Содержание
- Forums
- urllib.error.URLError: deleted-user-2024487 | 3 posts | Dec. 21, 2016, 8:57 p.m. | permalink
- Status code was -1 and not [200]: Request failed: #6022
- Comments
- Python-сообщество
- Уведомления
- #1 Март 20, 2020 11:23:34
- Не получается простейший запрос requests
- #2 Март 20, 2020 12:44:52
- Не получается простейший запрос requests
- #3 Март 20, 2020 14:39:47
- Не получается простейший запрос requests
- #4 Март 20, 2020 15:49:31
- Не получается простейший запрос requests
- #5 Март 20, 2020 17:46:45
- Не получается простейший запрос requests
- #6 Март 20, 2020 18:34:34
- Не получается простейший запрос requests
- #7 Март 20, 2020 18:52:33
- Не получается простейший запрос requests
- #8 Март 20, 2020 19:40:33
- Не получается простейший запрос requests
- #9 Март 21, 2020 02:56:43
- Не получается простейший запрос requests
- #10 Март 21, 2020 02:57:20
- Не получается простейший запрос requests
- Ошибка ERR_TUNNEL_CONNECTION_FAILED в Chrome и Яндекс Браузере
- Возможные причины ошибки ERR_TUNNEL_CONNECTION_FAILED и способы исправления
- Видео инструкция
Forums
urllib.error.URLError: deleted-user-2024487 | 3 posts | Dec. 21, 2016, 8:57 p.m. | permalink
Hello, I read some posts here in the forum about the same error I get. It seems the external website that I’m trying to use is not included in your proxy white list
The website is https://www.import.io/
Please let me know if it’s possible to get access to that website.
Many thanks Dario
The api endpoint for import.io (api.import.io) is already on the whitelist. Are you configuring your code to use the proxy? The proxy address is proxy.server:3128
I configured the proxy but I still get «IOError: [Errno socket error] [Errno 111] Connection refused»
Maybe the reason is that import.io offers other URLs that are not included in the whitelist. In particular I’m using:
Is it possible to add those URLs?
Many thanks Dario
Hi Dario — if you’re getting a connection refused error, your code must be missing the proxy somehow — a failure due to something not being on the whitelist would give you the 403 forbidden error you got originally.
Could you post your proxy setup code?
(If it’s not something you’d like to share publicly, you can email it to us at support@pythonanywhere.com)
Hi Glen, I am also getting same error. did you find any silution for this error? If you found, please let me know
See this explanation and do this after checking what you are trying to access isn’t on this
hi there, i have also same problem, when I try to get an image from URL (eg: «https://api.twilio.com/2010-04-01/Accounts/AC86a729d2c869f0ad33c9bb7974ddcae7/Messages/MM566185e8df7eecc50475daf93d2e8094/Media/MEc39b6f6bb1faa2d362d68cbf61375010»)
I got an error like: code for that: resp = urlopen(URL) image = np.asarray(bytearray(resp.read()), dtype=»uint8″) image = cv2.imdecode(image, cv2.IMREAD_COLOR)
can u pls respond to this issue asap I am working on my final yr project and I have 15 days left for this so pls resolve my issue as fast
twilio is already on the whitelist
Hello, i’m getting the same error when i try to access https://fundamentus.com.br, can someone help me how to implement some proxy to request or any other way? I’m using python 3.8
thanks in advance
It’s not whitelisted for free users.
Hello, i’m getting the same error when i try to access https://ttsapi.almagu.com/.
Free accounts have restricted Internet access — they can only make HTTP and HTTPS requests, and the sites that they access must be on the whitelist. We can add new sites to the whitelist if they have an official public API; if that site has one, please post a link to the API documentation.
Can I please ask to whitelist this website: https://api.nextbike.net/maps/nextbike-live.json ?
@tuchlin We can add new sites to the whitelist if they have an official public API; if that site has one, please post a link to the API documentation.
I don’t see a reference to api.nextbike.net there — could you send a link to a page that mentions that?
Can you possibly white list this site https://bon.navarra.es/*
@sploro We can add new sites to the whitelist if they have an official public API; if that site has one, please post a link to the API documentation. BTW your account is a paid one, so you should not be affected by the whitelist limitations.
Hi, I’m getting the same error with YouTube. Can it be added to the whitelist?
Exception Value: I’m getting the same error with many of the APIs that are already whitelisted. Earlier it was working well but now it is throwing errors like URLError or ProxyError
Pytube is not whitelisted earlier it was but now it is throwing forbidden error.
Official documentation: https://pytube.io/en/latest/api.html
ytmusicapi is also not whitelisted earlier it was.
Official documentation: https://ytmusicapi.readthedocs.io/en/latest/
Hi all, sorry for the slow reply.
We only add sites to the whitelist if they (the sites themselves) have official documented public APIs. We don’t actively monitor them, though, so some sites can get whitelisted and then remain on the list even when they’re not hosting APIs.
However, someone recently started abusing PythonAnywhere by setting up tens of thousands of junk accounts with code to «watch» a YouTube video. That meant that we had to review our blanked whitelisting of YouTube.com, and we discovered that it no longer seems to have an API hosted there — its API is now at www.googleapis.com .
If there is a documented API that is on a different hostname, however, do let us know — we just need a link to its docs.
