Раздел
2 Статистические гипотезы и их проверка
Лекция
№ 5
Тема:
общие
принципы проверки статистических
гипотез.
План:
1.Понятие статистической гипотезы.
Ошибки I
и II
рода.
2.Критерий
оценки статистических гипотез. Уровень
значимости.
Понятие
статистической гипотезы. Ошибки I
и II
рода.
Статистической
гипотезой
называется предположение о том, что
распределение случайной величины
(результата эксперимента) подчиняется
определённому закону распределения.
Статистический
критерий
(или критерий оценки статистической
гипотезы) -это проверка, позволяющая
оценить, насколько статистическая
гипотеза согласуется с экспериментальными
данными.
Пусть
в нашем распоряжении имеется величина
х
– одно из возможных значений случайной
величины (результата эксперимента).
Выдвинем
гипотезу о том, что случайная величина
х
распределена по закону, задаваемому
функцией плотности вероятности φ0(х).
Гипотезу обозначим как Н0
и назовем нуль гипотезой.
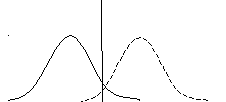
φ(х)
φ0(х) φ1(х)
—
х х
Введём
также некоторую альтернативную гипотезу
Н1,
содержание которой состоит в том, что
рассматриваемая случайная величина х
подчиняется закону распределения,
описываемого функцией плотности
вероятности φ1(х).
Будем считать, что гипотеза Н1
является
истинной, если нуль-гипотеза Н0
не
верна. Требуется на основании распределения
величины х
решить, какой из гипотез Н0
или Н1
следует
отдать предпочтение. Решение поставленной
задачи может быть как верным, так и
ложным.
Неправильное
решение может быть двух родов:
-
Ошибка
первого рода – не
принять нуль-гипотезу, когда она в
действительности верна, (т.е принять
Н1
вместо
Н0).
α
– это вероятность совершить ошибку I
рода
(или риск) – показывает какова вероятность
отбросить верные (истинные) результаты. -
Ошибка
второго рода – принять
нуль-гипотезу, когда она не верна (т.е.
принять Н0
вместо
Н1
).
β
– это вероятность совершить ошибку
второго рода. Показывает какова
вероятность принять неверные (ложные)
результаты.
Тогда,
α уменьшается, β увеличивается, а (1–β)
уменьшается. Т.е. α уменьшается
(вероятность не принять Н0,
когда она верна) следовательно (1- β)
уменьшается (вероятность не принять,
когда Н0
не
верна).
Поэтому,
для принятия проверяемой гипотезы
вероятность совершить ошибку I
рода α должна быть не самой низкой, а
оптимальной.
Для
выбора величины α существуют определённые
правила (критерии), которые позволяют
оценить насколько верно проверяемая
гипотеза описывает экспериментальные
данные.
Критерии
оценки статистических гипотез при
обработке результатов эксперимента
Рассмотрим
критерии оценки гипотезы Н0
(т.е.
верна она или нет) для случайной величины
х
(т.е. для результата эксперимента). Пусть
гипотеза Н0
верна
и
состоит
в том, что рассматриваемая случайная
величина х
действительно распределена по закону,
задаваемому функцией φ0(х).
Однако, если х
попало
в область, расположенную вблизи правого
или левого «хвоста» функции φ0(х),
то вероятность попадания случайной
величины в эту область, вычисляется при
помощи функции φ0(х)
мала и приближается к нулю. Поэтому
проще и целесообразнее признать
ошибочность гипотезы и не принять её в
этой область. Тогда эта область будет
характеризоваться α — вероятностью не
принять гипотезу Н0
, когда она в действительности верна.

φ0(х)
α/2
Р=1 – α α/2
х1 х2
х
критическая
область доверительный
интервал критическая
область
-
Назовём
интервал значений случайной величины
х,
т.е
отрезок оси абсцисс, расположенный
вблизи «хвоста» функции φ0(х)
критической
областью
данной функции распределения. -
Значения
случайной величины х1
и х2,
отделяющих критические области,
называются критическими
значениями данной
функции распределения. -
Размеры
критической области определяются
вероятностью попадания в неё случайных
величин. Вероятность попадания значений
х
случайной величины в критическую
область получила название уровень
значимости критерия оценки статистической
гипотезы или
просто уровень
значимости
р.
Видно, что
р=α
или р=1–Р
Уровень
значимости (риск)
– это вероятность отвергнуть проверяемую
гипотезу Н0,
когда она в действительности верна.
Проще говоря р
– это вероятность отбросить верные
результаты.
Критерием
оценки статистической гипотезы является
попадание хi
в
критическую область. Если случайная
величина
х
не попадает в критическую область, то
анализируемая гипотеза считается
приемлемой.
Если случайная величина
х попадает
в критическую область, то это свидетельствует
о неприемлемости
анализируемой
гипотезы.
Если
критическая область, попадание в которую
значений х
случайной величины, целиком расположена
в правой (или левой) части графика φ0(х),
то критерий оценки статистической
гипотезы называется односторонним.
В случае одностороннего критерия уровень
значимости равен α=р=(1
–Р).

 φ0(х) φ0(х)
φ0(х) φ0(х)
или
В
противном случае критическую область
необходимо рассматривать из двух частей,
а соответственный критерий называется
двухсторонним.
В случае двухстороннего критерия α=р=(1
–Р)/2.
φ0(х)
α=р=(1
–Р)/2 α=р=(1 –Р)/2
0 х
Односторонний
критерий используют только в том случае,
если экспериментатор заранее знает,
что результаты опытов не попадают в
противоположную часть (область) функции,
или для него это будет иметь практическое
значение.
