I’m new to python and I’m following a video tutorial.
So here’s the code snippet
from urllib.request import urlopen
with urlopen('http://sixty-north/c/t.txt') as story:
story_words = []
for line in story:
line_words = line.decode('utf-8').split()
for word in line_words:
story_words.append(word)
I’m able to access http://sixty-north.com/c/t.txt in my browser.
However when I type this into command prompt: python words.py I get this error:
C:New folder>python words.py
Traceback (most recent call last):
File "C:Python33liburllibrequest.py", line 1248, in do_open
h.request(req.get_method(), req.selector, req.data, headers)
File "C:Python33libhttpclient.py", line 1065, in request
self._send_request(method, url, body, headers)
File "C:Python33libhttpclient.py", line 1103, in _send_request
self.endheaders(body)
File "C:Python33libhttpclient.py", line 1061, in endheaders
self._send_output(message_body)
File "C:Python33libhttpclient.py", line 906, in _send_output
self.send(msg)
File "C:Python33libhttpclient.py", line 844, in send
self.connect()
File "C:Python33libhttpclient.py", line 822, in connect
self.timeout, self.source_address)
File "C:Python33libsocket.py", line 417, in create_connection
for res in getaddrinfo(host, port, 0, SOCK_STREAM):
socket.gaierror: [Errno 11001] getaddrinfo failed
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "words.py", line 2, in <module>
with urlopen('http://sixty-north/c/t.txt') as story:
File "C:Python33liburllibrequest.py", line 156, in urlopen
return opener.open(url, data, timeout)
File "C:Python33liburllibrequest.py", line 469, in open
response = self._open(req, data)
File "C:Python33liburllibrequest.py", line 487, in _open
'_open', req)
File "C:Python33liburllibrequest.py", line 447, in _call_chain
result = func(*args)
File "C:Python33liburllibrequest.py", line 1274, in http_open
return self.do_open(http.client.HTTPConnection, req)
File "C:Python33liburllibrequest.py", line 1251, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [Errno 11001] getaddrinfo failed>
I’m new to python and I’m following a video tutorial.
So here’s the code snippet
from urllib.request import urlopen
with urlopen('http://sixty-north/c/t.txt') as story:
story_words = []
for line in story:
line_words = line.decode('utf-8').split()
for word in line_words:
story_words.append(word)
I’m able to access http://sixty-north.com/c/t.txt in my browser.
However when I type this into command prompt: python words.py I get this error:
C:New folder>python words.py
Traceback (most recent call last):
File "C:Python33liburllibrequest.py", line 1248, in do_open
h.request(req.get_method(), req.selector, req.data, headers)
File "C:Python33libhttpclient.py", line 1065, in request
self._send_request(method, url, body, headers)
File "C:Python33libhttpclient.py", line 1103, in _send_request
self.endheaders(body)
File "C:Python33libhttpclient.py", line 1061, in endheaders
self._send_output(message_body)
File "C:Python33libhttpclient.py", line 906, in _send_output
self.send(msg)
File "C:Python33libhttpclient.py", line 844, in send
self.connect()
File "C:Python33libhttpclient.py", line 822, in connect
self.timeout, self.source_address)
File "C:Python33libsocket.py", line 417, in create_connection
for res in getaddrinfo(host, port, 0, SOCK_STREAM):
socket.gaierror: [Errno 11001] getaddrinfo failed
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "words.py", line 2, in <module>
with urlopen('http://sixty-north/c/t.txt') as story:
File "C:Python33liburllibrequest.py", line 156, in urlopen
return opener.open(url, data, timeout)
File "C:Python33liburllibrequest.py", line 469, in open
response = self._open(req, data)
File "C:Python33liburllibrequest.py", line 487, in _open
'_open', req)
File "C:Python33liburllibrequest.py", line 447, in _call_chain
result = func(*args)
File "C:Python33liburllibrequest.py", line 1274, in http_open
return self.do_open(http.client.HTTPConnection, req)
File "C:Python33liburllibrequest.py", line 1251, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [Errno 11001] getaddrinfo failed>
Содержание
- Urlerror urlopen error errno 11001 getaddrinfo failed
- Comments
- NRK [Errno 11001] getaddrinfo failed #16324
- Comments
- Please follow the guide below
- Make sure you are using the latest version: run youtube-dl —version and ensure your version is 2018.04.25. If it’s not, read this FAQ entry and update. Issues with outdated version will be rejected.
- Before submitting an issue make sure you have:
- What is the purpose of your issue?
- The following sections concretize particular purposed issues, you can erase any section (the contents between triple —) not applicable to your issue
- If the purpose of this issue is a bug report, site support request or you are not completely sure provide the full verbose output as follows:
- Description of your issue, suggested solution and other information
- ошибка urlopen [Errno 11001] getaddrinfo не удалось?
