
[Удален]
19 июня 2010, 13:08
6483
Всех приветствую.
Только что залес в панель вебмастера Яндекса.
Решил проверить индексируется ли разные папки и файлы сайта.
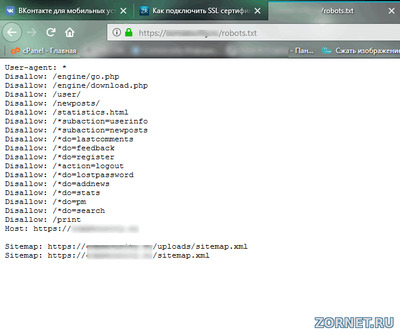
Я запретил все в robots.txt
User-agent: *
Dissalow: /
При добавлении ссылки сайта в «Список URL» и его проверки в Результатах проверки URL появляется такая вот надпись: этот URL не принадлежит вашему домену — что это значит?
Причем такая ерунда появляется только если вначале ссылки написано http://
http://мой сайт/poslednie-novosti/ — этот URL не принадлежит вашему домену
www.мой сайт/poslednie-novosti/ — запрещен правилом /
Подскажите что это и стоит ли с этим бороться) и если стоит, то как?
P
На сайте с 09.01.2010
Offline
26
Заданный URL не принадлежит сайту, для которого производится анализ robots.txt. Возможно, вы указали адрес одного из зеркал вашего сайта или допустили ошибку в написании имени домена.
Справочник по ошибкам анализа robots.txt
Видимо основным зеркалом является www.мой сайт..
[Удален]
19 июня 2010, 14:02
#2
Зеркал у сайта никаких нет и никогда не было.
И как это сайт с www стал зеркалом или наоборот? не понимаю!
И что с этим теперь делать?
Никаких ошибок в написании домена нет точно.
T
На сайте с 12.03.2010
Offline
32
karaul777:
Зеркал у сайта никаких нет и никогда не было.
И как это сайт с www стал зеркалом или наоборот? не понимаю!
И что с этим теперь делать?
Никаких ошибок в написании домена нет точно.
для яндекса имеет занчение с WWW или без. Посмотрите как ваш сайт в выдаче идет, с www или без.
[Удален]
19 июня 2010, 14:51
#4
Triol:
для яндекса имеет занчение с WWW или без. Посмотрите как ваш сайт в выдаче идет, с www или без.
Сайт идет в выдаче с WWW
Но что это за проблема и как ее решить?
Как так вообще получилось?

На сайте с 24.06.2009
Offline
116
у меня кстати тоже самое. Но я сам прописал специально с www как главное зеркало, но там неожиданно вылезли дубли, а запретить через роботс их не могу, т.к. они с вв и выдается та же ошибка — что урл не принадлежит вашему сайту.
На сайте с 24.06.2009
Offline
116
у меня кстати тоже самое. Но я сам прописал специально с www как главное зеркало, но там неожиданно вылезли дубли, а запретить через роботс их не могу, т.к. они с вв и выдается та же ошибка — что урл не принадлежит вашему сайту.
[Удален]
19 июня 2010, 16:29
#7
Mills:
у меня кстати тоже самое. Но я сам прописал специально с www как главное зеркало, но там неожиданно вылезли дубли, а запретить через роботс их не могу, т.к. они с вв и выдается та же ошибка — что урл не принадлежит вашему сайту.
А где вы прописали сами специально?

На сайте с 23.11.2003
Offline
104
было такое недавно, пишите Платону — поправят.
T
На сайте с 12.03.2010
Offline
32
А вот что сам Яша говорит по этому поводу:
Yandex:
Почему анализатор выдает ошибку «Этот URL не принадлежит вашему домену»?
Скорее всего, в списке URL вы указали адрес одного из зеркал вашего сайта, например, http://site.ru вместо http://www.site.ru (формально, это два различных URL). Необходимо, чтобы проверяемые URL принадлежали сайту, для которого производится анализ robots.txt.
http://help.yandex.ru/webmaster/?id=999047
очень полезно тыкать ссылки вокруг той формы куда вы вбиваете адреса.)))
На сайте с 24.06.2009
Offline
116
это ясно…
а как в роботсе тогда запретить ненужный дубль c www?
я же могу прописать только Disallow: /что-то.
Когда копирую урл (дубль с www), то выдается сообщение, что он разрешен к индексации (хотя я его запретил через Disallow). А когда без www, то урл не принадлежит вашему сайту.
- Новые сообщения
- Участники
- Правила форума
- Поиск
- RSS
|
Как подключить SSL сертификат на сайт? |
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|








Как устранить проблему «Несоответствующие домены»
В URL целевой страницы товара должен использоваться тот же домен, что и в адресе сайта, указанном в аккаунте Merchant Center.
Эта ошибка означает, что ссылка на целевую страницу, указанная в фиде данных, не совпадает с доменом URL, который зарегистрирован в вашем аккаунте Merchant Center.
Вот несколько распространенных причин этой ошибки:
- Вы не зарегистрировали URL в своем аккаунте. Если вы указываете в фиде ссылки на свой сайт, вам нужно зарегистрировать его домен.
- Вы зарегистрировали URL, но он не соответствует ссылкам из вашего файла. Ссылки, указанные в фиде, должны соответствовать домену сайта, зарегистрированному в вашем аккаунте Merchant Center.
Например, если нужно отправить файл с URL http://www.example.com/item1.html, зарегистрируйте в своем аккаунте домен родительского сайта http://www.example.com/.
Подробнее о том, как изменить зарегистрированный URL сайта, написано здесь. Чтобы отправлять фиды для нескольких доменов, можно запросить мультиаккаунт.
Инструкции
Шаг 1. Посмотрите список товаров, в которых есть ошибки
- Войдите в аккаунт Merchant Center.
- Перейдите на вкладку Товары в меню навигации и выберите Диагностика.
- Нажмите Проблемы с товарами. Откроется список затронутых позиций.
Как скачать список всех затронутых товаров (в формате .csv)
Как скачать список всех товаров с конкретной проблемой (в формате .csv)
- Найдите проблему в одноименном столбце и нажмите на значок скачивания
 в конце строки.
в конце строки.
Как посмотреть 50 самых популярных товаров с определенной проблемой
- Найдите проблему в одноименном столбце и нажмите Посмотреть примеры в столбце «Затронутые товары».
Шаг 2. Убедитесь, что все URL в фиде данных совпадают с URL, зарегистрированным в вашем аккаунте
- Отфильтруйте данные в скачанном отчете так, чтобы в столбце Issue title (Название проблемы) отображалось только следующее значение:
Mismatched domains (Несоответствующие домены). - Изучите список распространенных причин, приведенный в начале статьи, и определите, какая из них относится к вашей ситуации. Обновите сведения о товарах так, чтобы URL каждой позиции соответствовал домену, зарегистрированному в аккаунте Merchant Center.
Шаг 3. Повторно загрузите сведения о товарах
- После изменения данных о товаре отправьте их повторно, выбрав один из перечисленных ниже способов.
- Добавить фид напрямую
- Как отправить данные с помощью Content API
- Как импортировать данные с платформы электронной торговли
- Перейдите на страницу «Диагностика» и убедитесь, что проблема решена.
Обратите внимание, что изменения на этой странице могут появиться не сразу.
Статьи по теме
- Ссылка на изображение
[image_link] - Как подтвердить сайт своего магазина и заявить права на него
Эта информация оказалась полезной?
