Наверняка я вам не открою Америки рассказом о том, что логи назвали логами из-за судовых журналов, куда записывали всякое интересное (и не очень), что происходило на корабле во время плавания. (Возможно, некоторые из вас не знают, но по воде ходят именно корабли, а судно — это в больнице. Хотя тут показания расходятся)))
Но не об этом мы сегодня. Сегодня мы поговорим о структуре логов в Veeam Backup & Replication, об их названиях и ожидаемом содержимом. Список будет большим, но не исчерпывающим, ибо всё описать — задача практически невозможная.

Как же подойти к процессу описания? Как вариант, можно рассказать, что некоторые логи лежат в папочках, а некоторые без папочек. Но это и так понятно, стало быть малоэффективно. Поэтому давайте начнём с незамысловатого факта, что мы в Veeam стараемся называть логи максимально прозрачно и придерживаться единой системы наименования. Так что начнём мы с не с грустных папочек, а с привязки логов к типам джоб. И первым делом рассмотрим довольно очевидный
Backup Job
Итак, логи любой уважающей себя джобы лежат в отдельной папке, повторяющей её название из GUI Veeam. Кстати, если в гуе это название изменить, то папка с логами не переименуется, ибо человекочитаемые названия — тлен, а id в базе вечны.
У любой джобы всегда и везде есть её самый главный лог, именуемый для простоты джобнОй лог (чистой воды жаргонизм, уж простите) Job.<job name>.Backup. В него уходит вся общая информация: когда запустилось, какие прокси назначены, что там с ретеншн, чем всё закончилось в конце, и всё такое прочее.
Любая добавленная в джобу виртуалка обрабатывается в рамках отдельной таски. Поэтому вся информация, относящаяся к обработке отдельной машины, пишется в отдельный лог Task.<vm name>.<vm id> Это позволяет избежать нечитаемого фарша в одном файле и разбираться с каждой отдельной машиной в случае провала. Из интересного можно отметить, что vm id сильно отличается от того, как машина была добавлена в джобу. Возможно, не все знают, но в инфраструктуре VMware каждый считает своим святым долгом выдать свой уникальный id виртуалке. Поэтому одна и та же машина будет иметь уникальный номер на уровне ESXi, другой уникальный номер — на уровне vCenter, третий уникальный номер — на уровне vCloud, и так далее. Поэтому понимать, на каком уровне абстракций вы находитесь, крайне важно. В случае Hyper-V всё проще — там всегда будет огромный GUID.
Далее идут агентские логи. Каждый агент выполняет свою некую маленькую задачу, позволяя в итоге случиться полноценному бекапу. Например, Agent.<job name>.Index — это логи агента, отвечающего за индексирование файлов, если в джобе была отмечена соответствующая опция. Если галочки нет, то лог файл создаваться не будет.
Немного примеров других агентских логов:
-
Agent.VddkHelper В этом логе отмечаются API вызовы, запрещающие и разрешающие vCenter мигрировать машину во время бекапа.
Сейчас самое время запомнить простое правило: если в названии лога есть слово Source, значит, это лог агента, который что-то откуда-то читает. Если видим в названии лога слово Target, значит, это лог агента, который что-то куда-то записывает. В большинстве случаев работают они в паре и позволяют однозначно идентифицировать, где именно болит. Если сорсной агент не может прочитать данные, то не надо искать проблему на стороне репозитория.
-
Agent.<job name>.Source.<vm name> Логи агента, который занимается чтением файлов конфигурации машин участвующих в бекапе. VMX, VMXF, NVRAM — для VMware, или XML — для Hyper-V.
-
Agent.<job name>.Source.<vm name>.Hotadd.Attacher Как намекает название, это логи агента, который работает с дисками в Virtual Appliance режиме. Причём, если в процессе бекапа будет принято решение о смене режима на сетевой (если выбрана соответствующая опция), название файла не изменится. Также стоит отметить, что в данный момент диски с одной машины обрабатываются последовательно, поэтому лог тоже последовательный, и сочинять отдельный файл для каждого диска нет смысла.
-
Agent.<job name>.Source.<vm name>.<disk name> То же, что и выше, только про SAN/network режимы. Лог живёт непосредственно на машине с ролью прокси.
-
Agent.<job name>.Target Очень важный лог таргетного агента, в котором фиксируются события, связанные с открытием, чтением, записью файлов бекапов во время работы джобы. Если используется опция Per-vm, то у каждой машины в джобе будет свой отдельный лог в формате
-
Agent.<jobname>.Target.<vm name>.<vm id> Логи эти пишутся на репозитории и/или гейте.
-
Agent.<job name>.CtpTransfer.Client/Server Логи агента, отправляющего/получающего Changed Block Tracking данные, полученные от нашего драйвера.
-
Agent.<job name>.Target.Repair Если в процессе прохода джобы она потерпела неудачу (по любой причине), необходимо удалить с репозитория всё, что она успела туда записать. Эти операции логируются здесь.
-
Agent.<job name>.Client/Server или Agent.<job name>.Transform.<vm name>.Target/Source.<repo name> Логи от любимых всеми синтетических операций. Rollback, transform и прочие synthetic full фиксируются здесь.
Также есть небольшая порция специфических логов, которые появляются при работе с Hyper-V:
-
SnapshotCreator/SnapshotImporter Логи, связанные с VSS снапшотами. Есть смысл читать только вместе с Windows events.
-
HvWmiProxy-<HV host name> Логи отправляемых WMI запросов
-
Agent.<job name>.CtpTransfer.Client/Server Если используется наш драйвер для отслеживания изменённых блоков, то его работа фиксируется здесь.
-
Agent.<job name>.Source.<vm name>.CONFIGVMCX В Hyper-V 2016 произошёл уход от человекочитаемого XML формата при описании конфигурации машин в сторону бинарного VMCX. Однако со старым форматом тоже надо уметь работать. Агент делающих это отчитывается в этом файле.
-
Agent.<job name>.Source.<vm name>.CONFIGVMRS Тоже реверанс в сторону 2016 года, когда VRMS хранил в себе данные о рантайме вируталок.
Replication Job
Это были бекапы. А что с репликами? С ними всё то же самое. Только лог джобы будет называться Job.<job name>.Replica, а не .Backup. В остальном логика и названия будут ровно такие же, как и у бекапов. Хотя будет лукавством говорить, что у реплик нет ничего своего. Конечно, есть:
-
Например, появляется лог Agent.<job name>.Digests.Target, где содержится отчёт о создании метаданных реплики. Как вы, конечно же, помните, сама реплика хранится где-то на сторе вашего хоста. А вот метаданные от неё лежат уже в нашем репозитории.
-
Agent.<job name>.Repair.log Как известно, Veeam периодически проводит внутренние проверки блоков данных — забекапленного и реплицированного. Если будут обнаружены какие-то повреждения, то последует попытка спасти потерянные блоки. Штука на самом деле важная и полезная, а лог её работы лежит в этом файле.
-
Agent.<job name>.Target.<vm name>.<disk name> Лог таргетного агента, где хранится информация про запись данных на диски реплики.
-
И закончим на Agent.<job name>.Digests.Repository, посвящённом хранению метаданных.
Уверен, что вы уже поняли идею общей структуры логов. Всегда есть общий лог джобы. У него есть саб-логи тасок, где ведутся записи про каждую отдельную машину из джобы. Без тени сомнения могу сказать, что логи тасок несут в себе максимум полезной информации для решения большинства проблем. Но “большинства” не значит “всех”. Поэтому рядом с ними будут лежать логи агентов, которые делятся на сорсные и таргетные. Понимание этой незамысловатой структуры позволит вам детально разобраться с происходящим в любой вимовской джобе. Другой вопрос, что информация в логах может быть технически сложной, но про это будет в следующей статье. И не забываем, что некая часть логов оставляется агентами на бекапируемой/реплицируемой машине. И если проблема была на передающей стороне, искать её надо в логах сорсных агентов на соответствующей машине (читай прокси).
Ну а мы продолжаем.
