This is just something the site does. It appears to be part of some kind of anti-DDoS system. Why it returns 503 is perplexing, but it is definitely the site itself.
I tried the curl command Joe has above, and this is the response I get back:
HTTP/1.1 503 Service Temporarily Unavailable
Date: Mon, 08 Dec 2014 09:47:41 GMT
Content-Type: text/html; charset=UTF-8
Transfer-Encoding: chunked
Connection: keep-alive
Set-Cookie: __cfduid=d32f001037fafc1363bf86d29be0baf921418032061; expires=Tue, 08-Dec-15 09:47:41 GMT; path=/; domain=.gametracker.com; HttpOnly
X-Frame-Options: SAMEORIGIN
Cache-Control: no-cache
Server: cloudflare-nginx
CF-RAY: 19580b02d7c70f21-IAD
<!DOCTYPE HTML>
<html lang="en-US">
<head>
<meta charset="UTF-8" />
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1" />
<meta name="robots" content="noindex, nofollow" />
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1" />
<title>Just a moment...</title>
<style type="text/css">
html, body {width: 100%; height: 100%; margin: 0; padding: 0;}
body {background-color: #ffffff; font-family: Helvetica, Arial, sans-serif; font-size: 100%;}
h1 {font-size: 1.5em; color: #404040; text-align: center;}
p {font-size: 1em; color: #404040; text-align: center; margin: 10px 0 0 0;}
#spinner {margin: 0 auto 30px auto; display: block;}
.attribution {margin-top: 20px;}
</style>
<script type="text/javascript">
//<![CDATA[
(function(){
var a = function() {try{return !!window.addEventListener} catch(e) {return !1} },
b = function(b, c) {a() ? document.addEventListener("DOMContentLoaded", b, c) : document.attachEvent("onreadystatechange", b)};
b(function(){
var a = document.getElementById('cf-content');a.style.display = 'block';
setTimeout(function(){
var t,r,a,f, sdDUenl={"xRvHG":+((!+[]+!![]+[])+(!+[]+!![]+!![]+!![]+!![]+!![]+!![]+!![]))};
t = document.createElement('div');
t.innerHTML="<a href='/'>x</a>";
t = t.firstChild.href;r = t.match(/https?:///)[0];
t = t.substr(r.length); t = t.substr(0,t.length-1);
a = document.getElementById('jschl-answer');
f = document.getElementById('challenge-form');
;sdDUenl.xRvHG*=+((!+[]+!![]+!![]+[])+(!+[]+!![]+!![]+!![]));sdDUenl.xRvHG-=+((!+[]+!![]+[])+(!+[]+!![]+!![]+!![]+!![]));sdDUenl.xRvHG+=+((!+[]+!![]+!![]+[])+(!+[]+!![]+!![]+!![]));sdDUenl.xRvHG*=+((!+[]+!![]+!![]+!![]+[])+(!+[]+!![]+!![]+!![]+!![]+!![]));sdDUenl.xRvHG-=+((!+[]+!![]+!![]+!![]+!![]+[])+(+[]));sdDUenl.xRvHG-=+((!+[]+!![]+[])+(!+[]+!![]+!![]+!![]+!![]));sdDUenl.xRvHG*=+((!+[]+!![]+[])+(!+[]+!![]+!![]+!![]));sdDUenl.xRvHG-=+((!+[]+!![]+!![]+!![]+[])+(!+[]+!![]+!![]));sdDUenl.xRvHG*=+((+!![]+[])+(!+[]+!![]+!![]+!![]+!![]+!![]+!![]));sdDUenl.xRvHG+=+((!+[]+!![]+!![]+!![]+[])+(!+[]+!![]+!![]+!![]+!![]+!![]+!![]+!![]));a.value = parseInt(sdDUenl.xRvHG, 10) + t.length;
f.submit();
}, 5850);
}, false);
})();
//]]>
</script>
</head>
<body>
<table width="100%" height="100%" cellpadding="20">
<tr>
<td align="center" valign="middle">
<div class="cf-browser-verification cf-im-under-attack">
<noscript><h1 data-translate="turn_on_js" style="color:#bd2426;">Please turn JavaScript on and reload the page.</h1></noscript>
<div id="cf-content" style="display:none">
<img id="spinner" src="/cdn-cgi/images/spinner-2013.gif" />
<h1><span data-translate="checking_browser">Checking your browser before accessing</span> gametracker.com.</h1>
<p data-translate="process_is_automatic">This process is automatic. Your browser will redirect to your requested content shortly.</p>
<p data-translate="allow_5_secs">Please allow up to 5 seconds…</p>
</div>
<form id="challenge-form" action="/cdn-cgi/l/chk_jschl" method="get">
<input type="hidden" name="jschl_vc" value="3cecd7cab5d69708a3b1081e462824d0"/>
<input type="hidden" id="jschl-answer" name="jschl_answer"/>
</form>
</div>
<div class="attribution"><a href="http://www.cloudflare.com/" target="_blank" style="font-size: 12px;">DDoS protection by CloudFlare</a></div>
</td>
</tr>
</table>
</body>
</html>
Note that the body contains content, despite being a 503 status code. This is actually consistent with what I saw when trying to visit the page in the browser. First I was sent to this «anti-DDoS» page you see in the response above, and then I was automatically redirected to the page requested in the URL (apparently via JavaScript). This explains why it doesn’t behave as you expect outside your browser; a Python web request won’t execute JavaScript to perform the redirect.