Как можно улучшить эту статью?
by Loredana Harsana
Loredana is a passionate writer with a keen interest in PC software and technology. She started off writing about mobile phones back when Samsung Galaxy S II was… read more
Published on January 28, 2022
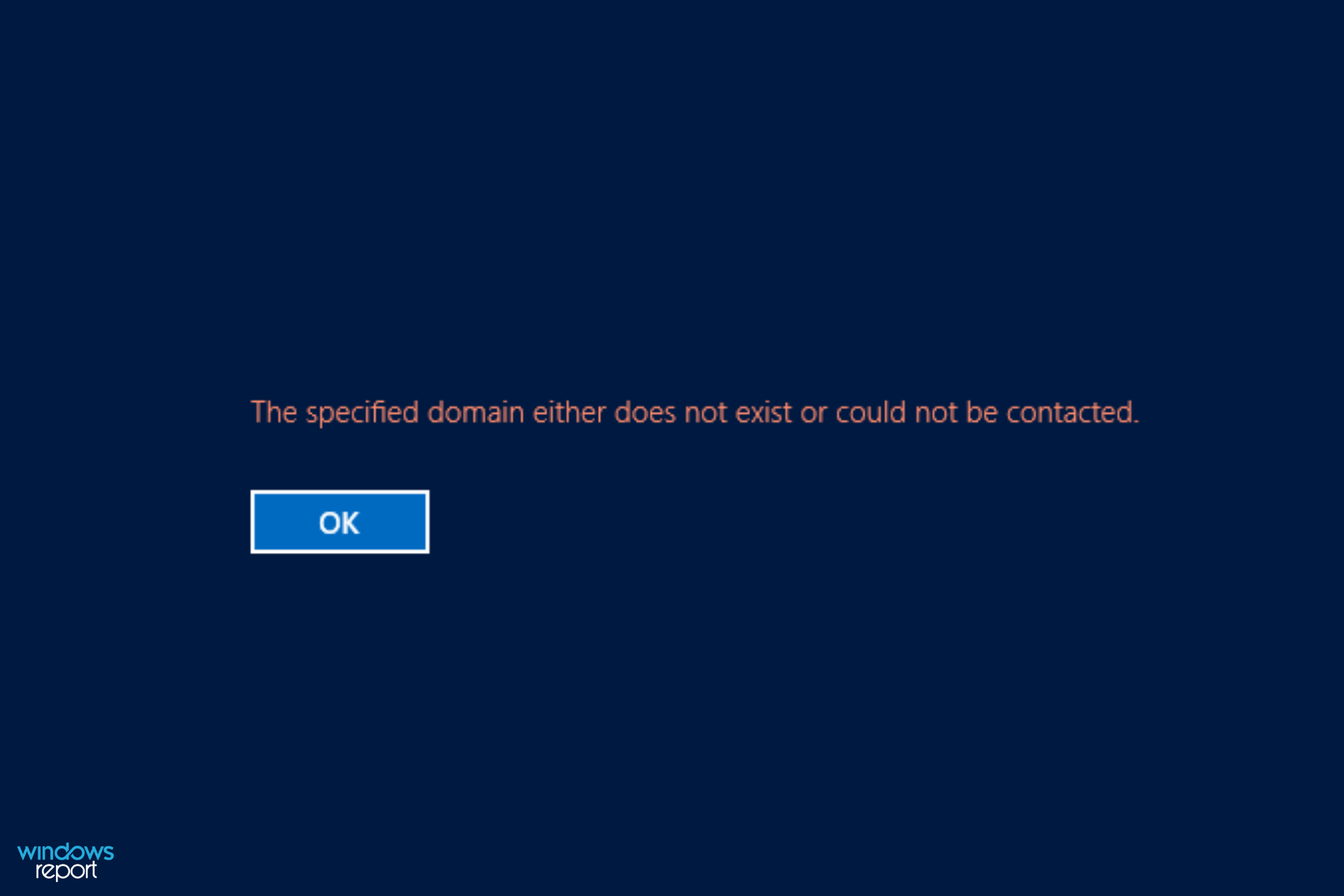
- Domain error messages are a frequent source of frustration. If the specified domain either does not exist or could not be contacted, this indicates a configuration problem.
- Troubleshooting such an error only takes a few minutes and can save a lot of time if you don’t have to reinstall Windows.
- DNS is a very useful and important protocol. If it is corrupted, you may experience problems accessing your domain.
XINSTALL BY CLICKING THE DOWNLOAD FILE
- Download Restoro PC Repair Tool that comes with Patented Technologies (patent available here).
- Click Start Scan to find Windows 11 issues that could be causing PC problems.
- Click Repair All to fix issues affecting your computer’s security and performance
- Restoro has been downloaded by 0 readers this month.
There are a lot of reasons why your computer might be unable to connect to the domain. When you try to connect to the server, you may come across this error: The specified domain either does not exist or could not be contacted.
When you encounter it, this means that the specific domain that you are trying to access is not responding to the request. This may be because it does not exist or because there is a problem with the DNS servers.
It is responsible for mapping domain names to their IP address. When you type www.google.com in your browser, it uses DNS to find out the actual IP address of google servers and connects to it.
If you have a domain name that isn’t resolving, there are a few things to check. The most common issue is that you have typed the URL incorrectly.
Can an invalid URL cause The specified domain either does not exist or could not be contacted error?
Having the right URL is essential in order for the website to load properly. If you are using a bookmark or typing it in manually, make sure you’ve copied and pasted it correctly without any typos.
First of all, if you’re using your web browser’s address bar, then you need to make sure that the website address is entered correctly.
Sometimes, it may become broken or contain an invalid syntax, and therefore cause an error when accessing the site.
If possible, try correcting the URL so that it is spelled correctly and has no missing punctuation marks or any other characters which might make it invalid.
Why does The specified domain either does not exist or could not be contacted error occur?
Although DNS addresses are a common cause of this error, there are many other possible causes. Many people experience the error and the instinct is to run through a series of troubleshooting steps.
Unfortunately, most of these are futile and can end up wasting an hour or two before you realize that the problem is something else entirely.
Some PC issues are hard to tackle, especially when it comes to corrupted repositories or missing Windows files. If you are having troubles fixing an error, your system may be partially broken.
We recommend installing Restoro, a tool that will scan your machine and identify what the fault is.
Click here to download and start repairing.
Some of the common reasons the error occurs include:
- The DNS you are currently using is not functioning properly and it might be a sign that it is getting corrupted. If your computer is not working as you expect it to, or if you have some problems with your connection, then don’t hesitate and try to fix the issue by changing your current server.
- IPv6 protocol may have failed for your network so you may want to disable it. The problem that you might be facing is that your router does not support it.
- You may have misconfigured network settings. Check your network settings to make sure that nothing is wrong with them. If there is, fix it. Make sure that the computer or router you’re trying to access the files from has the correct IP address, and that they match what’s in your PC’s network settings.
- Misconfigured registry keys could also be the cause of the error. Sometimes, if one of these keys gets corrupted and the system fails to fix it automatically, then manual editing of the system files might be required.
What can I do to fix The specified domain either does not exist or could not be contacted error?