Restore/Failover
Эти товарищи живут своей отдельной жизнью. Причём у них даже нет какого-то специального отдельного места для хранения своих логов. Просто создаётся папка с названием восстанавливаемой машины, и туда пишется вся информация. Правда, тут есть определённое неудобство, т.к. в одну папку могут попасть логи от разных ресторов, что (теоретически) приводит к путанице. Но с логикой наименования всё довольно просто:
-
IR.<vm name>.Mount/Dismount Нетрудно догадаться, IR означает Instant Recovery, а Mount/Dismount посвящены процессам монтирования машины из бекапа на продакшн сторадж и отпусканием бекапа в конце восстановления.
-
Vm.<vm name>.FileRestore Соответственно, логи восстановления файлов виртуалки.
-
Agent.<vm name>.FilesRestore.Client/Server Логи процесса копирования данных из бекапа в датастору. Опять же, разделены на два файла: один за источник, второй за приёмник.
-
Vm.<vm name>.Restore Появится, когда нам надо восстановить всю машину целиком.
-
А Vm.<vm name>.HddRestore — если восстановить нужно конкретный диск. И, по аналогии, рядом будет Agent.<vm name>.VmHardDisksRestore.Client/Server
Если речь идёт про фейловеры реплик, то самое интересное будет в следующих файлах со структурой Agent.<vm name>/<replicaname>.Failback.VddkAccessor. То есть главное — не перепутать, о чьём логе речь: реплики или оригинальной машины.
Как видите, у каждой джобы есть какие-то свои особенности, которые накладывают свой отпечаток на содержание лог файлов. Но всегда и всюду наименование остаётся человекочитаемым и довольно прозрачно отражает суть содержимого. Поэтому с логами, лежащими в папочках, я хочу закончить и перейти к так называемым
Standalone Logs
Как нетрудно догадаться, здесь поговорим про логи, не лежащие в какой-то особенной папочке, а расположенные прямо в корне логохранилища Veeam. Сделано это в основном по причине того, что они несут в себе информацию про какие-то общие процессы, и делать под каждый такой лог свою папку — занятие странное. Хотя, положа руку на сердце, иногда всё же хочется подумать над группировкой, ибо если просто начать перечислять всё, что может лежать в папке C:ProgramDataVeeamBackup, то это будет больше двух страниц (проверено). Поэтому давайте самостоятельно немного сгруппируем логи по смыслу.
Вот есть целая группа логов, начинающихся с Svc. Это логи наших сервисов.
-
Svc.VeeamBackup.log Лог того самого Veeam Backup Service, без которого ничего работать не будет. Поэтому в него приходит довольно много информации: расписание джоб, распределение ресурсов, отслеживание внутренней коммуникации между модулями, и так далее, и тому подобное. Тот редкий случай, когда в лог что-то постоянно пишется без перерывов на обед и сон.
-
Svc.VeeamBES.log То же самое, но это самый важный лог уже для Veeam Enterprise Manager
Дальше всё просто и понятно.
-
Svc.VeeamInstaller.log Фиксирует все действия Veeam Installer Service (aka Veeam Deployment service)
-
Svc.VeeamCatalog.log Содержит в себе записи о работе сервиса индексации гостей.
-
Svc.VeeamInstallerDll.log Поскольку Installer Service также проводит некоторые операции с файловой системой (проверка свободного места, поиск файлов, создание VBM и т.д.), было решено записывать эти события в отдельный лог. К слову, это единственный сервис, который приходится разворачивать через админскую шару и SCM. Все остальные устанавливаются уже с его помощью.
-
Svc.VeeamHvIntegration В этом логе фиксируется информация об операциях создания VSS снапшотов и взаимодействия с нашим проприетарным драйвером. Часть про VSS снапшоты одинакова с VeeamVssSupport.log файлом на гостевой машине. А поскольку у Hyper-V Integration сервисы работают в пассивном режиме, от них остаются только ответы на запросы.
-
Svc.VeeamWANSvc.log Логи WAN Accelerator сервиса. Лог пишется на обеих сторонах канала связи.
-
Svc.VeeamTransport.log Фиксирует работу Veeam Backup Proxy сервиса.
-
Svc.VeeamTape.log Здесь находится всё что связано с Remote Tape Server.
-
Svc.VeeamRestAPI.log Лог RESTfullAPI реквестов.
-
Svc.VeeamNFS.log. Та самая магия, которая позволяет ESXi хостам монтировать виртуалки прямо из бекапов. Используется для FLR, IR, SureBackups и прочих Other-OS File Recovery.
Есть сервис — должен быть отдельный лог. Или даже несколько, если так удобней.
Так же имеется плеяда агентских логов.
-
Agent.<vm name>.DeleteVm Появляется если удалить из бекапа на репозитории машину. Backups>Disk>Выбрать джобу>Выбрать VM>Delete from Disk
-
Agent.DynGroupMount Агент отвечающий за монтирование динамических дисков.во время Windows FLR, например.
-
Agent.NfcCommander.Client/Server В этом логе фиксируются операции c VMFS вольюмами: чтение конфигурации, удаление/создание директорий и файлов. Используется при IR, Failover и Other OS FLR.
-
VeeamAgent.FileOperation.Client/Server.log В том или ином виде есть во многих подпапках. Хранит информацию о таких операциях как File Copy Job, экспорт логов и ещё нескольких.
А вот логи инструментов работающих с инфраструктурой убрали в отдельную папку Utils
-
Util.CatCleanup Лог, ведущийся тулой Catalog Synchronization. Проверяет соответствие информации в VBRCatalog и реальных бекапов.
-
Util.HvCtpScanner Тула, проверяющая актуальность содержимого .ctp файлов, в которых содержится информация об измененных блоках внутри VHD дисков. Один файл на один диск. Адепты VMware vSphere могли видеть то же самое в .ctk файлах.
-
Util.VeeamBackupConfiguration.Restore Логи восстановления базы данных самого VBR.
-
Util.VmBackupValidate Этот лог создаётся, если руками запустить Veeam.Backup.Validator.exe. Проверяет целостность блоков данных на уровне хранилища.
-
Util.DatabaseResynchronizer Это уже не отдельный лог, а полноценная папка с логами процесса синхронизации базы данных и фактического содержимого бекапных репозиториев.
-
Util.VolumesHostDiscover Другая полноценная папка, где хранятся логи так называемых Volumes Discovery тасков. Этот процесс проверяет диски, подключенные к прокси серверам, на предмет возможности их использования в качестве точки монтирования при ресторе элементов приложений.
И, конечно же, есть гора логов-одиночек.
-
Job.DatabaseMaintenance Раз в неделю Veeam проводит обслуживание своей базы: дефрагментирует индексы, удаляет ненужные данные, и так далее. Завершается это всё перезапуском основного сервиса.
-
VeeamBackupMksConsole Фиксирует информацию про открытие окна консоли машин, запущенных в рамках SureBackup.
-
RTS.ResourcesUsage.log Здесь хранятся записи планировщика ресурсов всех компонентов Veeam.
-
VeeamShell Всё, что происходит в GUI, оставляет свой отпечаток здесь
-
PowerShellInvokerWrapper<SCVMM FQDN> Лог связи между Veeam сервером и SCVMM
-
VeeamBackupManager Логи менеджера, запускающего джобы и таски. Практически вся информация записывается в соответствующие логи, так что здесь мало чего остаётся. Однако, где-то это надо фиксировать.
Логи по папочкам
И есть ещё логи, которые напрямую к бекапам не относятся, однако свою отдельную папочку заслужили по разным причинам.
-
%Something% Explorer Логи от одного из AIR (Application-Item restore) визардов. Active Directory, SQL, Oracle и так далее.
-
ResourceScan, Чтобы поддерживать в актуальном виде информацию о состоянии бекапной инфраструктуры, Veeam с определённой периодичностью сканирует всё, что к нему было подключено.
-
BackupConfigurationJob Логи джобы, бекапящей конфиг самого Veeam сервера (по сути, делающей дамп базы).
-
Console Информация о запусках консоли от разных пользователей. Информация внутри поделена на разные логины, однако учтите, что лог хранится на той машине откуда, запускалась консоль, а не на самом VBR сервере.
-
EvacuateBackupsJob Появляется при эвакуации бекапов с SOBR репозитория.