Источник
Status code was -1 and not [200]: Request failed: #6022
Environment:
Cloud provider or hardware configuration:
OS ( printf «$(uname -srm)n$(cat /etc/os-release)n» ):
Linux 4.18.0-147.8.1.el8_1.x86_64 x86_64
NAME=»CentOS Linux»
VERSION=»8 (Core)»
ID=»centos»
ID_LIKE=»rhel fedora»
VERSION_ID=»8″
PLATFORM_ID=»platform:el8″
PRETTY_NAME=»CentOS Linux 8 (Core)»
ANSI_COLOR=»0;31″
CPE_NAME=»cpe:/o:centos:centos:8″
HOME_URL=»https://www.centos.org/»
BUG_REPORT_URL=»https://bugs.centos.org/»
CENTOS_MANTISBT_PROJECT=»CentOS-8″
CENTOS_MANTISBT_PROJECT_VERSION=»8″
REDHAT_SUPPORT_PRODUCT=»centos»
REDHAT_SUPPORT_PRODUCT_VERSION=»8″
Version of Ansible ( ansible —version ):
ansible 2.9.6
config file = /home/vagrant/kubespray/ansible.cfg
configured module search path = [‘/home/vagrant/kubespray/library’]
ansible python module location = /usr/local/lib/python3.6/site-packages/ansible
executable location = /usr/local/bin/ansible
python version = 3.6.8 (default, Nov 21 2019, 19:31:34) [GCC 8.3.1 20190507 (Red Hat 8.3.1-4)]
Version of Python ( python —version ):
python3 —version
Python 3.6.8
Kubespray version (commit) ( git rev-parse —short HEAD ):
3d59885
Network plugin used:
CALICO
Full inventory with variables
Full inventory with variables.txt
( ansible -i inventory/sample/inventory.ini all -m debug -a «var=hostvars[inventory_hostname]» ):
Command used to invoke ansible:
ansible-playbook -vvv -i inventory/mycluster/inventory.ini cluster.yml
Output of ansible run:
TASK [kubernetes-apps/ansible : Kubernetes Apps | Wait for kube-apiserver] ***********************************************************************************************************
task path: /home/vagrant/kubespray/roles/kubernetes-apps/ansible/tasks/main.yml:2
fatal: [node1]: FAILED! => <
«attempts»: 20,
«changed»: false,
«content»: «»,
«elapsed»: 0,
«invocation»: <
«module_args»: <
«attributes»: null,
«backup»: null,
«body»: null,
«body_format»: «raw»,
«client_cert»: «/etc/kubernetes/ssl/ca.crt»,
«client_key»: «/etc/kubernetes/ssl/ca.key»,
«content»: null,
«creates»: null,
«delimiter»: null,
«dest»: null,
«directory_mode»: null,
«follow»: false,
«follow_redirects»: «safe»,
«force»: false,
«force_basic_auth»: false,
«group»: null,
«headers»: <>,
«http_agent»: «ansible-httpget»,
«method»: «GET»,
«mode»: null,
«owner»: null,
«regexp»: null,
«remote_src»: null,
«removes»: null,
«return_content»: false,
«selevel»: null,
«serole»: null,
«setype»: null,
«seuser»: null,
«src»: null,
«status_code»: [
200
],
«timeout»: 30,
«unix_socket»: null,
«unsafe_writes»: null,
«url»: «https://127.0.0.1:6443/healthz»,
«url_password»: null,
«url_username»: null,
«use_proxy»: true,
«validate_certs»: false
>
>,
«msg»: «Status code was -1 and not [200]: Request failed: «,
«redirected»: false,
«status»: -1,
«url»: «https://127.0.0.1:6443/healthz»
>
output of ansible -i inventory/mycluster/inventory.ini all -m debug -a «var=hostvars[inventory_hostname]» > «Full inventory with variables».txt
state that no_proxy =»» why.
may it be the problem?
The text was updated successfully, but these errors were encountered:
Источник
Python-сообщество
Уведомления
#1 Март 20, 2020 11:23:34
Не получается простейший запрос requests
Traceback (most recent call last):
File “C:Python27main1.py”, line 28, in
res = requests.get(‘https://yobit.net/api/3/ticker/eth_usd’) # получаем данные info
File “C:Python27libsite-packagesrequestsapi.py”, line 72, in get
return request(‘get’, url, params=params, **kwargs)
File “C:Python27libsite-packagesrequestsapi.py”, line 58, in request
return session.request(method=method, url=url, **kwargs)
File “C:Python27libsite-packagesrequestssessions.py”, line 508, in request
resp = self.send(prep, **send_kwargs)
File “C:Python27libsite-packagesrequestssessions.py”, line 618, in send
r = adapter.send(request, **kwargs)
File “C:Python27libsite-packagesrequestsadapters.py”, line 502, in send
raise ProxyError(e, request=request)
ProxyError: HTTPSConnectionPool(host=’yobit.net’, port=443): Max retries exceeded with url: /api/3/ticker/eth_usd (Caused by ProxyError(‘Cannot connect to proxy.’, error(‘Tunnel connection failed: 407 Proxy Authentication Required’,)))
не могу понять что надо, через браузер выполняет через питон не хочет?
#2 Март 20, 2020 12:44:52
Не получается простейший запрос requests
Вы используете соединение через прокси-сервер. Ваш браузер настроен на аутентификацию на прокси-сервере, а питон-скрипт нет.
#3 Март 20, 2020 14:39:47
Не получается простейший запрос requests
Установлена вот такая версия Python 3.8.2 (tags/v3.8.2:7b3ab59, Feb 25 2020, 22:45:29) on win32
Интернет соединение через свисток мегафона
можно пример из нескольких строчек чтоб выполнился запрос https://yobit.net/api/3/ticker/eth_usd
понимаю что это элементарно, но все же я в разделе для новичков …
заранее спасибо
#4 Март 20, 2020 15:49:31
Не получается простейший запрос requests
Вот результат без использования прокси:
Scorp1978
error(‘Tunnel connection failed: 407 Proxy Authentication Required ‘,)))
Отредактировано Rafik (Март 20, 2020 15:51:16)
#5 Март 20, 2020 17:46:45
Не получается простейший запрос requests
я перешел на другой компьютер где инет напрямую без прокси
выполнил вот это программу
import requests
res = requests.get(‘https://yobit.net/api/3/ticker/eth_usd’)
print (res)
ошибки
Traceback (most recent call last):
File “C Users/server-2/AppData/Local/Programs/Python/Python38-32/zap.py”, line 1, in
Users/server-2/AppData/Local/Programs/Python/Python38-32/zap.py”, line 1, in
import requests
ModuleNotFoundError: No module named ‘requests’
я так понимаю что не нашел модуль requests
#6 Март 20, 2020 18:34:34
Не получается простейший запрос requests
Scorp1978
я так понимаю что не нашел модуль requests
#7 Март 20, 2020 18:52:33
Не получается простейший запрос requests
Вы удивительно догадливы! ))))))) без обид. я пытался его установить у меня не получилось конечно можно было сразу начать с этого вопрос но решил все с самого начала
>>> pip install requests
SyntaxError: invalid syntax
>>> easy_install requests
SyntaxError: invalid syntax
>>>
#8 Март 20, 2020 19:40:33
Не получается простейший запрос requests
Scorp1978
вы пытаетесь выполнить команду операционной системы из интерактивного сеанса питона. Так ничего не получится, выполняйте это из cmd.
#9 Март 21, 2020 02:56:43
Не получается простейший запрос requests
из cmd пишет что pip не является внутренней или внешней командой
#10 Март 21, 2020 02:57:20
Не получается простейший запрос requests
нужно скачать программу pip я правильно понимаю? но пишут что на питоне выше 3.4 пип уже в комплекте может в путях дело?