So it’s definitely the service. You’ll have to consult the people who made it to find out why and how they expect you to deal with it. You may want to look into whether they have a different endpoint for API calls, or the endpoint might respond differently if you set the Accept header. (application/json can be used to indicate you want JSON back.)
Learn how to get rid of this error for good
by Milan Stanojevic
Milan has been enthusiastic about technology ever since his childhood days, and this led him to take interest in all PC-related technologies. He’s a PC enthusiast and he… read more
Updated on January 26, 2023
Fact checked by
Alex Serban

After moving away from the corporate work-style, Alex has found rewards in a lifestyle of constant analysis, team coordination and pestering his colleagues. Holding an MCSA Windows Server… read more
- Browsers are essential tools for surfing the Internet, they are the middleman between your computer and the websites you visit.
- There are plenty of different browsers on the market, each targetting specific user needs, but there is one thing that browsers have in common: error 503.
- HTTP error 503: The service is unavailable is one of the most frequent error codes affecting browsers.

- Easy migration: use the Opera assistant to transfer exiting data, such as bookmarks, passwords, etc.
- Optimize resource usage: your RAM memory is used more efficiently than in other browsers
- Enhanced privacy: free and unlimited VPN integrated
- No ads: built-in Ad Blocker speeds up loading of pages and protects against data-mining
- Gaming friendly: Opera GX is the first and best browser for gaming
- Download Opera
HTTP errors usually come in the form of status codes which are standard response codes that help you identify the cause of the problem given by a website server when either a web page or other resource fails to load properly while online.
Whenever you get an HTTP status code, it comes with the code itself, and the corresponding explanation such as HTTP error 503: The service is unavailable.
Something else you may want to keep in mind is that each of these codes, also known as browser errors, Internet error codes or Internet connection errors have its groups.
What is the HTTP error 503?
The HTTP 503 error falls under the 5xx server error group of HTTP status codes. They usually indicate that the web page or resource request is understood by the server, but the latter cannot fill it for one reason or another.
However, the HTTP error or status codes shouldn’t be confused with Device Manager errors or system error codes, because the latter is associated with different errors and meanings altogether.
When you get HTTP error 503, this usually points to the website’s server, which may have been compromised by an overload (temporarily) or it is too busy, or there’s some ongoing such as scheduled maintenance.
Fortunately, although this error comes up often, there are fairly quick solutions to fix the issue and get the website back online.
What is HTTP error 503 and how can I fix it?
- Preliminary checks
- Close your proxy server
- Start the destination application pool
- Change Load User Profile
- Change Identity in Application Pool
1. Preliminary checks
Whether the issue is with the server or your computer, there are some things you can try and check before fixing HTTP error 503: The service is unavailable. You could start by retrying the URL from the address bar by reloading or refreshing the page.
You can also restart your modem and router, then restart your computer or device – this is especially so if you see the ‘service unavailable – DNS failure’ message. If this doesn’t fix the error 503 DNS issue, pick new DNS servers and change them on your PC or router.
Check with the website itself directly for assistance as they may be aware of the error 503, so they may let you know if it is an issue that’s with everyone, not just you. Sometimes waiting it out is the easiest fix to this error.
- ALSO READ: 4 best browsers with built-in VPN you should use today
2. Close your proxy server
Perhaps you use a VPN or a proxy server, in which case, you need to check whether the connection is working the way it should, or properly. If the proxy server is down, then you may end up getting the HTTP error 503: The service is unavailable message.
This usually happens with free proxy servers, but if you do not use a proxy server, you can disable it and then try to open the website that is showing the HTTP error 503 the service is unavailable.
3. Start the destination application pool
If the application pool of the corresponding web application is stopped, or disabled, it causes the website to show HTTP error 503: The service is unavailable.
Additionally, any misconfiguration in the application pool or site settings can cause an error on the site. Process crashes also happen due to incorrect application logic.
Sometimes the user account related to the user identity of an application pool can be locked or has an expired password or even inadequate privileges which tamper with the functioning of the website.
Some PC issues are hard to tackle, especially when it comes to corrupted repositories or missing Windows files. If you are having troubles fixing an error, your system may be partially broken.
We recommend installing Restoro, a tool that will scan your machine and identify what the fault is.
Click here to download and start repairing.
If the application pool runs out of RAM or other resources, it can crash and lead to HTTP error 503, plus server migrations also lead to such errors.
If HTTP error 503 the service is unavailable is caused by a stopped application pool, starting it would resolve the issue.
