[c.66]
В международных маркетинговых исследованиях могут возникать ошибки понятийного аппарата, терминологии применяемого инструментария источников информации размеров выборки и методов выборочного наблюдения.
[c.656]
Ошибки выборки связаны с процессом установления представительности той части генеральной совокупности данных, которая охватывается наблюдением. При установлении размера выборки возможны ошибки, связанные с различием используемых объемов генеральных выборок и методов выборочного наблюдения при проведении зарубежных маркетинговых исследований.
[c.657]
Иногда исследователи умышленно завышают отдельный тип ошибки, чтобы снизить об-ошибку, снижая размер других ошибок, Например, предположим, проводится почтовый опрос для определения потребительских предпочтений относительно покупки модной одежды в универмагах. Предлагалась выборка большого размера, чтобы снизить ошибку выборки. Доля ответов ожидается на уровне 30%. Учитывая ограниченный бюджет проекта и большой размер выборки, средств на дополнительный почтовый опрос не остается. Однако прошлый опыт показывает, что долю ответов можно увеличить до 45% с одним и до 55% с двумя дополнительными почтовыми отправлениями. Однако может быть желательным снизить размер выборки, так чтобы появились деньги для дополнительных почтовых отправлений. Хотя размера выборки увеличит ошибку выборки, два дополнительных почтовых отправления более чем возместят эту потерю за счет снижения систематической ошибки.
[c.133]
При определении объема (размера) выборки аудиторская организация должна установить риск выборки, допустимую и ожидаемую ошибки.
[c.264]
Планируя процедуры на уровне статей, аудитор должен принимать во внимание, что несущественные искажения сведений в отдельных статьях могут в совокупности составить значительное количество. Существенность в выборочном исследовании и проверке — это общий показатель, однако он применяется в отношении конкретных сальдо счетов как наибольшая по размеру ошибка, которая может быть допущена. Для избежания подобной проблемы используется понятие допустимая ошибка . Устанавливая допустимую ошибку ниже значения планируемой существенности, аудитор уменьшает вероятность того, что сумма расхождений (как выявленных, так и невыявленных) превысит уровень существенности. Размер допустимой ошибки учитывается при разработке программы аудита каждого конкретного счета, и прежде всего при расчете размера выборки. Обычно допустимая ошибка устанавливается на уровне 50% (иногда 75%) от планируемой существенности.
[c.116]
Далее посмотрим, как влияет колеблемость признака в генеральной совокупности на величину ошибки. Нетрудно доказать, что увеличение колеблемости признака влечет за собой увеличение среднего квадратического отклонения, а следовательно, и ошибки. Если предположить, что все единицы будут иметь одинаковую величину признака, то среднее квадратическое отклонение станет равно нулю и ошибка выборки также исчезнет. Тогда нет необходимости применять выборку. Однако следует иметь в виду, что величина колеблемости признака в генеральной совокупности бывает неизвестна, поскольку неизвестны размеры единиц в ней. Мы можем рассчитать лишь колеблемости признака в выборочной совокупности.
[c.131]
Необходимо отметить, что, поскольку выборка является частью изучаемой совокупности, полученные от выборки данные скорее всего не будут в точности соответствовать данным, которые можно было бы получить от всех единиц совокупности. Различие между данными, полученными от выборки, и истинными данными, называется ошибкой выборки. Ошибка выборки обусловливается двумя факторами методом формирования выборки и размером выборки. Эти вопросы будут рассмотрены ниже.
[c.165]
В планировании реального исследования кроме выяснения объема выборки и способа отбора респондентов решают задачу достижения требуемого исследователю уровня точности результата. При определении объема выборки нужно вычислить ее размер, оценить возможную ошибку и вероятность того, что результаты будут описаны определенным законом (по определенному распределению). Итого получается априорно неизвестных величин слишком много.
[c.150]
В табл. 4.7 приведен пример расчета размера выборки при Р = 0,954, / = 2 и допустимой ошибке 5%.
[c.151]
Используя данные п. 6, определите, каким должен быть размер выборки для того, чтобы оценить недельный доход с 95%-ной вероятностью и с максимальной ошибкой не более 0,004.
[c.253]
Такое направление исследований фактически было продолжено в статистической теории решений. В теории выборки нас интересует оптимальный размер выборки (а в случае последовательной выборки — когда прекратить обследование), и мы хотим оценить эффективность различных приемов выборки. Последняя проблема более проста, так как мы можем сравнить относительные затраты альтернативных вариантов, которые имеют одинаковые ошибки выборки, и поэтому есть возможность избежать оценки значимости информации. Однако некоторый прогресс был достигнут в области оценки значимости повышенной точности прогнозов в тех ситуациях, когда прогноз должен быть сделан в отношении формальных правил принятия решений в ситуациях выбора.
[c.63]
Допустимая ошибка выборки определяется на стадии планирования аудита в соответствии с выбранным уровнем существенности. Допустимой может рассматриваться ошибка в пределах материальной, установленной аудитором применительно к процедурам внутреннего контроля, оборотам и сальдо по счетам или проводкам определенной группы. Размер выборки определяется величиной допустимой ошибки. Чем меньше ее величина, тем больше необходимый объем выборки.
[c.64]
Зависимость между ошибкой выборки, колеблемостью изучаемого признака и размером выборки выражается следующей формулой [c.433]
Объём выборки, т. е. размер выборки при заданной ошибке и известной степени колеблемости изучаемого признака, определяется следующим образом.
[c.433]
Приведённые выше формулы (см. стр. 433) определения возможной ошибки и размера выборки предполагают повторную схему выборки.
