Challenge
This article discusses an error that occurs due to VSS and Veeam’s Guest Processing technique for Domain Controllers. It is relevant to all backup jobs for both virtual and physical Domain Controllers.
A job processing a Domain Controller with Application-Aware Processing fails with one of the following errors:
Unable to release guest. Details: Unfreeze error: [Backup job failed. Cannot create a shadow copy of the volumes containing writer's data. A VSS critical writer has failed. Writer name: [NTDS]. Class ID: [{b2014c9e-8711-4c5c-a5a9-3cf384484757}]. Instance ID: [{66fddc15-0e4c-4a2a-ad31-32eaf6dae8a3}]. Writer's state: [VSS_WS_FAILED_AT_POST_SNAPSHOT]. Error code: [0x800423f4].]
Solution
The actions listed in this section are to be performed within the Guest OS of the DC that is having these issues.
Attempt each of the following troubleshooting angles individually, testing the job after each.
Reboot the Domain Controller
As these errors are related to the Microsoft VSS subsystem, a reboot often is the fastest way to alleviate any issue which may be occurring at the OS level.
Isolate Anti-Virus Interference
Disabling the anti-virus temporarily can help isolate whether the issue is related to interference from the anti-virus. Disableuninstall the anti-virus fully and run the Veeam job. If the job works, reenablereinstall the antivirus, and if the job begins to fail again, the anti-virus needs to be investigated.
Many anti-virus solutions have developed modules that monitor and prevent access to the boot configuration data (BCD). These «boot protection modules» have been observed to prevent Veeam’s Application-Aware Processing processing from working with Domain Controllers. During the backup job’s Application-Aware Processing step, for Domain Controllers only, the BCD is temporarily modified to enable SafeBoot.
For more information about anti-virus exclusions recommended for Veeam Backup & Replication review: https://www.veeam.com/kb1999
Verify that the NTDS VSS writer is stable
From an elevated command prompt run the following command:
If the NTDS writer is not listed as "State: [1]Stable", reboot the Domain Controller.
If the NTDS VSS writer fails to remain stable and job failures persist, further investigation using VSS Trace may be necessary.
Note: If the NTDS writer does not appear in the list, it is advisable to contact Microsoft support to investigate why the writer is not present.
More Information
Isolating VSS issue using Windows Server Backup
As an isolation step, enable the Windows Server Backup feature within Server Manager. Then perform a full backup, including the system state.
If this fails with a similar VSS error, there is likely an OS-level issue that will require deeper investigation. Veeam Support will do its best to assist with investigating and will be available to work with you and Microsoft Support.
Rarer Solutions
The following are solutions that have been reported to Veeam Support by multiple customers facing an NTDS VSS issue. While rare, these have been shown to resolve OS issues that may be preventing the VSS operations from completing. They are provided here to aid in the possible resolution of edge cases.
Verify that there are no .bak keys in the ProfileList within the Registry.
HKLMSoftwareMicrosoftWindows NTCurrentVersionProfileList

Example of .bak profile
Check for WMI repository corruption and rebuild the WMI repository.
To submit feedback regarding this article, please click this link: Send Article Feedback
To report a typo on this page, highlight the typo with your mouse and press CTRL + Enter.
Verify Sufficient Free Space
Within the VM guest OS that cannot be backed up or replicated, use the Disk Management utility (diskmgmt.msc) to view free space on each NTFS volume:

If a volume is low on disk space, the solution is to delete files, expand the volume, or redirect shadow copies to another volume. For virtual machines, the simplest solution is usually to increase the size of the VM’s hard disk, then expand the volume in Disk Management.
Although it is sometimes possible to create a shadow copy using less than 1% of the free space on a volume, 15%-20% free space is often required on busy volumes. The smallest amount of space that can be allocated is configurable, but Microsoft Support has recommended maintaining at least 42 MB free on the system reserved partition.
If it is not clear which volume has insufficient space, see “How to Check Which Volume is Causing the Error”, below.
