
Вся прелесть и ужас VDDK ошибок в том, что, с одной стороны, совершенно точно понятно, где сломалось, а с другой — совершенно непонятно, почему, и как это теперь чинить. Это примерно как RPC call function failed в мире Windows.
Хотя не всё так ужасно, конечно же. Некоторые ошибки имеют совершенно конкретные причины и методы лечения. А некоторые — давно известный список наиболее частых причин и вариантов их исправления.
Наш Veeam Technical Support, конечно же, накапливает в себе подобные знания, и сегодня мы немного подглядим в их записи. Поэтому с превеликим удовольствием представляю вам топ самых частых VDDK errors и методы их устранения.
VDDK errors. Что это и как они получаются?
Как можно догадаться из названия, это какие-то проблемы на уровне VDDK Api (Virtual Disk Development Kit) — лучшего способа взаимодействия с vSphere инфраструктурой. Не важно, будет это отдельный ESXi хост или развесистый vCenter, но если нам надо что-то записать или считать из нашей инфраструктуры, лучший способ для этого — бесплатно распространяемый VDDK.
Если максимально упростить, то выглядит это взаимодействие примерно так: Veeam сервер хочет, например, что-то прочитать с хоста (или записать) и шлёт ему соответствующий запрос. Создаётся вызов на чтение с указанием, из какого диска, сколько хочется прочитать, с какого оффсета и в какой буфер в памяти. Или записать, аналогично, из указанного буфера. Всё просто.
Но это в идеальном мире.
В реальном же иногда на пути этого простого алгоритма случаются ошибки, из-за которых не получается завершить запрос. И вместо ожидаемого ответа к нам приходит номер ошибки, который тщательно записывается в логи.
Вот о самых частых таких ошибках мы сегодня и поговорим
Важный дисклеймер!
Не уверен — не делай! Не нажимай и вообще ничего не трогай! Позвонить или написать в саппорт Veeam всегда лучше, чем ставить эксперименты на своём проде. Благо саппорт у нас русскоязычный и технических крайне грамотный.
При малейших сомнениях позвонить и спросить: «У меня вот такая проблема, я нашёл в сети вот такой вариант решения, это поможет мне её решить?» — нормально и правильно. Что не нормально и не правильно, так это будучи не уверенным в своих действиях наворотить дел, а потом просить восстановить всё из руин за пять минут, и чтобы ничего не потерялось.
Да, мы, конечно же, поможем и в этом случае, но лучшая битва — та, которой не было. Поэтому всегда старайтесь критически оценивать свои действия, и всем большого аптайма.
VDDK error 1: Unknown error
На самом деле по этой ошибке у нас есть целая КВ статья. И, как она гласит, чаще всего эта ошибка возникает, если у вас установлено слишком много счётчиков производительности — и скачайте патч от VMware, который вам всё поправит.
С одной стороны, даже и комментировать нечего. Вот проблема, вот описание (пусть даже не очень понятное), и, что самое важное — вот вам ещё и ссылка на лекарство. Однако не всё так просто. По нашим наблюдениям, эта ошибка может возникать не только из-за скучной проблемы со счётчиками, но также из-за:
- Повреждения конкретного VMDK файла. То есть машина ваша вот прямо сейчас работает, но возможно, что скоро перестанет. Или — классический случай — вы её выключите и больше не сможете включить. Словом, приятного вас ожидает мало. Да, есть всякие тулы для проверки целостности и коррекции ошибок, однако это не панацея.
- Повреждения всего datastore. Тут даже и комментировать ничего не хочется. Надеемся, у вас есть запасной.
- Проблема с HBA контроллером. Да, проблемы идут по нарастающей. Хорошо если это просто плата сгорела и всё ограничится заменой с проверкой рейда. А если рейд был повреждён и его придётся пересчитывать?
- И самая безобидная, но тоже причина: ESXi хост периодически теряет связь с vCenter.
Ну хорошо, жути нагнал, скажете вы. А дальше-то что? Как понять, что пора срочно бежать за новыми дисками — или достаточно поставить патчик и выдыхать?
А я вам отвечу — держите набор простейших тестов, которые в случае чего помогут вам принять правильное решение.
- Запускаем Storage vMotion или просто клонируем подозрительную машину на другой датастор, а потом пытаемся запустить бекап. Если клонирование не прошло — однозначно беда где-то в дисковой подсистеме. Режим паранойи на максимум — и проверять всё, от дисков до контроллеров.
Если клонировалось и забекапилось успешно, значит, был повреждён VMDK, т. к. во время клонирования VMware пересоздаёт его содержимое, и теперь там точно нет ошибок.
- Были случаи, когда перезагрузка хоста лечила проблему. Да, это не шутка. «Семь бед — один ресет» всё ещё актуально.
- Если вы уже и перезагрузились, и патч поставили, и машину клонировали, и всё равно ничего не работает — бегом в саппорт VMware.
- Если клонированная машина успешно забекапилась, попробуйте мигрировать её обратно на продакшн сторадж и продолжайте использовать вместо старой. Можно даже делать это ночью на выключенных машинах, чтобы процесс прошёл быстрее и по пути ничего не потерялось.