-
Exportlogs Логи визарда, собирающего логи для сапорта. Да, это логи на логи =)
-
Filefromtaperestore Удивительно, но тут живут логи восстановления файлов с лент.
-
FLRSessions Практически вся информация про FLR и Other OS ресторы.
-
Import_job Логи процесса импорта бекапов
-
NfsDatastore Всё, что связано с работой vPower NFS, фиксируется здесь
-
Satellites Своих спутников на орбите, к сожалению, у нас пока нет, однако есть несколько вспомогательных процессов, разгружающих GUI. Следы этих процессов будут в этой папке.
На этом пока всё. Повторюсь: это даже приблизительно не полный список логов и папок с ними. Как вы могли убедиться, логи пишутся буквально на каждый чих. Такова уж специфика софта, обеспечивающего защиту ваших данных. А поскольку функционал Veeam Backup&Replication невероятно огромен, то и логи генерируются в олимпийских количествах. И помимо таких очевидных вещей, как простой запуск бекапа/реплики, есть ещё фоновые задачи, такие как Health Check, например. И они тоже генерируют свои логи, дабы в случае аварии всегда можно было максимально подробно восстановить картину мира и понять, что мешает успешной работе.
Поэтому основная цель, которую я перед собой ставил — это показать на примерах, как происходит именование файлов и как выглядят логи самых часто используемых функций. Надеюсь, всё получилось, и если нелёгкая заставит вас открыть %ProgramData%/Veeam/Backups, то вы сможете сориентироваться в этом море названий. А в следующей статье мы уже наконец-то перейдём к азам чтения самих логов. Поговорим про общие правила, которых надо придерживаться, и научимся вычленять базовую информацию.
Knowledge Base
-
Home
-
Knowledge Base
-
Windows Agent Backups
-
Agent Job Errors
-
Troubleshooting: Job Errors
-
Home
-
Knowledge Base
-
Virtual Machine Backups
-
VM Job Errors
-
Troubleshooting: Job Errors
-
Home
-
Knowledge Base
-
Troubleshooting
-
Troubleshooting: Job Errors
General Troubleshooting: Veeam Backup Job Errors
Below are common host and backup job error messages you may encounter and what they mean.
This article is organized by Alarm Type:
- Backup Agent Job State Errors
- Job Session State Errors
- Job Status Errors
- Computer/VM Not Backed Up
- Miscellaneous
For Additional Errors Not Listed Below, Consult the Veeam Knowledge Base and/or Forums:
- Veeam Knowledge Base – https://www.veeam.com/kb_search_results.html
- Veeam Community Forums – https://forums.veeam.com/
1. Backup Agent Job State Errors
Error: write: An existing connection was forcibly closed by the remote host Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}.
What This Means
- The last backup job was unsuccessful because the remote host (machine backing up) closed the connection to eSilo while the backup was running.
Possible Causes
- The machine was powered down during the backup. Upon shutdown, the active snapshot taken at the start of the backup is lost.
Troubleshooting Steps
- No user intervention is typically required. When the computer is powered back on, a new snapshot will be taken at the next scheduled backup time, and a new backup job will begin. (Note: If the machine is put to Sleep or Standby during a backup, it should resume when it wakes up. It is only when the machine is completely powered down that this error happens).
Error: Task failed unexpectedly
What This Means
- The job was terminated suddenly, resulting in an incomplete backup and restore point.
Possible Causes
- Host rebooted during the backup, resulting in the loss of the active snapshot.
Troubleshooting Steps
- Check host’s Event Viewer Windows System logs to see if there was a reboot.
- Rerun the backup job.
Error: Root element missing
What This Means
- The VBM file associated with the backup job has become corrupted.
Possible Causes
- This may be caused by a connection issue during the backup job or the Veeam repository had an error.
Troubleshooting Steps
- Locate the VBM file associated with the backup job and rename the file, such as by adding “.old” to end of the file name.
- Start a new backup job to generate a new VBM file.
- After the new VBM file gets created, the old file can be safely deleted without waiting for the running job to complete.
Unable to allocate processing resources. Error: Job session with id [STRING] does not exist
What This Means
- Host requested but was not assigned processing resources by eSilo cloud connect. This happens because the maximum number of concurrent backup jobs was already reached.
Possible Causes
- eSilo limits the number of concurrent backup jobs from a single Company when their bandwidth is lower than recommended thresholds. This max limit ensures hosts queue their backup jobs sequentially (vs. all machines at once) and avoids network slowdowns for the customer.
- When the first few machines’ backup jobs run long, they can cause subsequent hosts’ jobs to time out while waiting for their turn to backup.
Troubleshooting Steps
- Hosts should automatically retry backups at their next scheduled interval. No user intervention is typically required.
- If this is a persistent issue, or if your hosts are connecting from multiple locations (and thus there is little concern that multiple backups may saturate a site’s connection), contact eSilo Support to request the concurrent task limit be increased for your Company.
Failed to start a backup job. Failed to perform the operation. Invalid job configuration: Connection over network is blocked by network throttling rules
What This Means
- Backup job was unable to complete due to network restrictions.
Possible Causes
- The host is on a metered connection (ex: hot spot), or on a WiFi connection that has “Set as a metered connection” toggled on in the properties for the currently active WiFi connection. By default, eSilo Backup Jobs are set to “Disable backups over a metered connection”.
- Temporary network congestion may also cause this error.
- Firewall rules that limit or severely restrict certain types of traffic.
Troubleshooting Steps
- To check if the current WiFi connection is flagged as “metered” by Windows, the user can navigate to the Properties of their WiFi Network, and scroll to “Metered Connection” to verify if this is toggled ON. The preferred setting is to turn this OFF. Alternatively, if you don’t have remote access to the machine, uncheck the “Disable backups over metered connection” setting in the backup job and rerun it.

- Wait until the next scheduled backup run to see if the issue persists or was temporary.
- Contact the network or IT administrator for the site to investigate if there were recent firewall rule changes or upgrades that may have introduced new blocking or throttling settings.
Unable to allocate processing resources. Error: Authentication failed because the remote party has closed the transport stream.
What This Means
- The backup job failed due to an authentication error between the client machine backing up and the eSilo infrastructure.
Possible Causes
- Client machine is behind on Windows Updates which include authentication and security enhancements, or they have not checked the box in Windows Update Settings to include updates for other Microsoft Products, such as .NET Framework.
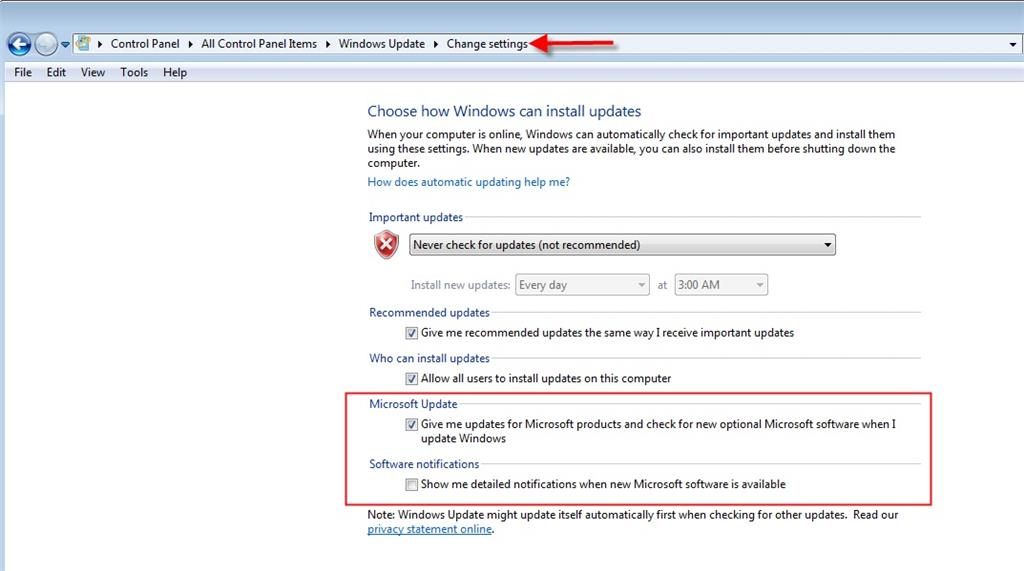
Troubleshooting Steps
- Apply latest Windows Security updates and .NET Framework updates
- Check if at the time of the above error on the tenant side, the eSilo Svc.VeeamCloudConnect.log log file displays the following error: “A call to SSPI failed, see inner exception“. If so, the issue may be related to a Windows Update enforcing a new .Net Framework security check. This check does not allow the client to establish a secure connection between their Veeam backup servers or agents and the eSilo Cloud Connect service, if there is a weak Diffie-Hellman Ephemeral (DHE) key. See this help article from Veeam on the steps needed to confirm and resolve. https://www.veeam.com/kb3208
- Subsequent job reattempts may complete successfully without user intervention, although this error may still sporadically cause jobs to fail.