(Optionally) Redirect Shadow Copies
It is possible to change the shadow storage association to use a volume with sufficient free space; The location can be changed from the Shadow Copies utility, or from the command line. To access the utility, right click any volume and choose Configure Shadow Copies.
Warning: This is not recommended in a Hyper-V environment.
Shadow Copies Utility (Server OS Only)
To access the utility, right click any volume and choose Configure Shadow Copies. On older server operating systems, this may instead be a tab in Properties.
- Select the volume with insufficient space;
- Click Settings…
- In the dropdown labeled Located on this volume, select a volume with sufficient space to store the shadow copies.
Command Line (Client or Server OS)
All commands below should be run from an administrator command prompt.
Use vssadmin list shadowstorage to view existing shadow storage associations. If no shadow storage exists for any volume, the command response will be “No items found that satisfy the query.”
If no association is listed for the volume, run vssadmin add shadowstorage to change the location of the shadow storage area. For example, to redirect shadows from D: to E:
vssadmin add shadowstorage /for=D: /on=E: /maxsize=200GB
If a shadow storage association already exists, run vssadmin resize shadowstorage to change the size of the shadow storage area. For example, to redirect shadows from D: to E:
vssadmin resize shadowstorage /for=D: /on=E: /maxsize=200GB
The /maxsize parameter is not optional, but can be set as /maxsize=UNBOUNDED. Otherwise, a value of 15-20% of the source volume’s size is generally recommended for busy servers.
How to Check Which Volume is Causing the Error
In some cases, it may not be obvious which volume needs to be modified. To isolate the problem, perform the following steps within the VM guest OS that cannot be backed up or replicated.
Create and then delete a shadow copy of each volume, one at a time. To access the GUI, right click any volume and choose Configure Shadow Copies. On older operating systems, this may instead be a tab in Properties. In the Shadow Copies utility:
- Select a volume;
- Click Create Now;
- If this is successful, select the shadow copy and click Delete Now;
- Repeat steps 1-3 for each volume.
This can also be performed using the Diskshadow utility, which may provide a better match for the behavior of the VSS API used by Veeam Backup & Replication.
If the affected volume has sufficient free disk space, the shadow storage limit may be too small. Redirect the shadow copies as shown above, or increase the shadow storage limit.
While we had some hardware errors and failures on our physical Veeam proxie and repository servers in the past, we tought it was a good idea to get them at least backud upped regularly through Veeam’s own Physical & Cloud Infrastructure. Yes, we did put them in a protection group. How insignificant it may seem, it give us some advantages like recovery media (ISO), different restore possibilities etc. Just in case we might need it in the future. It must be said that we are only backuing up the operating system and the C: and D: volumes, not the backup data itself.
So the idea was to backup one proxy and repository from the A. datacenter to the repository server in the B. datacenter and vice versa. So, after configuring the protection group, installing the driver and creating the backup job, one repository server backup job failed and kept on failing with the following message:
7/23/2019 12:51:55 PM :: Creating VSS snapshot Error: Failed to create snapshot: Backup job failed.
Cannot create a shadow copy of the volumes containing writer’s data.
VSS asynchronous operation is not completed. Operation: [Shadow copies commit]. Code: [0x80042306].
This could only mean that on first hand we have a problem with the VSS (Volume Shadow Copy service) or something related to thatm and that could mean a lot of other things. So first I started to look at the VSS writers on the repository server with vssadmin list writers :
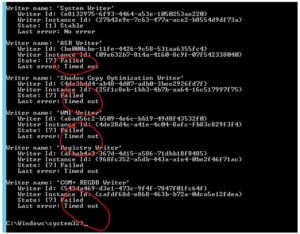
As you can see in the above screen capture, the last error is : Timed Out. So lets take a look at the event viewer.