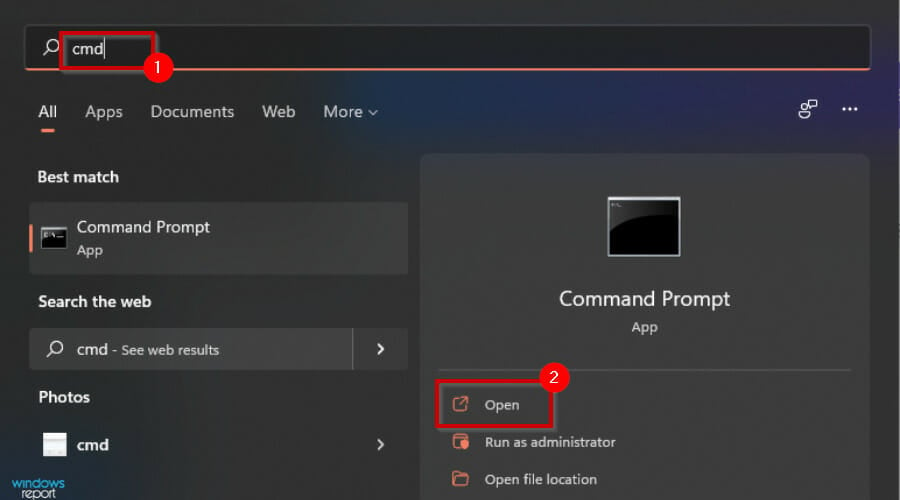
1. Use a different DNS address
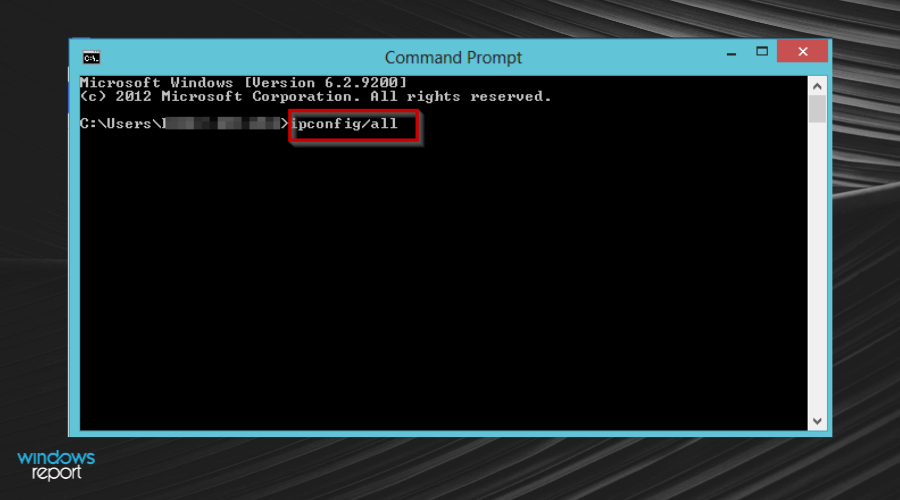
- Press the Windows key, type cmd, and click Open.

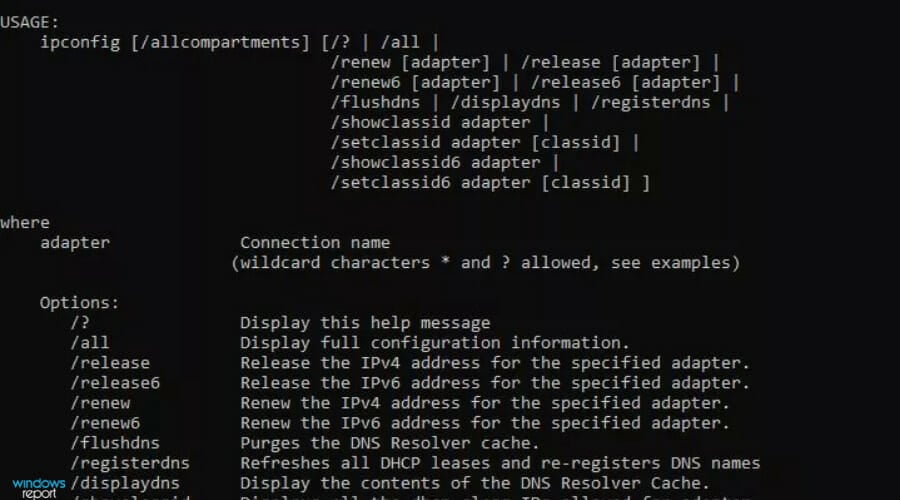
- Enter the following command prompt and take note of the Default Gateway and DNS addresses:
ipconfig /all
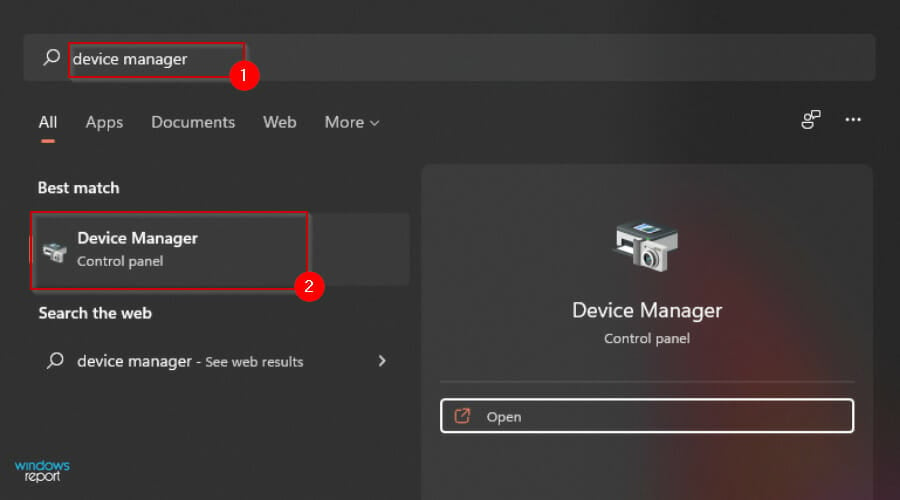
- Next, press the Windows key and search for Device Manager to open.
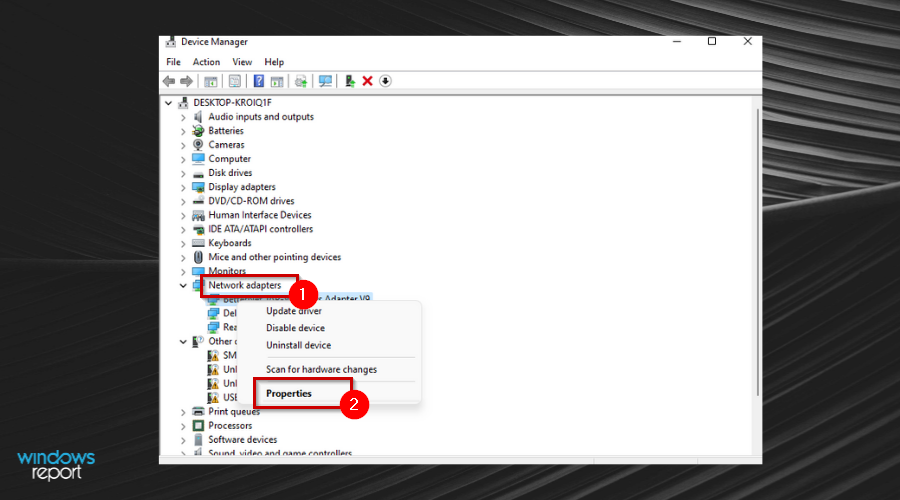
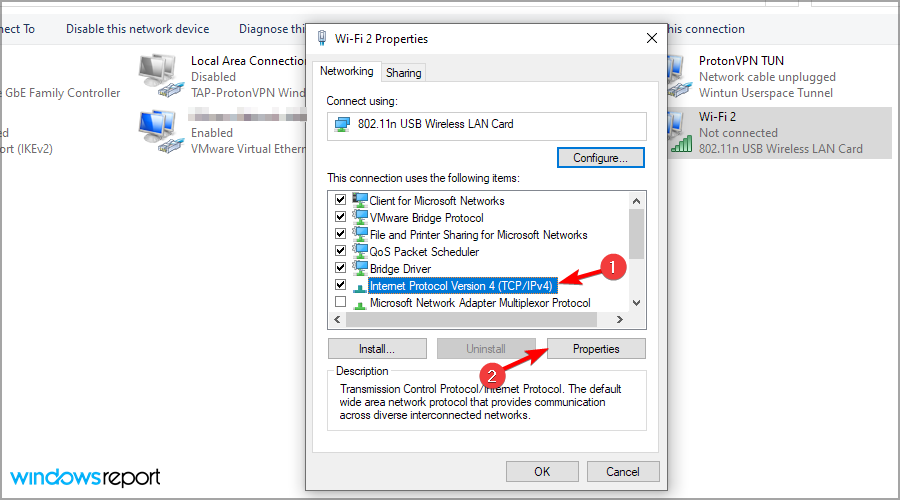
- Right-click the Network Adapter and click on the Properties button.
