00 0x05 0xe9 0x00 0x00 ID = 110 SEQUENCE NUMBER = 45557 TIME = 07-07-2019 20:36:05 LOCALIZED MESSAGE = Controller ID: 0 Corrected medium error during recovery: PD -:-:0 Location 0x12d59c10 ID = 113 SEQUENCE NUMBER = 45556 TIME = 07-07-2019 20:36:05 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x12 0xd5 0x9c 0x10 0x00 0x00 0x40 0x00 , Sense = 0xf0 0x00 0x03 0x12 0xd5 0x9c 0x10 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x00 0x61 0x66 0x00 0x05 0xf1 0x00 0x00 ID = 58 SEQUENCE NUMBER = 45555 TIME = 07-07-2019 07:20:54 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check done on VD: 0 ID = 57 SEQUENCE NUMBER = 45532 TIME = 07-07-2019 07:04:02 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369edb2f, PD -:-:0 Location 0x369edb2f) ID = 57 SEQUENCE NUMBER = 45531 TIME = 07-07-2019 07:04:02 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369edb2d, PD -:-:0 Location 0x369edb2d) ID = 57 SEQUENCE NUMBER = 45530 TIME = 07-07-2019 07:04:02 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369edb2c, PD -:-:0 Location 0x369edb2c) ID = 57 SEQUENCE NUMBER = 45529 TIME = 07-07-2019 07:04:02 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369edb2b, PD -:-:0 Location 0x369edb2b) ID = 57 SEQUENCE NUMBER = 45528 TIME = 07-07-2019 07:04:02 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369edb2a, PD -:-:0 Location 0x369edb2a) ID = 57 SEQUENCE NUMBER = 45527 TIME = 07-07-2019 07:04:02 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369edb28, PD -:-:0 Location 0x369edb28) ID = 57 SEQUENCE NUMBER = 45526 TIME = 07-07-2019 07:04:02 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369edb12, PD -:-:0 Location 0x369edb12) ID = 57 SEQUENCE NUMBER = 45525 TIME = 07-07-2019 07:04:02 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369edb11, PD -:-:0 Location 0x369edb11) ID = 57 SEQUENCE NUMBER = 45524 TIME = 07-07-2019 07:04:02 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369edb10, PD -:-:0 Location 0x369edb10) ID = 113 SEQUENCE NUMBER = 45523 TIME = 07-07-2019 07:04:02 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xdb 0x2e 0x00 0x00 0x52 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xdb 0x2f 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe1 0x00 0x02 0xec 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45522 TIME = 07-07-2019 07:04:01 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xdb 0x2d 0x00 0x00 0x53 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xdb 0x2d 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe1 0x00 0x02 0xea 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45521 TIME = 07-07-2019 07:04:01 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xdb 0x2c 0x00 0x00 0x54 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xdb 0x2c 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe1 0x00 0x02 0xe9 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45520 TIME = 07-07-2019 07:04:00 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xdb 0x2b 0x00 0x00 0x55 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xdb 0x2b 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe1 0x00 0x02 0xe8 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45519 TIME = 07-07-2019 07:03:59 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xdb 0x29 0x00 0x00 0x57 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xdb 0x2a 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe1 0x00 0x02 0xe7 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45518 TIME = 07-07-2019 07:03:57 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xdb 0x13 0x00 0x00 0x6d 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xdb 0x28 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe1 0x00 0x02 0xe5 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45517 TIME = 07-07-2019 07:03:56 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xdb 0x12 0x00 0x00 0x6e 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xdb 0x12 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe1 0x00 0x02 0xcf 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45516 TIME = 07-07-2019 07:03:55 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xdb 0x11 0x00 0x00 0x6f 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xdb 0x11 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe1 0x00 0x02 0xce 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45515 TIME = 07-07-2019 07:03:55 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xdb 0x00 0x00 0x00 0x80 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xdb 0x10 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe1 0x00 0x02 0xcd 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45514 TIME = 07-07-2019 07:03:54 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xdb 0x00 0x00 0x00 0x80 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xdb 0x10 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe1 0x00 0x02 0xcd 0x00 0x00 ID = 57 SEQUENCE NUMBER = 45513 TIME = 07-07-2019 07:03:51 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369eda76, PD -:-:0 Location 0x369eda76) ID = 57 SEQUENCE NUMBER = 45512 TIME = 07-07-2019 07:03:51 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369eda75, PD -:-:0 Location 0x369eda75) ID = 57 SEQUENCE NUMBER = 45511 TIME = 07-07-2019 07:03:51 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369eda73, PD -:-:0 Location 0x369eda73) ID = 57 SEQUENCE NUMBER = 45510 TIME = 07-07-2019 07:03:51 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369eda72, PD -:-:0 Location 0x369eda72) ID = 57 SEQUENCE NUMBER = 45509 TIME = 07-07-2019 07:03:51 