- 2 ответа
- socket.gaierror: [Errno 11001] getaddrinfo failed #331
- Comments
- Footer
- Русские Блоги
- [Python] Детальная работа библиотеки urllib, запросы, ошибка, модуль разбора
- urllib — это встроенная библиотека http-запросов в python. Основными встроенными модулями являются следующие модули:
- 1. urllib реализует запрос get или post
- 2. Метод urllib.requests.Request
- 3. Обработка исключений
- 4. Разобрать ссылку
Urlerror urlopen error errno 11001 getaddrinfo failed
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
I am running this code:
from googleplaces import GooglePlaces, types, lang
google_places = GooglePlaces(‘xxxxxx’)
query_result = google_places.nearby_search(
lat_lng=<‘lat’:-1.743103,’lng’:-79.534646>,
radius=600, sensor=True)](url)
I am getting this error:
File «C:UsersNA401134AppDataLocalContinuumanaconda3libsite-packagesgoogleplaces_init_.py», line 304, in nearby_search
GooglePlaces.NEARBY_SEARCH_API_URL, self._request_params)
File «C:UsersNA401134AppDataLocalContinuumanaconda3libsite-packagesgoogleplaces_init_.py», line 78, in _fetch_remote_json
request_url, response = _fetch_remote(service_url, params, use_http_post)
File «C:UsersNA401134AppDataLocalContinuumanaconda3libsite-packagesgoogleplaces_init_.py», line 71, in _fetch_remote
return (request_url, urllib.request.urlopen(request))
File «C:UsersNA401134AppDataLocalContinuumanaconda3liburllibrequest.py», line 223, in urlopen
return opener.open(url, data, timeout)
File «C:UsersNA401134AppDataLocalContinuumanaconda3liburllibrequest.py», line 526, in open
response = self._open(req, data)
File «C:UsersNA401134AppDataLocalContinuumanaconda3liburllibrequest.py», line 544, in _open
‘_open’, req)
File «C:UsersNA401134AppDataLocalContinuumanaconda3liburllibrequest.py», line 504, in _call_chain
result = func(*args)
File «C:UsersNA401134AppDataLocalContinuumanaconda3liburllibrequest.py», line 1361, in https_open
context=self._context, check_hostname=self._check_hostname)
File «C:UsersNA401134AppDataLocalContinuumanaconda3liburllibrequest.py», line 1320, in do_open
raise URLError(err)
The text was updated successfully, but these errors were encountered:
Источник
NRK [Errno 11001] getaddrinfo failed #16324
Please follow the guide below
- You will be asked some questions and requested to provide some information, please read them carefully and answer honestly
- Put an x into all the boxes [ ] relevant to your issue (like this: [x] )
- Use the Preview tab to see what your issue will actually look like
Make sure you are using the latest version: run youtube-dl —version and ensure your version is 2018.04.25. If it’s not, read this FAQ entry and update. Issues with outdated version will be rejected.
- I’ve verified and I assure that I’m running youtube-dl 2018.04.25
Before submitting an issue make sure you have:
- At least skimmed through the README, most notably the FAQ and BUGS sections
- Searched the bugtracker for similar issues including closed ones
- Checked that provided video/audio/playlist URLs (if any) are alive and playable in a browser
What is the purpose of your issue?
- Bug report (encountered problems with youtube-dl)
- Site support request (request for adding support for a new site)
- Feature request (request for a new functionality)
- Question
- Other
The following sections concretize particular purposed issues, you can erase any section (the contents between triple —) not applicable to your issue
If the purpose of this issue is a bug report, site support request or you are not completely sure provide the full verbose output as follows:
Description of your issue, suggested solution and other information
I’m getting [Errno 11001] getaddrinfo failed when i try to download from tv.nrk.no. I have also tried other url’s than the one provided in the log.
The text was updated successfully, but these errors were encountered:
Источник
ошибка urlopen [Errno 11001] getaddrinfo не удалось?
Всем привет. Я начинающий программист, владеющий языком Python , и мне нужна помощь.
Это мой код на Python, он выдает ошибку, помогите исправить
urllib.error.URLError: ошибка urlopen [Errno 11001] getaddrinfo не удалось
Python:
Это в командной строке: python, я получаю эту ошибку:
2 ответа
Я попытаюсь объяснить три основных способа разобраться в проблеме программирования:
(1) Используйте отладчик. Вы можете пройтись по своему коду и изучить переменные до того, как они будут использованы и до того, как они вызовут исключение. Python поставляется с pdb . В этой задаче вы должны выполнить код и распечатать href перед urlopen() .
(2) Утверждения. Используйте Python assert , чтобы утверждать предположения в вашем коде. Вы могли бы, например, assert not href.startswith(‘http’)
(3) Регистрация. Зарегистрируйте соответствующие переменные перед их использованием. Вот что я использовал:
Я добавил в ваш код следующее .
Отсюда вы можете увидеть свою проблему с getaddrinfo : ваша система пытается открыть URL-адрес на хосте с именем allrecipes.comhttp .
Это похоже на проблему, основанную на вашем предположении, что WEBSITE должен добавляться к каждому href , который вы извлекаете из html.
Вы можете обработать случай абсолютного и относительного href примерно так и функция для определения абсолютного URL-адреса:
Лучший способ сделать это — использовать синтаксический анализ как таковой:
Это вернет полный URL-адрес href, если он не является полным.