Пример
1:
![]()
 φ0(х)
φ0(х)
α=р=1-Р
 +Wвлаги
+Wвлаги
—
х 0 х
Пример
2: Д окрашивание раствора
-0,16;
0,16; 0,17;…
-0,16
не имеет практического значения, т.к.
раствор мутный и луч не проходит через
раствор – результат не верен.



α=р=(1-Р)/2
0
Принять
проверяемую гипотезу можно только при
определённых значениях р. Критерии
принятия статистической гипотезы:
-
Если
значения уровня значимости р равно 5%
и более, то проверяемую гипотезу следует
признать согласующейся с полученными
экспериментальными данными. В этом
случае различия между гипотетическими
экспериментальными данными являются
статистически незначимым.
р≥0,05
-
Если
уровень значимости менее 5%, но более
1%, то можно пойти на риск принятия
проверяемой гипотезы, либо взять
гипотезу под сомнение. Различие между
гипотетическими и экспериментальными
данными является спорным. Для уточнения
выводов следует признать целесообразным
повторение эксперимента
0,01<p<0,05
-
Если
значение критерия значимости составляет
1% и менее, то проверяемая гипотеза
отбрасывается. Различия между
гипотетическими и экспериментальными
данными являются статистически
значимыми.
р≤0,01
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Материал из MachineLearning.
Перейти к: навигация, поиск
Содержание
- 1 Стандартная методика проверки статистических гипотез
- 2 Вычисление пи-величины
- 3 Вычисление ROC-кривой
- 4 Литература
- 5 См. также
- 6 Ссылки
Уровень значимости статистического теста — допустимая для данной задачи вероятность ошибки первого рода (ложноположительного решения, false positive), то есть вероятность отклонить нулевую гипотезу, когда на самом деле она верна.
Другая интерпретация:
уровень значимости — это такое (достаточно малое) значение вероятности события, при котором событие уже можно считать неслучайным.
Уровень значимости обычно обозначают греческой буквой  (альфа).
(альфа).
Стандартная методика проверки статистических гипотез
В стандартной методике проверки статистических гипотез уровень значимости фиксируется заранее, до того, как становится известной выборка
.
Чрезмерное уменьшение уровня значимости (вероятности ошибки первого рода) может привести к увеличению вероятности ошибки второго рода, то есть вероятности принять нулевую гипотезу, когда на самом деле она не верна (это называется ложноотрицательным решением, false negative).
Вероятность ошибки второго рода связана с мощностью критерия простым соотношением .
Выбор уровня значимости требует компромисса между значимостью и мощностью или
(что то же самое, но другими словами)
между вероятностями ошибок первого и второго рода.
Обычно рекомендуется выбирать уровень значимости из априорных соображений.
Однако на практике не вполне ясно, какими именно соображениями надо руководствоваться,
и выбор часто сводится к назначению одного из популярных вариантов
.
В докомпьютерную эпоху эта стандартизация позволяла сократить объём справочных статистических таблиц.
Теперь нет никаких специальных причин для выбора именно этих значений.
Существует две альтернативные методики, не требующие априорного назначения .
Вычисление пи-величины
Достигаемый уровень значимости или пи-величина (p-value) — это наименьшая величина уровня значимости,
при которой нулевая гипотеза отвергается для данного значения статистики критерия .
где
— критическая область критерия.
Другая интерпретация:
достигаемый уровень значимости или пи-величина — это вероятность, с которой (при условии истинности нулевой гипотезы) могла бы реализоваться наблюдаемая выборка, или любая другая выборка с ещё менее вероятным значением статистики .
Случайная величина имеет равномерное распределение.
Фактически, функция приводит значение статистики критерия к шкале вероятности.
Маловероятным значениям (хвостам распределения) статистики соотвествуют значения , близкие к нулю или к единице.
Вычислив значение на заданной выборке ,
статистик имеет возможность решить,
является ли это значение достаточно малым, чтобы отвергнуть нулевую гипотезу.
Данная методика является более гибкой, чем стандартная.
В частности, она допускает «нестандартное решение» — продолжить наблюдения, увеличивая объём выборки, если оценка вероятности ошибки первого рода попадает в зону неуверенности, скажем, в отрезок .
Вычисление ROC-кривой
ROC-кривая (receiver operating characteristic) — это зависимость мощности от уровня значимости .
Методика предполагает, что статистик укажет подходящую точку на ROC-кривой, которая соответствует компромиссу между вероятностями ошибок I и II рода.
Литература
- Кобзарь А. И. Прикладная математическая статистика. Справочник для инженеров и научных работников. — М.: Физматлит, 2006.
- Цейтлин Н. А. Из опыта аналитического статистика. — М.: Солар, 2006. — 905 с.
- Алимов Ю. И. Альтернатива методу математической статистики. — М.: Знание, 1980.
См. также
- Проверка статистических гипотез — о стандартной методике проверки статистических гипотез.
- Достигаемый уровень значимости, синонимы: пи-величина, p-Value.
Ссылки
- P-value — статья в англоязычной Википедии.
- ROC curve — статья в англоязычной Википедии.
Проверка статистических гипотез
- Понятие о статистической гипотезе
- Уровень значимости при проверке гипотезы
- Критическая область
- Простая гипотеза и критерии согласия
- Критерий согласия (X^2) Пирсона
- Примеры
п.1. Понятие о статистической гипотезе
Статистическая гипотеза – это предположение о виде распределения и свойствах случайной величины в наблюдаемой выборке данных.