Отредактировано Scorp1978 (Март 21, 2020 02:59:10)
Источник
Ошибка ERR_TUNNEL_CONNECTION_FAILED в Chrome и Яндекс Браузере
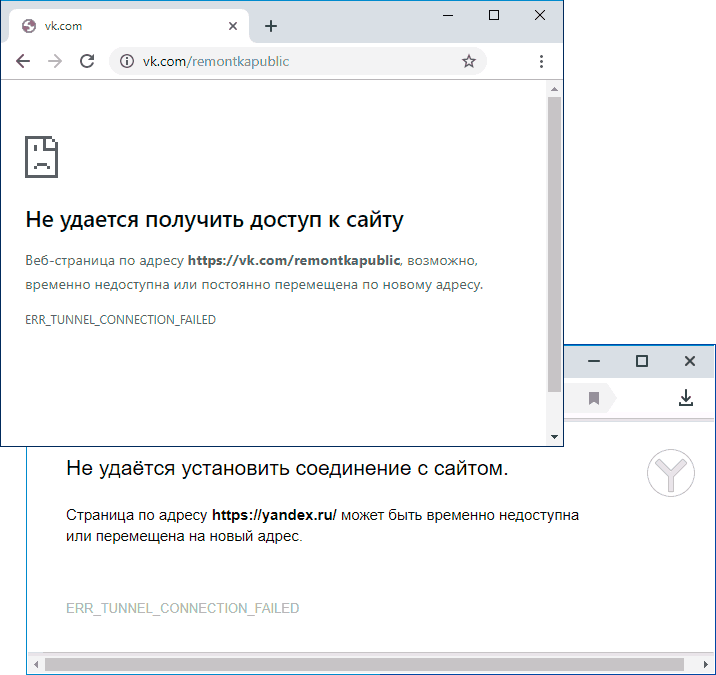
 Иногда при открытии сайтов в Google Chrome и Яндекс Браузере вы можете столкнуться с ошибкой с кодом ERR_TUNNEL_CONNECTION_FAILED, с пояснением «Не удается получить доступ к сайту» или «Не удается установить соединение с сайтом».
Иногда при открытии сайтов в Google Chrome и Яндекс Браузере вы можете столкнуться с ошибкой с кодом ERR_TUNNEL_CONNECTION_FAILED, с пояснением «Не удается получить доступ к сайту» или «Не удается установить соединение с сайтом».
В этой инструкции подробно о том, что делать, если сайты не открываются с этой ошибкой способах исправить ERR_TUNNEL_CONNECTION_FAILED в браузере в Windows 10, 8.1 и Windows 7. Схожая ошибка: ERR_PROXY_CONNECTION_FAILED.
Возможные причины ошибки ERR_TUNNEL_CONNECTION_FAILED и способы исправления
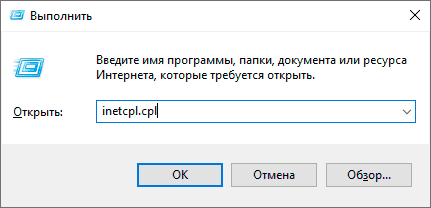
Самая частая причина рассматриваемой ошибки — установленный в параметрах подключения прокси-сервер, который работает неправильно либо, по какой-то причине не может установить соединение с вами. Соответственно, самое простое и чаще всего работающее решение — отключить прокси-сервер:
- Зайдите в Панель управления (в Windows 10 это можно легко сделать с помощью поиска на панели задач), а затем откройте пункт «Свойства браузера». Вместо этого также можно нажать клавиши Win+R на клавиатуре, ввести inetcpl.cpl и нажать Enter.

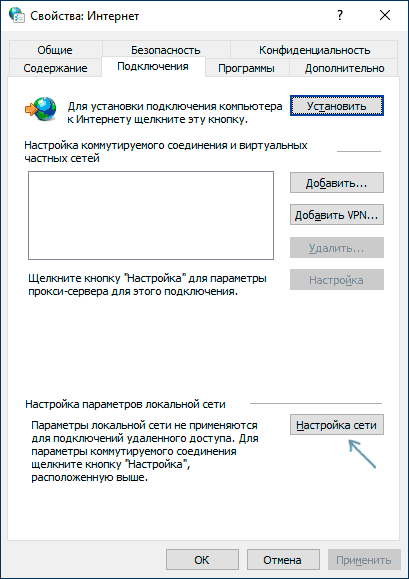
- В открывшемся окне перейдите на вкладку «Подключения» и нажмите кнопку «Настройка сети».
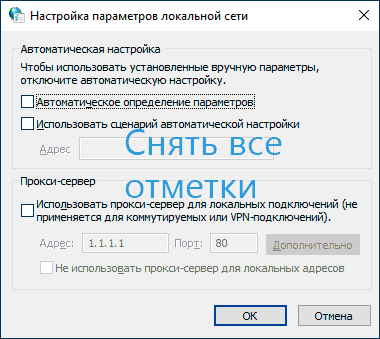
- В следующем окне снимите все без исключения отметки и примените настройки.
- Проверьте, была ли решена проблема и открываются ли сайты теперь.
Обычно, указанного выше оказывается достаточно, чтобы исправить ошибку ERR_TUNNEL_CONNECTION_FAILED при открытии страниц в Интернете.
Прежде чем приступать к следующим шагам учитывайте:
- При появлении ошибки только на одном сайте, когда все остальные работают, причина может быть со стороны самого сайта либо со стороны вашего провайдера. В этом случае ошибка обычно является временной.
- Иногда ошибка бывает связана с какими-либо блокировками (опять же, если речь идет об одном сайте), тогда сайты обычно доступны по VPN без ошибок.
Следующие шаги, которые можно попробовать для исправления рассматриваемой проблемы:
- Попробуйте отключить любые расширения прокси и VPN в браузере, если таковые имеются. Причина почти точно в этом, если в других браузерах эти же сайты открываются.
- Попробуйте отключиться от Интернета (или выключить роутер, если подключение выполняется через него), а затем снова запустить подключение (или включить роутер).
- Проверьте, сохраняется ли ошибка, если отключить антивирус (при использовании сторонних антивирусов).
- Выполните сброс сети Windows 10 (если у вас эта ОС).
- Попробуйте очистить кэш DNS.
Если всё перечисленное также не исправляет ситуацию, запустите командную строку от имени администратора и выполните команды (вводите по одной строке, нажимая Enter после каждой):
А после выполнения всех команд перезагрузите компьютер и проверьте, исчезла ли ошибка ERR_TUNNEL_CONNECTION_FAILED.
Видео инструкция
В завершение — видео, где основные методы показаны наглядно, а также даны пояснения по остальным нюансам ошибки.
В том случае, если ваша ситуация с этой ошибкой отличается, а решения не подходят, опишите происходящее в комментариях, я постараюсь помочь.
Источник
urllib.error.URLError: <urlopen error Tunnel connection failed: 403 Forbidden
Hello,
i’m trying to connect to the website import.io using urllib.request.Request but I get the following error:
urllib.error.URLError: <urlopen error Tunnel connection failed: 403 Forbidden
I don;t have that error if I run the script from my PC. Do you have any idea to solve the issue?