Источник
socket.gaierror: [Errno 11001] getaddrinfo failed #331
Getting the below error on numerous samples. add_vswitch_to_host.py and dc_create.py that I’ve tried. Others (vcenter_details.py for example) work fine. Tried to add ssl.SSLContext, but no good. Full error:
Traceback (most recent call last):
File «dc_create.py», line 39, in
sslContext= context)
File «c:python33libsite-packagespyVimconnect.py», line 817, in SmartConnect
sslContext)
File «c:python33libsite-packagespyVimconnect.py», line 702, in __FindSupportedVersion
sslContext)
File «c:python33libsite-packagespyVimconnect.py», line 622, in __GetServiceVersionDescription
path + «/vimServiceVersions.xml», sslContext)
File «c:python33libsite-packagespyVimconnect.py», line 588, in __GetElementTree
conn.request(«GET», path)
File «c:python33libhttpclient.py», line 1106, in request
self._send_request(method, url, body, headers)
File «c:python33libhttpclient.py», line 1151, in _send_request
self.endheaders(body)
File «c:python33libhttpclient.py», line 1102, in endheaders
self._send_output(message_body)
File «c:python33libhttpclient.py», line 934, in _send_output
self.send(msg)
File «c:python33libhttpclient.py», line 877, in send
self.connect()
File «c:python33libhttpclient.py», line 1252, in connect
super().connect()
File «c:python33libhttpclient.py», line 849, in connect
(self.host,self.port), self.timeout, self.source_address)
File «c:python33libsocket.py», line 693, in create_connection
for res in getaddrinfo(host, port, 0, SOCK_STREAM):
File «c:python33libsocket.py», line 732, in getaddrinfo
for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
socket.gaierror: [Errno 11001] getaddrinfo failed
The text was updated successfully, but these errors were encountered:
The only times I have got the error I mistyped the host. I have just tested add_vswitch_to_host.py and I didn’t have any problem to perform the connection. Are you sure that the host was reachable and that you didn’t mistype it ?
@blacksponge, I am having the same error. Can you please suggest me a correct host
@akhilesh-agrhari sorry but that was quite a while ago and I don’t have the possibilty of doing any kind of test now. I would say an ip or valid domain name.
I have the same error and i can assure you that my host name and port is correct. What can i do about this please?
Traceback (most recent call last):
File «D:/Propy/pythonProject_douyu/douyu.py», line 267, in
client = DouyuClient(‘openbarrage.douyutv.com’,8601,data_callback=data_callback)
File «D:/Propy/pythonProject_douyu/douyu.py», line 132, in init
self.connect(address)
File «C:UsersadainAppDataLocalProgramsPythonPython37libasyncore.py», line 333, in connect
err = self.socket.connect_ex(address)
socket.gaierror: [Errno 11001] getaddrinfo failed
Have anypeopel solve the problem?
I am encountering the same issue
Traceback (most recent call last):
File «/app/EmailSender/main.py», line 9, in
EmailSender(push_file_path=__path).send_message()
File «/app/EmailSender/EmailSender.py», line 25, in send_message
Email_Auth(push_mail=config, path_file=path_file).send_mail(file_names=files)
File «/app/EmailSender/EmailSender.py», line 79, in send_mail
self.generate_smtp(msg)
File «/app/EmailSender/EmailSender.py», line 103, in generate_smtp
smtp = smtplib.SMTP(self.server, self.port)
File «/usr/local/lib/python3.9/smtplib.py», line 253, in init
(code, msg) = self.connect(host, port)
File «/usr/local/lib/python3.9/smtplib.py», line 339, in connect
self.sock = self._get_socket(host, port, self.timeout)
File «/usr/local/lib/python3.9/smtplib.py», line 310, in _get_socket
return socket.create_connection((host, port), timeout,
File «/usr/local/lib/python3.9/socket.py», line 822, in create_connection
for res in getaddrinfo(host, port, 0, SOCK_STREAM):
File «/usr/local/lib/python3.9/socket.py», line 953, in getaddrinfo
for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
socket.gaierror: [Errno -2] Name or service not known
Traceback (most recent call last):
File «C:UserslenovoDesktopKeyloggerkeylogger.py», line 124, in
keylogger.run()
File «C:UserslenovoDesktopKeyloggerkeylogger.py», line 94, in run
self.report()
File «C:UserslenovoDesktopKeyloggerkeylogger.py», line 57, in report
self.send_mail(self.email, self.password, «nn» + self.log)
File «C:UserslenovoDesktopKeyloggerkeylogger.py», line 50, in send_mail
server = smtplib.SMTP(‘smtp.gmail.com’, 587, message.encode(«utf8»))
File «C:UserslenovoAppDataLocalProgramsPythonPython39libsmtplib.py», line 255, in init
(code, msg) = self.connect(host, port)
File «C:UserslenovoAppDataLocalProgramsPythonPython39libsmtplib.py», line 341, in connect
self.sock = self._get_socket(host, port, self.timeout)
File «C:UserslenovoAppDataLocalProgramsPythonPython39libsmtplib.py», line 312, in _get_socket
return socket.create_connection((host, port), timeout,
File «C:UserslenovoAppDataLocalProgramsPythonPython39libsocket.py», line 822, in create_connection
for res in getaddrinfo(host, port, 0, SOCK_STREAM):
File «C:UserslenovoAppDataLocalProgramsPythonPython39libsocket.py», line 953, in getaddrinfo
for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
socket.gaierror: [Errno 11001] getaddrinfo failed
Traceback (most recent call last):
File «C:UsersEmiHPPycharmProjectssftp_downloadmain.py», line 6, in
transport=paramiko.Transport((host,port))
File «C:UsersEmiHPAppDataLocalProgramsPythonPython39libsite-packagesparamikotransport.py», line 426, in init
addrinfos = socket.getaddrinfo(
File «C:UsersEmiHPAppDataLocalProgramsPythonPython39libsocket.py», line 954, in getaddrinfo
for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
socket.gaierror: [Errno 11001] getaddrinfo failed
make sure that the hostname is just hostname and not including any path in the hostname variable, that fixed my problem.