Прежде всего, мы формулируем «рабочую» гипотезу. Желательно это делать не на основе полученных данных, а исходя из природы и свойств исследуемого явления.
Затем формулируется нулевая гипотеза (H_0), отвергающая нашу рабочую гипотезу.
Наша рабочая гипотеза при этом называется альтернативной гипотезой (H_1).
Получаем, что (H_0=overline{H_1}), т.е. нулевая и альтернативная гипотеза вместе составляют полную группу несовместных событий.
Основной принцип проверки гипотезы – доказательство «от противного», т.е. опровергнуть гипотезу (H_0) и тем самым доказать гипотезу (H_1).
В результате проверки гипотезы возможны 4 исхода:
| Верная гипотеза | |||
| (H_0) | (H_1) | ||
| Принятая гипотеза | (H_0) | True Negative (H_0) принята верно |
False Negative (H_0) принята неверно Ошибка 2-го рода |
| (H_1) | False Positive (H_0) отвергнута неверно (H_1) принята неверно Ошибка 1-го рода |
True Positive (H_0) отвергнута верно (H_1) принята верно |
Ошибка 1-го рода – «ложная тревога».
Ошибка 2-го рода – «пропуск события».
Например:
К врачу обращается человек с некоторой жалобой.
Гипотеза (H_1) — человек болен, гипотеза (H_0) — человек здоров.
True Negative – здорового человека признают здоровым
True Positive – больного человека признают больным
False Positive – здорового человека признают больным – «ложная тревога»
False Negative – больного человека признают здоровым – «пропуск события»
Уровень значимости при проверке гипотезы
Статистический тест (статистический критерий) – это строгое математическое правило, по которому гипотеза принимается или отвергается.
В статистике разработано множество критериев: критерии согласия, критерии нормальности, критерии сдвига, критерии выбросов и т.д.
Уровень значимости – это пороговая (критическая) вероятность ошибки 1-го рода, т.е. непринятия гипотезы (H_0), когда она верна («ложная тревога»).
Требуемый уровень значимости α задает критическое значение для статистического теста.
Например:
Уровень значимости α=0,05 означает, что допускается не более чем 5%-ая вероятность ошибки.
В результате статистического теста на конкретных данных получают эмпирический уровень значимости p. Чем меньше значение p, тем сильнее аргументы против гипотезы (H_0).
Обобщив практический опыт, можно сформулировать следующие рекомендации для оценки p и выбора критического значения α:
| Уровень значимости (p) |
Решение о гипотезе (H_0) | Вывод для гипотезы (H_1) |
| (pgt 0,1) | (H_0) не может быть отклонена | Статистически достоверные доказательства не обнаружены |
| (0,5lt pleq 0,1) | Истинность (H_0) сомнительна, неопределенность | Доказательства обнаружены на уровне статистической тенденции |
| (0,01lt pleq 0,05) | Отклонение (H_0), значимость | Обнаружены статистически достоверные (значимые) доказательства |
| (pleq 0,01) | Отклонение (H_0), высокая значимость | Доказательства обнаружены на высоком уровне значимости |
Здесь под «доказательствами» мы понимаем результаты наблюдений, свидетельствующие в пользу гипотезы (H_1).
Традиционно уровень значимости α=0,05 выбирается для небольших выборок, в которых велика вероятность ошибки 2-го рода. Для выборок с (ngeq 100) критический уровень снижают до α=0,01.
п.3. Критическая область
Критическая область – область выборочного пространства, при попадании в которую нулевая гипотеза отклоняется.
Требуемый уровень значимости α, который задается исследователем, определяет границу попадания в критическую область при верной нулевой гипотезе.
Различают 3 вида критических областей
Критическая область на чертежах заштрихована.
(K_{кр}=chi_{f(alpha)}) определяют границы критической области в зависимости от α.
Если эмпирическое значение критерия попадает в критическую область, гипотезу (H_0) отклоняют.
Пусть (K*) — эмпирическое значение критерия. Тогда:
(|K|gt K_{кр}) – гипотеза (H_0) отклоняется
(|K|leq K_{кр}) – гипотеза (H_0) не отклоняется
п.4. Простая гипотеза и критерии согласия
Пусть (x=left{x_1,x_2,…,x_nright}) – случайная выборка n объектов из множества (X), соответствующая неизвестной функции распределения (F(t)).
Простая гипотеза состоит в предположении, что неизвестная функция (F(t)) является совершенно конкретным вероятностным распределением на множестве (X).
Например: 
Глядя на полученные данные эксперимента (синие точки), можно выдвинуть следующую простую гипотезу:
(H_0): данные являются выборкой из равномерного распределения на отрезке [-1;1]
Критерий согласия проверяет, согласуется ли заданная выборка с заданным распределением или с другой выборкой.
К критериям согласия относятся:
- Критерий Колмогорова-Смирнова;
- Критерий (X^2) Пирсона;
- Критерий (omega^2) Смирнова-Крамера-фон Мизеса
п.5. Критерий согласия (X^2) Пирсона
Пусть (left{t_1,t_2,…,t_nright}) — независимые случайные величины, подчиняющиеся стандартному нормальному распределению N(0;1) (см. §63 данного справочника)
Тогда сумма квадратов этих величин: $$ x=t_1^2+t_2^2+⋯+t_n^2 $$ является случайной величиной, которая имеет распределение (X^2) с n степенями свободы.
График плотности распределения (X^2) при разных n имеет вид: 
С увеличением n распределение (X^2) стремится к нормальному (согласно центральной предельной теореме – см. §64 данного справочника).