Error: Failed to connect to the port [DNS_Name:Port].
What This Means
- Host unable to connect to eSilo cloud connect at the specified gateway and port address.
Possible Causes
- If this issue is occurring for only one or two machines (most common), and not all machines connecting to the eSilo cloud connect infrastructure, it may be indicative of a network issue on the client side.
Troubleshooting Steps
- The host should reattempt the job at the next scheduled interval. You can also manually start a backup to reattempt the job. No other user intervention is typically required.
Error: Insufficient quota to complete the requested service. Asynchronous read operation failed Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}. Exception from server: Insufficient quota to complete the requested service. Asynchronous read operation failed Unable to retrieve next block transmission command. Number of already processed blocks: [#]. Failed to download disk ‘[LONG_ID]’.
What This Means
- The error description may be misleading. We’ve observed this error previously, and it was unrelated to the Tenant’s Quota, which was well within limits.
Possible Causes
- When this was observed on an internal testing VM, the cause was that the source VM in the backup job was very low on memory (RAM) resources and was unresponsive. Restarting the VM brought it back online, and the next automatic job try was successful.
Troubleshooting Steps
- Verify the source machine is online and responsive. Ensure resource levels look good.
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: Invalid backup cache synchronization state.
What This Means
- Host is currently saving backups to Local Backup Cache. An attempt to sync cached backups to the eSilo cloud repository failed, due to a mismatch between what the Veeam Agent for Windows had in its local database for expected restore points and what was actually found in the repository and/or local backup cache.
Possible Causes
- If an in-progress backup is abruptly stopped, for example due to power failure, Veeam will discard any partially written restore points. However, if all references to those now discarded restore points are not cleared from the database (which should happen automatically), this can cause a job error on the next run, which highlights a mismatch between restore points expected on disk and what was found.
Troubleshooting Steps
- In most cases where this has been observed, the job will complete successfully the next time it is run, without any user intervention.
- If this error persists more than once, contact eSilo Support for assistance troubleshooting Backup Cache issues.
Job session for “[JOB_NAME]” finished with error. Job [JOB_NAME] cannot be started. SessionId: [ID], Timeout: [XX sec]
What This Means
- The Veeam job could not start due to too many active sessions or jobs running on the host consuming all available memory.
Possible Causes
- Too many running sessions causes Veeam services to be impacted by the host’s Desktop Heap limitation. This is because the Desktop Heap size for services is much smaller than that for applications.
Troubleshooting Steps
- To resolve this issue the Desktop Heap size must be increased via a registry modification.
- See this Veeam Knowledge Base article for detailed resolution steps: KB1909
Error: The system cannot find the file specified. Failed to open I/O device Failed to open emulated disk. Failed to open disk for read. Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}
What This Means
- An expected disk on the client machine (machine to backup) was unable to be opened and read during the backup job.
Possible Causes
- Not known at this time.
Troubleshooting Steps
- The host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: Oib is complete and cannot be continued
What This Means
- The “oib” stands for “objects in backup” and is a unique identifier used by Veeam.
- The error indicates there is a discrepancy; a job is attempting to write to an oib that is already complete or finalized.
Possible Causes
- This may occur on a backup cache sync job that was interrupted right at very end, during the finalization stage. The error indicates that the oib was finalized by the previous job (“oib is complete”), however the current job is trying to modify or append to it, which is not allowed.
Troubleshooting Steps
- This error should resolve itself on next job run. If not, contact eSilo support.
Job session for “[JOB_NAME]” finished with error. Backup cache size has been exceeded
What This Means
- The size of the local backup cache has exceeded the maximum allowed size as configured in the backup job, preventing new restore points from being saved to the cache.
Possible Causes
- Persistent network disruptions may be preventing cached restore points from syncing, or uploading, to the eSilo Backup Cloud and thus they are not rotated out of the local backup cache. Restore points accumulate until the backup cache location is full.
- Service provider resources are busy or unable to be allocated to this host, preventing the syncing of cached restore points.
Troubleshooting Steps
- The Backup Cache Sync should resume in time, once the originating network or resource issues are resolved.
- The maximum Backup Cache size can be increased in the job settings, so long as there is sufficient local space.
- For more detail on advanced resolution steps, see this eSilo KB article: How to Resolve Backup Cache Size Exceeded Error
Error: Failed to create snapshot: Backup job failed. Cannot create a shadow copy of the volumes containing writer’s data. A VSS critical writer has failed. Writer name: [NAME]. Class ID: [ID]. Instance ID: [ID]. Writer’s state: [VSS_WS_FAILED_AT_PREPARE_SNAPSHOT]. Error code: [0x800423f0].
What This Means
- There is an issue with the built-in Windows VSS (Volume Shadow Copy service) on the host machine. Specifically, the VSS writer mentioned was not available at the time of the backup.
- eSilo Backups powered by Veeam use VSS writers to backup files that may be in-use, open or locked at the time of backup. This is particularly useful for databases, allowing backups to complete without downtime. If a writer is not in the proper state and functioning as expected, the backup snapshot will fail. VSS writer issues must be resolved on the host, and can usually be corrected by restarting the associated service.
Possible Causes
- The VSS service and/or the VSS Providers service is disabled
- The VSS writer is not in the Stable state, indicating it is ready and waiting to perform a backup. Below are alternative states:
- Failed or Unstable – the Writer encountered a problem, and must be reset .
- In-Progress or Waiting for Completion – the Writer is currently in use by a backup process. When the backup is finished, the Writer will revert to back to Stable state. However, if you see this state when no backups are running, the Writer needs to be reset.
Troubleshooting Options
- Verify the Volume Shadow Copy and Microsoft Software Shadow Copy Provider services are not disabled in services.msc.
- Check the state of VSS Writers using the following syntax in an admin command prompt. Also check the Windows Event Viewer for additional error information.
vssadmin list writers
-
- For the specified Writer in the error message, verify it is in a Stable state. If not, restart the respective Service related to that writer as mentioned in the table here. Then run the above command a second time to ensure the writer has returned to a stable state.
- Note that Services often have dependencies on one another. When one service is reset it may require others to be reset as well. Restarting a service will momentarily disrupt any application services that rely on it. For example, while resetting the MEIS service (Microsoft Exchange Information Store), MS Exchange will be unable to send and receive emails.
- A system reboot can also resolve most VSS writer problems, although it requires downtime.
- This Veeam KB article can also be useful in troubleshooting VSS issues for servers.
Job Session for [JOB_NAME] finished with error. Job [JOB_NAME] cannot be started. SessionID: [ID], Timeout: [VALUE]
What This Means:
- The job could not start, due to timeout waiting for required Veeam resources
Possible Causes:
- The Concurrent Task limit set at the Company level is too low for the number of hosts and disks schedule to be backup within a defined backup window.
Troubleshooting Options:
- Increase the number of concurrent tasks (e.g. disks that can be processed at once). This setting can be found in the eSilo Backup Portal under Companies >> Edit >> Bandwidth >> Max Concurrent Tasks. The minimum value should be 2, but greater numbers may be needed based on the timing and staggering of host backups.
Job session for “[JOB_NAME]” finished with error.
Error: Service provider side storage commander failed to perform an operation: CreateStorage
What this Means:
- eSilo was not able to allocate repository storage for the backup job.