[c.434]
Другая ошибка, за возникновение которой ответственна эвристика репрезентативности, — это игнорирование размера выборки. Пытаясь понять, были ли те или иные данные сгенерированы определенной моделью, большинство людей полностью игнорируют такую важную вероятностную характеристику, как объем этих данных. Люди считают, что как большие, так маленькие выборки несут одинаковую информацию о том, какая модель их сгенерировала. Хотя очевидно, что, чем больше выборка, тем выше ее информативность. Вот простой пример. Предположим, что у нас есть честная монетка, т.е. при ее броске с вероятностью 50/50 можно ожидать выпадения орла или решки. Возьмем двух людей и зададим им следующие вопросы. Одному скажем, что мы подкинули монетку 1000 раз, из них 500 раз выпал орел и 500 раз — решка. Не мог бы он теперь сказать, с какой вероятностью монетка, с которой мы имеем дело, является честной Другому человеку скажем, что размер выборки составляет всего лишь шесть бросков, из которых три раза выпала решка и три раза — орел, и спросим у него вероятность того, что монетка является честной . Вероятность эти два человека установят примерно одинаковую Это называется игнорировать размеры выборки.
[c.226]
Контроль факторов ошибки отбора и убыли возможен при применении специально разработанных процедур эксперимента. Изменения отдельных связанные с их зрелостью, часто не представляют особенного интереса для исследователя. С другой стороны, эта модель имеет значительные преимущества с учетом сроков и стоимости проведения исследований, а также требований к размеру выборки, Для ее применения требуются лишь две группы респондентов и всего одно обследование каждой группы. Благодаря простоте применения эта модель на данный момент наиболее распространенная в практике маркетинговых исследований. Необходимо также отметить, что она очень схожа по своему содержанию с моделью предварительного и итогового исследования с использованием контрольной группы.
[c.289]
Поскольку существуют ошибки выборки и в первом и во втором случаях, то можно сделать следующий вывод. Для первого случая около 30% опрошенных выразили неудовлетворенность купленной моделью автомобиля. Для второго случая около 35% опрошенных выразили неудовлетворенность купленной моделью автомобиля. Какой же общий вывод можно сделать в данном случае Как избавиться от термина «около» Для этого введем показатель ошибки 30% х% и 35% у% и сравнить х и у. Используя логический анализ, можно сделать вывод, что большая выборка содержит меньшую ошибку и что на ее основе можно сделать более правильные выводы о мнении всей совокупности потребителей. Видно, что решающим фактором для получения правильных выводов является размер выборки. Данный показатель присутствует во всех формулах, определяющих содержание различных методов статистического вывода.
[c.38]
Чаще всего делают заключение об удовлетворительности выборки, сопоставляя получившиеся пределы ошибок выборочных показателей с величинами допустимых погрешностей. Может получиться, что предел ошибки, рассчитанный с заданной вероятностью, окажется выше допустимого размера погрешности. В этих случаях определяют вероятность того, что ошибка выборки не превзойдет допускаемую погрешность. Решение этой задачи и заключается в отыскании F(t) на основе формулы предела ошибки выборки [c.186]
Этап 2. По остальным расчетным документам делается контрольная выборка. Для этого применяются различные способы. Одним из самых простейших является -процентный тест (так, при п = 10% проверяют каждый десятый документ, отбираемый по какому-либо признаку, например, по времени возникновения обязательства). Существуют и более сложные статистические методы отбора, основанные на задании критических значений уровня значимости, ошибки выборки, допустимого отклонения между отраженным в отчетности и исчисленным по выборочным данным размером дебиторской задолженности и т. п. В этом случае определяют интервал выборки (подснежному измерителю), и каждый расчетный документ, на который падает граница очередного интервала, отбирается для контроля и анализа.
[c.331]
Рассмотрим три примера вычисления стандартной ошибки при разных размерах торговой выборки (10, 30 и 100 сделок) [c.67]
Для уменьшения ошибки, обусловленной отказом отвечать на вопросы, необходимо прежде всего ее измерить. Если величина ошибки является существенной, то надо предпринять меры для ее уменьшения. Для этого используется два метода взвешенных средних и формирование выборки больших размеров.
[c.173]
Предположим, мы намерены определить параметры некоторой группы людей, например летающих самолетами Аэрофлота. Если нас интересует средний возраст пассажира, то вычисляем среднее арифметическое значение возраста людей. Извлекая выборки определенного размера (предположим, по 200 человек), мы будем получать, что средний возраст отклоняется то в одну, то в другую сторону от истинного значения приблизительно с одинаковой частотой. При увеличении количества выборок средняя арифметическая ошибка стремится к нулю. Это и есть случайная погрешность.
[c.150]
Ответственность за достоверность данных, представляемых аудитору по его запросу, несет руководитель предприятия. Аудитор отвечает только за квалифицированное выполнение своих обязанностей, предусмотренных законодательством и заключенным с заказчиком договором. За ущерб, причиненный предприятию некачественным проведением аудиторской проверки, аудитор несет имущественную ответственность в размере, предусмотренном в договоре, с учетом ограничения ответственности, установленного законодательством. Свою ответственность аудиторы могут страховать за счет средств аудиторской фирмы, а индивидуальные аудиторы — за свой счет. В мировой практике проблема ответственности аудиторов решается через аудиторские стандарты, обязательные для соблюдения всеми аудиторскими компаниями. Применяются стандартизированные методы статистической выборки, используемые аудиторами в ходе проверок. Действует и принцип существенности, в соответствии с которым степень ответственности аудитора определяется в зависимости от цены допущенной им ошибки. Зарубежный опыт регулирования аудиторской деятельности представляется полезным для России и в отношении ответственности аудиторских фирм в случае неквалифицированного осуществления аудиторских услуг — она носит, как правило, не административный (лишение лицензии на осуществление аудиторской деятельности), а имущественный характер.