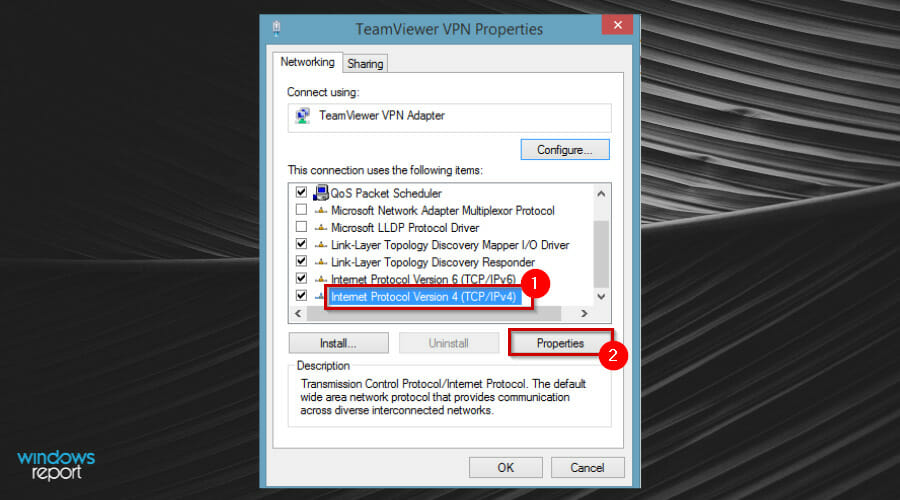
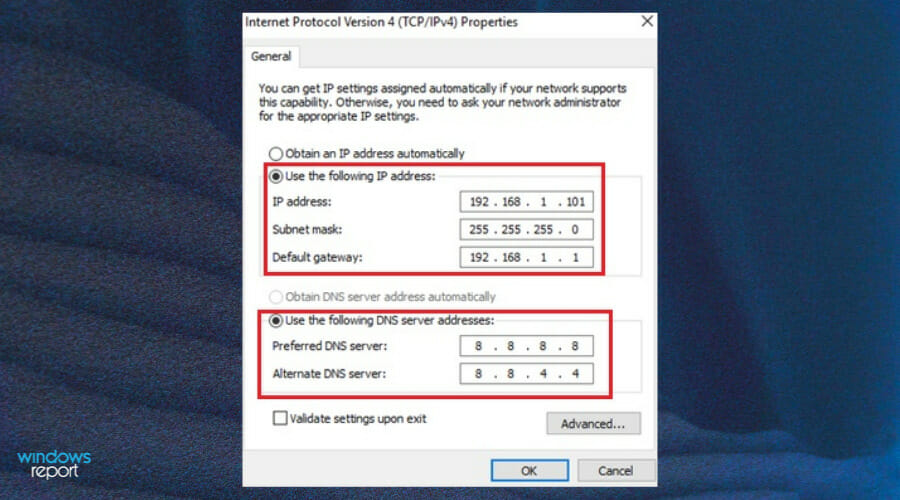
- Find the Internet Protocol Version 4 (TCP/IPv4) item and click on the Properties button.
- On the General tab, change the Preferred DNS server address to match the Primary Domain Controller’s IP Address and press OK.
2. Disable IPv6 and run several useful commands
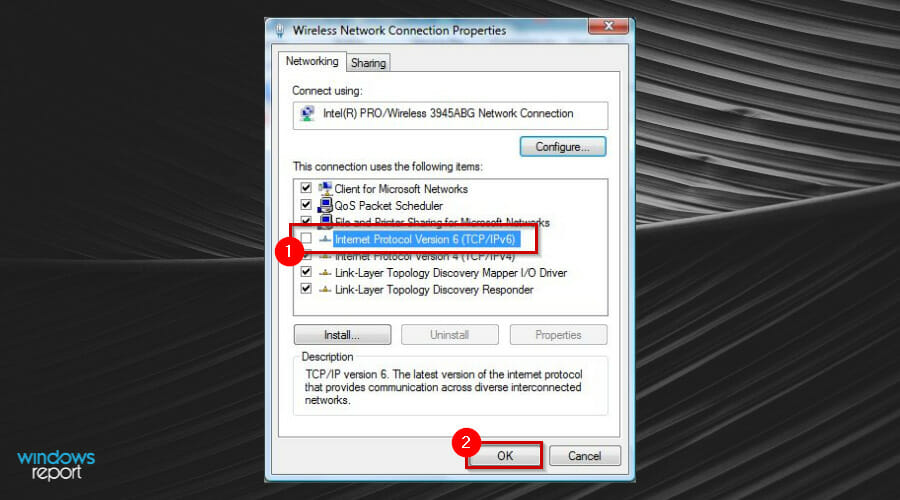
- Press the Windows key, search for Device Manager, and click on it to open.
- Once the Device Manager window opens, right-click on Network adapter to select Properties.
- Locate Internet Protocol Version 6, disable the checkbox, and click OK.
- Restart your device for the changes to take effect.
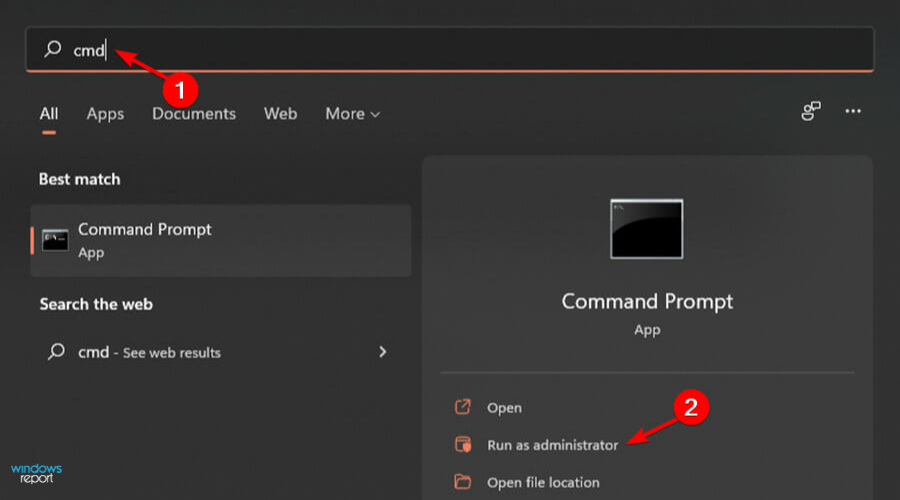
- Hit the Windows key and type cmd in the search bar.
- Run the following commands by pressing Enter after each one:
ipconfig/flushdnsipconfig/releaseipconfig/release6ipconfig/renew
- Try connecting to the domain again.