Possible Causes:
- The assigned repository quota for this Tenant has been exceeded, thus preventing new backups from initiating.
Troubleshooting Options:
- Increase the Company’s repository quota.
- Remove existing backup chains or reduce the retention period to free space.
Job Status Warning: Unable to truncate SQL server transaction logs. Details: Failed to truncate SQL server transaction logs for instances: [MSSQLSERVER].
What this Means:
- Veeam was unable to truncate SQL server logs as specified in the job settings.
Possible Causes:
- This most commonly due to a permissions issue.
Troubleshooting Options:
- This Veeam Helpcenter article discusses the Log Truncation settings.
- You can confirm if this is a permissions issue by reviewing the Backup Job log for Warning items. Ex: Description = The server principal “[HOST][ACCOUNT]” is not able to access the database “[HOSTNAME]” under the current security context.
- Grant necessary permissions and rerun the job.
- Alternatively, you can modify the Backup Job settings to not truncate SQL Logs.
- Edit the Backup Job
- Under Guest Processing, click to “Customize application handling options for individual applications…”
- On the SQL tab, select the option for “Do not truncate logs”
2. Job Session State Errors (for VMs)
Host [LOCAL_IP] is not available. Error: Cannot complete login due to an incorrect user name or password. Virtual Machine [NAME] is unavailable and will be skipped from processing. Nothing to process. [#] machines were excluded from task list.
What This Means
- Veeam Backup and Replication was unable to access the Virtual Machine (VM) to perform the backup.
Possible Causes
- Incorrect user name or password specified to access the source VM. The password may have expired or the account credentials or permissions may have been changed.
Troubleshooting Steps
- Contact the IT Administrator for the VM to troubleshoot the credentials saved in the Backup Job.
3. Job Status Errors
SQL VSS Writer is missing: databases will be backed up in crash-consistent state and transaction log processing will be skipped
What This Means
- The SQL Writer for the Windows Volume Shadow Copy Service (VSS) is not available on the host machine, or is not configured with adequate permissions. This issue is related to the setup of the SQL database, and not specific to eSilo provided software or the backup itself.
Steps to Confirm the Issue
- Running ‘vssadmin list writers’ in an Administrator Command Prompt shows that SqlServerWriter is not in the list, or is in a State other than ‘Stable’.
Possible Causes
- The SQL instance has at least one database with name starting or ending in a space character
- The account under which SQL VSS Writer service is running doesn’t have sysadmin role on a SQL server – most frequently encountered
- SQL VSS Writer service is stuck in an invalid state, e.g. other than ‘Stable’
Troubleshooting Steps
- Depending on a particular cause:
- Rename the database to a new name (without a space in it). To check if your database has space in the name you can run the following query:
select name from sys.databases where name like '% '
If you notice any spaces in the database names, then you will need to remove the spaces from the database names.
- Grant the SQL VSS Writer service user a sysadmin role (Instructions in KB here: https://www.veeam.com/kb1978)
- Restart SQL VSS Writer service (Instructions in KB here: https://www.veeam.com/kb2041)
- In the case of SBS machines that are also Domain Controllers, ensure that the SQL Writer is running as a domain administrator and not local system.
- Allow the SQL Writer service account access to the Volume Shadow Copy service via the registry:
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesVSSVssAccessControl- If the DWORD value “NT SERVICESQLWriter” is present in this key, it must be set to 1.
- If the Volume Shadow Copy service is running, stop it after changing this registry value. Do not disable it.
For More Information
See this Veeam Knowledgebase article: https://www.veeam.com/kb2095
Microsoft documentation states that the SQL Writer service must run as Local System.
- In SQL Server 2008R2 and earlier, this means that the writer service account appears to SQL Server as “NT AUTHORITYSystem”.
- In SQL Server 2012 and later, the writer service account appears to SQL Server as “NT ServiceSQLWriter”.
4. Computer/VM Not Backed Up Errors
Backup Agent ‘[HOSTNAME]’ has fallen out of the configured RPO interval ([#]days). Last backup: [#] days, [#] hours ago.
What This Means
- The host’s most recent eSilo cloud backup is greater than the specified RPO (Recovery Point Objective) interval.
Possible Causes
- Host has been powered off or offline.
- Backups are being saved to the host’s Local Backup Cache and all restore points in the cache have not yet synced to the eSilo Cloud Repository (e.g. eSilo has not yet received the backups).
- Veeam Backup Agent Service or Veeam Management Agent Service is not running on host.
- The backups and/or backup schedule have been manually disabled (uncommon).
Troubleshooting Steps
- Verify host is online and connected to network.
- Check Backup Job to determine if Backup Cache is enabled. View cache folder on host to see if populated with recent restore points (default location: C:VeeamCache).
- Verify ‘VeeamManagementAgentSvc’ service is running on host. Status should be ‘Running’ and Startup Type should be ‘Automatic (Delayed Start)’. If the service is ‘Stopped’, check the Event Viewer for possible error details. See this article for more troubleshooting steps.
- Verify ‘VeeamEndpointBackupSvc’ service is running on host. Status should be ‘Running’ and Startup Type should be ‘Automatic’. Restart or reinstall if necessary.
- Check Backup Job to verify schedule and ensure not ‘Disabled’
Other Errors – Full Details Coming Soon
Error: Reconnectable protocol device was closed. Agent failed to process method {FileBackup.SyncDirs}. Exception from server: Reconnectable protocol device was closed.
Troubleshooting Steps
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond.
Troubleshooting Steps
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
[In Backup Job Log] Error: [CStorageLinksHelper] Link Id=[LONG_ID] doesn’t exist for storage [JOBNAME_SUBTENANTNAME]yyy-mm-ddTxxxxxx.vib
What This Means
- While the restore point exists on the repository, the Link ID to that restore point in the metadata (.vbm) file is missing.
- Note: If the Backup Job is configured to use Backup Cache, this error does not by itself trigger a Backup Job Failure, since the restore points are successfully written to local cache. You will notice it however, because the eSilo Backup Portal will warn that a new restore point has not been uploaded in X days (according to the RPO alarm thresholds set for this tenant).
Possible Causes
- This can be a symptom of a network drop, where a handshake was missed in the final stages of job completion for the last restore point uploaded to eSilo. The local Veeam Agent database (on the subtenant’s machine) saw the restore point created, but the finalization step didn’t update the metadata file on the repository side with eSilo.
Troubleshooting Steps
- In the repository, we will force the job to recreate the metadata file by editing the existing metadata file to append “.old” at the end. At the next job run, this will force a recheck of all restore points in the backup chain and recreate the metadata file from that chain.
[In Svc.VeeamEndpointBackup.log] Error: Warning [CertificateError] Validation complete with warnings, AND/OR Warning Remote certificate chain errors, AND/OR Warning WarningRevocationStatusUnknown (The revocation function was unable to check revocation for the certificate.
What This Means
- The subtenant was unable to validate the eSilo Cloud Connect server’s certificate.
Possible Causes
- If this is happening for only one tenant, as opposed to all tenants, it suggests an issue with how this specific subtenant is connecting to eSilo.
- If no firewall or other changes have been made recently, you can recheck the credentials used by the subtenant in the backup job.
- This Veeam KB article is also helpful for investigating common causes of certificate errors: https://www.veeam.com/kb2323
Troubleshooting Steps
- Verify the Management Agent status shows as Connected. You can force a reconnect by changing a property in the dialog box, then changing it back and clicking “Apply“.
- Pause and unpause sync of Backup Cache files by right-clicking on the Veeam Backup Agent icon in the taskbar.
- Edit the Backup Job to specify the correct sub-tenant login credentials. Save and rerun the job. Upon the next job run, you should see “Uploading cached restore points” when you hover over the Veeam Backup Agent icon in the taskbar.
Was this article helpful?
Related Articles
Page load link
Go to Top
Introduction
Recently I got to diagnose a really interesting Veeam Backup & Replication symptom. Imagine you have a backup environment that runs smoothly. All week long but then, suddenly, running backup jobs stall. News jobs that start do not make an ounce of progress. It is as the state of every job is frozen in time. Let’s investigate and dive into troubleshooting 100% stalled Veeam backup jobs.