[c.230]
Существует альтернативный подход, иногда используемый для оценки дополнительной премии за риск, которая должна устанавливаться для частной фирмы. В этом подходе мы сравниваем историческую доходность, зарабатываемую венчурным капиталом и частными взаимными фондами, инвестирующими в публично торгуемые акции. Разница между ними может рассматриваться как премия за риск частной компании. Например, частные взаимные фонды в 1990-2000 гг. сообщали о среднегодовой доходности в размере 24%. С другой стороны, среднегодовая доходность акций в 1990-2000 гг. составляла 15%. Разницу в 9% можно рассматривать, как премию за риск частной фирмы, и ее следует прибавить к стоимости собственного капитала, оцененного с использованием рыночного коэффициента бета или нескольких коэффициентов бета. Данный подход связан с тремя ограничениями. Во-первых, большинство венчурных капиталистов и частных инвесторов-акционеров не афиширует свои годовые доходы, и возникает ошибка выборки обнародованных данных. В то же время успешные частные взаимные фонды, скорее всего, будут стремиться полнее раскрыть данные о своих доходах. Во-вторых, стандартные ошибки в годовых доходах, по всей вероятности, будут очень большими, и возникающий шум также будет влиять на оценку премии за риск. В-третьих, все частные фирмы в рамках данного подхода рассматриваются как эквивалентные, и не делается никакой попытки оценить более значительные премии для одних фирм и меньшие премии для других.
[c.894]
При изучении элементов, попавших в выборку (документов, операций, сальдо и др.), фиксируются все ошибки независимо от их стоимости, так как результаты выборки будут распространены на всю совокупность. При использовании выборки, основанной на денежной единице, важен не столько абсолютный размер ошибки, сколько соотношение ошибки и величины элемента совокупности. В ходе анализа документов устанавливается удельный вес неправильно оформленных или отсутствующих документов. Необнаружение документа по операции, включенной в выборку, должно рассматриваться как серьезное нарушение.
[c.63]
Для проверки существования AR H необходимо возвести в квадрат ошибки из первоначального уравнения условной средней. Этот ряд квадратов регрессируется по константе и прошлым значениям квадратов с лагом р. Критерием является Т R2, где Т — размер выборки и R2 — коэффициент множественной регрессии из уравнения регрессии квадратов ошибок. Этот критерий подчиняется х2 РаспРеДелению. Число степеней свободы равно числу временных лагов в регрессии. Если значение критерия больше критического значения из таблиц х2, то нулевая гипотеза о том, что AR H не присутствует, отвергается.
[c.356]
Определение объема выборки. Располагая некоторой информацией о изменчивости изучаемого признака очень большой совокупности, минимальный размер выборки определяют на основе классического метода, при котором относительную ошибку оценки признака и риск принимают равными4. Тогда для определения параметра с заданной точностью необходима выборка величиной [c.66]
Все ошибки выборочного наблюдения подразделяются на ошибки выборки (случайные) ошибки, вызванные отклонением от схемы отбора (неслучайные) ошибки наблюдения (случайные и не-случайные).Ппохо, когда ошибка выборки превышает допустимый размер погрешности, но слишком высокая точность также подозрительна и, как правило, свидетельствует об ошибках отбора.
[c.164]
При проведении выборки совокупность следует разбить на отдельные группы (подсовокупности), элементы каждой из которых имеют сходные характеристики. Критерии разбиения совокупности должны быть такими, чтобы для каждого элемента можно было четко указать, к какой совокупности он принадлежит. Данная процедура, называемая стратификацией, позволяет уменьшить разброс (вариацию) данных. При определении объема (размера) выборки аудиторская организация должна установить риск выборки, допустимую и ожидаемую ошибки.
[c.39]
Контур выборки неизбежно содержит ошибку, называемую ошибкой контура выборки и характеризующую степень отклонения от истинных размеров совокупности. Очевидно, что не существует полного официального списка всех автосервисных мастерских города Москвы, включая полулегальный и нелегальный бизнес в данной области. Исследователь должен информировать заказчика работы о размерах ошибки контура выборки.
[c.166]
Очевидно, что цена , которую мы платим за уменьшение объема выборки, выражающаяся в уменьшении точности получаемых результатов, зависит также и от фактического распределения ответов. На сайте Gallup можно найти таблицу, связывающую размер выборки (по горизонтали от 25 до 1000) с величиной стандартной ошибки (числовые данные в ячейках табл. 4.8).
[c.154]
Соотношение коэффициента и его стандартной ошибки, или /-статистика (в последнем случае 0,017 0,004 = 4,25), важна для определения статистической значимости зависимости функции от соответствующей объясняющей переменной. Вообще говоря, нулевая гипотеза для /-статистики и, соответственно, коэффициента регрессии проверяется с помощью таблиц распределения Стьюдента. В данном случае ясно без таблиц, по общему порядку цифр, что коэффициент при GNP, равный 0,017, статистически значим (так как t Np = 4,25), а коэффициент при RSR, равный (-0,411), статистически незначим. Его /-статистика / =-0,411/0,947 -0,434 слишком мала по абсолютной величине. Если уточнить по таблицам, уровень значимости здесь составляет примерно. Следовательно, если в действительности (для генеральной совокупности) этот коэффициент равен нулю, то вполне вероятно (с вероятностью 2/3) для данного размера выборки (60 наблюдений) при двух объясняющих переменных получить такую (-0,434) или большую по модулю /-статистику данного коэффициента регрессии. Для оценки значимости коэф-
[c.336]
Что, если распределение не соответствует нормальному При проведении проверки по критерию Стьюдента исходят из предположения, что данные соответствуют нормальному распределению. В реальности распределение показателей прибылей и убытков торговой системы таким не бывает, особенно при наличии защитных остановок и целевых прибылей, как показано на рис. 4-1. Дело в том, что прибыль выше, чем целевая, возникает редко. Фактически большинство прибыльных сделок будут иметь прибыль, близкую к целевой. С другой стороны, кое-какие сделки закроются с убытком, соответствующим уровню защитной остановки, а между ними будут разбросаны другие сделки, с прибылью, зависящей от методики выхода. Следовательно, это будет совсем непохоже на колоко-лообразную кривую, которая описывает нормальное распределение. Это составляет нарушение правил, лежащих в основе проверки по критерию Стьюдента. Впрочем, в данном случае спасает так называемая центральная предельная теорема с ростом числа точек данных в выборке распределение стремится к нормальному. Если размер выборки составит 10, то ошибки будут небольшими если же их будет 20 — 30, ошибки будут иметь исчезающе малое значение для статистических заключений. Следовательно, многие виды статистического анализа можно с уверенностью применять при адекватном размере выборки, например при п = 47 и выше, не опасаясь за достоверность заключений.