VDDK error 2: Value: 0x0000000000000002
Практически всегда идёт рука об руку с VDDK error 1. По нашей статистике, появление ошибки обычно связано с определёнными версиями связки vCenter/ESXi, так что лучший совет здесь — это обновиться хотя бы до версии 6.7. А лучше и 7.0.
Если же не помогло, то переходим к плану Б.
Сама ошибка появляется, когда у ESXi хоста заканчивается память, выделенная под буфер NFC read. По умолчанию, Veeam работает в асинхронном режиме чтения NBD/NFC, что в нормальных условиях может потребовать расширения этого буфера. Но происходит это не всегда. Поэтому для отключения данного режима есть специальный ключик:
Name: VMwareDisableAsyncIo
Path: HKEY_LOCAL_MACHINESOFTWAREVeeamVeeam Backup and Replication
Type: REG_DWORD
Value: 1После его создания надо перезапустить Veeam Backup Service и быть готовым к производительности, просевшей примерно на 10%.
Другой вариант — это зайти со стороны хоста и перезапустить management агентов:
/etc/init.d/hostd restart
/etc/init.d/vpxa restartПодробно процедура описана в КВ от VMware, так что не будем её переписывать.
И стандартный набор вариантов, которые не будет лишним перебрать в процессе диагностики:
- Мигрировать машины с ошибками на другой хост.
- Попробовать другой Transport mode — HotAdd с виртуальным прокси или DirectSAN.
VDDK error 3: One of the parameters is invalid
Ошибка, практически всегда случающаяся при использовании Virtual Appliance режима (он же HotAdd mode).
Тут особенно рассказывать нечего, просто дам ссылки на две наших KB, где расписано много вариантов, и даже если вы сразу придёте в саппорт, вас попросят проделать всё там написанное.
КВ1218 — Общее описание возможных проблем и методы их устранения.
KB1332 — В случае если ваш Veeam сервер работает как прокси для HotAdd режима
VDDK error 13: You do not have access rights to this file
И на этот случай у нас имеется KB2008. Да, там очень много вариантов устранения этой беды, но такая уж ошибка. Однозначно сказать, что именно случилось именно в вашем случае, практически невозможно, поэтому надо брать и перебирать весь список.
Что хочется сказать дополнительно. Очень внимательно относитесь к секции Additional Troubleshooting. Да, там написаны, возможно, слишком очевидные для многих вещи. Но даже такие банальности ускользают от взгляда самых профессиональных профессионалов. Нередки случаи, когда спустя неделю в попытках решить всё самостоятельно они приходят в саппорт только лишь для того, чтобы узнать, что невнимательно прочитали список технических требований, или нечто такое. И обидно, и жалко потраченного времени.
И два совета на все времена:
- Если машина с ролью Veeam proxy была хоть раз клонирована или реплицирована, у её клонов мог сохраниться UUID оригинальной машины. Из-за чего диски временно маунтятся хостом к одной машине, а читать мы их пытаемся с другой. Да, звучит странно, но бывает и такое.
- Если реплицированная машина выключена (а это нормально для реплик — быть выключенными), само собой, все VDDK вызовы и попытки присоединиться будут обречены на провал.
VDDK error 18000: Cannot connect to the host
В большинстве случаев вина за эту ошибку лежит на баге в самом VDDK. А конкретно виновата библиотека gvmomi.dll. И проявляет он себя только под большой нагрузкой. Например, когда много машин бекапится в параллельном режиме, одна из функций принимает значение 0, и библиотека может схлопнуться. А следом падает всё остальное.
Такая вот печальная история.
Но самое плохое в этой истории — то, что никак не получается точно воспроизвести условия возникновения бага. Это то, что тестировщики называют плавающими багами. Поэтому невозможно точно сказать, сколько именно параллельно обрабатываемых машин вызывает падение.
Однако согласно официальным release notes это баг был полностью исправлен. Так что правильный выход из положения — обновить свой хост. Но если по какой-то из причин сделать это невозможно, единственное, чем мы можем помочь — это посоветовать уменьшить количество одновременно обрабатываемых машин.
Больше никак.
VDDK error 14008: The specified server could not be contacted
Итак, если вас постигла эта беда, то первым делом надо проверять сеть. Скорее всего, сбоит связь между vCenter и Veeam proxy. Смотрим, все ли порты открыты и доступны, все ли DNS имена правильно резолвятся в ожидаемые IP адреса. Причём проверять надо конкретный прокси, задействованный в неудавшейся джобе, а не стоящий рядом точно такой же (бывают случаи).
95% кейсов с этой ошибкой закрываются с пометкой «Проблема с DNS/портами в инфраструктуре клиента».
Поэтому ещё раз призываю вас очень внимательно проверить, везде ли указан верный DNS сервер, нет ли закрытых портов и в какие IP резолвятся FQDN имена.
В старых версиях VDDK была схожая ошибка, возникавшая при использовании недефолтного порта для работы с vCenter, на которую приходились оставшиеся 5%, но сейчас VMware скрыло КВ с её описанием, что, вероятно, означает, что КВ более не релевантна. Но можете поискать её в интернет-архивах по номеру 2108658 (Backup fails when a non-default port is specified for VMware vCenter Server).