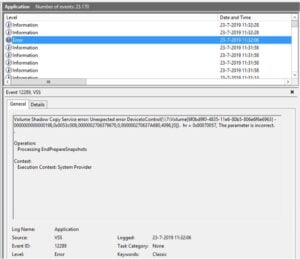
So it has something to do with VSS; accounts and permissions perhaps? So let’s fire up DCOMCNFG and lets find out if there is a problem with an account or a permission.
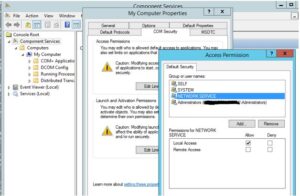
Everything looks allright and even the registry setting of the VSSAccessControl seems to be OK:
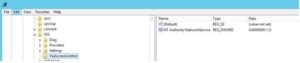
By now it is time to take a look at some Veeam logging to see what is actualy going on, and to give us some more indepth knowledge of the problem.
So the log file to look for would be the name of the job in which we are backing up the physical machine, in this case the name of the log file is Job.PRD_Physical_Backup_Prot-Grp-Name_-_extension.log.
Here is what we have found:
The process of committing shadow copies is failing.
[22.07.2019 15:22:24] Info < a60> Commiting shadow copies.
[22.07.2019 15:22:25] Info < a60> Commiting shadow copies.. Failed.
[22.07.2019 15:22:25] Info < a60> Cancelling changes made to prepare an application for a subsequent restore operation. Application: [NTDS].
[22.07.2019 15:22:25] Info < a60> There is no changes related to the NDIS service or changes were already cancelled.
[22.07.2019 15:22:25] Info < a60> Cancelling changes made to prepare an application for a subsequent restore operation. Application: [NTDS].. Ok.
[22.07.2019 15:22:25] Info < a60> Cancelling changes (if exists) that were made before the freeze stage in order to support Exchange server writer.
[22.07.2019 15:22:25] Info < a60> Cancellation of changes made to support Exchange Server writer is not required.
[22.07.2019 15:22:25] Info < a60> Cancelling changes (if exists) that were made before the freeze stage in order to support Exchange server writer.. Ok.
[22.07.2019 15:22:25] Info < a60> Creating a shadow copy of the volumes containing writer’s data. Backup type: ‘VSS_BT_FULL’.. Failed.
[22.07.2019 15:22:25] Info < a60> Performing backup steps. Backup type: [VSS_BT_FULL].. Failed.
[22.07.2019 15:22:25] Info < a60> Terminating the snapshot set. Snapshot set ID: [{198b61f6-f167-473b-af85-5fda94efeddb}].
[22.07.2019 15:22:25] Info < a60> Terminating the snapshot set. Snapshot set ID: [{198b61f6-f167-473b-af85-5fda94efeddb}].. Ok.
[22.07.2019 15:22:25] Error < a60> Freeze job failed.
[22.07.2019 15:22:25] Warning < a60> Backup job failed.
[22.07.2019 15:22:25] Warning < a60> Cannot create a shadow copy of the volumes containing writer’s data.
[22.07.2019 15:22:25] Warning < a60> VSS asynchronous operation is not completed. Operation: [Shadow copies commit]. Code: [0x80042306].
[22.07.2019 15:22:27] <01> Info Failed to create snapshot. Error code -2147467259. ‘Backup job failed.
[22.07.2019 15:22:27] <01> Info Cannot create a shadow copy of the volumes containing writer’s data.
Usually this might happen due to insufficient space for shadow copy storage.
As you now can see in the output of the vssadmin list shadowstorage command, listed is only the shadow copy storage for C: volume.
vssadmin 1.1 — Volume Shadow Copy Service administrative command-line tool
(C) Copyright 2001-2013 Microsoft Corp.
Shadow Copy Storage association
For volume: (C:)?Volume{6f0bd9f1-4835-11e6-80b5-806e6f6e6963}
Shadow Copy Storage volume: (C:)?Volume{6f0bd9f1-4835-11e6-80b5-806e6f6e6963}
Used Shadow Copy Storage space: 0 bytes (0%)
Allocated Shadow Copy Storage space: 0 bytes (0%)
Maximum Shadow Copy Storage space: 36,5 GB (25%)
So what we need to do is to add to the snapshot set [?Volume{6f0bd9f0-4835-11e6-80b5-806e6f6e6963}] and [?Volume{6f0bd9f1-4835-11e6-80b5-806e6f6e6963}].