Если мы:
1) выдвигаем простую гипотезу (H_0) о том, что полученные данные являются выборкой из некоторого закона распределения (f(x));
2) выбираем в качестве теста проверки гипотезы (H_0) критерий Пирсона, —
тогда определение критической области будет основано на распределении (X^2).
Заметим, что выдвижение основной гипотезы в качестве (H_0) при проведении этого теста исторически сложилось.
В этом случае критическая область правосторонняя.
Мы задаем уровень значимости α и находим критическое значение
(X_{кр}^2=X^2(alpha,k-r-1)), где k — число вариант в исследуемом ряду, r – число параметров предполагаемого распределения.
Для этого есть специальные таблицы.
Или используем функцию ХИ2ОБР(α,k-r-1) в MS Excel (она сразу считает нужный нам правый хвост). Например, при r=0 (для равномерного распределения):
Пусть нам дан вариационный ряд с экспериментальными частотами (f_i, i=overline{1,k}).
Пусть наша гипотеза (H_0) –данные являются выборкой из закона распределения с известной плотностью распределения (p(x)).
Тогда соответствующие «теоретические частоты» (m_i=Ap(x_i)), где (x_i) – значения вариант данного ряда, A – коэффициент, который в общем случае зависит от ряда (дискретный или непрерывный).
Находим значение статистического теста: $$ X_e^2=sum_{j=1}^kfrac{(f_i-m_i)^2}{m_i} $$ Если эмпирическое значение (X_e^2) окажется в критической области, гипотеза (H_0) отвергается.
(X_e^2geq X_{кр}^2) — закон распределения не подходит (гипотеза (H_0) не принимается)
(X_e^2lt X_{кр}^2) — закон распределения подходит (гипотеза (H_0) принимается)
Например:
В эксперименте 60 раз подбрасывают игральный кубик и получают следующие результаты:
| Очки, (x_i) | 1 | 2 | 3 | 4 | 5 | 6 |
| Частота, (f_i) | 8 | 12 | 13 | 7 | 12 | 8 |
Не является ли кубик фальшивым?
Если кубик не фальшивый, то справедлива гипотеза (H_0) — частота выпадений очков подчиняется равномерному распределению: $$ p_i=frac16, i=overline{1,6} $$ При N=60 экспериментах каждая сторона теоретически должна выпасть: $$ m_i=p_icdot N=frac16cdot 60=10 $$ по 10 раз.
Строим расчетную таблицу:
| (x_i) | 1 | 2 | 3 | 4 | 5 | 6 | ∑ |
| (f_i) | 8 | 12 | 13 | 7 | 12 | 8 | 60 |
| (m_i) | 10 | 10 | 10 | 10 | 10 | 10 | 60 |
| (f_i-m_i) | -2 | 2 | 3 | -3 | 2 | -2 | — |
| (frac{(f_i-m_i)^2}{m_i}) | 0,4 | 0,4 | 0,9 | 0,9 | 0,4 | 0,4 | 3,4 |
Значение теста: $$ X_e^2=3,4 $$ Для уровня значимости α=0,05, k=6 и r=0 находим критическое значение: $$ X_{кр}^2approx 11,1 $$ Получается, что: $$ X_e^2lt X_{кр}^2 $$ На уровне значимости α=0,05 принимается гипотеза (H_0) про равномерное распределение.
$$ X_{кр}^2approx 11,1 $$ Получается, что: $$ X_e^2lt X_{кр}^2 $$ На уровне значимости α=0,05 принимается гипотеза (H_0) про равномерное распределение.
Значит, с вероятностью 95% кубик не фальшивый.
п.6. Примеры
Пример 1. В эксперименте 72 раза подбрасывают игральный кубик и получают следующие результаты:
| Очки, (x_i) | 1 | 2 | 3 | 4 | 5 | 6 |
| Частота, (f_i) | 8 | 12 | 13 | 7 | 10 | 22 |
Не является ли кубик фальшивым?
Если кубик не фальшивый, то справедлива гипотеза (H_0) — частота выпадений очков подчиняется равномерному распределению: $$ p_i=frac16, i=overline{1,6} $$ При N=72 экспериментах каждая сторона теоретически должна выпасть: $$ m_i=p_icdot N=frac16cdot 72=12 $$ по 12 раз.
Строим расчетную таблицу:
| (x_i) | 1 | 2 | 3 | 4 | 5 | 6 | ∑ |
| (f_i) | 8 | 12 | 13 | 7 | 10 | 22 | 72 |
| (m_i) | 12 | 12 | 12 | 12 | 12 | 12 | 72 |
| (f_i-m_i) | -4 | 0 | 1 | -5 | -2 | 10 | — |
| (frac{(f_i-m_i)^2}{m_i}) | 1,333 | 0,000 | 0,083 | 2,083 | 0,333 | 8,333 | 12,167 |
Значение теста: $$ X_e^2=12,167 $$ Для уровня значимости α=0,05, k=6 и r=0 находим критическое значение: $$ X_{кр}^2approx 11,1 $$ Получается, что: $$ X_e^2gt X_{кр}^2 $$ На уровне значимости α=0,05 гипотеза (H_0) про равномерное распределение не принимается.
$$ X_{кр}^2approx 11,1 $$ Получается, что: $$ X_e^2gt X_{кр}^2 $$ На уровне значимости α=0,05 гипотеза (H_0) про равномерное распределение не принимается.
Значит, с вероятностью 95% кубик фальшивый.