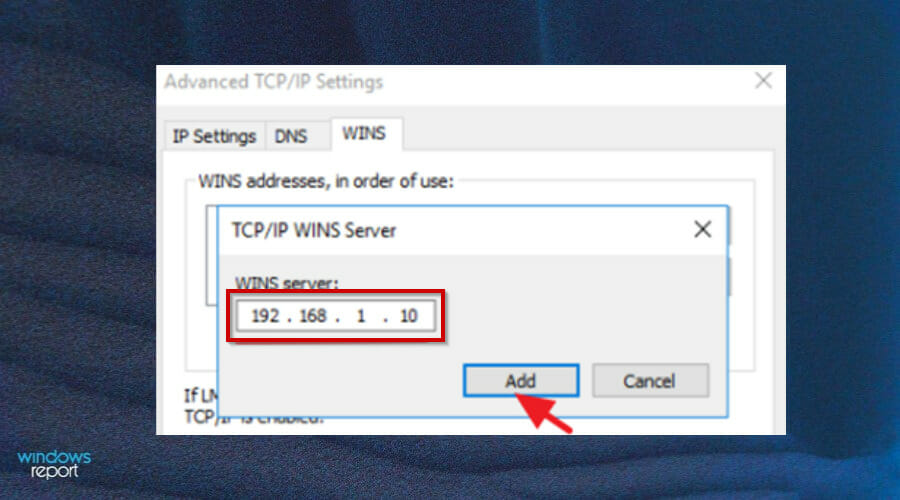
3. Change the WINS Server’s IP Address
- Press the Windows key and search for Device Manager to open.
- Right-click Network Adapter and click on the Properties button.
- Find the Internet Protocol Version 4 (TCP/IPv4) item on and select the Properties button.
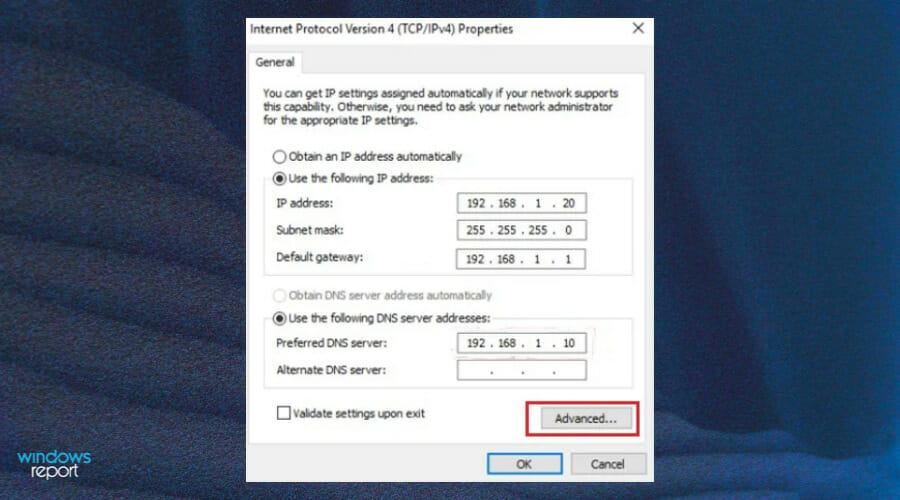
- On the General tab, change the Preferred DNS server address to match the Primary Domain Controller’s IP Address.
- Click on the Advanced button.
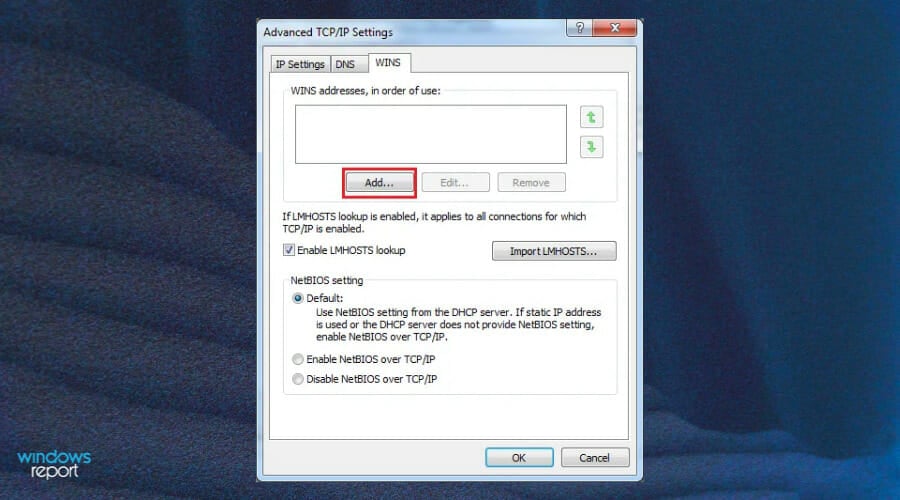
- Go to the WINS tab and click Add.
- Fill in the Preferred DNS server address and tap on Add.
- Save all the changes and try connecting again.
4. Tweak the Registry Editor
- Press the Windows + R keys simultaneously to open the Run window.
- Type regedit and hit Enter.
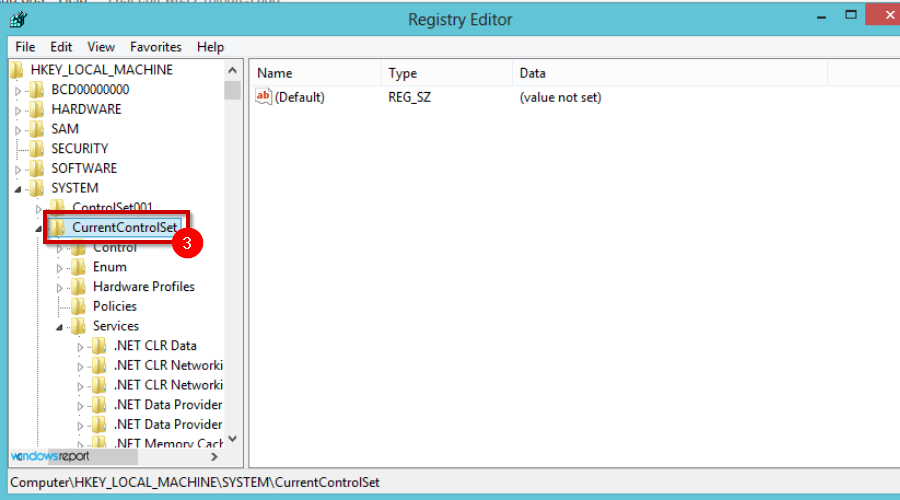
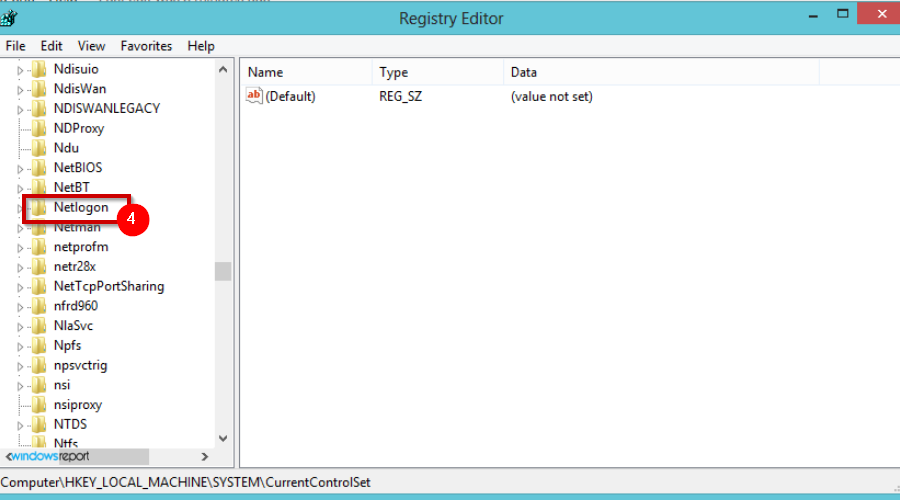
- Navigate to the following location:
HKEY_LOCAL_MACHINESystemCurrentControlSetNetlogonParameters - Locate SysvolReady and right-click then Modify.