VDDK error 14009: The server refused connection
И последняя ошибка в нашем сегодняшнем топе — The server refused connection. Тут всё абсолютно банально: что-то мешает установить связь между хостом и прокси. В большинстве случаев оказывается виноват фаервол. Но — тонкий момент — не из-за закрытых портов, а из-за вносимых задержек. Так что первым делом проверяем открытость порта 443, а потом смотрим на таймауты.
Если оба варианта ничего не дали — идём в саппорт. Придётся проверять сам хост. Возможно, он просто слишком загружен и не успевает отвечать вовремя, а, возможно, и что-то другое.
И в завершение немного полезных ссылок:
- Портал нашей орденоносной технической поддержки.
- Veeam Support Knowledge Base

In this blog, I discuss Veeam’s SAN mode configuration which delivers optimal data transport. However, ensuring that SAN mode is utilized can be sometimes challenging. I will provide details about the SAN mode setup and how to avoid common pitfalls.
Before we jump into configuration let us see what is SAN mode and NBD(Network) mode.
Direct SAN
Direct SAN access transport mode is best suited for Virtual Machines with disks located on shared VMFS volumes which are connected to ESXi hosts over iSCSI or FC protocols. In this case, Veeam uses VMware’s VADP (VMware vSphere Storage APIs – Data Protection) to move the VM data (vmdk files) directly from and to FC and iSCSI shared storage over the SAN. VM data moves through the SAN, circumventing ESXi hosts and the LAN. See Figure 1.)
Figure 1.
Network Mode
In Network mode, data is transferred via the ESXi host over LAN using the Network Block Device protocol (NBD). The network mode is not recommended due to potential network bandwidth constraints and utilization resulting in low data transfer speeds extending backup and restore times.
SAN And Network Mode Tests
We performed performance testing with Veeam version 9.5 by backing up and restoring a single large virtual machine with direct SAN and network modes.
The test results are shown below. Backing up the same virtual machine over SAN resulted in 4 to 5 times faster job processing speed as compared to network mode.
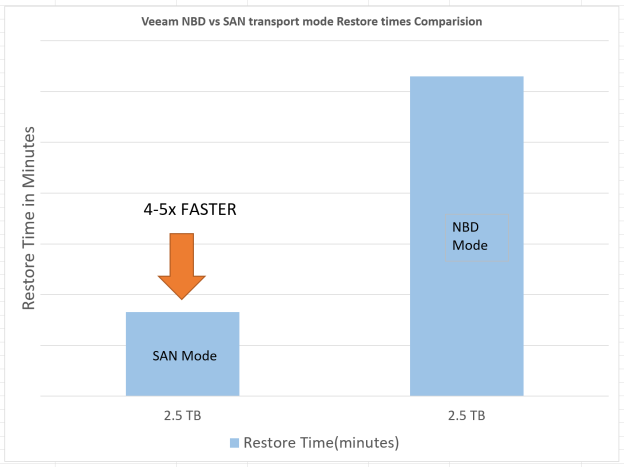
Figure 2
Configuring Direct SAN Access Mode for Backup
In order to use the Direct SAN access mode, make sure that the following requirements are met:
- In order to get the best performance, always use a physical backup proxy in Direct SAN access mode. If your backup proxy is a VM, performance may not be optimal. Please see below:
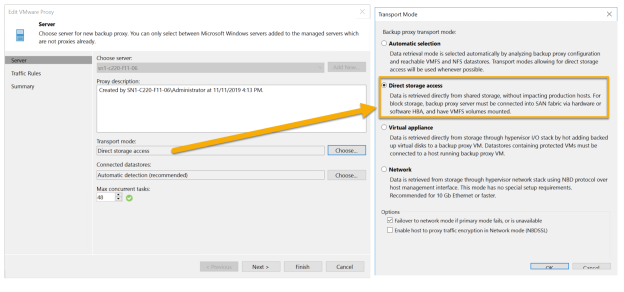
Figure 5
- A backup proxy using the Direct SAN access mode must have direct access to the production storage via a hardware or software HBA. It is highly recommended to use Pure Storage snapshots for backups. FlashArray
 snapshots are instantaneous and do not stun the VM(slow down the VM). See the advanced settings for the backup job below (Figure 6), to ensure the backup job uses storage snapshots for backups.
snapshots are instantaneous and do not stun the VM(slow down the VM). See the advanced settings for the backup job below (Figure 6), to ensure the backup job uses storage snapshots for backups.
 snapshots are instantaneous and do not stun the VM(slow down the VM). See the advanced settings for the backup job below (Figure 6), to ensure the backup job uses storage snapshots for backups.
snapshots are instantaneous and do not stun the VM(slow down the VM). See the advanced settings for the backup job below (Figure 6), to ensure the backup job uses storage snapshots for backups.
Figure 6.
Configuration Direct SAN Access Mode for Restore
- The VMware datastores underneath the SAN volumes have to be presented to the proxy server OS in offline mode. If initialized it may cause the VMFS file system to be overwritten by NTFS which can corrupt the data. See Figure 7 for an example of a data store’s SAN volume presented to Veeam proxy’s OS as an Offline volume.
Figure 7.