[22.07.2019 15:22:23] Info < a60> The following volumes should be added to the snapshot set.
[22.07.2019 15:22:23] Info < a60> {
[22.07.2019 15:22:23] Info < a60> [?Volume{6f0bd9f0-4835-11e6-80b5-806e6f6e6963}]. Mount point: []
[22.07.2019 15:22:23] Info < a60> [?Volume{6f0bd9f1-4835-11e6-80b5-806e6f6e6963}]. Mount point: [C:]
[22.07.2019 15:22:23] Info < a60> }
To add the shadow copy storage for the system reserved volume to the C: volume we need to use the below command (command prompt with administrative privileges):
vssadmin add shadowstorage /for=?Volume{6f0bd9f0-4835-11e6-80b5-806e6f6e6963} /on=C: /maxsize=unbounded
From there on, just restarted the job and everything went just fine…
Arie-Jan Bodde

Virtualization Consultant
Let’s talk!
Knowledge is key for our existence. This knowledge we use for disruptive innovation and changing organizations. Are you ready for change?
«*» indicates required fields
I recently utilized VMware Converter for a Microsoft Hyper-V to VMware conversion. After the conversion, Veeam backups started failing on the converted machines due to a VSSControl Error. The error stated:
Failed to prepare guest for hot backup. Error: VSSControl: -2147212529 Backup job failed.
Discovery phase failed.
Cannot add volumes to the snapshot set.
Cannot add volume to the set of volumes that should be shadowed.
VSS error: VSS_E_UNEXPECTED_PROVIDER_ERROR. Code:0x8004230f
![]()
As per Veeam, this error is due to a third party or incompatible VSS provider component still installed on the virtual machine. Let’s look at how to check and remediate the issue.
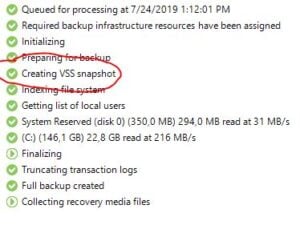
Check Volume Shadow Copy Service (VSS) Providers Installed
On the guest OS, open the command prompt as an administrator and run the vssadmin list providers command. Looking at the results, we can see a list of providers and among them is a leftover Hyper-V IC Software Shadow Copy Provider. Since the vm now resides on vSphere, we can infer that this provider is likely causing issues when VSS is initiated during backup.
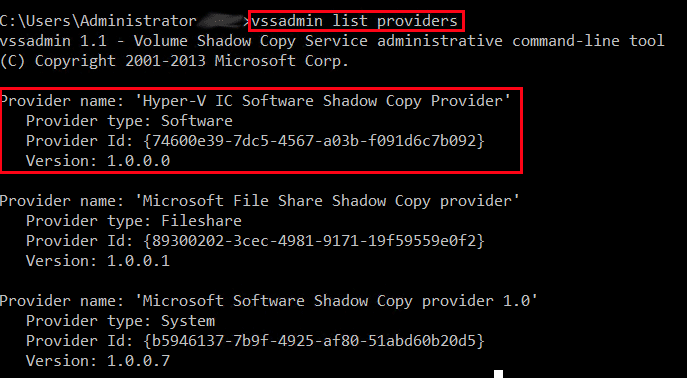
To verify this is the pertinent provider, we can check logs in Event Viewer. Typically, EventID 12292 and 22 in the Application logs will indicate VSS issues.

Under the General tab of the Event, we can see the Provider ID associated with the error. In our case, the affected Provider ID matches that of the Hyper-V IC Software Shadow Copy Provider from above.
As a solution, we can remove the Hyper-V IC Software Shadow Copy Provider. To do so, the registry key for that provider must be removed.