Пример 2. Во время Второй мировой войны Лондон подвергался частым бомбардировкам. Чтобы улучшить организацию обороны, город разделили на 576 прямоугольных участков, 24 ряда по 24 прямоугольника.
В течение некоторого времени были получены следующие данные по количеству попаданий на участки:
| Число попаданий, (x_i) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Количество участков, (f_i) | 229 | 211 | 93 | 35 | 7 | 0 | 0 | 1 |
Проверялась гипотеза (H_0) — стрельба случайна.
Если стрельба случайна, то попадание на участок должно иметь распределение, подчиняющееся «закону редких событий» — закону Пуассона с плотностью вероятности: $$ p(k)=frac{lambda^k}{k!}e^{-lambda} $$ где (k) — число попаданий. Чтобы получить значение (lambda), нужно посчитать математическое ожидание данного распределения.
Составим расчетную таблицу:
| (x_i) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ∑ |
| (f_i) | 229 | 211 | 93 | 35 | 7 | 0 | 0 | 1 | 576 |
| (x_if_i) | 0 | 211 | 186 | 105 | 28 | 0 | 0 | 7 | 537 |
$$ lambdaapprox M(x)=frac{sum x_if_i}{N}=frac{537}{576}approx 0,932 $$ Тогда теоретические частоты будут равны: $$ m_i=Ncdot p(k) $$ Получаем:
| (x_i) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ∑ |
| (f_i) | 229 | 211 | 93 | 35 | 7 | 0 | 0 | 1 | 576 |
| (p_i) | 0,39365 | 0,36700 | 0,17107 | 0,05316 | 0,01239 | 0,00231 | 0,00036 | 0,00005 | 0,99999 |
| (m_i) | 226,7 | 211,4 | 98,5 | 30,6 | 7,1 | 1,3 | 0,2 | 0,0 | 576,0 |
| (f_i-m_i) | 2,3 | -0,4 | -5,5 | 4,4 | -0,1 | -1,3 | -0,2 | 1,0 | — |
| (frac{(f_i-m_i)^2}{m_i}) (результат) | 0,02 | 0,00 | 0,31 | 0,63 | 0,00 | 1,33 | 0,21 | 34,34 | 36,84 |
Значение теста: (X_e^2=36,84)
Поскольку в ходе исследования мы нашли оценку для λ через подсчет выборочной средней, нужно уменьшить число степеней свободы на r=1, и критическое значение статистики искать для (X_{кр}^2=X^2(alpha,k-2)).
Для уровня значимости α=0,05 и k=8, r=1 находим:
(X_{кр}^2approx 12,59)
Получается, что: (X_e^2gt X_{кр}^2)
Гипотеза (H_0) не принимается.
Стрельба не случайна.
Пример 3. В предыдущем примере объединили события x={4;5;6;7} с редким числом попаданий:
| Число попаданий, (x_i) | 0 | 1 | 2 | 3 | 4-7 |
| Количество участков, (f_i) | 229 | 211 | 93 | 35 | 8 |
Проверялась гипотеза (H_0) — стрельба случайна.
Для последней объединенной варианты находим среднюю взвешенную: $$ x_5=frac{4cdot 7+5cdot 0+6cdot 0+7cdot 1}{7+1}=4,375 $$ Найдем оценку λ.
| (x_i) | 0 | 1 | 2 | 3 | 4,375 | ∑ |
| (f_i) | 229 | 211 | 93 | 35 | 8 | 576 |
| (x_if_i) | 0 | 211 | 186 | 105 | 35 | 537 |
$$ lambdaapprox M(x)=frac{sum x_if_i}{N}=frac{537}{576}approx 0,932 $$ Оценка не изменилась, что указывает на правильное определение средней для (x_5).
Строим расчетную таблицу для подсчета статистики:
| (x_i) | 0 | 1 | 2 | 3 | 4,375 | ∑ |
| (f_i) | 229 | 211 | 93 | 35 | 8 | 576 |
| (p_i) | 0,3937 | 0,3670 | 0,1711 | 0,0532 | 0,0121 | 0,9970 |
| (m_i) | 226,7 | 211,4 | 98,5 | 30,6 | 7,0 | 574,2 |
| (f_i-m_i) | 2,3 | -0,4 | -5,5 | 4,4 | 1,0 | — |
| (frac{(f_i-m_i)^2}{m_i}) | 0,02 | 0,00 | 0,31 | 0,63 | 0,16 | 1,12 |
Значение теста: (X_e^2=1,12)
Критическое значение статистики ищем в виде (X_{кр}^2=X^2(alpha,k-2)), где α=0,05 и k=5, r=1
(X_{кр}^2approx 7,81)
Получается, что: (X_e^2lt X_{кр}^2)
Гипотеза (H_0) принимается.
Стрельба случайна.
И какой же ответ верный? Полученный в Примере 2 или в Примере 3?
Если посмотреть в расчетную таблицу для статистики (X_e^2) в Примере 2, основной вклад внесло слагаемое для (x_i=7). Оно равно 34,34 и поэтому сумма (X_e^2=36,84) в итоге велика. А в расчетной таблице Примера 3 такого выброса нет. Для объединенной варианты (x_i=4,375) слагаемое статистики равно 0,16 и сумма (X_e^2=1,12) в итоге мала.
Правильный ответ – в Примере 3.
Стрельба случайна.