- The VMware datastore disk presented to the OS (Step 3) should have write access. Sometimes the backup or restore job will switch to NBD mode or will fail with the following error during restore job:
Restore job failed Error: VDDK error: 16000 (One of the parameters supplied is invalid).
To solve this problem clear the read-only attributes of the disk using diskpart.
- Only “Thick Provision Lazy Zeroed” and “ThickProvision Eager Zeroed” VM disks can be used in Direct SAN mode. See Figure 8.
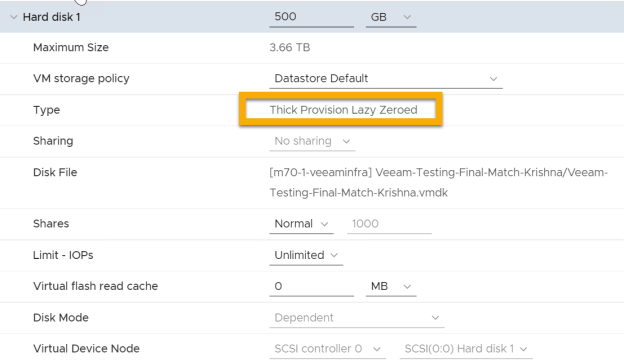
Figure 8.
- SAN access mode cannot be used for incremental restore due to VMware limitations. Disable the CBT for VM virtual disks for the duration of the restore process by setting ctkEnabled to False in Advanced VM configuration parameters. See Figure 9.

Figure 9.
Direct SAN Mode Limitations
Direct SAN access mode is not supported for VMs using vSAN. VVols based virtual machines are not supported either. In these cases, it is suggested to use Virtual appliance or network transport modes. If these limitations don’t apply we would highly recommend you SAN mode to get the best performance with Veeam software.
Summary
As we have seen SAN mode is the fastest transport mode available in Veeam. By utilizing high bandwidth in SAN and FlashArray instantaneous volume snapshots, and avoiding transferring data via ESXi host, the backup and restore window can be significantly shortened, resulting in improved recovery time objective (RTO).
APAR status
-
Closed as program error.
Error description
-
Backup of Virtual Machines (VMs) based on Virtual Volumes (VVOL) datastores may fail with the following error: ERROR, <timestamp>, CTGGA2649,Backup of virtual machine <VMName> has failed. Error: One of the parameters supplied is invalid (evddk-16000) Additionally in the VADP proxy log the following info is presented: <timestamp> [I] <VDDK> VixDiskLib: VixDiskLibQueryBlockList: Fail to query blocks (offset 0, chunkSize 4096, chunkNumber 256000). Error 16000 (One of the parameters supplied is invalid) (DiskLib error 1: One of the parameters supplied is invalid) at 591. <timestamp> [E] QueryAllocatedBlocks failed for disk [<datastore>] <VMName>/<VMName>.vmdk,(Handle:0x7f1870009e80). startSector:0. numSectors:1048576000. Error:One of the parameters supplied is invalid (evddk-16000) The issue may not affect all VMDKs. It can occur on individual VMDK, while the rest are OK. | MDVREGR 10.1.7.0-TIV_5737SPLUS | IBM Spectrum Protect Versions Affected: IBM Spectrum Protect Plus 10.1.8 Additional Keywords: SPP, SPPLUS, TS006348021, evddk-16000
Local fix
Problem summary
-
**************************************************************** * USERS AFFECTED: * * IBM Spectrum Protect Plus level 10.1.8 * **************************************************************** * PROBLEM DESCRIPTION: * * See ERROR DESCRIPTION * **************************************************************** * RECOMMENDATION: * * Apply fixing level when available. This problem is currently * * projected to be fixed in IBM Spectrum Protect Plus level * * 10.1.8 ifix2 and 10.1.9. Note that this is subject to change * * at the discretion of IBM * ****************************************************************
Problem conclusion
-
This problem has been fixed so that after encountering condition of failing on querying allocated blocks, the new behavior is that alternative approach will be used so that backup can proceed successfully.
Temporary fix
Comments
APAR Information
-
APAR number
IT38050
-
Reported component name
SP PLUS
-
Reported component ID
5737SPLUS
-
Reported release
A18
-
Status
CLOSED PER
-
PE
NoPE
-
HIPER
NoHIPER
-
Special Attention
NoSpecatt / Xsystem
-
Submitted date
2021-08-18
-
Closed date
2021-08-27
-
Last modified date
2021-08-27
-
APAR is sysrouted FROM one or more of the following:
-
APAR is sysrouted TO one or more of the following:
Modules/Macros
-
Hypervis VMware
Fix information
-
Fixed component name
SP PLUS
-
Fixed component ID
5737SPLUS
Applicable component levels
[{«Line of Business»:{«code»:»LOB26″,»label»:»Storage»},»Business Unit»:{«code»:»BU058″,»label»:»IBM Infrastructure w/TPS»},»Product»:{«code»:»SSNQFQ»,»label»:»IBM Spectrum Protect Plus»},»Platform»:[{«code»:»PF025″,»label»:»Platform Independent»}],»Version»:»A18″}]
Copyright © SEP AG 1999-2023. All rights reserved.
Any form of reproduction of the contents or parts of this manual is allowed only with the express written permission from SEP AG. When compiling and designing user documentation SEP AG uses great diligence and attempts to deliver accurate and correct information. However, SEP AG cannot issue a guarantee for the contents of this manual.