© 2023 GitHub, Inc.
You can’t perform that action at this time.
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session.
Источник
Русские Блоги
[Python] Детальная работа библиотеки urllib, запросы, ошибка, модуль разбора
urllib — это встроенная библиотека http-запросов в python. Основными встроенными модулями являются следующие модули:
- urllib.request: модуль запроса
- urllib.error: модуль обработки исключений
- urllib.parse: модуль парсинга URL
- urllib.robotparer: модуль синтаксического анализа robot.txt
1. urllib реализует запрос get или post
urllib.request.urlopen(url,data = None,[timeout,],cafile = None,capath = None,cadefualt = False,context = None)
- urllib.requests.urlopen — получите следующие примеры:
- Используйте post запрос для передачи данных, urllib.requests.urlopen —post выглядит следующим образом:
Следовательно, для способа получения и публикации запросов необходимо только передать данные для различения.
2. Метод urllib.requests.Request
Предыдущий текст использует URLopen для непосредственного запроса веб-страниц, но добавлять информацию, такую как заголовки, неудобно, поэтому для построения требуется Request.
- url: обязательный параметр, входящая ссылка, которую нужно запросить
- данные: если вы хотите передать, это должен быть тип байтов (поток байтов). Если это словарь параметров, urlencode, который необходимо проанализировать, кодируется в виде строки
- headers: заголовки запроса; могут быть добавлены непосредственно к экземпляру Request или add_headers; наиболее распространенный способ добавления заголовков запроса — замаскировать браузер, изменив User_Agent, python по умолчанию — python-urllib, мы можем изменить его Сделайте вид, что браузер, такой как Google browser, установлен на «User-Agent», «Mozilla / 5.0 (Windows NT 10.0; WOW64) AppleWebKit / 537.36 (KHTML, как Gecko) Chrome / 63.0.3239.132 Safari / 537.36»
- origin_req_host: имя хоста или IP-адрес запрашивающей стороны
- unverifiable: указывает, что запрос не может быть проверен, по умолчанию используется значение False, что означает, что разрешения на запрос недостаточно.
- method: метод, используемый для указания запроса, такой как GET, POST, PUT
Объект запроса, созданный с помощью запроса, передается в urllib.request.urlopen () для открытия следующим образом:
2.1, Обработчик: более сложный метод
Первый — это класс BaseHandler для urllib.request, который является родительским классом для всех других обработчиков, предоставляя самые основные методы, такие как default_open (), protocol_request () и т. Д.
Во-вторых, различные часто используемые подклассы наследуют этот класс BaseHandler:
- HTTPHandler () открывает URL через HTTP
- CacheFTPHandler () FTP-обработчик с постоянным FTP-соединением
- FileHandler () Открыть локальный файл
- FTPHandler () Открыть URL через FTP
- HTTPBasicAuthHandler () обрабатывает аутентификацию через HTTP
- HTTPCookieProcessor () обрабатывает файлы cookie HTTP
- HTTPDefaultErrorHandler () обрабатывает ошибки HTTP, вызывая исключение HTTPError
- HTTPDigestAuthHandler () обработка дайджест-аутентификации HTTP
- HTTPRedirectHandler () обрабатывает перенаправления HTTP
- HTTPSHandler () перенаправляет через безопасный HTTP
- ProxyHandler () перенаправляет запрос через прокси
- ProxyBasicAuthHandler базовая проверка подлинности прокси
- ProxyDigestAuthHandler дайджест аутентификации прокси
- Обработчик UnknownHandler для всех неизвестных URL
Другой практический класс — OpenerDirector, который можно назвать Opener. Мы можем использовать обработчик для сборки Opener.
Здесь возникает ошибка при использовании прокси: .
Общий агент бесполезен. Исследование агента все еще нуждается в углубленном изучении. В настоящее время более удобным способом борьбы с ним является удаление агента.
Сначала объявите объект Cookiejar, затем используйте HTTPCookieProcessor для построения обработчика и, наконец, соберите Opener с помощью метода build_opener и выполните функцию open ().