[c.79]
Стандартное отклонение выборки составило более 6000, почти вдвое больше, чем в пределах выборки, по которой проводилась оптимизация. Следовательно, стандартное отклонение средней прибыли в сделке было около 890, что составляет немалую ошибку. С учетом небольшого размера выборки это приводит к снижению значения t-критерия по сравнению с полученным при оптимизации и к меньшей статистической значимости — около 14%. Эти результаты не слишком плохи, но и не слишком хороши вероятность нахождения скрытой неэффективности рынка составляет более 80%. Но при этом серийная корреляция в тесте была значительно выше (ее вероятность составила 0,1572). Это означает, что такой серийной корреляции чисто случайно можно достичь лишь в 16% случаев, даже если никакой реальной корреляции в данных нет. Следовательно, и t-критерий прибыли/убытка, скорее всего, переоценил статистическую значимостьдо некоторой степени (вероятно, на 20 — 30%). Если размер выборки был бы меньше, то значение t составило бы около 0,18 вместо полученного 0,1392. Доверительный интервал для процента прибыльных сделок в популяции находился в пределах от 17 до приблизительно 53%.
[c.84]
После определения суммарного размера ожидаемой ошибки по всем интервалам выборки (т. е. шагам отбора) производится сравнение с допустимым размером суммарной ошибки, и если рассчитанная суммарная ошибка превосходит допустимую величину, то, подставляя первую в формулу объема выборки, определяют, с каким коэффициентом надежности и соответственно с какой довери-
[c.224]
Для формирования фокус-групп было выбрано пять главных мегаполюсных регионов с жарким и влажным климатом. Было решено использовать по 12 человек в каждой фокус-группе. Опрос домовладельцев также был ограничен регионами с влажным, жарким климатом. Размер подвыборок определялся случайным образом на основе номеров телефонов пропорционально численности населения каждого региона. Было решено принять размер общей выборки, равной 1000 домовладельцев с ошибкой 3%. Данная ошибка сравнима
[c.181]
Влияние случайности полностью устранить невозможно. Со случайной ошибкой можно бороться двумя способами увеличивать количество выборок или их размер, т.е. число опрашиваемых в каждой выборке. Ошибка уменьшается при увеличении количества опрашиваемых в выборке. Несмотря на то что увеличение объема выборки повышает достоверность полученных результатов, бесконечно увеличивать количество опрашиваемых не следует, потому что пропорционально возрастают затраты»На огтрос и увеличивается время получения и обработки информации.
[c.150]
First, I’d like to blow your mind: Increasing sample size does not decrease the variance of an estimate. What you call variance can, for example, stay essentially flat, even as $n$ goes to infinity. But let’s come back to that.
We need to define terms. What you’re referring to as «variance» is generally called standard error, the standard deviation of the sampling distribution of the statistic. A statistic’s sampling distribution is just the distribution of all possible values the estimate could take, over all possible samples of a given size drawn from the population of interest. So, when you ask why variance decreases with sample size, you’re really asking why the sampling distribution of a statistic is wider for smaller $n$ and narrower for larger $n$. For the vast majority of practical statistics, your assumption that this will be the case is correct.
The reason this tends to be the case is, as others have said, the Central Limit Theorem. However, what others have neglected to tell you is that there are many limit theorems. Which one applies depends on a) the family of distributions a statistic’s sampling distribution belongs to, and b) the asymptotic behavior of the distribution as $n$ goes to infinity.
The vast majority of statistics have a sampling distribution that is approximately and asymptotically normal, so the famous Central Limit Theorem applies. Normal distributions get skinnier as n increases, for reasons others detail. Having a normal sampling distribution gives a statistic a property called efficiency, which just means its observed value gets closer to its expected value with increasing $n$.
That’s exactly what we want. We therefore purposely choose statistics with this property when we have the option. It’s easy to assume that all statistics have this property when all statistics you see have it, but I guess that’s what you’d call selection bias. (It’s also called stats being oversimplified for beginners because it’s hard enough as it is!)
A particularly interesting counterexample is a certain function of the Hamming distance, computed between a pair of bivariate normal random vectors that have been converted to ranks without ties. That is, suppose you draw $n$ pairs at random from a bivariate normal population with correlation parameter $rho$, $(X, Y)$. You replace each real number in $X$ with an integer indicating its relative order in $X$ after sorting the vector (first $= 1$, second $= 2$, and so on), and the same for $Y$.
You then count the number of bivariate observations with equal ranks. (So, the count equals $n$ minus the Hamming distance between $X$ and $Y$.) This count’s sampling distribution is approximately and asymptotically Poisson with parameter $np$, where $p$ is the probability of obtaining at least one pair of equal ranks (Zolotukhina and Latyshev, 1987).
It is well known that $np = 1$ when $rho = 0$ (As first shown by Montmort in 1708). Because a Poisson variable’s parameter is equal to both its mean and its variance, the standard error of the count only gets closer and closer to $1$ as sample size increases, when $rho = 0$ (Rae, 1987; Rae and Spencer, 1991). Cool, right? In general, for $rho geq 0$, the variance converges to $1/(1 — rho)$ as $n$ goes to infinity (Zolotukhina and Latyshev, 1987) under bivariate normality. It does NOT decrease for non-negative $rho$.