- Under the Value data field put 1 and press OK.
- Save the changes and restart your device.


Could my domain be expired?
There are some things to check if you think your domain is expired. If you’re not sure whether or not it is, the most common reason is that it’s been inactive for a number of years.
If the domain has expired then the website associated with it will not be available and there may be a new owner. In this case, you can either attempt to contact them to see if they will renew it, or register a new one.
Provided your domain is still registered to you and you have made changes to your website but they have not yet gone live, then these changes may not have been lost.
However, if you have just changed your DNS settings through your registrar or web host, this won’t cause an expired status unless the change has been fully propagated through the internet’s DNS system.
All domains have an expiration date when they can be deleted from the name registry. The normal length of time for registration is two years, but there are tiers for different lengths of time that vary from registrar to registrar.
If the registration is not renewed within the grace period, it will go through the normal process of being released for new ones.
To avoid such inconveniences in the future, find out how you can get access to the best Windows hosting services that offer unlimited domains.
We hope that if you were experiencing this error, one of our solutions in this guide was able to solve your issue. Also, we have more on what to do if your domain is expired so feel free to check out our linked article in that regard.
Should you encounter any other domain-related errors, do not hesitate to visit our guide on how to fix them easily.
If you have any queries, suggestions, or comments, we’d love to hear from you. Leave us a comment down below.
Still having issues? Fix them with this tool:
SPONSORED
If the advices above haven’t solved your issue, your PC may experience deeper Windows problems. We recommend downloading this PC Repair tool (rated Great on TrustPilot.com) to easily address them. After installation, simply click the Start Scan button and then press on Repair All.
![]()
Newsletter
by Loredana Harsana
Loredana is a passionate writer with a keen interest in PC software and technology. She started off writing about mobile phones back when Samsung Galaxy S II was… read more
Published on January 28, 2022
- Domain error messages are a frequent source of frustration. If the specified domain either does not exist or could not be contacted, this indicates a configuration problem.
- Troubleshooting such an error only takes a few minutes and can save a lot of time if you don’t have to reinstall Windows.
- DNS is a very useful and important protocol. If it is corrupted, you may experience problems accessing your domain.
XINSTALL BY CLICKING THE DOWNLOAD FILE
- Download Restoro PC Repair Tool that comes with Patented Technologies (patent available here).
- Click Start Scan to find Windows 11 issues that could be causing PC problems.
- Click Repair All to fix issues affecting your computer’s security and performance
- Restoro has been downloaded by 0 readers this month.
There are a lot of reasons why your computer might be unable to connect to the domain. When you try to connect to the server, you may come across this error: The specified domain either does not exist or could not be contacted.
When you encounter it, this means that the specific domain that you are trying to access is not responding to the request. This may be because it does not exist or because there is a problem with the DNS servers.
It is responsible for mapping domain names to their IP address. When you type www.google.com in your browser, it uses DNS to find out the actual IP address of google servers and connects to it.
If you have a domain name that isn’t resolving, there are a few things to check. The most common issue is that you have typed the URL incorrectly.
Can an invalid URL cause The specified domain either does not exist or could not be contacted error?
Having the right URL is essential in order for the website to load properly. If you are using a bookmark or typing it in manually, make sure you’ve copied and pasted it correctly without any typos.
First of all, if you’re using your web browser’s address bar, then you need to make sure that the website address is entered correctly.
Sometimes, it may become broken or contain an invalid syntax, and therefore cause an error when accessing the site.
If possible, try correcting the URL so that it is spelled correctly and has no missing punctuation marks or any other characters which might make it invalid.
Why does The specified domain either does not exist or could not be contacted error occur?
Although DNS addresses are a common cause of this error, there are many other possible causes. Many people experience the error and the instinct is to run through a series of troubleshooting steps.
Unfortunately, most of these are futile and can end up wasting an hour or two before you realize that the problem is something else entirely.
Some PC issues are hard to tackle, especially when it comes to corrupted repositories or missing Windows files. If you are having troubles fixing an error, your system may be partially broken.
We recommend installing Restoro, a tool that will scan your machine and identify what the fault is.
Click here to download and start repairing.
Some of the common reasons the error occurs include:
- The DNS you are currently using is not functioning properly and it might be a sign that it is getting corrupted. If your computer is not working as you expect it to, or if you have some problems with your connection, then don’t hesitate and try to fix the issue by changing your current server.
- IPv6 protocol may have failed for your network so you may want to disable it. The problem that you might be facing is that your router does not support it.
- You may have misconfigured network settings. Check your network settings to make sure that nothing is wrong with them. If there is, fix it. Make sure that the computer or router you’re trying to access the files from has the correct IP address, and that they match what’s in your PC’s network settings.
- Misconfigured registry keys could also be the cause of the error. Sometimes, if one of these keys gets corrupted and the system fails to fix it automatically, then manual editing of the system files might be required.
What can I do to fix The specified domain either does not exist or could not be contacted error?
1. Use a different DNS address
- Press the Windows key, type cmd, and click Open.
- Enter the following command prompt and take note of the Default Gateway and DNS addresses:
ipconfig /all
- Next, press the Windows key and search for Device Manager to open.
- Right-click the Network Adapter and click on the Properties button.
- Find the Internet Protocol Version 4 (TCP/IPv4) item and click on the Properties button.
- On the General tab, change the Preferred DNS server address to match the Primary Domain Controller’s IP Address and press OK.
2. Disable IPv6 and run several useful commands
- Press the Windows key, search for Device Manager, and click on it to open.
- Once the Device Manager window opens, right-click on Network adapter to select Properties.
- Locate Internet Protocol Version 6, disable the checkbox, and click OK.
- Restart your device for the changes to take effect.
- Hit the Windows key and type cmd in the search bar.
- Run the following commands by pressing Enter after each one:
ipconfig/flushdnsipconfig/releaseipconfig/release6ipconfig/renew
- Try connecting to the domain again.
3. Change the WINS Server’s IP Address
- Press the Windows key and search for Device Manager to open.
- Right-click Network Adapter and click on the Properties button.
- Find the Internet Protocol Version 4 (TCP/IPv4) item on and select the Properties button.
- On the General tab, change the Preferred DNS server address to match the Primary Domain Controller’s IP Address.
- Click on the Advanced button.
- Go to the WINS tab and click Add.
- Fill in the Preferred DNS server address and tap on Add.
- Save all the changes and try connecting again.