Many thanks
Dario
deleted-user-2024487
|
3
posts
|
Dec. 21, 2016, 8:57 p.m.
|
permalink
Hello,
I read some posts here in the forum about the same error I get.
It seems the external website that I’m trying to use is not included in your proxy white list
The website is https://www.import.io/
Please let me know if it’s possible to get access to that website.
Many thanks
Dario
deleted-user-2024487
|
3
posts
|
Dec. 22, 2016, 10:57 a.m.
|
permalink
The api endpoint for import.io (api.import.io) is already on the whitelist. Are you configuring your code to use the proxy? The proxy address is proxy.server:3128

glenn
|
8703
posts
|
PythonAnywhere staff
|
Dec. 22, 2016, 12:17 p.m.
|
permalink
Thanks Glen,
I configured the proxy but I still get «IOError: [Errno socket error] [Errno 111] Connection refused»
Maybe the reason is that import.io offers other URLs that are not included in the whitelist. In particular I’m using:
https://extraction.import.io
https://data.import.io/
Is it possible to add those URLs?
Many thanks
Dario
deleted-user-2024487
|
3
posts
|
Dec. 22, 2016, 1:17 p.m.
|
permalink
Hi Dario — if you’re getting a connection refused error, your code must be missing the proxy somehow — a failure due to something not being on the whitelist would give you the 403 forbidden error you got originally.
Could you post your proxy setup code?
giles
|
11190
posts
|
PythonAnywhere staff
|
Dec. 22, 2016, 10:08 p.m.
|
permalink
(If it’s not something you’d like to share publicly, you can email it to us at support@pythonanywhere.com)
giles
|
11190
posts
|
PythonAnywhere staff
|
Dec. 23, 2016, 1:55 p.m.
|
permalink
Hi Glen, I am also getting same error. did you find any silution for this error? If you found, please let me know
deleted-user-4816321
|
1
post
|
Nov. 24, 2018, 6:30 a.m.
|
permalink
See this explanation and do this after checking what you are trying to access isn’t on this
conrad
|
4233
posts
|
PythonAnywhere staff
|
Nov. 24, 2018, 11:46 a.m.
|
permalink
hi there,
i have also same problem, when I try to get an image from URL (eg: «https://api.twilio.com/2010-04-01/Accounts/AC86a729d2c869f0ad33c9bb7974ddcae7/Messages/MM566185e8df7eecc50475daf93d2e8094/Media/MEc39b6f6bb1faa2d362d68cbf61375010»)
I got an error like: <urlopen error Tunnel connection failed: 403 Forbidden>
code for that:
resp = urlopen(URL)
image = np.asarray(bytearray(resp.read()), dtype=»uint8″)
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
can u pls respond to this issue asap
I am working on my final yr project and I have 15 days left for this
so pls resolve my issue as fast
deleted-user-6962144
|
1
post
|
March 27, 2020, 6:22 p.m.
|
permalink
twilio is already on the whitelist
conrad
|
4233
posts
|
PythonAnywhere staff
|
March 28, 2020, 2:54 p.m.
|
permalink
Hello, i’m getting the same error when i try to access https://fundamentus.com.br, can someone help me how to implement some proxy to request or any other way? I’m using python 3.8
thanks in advance
deleted-user-8172843
|
1
post
|
Aug. 15, 2020, 1:45 a.m.
|
permalink
It’s not whitelisted for free users.
fjl
|
3651
posts
|
PythonAnywhere staff
|
Aug. 16, 2020, 11:37 a.m.
|
permalink
Hello, i’m getting the same error when i try to access https://ttsapi.almagu.com/.
yoror21631
|
6
posts
|
July 24, 2021, 9:06 p.m.
|
permalink
Free accounts have restricted Internet access — they can only make HTTP and HTTPS requests, and the sites that they access must be on the whitelist. We can add new sites to the whitelist if they have an official public API; if that site has one, please post a link to the API documentation.
giles
|
11190
posts
|
PythonAnywhere staff
|
July 25, 2021, 3:50 p.m.
|
permalink
Can I please ask to whitelist this website: https://api.nextbike.net/maps/nextbike-live.json ?
tuchlin
|
2
posts
|
Jan. 5, 2022, 7:55 p.m.
|
permalink
@tuchlin We can add new sites to the whitelist if they have an official public API; if that site has one, please post a link to the API documentation.
fjl
|
3651
posts
|
PythonAnywhere staff
|
Jan. 6, 2022, 10:47 a.m.
|
permalink
https://github.com/nextbike/api-doc
tuchlin
|
2
posts
|
Jan. 6, 2022, 12:13 p.m.
|
permalink
I don’t see a reference to api.nextbike.net there — could you send a link to a page that mentions that?
giles
|
11190
posts
|
PythonAnywhere staff
|
Jan. 6, 2022, 7:20 p.m.
|
permalink
Can you possibly white list this site https://bon.navarra.es/*

sploro
|
1
post
|
March 15, 2022, 11:40 p.m.
|
permalink
@sploro We can add new sites to the whitelist if they have an official public API; if that site has one, please post a link to the API documentation. BTW your account is a paid one, so you should not be affected by the whitelist limitations.
fjl
|
3651
posts
|
PythonAnywhere staff
|
March 16, 2022, 11:22 a.m.
|
permalink
Hi, I’m getting the same error with YouTube. Can it be added to the whitelist?
DailyMeme
|
1
post
|
July 15, 2022, 7:33 p.m.
|
permalink
_
30bits
|
10
posts
|
July 16, 2022, 3:53 a.m.
|
permalink
Exception Value: <urlopen error Tunnel connection failed: 403 Forbidden>
I’m getting the same error with many of the APIs that are already whitelisted. Earlier it was working well but now it is throwing errors like URLError or ProxyError
downtube
|
9
posts
|
July 16, 2022, 3:54 a.m.
|
permalink
Pytube is not whitelisted earlier it was but now it is throwing forbidden error.
Official documentation: https://pytube.io/en/latest/api.html
downtube
|
9
posts
|
July 16, 2022, 4:44 a.m.
|
permalink
ytmusicapi is also not whitelisted earlier it was.
Official documentation: https://ytmusicapi.readthedocs.io/en/latest/
downtube
|
9
posts
|
July 16, 2022, 7:02 a.m.
|
permalink
Hi all, sorry for the slow reply.
We only add sites to the whitelist if they (the sites themselves) have official documented public APIs. We don’t actively monitor them, though, so some sites can get whitelisted and then remain on the list even when they’re not hosting APIs.
However, someone recently started abusing PythonAnywhere by setting up tens of thousands of junk accounts with code to «watch» a YouTube video. That meant that we had to review our blanked whitelisting of YouTube.com, and we discovered that it no longer seems to have an API hosted there — its API is now at www.googleapis.com.