Уровень значимости
- Уровень значимости
-
В статистике величину называют статисти́чески зна́чимой, если мала вероятность чисто случайного возникновения её или ещё более крайних величин. Здесь под крайностью понимается степень отклонения от нуль-гипотезы. Разница называется «статистически значимой», если имеются данные, появление которых было бы маловероятно, если предположить, что эта разница отсутствует; это выражение не означает, что данная разница должна быть велика, важна, или значима в общем смысле этого слова.
Уровень значимости теста — это традиционное понятие проверки гипотез в частотной статистике. Он определяется как вероятность принять решение отклонить нуль-гипотезу, если на самом деле нуль-гипотеза верна (решение известное как ошибка первого рода, или ложноположительное решение.) Процесс решения часто опирается на p-величину (читается «пи-величина»): если p-величина меньше уровня значимости, то нуль-гипотеза отвергается. Чем меньше p-величина, тем более значимой называется тестовая статистика. Чем меньше p-величина, тем сильнее основания отвергнуть нуль-гипотезу.
Уровень значимости обыкновенно обозначают греческой буквой α (альфа). Популярными уровнями значимости являются 5%, 1%, и 0.1%. Если тест выдаёт p-величину меньше α-уровня, то нуль-гипотеза отклоняется. Такие результаты неформально называют «статистически значимыми». Например, если кто-то говорит, что «шансы того, что случившееся является совпадением, равным одному из тысячи», то имеется в виду 0.1 % уровень значимости.
Различные значения α-уровня имеют свои достоинства и недостатки. Меньшие α-уровни дают бо́льшую уверенность в том, что уже установленная альтернативная гипотеза значима, но при этом есть больший риск не отвергнуть ложную нуль-гипотезу (ошибка второго рода, или «ложноотрицательное решение»), и таким образом меньшая статистическая мощность. Выбор α-уровня неизбежно требует компромисса между значимостью и мощностью, и следовательно между вероятностями ошибок первого и второго рода. В отечественных научных работах часто употребляется неправильный термин «достоверность» вместо термина «статистическая значимость».
См. также
- Ложное срабатывание
- Ошибки первого и второго рода
Примечания
George Casella, Roger L. Berger Hypothesis Testing // Statistical Inference. — Second Edition. — Pacific Grove, CA: Duxbury, 2002. — С. 397. — 660 с. — ISBN 0-534-24312-6
О НЕПРАВИЛЬНОМ УПОТРЕБЛЕНИИ ТЕРМИНА «ДОСТОВЕРНОСТЬ» В РОССИЙСКИХ НАУЧНЫХ ПСИХИАТРИЧЕСКИХ И ОБЩЕМЕДИЦИНСКИХ СТАТЬЯХ http://www.biometrica.tomsk.ru/let1.htm
Wikimedia Foundation.
2010.
Полезное
Смотреть что такое «Уровень значимости» в других словарях:
-
УРОВЕНЬ ЗНАЧИМОСТИ — число столь малое, что можно считать практически несомненным, что событие с вероятностью α не произойдет при единичном опыте. Обычно У. з. фиксируется произвольно, а именно: 0,05, 0,01 и при особой точности 0,005 и т. д. В геол. работах… … Геологическая энциклопедия
-
уровень значимости — статистического критерия (его называют также “альфа уровень” и обозначают греческой буквой ) – это ограничение сверху на вероятность ошибки первого рода (вероятность отвергнуть нулевую гипотезу, когда она на самом деле верна). Типичные значения – … Словарь социологической статистики
-
УРОВЕНЬ ЗНАЧИМОСТИ — англ. level, significance; нем. Signifikanzniveau. Степень риска в том, что исследователь может сделать неправильный вывод об ошибочности статист, гипотезы на основе выборочных данных. Antinazi. Энциклопедия социологии, 2009 … Энциклопедия социологии
-
уровень значимости — — [Л.Г.Суменко. Англо русский словарь по информационным технологиям. М.: ГП ЦНИИС, 2003.] Тематики информационные технологии в целом EN level of significance … Справочник технического переводчика
-
уровень значимости — 3.31 уровень значимости (significance level) α: Заданное значение, представляющее собой верхний предел вероятности отвергнуть статистическую гипотезу, когда эта гипотеза верна. Источник: ГОСТ Р ИСО 12491 2011: Материалы и изделия строительные.… … Словарь-справочник терминов нормативно-технической документации
-
УРОВЕНЬ ЗНАЧИМОСТИ — понятие математической статистики, отражающее степень вероятности ошибочного вывода относительно статистической гипотезы о распределении признака, проверяемой на основе выборочных данных. В психологических исследованиях за достаточный уровень… … Современный образовательный процесс: основные понятия и термины
-
уровень значимости — reikšmingumo lygis statusas T sritis automatika atitikmenys: angl. significance level vok. Signifikanzniveau, n rus. уровень значимости, m pranc. niveau de signifiance, m … Automatikos terminų žodynas
-
уровень значимости — reikšmingumo lygis statusas T sritis fizika atitikmenys: angl. level of significance; significance level vok. Sicherheitsschwelle, f rus. уровень значимости, f pranc. niveau de significance, m … Fizikos terminų žodynas
-
Уровень значимости (критический пороговый уровень статистической значимости) — Уровень значимости (критический, пороговый уровень статистической значимости) * узровень значнасці (крытычны, парогавы ўзровень статыстычнай значнасці) * significance level допускаемая исследователем величина α ошибки, т. е. максимально… … Генетика. Энциклопедический словарь
-
уровень значимости (статистического испытания) — — [http://www.iks media.ru/glossary/index.html?glossid=2400324] Тематики электросвязь, основные понятия EN significance level (of a statistical test) … Справочник технического переводчика
5.3. Ошибки первого и второго рода
Ошибка первого рода состоит в том, что гипотеза ![]() будет отвергнута, хотя на самом деле она правильная. Вероятность
будет отвергнута, хотя на самом деле она правильная. Вероятность
допустить такую ошибку называют уровнем значимости и обозначают буквой ![]() («альфа»).