- Click Start
- In the search bar, type Windows Features
- Select Turn Windows Features on or off
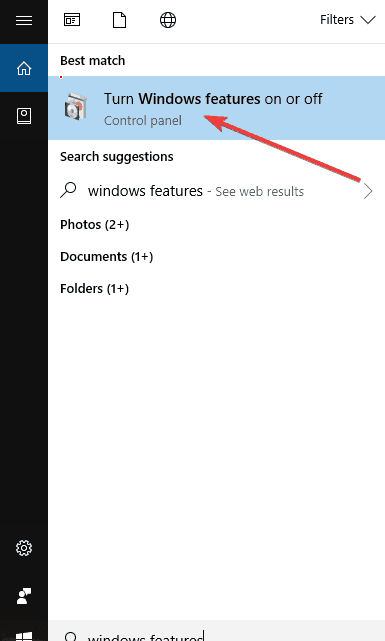
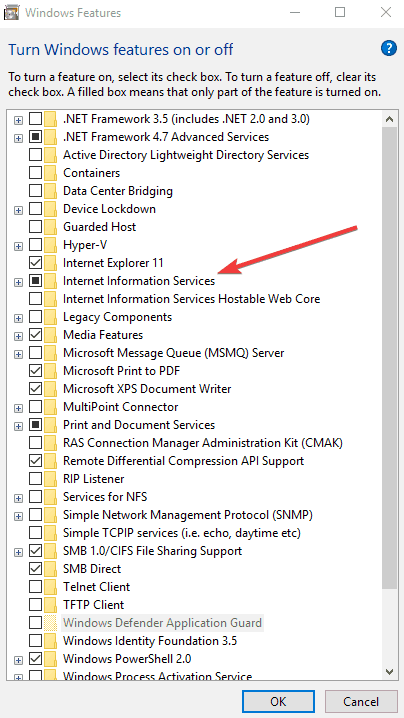
- Locate Internet Information Services and check the box – this will install everything you need to use IIS
- Go to Control Panel
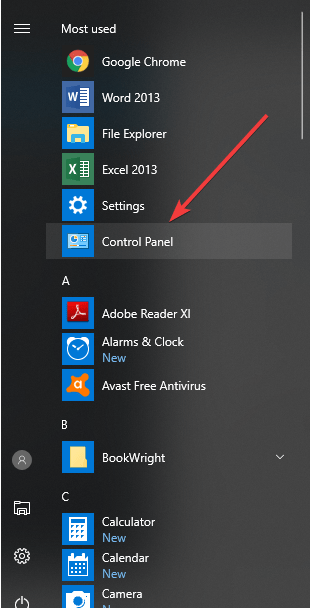
- Select View By and click Large Icons
- Click Administrative Tools
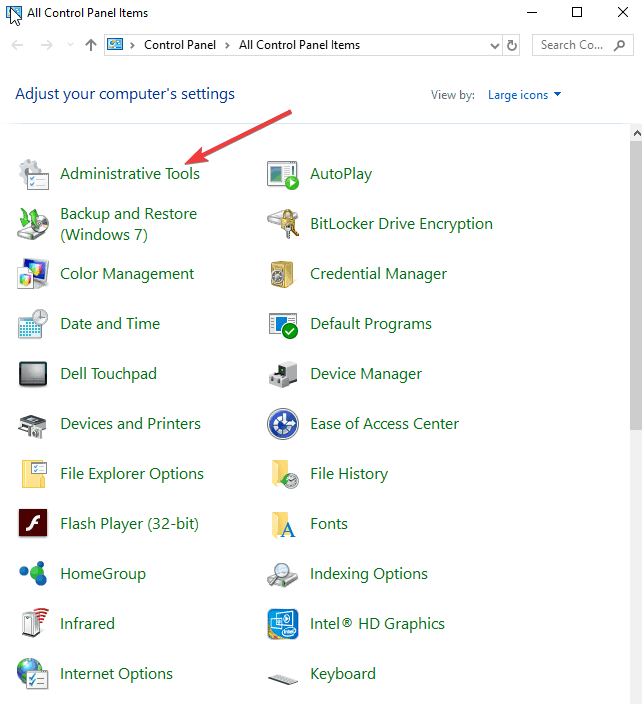
- Find IIS Manager and double-click on it
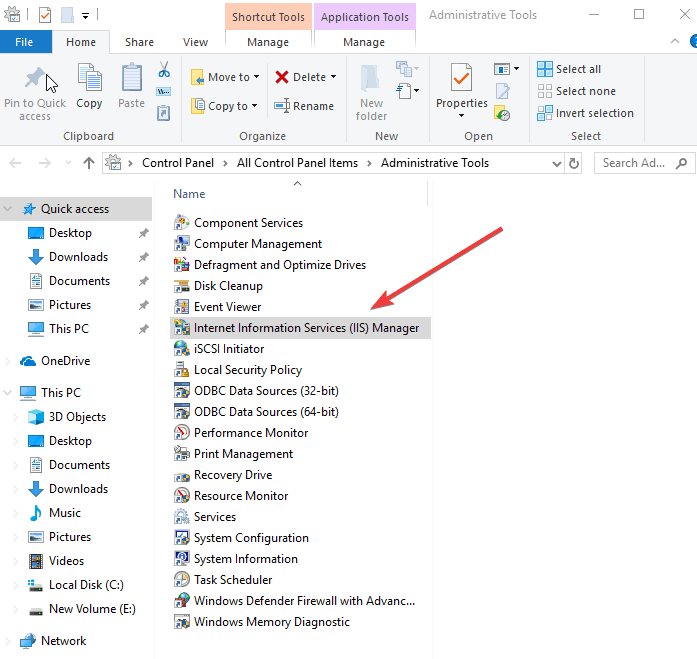
- Select Application Pools node
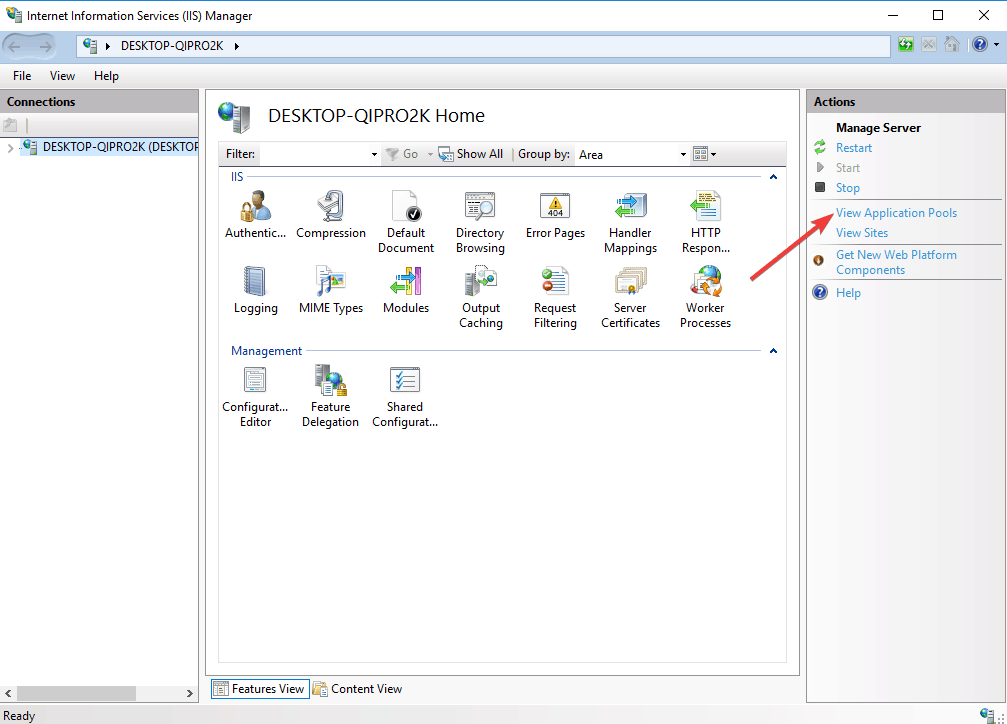
- Right-click on DefaultAppPool to check the status. If it is stopped, start it. If it is running, restart it and see if HTTP error 503 the service is unavailable is gone.
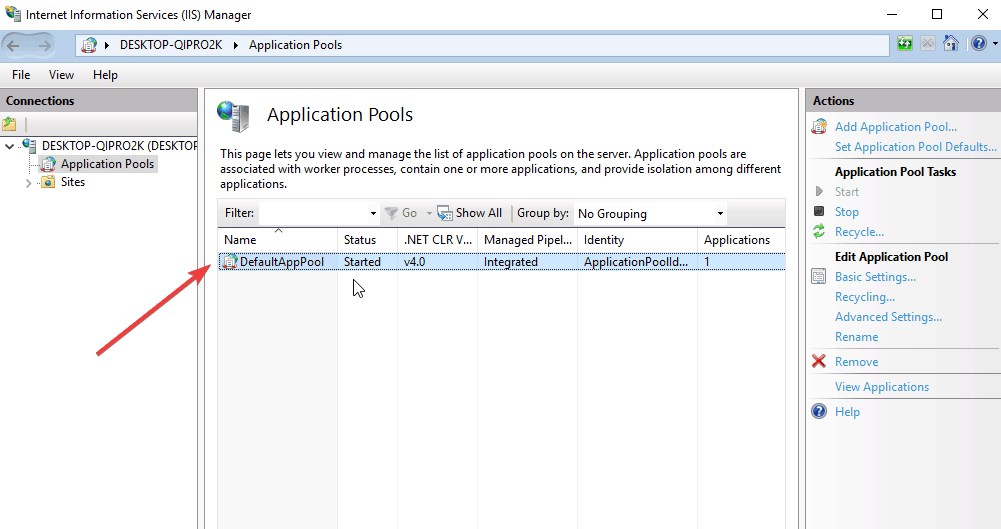
- ALSO READ: 3 best browsers with VPN that don’t slow down Internet connection
4. Change Load User Profile
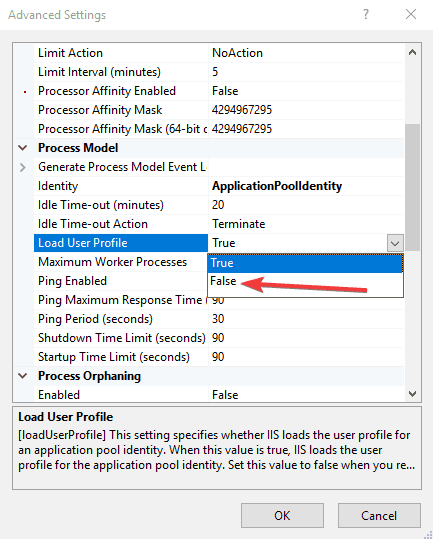
If the problem is the DefaultAppPool, change the ‘Load User Profile’ to false by doing the following:
- Go to Control Panel
- Select View By and click Large Icons
- Click Administrative Tools