First, I’d like to blow your mind: Increasing sample size does not decrease the variance of an estimate. What you call variance can, for example, stay essentially flat, even as $n$ goes to infinity. But let’s come back to that.
We need to define terms. What you’re referring to as «variance» is generally called standard error, the standard deviation of the sampling distribution of the statistic. A statistic’s sampling distribution is just the distribution of all possible values the estimate could take, over all possible samples of a given size drawn from the population of interest. So, when you ask why variance decreases with sample size, you’re really asking why the sampling distribution of a statistic is wider for smaller $n$ and narrower for larger $n$. For the vast majority of practical statistics, your assumption that this will be the case is correct.
The reason this tends to be the case is, as others have said, the Central Limit Theorem. However, what others have neglected to tell you is that there are many limit theorems. Which one applies depends on a) the family of distributions a statistic’s sampling distribution belongs to, and b) the asymptotic behavior of the distribution as $n$ goes to infinity.
The vast majority of statistics have a sampling distribution that is approximately and asymptotically normal, so the famous Central Limit Theorem applies. Normal distributions get skinnier as n increases, for reasons others detail. Having a normal sampling distribution gives a statistic a property called efficiency, which just means its observed value gets closer to its expected value with increasing $n$.
That’s exactly what we want. We therefore purposely choose statistics with this property when we have the option. It’s easy to assume that all statistics have this property when all statistics you see have it, but I guess that’s what you’d call selection bias. (It’s also called stats being oversimplified for beginners because it’s hard enough as it is!)
A particularly interesting counterexample is a certain function of the Hamming distance, computed between a pair of bivariate normal random vectors that have been converted to ranks without ties. That is, suppose you draw $n$ pairs at random from a bivariate normal population with correlation parameter $rho$, $(X, Y)$. You replace each real number in $X$ with an integer indicating its relative order in $X$ after sorting the vector (first $= 1$, second $= 2$, and so on), and the same for $Y$.
You then count the number of bivariate observations with equal ranks. (So, the count equals $n$ minus the Hamming distance between $X$ and $Y$.) This count’s sampling distribution is approximately and asymptotically Poisson with parameter $np$, where $p$ is the probability of obtaining at least one pair of equal ranks (Zolotukhina and Latyshev, 1987).
It is well known that $np = 1$ when $rho = 0$ (As first shown by Montmort in 1708). Because a Poisson variable’s parameter is equal to both its mean and its variance, the standard error of the count only gets closer and closer to $1$ as sample size increases, when $rho = 0$ (Rae, 1987; Rae and Spencer, 1991). Cool, right? In general, for $rho geq 0$, the variance converges to $1/(1 — rho)$ as $n$ goes to infinity (Zolotukhina and Latyshev, 1987) under bivariate normality. It does NOT decrease for non-negative $rho$.
Влияние увеличения размера выборки на точность оценок
Будем по-прежнему предполагать, что мы
исследуем случайную переменную xс неизвестным математическим ожиданием![]() и теоретической дисперсией
и теоретической дисперсией![]() и что для оценивания
и что для оценивания![]() используется
используется![]() .
.
Каким образом точность оценкиxзависит от числа наблюденийn?
При увеличении nоценка![]() ,
,
вообще говоря, становится более точной.
В единичном эксперименте большая по
размеру выборка необязательно даст
более точную оценку, чем меньшая выборка,
но общая тенденция должна быть именно
такой. Поскольку дисперсия![]() выражается формулой
выражается формулой![]() ,
,
она тем меньше, чем больше размер выборки,
и, значит, тем сильнее «сжата» функция
плотности вероятности для![]() .
.
Это показано на рис. 9. Предположим, что
xнормально распределена
со средним 25 и стандартным отклонением
50. Если размер выборки равен 25, то
стандартное отклонение величины![]() ,
,
равное![]() ,
,
составит:![]() .
.
Если размер выборки равен 100, то это
стандартное отклонение равно 5. На рис.
9 показаны соответствующие функции
плотности вероятности. Вторая (![]() )
)
выше первой в окрестности![]() ,
,
что говорит о более высокой вероятности
получения с ее помощью аккуратной
оценки. За пределами этой окрестности
вторая функция всюду ниже первой.