Если вам нужно сохранить куки в локальном файле, вам нужно заменить CookieJar на MozillaCookieJar или LWPCookieJar, которые лишь немного отличаются по типу сохраняемого файла.
Как читать, вызовите метод load (), чтобы прочитать локальный файл cookie.Обратите внимание, что использованный ранее метод MozillaCookieJar сохраняется. Позже вам необходимо объявить тот же метод MozillaCookieJar для загрузки. Затем завершите запрос веб-страницы, вызвав метод обработчика и метод открывания.
3. Обработка исключений
Модуль ошибок urllib определяет исключение, сгенерированное запросом urllib.request. В случае сбоя запроса urllib.request сгенерирует исключение в модуле ошибок.
- URLError
Класс URLError происходит из модуля ошибок urllib, он наследует модуль OSError и является базовым классом модуля исключений. Он имеет атрибут reason, который возвращает причину ошибки.
- HTTPError
Это подкласс URLError, специально используемый для обработки ошибок HTTP-запроса, и имеет три атрибута:
1. code: вернуть код состояния HTTP
2. причина: ненормальная причина
3. заголовки: заголовки запроса
URLError и HTTPError объединяются для обработки исключений.Во-первых, подкласс HTTPERror используется для захвата его кода состояния ошибки, причины, заголовков и другой информации. Если это не HTTPError, перехватите URLError, выведите причину ошибки и, наконец, обработайте обычную логику.
4. Разобрать ссылку
В библиотеке urllib есть также модуль разбора, который определяет стандартный интерфейс для обработки URL-адресов, таких как извлечение, объединение и преобразование ссылок различных частей URL-адреса.
- urlparse: реализует идентификацию и сегментацию URL
Есть определенные разделители во время синтаксического анализа,? / Находится перед схемой, которая представляет протокол, первый / символ находится перед netloc, который является доменным именем;
сопровождается путем, который является путем доступа; точка с запятой; впереди находится params, который представляет параметр; вопросительный знак? После запроса условия запроса, как правило, в виде URL-адреса типа GET, # за — это точка привязки, используемая для непосредственного определения позиции раскрывающегося списка внутри страницы.
Таким образом, можно нарисовать стандартный формат ссылки:
Общий стандартный URL-адрес будет соответствовать вышеуказанным правилам, используя метод urlparse для его разделения. В дополнение к этому наиболее простому способу синтаксического анализа, он использует API:
Функция синтеза URL должна передавать 6 параметров, которые могут быть в форме кортежа или списка параметров:
Этот метод очень похож на urlparse, возвращается только 5 значений, он больше не анализирует параметры отдельно и объединяет параметры в пути:
Подобно urlunparse, входящий параметр также является итерируемым объектом, таким как список или кортеж, единственное отличие — длина, которая должна быть передана в 5 параметрах.
- urljoin
Для методов urlunsplit и urlunparse вы можете завершить слияние ссылок, но длина должна быть определенной, и каждая часть ссылки должна быть четко отделена. С помощью urljoin вы можете предоставить base_url в качестве первого параметра и новую ссылку в качестве второго параметра.Этот метод проанализирует схему base_url, netloc и путь, чтобы дополнить недостающую часть новой ссылки.
- urlencode
Очень полезно для построения параметров запроса GET, сначала объявите словарь для представления параметров, а затем вызовите метод urlencode, чтобы сериализовать его в параметры запроса GET.
Десериализовать, разобрать параметры запроса GET
Конвертировать параметры в список кортежей
Этот метод преобразует содержимое в формат кодировки URL.Этот метод может преобразовать строку китайских символов в кодировку URL
- unquote
Используйте unquote для восстановления
Источник
Checklist
- I’m reporting a broken site support issue
- I’ve verified that I’m running youtube-dl version 2020.06.06
- I’ve checked that all provided URLs are alive and playable in a browser
- I’ve checked that all URLs and arguments with special characters are properly quoted or escaped
- I’ve searched the bugtracker for similar bug reports including closed ones NRK [Errno 11001] getaddrinfo failed #16324
- I’ve read bugs section in FAQ
Verbose log
This is what i get:
C:>youtube-dl -v "https://www.youtube.com/watch?v=9A-HLSvtBWc"
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: ['-v', 'https://www.youtube.com/watch?v=9A-HLSvtBWc']
[debug] Encodings: locale cp1252, fs mbcs, out cp850, pref cp1252
[debug] youtube-dl version 2020.06.06
[debug] Python version 3.4.4 (CPython) - Windows-10-10.0.14393
[debug] exe versions: ffmpeg git-2020-06-03-b6d7c4c, ffprobe git-2020-06-03-b6d7c4c
[debug] Proxy map: {}
[youtube] 9A-HLSvtBWc: Downloading webpage
ERROR: Unable to download webpage: <urlopen error [Errno 11001] getaddrinfo failed> (caused by URLError(gaierror(11001, 'getaddrinfo failed'),))
File "C:UsersdstAppDataRoamingBuild archiveyoutube-dlytdl-orgtmpd0boo4lkbuildyoutube_dlextractorcommon.py", line 627, in _request_webpage
File "C:UsersdstAppDataRoamingBuild archiveyoutube-dlytdl-orgtmpd0boo4lkbuildyoutube_dlYoutubeDL.py", line 2238, in urlopen
File "C:PythonPython34liburllibrequest.py", line 464, in open
File "C:PythonPython34liburllibrequest.py", line 482, in _open
File "C:PythonPython34liburllibrequest.py", line 442, in _call_chain
File "C:UsersdstAppDataRoamingBuild archiveyoutube-dlytdl-orgtmpd0boo4lkbuildyoutube_dlutils.py", line 2736, in https_open
File "C:PythonPython34liburllibrequest.py", line 1185, in do_open
Description
I wanted to download a video from youtube. Due to an error message u updated to version 2020-06-06 to download it. I tried
- youtube-dl -v «https://www.youtube.com/watch?v=9A-HLSvtBWc»
But i stil get the error: Unable to download webpage: <urlopen error [Errno 11001] getaddrinfo failed> (caused by URLError(gaierror(11001, 'getaddrinfo failed')
Urllib package is the URL handling module for python. It is used to fetch URLs (Uniform Resource Locators). It uses the urlopen function and is able to fetch URLs using a variety of different protocols.