NOTE: Best practice dictates backing up the entire registry or that registry key before removal.
Remove VSS Providers from Registry
Open the Registry Editor (regedit) on the affected virtual machine.

Navigate to HKEY_LOCAL_MACHINESYSTEMCurrentControlSetservicesVSSProviders
If you haven’t done so already, back up the registry. Next, right-click the key and select Delete.
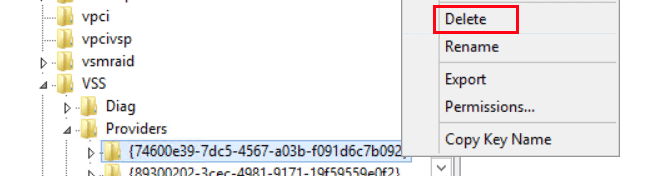
Lastly, open Windows Services and restart the Volume Shadow Copy service (or restart the virtual machine).
Hi all.
I’ll try to keep this succinct but provide all relevant detail where possible 
We have 2 physical 2012 R2 Core servers running as Hyper-V hosts, not clustered; let’s call them Server-A and Server-B.
Both server installations are on 30GB USB sticks. Server-A is a Dell Poweredge 1950, Server-B a Dell Poweredge R710 (probably not relevant). For all intents and purposes the installations should be identical.
Server-A hosts Legacy Generation 1 VM’s, Server-B hosts all Gen 2 VM’s.
Using Veeam B&R 9.5 Free Edition, all VM’s on Server-A backup just fine, not a single VM on Server-B will backup using Veeam.
Both servers will successfully allow VM backups via DPM and Windows Backup will succeed when logged into any VM. I am also able to manually create shadow copies on any VM via CMD line.
I moved a Gen 1 VM from Server-A to Server-B and a Veeam backup failed.
I moved a Gen 2 VM from Server-B to Server-A and a Veeam backup succeeded.
It appears to me that there is an issue (VSS) on Server-B that I can’t identify.
Veeam is installed on a 2012 R2 Standard Edition server (Server-C).
When a Veeam backup is attempted on a VM hosted by Server-B I have located these Logs and reports:
Veeam history log report:
Text
Failed to create snapshot (Microsoft Software Shadow Copy provider 1.0) (mode: Hyper-V child partition snapshot) Details: Unknown status of async operation Vss error: '0x80070057' --tr:Failed to create VSS snapshot. --tr:Failed to perform pre-backup tasks. Retrying snapshot creation attempt (Unknown status of async operation Vss error: '0x80070057' --tr:Failed to create VSS snapshot. --tr:Failed to perform pre-backup tasks.) Task has been rescheduled Queued for processing at 1/23/2017 2:50:13 PM Unable to allocate processing resources. Error: Unknown status of async operation Vss error: '0x80070057' --tr:Failed to create VSS snapshot. --tr:Failed to perform pre-backup tasks.