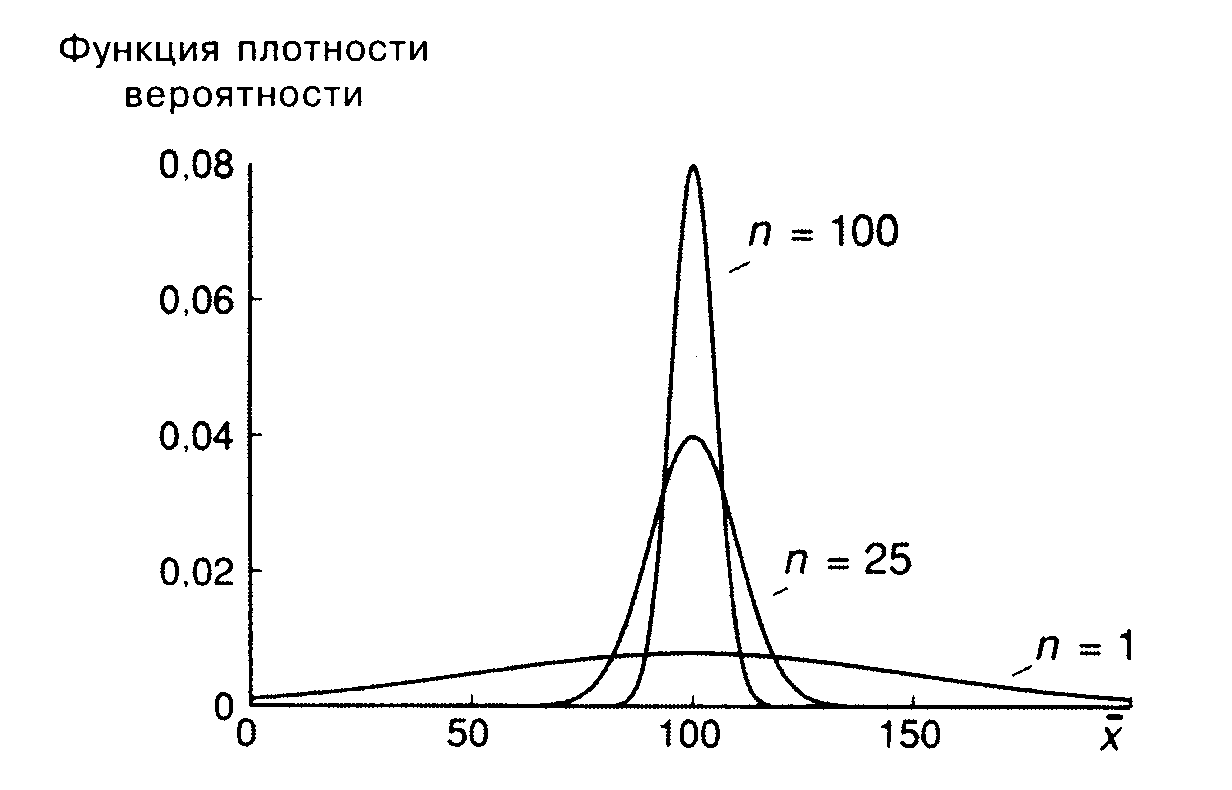
Рис. 9.
Чем больше размер выборки, тем уже и
выше будет график функции плотности
вероятности для
![]() .
.
Еслиnстановится
действительно большим, то график функции
плотности вероятности будет неотличим
от вертикальной прямой, соответствующей![]() .
.
Для такой выборки случайная составляющаяxстановится действительно
очень малой, и поэтому![]() обязательно будет очень близкой к
обязательно будет очень близкой к![]() .
.
Это вытекает из того факта, что стандартное
отклонение![]() ,
,
равное![]() ,
,
становится очень малым при большихn.
В пределе, при стремлении nк бесконечности,![]() стремится к нулю и
стремится к нулю и![]() стремится в точности к
стремится в точности к![]() .
.
Состоятельность
Вообще говоря, если предел оценки по
вероятности равен истинному значению
характеристики генеральной совокупности,
то эта оценка называется состоятельной.
Иначе говоря, состоятельной называется
такая оценка, которая дает точное
значение для большой выборки независимо
от входящих в нее конкретных наблюдений.
В большинстве конкретных случаев
несмещенная оценка является и
состоятельной.
Иногда бывает, что оценка, смещенная на
малых выборках, является состоятельной
(иногда состоятельной может быть даже
оценка, не имеющая на малых выборках
конечного математического ожидания).
На рис. 10 показано, как при различных
размерах выборки может выглядеть
распределение вероятностей. Тот факт,
что при увеличении размера выборки
распределение становится симметричным
вокруг истинного значения, указывает
на асимптотическую несмещенность. То,
что, в конечном счете, оно превращается
в единственную точку истинного значения,
говорит о состоятельности оценки.

Рис. 10.
Оценки, типа показанных на рис. 10, весьма
важны в регрессионном анализе. Иногда
невозможно найти оценку, несмещенную
на малых выборках. Если при этом вы
можете найти хотя бы состоятельную
оценку, это может быть лучше, чем не
иметь никакой оценки, особенно если вы
можете предположить направление смещения
на малых выборках.
Приложение 2
Что влияет на ширину доверительного интервала?
К этому моменту мы обсудили два фактора, которые влияют на ширину интервала:
- выбор статистики ((t) или (z)) и
- выбор степени доверия (влияющий на то, какую величину (t) или (z) мы используем).
Эти два варианта определяют фактор надежности.
Напомним, что доверительный интервал имеет следующую структуру:
Точечная оценка (pm) Фактор надежности (times) Стандартная ошибка.
Выбор размера выборки также влияет на ширину доверительного интервала. При прочих равных, больший размер выборки уменьшает ширину доверительного интервала.
Напомним формулу стандартной ошибки выборочного среднего:
( Large substack{ textbf{Стандартная ошибка} \ textbf{выборочного среднего} } = { textbf{Стандартное отклонение выборки} over sqrt { textbf{Размер выборки}}} )
Мы видим, что стандартная ошибка меняется обратно пропорционально квадратному корню из размера выборки.
По мере увеличения размера выборки, стандартная ошибка уменьшается и, следовательно, ширина доверительного интервала также уменьшается. Чем больше размер выборки, тем выше точность, с которой мы можем оценить параметр совокупности.
Существует формула для определения размера выборки, необходимого для получения доверительного интервала нужной ширины.
Определим (E) = Фактор надежности (times) Стандартная ошибка.
Чем меньше (E), тем меньше ширина доверительного интервала, так как (2E) — это ширина доверительного интервала.
Размер выборки, необходимый для получения нужного значения (E) при заданной степени уверенности ((1 — alpha) ) равен:
( Large {n = [(t_{alpha / 2}s) / E]^2} ).
При прочих равных, более крупные выборки лучше в этом смысле. На практике, однако, два соображения могут повлиять на решение против увеличения размера выборки.
- Во-первых, как мы уже видели в Примере (2) расчета коэффициента Шарпа, увеличение размера выборки может привести к выборке из более чем одной совокупности.