VMware vStorage API
SEP sesam version > 4.4.3.22
Backup
Virtual machines residing on NFS storage are unresponsive during a backup
Problem
- When using NFSv3 to mount NFS data stores and performing VMware backup in HotAdd transport mode, the VM that is backed up is not reachable for approx. 30 seconds when the HotAdd data mover detaches the VMDK.
Cause
- This issue occurs when the target VM and the data mover are running on two different hosts (ESXi), and the NFSv3 protocol is used to mount NFS data stores.
⇒ Solution
- To avoid this problem, the VMware data mover and VM have to run on the same ESXi.
- Use the NFSv4 protocol to mount NFS data stores.
VMware vSphere backup on Linux fails due to VDDK error
Problem
- A VMware vSphere backup (on the SEP sesam Server or RDS) on Linux fails with the following error:
Load VDDK library failed: Cannot load: libvixDiskLib.so
Cause
- The VMware Virtual Disk Development Kit (VDDK) is not installed.
VMware backup or browsing of VMware vCenter fails with an error due to a Java VM security restriction
Problem
- VMware backup or browsing of VMware vCenter might fail with the following error:
Error: VM Exception: [VI SDK invoke exception:javax.net.ssl.SSLHandshakeException: java.security.cert.CertificateException: Certificates does not conform to algorithm constraints].
Cause
- Due to advanced security settings, the Java virtual machine does not allow connection to VMware vCenter.
⇒ Solution
- To avoid the Java virtual machine security restriction, proceed as follows:
- On your SEP sesam Server, locate the following file in the Java installation directory:
- Once done, restart the SEP sesam service.
JDK_HOME/jre/lib/security/java.security
Then change the line
jdk.certpath.disabledAlgorithms=MD2, RSA > 1024
to
jdk.certpath.disabledAlgorithms=
Segmentation fault during VMware backup on Linux-based data movers
Problem
- VM backup on Linux-based data mover completed successfully, however a segfault event is recorded.
Cause
- This is the VMware library issue caused by the missing /sys/class/scsi_disk directory on the Linux system.
⇒ Solution
- Before executing the VMware backups on Linux-based data movers, use the modprobe command
modprobe sd_modto load the sd_mod kernel module and make the /sys/class/scsi_disk directory available.
VMware slow backup performance via NBD. OR: Backups are failing in SAN transport mode with VMs residing on VMFS 6.0
Problem
- Slow backup performance via NBD. Another problem is that backups might fail in SAN transport mode.
Cause
- vSphere 6.5 and 6.7 may have slow backup performance via NBD with VDDK 6.0.x due to the VMware policy concerning backward and forward compatibility for VDDK to support N-2 and N+1 releases.
- With vSphere 6.5 neither of VDDK 6.0.x versions provides SAN transport support when using datastores formatted with new VMFS 6.0 filesystem. Consequently, the backup will fail.
⇒ Solution
- On Windows, VDDK is installed automatically during the SEP sesam installation. However, if you use a new vSphere version you should check the VDDK Compatibility Matrix to find its corresponding VDDK version and install it manually, if required.
- On Linux, you have to install the required VDDK version manually. Note that every new release of vSphere has a corresponding VDDK version; typically, the version number of VDDK matches the version number of vSphere.
For details on the required version, see VDDK Compatibility Matrix.
VMware backup fails with error due to unrecognized extended LUN connected to a Linux data mover
Problem
- VMware backup fails with error, such as:
Error while reading data. Error: VixDiskLib: VixDiskLib_Read: Read 2048 sectors at 0 failed. Error 16000 (One of the parameters supplied is invalid) (DiskLib error 4096062: One of the parameters supplied is invalid) at 5024.
Cause
- On the Linux data mover in VMware environments, when you extend LUN while online (without restarting your Linux system), the extended LUN will not be instantly visible from the Linux operating system. The extended disk is automatically adjusted on Windows, while on Linux you need to rescan SCSI bus manually. Consequently, the backup will fail.
⇒ Solution
- To rescan SCSI bus on Linux without restarting it, use the following command when adding a new disc (X is the number of SCSI host to scan):
echo “- – -” > /sys/class/scsi_host/hostX/scan
- Use the following command when expanding an existing disc:
echo 1 > /sys/class/scsi_device/device/rescan
Single file restore
Mounting VMware saveset on Linux fails with error
Problem
- Mounting VMware saveset (on the SEP sesam Server or RDS) on Linux fails with an error, for example:
Client mount tools not installed
Cause
- The guestmount tool is not installed on the Linux host.
⇒ Solution
- To be able to access and mount the file system of an image on Linux, you have to use use the guestfs-tools. Install the guestfs-tools package as described in Installing guestfs-tools on Linux.
Single file restore is not working with VMware 6.0
Problem
- When restoring single files on VMware 6.0, the restore fails with: Cannot open Thin/TBZ disks in a multiwriter mode.
This log is also shown in the vCenter events.
Cause
- This error appears if the SCSI bus sharing type on the proxy machine is set to Physical.
⇒ Solution
- Shut down the proxy machine and change the type of SCSI bus sharing to None, so the virtual disks cannot be shared by other virtual machines.