If there is a documented API that is on a different hostname, however, do let us know — we just need a link to its docs.
giles
|
11190
posts
|
PythonAnywhere staff
|
July 18, 2022, 4:35 p.m.
|
permalink
can u whitelist cassandra-driver please
ExLinked
|
1
post
|
Oct. 25, 2022, 12:38 a.m.
|
permalink
@ExLinked
Please note we need public api documentation stating the hostname for the endpoint. Please see the URL below for additional information in regards to whitelist requests:
https://help.pythonanywhere.com/pages/RequestingWhitelistAdditions/
Kabbie
|
31
posts
|
PythonAnywhere staff
|
Oct. 25, 2022, 10:57 a.m.
|
permalink
Checklist
- I’m reporting a broken site support
- I’ve verified that I’m running youtube-dl version 2019.06.08
- I’ve checked that all provided URLs are alive and playable in a browser
- I’ve checked that all URLs and arguments with special characters are properly quoted or escaped
- I’ve searched the bugtracker for similar issues including closed ones
Verbose log
$ youtube-dl -v --proxy=https://localhost:3128/ 'https://www.mylifetime.com/shows/married-at-first-sight/season-9/episode-0'[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: ['--restrict-filenames', '-o', '%(title)s-%(id)s-%(uploader)s.%(ext)s', '-w', '-v', '--proxy=https://localhost:3128/', 'https://www.mylifetime.com/shows/married-at-first-sight/season-9/episode-0']
[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2019.06.08
[debug] Python version 3.6.5 (CPython) - Linux-4.4.39-x86_64-Intel-R-_Core-TM-_i5
[debug] exe versions: ffmpeg 3.4.5, ffprobe 3.4.5, rtmpdump 2.4
[debug] Proxy map: {'http': 'https://localhost:3128/', 'https': 'https://localhost:3128/'}
[aenetworks] married-at-first-sight/season-9/episode-0: Downloading webpage
[aenetworks] 1533507139870: Downloading JSON metadata
ERROR: Unable to download JSON metadata: <urlopen error Tunnel connection failed: 403 Forbidden> (caused by URLError(OSError('Tunnel connection failed: 403 Forbidden',),))
File "/usr/lib64/python3.6/site-packages/youtube_dl/extractor/common.py", line 627, in _request_webpage
return self._downloader.urlopen(url_or_request)
File "/usr/lib64/python3.6/site-packages/youtube_dl/YoutubeDL.py", line 2227, in urlopen
return self._opener.open(req, timeout=self._socket_timeout)
File "/usr/lib64/python3.6/urllib/request.py", line 526, in open
response = self._open(req, data)
File "/usr/lib64/python3.6/urllib/request.py", line 544, in _open
'_open', req)
File "/usr/lib64/python3.6/urllib/request.py", line 504, in _call_chain
result = func(*args)
File "/usr/lib64/python3.6/urllib/request.py", line 806, in <lambda>
meth(r, proxy, type))
File "/usr/lib64/python3.6/site-packages/youtube_dl/utils.py", line 3679, in proxy_open
self, req, proxy, type)
File "/usr/lib64/python3.6/urllib/request.py", line 834, in proxy_open
return self.parent.open(req, timeout=req.timeout)
File "/usr/lib64/python3.6/urllib/request.py", line 526, in open
response = self._open(req, data)
File "/usr/lib64/python3.6/urllib/request.py", line 544, in _open
'_open', req)
File "/usr/lib64/python3.6/urllib/request.py", line 504, in _call_chain
result = func(*args)
File "/usr/lib64/python3.6/site-packages/youtube_dl/utils.py", line 1140, in https_open
req, **kwargs)
File "/usr/lib64/python3.6/urllib/request.py", line 1320, in do_open
raise URLError(err)
Description
I am not sure exactly what the problem is, but I did notice that the site now checks for private windows, and will not play videos in those («PRIVATE/INCOGNITO WINDOW DETECTED To watch videos on our site, please use a non-private window»).

-
Python
-
Парсинг
Добрый день.
Хотел развернуть парсер на Pythonanywhere, но возникла ошибка
urllib.error.URLError:
хотя на локальной машине все нормально работает
-
Вопрос заданболее трёх лет назад
-
346 просмотров
1
комментарий
-
urllib.error.URLError: <urlopen error Tunnel connection failed: 403 Forbidden>
Решения вопроса 1
Доступно только на платном аккаунте
Access to external internet sites
from your code e.g. urllib or wget
-
да, только что наткнулся на ответ от админов сайта.
Free accounts’ internet access goes via a proxy «whitelist». Here is the list of sites currently allowed:
https://www.pythonanywhere.com/whitelist/
We operate this to prevent malicious users from using our site to hack into and spam other websites. Paid-for accounts don’t have this limitation, because we can connect them to real people. Spammers and criminals prefer to be anonymous, so we figure they’re unlikely to sign up for paid accounts here.
Пригласить эксперта
Похожие вопросы
-
Показать ещё
Загружается…
10 февр. 2023, в 04:49
50000 руб./за проект
10 февр. 2023, в 02:20
3000 руб./за проект
10 февр. 2023, в 01:33
1500 руб./за проект
Минуточку внимания
process
| Status: | open | Resolution: | accepted |
|---|---|---|---|
| Dependencies: | Superseder: | ||
| Assigned To: | orsenthil | Nosy List: | Jessica Ridgley, alexey.namyotkin, b.a.scott, dieresys, martin.panter, mbeachy, orsenthil, ronaldoussoren, tsujikawa, vzafzal, yan12125 |
| Priority: | normal | Keywords: | patch |
Created on 2009-11-09 04:38 by tsujikawa, last changed 2022-04-11 14:56 by admin.
| Files | |||
|---|---|---|---|
| File name | Uploaded | Description | Edit |
| https_proxy_auth.patch |
tsujikawa, 2009-11-09 06:56 |
patch to send Proxy-Authorization header in CONNECT method(https proxy) |
review |
| urllib2_with_proxy_auth_comparison.py |
dieresys, 2009-12-23 22:16 |
||
| 2_7_x.patch |
mbeachy, 2011-02-19 17:23 |
2.7 maintenance branch patch |
review |
| monkey_2_6_4.py |
mbeachy, 2011-02-19 17:25 |
2.6.4 monkey patch | |
| urllib2_tests.tar.gz |
b.a.scott, 2011-02-21 11:09 |
Test code, results and instructions | |
| http_proxy_https.patch |
b.a.scott, 2011-02-21 11:19 |
Fix handling of 407 and 401 in urllib2 and httplib |
review |
| new_http_proxy_patch.py |
vzafzal, 2014-02-21 13:45 |
| Messages (24) | ||
|---|---|---|
| msg95058 — (view) | Author: Tatsuhiro Tsujikawa (tsujikawa) | Date: 2009-11-09 04:38 |
urllib2 cannot handle https with proxy requiring authorization.