- Во-вторых, увеличение размера выборки может означать дополнительные затраты времени и денег, которые не окупятся благодаря дополнительной точности.
Таким образом, есть три фактора, которые финансовый аналитик должен оценить при определении размера выборки, — это:
- потребность в точности,
- риск отбора выборки из более чем одной совокупности, а также
- издержки на получение выборок различных размеров.
Пример (6) оценки инвестиционным менеджером чистого притока денежных средств клиентов.
Инвестиционный менеджер хочет построить 95-процентный доверительный интервал для притоков и оттоков денежных средств своих клиентов в течение следующих 6 месяцев.
Он начинается с обзвона случайной выборки из 10 клиентов, чтобы опросить их о планируемых взносах и изъятиях средств из инвестиционного фонда.
Затем менеджер вычисляет изменение денежного потока для каждого клиента из выборки, как процентное изменение от общего объема средств, размещенных у менеджера. Положительное процентное изменение указывает на чистый приток денежных средств на счет клиента, а отрицательное процентное изменение указывает на чистый отток денежных средств со счета клиента.
Менеджер взвешивает каждый ответ клиента по относительному размеру счета в рамках выборки, а затем вычисляет взвешенное среднее.
Проделав все это, инвестиционный менеджер вычисляет взвешенное среднее значение равное 5.5%. Таким образом, проведенная точечная оценка означает, что общая сумма средств под управлением менеджера увеличится на 5.5% в течение следующих 6 месяцев.
Стандартное отклонение наблюдений в выборке составляет 10%. Гистограмма прошлых данных выглядит довольно близко к нормальному распределению, так что менеджер предполагает, что генеральная совокупность также соответствует нормальному распределению.
1. Рассчитайте 95-процентный доверительный интервал для среднего по совокупности и интерпретируйте результаты.
Менеджер решил проанализировать, каким будет доверительный интервал, если использовать размер выборки 20 или 30, и получил то же самое среднее (5.5%) и стандартное отклонение (10%).
2. Используя выборочное среднее 5.5% и стандартное отклонение 10%, вычислите доверительный интервал для размеров выборки от 20 до 30. Для размера выборки 30 используйте Формулу 6.
3. Интерпретируйте результаты для частей 1 и 2.
Решение для части 1:
Поскольку совокупность неизвестна, а размер выборки мал, менеджер должен использовать t-статистику из Формулы 6 для расчета доверительного интервала.
Для выборки размера 10, (rm{df} = n — 1 = 10 — 1 = 9).
Для 95-процентного доверительного интервала, он должен использовать значение (t_{0.025}) для df = 9.
В соответствии с таблицами распределения Стьюдента это значение равно 2.262.
Таким образом, 95-процентный доверительный интервал для среднего значения по совокупности равен:
( begin{aligned} overline X pm t_{0.025} {s over sqrt{n}} &= 5.5% pm 2.262 {10% over sqrt {10}} \ &= 5.5% pm 2.262(3.162) \ &= 5.5% pm 7.15% end{aligned} )
Доверительный интервал для среднего по совокупности охватывает значения -1.65% до + 12,65%.
Мы предположили, что в этом примере размер выборки достаточно мал по сравнению с размером клиентской базы, поэтому мы можем пренебречь поправкой для конечной совокупности.
Менеджер может быть уверен на 95%, что этот диапазон включает в себя среднее значение по совокупности.
Решение для части 2:
В Таблице 4 приведены расчеты для выборок трех размеров.
|
Распределение |
95% доверительный интервал |
Нижняя граница |
Верхняя граница |
Относительный размер |
|---|---|---|---|---|
|
( t(n = 10) ) |
(5.5% pm 2.262(3.162) ) |
-1.65% |
12.65% |
100.0% |
|
( t(n = 20) ) |
(5.5% pm 2.093(2.236) ) |
0.82 |
10.18 |
65.5 |
|
( t(n = 30) ) |
(5.5% pm 2.045(1.826) ) |
1.77 |
9.23 |
52.2 |
Решение для части 3:
Ширина доверительного интервала уменьшается по мере увеличения размера выборки. Это уменьшение является функцией стандартной ошибки, которая становится меньше при увеличении (n).
Коэффициент надежности также становится меньше, так как число степеней свободы возрастает.
В последней колонке Таблицы 4 показан относительный размер ширины доверительных интервалов, если принять (n = 10 ) за 100%. Размер выборки 20 уменьшает ширину доверительного интервала до 65.5% от ширины интервала для размера выборки 10.
При размере выборки 30 ширина интервала сокращается почти в два раза. На основе этих данных, инвестиционный менеджер получил бы наиболее точные результаты, используя размер выборки 30.
Рассмотрев многие из фундаментальных понятий статистической выборки и оценки, мы можем сосредоточить внимание на вопросах отбора выборки, представляющих особый интерес для финансовых аналитиков. Качество выводов зависит от качества данных, а также от качества используемого плана выборки.
Финансовые данные создают особые проблемы, и планы выборки часто отражают одну или несколько систематических ошибок (смещений). В следующем разделе этого чтения обсуждаются эти вопросы.
Размер ошибки выборки прежде всего зависит от объема выборочной совокупности N. Средняя ошибка выборки обратно пропорциональна![]() (например, при увеличении объема выборки в четыре раза, ее ошибка уменьшается в только в два раза). Таким образом, увеличение объема выборки приводит к снижению ошибки выборки, но, с другой стороны, вызывает дополнительные расходы на проведение исследования.
(например, при увеличении объема выборки в четыре раза, ее ошибка уменьшается в только в два раза). Таким образом, увеличение объема выборки приводит к снижению ошибки выборки, но, с другой стороны, вызывает дополнительные расходы на проведение исследования.
При планировании выборочного наблюдения обычно заранее задают допустимую ошибку выборки и доверительную вероятность, чтобы обеспечить заданную точность результатов наблюдения.