When restoring a single file, SEP sesam cannot access storage on a VM that is configured with the SCSI LSI Logic SAS adapter
Problem
- In SEP sesam version ≥ 4.4.3.48 in combination with a Linux proxy VM, when trying to select the restore source in the restore wizard (step 4: Select Files), no items are displayed in the browser.
Cause
- This issue seems to be related to the SCSI controller of the proxy VM. When trying to restore a single file from a virtual machine, SEP sesam cannot access storage on a virtual machine that is configured with the SCSI LSI Logic SAS adapter.
⇒ Solution
- Open the properties of the proxy VM in your vCenter and change the controller on the VM from the LSI Logic SAS controller (on some VMs, this is selected by default) to an LSI Logic Parallel controller.
For more information, see VMware Docs article Change the SCSI Controller Type in the vSphere Client.
- Restart the restore wizard. If there are still no items displayed in the restore browser, reboot the proxy VM and then click the Update button.
After updating an existing SEP sesam structure with a new VDDK version, it is no longer possible to mount a VMDK
Problem
- After VDDK ≥ 6.5.x has been manually installed on Windows, it is no longer possible to mount a VMDK saveset on this host.
Cause
- If another VDDK version, for example VDDK ≥ 6.5.x, is manually installed on Windows, the host requires a reboot after the update if you want to mount a VMDK on this host.
⇒ Solution
- Reboot the host after the VDDK update, then run the following script from the command line:
vstor2install.bat in directory C:Program FilesVMwareVMware Virtual Disk Development Kitbin
Hard reset (offline via CLI)
Depending on SEP sesam version, use a relevant command for hard reset via CLI:
- For SEP sesam v. < 4.4.1.x, if a soft reset does not work or it is not available, use the following command for hard reset.
- As of SEP sesam v. 4.4.1.x, use this command for hard reset.
Example
sbc_vadp -b -a «action=resetcbt,server=ws2008x64,username=Administrator,password=secret»
«DC/linuxdbserver»
Example
sm_cmd resetcbt -S qsbox1 -d «SEP Cloud» -V «cosinus (SEP)» -m hard
The virtual machine must be powered off for this action.
CBT reset via the vSphere client
- Alternatively, a CBT-reset can be performed via the vSphere client:
Online
- The virtual machine does not need to be shut down to reset CBT:
- Open the properties of the affected virtual machine from Tasks > By Clients.
- Uncheck Enable Change Block Tracking (CBT) and save the task.
- Create a snapshot via vSphere Client of the affected virtual machine (none of the ticks needs to be selected).
- Delete the snapshot that was created before.
- In SEP sesam, activate the CBT option in the VM client settings and start the VM backup.
Offline
- This step needs to be performed if a reset of CBT in online mode does not work. The virtual machine must be turned off for this step:
- Shut down the VM.
- Open the VMware Snapshot-Manager and delete all snapshots.
- Right-click VM -> Edit settings -> Options tab -> General -> Configuration Parameters.
- Set the value «ctkEnabled» to false.
- Set the value «scsi0:0.ctkEnabled» to false (NOTE: set the value to false for each disk).
- Open the folder where the VM *.VMDK files exists and delete all *-CTK.VMDK files
- Start the VM.
- Shut down the VM (this is required for the CTK table update).
- Start the VM again.
- In SEP sesam, activate the CBT option in the VM client settings and start the VM backup.—>
See also
VMware
Just started getting some errors in VMWare backups after VMs were storage vmotioned to a newly provisioned LUN.
The Datastore LUN is presented to my Media Agents and I have verified that I can see the LUN on the Media Agents.
Not all VMs on the LUN are having backup issues.
Netbackup 7.6.1.2 or RHEL
I get an error 6 in the Activity Log after the snapshot has been created. The cleanup of the snapshot is successful.