(«альфа»).
Ошибка второго рода состоит в том, что гипотеза ![]() будет принята, но на самом деле она неправильная. Вероятность
будет принята, но на самом деле она неправильная. Вероятность
совершить эту ошибку обозначают буквой ![]() («бета»). Значение
(«бета»). Значение ![]() называют мощностью критерия – это вероятность отвержения неправильной
называют мощностью критерия – это вероятность отвержения неправильной
гипотезы.
В практических задачах, как правило, задают уровень значимости, наиболее часто выбирают значения ![]() .
.
И тут возникает мысль, что чем меньше «альфа», тем вроде бы лучше. Но это только вроде: при уменьшении
вероятности ![]() —
—
отвергнуть правильную гипотезу растёт вероятность ![]() — принять неверную гипотезу (при прочих равных условиях).
— принять неверную гипотезу (при прочих равных условиях).
Поэтому перед исследователем стоит задача грамотно подобрать соотношение вероятностей ![]() и
и ![]() , при этом учитывается тяжесть последствий, которые
, при этом учитывается тяжесть последствий, которые
повлекут за собой та и другая ошибки.
Понятие ошибок 1-го и 2-го рода используется не только в статистике, и для лучшего понимания я приведу пару
нестатистических примеров.
Петя зарегистрировался в почтовике. По умолчанию, ![]() – он считается добропорядочным пользователем. Так считает антиспам
– он считается добропорядочным пользователем. Так считает антиспам
фильтр. И вот Петя отправляет письмо. В большинстве случаев всё произойдёт, как должно произойти – нормальное письмо дойдёт до
адресата (правильное принятие нулевой гипотезы), а спамное – попадёт в спам (правильное отвержение). Однако фильтр может
совершить ошибку двух типов:
1) с вероятностью ![]() ошибочно отклонить нулевую гипотезу (счесть нормальное письмо
ошибочно отклонить нулевую гипотезу (счесть нормальное письмо
за спам и Петю за спаммера) или
2) с вероятностью ![]() ошибочно принять нулевую гипотезу (хотя Петя редиска).
ошибочно принять нулевую гипотезу (хотя Петя редиска).
Какая ошибка более «тяжелая»? Петино письмо может быть ОЧЕНЬ важным для адресата, и поэтому при настройке фильтра
целесообразно уменьшить уровень значимости ![]() , «пожертвовав» вероятностью
, «пожертвовав» вероятностью ![]() (увеличив её). В результате в основной ящик будут попадать все
(увеличив её). В результате в основной ящик будут попадать все
«подозрительные» письма, в том числе особо талантливых спаммеров. …Такое и почитать даже можно, ведь сделано с любовью 
Существует примеры, где наоборот – более тяжкие последствия влечёт ошибка 2-го рода, и вероятность ![]() следует увеличить (в пользу уменьшения
следует увеличить (в пользу уменьшения
вероятности ![]() ). Не хотел я
). Не хотел я
приводить подобные примеры, и даже отшутился на сайте, но по какой-то мистике через пару месяцев сам столкнулся с непростой
дилеммой. Видимо, таки, надо рассказать:
У человека появилась серьёзная болячка. В медицинской практике её принято лечить (основное «нулевое» решение). Лечение
достаточно эффективно, однако не гарантирует результата и более того опасно (иногда приводит к серьёзному пожизненному
увечью). С другой стороны, если не лечить, то возможны осложнения и долговременные функциональные нарушения.
Вопрос: что делать? И ответ не так-то прост – в разных ситуациях разные люди могут принять разные
решения (упаси вас).
Если болезнь не особо «мешает жить», то более тяжёлые последствия повлечёт ошибка 2-го рода – когда человек соглашается
на лечение, но получает фатальный результат (принимает, как оказалось, неверное «нулевое» решение). Если же…, нет, пожалуй,
достаточно, возвращаемся к теме:
 5.4. Процесс проверки статистической гипотезы
5.4. Процесс проверки статистической гипотезы
 5.2. Нулевая и альтернативная гипотезы
5.2. Нулевая и альтернативная гипотезы
| Оглавление |
Ошибки I и II рода при проверке гипотез, мощность
Общий обзор
Принятие неправильного решения
Мощность и связанные факторы
Проверка множественных гипотез
Общий обзор
Большинство проверяемых гипотез сравнивают между собой группы объектов, которые испытывают влияние различных факторов.
Например, можно сравнить эффективность двух видов лечения, чтобы сократить 5-летнюю смертность от рака молочной железы. Для данного исхода (например, смерть) сравнение, представляющее интерес (например, различные показатели смертности через 5 лет), называют эффектом или, если уместно, эффектом лечения.
Нулевую гипотезу выражают как отсутствие эффекта (например 5-летняя смертность от рака молочной железы одинаковая в двух группах, получающих разное лечение); двусторонняя альтернативная гипотеза будет означать, что различие эффектов не равно нулю.
Критериальная проверка гипотезы дает возможность определить, достаточно ли аргументов, чтобы отвергнуть нулевую гипотезу. Можно принять только одно из двух решений:
- отвергнуть нулевую гипотезу и принять альтернативную гипотезу
- остаться в рамках нулевой гипотезы
Важно: В литературе достаточно часто встречается понятие «принять нулевую гипотезу». Хотелось бы внести ясность, что со статистической точки зрения принять нулевую гипотезу невозможно, т.к. нулевая гипотеза представляет собой достаточно строгое утверждение (например, средние значения в сравниваемых группах равны ![]() ).