Urllib is a package that collects several modules for working with URLs, such as:
- urllib.request for opening and reading.
- urllib.parse for parsing URLs
- urllib.error for the exceptions raised
- urllib.robotparser for parsing robot.txt files
If urllib is not present in your environment, execute the below code to install it.
pip install urllib
Let’s see these in details.
urllib.request
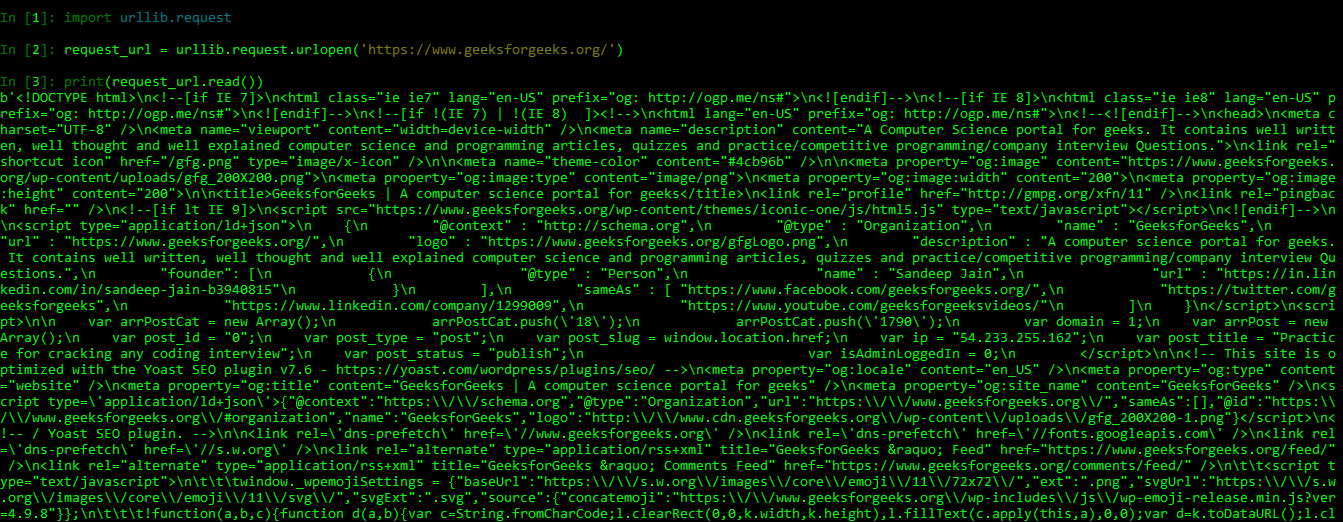
This module helps to define functions and classes to open URLs (mostly HTTP). One of the most simple ways to open such URLs is :
urllib.request.urlopen(url)
We can see this in an example:
The source code of the URL i.e. Geeksforgeeks.
urllib.parse
This module helps to define functions to manipulate URLs and their components parts, to build or break them. It usually focuses on splitting a URL into small components; or joining different URL components into URL strings.
We can see this from the below code:
print(parse_url)
print("n")
unparse_url = urlunparse(parse_url)
print(unparse_url)
ParseResult(scheme='https', netloc='www.geeksforgeeks.org', path='/python-langtons-ant/', params='', query='', fragment='') https://www.geeksforgeeks.org/python-langtons-ant/
Note:- The different components of a URL are separated and joined again. Try using some other URL for better understanding.
Different other functions of urllib.parse are :
| Function | Use |
|---|---|
| urllib.parse.urlparse | Separates different components of URL |
| urllib.parse.urlunparse | Join different components of URL |
| urllib.parse.urlsplit | It is similar to urlparse() but doesn’t split the params |
| urllib.parse.urlunsplit | Combines the tuple element returned by urlsplit() to form URL |
| urllib.parse.urldeflag | If URL contains fragment, then it returns a URL removing the fragment. |
urllib.error
This module defines the classes for exception raised by urllib.request. Whenever there is an error in fetching a URL, this module helps in raising exceptions. The following are the exceptions raised :
- URLError – It is raised for the errors in URLs, or errors while fetching the URL due to connectivity, and has a ‘reason’ property that tells a user the reason of error.