10/23/2015 03:55:06 - Info nbjm (pid=22342) starting backup job (jobid=917452) for client NTBIUT01, policy test_blc, schedule Weekly_Full_Wed_1800
10/23/2015 03:55:06 - estimated 0 kbytes needed
10/23/2015 03:55:06 - Info nbjm (pid=22342) started backup (backupid=NTBIUT01_1445586906) job for client NTBIUT01, policy test_blc, schedule Weekly_Full_Wed_1800 on storage unit blc_copy1 using backup host lxnbumablcp01.conseco.bak
10/23/2015 03:55:07 - started process bpbrm (pid=26518)
10/23/2015 03:55:07 - connecting
10/23/2015 03:55:07 - connected; connect time: 0:00:00
10/23/2015 03:55:10 - begin writing
10/23/2015 03:55:49 - end writing; write time: 0:00:39
10/23/2015 03:57:14 - Info bpbrm (pid=26518) NTBIUT01 is the host to backup data from
10/23/2015 03:57:14 - Info bpbrm (pid=26518) reading file list for client
10/23/2015 03:57:14 - Info bpbrm (pid=26518) starting bpbkar on client
10/23/2015 03:57:14 - Info bpbkar (pid=26521) Backup started
10/23/2015 03:57:14 - Info bpbrm (pid=26518) bptm pid: 26522
10/23/2015 03:57:14 - Info bptm (pid=26522) start
10/23/2015 03:57:15 - Info bptm (pid=26522) using 262144 data buffer size
10/23/2015 03:57:15 - Info bptm (pid=26522) using 30 data buffers
10/23/2015 03:57:16 - Info bptm (pid=26522) start backup
10/23/2015 03:57:49 - Critical bpbrm (pid=26518) from client NTBIUT01: FTL - cleanup() failed, status 6
10/23/2015 03:57:51 - Error bptm (pid=26522) media manager terminated by parent process
10/23/2015 03:57:56 - Info bpbkar (pid=0) done. status: 6: the backup failed to back up the requested files
the backup failed to back up the requested files (6)
We did note this in the logs
EMCPOWER emcpower_parse_devname : /nbcm_builds/NB/7.6.1.2/src/vxms/plugin/platforms/linux/osdep_emcpower.c.70 <INFO> : emcpower_parse_devname: is returning with ERROR
10/22/2015 23:55:50 : vdRead:VixInterface.cpp:693 <ERROR> : Error 17592452332404352 in read with disk handle 46659552 startSector 0 numSectors 1
10/22/2015 23:55:51 : readFlatSector:VixGuest.cpp:2500 <ERROR> : vdRead failed with error [16000] for [[vmd-pi-526] NTBIUT01/NTBIUT01.vmdk]. Issuing retry 1 of 3
10/22/2015 23:55:55 : vdRead:VixInterface.cpp:693 <ERROR> : Error 17592452332404352 in read with disk handle 47317568 startSector 0 numSectors 1
10/22/2015 23:55:56 : readFlatSector:VixGuest.cpp:2500 <ERROR> : vdRead failed with error [16000] for [[vmd-pi-526] NTBIUT01/NTBIUT01.vmdk]. Issuing retry 2 of 3
10/22/2015 23:56:00 : vdRead:VixInterface.cpp:693 <ERROR> : Error 17592452332404352 in read with disk handle 49823232 startSector 0 numSectors 1
10/22/2015 23:56:01 : readFlatSector:VixGuest.cpp:2500 <ERROR> : vdRead failed with error [16000] for [[vmd-pi-526] NTBIUT01/NTBIUT01.vmdk]. Issuing retry 3 of 3
10/22/2015 23:56:05 : vdRead:VixInterface.cpp:693 <ERROR> : Error 17592452332404352 in read with disk handle 47381456 startSector 0 numSectors 1
10/22/2015 23:56:05 : readFlatSector:VixGuest.cpp:2506 <ERROR> : Exiting with error in reading sector 0x0000000000000000 with sector run 0x0000000000000001 from disk [vmd-pi-526] NTBIUT01/NTBIUT01.vmdk
10/22/2015 23:56:05 : resolvePartitions:VixGuest.cpp:2173 <ERROR> : Exited with VIX_PLG_EVDISKREAD
10/22/2015 23:56:05 : resolvePartitions:VixGuest.cpp:2174 <ERROR> : Returning: 1026
10/22/2015 23:56:05 : vixMapObjCtl:VixCoordinator.cpp:976 <ERROR> : Returning: 1026
10/22/2015 23:56:05 : vix_map_objctl:libvix.cpp:1206
Ran across this article https://www.veritas.com/support/en_US/article.TECH167193 but it deals more with an error code 13, not a 6.
Thoughts?
I’m using VDDK 6.0 build 3566099 to mount a 2TB Win 7 x64 guest on the U: drive of my test system (also a Win 7 x64 system).
In total I have 20 guests ranging from Win Vista x86-Win Svr 2016 x64 — all of which can successfully mount except for this one guest which is by far the largest.
I am using nbd transport to mount the image with open flags VIXDISKLIB_FLAG_OPEN_READ_ONLY.
I am able to execute VixDiskLib_GetInfo() on the image successfully, just unable to mount it. From logging it does appear to be failing at the creation of the local child disk .vmdk. VixDisk_Lib_CreateChild says one of the parameters is incorrect.
I’ve seen other postings regarding certain limits with VMWARE and the 2TB ceiling but not specifically with VDDK.
Is there possibly a workaround for this? I don’t want to create a disk, nor write to it — just mount RO.
Here is the output of my mount app:
childDiskName: C:7-childDisk-1.vmdk
Calling VixMntapi_Init()…
INFO: `anonymous-namespace’::VixMntapiReadTmpDirPath: Using tempDirectory C:VDDKtmp.
INFO: Mntapi_Init Asked — 2.2 Served — 2.2 was successful,TempDirectory: C:VDDKtmp.Calling VixDiskLib_Connect()…
INFO: VixDiskLib: VixDiskLib_Connect: Establish connection.
INFO: VixDiskLib: VixDiskLib_OpenEx: Open a disk.
INFO: VixDiskLibVim: VixDiskLibVim_GetNfcTicket: Get NFC ticket for [datastore2] Win 7 x64_1/Win 7 x64_1.vmdk.
INFO: VixDiskLibVim: Request RandomAccessRO diskKey = 2000, readOnly = 1, openSnapshot = 0.
INFO: VixDiskLibVim: VixDiskLibVim_FreeNfcTicket: Free NFC ticket.