After https_proxy is set correctly,
Python 2.6.4 (r264:75706, Oct 29 2009, 15:38:25)
[GCC 4.4.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import urllib2
>>> c=urllib2.urlopen("https://sourceforge.net")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python2.6/urllib2.py", line 124, in urlopen
return _opener.open(url, data, timeout)
File "/usr/lib/python2.6/urllib2.py", line 389, in open
response = self._open(req, data)
File "/usr/lib/python2.6/urllib2.py", line 407, in _open
'_open', req)
File "/usr/lib/python2.6/urllib2.py", line 367, in _call_chain
result = func(*args)
File "/usr/lib/python2.6/urllib2.py", line 1154, in https_open
return self.do_open(httplib.HTTPSConnection, req)
File "/usr/lib/python2.6/urllib2.py", line 1121, in do_open
raise URLError(err)
urllib2.URLError: <urlopen error Tunnel connection failed: 407 Proxy
Authentication Required>
This is because HTTPConnection::_tunnel() in httplib.py doesn't send
Proxy-Authorization header.
|
||
| msg95060 — (view) | Author: Tatsuhiro Tsujikawa (tsujikawa) | Date: 2009-11-09 06:56 |
I created a patch. I added additional argument 'headers' to HTTPConnection::set_tunnel() method, which is a mapping of HTTP headers to sent with CONNECT method. Since authorization credential is already set to Request object, in AbstractHTTPHandler::do_open(), if "Proxy-Authorization" header is found, pass it to set_tunnel(). It works fine for me. |
||
| msg95373 — (view) | Author: Ronald Oussoren (ronaldoussoren) *  |
Date: 2009-11-17 10:40 |
The patch looks good to me. IMHO this should be backported to 2.6 as well. |
||
| msg95377 — (view) | Author: Ronald Oussoren (ronaldoussoren) * |
Date: 2009-11-17 10:52 |
I've tested a backport of the patch to 2.6 (just replace set_proxy by _set_proxy in the patch) and the resulting version of urllib2 can login to the proxy (as expected). Thanks for the patch. |
||
| msg96659 — (view) | Author: Senthil Kumaran (orsenthil) * |
Date: 2009-12-20 06:05 |
Fixed and Committed revision 76908 in the trunk. |
||
| msg96660 — (view) | Author: Senthil Kumaran (orsenthil) * |
Date: 2009-12-20 07:22 |
Fixed through reversions r76908, r76909, r76910, r76911 Thanks for the patch, Tatsuhiro Tsujikawa. |
||
| msg96661 — (view) | Author: Senthil Kumaran (orsenthil) * |
Date: 2009-12-20 07:22 |
meant revisions. |
||
| msg96844 — (view) | Author: Manuel Muradás (dieresys) | Date: 2009-12-23 22:11 |
Hi! 2.6 backport is missing an argument in _set_tunnel definition. It
should be:
def _set_tunnel(self, host, port=None, headers=None):
|
||
| msg96845 — (view) | Author: Manuel Muradás (dieresys) | Date: 2009-12-23 22:16 |
The patch fixes only when you pass the authentication info in the proxy
handler's URL. Like:
proxy_handler = urllib2.ProxyHandler({'https':
'http://user:pass@proxy-example.com:3128/'})
But setting the authentication using a ProxyBasicAuthHandler is still
broken:
proxy_auth_handler = urllib2.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', 'proxy-example.com:3128',
'user', 'pass')
In the attached file (urllib2_with_proxy_auth_comparison.py) we've wrote
a comparison between what works with HTTP and HTTPS.
The problem is the 407 error never reaches the ProxyBasicAuthHandler
because HTTPConnection._tunnel raises an exception when the http
response status code is not 200.
|
||
| msg96846 — (view) | Author: Senthil Kumaran (orsenthil) * |
Date: 2009-12-24 00:53 |
Thanks for the note, Manuel. Fixed it in revision 77013. |
||
| msg100840 — (view) | Author: Senthil Kumaran (orsenthil) * |
Date: 2010-03-11 09:31 |
In this ticket, setting the authentication using a ProxyBasicAuthHandler is not yet addressed yet. (this was informed in the last note). Reopening this one to track it. |
||
| msg103090 — (view) | Author: Mike Beachy (mbeachy) | Date: 2010-04-13 23:11 |
I have worked up a monkey patch for urllib2/httplib for the issue of setting the authentication using a Proxy(Basic|Digest)AuthHandler. The basic approach was to create a new httplib exception (ProxyTunnelError) and raise that with the http response attached so that the HTTPSHandler can determine when 407 Proxy authentication required is present, and then reroute the urllib2.OpenerDirector to error handling mode. Unfortunately, there is a backwards compatibility issue - cases where a socket.error was previously being raised now get an ProxyTunnelError. Not that you could do much useful with the socket.error in the first place, but I suppose you could look for '407' in the text. Ugh. If you think this might prove useful, let me know and I can rework it into a real patch - just let me know what branch/version to base it off of. (My monkey patch is for python 2.6.4.) |
||
| msg128861 — (view) | Author: Mike Beachy (mbeachy) | Date: 2011-02-19 17:23 |
I've been in contact w/ Barry Scott offline re: the monkey patch previously mentioned. I'm attaching a 2.7 maintenance branch patch that he has needed to extend, and plans to follow up on. |
||
| msg128862 — (view) | Author: Mike Beachy (mbeachy) | Date: 2011-02-19 17:25 |
Attached to this comment (can you attach multiple files at once?) is the somewhat moldy 2.6.4 monkey patch, mercilessly ripped from my own code and probably not good for much. |
||
| msg128952 — (view) | Author: Barry Scott (b.a.scott) | Date: 2011-02-21 10:41 |
The attached patch builds on Mike's work. The core of the problem is that the Request object did not know what was going on. This means that it was not possible for get_authorization() to work for proxy-auth and www-auth. I change Request to know which of the four types of connection it represents. There are new methods on Request that return the right information based on the connection type. To understand how to make this work I needed to instrument the code. There is now a set_debuglevel on the OpenerDirector object that turns on debug in all the handlers and the director. I have added more debug messages to help understand this code. This code now passes the 72 test cases I run. I'll attach the code I used to test as a follow up to this. |
||
| msg128953 — (view) | Author: Barry Scott (b.a.scott) | Date: 2011-02-21 11:09 |
Attached is the code I used to test these changes. See the README.txt file for details include the results of a test run. |
||
| msg128955 — (view) | Author: Barry Scott (b.a.scott) | Date: 2011-02-21 11:19 |
I left out some white space changes to match the style of the std lib code. Re posting with white space cleanup. |