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369eda71, PD -:-:0 Location 0x369eda71) ID = 57 SEQUENCE NUMBER = 45508 TIME = 07-07-2019 07:03:51 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369eda70, PD -:-:0 Location 0x369eda70) ID = 57 SEQUENCE NUMBER = 45507 TIME = 07-07-2019 07:03:51 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369eda42, PD -:-:0 Location 0x369eda42) ID = 57 SEQUENCE NUMBER = 45506 TIME = 07-07-2019 07:03:51 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369eda41, PD -:-:0 Location 0x369eda41) ID = 57 SEQUENCE NUMBER = 45505 TIME = 07-07-2019 07:03:51 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x369eda40, PD -:-:0 Location 0x369eda40) ID = 113 SEQUENCE NUMBER = 45504 TIME = 07-07-2019 07:03:51 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xda 0x76 0x00 0x00 0x0a 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xda 0x76 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe0 0x00 0x01 0xc2 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45503 TIME = 07-07-2019 07:03:50 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xda 0x74 0x00 0x00 0x0c 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xda 0x75 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe0 0x00 0x01 0xc1 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45502 TIME = 07-07-2019 07:03:49 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xda 0x73 0x00 0x00 0x0d 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xda 0x73 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe0 0x00 0x01 0xbf 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45501 TIME = 07-07-2019 07:03:48 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xda 0x72 0x00 0x00 0x0e 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xda 0x72 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe0 0x00 0x01 0xbe 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45500 TIME = 07-07-2019 07:03:47 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xda 0x71 0x00 0x00 0x0f 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xda 0x71 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe0 0x00 0x01 0xbd 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45499 TIME = 07-07-2019 07:03:46 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xda 0x43 0x00 0x00 0x3d 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xda 0x70 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe0 0x00 0x01 0xbc 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45498 TIME = 07-07-2019 07:03:45 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xda 0x42 0x00 0x00 0x3e 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xda 0x42 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe0 0x00 0x01 0x8e 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45497 TIME = 07-07-2019 07:03:44 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xda 0x41 0x00 0x00 0x3f 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xda 0x41 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe0 0x00 0x01 0x8d 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45496 TIME = 07-07-2019 07:03:43 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xda 0x00 0x00 0x00 0x80 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xda 0x40 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe0 0x00 0x01 0x8c 0x00 0x00 ID = 113 SEQUENCE NUMBER = 45495 TIME = 07-07-2019 07:03:42 LOCALIZED MESSAGE = Controller ID: 0 Unexpected sense: PD = -:-:0Unrecovered read error, CDB = 0x28 0x00 0x36 0x9e 0xda 0x00 0x00 0x00 0x80 0x00 , Sense = 0xf0 0x00 0x03 0x36 0x9e 0xda 0x40 0x18 0x00 0x00 0x00 0x00 0x11 0x00 0x00 0x80 0x00 0x4d 0x00 0x00 0xf7 0x2d 0x00 0x00 0x01 0x34 0xe0 0x00 0x01 0x8c 0x00 0x00 ID = 57 SEQUENCE NUMBER = 45493 TIME = 07-07-2019 07:03:08 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x36484647, PD -:-:0 Location 0x36484647) ID = 57 SEQUENCE NUMBER = 45492 TIME = 07-07-2019 07:03:08 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x36484646, PD -:-:0 Location 0x36484646) ID = 57 SEQUENCE NUMBER = 45491 TIME = 07-07-2019 07:03:08 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x36484645, PD -:-:0 Location 0x36484645) ID = 57 SEQUENCE NUMBER = 45490 TIME = 07-07-2019 07:03:08 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x36484644, PD -:-:0 Location 0x36484644) ID = 57 SEQUENCE NUMBER = 45489 TIME = 07-07-2019 07:03:08 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x36484643, PD -:-:0 Location 0x36484643) ID = 57 SEQUENCE NUMBER = 45488 TIME = 07-07-2019 07:03:08 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x36484642, PD -:-:0 Location 0x36484642) ID = 57 SEQUENCE NUMBER = 45487 TIME = 07-07-2019 07:03:08 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x36484641, PD -:-:0 Location 0x36484641) ID = 57 SEQUENCE NUMBER = 45486 TIME = 07-07-2019 07:03:08 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x36484640, PD -:-:0 Location 0x36484640) ID = 57 SEQUENCE NUMBER = 45485 TIME = 07-07-2019 07:03:08 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x3648463f, PD -:-:0 Location 0x3648463f) ID = 57 SEQUENCE NUMBER = 45484 TIME = 07-07-2019 07:03:08 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x3648463e, PD -:-:0 Location 0x3648463e) ID = 57 SEQUENCE NUMBER = 45483 TIME = 07-07-2019 07:03:08 LOCALIZED MESSAGE = Controller ID: 0 Consistency Check corrected medium error: ( VD 0 Location 0x3648463d, PD -:-:0 Location 0x3648463d)
Ну и так далее. Полный лог во вложении.
Подскажите, пожалуйста, что это может быть?
Спасибо.
__________________
Помощь в написании контрольных, курсовых и дипломных работ, диссертаций здесь
0