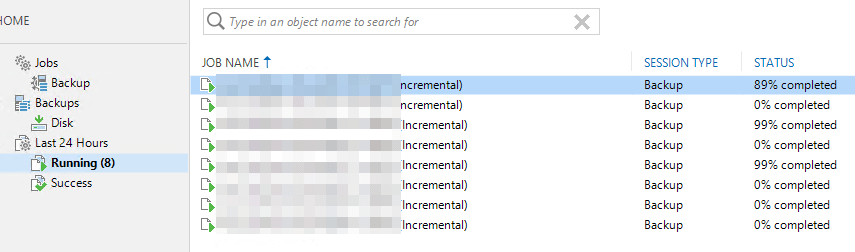
Troubleshooting 100% stalled Veeam backup jobs
When looking at the stalled jobs, nothing in the Veeam GUI indicates an error. Looking at the Windows event logs we see no warning, error, or critical messages. All seems fine. As this Veeam environment uses ReFS on storage spaces we are a bit weary. While the bugs that caused slowdowns have been fixed, we are still alert to potential issues. The difference with the know (fixed) ReFS issues that this is no slowdown, No sir, the Veeam backup jobs have literally frozen in time but everything seems to be functional otherwise.
Another symptom of this issue is that the synthetic full backups complete perfectly well, but they finfish with an error message none the less due to a time out. This has no effect on the synthetic backup result (they are usable) but it is disconcerting to see an issue with this.
On top of that, data copies into the ReFS volumes work just fine and at an excellent speed. Via performance monitor, we can see that the rotation of full regions from mirror to parity is also working well once the mirror tier has reached a specified capacity level.
Time to dive into the Veeam logs I would say.
Veeam backup job log
So the next stop is the Veeam logs themselves. While those can seem a little intimidating, they are very useful to scroll through. And sure enough, we find the following in one of the stalled jobs its backup log.
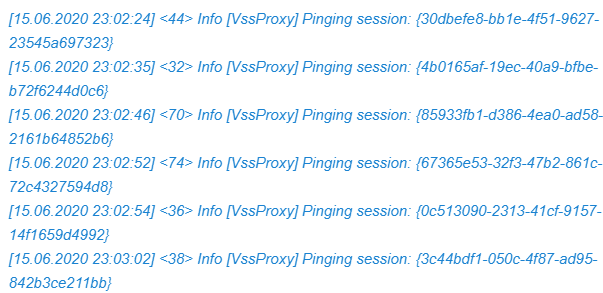
For hours on end … it goes on that way.
VIRTUAL MACHINE TASK LOGS 1
When we look at the task log of ar virtual machine that is still at 0% we see the same reflected there. Note that nothing happens between 22:465 and 05:30, that’s when I disabled and enabled the vNIC of the preferred networks in the VBR virtual machine and it all sprung back to life.

So it is clear we have a network issue of some sort. We checked the repository servers and the Hyper-V cluster but there everything is just fine. So where is it?
Virtual Machine task logs 2
We dive into the task log of one of the virtual machines who’s backing up and that is hanging at 88%. There we see one after the other reconnect to the repository IP (over the preferred network as defined in VB). That also happens all night long until we reset the VBR virtual machine’s preferred network vNICs. In the log snippet below notice the following:
Error A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond (System.Net.Sockets.SocketException)
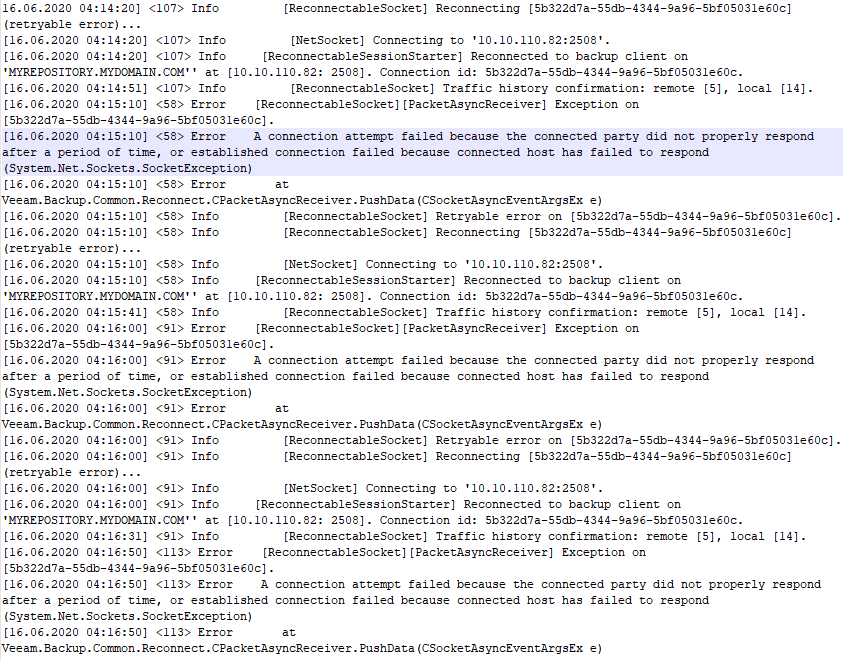
From the logs we deduct that the network error appears to be on the VBR virtual machine itself. This is confirmed by the fact that bouncing the vNICs of the preferred network (10.10.110.x is the preferred network subnet) on the VBR virtual machine kicks the jobs back into action. So what is the issue? So we start checking the network configurations and settings. The switch ports, pNICs, vNIC, vSwitches etc. to find out what’s going on, As it seems to work for days or a week before the issue shows up we suspect a jumbo frame issue so we start there.
The solution
While checking the configuration we to make sure jumbo frames are enabled on the vNIC and the pNICs of the vSwitch’s NIC team. That’s when we notice the jumbo frames are missing from those pNICs. So we set those again.
From the VBR virtual machine we run some ping tests. The default works fine.
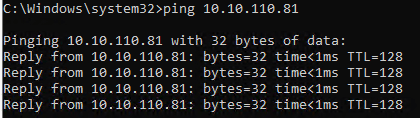
When we test with jumbo frames however we notice something. The ping tests do not complain about jumbo frames being too large and that with the “do not fragment” option set the “Packet needs to be fragmented but DF set.” Note it just says “request timed out”. This indicates an issue right here, jumbo frames are set but they do not work.
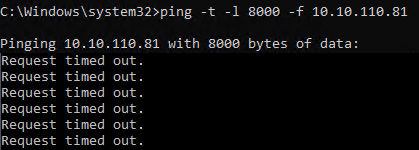
As the requests time out and the ping test does not complain about the jumbo frames we have another issue here than just the jumbo frame settings. It smells of a firmware and/or driver issue. So we dive a bit further. That’s when I notice the driver for the relevant pNICs (Broadcom) is the inbox Windows driver. That’s no good. The inbox drivers only exists to be able to go out and fetch the vendor’s driver and firmware when need, as a courtesy so to speak. We copy those to the hosts that require an update. In this case, the nodes where the VBR virtual machine can run. The firmware update requires a reboot. When the host is up and the VBR virtual machine is running I test again.
Bingo, now a ping test succeeds.
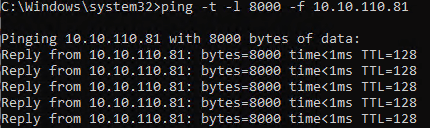
What happened?
So did we really forget to update the drivers? Did we walk out of the offices to go in lockdown for the Corona crisis and forget about it? In the end, it turned out they did run the updates for the physical hosts. But for some reason, the Broadcom firmware and drivers did not get updated properly. However, that failed update seems to have also removed the Jumbo frame settings from the pNICs that are used for the virtual switch. After fixed both of these we have not seen the issue return.
Remarks
The preferred networks do not absolutely have to be present on the VBR server itself. Define, yes, present, no. But it speeds up backup job initialization a lot when they are there present on the VBR server and Veeam also indicates to do so in their documentation.
Why jumbo frames? Ah well the networks we use for the preferred networks are end to end jumbo frame enabled. So we maintain this in to the VBR server. We might get away by not setting jumbo frames on the VBR server but we want to be consistent.