- Find IIS Manager and double click on it
- Select Application Pools node
- Click on DefaultAppPool to select or highlight it
- On the right pane, select Advanced settings
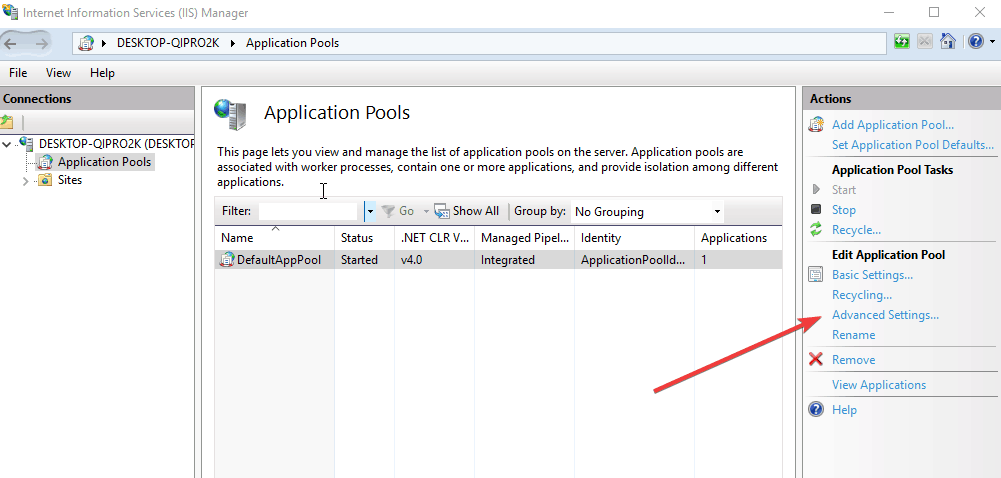
- Find Process Model
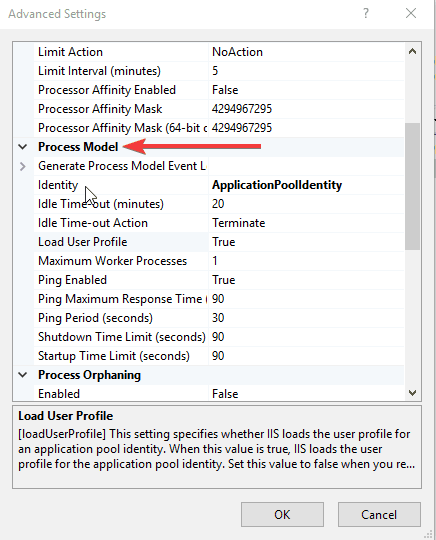
- Go to Load User Profile
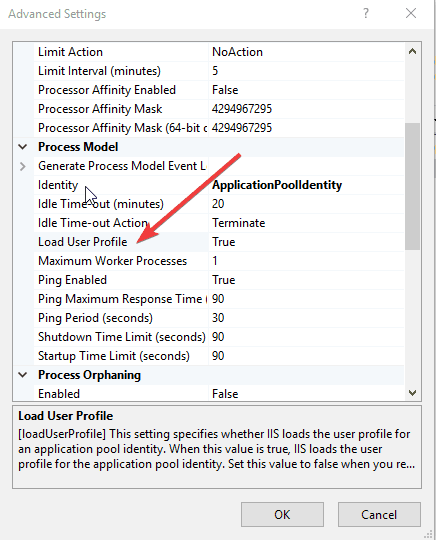
- Change from True to False
5. Change Identity in Application Pool
- Go to Control Panel
- Select View By and click Large Icons
- Click Administrative Tools
- Find IIS Manager and double-click on it
- Select Application Pools node
- Find the correct Application Pool for your website and click on it
- Click Advanced Settings
- Under Process Model, select Identity and change it, then enter a new user and password
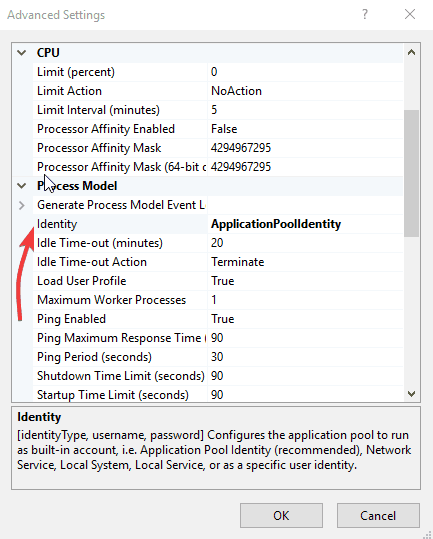
- Click on your Application Pool again and select Recycle to restart it.
- Reload the website
- Restart your modem and your computer
- Clear the browser cache
- Check your proxy settings
- Restart the DefaultAppPool
- What does service temporarily unavailable mean?
The error message Service temporarily unavailable indicates the server is not available either due to overloading issues or scheduled maintenance work. This is only a temporary issue, the service should get back online once the problem has been solved.
How can I fix error 503 on specific services?
1. Fix Tachiyomi HTTP error 503
This error affects Manga fans since Tachiyomi is a popular Manga reader for Android. PC users can also use this app with the help of an emulator or a bootable USB device. Here’s how to fix error 503 on Tachiyomi:
- Update the app, and make sure you’re using the latest version.
- Reset your Internet connection, and restart your modem and computer.
- Go back to the chapter menu, reload a new chapter and resume reading.
- Open a manga from the catalog throwing error 503. Click on the menu and select the option that allows you to open it in the browser. Close the browser and the source should be fixed now.
2. Fix HTTP error 503 the service is unavailable in IIS
To fix error 503 on IIS, you can do so through the built-in Application Pool. IIS stands for Information System Security and can be easily modified through the following steps.
1. Enable IIS
- Press the Windows Key and type windows features in the search box.
- Click on the result to open the Windows Features tab.