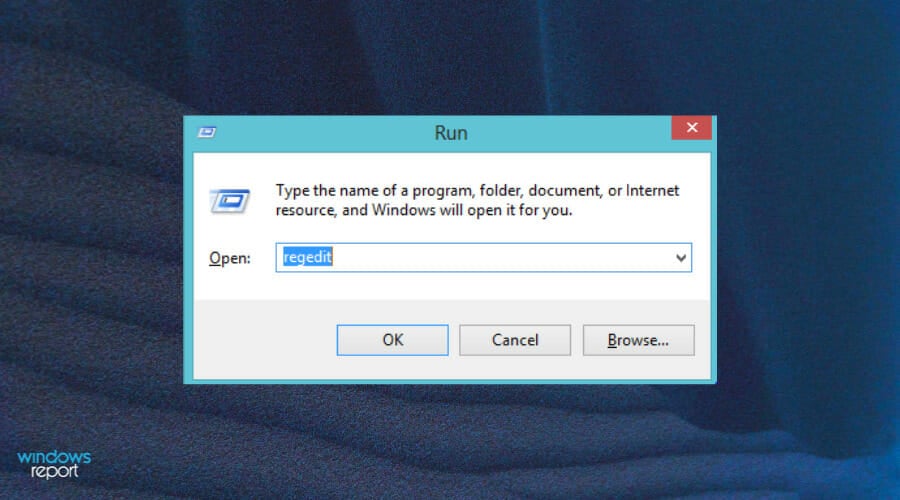
4. Tweak the Registry Editor
- Press the Windows + R keys simultaneously to open the Run window.
- Type regedit and hit Enter.
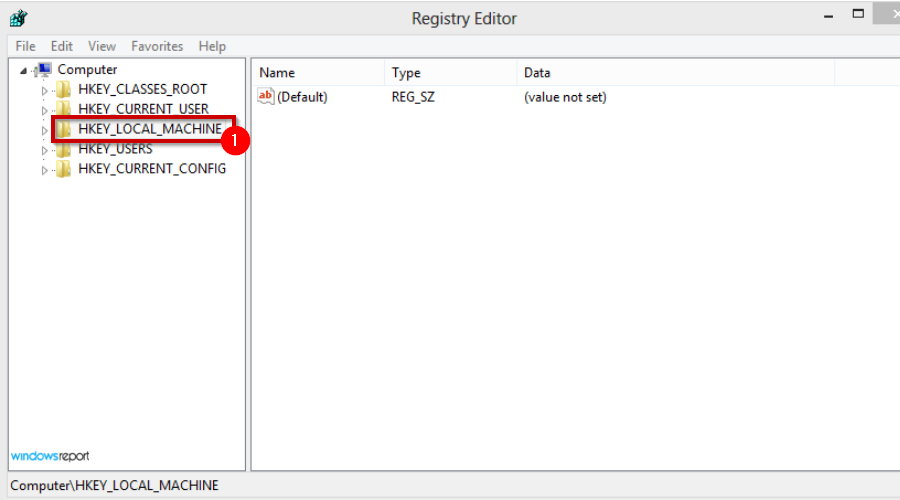
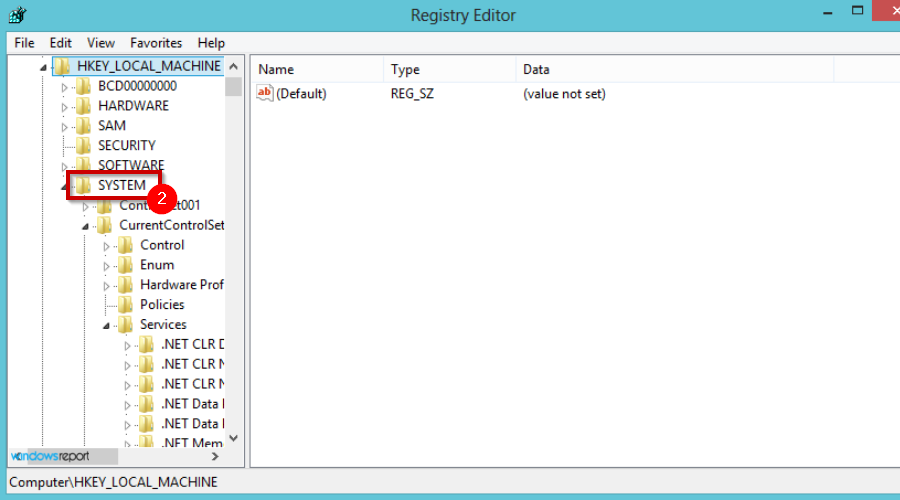
- Navigate to the following location:
HKEY_LOCAL_MACHINESystemCurrentControlSetNetlogonParameters - Locate SysvolReady and right-click then Modify.
- Under the Value data field put 1 and press OK.
- Save the changes and restart your device.
Could my domain be expired?
There are some things to check if you think your domain is expired. If you’re not sure whether or not it is, the most common reason is that it’s been inactive for a number of years.
If the domain has expired then the website associated with it will not be available and there may be a new owner. In this case, you can either attempt to contact them to see if they will renew it, or register a new one.
Provided your domain is still registered to you and you have made changes to your website but they have not yet gone live, then these changes may not have been lost.
However, if you have just changed your DNS settings through your registrar or web host, this won’t cause an expired status unless the change has been fully propagated through the internet’s DNS system.
All domains have an expiration date when they can be deleted from the name registry. The normal length of time for registration is two years, but there are tiers for different lengths of time that vary from registrar to registrar.
If the registration is not renewed within the grace period, it will go through the normal process of being released for new ones.
To avoid such inconveniences in the future, find out how you can get access to the best Windows hosting services that offer unlimited domains.
We hope that if you were experiencing this error, one of our solutions in this guide was able to solve your issue. Also, we have more on what to do if your domain is expired so feel free to check out our linked article in that regard.
Should you encounter any other domain-related errors, do not hesitate to visit our guide on how to fix them easily.
If you have any queries, suggestions, or comments, we’d love to hear from you. Leave us a comment down below.
Still having issues? Fix them with this tool:
SPONSORED
If the advices above haven’t solved your issue, your PC may experience deeper Windows problems. We recommend downloading this PC Repair tool (rated Great on TrustPilot.com) to easily address them. After installation, simply click the Start Scan button and then press on Repair All.
![]()
Newsletter
Robots.txt — это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие — нет.
Файл располагается в корневом каталоге сайта и доступен по адресу: domain.com/robots.txt.
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование Роботс может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит неверные данные, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Например:
User-Agent: * Disallow: /
Эта запись говорят о том, что поисковые системы не смогут увидеть и проиндексировать ваш сайт.
Пустой или недоступный файл Роботс поисковые роботы воспринимают как разрешение на сканирование всего сайта.
Ниже приведены ссылки на инструкции по использованию файла:
- от Яндекса;
- от Google.
Какие директивы используются в robots.txt
User-agent
User-agent — основная директива, которая указывает, для какого поискового робота прописаны нижеследующие указания по индексации, например:
Для всех роботов:
User-agent: *
Для поискового робота Яндекс:
User-agent: Yandex
Для поискового робота Google:
User-agent: Googlebot
Disallow и Allow
Директива Disallow закрывает раздел или страницу от индексации. Allow — принудительно открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге).
Операторы, которые используются с этими директивами: «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки.
* — спецсимвол звездочка обозначает любую последовательность символов. Например, все URL сайта, которые содержат значения, следующие после этого оператора, будут закрыты от индексации:
User-agent: *
Disallow: /cgi-bin* # блокирует доступ к страницам
# начинающимся с '/cgi-bin'
Disallow: /cgi-bin # то же самое
$ — знак доллара означает конец адреса и ограничивает действие знака «*», например:
User-agent: *
Disallow: /example$ # запрещает '/example',
# но не запрещает '/example.html'
Crawl-delay
Crawl-delay — директива, которая позволяет указать минимальный промежуток времени между окончанием загрузки одной страницы и началом загрузки следующей. Использовать ее следует в случаях, если сервер сильно загружен и не успевает обрабатывать запросы поискового робота.