Conclusion
It pays to make sure you have all settings correctly configured and are running the latest and greatest known good firmware. But that should have been the case here. And it all worked so well for quite a while before the backup jobs stall. The issue can lie in the details and sometimes things are not what you assume they are. Always verify and verify it again.
I hope this helps someone out there if they are ever troubleshooting 100% stalled Veeam backup jobs If you need help, reach out in the comments. There are a lot of very experienced and respected people around in my network that can help. Maybe even I can lend a hand and learn something along the way.
0 Flares Twitter 0 Facebook 0 LinkedIn 0 Email — 0 Flares ×
Many users of Veeam Backup & Replication have also acquired Veeam ONE as their monitoring and reporting solution, but many have already some existing monitoring solution in their datacenters, and they’d prefer to monitor Veeam together with other systems and applications using their own unified solution. This is a sound request, and in order to do so there are different possible ways. One of them is via the the Windows Event Log; since the Veeam backup server is a Windows software, each event is registered in Veeam logs, but also in the Windows Event Log:

As you can see in this screenshot coming from an installation of Veeam Backup & Replication v9.5 in a Windows 2012 R2 server, a new section is created specifically for Veeam Backup, and here different administrators can go and look at events, filter them, and search through them. Or again, these events can be collected centrally using one of the many existing solutions able to do so.
But what events can be be searched?
This is indeed a good question, and if previously I would have had some doubt about the correct answer, other than going through the event viewer myself and learn about the different Event IDs, I’ve learned a few days ago a way better answer: Veeam technical writing team has just created a new document, where all the Veeam events are listed, divided by category. Here is a screenshot of the document:

There are many interesting Event IDs that can be searched, like for example “24020 – License expiring”, as I’ve seen many times that one of the most overlooked information in many installations is the fact that a license is about to expire, and so the software will soon stop to operate (people usually finds about the expired license because jobs are not executed anymore). Another nice one is obviously “190 – Backup job finished”, where the status can be Info, Warning or Error depending on the final result of the backup job.
The document is 10 pages long, and can be downloaded here: https://www.veeam.com/pdf/guide/veeam_backup_9_0_events_en.pdf
![]() When Veeam released their Veeam Agent for Windows 2.0 on May 11th, 2017 I was first in line to go for an upgrade on my main PC (Windows 10 Build 1607) at home. The upgrade went smooth as I expected from Veeam.
When Veeam released their Veeam Agent for Windows 2.0 on May 11th, 2017 I was first in line to go for an upgrade on my main PC (Windows 10 Build 1607) at home. The upgrade went smooth as I expected from Veeam.
Problem:
When I started my first backup with the new version, the backup job stopped with the following error message:
Cannot request cryptocontainer. Win32 error:The data is invalid. Code 13.
That was not the start I expected from the new version. I started troubleshooting and log analysis of this backup job. Backup job log files are located in C:ProgramDataVeeamEndpointBackup_Job_HOSTNAME. There you can find the log file Job.Backup_Job_HOSTNAME.Backup.log.
I went through this log and found this:
[15.05.2017 09:25:25] Info <13cc> Requesting cryptocontainer ‘VeeamCryptoContainer’…
[15.05.2017 09:25:25] Error <13cc> Cannot create cryptoprovider.
[15.05.2017 09:25:25] Error <13cc> Cannot request cryptocontainer.
[15.05.2017 09:25:25] Error <13cc> Win32 error:The data is invalid.
[15.05.2017 09:25:25] Error <13cc> Code: 13
[15.05.2017 09:25:25] Info <13cc> Creating cryptoprovider ‘Microsoft Base Cryptographic Provider v1.0’ (0x00000001).. Failed.
[15.05.2017 09:25:25] Info <13cc> Releasing cryptoprovider.
[15.05.2017 09:25:25] Info <13cc> Releasing cryptoprovider.. Ok.
[15.05.2017 09:25:25] <01> Error Cannot request cryptocontainer.
[15.05.2017 09:25:25] <01> Error Win32 error:The data is invalid.
[15.05.2017 09:25:25] <01> Error Code: 13 (System.Runtime.InteropServices.COMException)
[15.05.2017 09:25:25] <01> Error at VeeamEndpointSysUtilsDllLib.IVeeamEpIndexingProvider.InitSecuredStrings()
[15.05.2017 09:25:25] <01> Error at Veeam.EndPoint.SysUtils.CEpGuestSubsystem.GetInventoryInfo(CVssHostInfoConfig config, Boolean secure)
[15.05.2017 09:25:25] <01> Error at Veeam.EndPoint.SysUtils.CEpGuestSubsystem.GetInventoryInfo(CCredentials credentials)
This was now the right moment to open a Veeam Case because the error log contains the same message which also shows up in the GUI. It took only 3-4 days until the Veeam support engineer came up with the right solution and in my case it was not an Veeam issue. It was an Windows issue. I assume this is also specific to Windows 10.
Solution:
- Navigate to the C:ProgramDataMicrosoftCryptoRSA folder
- Rename the folder labelled S-1-5-18 to .old or something else
- Restart the system
So what is exactly this S-1-5-18 folder? In my case it was the folder for the well-known security identifier of the “Local System” account. The CryptoRSA folder stores certificate pair keys for both the computer and users. I can only assume that one of this key pairs was corrupted and therefor lead to this error.
After the system was restarted, backups start working again. I also want to give a big thank you to Mike Powell who was the Veeam Support Engineer helping me with this problem.
This concludes the post. Please leave a comment if you have any further question or feedback.
Под катом особенности установки Veeam Agent на сервер Oracle Linux 6.10. Все встреченные в процессе инсталляции ошибки и пути их исправления.
TL;DR – список команд в самом конце.
Прежде чем подумать об использовании агентов для резервного копирования серверов, стоит убедиться, что агент поддерживает версию операционной системы, на которую его планируется установить.
Проверим список всех поддерживаемых ОС для Veeam Agent версии 4.0 по ссылке.
В отношении Oracle Linux и поддержки в документации указаны следующие версии:
Oracle Linux 6 – 8.2 (RHCK)
Oracle Linux 6 (starting from UEK R1) – Oracle Linux 8.0 (up to UEK R6)
Правда с небольшой сноской – «Pre-built binary veeamsnap kernel module packages are not compatible with these distributions. Use the dkms packages instead.»
Как видно из документации, агент поддерживает OL начиная с версии 6, вплоть до версии 8.2. Поддерживаются ядра как RHCK – Red Hat Compatible Kernel, так и UEK – Unbreakable Enterprise Kernel.
Вводные:
[root@ol-10-host ~]# cat /etc/oracle-release
Oracle Linux Server release 6.10[root@ol-10-host ~]# uname -r
4.1.12-124.48.2.el6uek.x86_64
Veeam самой актуальной на момент написания статьи версии – 10.0.1.4584 с агентом 4.0.1.2365.
Займемся инсталляцией агента
Создаю новую Protection Group, в которую я добавляю свой хост под управлением Oracle Linux 6.10.
Начинается автоматическая установка агента, и, конечно же, не завершается успешно, ведь иначе не было бы и статьи:
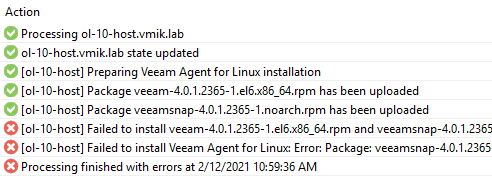
Обратимся к логам, которые находятся в:
C:ProgramDataVeeamBackupRescanRescan_of_Test
C:ProgramDataVeeamBackup – Место, где Veeam хранит свои логи.
RescanRescan_of_Test – это логи хостов в Protection Group (моя группа называется Test).
Находим лог с говорящим именем – Task.ol-10-host.vmik.lab
Переходим в конец лога и сразу же бросается в глаза ошибка:
[SshEpInvoker] Error: Package: veeamsnap-4.0.1.2365-1.noarch (/veeamsnap-4.0.1.2365-1.noarch)
[SshEpInvoker] Requires: dkms
[SshEpInvoker] Exit code: [1]
Вспоминаем сноску выше, а также находим некоторую информацию в документации:
dkms — required by the veeamsnap package for building the kernel module for Veeam Agent for Linux Driver.