Найдем оптимальный объем выборки для нахождения выборочной средней (случайный повторный отбор) при заданных предельной ошибке выборки ![]() и доверительной вероятности A. Согласно (5.4) и (5.8)
и доверительной вероятности A. Согласно (5.4) и (5.8)
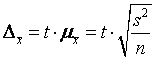 .
.
Отсюда оптимальный объем выборки N
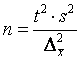 . (5.10)
. (5.10)
В таблице приведены формулы для расчета оптимального размера выборки (случайный отбор).

Эти формулы должны использоваться на этапе планирования выборочного наблюдения, однако в них необходимо указывать неизвестные нам значения выборочной дисперсии S2 и выборочной доли W. Вместо них на практике рекомендуется использовать какие-либо приближенные оценки этих характеристик (например, полученные в результате пробных выборочных наблюдений или из предыдущих обследований аналогичной совокупности). Кроме того, часто неизвестное значение W заменяют значением 0,5. Если известна примерная величина генеральной средней, то иногда используют приближенную формулу 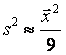 . Если известна примерная величина размаха совокупности, то можно использовать приближенную формулу
. Если известна примерная величина размаха совокупности, то можно использовать приближенную формулу 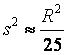 .
.
E Эти приближенные формулы можно использовать ТОЛЬКО ПРИ ОТСУТСТВИИ БОЛЕЕ ТОЧНЫХ ДАННЫХ, полученных в результате пробных выборочных обследований или из предыдущих обследований аналогичной совокупности.
E При больших размерах генеральной совокупности оптимальный объем выборки при повторном и бесповторном отборе отличаются незначительно.
| < Предыдущая | Следующая > |
|---|

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
Ошибка выборки — определение, типы, контроль и уменьшение ошибок
Опубликовано 2023-02-11 19:54 пользователем

Что такое ошибка выборки?
Ошибка выборки возникает, когда выборка, используемая в исследовании, не является репрезентативной для всей популяции. Ошибки выборки случаются часто, поэтому исследователи всегда рассчитывают предел ошибки при получении окончательных результатов в качестве статистической практики. Предел погрешности — это величина погрешности, допустимая при неправильном расчете, представляющая собой разницу между выборкой и реальной популяцией.
Выберите своих респондентов
Каковы наиболее распространенные ошибки выборки в маркетинговых исследованиях?
Вот четыре основные ошибки маркетинговых исследований при составлении выборки:
- Ошибка спецификации популяции: Ошибка спецификации популяции возникает, когда исследователи не знают, кого именно нужно опросить. Например, представьте себе исследование, посвященное детской одежде. Кого нужно опросить? Это могут быть оба родителя, только мать или ребенок. Родители принимают решение о покупке, но дети могут повлиять на их выбор.
- Ошибка выборочной совокупности: Ошибки выборочной совокупности возникают, когда исследователи неправильно ориентируются на субпопуляцию при отборе выборки. Например, выборка из телефонного справочника может иметь ошибочные включения, поскольку люди меняют свои города. Ошибочные исключения происходят, когда люди предпочитают не указывать свои номера. Богатые домохозяйства могут иметь более одного подключения, что приводит к многократным включениям.
- Ошибка отбора: Ошибка отбора происходит, когда респонденты сами выбирают себя для участия в исследовании. Отвечают только те, кто заинтересован. Ошибки отбора можно контролировать, если сделать дополнительный шаг и запросить ответы у всей выборки. Планирование перед опросом, последующие действия и аккуратный и чистый дизайн опроса повысят процент участия респондентов. Кроме того, попробуйте такие методы, как CATI-опросы и личные интервью, чтобы максимизировать количество ответов.
- Ошибки выборки: Ошибки выборки возникают из-за неравномерной репрезентативности респондентов. В основном это происходит, когда исследователь не планирует тщательно свою выборку. Эти ошибки выборки можно контролировать и устранять, создавая тщательный план выборки, имея достаточно большую выборку, отражающую все население, или используя для сбора ответов онлайн-выборку или аудиторию опроса.
Контроль ошибки выборки
Статистические теории помогают исследователям измерить вероятность ошибки выборки в зависимости от размера выборки и населения. Размер выборки, рассматриваемой из совокупности, в первую очередь определяет размер ошибки выборки. При больших размерах выборки вероятность ошибки ниже. Для понимания и оценки погрешности исследователи используют метрику, известную как предел погрешности. Обычно желаемым уровнем достоверности считается уровень достоверности в 95%.
Про совет: Если вам нужна помощь в расчете собственного предела погрешности, вы можете воспользоваться нашим калькулятором предела погрешности.
Каковы шаги по сокращению ошибок выборки?
Ошибки выборки легко выявить. Вот несколько простых шагов по уменьшению ошибки выборки:
- Увеличение размера выборки: Больший размер выборки дает более точный результат, поскольку исследование приближается к реальному размеру популяции.
- Разделение популяции на группы: Тестируйте группы в соответствии с их размером в популяции вместо случайной выборки. Например, если люди определенной демографической группы составляют 20% населения, убедитесь, что ваше исследование состоит из этой переменной, чтобы уменьшить смещение выборки.
- Знать свое население: Изучите свое население и поймите его демографический состав. Знайте, какие демографические группы используют ваш продукт и услугу, и убедитесь, что вы нацелены только на ту выборку, которая имеет значение.
Мы также создали инструмент, который поможет вам легко определить вашу выборку: Калькулятор размера выборки.
Ошибка выборки поддается измерению, и исследователи могут использовать ее в своих интересах, чтобы оценить точность своих выводов и оценить дисперсию.
Рубрика:
- Бизнес
Ключевые слова:
- аудитория
Автор:
- Dan Fleetwood
Источник:
- questionpro
Перевод:
- Дмитрий Л