- HTTPError – It is raised for the exotic HTTP errors, such as the authentication request errors. It is a subclass or URLError. Typical errors include ‘404’ (page not found), ‘403’ (request forbidden),
and ‘401’ (authentication required).
We can see this in following examples :
import urllib.request
import urllib.parse
try:
print(x.read())
except Exception as e :
print(str(e))
URL Error: urlopen error [Errno 11001] getaddrinfo failed
import urllib.request
import urllib.parse
try:
print(x.read())
except Exception as e :
print(str(e))
HTTP Error 403: Forbidden
urllib.robotparser
This module contains a single class, RobotFileParser. This class answers question about whether or not a particular user can fetch a URL that published robot.txt files. Robots.txt is a text file webmasters create to instruct web robots how to crawl pages on their website. The robot.txt file tells the web scraper about what parts of the server should not be accessed.
For example :
None None True False
thanks in advance for any help:
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: [‘—verbose’, ‘https://open.spotify.com/episode/1u5zE2Up9B3S8XXz9F7qQC’]
[debug] youtube-dl version 2021.06.06
[debug] Python version 3.4.4 (CPython)
[debug] exe versions: none
[debug] Proxy map: {}
[debug] Default format spec: best/bestvideo+bestaudio
ERROR: unable to download video data: <urlopen error [Errno 11001] getaddrinfo failed>
Traceback (most recent call last):
File «C:PythonPython34liburllibrequest.py», line 1183, in do_open
File «C:PythonPython34libhttpclient.py», line 1137, in request
File «C:PythonPython34libhttpclient.py», line 1182, in _send_request
File «C:PythonPython34libhttpclient.py», line 1133, in endheaders
File «C:PythonPython34libhttpclient.py», line 963, in _send_output
File «C:PythonPython34libhttpclient.py», line 898, in send
File «C:PythonPython34libhttpclient.py», line 1279, in connect
File «C:PythonPython34libhttpclient.py», line 871, in connect
File «C:PythonPython34libsocket.py», line 498, in create_connection
File «C:PythonPython34libsocket.py», line 537, in getaddrinfo socket.gaierror: [Errno 11001] getaddrinfo failed
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «C:UsersdstAppDataRoamingBuild archiveyoutube-dlytdl-orgtmpkqxnwl31buildyoutube_dlYoutubeDL.py», line 1976, in process_info
File «C:UsersdstAppDataRoamingBuild archiveyoutube-dlytdl-orgtmpkqxnwl31buildyoutube_dlYoutubeDL.py», line 1915, in dl
File «C:UsersdstAppDataRoamingBuild archiveyoutube-dlytdl-orgtmpkqxnwl31buildyoutube_dldownloadercommon.py», line 366, in download
File «C:UsersdstAppDataRoamingBuild archiveyoutube-dlytdl-orgtmpkqxnwl31buildyoutube_dldownloaderhttp.py», line 351, in real_download
File «C:UsersdstAppDataRoamingBuild archiveyoutube-dlytdl-orgtmpkqxnwl31buildyoutube_dldownloaderhttp.py», line 116, in establish_connection
File «C:UsersdstAppDataRoamingBuild archiveyoutube-dlytdl-orgtmpkqxnwl31buildyoutube_dldownloaderhttp.py», line 110, in establish_connection
File «C:UsersdstAppDataRoamingBuild archiveyoutube-dlytdl-orgtmpkqxnwl31buildyoutube_dlYoutubeDL.py», line 2288, in urlopen
File «C:PythonPython34liburllibrequest.py», line 464, in open
File «C:PythonPython34liburllibrequest.py», line 482, in _open
File «C:PythonPython34liburllibrequest.py», line 442, in _call_chain
File «C:UsersdstAppDataRoamingBuild archiveyoutube-dlytdl-orgtmpkqxnwl31buildyoutube_dlutils.py», line 2737, in https_open
File «C:PythonPython34liburllibrequest.py», line 1185, in do_open urllib.error.URLError: <urlopen error [Errno 11001] getaddrinfo failed>
Shaozhong SHI
unread,
Feb 12, 2022, 11:17:07 PM2/12/22
to
The following is used in a loop to get response code for each url.
print (urllib.request.urlopen(url).getcode())
However, error message says: URLError: <urlopen error [Errno 11001]
getaddrinfo failed>
Python 3.6.5 is being used to test whether url is live or not.
Can anyone shed light on this?
Regards,
David
Peter J. Holzer
unread,
Feb 12, 2022, 11:26:53 PM2/12/22
to
getaddrinfo is the function that resolves a domain name into an IP
address. If that fails, either the domain name doesn’t exist or you have
a problem with your DNS setup.
Things to test:
* Can you resolve the domain name to an address (try «nslookup» or
«host» or «dig» depending on your OS)?