||
| msg211850 — (view) | Author: Vackar Afzal (vzafzal) | Date: 2014-02-21 11:40 |
I've found that for the Python2.6.x patch to play nicely with the popular rquests library, I've had to set some defaults on the modified __init__ function so that it reads as follows:
def __init__(self, *args, **kwargs):
_orig_init(self, *args, **kwargs)
self._tunnel_headers = {}
self._tunnel_host = ''
self._tunnel_port = ''
Also seems to work with python 2.6.1. Note: Change the entry condition to:
if os.environ.get('https_proxy', None) and sys.version_info[:2] == (2, 6) :
|
||
| msg211860 — (view) | Author: Vackar Afzal (vzafzal) | Date: 2014-02-21 13:45 |
Also needed to make another minor update to the monkey patch. Have uploaded the new files as new_http_proxy_patch.py for use with python 2.6.x |
||
| msg228406 — (view) | Author: Mark Lawrence (BreamoreBoy) * | Date: 2014-10-03 22:49 |
Is there any work still needed here? Surely the 2.6.x patches can't be applied unless there are security issues? |
||
| msg244513 — (view) | Author: Martin Panter (martin.panter) * |
Date: 2015-05-31 03:57 |
I believe this also affects Python 3; see Issue 24333. I think making the CONNECT response object available to the caller is the right general approach. But I really dislike raising an exception that holds a socket connection to be closed. (I know this is already done with urllib.error.HTTPError; let’s not repeat this in the “http.client” module!) Ideally, at the “http.client” level I would prefer to avoid all the special set_tunnel() calls, and use the usual request() and getresponse() API to make the CONNECT request. This way the response status and header fields would be available just like any other response. For this approach to work, we would probably need to add a new HTTPConnection.detach() method that released the original socket reader and writer, and add a way to create a new HTTPConnection instance using these socket objects. This enhancement probably wouldn’t be appropriate for Python 2 or a bug fix release. But it seems the cleanest approach to me, and may also allow using HTTPConnection with the Upgrade header (e.g. for opportunistic encryption, HTTP 2, Web etc), and proxying non-HTTP connections, as bonuses. A less revolutionary approach might be to add a HTTPSConnection.tunnel() method, that always returns the proxy’s response, but only does the SSL wrapping for a successful response. |
||
| msg247805 — (view) | Author: Martin Panter (martin.panter) * |
Date: 2015-08-01 10:14 |
For the record, a while ago I think I made a patch implementing my HTTPConnection.detach() proposal. I can probably dig it up if anyone is interested. However I gave up on fixing this bug in “urllib.request”. As far as I understand it, the framework does not distinguish the 407 Proxy Authentication Required error of the initial proxy CONNECT request from any potential 407 response from a tunnelled connection. Perhaps a special case could be made; I think there are already lots of special cases. But the maze of urlopen() handlers is already too complicated and I decided this was too hard to bother working on. Sorry :) |
||
| msg283306 — (view) | Author: (yan12125) * | Date: 2016-12-15 14:00 |
Modify target versions to bugfix and feature branches |
||
| msg374687 — (view) | Author: Alexey Namyotkin (alexey.namyotkin) * | Date: 2020-08-02 19:06 |
It has been 5 years, now the urllib3 is actively used, but it also inherited this problem: if no authentication data has been received, then the method _tunnel raises an exception OSError that does not contain response headers. Accordingly, this exception cannot be handled. And perhaps this is an obstacle to building a convenient system of authentication on a proxy server in a widely used library requests (it would be nice to be able to just provide an argument proxy_auth, similar to how it is done for server authorization). Now, if a user wants to send a https request through a proxy that requires complex authentication (Kerberos, NTLM, Digest, other) using the urllib3, he must first send a separate request to the proxy, receive a response, extract the necessary data to form the header Proxy-Authorization, then generate this header and pass it to the ProxyManager. And if we are talking about Requests, then the situation there is worse, because you cannot pass proxy headers directly (https://github.com/psf/requests/issues/2708). If we were to aim to simplify the authentication procedure on the proxy server for the user, then where would we start, do we need to change the http.client so that the error returned by the method _tunnel contains headers? Or maybe it's not worth changing anything at all and the path with preliminary preparation by user of the header Proxy-Authorization is the only correct one? Martin Panter, could you also give your opinion? Thank you in advance. |
| History | |||
|---|---|---|---|
| Date | User | Action | Args |
| 2022-04-11 14:56:54 | admin | set | github: 51540 |
| 2020-08-02 19:06:17 | alexey.namyotkin | set | messages: + msg374687 |
| 2020-07-29 15:36:59 | Jessica Ridgley | set | nosy: + Jessica Ridgley versions: |
| 2020-07-29 14:46:07 | alexey.namyotkin | set | nosy: + alexey.namyotkin |
| 2016-12-15 14:58:30 | BreamoreBoy | set | nosy: — BreamoreBoy |
| 2016-12-15 14:00:36 | yan12125 | set | messages: + msg283306 versions: + Python 3.7, — Python 2.6, Python 3.4 |
| 2015-12-11 07:25:49 | yan12125 | set | nosy: + yan12125 |
| 2015-08-01 10:14:33 | martin.panter | set | messages: + msg247805 stage: needs patch |
| 2015-05-31 04:00:10 | martin.panter | link | issue24333 superseder |
| 2015-05-31 03:57:45 | martin.panter | set | nosy: + martin.panter messages: |
| 2014-10-03 22:49:46 | BreamoreBoy | set | nosy: + BreamoreBoy messages: + msg228406 |
| 2014-02-21 13:45:45 | vzafzal | set | files: + new_http_proxy_patch.py messages: |
| 2014-02-21 11:40:19 | vzafzal | set | nosy: + vzafzal messages: + msg211850 |
| 2011-02-21 11:19:31 | b.a.scott | set | files: — http_proxy_https.patch nosy: ronaldoussoren, orsenthil, mbeachy, dieresys, tsujikawa, b.a.scott |
| 2011-02-21 11:19:23 | b.a.scott | set | files: + http_proxy_https.patch nosy: ronaldoussoren, orsenthil, mbeachy, dieresys, tsujikawa, b.a.scott messages: + msg128955 |
| 2011-02-21 11:09:42 | b.a.scott | set | files: + urllib2_tests.tar.gz nosy: ronaldoussoren, orsenthil, mbeachy, dieresys, tsujikawa, b.a.scott messages: + msg128953 |