- Check the box next to Internet Information Services to enable it.
2. Start the Application Pool
- Press the Windows Key and type control panel.
- Click on the result to open Control Panel.
- Select Administrative Tools from the list.
- Find IIS Manager and click on it.
- Click on View Application Pools from the actions tab.
3. Change the AppPool username and password
- Go to Server, select the Application Pools and select the Application Pool of your website.
- Go to Advanced Settings and select Identity.
- Enter a new username and password, click on your Application Pool again.
- Select Recycle to restart it.
4. Tweak the Load User Profile
- Open the Advanced Settings of the DefaultAppPool.
- Change the Load User Profile option to false as shown at step 4.
5. Delete the URL ACL
If the URL’s ACL is reserver somewhere else in the system, you’re bound to get error 503. Here’s how to fix that:
- Open the console command and enter the netsh http show urlacl command to dump all URL ACLs.
- If the command returns the URL that triggered error 503, delete it using the netsh http delete urlacl url=[Insert URL] command.
3. Fix urllib.error.httperror: http error 503: service unavailable
Here’s what you can do to fix urllib 503 errors:
- Reset your Internet connection. Or connect to a different network (eg: temporarily switch to your mobile hotspot).
- Replace urllib by curl
4. Fix www.netflix.com is currently unable to handle this request. HTTP error 503
We’re sure one of these solutions will help you fix the problem:
- Try a different Internet connection if available.
- Make sure your firewall settings are not blocking Netflix.
- Sign in to your Netflix account using another device.
- Clear your browser’s cache and cookies.
You may also want to try the solutions listed in this Netflix site error troubleshooting guide.
5. Fix Subsonic HTTP error 503
To fix error 503 on Subsonic, follow these steps:
- Clean your Subsonic database. But first, do keep a copy of your database folder. Then, open the subsonic.data file and deleted all the media entries. Keep only the settings.
- Reinstall the player.
Did any of these solutions help fix HTTP error 503? Let us know by leaving a comment in the section below.
![]()
Newsletter
Good evening Olivier,
Thank you very much for sharing this script! I’m a first-time user, and I’ve been running into an HTTP Error 503. At the moment, I’m just testing things out by using your README example, with no proxy and my own usgs.txt file:
download_landsat_scene.py -o scene -b LC8 -d 20130127 -s 043034 -u usgs.txt —output /home/miriam/Documents/test/
The full error is:
None None
Traceback (most recent call last):
File «download_landsat_scene.py», line 594, in
main()
File «download_landsat_scene.py», line 412, in main
connect_earthexplorer_no_proxy(usgs)
File «download_landsat_scene.py», line 79, in connect_earthexplorer_no_proxy
f = urllib2.urlopen(request)
File «/usr/lib/python2.7/urllib2.py», line 127, in urlopen
return _opener.open(url, data, timeout)
File «/usr/lib/python2.7/urllib2.py», line 410, in open
response = meth(req, response)
File «/usr/lib/python2.7/urllib2.py», line 523, in http_response
‘http’, request, response, code, msg, hdrs)
File «/usr/lib/python2.7/urllib2.py», line 442, in error
result = self._call_chain(*args)
File «/usr/lib/python2.7/urllib2.py», line 382, in _call_chain
result = func(*args)
File «/usr/lib/python2.7/urllib2.py», line 629, in http_error_302
return self.parent.open(new, timeout=req.timeout)
File «/usr/lib/python2.7/urllib2.py», line 410, in open
response = meth(req, response)
File «/usr/lib/python2.7/urllib2.py», line 523, in http_response
‘http’, request, response, code, msg, hdrs)
File «/usr/lib/python2.7/urllib2.py», line 448, in error
return self._call_chain(*args)
File «/usr/lib/python2.7/urllib2.py», line 382, in _call_chain
result = func(*args)
File «/usr/lib/python2.7/urllib2.py», line 531, in http_error_default
raise HTTPError(req.get_full_url(), code, msg, hdrs, fp)
urllib2.HTTPError: HTTP Error 503: Service Unavailable
Generally, I think a 503 error would signal some issue with the webpage itself, but I can sign in just fine using a browser, and a quick check with curl (curl -I «https://ers.cr.usgs.gov/login») says «HTTP/1.1 200 OK.»
Do you know what the source of this issue may be? Many thanks, in advance. I really appreciate your help.
This is my completed Python script so far. It basically just parses a news website and organizes the companies’ news into a google sheet file. The news is searched for with key words, and companies of certain market caps are kept.