User-agent: * Crawl-delay: 3.0 # задает тайм-аут в 3 секунды
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере. Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Clean-param
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param.
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param, не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Пример директивы Clean-param:
Clean-param: s /forum/showthread.php
Данная директива означает, что параметр «s» будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php.
Подробнее прочитать о директиве Clean-param можно в указаниях от Яндекс, ссылка на которые расположена выше.
Sitemap
Sitemap — это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо проверить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
Следует указать полный путь к странице, в которой содержится файл sitemap.
Пример использования:
Sitemap: https://www.site.ru/sitemap.xml
Пример правильно составленного файла robots.txt:
User-agent: * # нижеследующие правила задаются для всех поисковых роботов Allow: / # сайт открыт для индексации Sitemap: https://www.site.ru/sitemap.xml # карта сайта для поисковых систем
Как найти ошибки в robots.txt с помощью Labrika?
Для проверки файла robots используйте Labrika. Она позволяет увидеть 26 видов ошибок в структуре файла – это больше, чем определяет сервис Яндекса. Отчет «Ошибки robots.txt » находится в разделе «Технический аудит» левого бокового меню. В отчете приводится содержимое строк файла. При наличии в какой-либо директиве проблемы Labrika дает её описание.
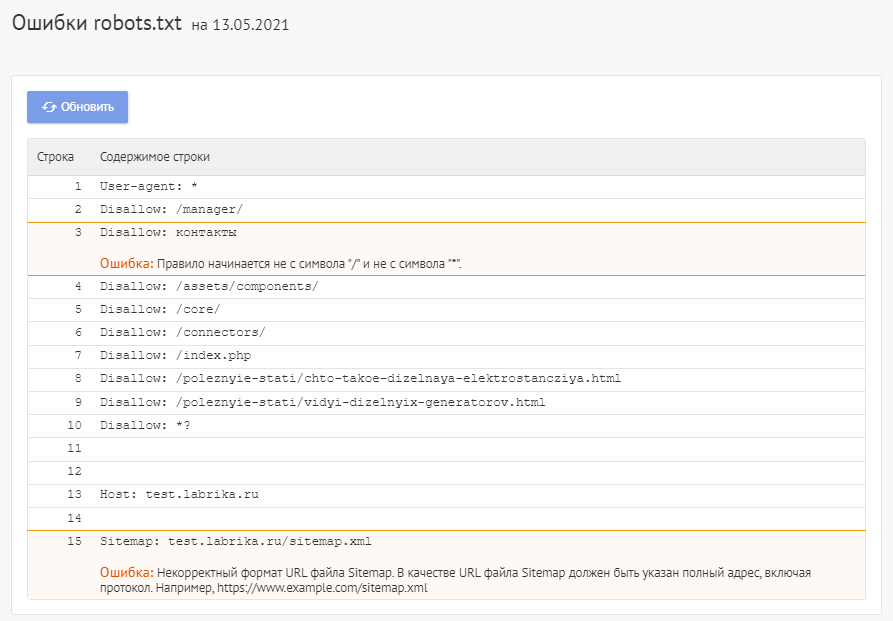
Ошибки robots.txt, которые определяет Labrika:
Сервис находит следующие:
Директива должна отделятся от правила символом «:».
Каждая действительная строка в файле Роботс должна состоять из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Для добавления комментария применяется символ решётки «#», который ставится перед его началом. Весь текст после символа «#» и до конца строки робот поисковой системы будет игнорировать.
Стандартный формат:
<field>:<value><#optional-comment>
Пример:
User-agent Googlebot
Пропущен символ “:”.
Правильный вариант:
User-agent: Googlebot
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent, поскольку она указывает, для какого поискового робота предназначены инструкции.
Пример:
User-agent:
Не указан пользовательский агент.
Правильный вариант:
User-agent: название бота
Например:
User-agent: Googlebot
Директивы Allow или Disallow задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: /, то есть «не запрещать ничего».
Пример ошибки в директиве Sitemap:
Sitemap:
Не указан путь к карте сайта.
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent. Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Пример:
Disallow: /category User-agent: Googlebot
Правильный вариант:
User-agent: Googlebot Disallow: /category
Найдено несколько правил вида «User-agent: *»
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Пример:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
Правильный вариант:
User-agent: * Disallow: /category Disallow: /*.pdf.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования Роботс от Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущен ошибочный синтаксис, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Пример:
Disalow: /catalog
Директивы «Disalow» не существует, допущена опечатка в написании слова.
Правильный вариант:
Disallow: /catalog
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt, если его размер не превышает 500 КБ. Допустимое количество правил в файле — 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Disallow: /*.pdf
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к коду UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt, все правила должны быть написаны согласно стандарту исключений для роботов (REP).
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt. Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Пример:
User-agent: Yandex Sitemap: сайт.рф/sitemap.xml
Правильный вариант:
User-agent: Yandex Sitemap: https://xn--80aswg.xn--p1ai/sitemap.xml
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Например:
Disallow: /*.php$
Директива запрещает индексировать любые php файлы.
Если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак «$» можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Пример:
Allow: /file$html
Правильный вариант:
Allow: /file.html$
Правило начинается не с символа «/» и не с символа «*».
Правило может начинаться только с символов «/» и «*».
Если значение пути указывается относительно корневого каталога сайта, оно должно начинаться с символа слэш «/», обозначающего корневой каталог.
Пример:
Disallow: products
Правильным вариантом будет:
Disallow: /products
или
Disallow: *products
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
В качестве URL файла Sitemap должен быть указан полный адрес, который содержит обозначение протокола (http:// или https://), название домена (главная страница сайта), путь к файлу карты сайта, а также имя файла.
Пример:
Sitemap: /sitemap.xml
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
Директива Host могла содержать только протокол (необязательный) и домен сайта. Прописывался протокол https, если он использовался. Указывалась только одна директива Host. Если их было несколько, робот учитывал первую.
Пример:
User-agent: Yandex Host: http://www.example.com/catalog Host: https://example.com
Правильный вариант:
User-agent: Yandex Host: https://example.com
Некорректный формат директивы Crawl-delay
При указании в директиве Crawl-delay интервала между загрузками страниц можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды.
К ошибкам относят:
- несколько директив
Crawl-delay; - некорректный формат директивы
Crawl-delay.
Пример:
Crawl-delay: 0,5 second
Правильный вариант:
Crawl-delay: 0.5
Некорректный формат директивы Clean-param
Labrika определяет некорректный формат директивы Clean-param, например:
В именах GET-параметров встречается два или более знака амперсанд «&» подряд:
Clean-param: sort&&session /category
Правильный вариант:
Clean-param: sort&session /category
Правило должно соответствовать виду «p0[&p1&p2&..&pn] [path]». В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: «.», «-«, «/», «*», «_».
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark — маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
Стандартные редакторы, создавая файл, могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
Использование маркера последовательности байтов в файлах .html приводит к сбою настроек дизайна, смещению блоков, появлению нечитаемых наборов символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать — открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Название
В наименовании должен быть использован нижний регистр букв.
Как исправить ошибки в robots.txt?
Исправьте ошибки в директивах robots.txt, следуя рекомендациям Labrika. Наш сервис проверяет файл robots.txt согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
После исправления указанных в отчете Labrika ошибок нажмите кнопку «Обновить», чтобы получить свежие данные о наличии ошибок в файле robots.txt и убедиться в правильном написании директив.
Не забудьте добавить новую версию Роботс в Вебмастера.
О том, как написать правильный файл robots.txt и ответы на другие вопросы вы можете найти в отдельной статье на нашем сайте.