| 2011-02-21 10:41:27 | b.a.scott | set | files: + http_proxy_https.patch nosy: + b.a.scott messages: + msg128952 |
| 2011-02-19 17:25:17 | mbeachy | set | files: + monkey_2_6_4.py nosy: ronaldoussoren, orsenthil, mbeachy, dieresys, tsujikawa messages: + msg128862 |
| 2011-02-19 17:23:26 | mbeachy | set | files: + 2_7_x.patch nosy: ronaldoussoren, orsenthil, mbeachy, dieresys, tsujikawa messages: + msg128861 |
| 2010-04-13 23:11:40 | mbeachy | set | nosy: + mbeachy messages: + msg103090 |
| 2010-03-11 09:31:44 | orsenthil | set | status: closed -> open resolution: fixed -> accepted messages: + msg100840 |
| 2010-02-22 16:13:43 | flox | link | issue7986 superseder |
| 2009-12-24 00:53:30 | orsenthil | set | messages: + msg96846 |
| 2009-12-23 22:16:00 | dieresys | set | files: + urllib2_with_proxy_auth_comparison.py messages: |
| 2009-12-23 22:11:04 | dieresys | set | nosy: + dieresys messages: + msg96844 |
| 2009-12-20 07:22:49 | orsenthil | set | messages: + msg96661 |
| 2009-12-20 07:22:10 | orsenthil | set | status: open -> closed
messages: |
| 2009-12-20 06:06:00 | orsenthil | set | keywords: — needs review resolution: accepted -> fixed messages: + msg96659 |
| 2009-11-17 10:52:27 | ronaldoussoren | set | messages: + msg95377 |
| 2009-11-17 10:40:36 | ronaldoussoren | set | keywords: + needs review nosy: + ronaldoussoren messages: + msg95373 |
| 2009-11-15 09:21:35 | orsenthil | set | assignee: orsenthil
resolution: accepted |
| 2009-11-11 01:06:09 | tsujikawa | set | versions: + Python 2.7 |
| 2009-11-09 06:56:13 | tsujikawa | set | files: + https_proxy_auth.patch keywords: + patch messages: + msg95060 |
| 2009-11-09 04:38:16 | tsujikawa | create |
- Remove From My Forums
-
Question
-
Despite https://notebooks.azure.com/faq notebooks.azure.com python 3 fails to read external URL resources. Here are examples
import requests
url = «https://onlinecourses.science.psu.edu/stat501/sites/onlinecourses.science.psu.edu.stat501/files/data/birthsmokers.txt»
requests.get(url)=>
ProxyError: HTTPSConnectionPool(host='onlinecourses.science.psu.edu', port=443): Max retries exceeded with url: /stat501/sites/onlinecourses.science.psu.edu.stat501/files/data/birthsmokers.txt (Caused by ProxyError('Cannot connect to proxy.', OSError('Tunnel connection failed: 403 Forbidden',)))
import urllib.request as request
url = "https://onlinecourses.science.psu.edu/stat501/sites/onlinecourses.science.psu.edu.stat501/files/data/birthsmokers.txt"
request.urlopen(url).read()=>
URLError: <urlopen error Tunnel connection failed: 403 Forbidden>
import pandas
pandas.read_csv("https://onlinecourses.science.psu.edu/stat501/sites/onlinecourses.science.psu.edu.stat501/files/data/birthsmokers.txt")=>
OSError: Tunnel connection failed: 403 Forbidden
With other urls the error differs.
Answers
-
jandersonlee,
It is hard to find this information, as Jupyter notebooks documentation on AML is scattered and limited. From: https://blogs.technet.microsoft.com/machinelearning/2016/03/30/jupyter-notebooks-with-r-in-azure-ml-studio-2/:
Access to external internet sites is restricted. However, we have white
listed a number of important URLs:- All CRAN mirrors are on the white list, so you should be able to install packages using your favorite CRAN mirror.
- Github is also white listed, meaning you can use devtools::install_github() to install packages that are not on CRAN, or get the development version of a package.
Preview Limitations
The following limitation currently exist and will likely be changed in the future:
-
Network access is limited to Azure (with the exception of the white listed sites
mentioned above). You can place your data in various stores in Azure and access them in Python (Azure SDK) or Azure ML Studio.
Regards,
-
Proposed as answer by
Friday, March 3, 2017 2:45 PM
-
Marked as answer by
neerajkh_MSFT
Friday, March 10, 2017 6:21 AM
Hi all,
I wrote a small script to get some data from an API, which works fine in jupyter notebook on my laptop: https://imgur.com/a/yzzSbHI
However, when I try to run the same script in pythonanywhere.com’s console, I get the following error:
>>> from requests import get
>>>
>>> #url = ‘https://rsbuddy.com/exchange/names.json’
… url = ‘https://rsbuddy.com/exchange/summary.json’
>>> data = get(url).json()
Traceback (most recent call last):
File «/usr/lib/python3.7/site-packages/urllib3/connectionpool.py», line 594, in urlopen
self._prepare_proxy(conn)
File «/usr/lib/python3.7/site-packages/urllib3/connectionpool.py», line 815, in _prepare_proxy
conn.connect()
File «/usr/lib/python3.7/site-packages/urllib3/connection.py», line 324, in connect
self._tunnel()
File «/usr/lib/python3.7/http/client.py», line 911, in _tunnel
message.strip()))
OSError: Tunnel connection failed: 403 Forbidden
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «/usr/lib/python3.7/site-packages/requests/adapters.py», line 445, in send
timeout=timeout
File «/usr/lib/python3.7/site-packages/urllib3/connectionpool.py», line 638, in urlopen
_stacktrace=sys.exc_info()[2])
File «/usr/lib/python3.7/site-packages/urllib3/util/retry.py», line 398, in increment
raise MaxRetryError(_pool, url, error or ResponseError(cause))
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host=’rsbuddy.com’, port=443): Max retries exceeded with url: /exchange/summary.json (Caused b
y ProxyError(‘Cannot connect to proxy.’, OSError(‘Tunnel connection failed: 403 Forbidden’)))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «<stdin>», line 1, in <module>
File «/usr/lib/python3.7/site-packages/requests/api.py», line 72, in get
return request(‘get’, url, params=params, **kwargs)
File «/usr/lib/python3.7/site-packages/requests/api.py», line 58, in request
return session.request(method=method, url=url, **kwargs)
File «/usr/lib/python3.7/site-packages/requests/sessions.py», line 512, in request
resp = self.send(prep, **send_kwargs)
File «/usr/lib/python3.7/site-packages/requests/sessions.py», line 622, in send
r = adapter.send(request, **kwargs)
File «/usr/lib/python3.7/site-packages/requests/adapters.py», line 507, in send
raise ProxyError(e, request=request)
requests.exceptions.ProxyError: HTTPSConnectionPool(host=’rsbuddy.com’, port=443): Max retries exceeded with url: /exchange/summary.json (Caused by
ProxyError(‘Cannot connect to proxy.’, OSError(‘Tunnel connection failed: 403 Forbidden’)))
I honestly don’t know what to make of this.. Any help would be appreciated!