while True:
import bs4 as bs
import urllib.request
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://login.globenewswire.com/?ReturnUrl=%2fSecurity%2fLogin%3fculture%3den-US&culture=en-US#login')
# MANUALLY DO THE LOGIN
import pygsheets
gc = pygsheets.authorize()
sh = gc.open('GNW API')
wks = sh.sheet1
import datetime
import time
x = 18
y = 26
KeyWords = ['develop', 'contract', 'award', 'certif', 'execut', 'research', 'drug', 'theraputic', 'pivotal', 'trial', 'patient', 'data', 'fda', 'stud', 'phase', 'licenc', 'cancer', 'agree', 'clinical', 'acquisition', 'translational', 'trial', 'worldwide', 'world wide', 'world-wide', 'exclusiv', 'positive', 'successful', 'enter', 'sell', 'acquir', 'buy', 'bought', 'payment', 'availiab', 'design', 'transaction', 'increas', 'sale', 'record', 'clearance', 'right', 'launch', 'introduc', 'payment', 'meet', 'endpoint', 'primary', 'secondary', 'major', 'milestone', 'collaborat', 'beat', 'astound', 'sign', 'order', 'suppl', 'produc', 'made', 'make', 'making', 'customer', 'client', 'mulitpl', 'result', 'distribut', 'disease', 'treat', 'chmp', 'priority', 'promis', 'patent', 'purchas', 'allianc', 'strategic', 'team', 'commercializ', 'approv', 'select', 'strong', 'strength', 'grow', 'profit', 'improv', 'partner', 'cannabis', 'crypto', 'bitcoin', 'platform', 'expands', 'extends']
break
while True:
now = datetime.datetime.today()
while now.hour == x:
while now.minute == y:
list =
listfinal =
driver.get('https://globenewswire.com/Search?runSearchId=41556723')
elementals = driver.find_elements_by_class_name('post-title16px')
for elements in elementals:
list.append(elements.find_element_by_css_selector('a').get_attribute('href'))
for elements in list:
if any(KeyWords_item in elements.lower() for KeyWords_item in KeyWords):
listfinal.append(elements)
for elementals in listfinal:
sauce = urllib.request.urlopen(elementals).read()
soup = bs.BeautifulSoup(sauce,'lxml')
desc = soup.find_all(attrs={"name":"ticker"}, limit=1)
tickerraw = (desc[0]['content'].encode('utf-8'))
decodedticker = tickerraw.decode('utf')
souptitle = soup.title.text
while True:
if ', ' in decodedticker.lower():
finaltickerlist = decodedticker.split(', ')
for elements in finaltickerlist:
if 'nyse' in elements.lower():
if ':' in elements:
a, b = elements.split(':')
finaltickerexchange = 'NYSE'
finalticker = b
if ' ' in finalticker:
finalticker = finalticker.replace(' ', '')
break
else:
break
else:
finalticker = 'NoTicker'
finaltickerexchange = 'NoTicker'
elif 'nasdaq' in elements.lower():
if ':' in elements:
a, b = elements.split(':')
finaltickerexchange = 'NASDAQ'
finalticker = b
if ' ' in finalticker:
finalticker = finalticker.replace(' ', '')
break
else:
break
else:
finalticker = 'NoTicker'
finaltickerexchange = 'NoTicker'
elif 'tsx' in elements.lower():
if ':' in elements:
a, b = elements.split(':')
finaltickerexchange = 'TSX'
finalticker = b
if ' ' in finalticker:
finalticker = finalticker.replace(' ', '')
break
else:
break
else:
finalticker = 'NoTicker'
finaltickerexchange = 'NoTicker'
else:
finalticker = 'NoTicker'
finaltickerexchange = 'NoTicker'
elif 'nasdaq' in decodedticker.lower():
if ':' in decodedticker.lower():
a, b = decodedticker.split(':', maxsplit=1)
finalticker = b
if ' ' in finalticker:
finalticker = finalticker.replace(' ', '')
finaltickerexchange = 'NASDAQ'
elif 'nyse' in decodedticker.lower():
if ':' in decodedticker.lower():
a, b = decodedticker.split(':', maxsplit=1)
finalticker = b
if ' ' in finalticker:
finalticker = finalticker.replace(' ', '')
finaltickerexchange = 'NYSE'
elif 'tsx' in decodedticker.lower():
if ':' in decodedticker.lower():
a, b = decodedticker.split(':', maxsplit=1)
finalticker = b
if ' ' in finalticker:
finalticker = finalticker.replace(' ', '')
finaltickerexchange = 'TSX'
else:
finalticker = 'NoTicker'
finaltickerexchange = 'NoTicker'
break
if finalticker != 'NoTicker':
sauce = urllib.request.urlopen('https://finance.yahoo.com/quote/' + finalticker + '?p=' + finalticker).read()
soup = bs.BeautifulSoup(sauce,'lxml')
mc_elm = soup.find(attrs={"data-test":"MARKET_CAP-value"})
while True:
if mc_elm:
marketcap = mc_elm.get_text()
else:
marketcap = "TickerNotFound"
break
while True:
if 'B' in marketcap:
marketcap = 'Billion Kalppa'
else:
values_list = ([finalticker,finaltickerexchange,marketcap,souptitle,elements])
wks.insert_rows(row=0, number=1, values=values_list)
break
if x == 23:
x = 0
time.sleep(3000)
else:
x += 1
time.sleep(3000)
break
time.sleep(55)
break
I intend to have this program run in the background and scrap news every hour when its the 26th minute of the hour. However after a while (not immediately, the code can run for 7-8 hours or iterations before this happens) I get this error:
Traceback (most recent call last):
File "<pyshell#3>", line 93, in <module>
sauce = urllib.request.urlopen('https://finance.yahoo.com/quote/' + finalticker + '?p=' + finalticker).read()
File "C:UsersArbi717AppDataLocalProgramsPythonPython36-32liburllibrequest.py", line 223, in urlopen
return opener.open(url, data, timeout)
File "C:UsersArbi717AppDataLocalProgramsPythonPython36-32liburllibrequest.py", line 532, in open
response = meth(req, response)
File "C:UsersArbi717AppDataLocalProgramsPythonPython36-32liburllibrequest.py", line 642, in http_response
'http', request, response, code, msg, hdrs)
File "C:UsersArbi717AppDataLocalProgramsPythonPython36-32liburllibrequest.py", line 570, in error
return self._call_chain(*args)
File "C:UsersArbi717AppDataLocalProgramsPythonPython36-32liburllibrequest.py", line 504, in _call_chain
result = func(*args)
File "C:UsersArbi717AppDataLocalProgramsPythonPython36-32liburllibrequest.py", line 650, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 503: Service Unavailable
I believe urllib.request is the problem because I am seeing that in the error a lot, however I have no idea what the solution is. Any help is much appreciated. 