INFO: NBD_ClientOpen: attempting to create connection to ha-nfc://[datastore2] Win 7 x64_1/Win 7 x64_1.vmdk@192.168.4.201:902
INFO: Started up WSA
INFO: Opening file [datastore2] Win 7 x64_1/Win 7 x64_1.vmdk (ha-nfc://[datastore2] Win 7 x64_1/Win 7 x64_1.vmdk@192.168.4.201:902)
INFO: DISKLIB-LINK : Opened ‘ha-nfc://[datastore2] Win 7 x64_1/Win 7 x64_1.vmdk@192.168.4.201:902’ (0x1e): custom, 4294967296 sectors / 2 TB.
INFO: DISKLIB-LIB : Opened «ha-nfc://[datastore2] Win 7 x64_1/Win 7 x64_1.vmdk@192.168.4.201:902» (flags 0x1e, type custom).
INFO: VixDiskLib: VixDiskLib_GetTransportMode: Retrieve transport mode.
Selected transport method: nbd
childDisks[0].c_str() C:7-childDisk-1.vmdk
INFO: VixDiskLib: VixDiskLib_CreateChild: Create a child disk.
INFO: DISKLIB-LIB_CREATE : CREATE CHILD: «C:7-childDisk-1.vmdk» — monolithicSparse grainSize=128 policy=»
INFO: DISKLIB-LIB_CREATE : CREATE-CHILD: Creating disk backed by ‘default’
INFO: DISKLIB-LIB_CREATE : Failed to create link: One of the parameters supplied is invalid (1)
INFO: DISKLIB-LIB_CREATE : DiskLib_CreateChild: failed to create child disk: One of the parameters supplied is invalid (1).
INFO: VixDiskLib: Detected DiskLib error 1 (One of the parameters supplied is invalid).
INFO: VixDiskLib: VixDiskLib_CreateChild: Unable to create child disk. Error 16000 (One of the parameters supplied is invalid) (DiskLib error 1: One of the parameters supplied is invalid) at 4408.
VixDiskLib_CreateChild() returned: 16000 (Disk Invalid): childDisks[0].c_str(): C:7-childDisk-1.vmdk
childDiskName: C:7-childDisk-1.vmdk
Calling VixMntapi_Init()…
INFO: `anonymous-namespace’::VixMntapiReadTmpDirPath: Using tempDirectory C:VDDKtmp.
INFO: Mntapi_Init Asked — 2.2 Served — 2.2 was successful,TempDirectory: C:VDDKtmp.Calling VixDiskLib_Connect()…
INFO: VixDiskLib: VixDiskLib_Connect: Establish connection.
INFO: VixDiskLib: VixDiskLib_OpenEx: Open a disk.
INFO: VixDiskLibVim: VixDiskLibVim_GetNfcTicket: Get NFC ticket for [datastore2] Win 7 x64_1/Win 7 x64_1.vmdk.
INFO: VixDiskLibVim: Request RandomAccessRO diskKey = 2000, readOnly = 1, openSnapshot = 0.
INFO: VixDiskLibVim: VixDiskLibVim_FreeNfcTicket: Free NFC ticket.
INFO: NBD_ClientOpen: attempting to create connection to ha-nfc://[datastore2] Win 7 x64_1/Win 7 x64_1.vmdk@192.168.4.201:902
INFO: Started up WSA
INFO: Opening file [datastore2] Win 7 x64_1/Win 7 x64_1.vmdk (ha-nfc://[datastore2] Win 7 x64_1/Win 7 x64_1.vmdk@192.168.4.201:902)
INFO: DISKLIB-LINK : Opened ‘ha-nfc://[datastore2] Win 7 x64_1/Win 7 x64_1.vmdk@192.168.4.201:902’ (0x1e): custom, 4294967296 sectors / 2 TB.
INFO: DISKLIB-LIB : Opened «ha-nfc://[datastore2] Win 7 x64_1/Win 7 x64_1.vmdk@192.168.4.201:902» (flags 0x1e, type custom).
INFO: VixDiskLib: VixDiskLib_GetTransportMode: Retrieve transport mode.
Selected transport method: nbd
childDisks[0].c_str() C:7-childDisk-1.vmdk
INFO: VixDiskLib: VixDiskLib_CreateChild: Create a child disk.
INFO: DISKLIB-LIB_CREATE : CREATE CHILD: «C:7-childDisk-1.vmdk» — monolithicSparse grainSize=128 policy=»
INFO: DISKLIB-LIB_CREATE : CREATE-CHILD: Creating disk backed by ‘default’
INFO: DISKLIB-LIB_CREATE : Failed to create link: One of the parameters supplied is invalid (1)
INFO: DISKLIB-LIB_CREATE : DiskLib_CreateChild: failed to create child disk: One of the parameters supplied is invalid (1).
INFO: VixDiskLib: Detected DiskLib error 1 (One of the parameters supplied is invalid).
INFO: VixDiskLib: VixDiskLib_CreateChild: Unable to create child disk. Error 16000 (One of the parameters supplied is invalid) (DiskLib error 1: One of the para
meters supplied is invalid) at 4408.
VixDiskLib_CreateChild() returned: 16000 (Disk Invalid): childDisks[0].c_str(): C:7-childDisk-1.vmdk