* Can you access the whole URL with a different tool like «wget» or
«curl»?
hp
—
_ | Peter J. Holzer | Story must make more sense than reality.
|_|_) | |
| | | h…@hjp.at | — Charles Stross, «Creative writing
__/ | http://www.hjp.at/ | challenge!»
Chris Angelico
unread,
Feb 12, 2022, 11:27:09 PM2/12/22
to
On Sun, 13 Feb 2022 at 07:17, Shaozhong SHI <shisha…@gmail.com> wrote:
>
> The following is used in a loop to get response code for each url.
>
> print (urllib.request.urlopen(url).getcode())
>
> However, error message says: URLError: <urlopen error [Errno 11001]
> getaddrinfo failed>
>
> Python 3.6.5 is being used to test whether url is live or not.
>
> Can anyone shed light on this?
>
What that’s saying is that it couldn’t look up the domain name to get
the corresponding address. Most likely, that means you either don’t
have DNS available, or the DNS server said that it couldn’t find that
server. (Whether that’s true or not. It’s always possible for the DNS
server to be wrong.) So, if you can fairly safely assume that you have
a fully-functioning internet connection (for instance, if other URLs
can be fetched successfully), the most reasonable interpretation of
this is that the URL is, in some way, broken.
I suspect that errno 11001 is a Winsock error, in which case it would
mean «Host not found». On my Linux system, I get a chained exception
that says «Name or service not found». Most likely, you can find this
information further up in the traceback.
ChrisA
Gisle Vanem
unread,
Feb 13, 2022, 10:47:03 AM2/13/22
to
Shaozhong SHI wrote:
> The following is used in a loop to get response code for each url.
>
> print (urllib.request.urlopen(url).getcode())
>
> However, error message says: URLError: <urlopen error [Errno 11001]
11001 == WSAHOST_NOT_FOUND.
Look in any ‘winsock.h’ header:
#define WSAHOST_NOT_FOUND (WSABASEERR+1001)
—
—gv
Hi @v-yingjl
No, unfortunately I haven’t found a solution.
I decided to open the file from an S3 in AWS (Amazon) as @lbendlin suggested. This work great in the Desktop version, but as soon as I publish the report to the Service, it breaks.
Your solution didn’t work for me because I still need to have interactivity in the visual (I need other filters to affect the visual because they are the input to the model).
@lbendlin Do you know how to make the connection to the web server accessible from Power BI Service?
This is a summary of what I have so far:
link = "https://xxxxxx.s3.amazonaws.com/models/linear_model_v1.pkl"
def predict_sq_meter_value(apartments):
try:
lin_model_v0
except:
lin_model_v0 = pickle.load(urllib.request.urlopen(link))
...The last line «pickle.load(urllib.request.urlopen(link))» is the one that breaks when published to the PBI Service, but in the Desktop works as expected.
This is the error I get in the published report

Script Runtime Error
self._send_request(method, url, body, headers, encode_chunked)
File "C:PythonLibhttpclient.py", line 1298, in _send_request
self.endheaders(body, encode_chunked=encode_chunked)
File "C:PythonLibhttpclient.py", line 1247, in endheaders
self._send_output(message_body, encode_chunked=encode_chunked)
File "C:PythonLibhttpclient.py", line 1026, in _send_output
self.send(msg)
File "C:PythonLibhttpclient.py", line 966, in send
self.connect()
File "C:PythonLibhttpclient.py", line 1414, in connect
super().connect()
File "C:PythonLibhttpclient.py", line 938, in connect
(self.host,self.port), self.timeout, self.source_address)
File "C:PythonLibsocket.py", line 707, in create_connection
for res in getaddrinfo(host, port, 0, SOCK_STREAM):
File "C:PythonLibsocket.py", line 752, in getaddrinfo
for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
socket.gaierror: [Errno 11001] getaddrinfo failed
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:Script.py", line 92, in <module>
sq_val, tot_val = predict_sq_meter_value(property)
File "C:Script.py", line 39, in predict_sq_meter_value
lin_model_v0 = pickle.load(urllib.request.urlopen(link))
File "C:PythonLiburllibrequest.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "C:PythonLiburllibrequest.py", line 525, in open
response = self._open(req, data)
File "C:PythonLiburllibrequest.py", line 543, in _open
'_open', req)
File "C:PythonLiburllibrequest.py", line 503, in _call_chain
result = func(*args)
File "C:PythonLiburllibrequest.py", line 1362, in https_open
context=self._context, check_hostname=self._check_hostname)
File "C:PythonLiburllibrequest.py", line 1321, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [Errno 11001] getaddrinfo failed>
Please try again later or contact support. If you contact support, please provide these details.
Activity ID: 28e08314-3838-462e-b4ec-5de753c8fb15
Request ID: 80f03bdf-612e-aa34-1a41-e45de7239e1a
Correlation ID: f0bea7a5-a996-d6a4-6786-0c24eecfbb45
Time: Tue Jul 28 2020 10:39:59 GMT-0500 (Colombia Standard Time)
Service version: 13.0.13960.55
Client version: 2007.3.02011-train
Cluster URI: https://wabi-south-central-us-redirect.analysis.windows.net/Any ideas on how can I solve this? I think I’m very close.