If this is not the right place to ask this question, please point me in the right direction. Thanks in advance!
I have a small python3 function that downloads some file from the internet using urllib.request.urlopenor and urllib.request.urlretrieve. I run this function in a bigger code in docker container based on Ubuntu 16.04. When trying to download the file using http protocol, the call fails with error code 503 Service Unavailable. When downloading a webpage content from an https server, the call fails during handshake.
Following is the call I do to download some tarball from an http server:
import urllib.request
url = "http://example.com/file.tar.gz"
urllib.request.urlretrieve(url, "file.tar.gz")
Above call fails with error
Traceback (most recent call last):
File "/usr/lib/python3.5/urllib/request.py", line 188, in urlretrieve
with contextlib.closing(urlopen(url, data)) as fp:
File "/usr/lib/python3.5/urllib/request.py", line 163, in urlopen
return opener.open(url, data, timeout)
File "/usr/lib/python3.5/urllib/request.py", line 472, in open
response = meth(req, response)
File "/usr/lib/python3.5/urllib/request.py", line 582, in http_response
'http', request, response, code, msg, hdrs)
File "/usr/lib/python3.5/urllib/request.py", line 510, in error
return self._call_chain(*args)
File "/usr/lib/python3.5/urllib/request.py", line 444, in _call_chain
result = func(*args)
File "/usr/lib/python3.5/urllib/request.py", line 590, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 503: Service Unavailable
And the following is what I do with https:
def download_report(self, id, output_file):
ssl_def_function = ssl._create_default_https_context
ssl._create_default_https_context = ssl._create_unverified_context
css = urllib.request.urlopen(self.url + "/print.css")
report = urllib.request.urlopen(self.url + "/run/" + id + "/report/")
with open(output_file, "w+") as f:
# We need to embed the CSS first
css = str(css.read(), "utf-8")
report = str(report.read(), "utf-8").replace("<head>", "<head><style>%s</style>" % css) f.write(report)
ssl._create_default_https_context = ssl_def_function
and this fails with following:
Traceback (most recent call last):
File "/usr/lib/python3.5/urllib/request.py", line 1254, in do_open
h.request(req.get_method(), req.selector, req.data, headers)
File "/usr/lib/python3.5/http/client.py", line 1106, in request
self._send_request(method, url, body, headers)
File "/usr/lib/python3.5/http/client.py", line 1151, in _send_request
self.endheaders(body)
File "/usr/lib/python3.5/http/client.py", line 1102, in endheaders
self._send_output(message_body)
File "/usr/lib/python3.5/http/client.py", line 934, in _send_output
self.send(msg)
File "/usr/lib/python3.5/http/client.py", line 877, in send
self.connect()
File "/usr/lib/python3.5/http/client.py", line 1260, in connect
server_hostname=server_hostname)
File "/usr/lib/python3.5/ssl.py", line 377, in wrap_socket
_context=self)
File "/usr/lib/python3.5/ssl.py", line 752, in __init__
self.do_handshake()
File "/usr/lib/python3.5/ssl.py", line 988, in do_handshake
self._sslobj.do_handshake()
File "/usr/lib/python3.5/ssl.py", line 633, in do_handshake
self._sslobj.do_handshake()
ConnectionResetError: [Errno 104] Connection reset by peer
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "./utils/Uploader.py", line 148, in <module>
handler.download_report(id, output_file)
File "/tmp/prj/Helper.py", line 250, in download_report
css = urllib.request.urlopen(self.url + "/static/print.css")
File "/usr/lib/python3.5/urllib/request.py", line 163, in urlopen
return opener.open(url, data, timeout)
File "/usr/lib/python3.5/urllib/request.py", line 466, in open
response = self._open(req, data)
File "/usr/lib/python3.5/urllib/request.py", line 484, in _open
'_open', req)
File "/usr/lib/python3.5/urllib/request.py", line 444, in _call_chain
result = func(*args)
File "/usr/lib/python3.5/urllib/request.py", line 1297, in https_open
context=self._context, check_hostname=self._check_hostname)
File "/usr/lib/python3.5/urllib/request.py", line 1256, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error [Errno 104] Connection reset by peer>
It is worth mentioning that the same code works perfectly on following OSes (docker containers) but only fails on Ubuntu 16.04
-
Ubuntu (14.04, 18.04)
-
Fedora (27, 28, 29)
-
CentOS (7.4, 7.5)
-
OpenSuse (42.3, 15.0)
-
Windows
I even installed Ubuntu 16.04 on a VM and it also fails. I also tried running the container on multiple machines and they all fail with the same error. This kept me thinking for 2 days and I can’t figure out the solution. I made sure OpenSSL and libssl-dev are installed. I also tried python 3.7 by compiling it. Thank you for any help.
Edit: I worked around the issues by using the requests module rather than the urllib. requests. I do now requests. get(url). Thanks for the help!