Кажется, все понятно. На хосте должен быть установлен пакет dkms, но его нет. Займемся установкой dkms в Oracle Linux:
# yum install dkms
Loaded plugins: security, ulninfo
Setting up Install Process
No package dkms available.
Error: Nothing to do
Неожиданно и, одновременно, вполне ожидаемо. В стандартных репозиториях данного пакета может и не быть.
По запросу Oracle Linux 6 dkms первой же ссылкой будет статья от Oracle в которой написано, что пакет dkms имеется в репозитории EPEL (Extra Packages for Enterprise Linux), но только для версии Oracle Linux 7 и выше. Oracle Linux 6 этот пакет обошел стороной.
Некоторое время поисков не вывело меня на «легальный» способ установки dkms в Oracle Linux, поэтому я решил воспользоваться пакетом dmks из EPEL репозитория, заботливо предоставленного Fedora Linux.
# rpm -ivh https://archives.fedoraproject.org/pub/archive/epel/6/x86_64/Packages/d/dkms-2.4.0-1.20170926git959bd74.el6.noarch.rpm
Retrieving https://archives.fedoraproject.org/pub/archive/epel/6/x86_64/Packages/d/dkms-2.4.0-1.20170926git959bd74.el6.noarch.rpm
warning: /var/tmp/rpm-tmp.invfo2: Header V3 RSA/SHA256 Signature, key ID 0608b895: NOKEY
error: Failed dependencies:
elfutils-libelf-devel is needed by dkms-2.4.0-1.20170926git959bd74.el6.noarch
gcc is needed by dkms-2.4.0-1.20170926git959bd74.el6.noarch
kernel-devel-uname-r is needed by dkms-2.4.0-1.20170926git959bd74.el6.noarch
Зависимости, они повсюду. Смотрим, в каком пакете у нас может быть kernel-devel-uname-r
# yum provides kernel-devel-uname-rkernel-devel-2.6.32-754.35.1.el6.x86_64 : Development package for building
: kernel modules to match the kernel
По итогу нам необходимо установить пакет kernel-devel, также дополнительные зависимости в виде gcc и elfutils-libelf-devel:
# yum install kernel-devel elfutils-libelf-devel gcc
Вновь устанавливаю dkms. В этот раз успешно:
Возвращаюсь в консоль Veem, нахожу хост с OL и сперва удаляю все, что он попытался установить до этого, затем пробую установить агента вновь:

Уже лучше, но все еще не то:
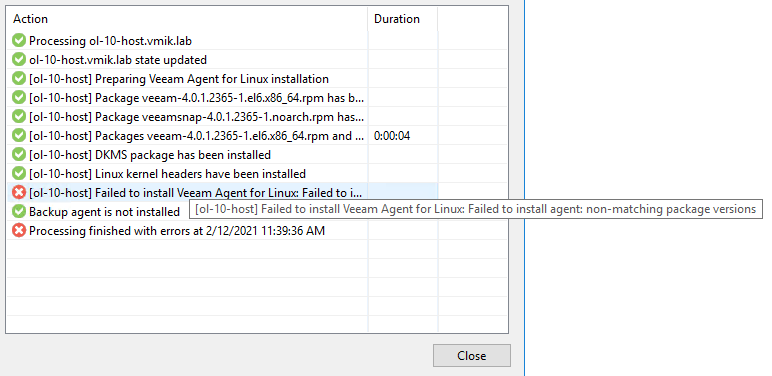
Процесс установки прошел немного дальше, но как можно заметить, теперь у нас новая ошибка:
«Failed to install Veeam Agent for Linux: non-matching package versions»
В логах тоже не особо информативно
«Failed to execute command modinfo, output: ERROR: modinfo: could not find module veeamsnap»
Очевидны проблемы с модулем veeamsnap. Поиски выводят на очередную KB от Veeam. Согласно KB проверяем статус dkms на машине, где устанавливается агент:
# dkms status
veeamsnap, 4.0.1.2365: added
Как можно заметить, модуль добавлен, но не скомпилирован. Пробуем скомпилировать модуль veeamsnap:
# dkms build -m veeamsnap -v 4.0.1.2365
Your kernel headers for kernel 4.1.12-124.48.2.el6uek.x86_64 cannot be found at /lib/modules/4.1.12-124.48.2.el6uek.x86_64/build or /lib/modules/4.1.12-124.48.2.el6uek.x86_64/source.
Понятно, отсутствуют требуемые исходные коды текущего ядра для сборки модуля. Устанавливаем:
# yum install kernel-uek-devel-`uname -r` kernel-headers
Yum установит пакет kernel-uek-devel версии, аналогичной текущему работающему ядру. Пробуем вновь выполнить dkms build:
# dkms build -m veeamsnap -v 4.0.1.2365
Kernel preparation unnecessary for this kernel. Skipping...
Building module:
cleaning build area...
make -j1 KERNELRELEASE=4.1.12-124.48.2.el6uek.x86_64 -C /lib/modules/4.1.12-124.48.2.el6uek.x86_64/build M=/var/lib/dkms/veeamsnap/4.0.1.2365/build......
cleaning build area...
DKMS: build completed.
Теперь проверим статус dkms:
# dkms status
veeamsnap, 4.0.1.2365, 4.1.12-124.48.2.el6uek.x86_64, x86_64: built
Как можно заметить, статус veeamsnap изменен с added на built.
Возвращаюсь в консоль Veeam и запускаю процесс установки агента без предварительного удаления всех компонентов. Система очень быстро рапортует о том, что агент уже установлен и работает:

Создаю задачу резервного копирования, пробую сделать резервную копию всей машины:
Failed to load module [veeamsnap] with parameters [zerosnapdata=1 debuglogging=0 snapstore_block_size_pow=14 change_tracking_block_size_pow=18 logdir=/var/log/veeam fixflags=0 logmaxsize=15728640].
Очередная ошибка.
Возвращаюсь в консоль Veeam и пробую вновь переустановить агент. На этот инсталлятор сообщает об успехе на всех этапах установки.
Важный момент, сперва я удаляю все остатки агента через Uninstall, затем устанавливаю заново через Install:
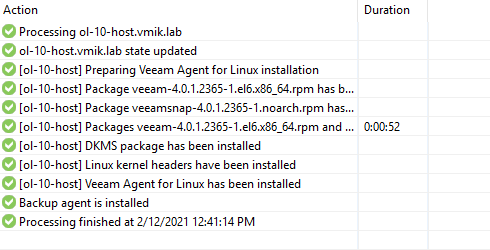
Вновь запускаю задачу резервного копирования, пробую сделать резервную копию всей машины. Успешно:
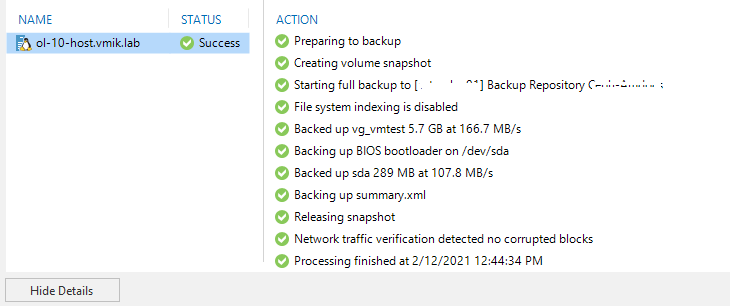
Вот так, через несколько разных документаций устанавливается агент под Oracle Linux 6.
В качестве заключения:
Опустив весь процесс траблшутинга, прикладываю список команд, чтобы поставить все с первого раза:
# yum install kernel-devel elfutils-libelf-devel gcc# rpm -ivh https://archives.fedoraproject.org/pub/archive/epel/6/x86_64/Packages/d/dkms-2.4.0-1.20170926git959bd74.el6.noarch.rpm# yum install kernel-uek-devel-`uname -r` kernel-headers
Теперь можно устанавливать агент и, скорее всего, он даже установится с первого раза без чтения документации.