).
Поэтому фразу о принятии нулевой гипотезы следует понимать как то, что мы просто остаемся в рамках гипотезы.
Принятие неправильного решения
Возможно неправильное решение, когда отвергают/не отвергают нулевую гипотезу, потому что есть только выборочная информация.
| |
Верная гипотеза | ||
|---|---|---|---|
| H0 | H1 | ||
| Результат применения критерия |
H0 | H0 верно принята | H0 неверно принята (Ошибка второго рода) |
| H1 | H0 неверно отвергнута (Ошибка первого рода) |
H0 верно отвергнута |
Ошибка 1-го рода: нулевую гипотезу отвергают, когда она истинна, и делают вывод, что имеется эффект, когда в действительности его нет. Максимальный шанс (вероятность) допустить ошибку 1-го рода обозначается α (альфа). Это уровень значимости критерия; нулевую гипотезу отвергают, если наше значение p ниже уровня значимости, т. е., если p < α.
Следует принять решение относительно значения а прежде, чем будут собраны данные; обычно назначают условное значение 0,05, хотя можно выбрать более ограничивающее значение, например 0,01.
Шанс допустить ошибку 1-го рода никогда не превысит выбранного уровня значимости, скажем α = 0,05, так как нулевую гипотезу отвергают только тогда, когда p< 0,05. Если обнаружено, что p > 0,05, то нулевую гипотезу не отвергнут и, следовательно, не допустят ошибки 1-го рода.
Ошибка 2-го рода: не отвергают нулевую гипотезу, когда она ложна, и делают вывод, что нет эффекта, тогда как в действительности он существует. Шанс возникновения ошибки 2-го рода обозначается β (бета); а величина (1-β) называется мощностью критерия.
Следовательно, мощность — это вероятность отклонения нулевой гипотезы, когда она ложна, т.е. это шанс (обычно выраженный в процентах) обнаружить реальный эффект лечения в выборке данного объема как статистически значимый.
В идеале хотелось бы, чтобы мощность критерия составляла 100%; однако это невозможно, так как всегда остается шанс, хотя и незначительный, допустить ошибку 2-го рода.
К счастью, известно, какие факторы влияют на мощность и, таким образом, можно контролировать мощность критерия, рассматривая их.
Мощность и связанные факторы
Планируя исследование, необходимо знать мощность предложенного критерия. Очевидно, можно начинать исследование, если есть «хороший» шанс обнаружить уместный эффект, если таковой существует (под «хорошим» мы подразумеваем, что мощность должна быть по крайней мере 70-80%).
Этически безответственно начинать исследование, у которого, скажем, только 40% вероятности обнаружить реальный эффект лечения; это бесполезная трата времени и денежных средств.
Ряд факторов имеют прямое отношение к мощности критерия.
Объем выборки: мощность критерия увеличивается по мере увеличения объема выборки. Это означает, что у большей выборки больше возможностей, чем у незначительной, обнаружить важный эффект, если он существует.
Когда объем выборки небольшой, у критерия может быть недостаточно мощности, чтобы обнаружить отдельный эффект. Эти методы также можно использовать для оценки мощности критерия для точно установленного объема выборки.
Вариабельность наблюдений: мощность увеличивается по мере того, как вариабельность наблюдений уменьшается.
Интересующий исследователя эффект: мощность критерия больше для более высоких эффектов. Критерий проверки гипотез имеет больше шансов обнаружить значительный реальный эффект, чем незначительный.
Уровень значимости: мощность будет больше, если уровень значимости выше (это эквивалентно увеличению допущения ошибки 1-го рода, α, а допущение ошибки 2-го рода, β, уменьшается).
Таким образом, вероятнее всего, исследователь обнаружит реальный эффект, если на стадии планирования решит, что будет рассматривать значение р как значимое, если оно скорее будет меньше 0,05, чем меньше 0,01.
Обратите внимание, что проверка ДИ для интересующего эффекта указывает на то, была ли мощность адекватной. Большой доверительный интервал следует из небольшой выборки и/или набора данных с существенной вариабельностью и указывает на недостаточную мощность.
Проверка множественных гипотез
Часто нужно выполнить критериальную проверку значимости множественных гипотез на наборе данных с многими переменными или существует более двух видов лечения.
Ошибка 1-го рода драматически увеличивается по мере увеличения числа сравнений, что приводит к ложным выводам относительно гипотез. Следовательно, следует проверить только небольшое число гипотез, выбранных для достижения первоначальной цели исследования и точно установленных априорно.
Можно использовать какую-нибудь форму апостериорного уточнения значения р, принимая во внимание число выполненных проверок гипотез.
Например, при подходе Бонферрони (его часто считают довольно консервативным) умножают каждое значение р на число выполненных проверок; тогда любые решения относительно значимости будут основываться на этом уточненном значении р.
Связанные определения:
p-уровень
Альтернативная гипотеза, альтернатива
Альфа-уровень
Бета-уровень
Гипотеза
Двусторонний критерий
Критерий для проверки гипотезы
Критическая область проверки гипотезы
Мощность
Мощность исследования
Мощность статистического критерия
Нулевая гипотеза
Односторонний критерий
Ошибка I рода
Ошибка II рода
Статистика критерия
Эквивалентные статистические критерии
В начало
Содержание портала