On the Veeam host, C:/ProgramData/Veeam/BackUp/Task.VMName.txt
Text
[23.01.2017 14:50:02] <07> Info Guest won't be initialized: No guest features required.[23.01.2017 14:50:02] <07> Info [RTS] [COTESS-MEL-FS1] Creating pre-snapshot CTP timestamps for VM 'COTESS-MEL-FS1', vmId 'bf954a13-b9b5-4ac3-9c4a-3a5f3922d74a'.[23.01.2017 14:50:02] <07> Info [COTESS-MEL-FS1] Creating pre-snapshot CTP timestamps for VM 'COTESS-MEL-FS1', vmId 'bf954a13-b9b5-4ac3-9c4a-3a5f3922d74a'.[23.01.2017 14:50:02] <07> Error [COTESS-MEL-FS1] Failed to flush change tracking data for VM COTESS-MEL-FS1 before snapshot.[23.01.2017 14:50:02] <07> Error Changed block tracking is disabled for VMs in job [COTESS-MEL-FS1_2017-01-23T144941]. (System.Exception)[23.01.2017 14:50:02] <07> Error at Veeam.Backup.Core.ResourceScheduler.CCtpGenerator.PreSnapshotVmFlush(CHvVmSnapshotData vm)[23.01.2017 14:50:02] <07> Info [RTS] [COTESS-MEL-FS1] Creating snapshot Microsoft Software Shadow Copy provider 1.0 (mode: Hyper-V child partition snapshot)[23.01.2017 14:50:02] <07> Info [COTESS-MEL-FS1] Creating snapshot Microsoft Software Shadow Copy provider 1.0 (mode: Hyper-V child partition snapshot)[23.01.2017 14:50:02] <07> Info Prepare AutoMount feature on host 'VMHMEL02'.[23.01.2017 14:50:02] <07> Info AutoMount is 'enabled'.[23.01.2017 14:50:02] <07> Info [RTS] Starting snapshot creation, spec '<?xml version="1.0"?><HVBackupSpec><VMs><VM id="BF954A13-B9B5-4AC3-9C4A-3A5F3922D74A" crashConsistent="0" /></VMs><volumes><volProvider volMountPoint="D:" id="b5946137-7b9f-4925-af80-51abd60b20d5" type="1" /></volumes><Settings UseCsvVssWriter="0" Persistent="0" SnapInProgressRetryCount="0" SnapInProgressRetryWaitSec="30" /></HVBackupSpec>'[23.01.2017 14:50:02] <07> Info [hv-'VMHMEL02'] Starting snapshot creation. JobName 'COTESS-MEL-FS1_2017-01-23T144941'[23.01.2017 14:50:03] <07> Info [RTS] On-host snapshot started, id 'e17e7bad-629f-43b2-a124-b824a9151032'[23.01.2017 14:50:03] <07> Info [COTESS-MEL-FS1] On-host snapshot started, id 'e17e7bad-629f-43b2-a124-b824a9151032'[23.01.2017 14:50:13] <07> Warning [COTESS-MEL-FS1] Skipping post-snapshot ctp flush for VM 'COTESS-MEL-FS1', id 'bf954a13-b9b5-4ac3-9c4a-3a5f3922d74a' : pre-snapshot ctp flush has failed.[23.01.2017 14:50:13] <07> Warning [COTESS-MEL-FS1] Failed to create snapshot (Microsoft Software Shadow Copy provider 1.0) (mode: Hyper-V child partition snapshot)[23.01.2017 14:50:13] <07> Error Unknown status of async operation[23.01.2017 14:50:13] <07> Error Vss error: '0x80070057'[23.01.2017 14:50:13] <07> Error --tr:Failed to create VSS snapshot.[23.01.2017 14:50:13] <07> Error --tr:Failed to perform pre-backup tasks. (System.Exception)[23.01.2017 14:50:13] <07> Error Unknown status of async operation[23.01.2017 14:50:13] <07> Error Vss error: '0x80070057'[23.01.2017 14:50:13] <07> Error --tr:Failed to create VSS snapshot.[23.01.2017 14:50:13] <07> Error --tr:Failed to perform pre-backup tasks. (System.Exception)[23.01.2017 14:50:13] <07> Error [RTS] On-host snapshot was not created. Result: ERR: [Unknown status of async operation[23.01.2017 14:50:13] <07> Error Vss error: '0x80070057'[23.01.2017 14:50:13] <07> Error --tr:Failed to create VSS snapshot.[23.01.2017 14:50:13] <07> Error --tr:Failed to perform pre-backup tasks.][23.01.2017 14:50:13] <07> Error [COTESS-MEL-FS1] On-host snapshot was not created. Result: ERR: [Unknown status of async operation[23.01.2017 14:50:13] <07> Error Vss error: '0x80070057'[23.01.2017 14:50:13] <07> Error --tr:Failed to create VSS snapshot.[23.01.2017 14:50:13] <07> Error --tr:Failed to perform pre-backup tasks.][23.01.2017 14:50:13] <07> Info [CHvSnapshotCreationLocker] Unlocking snapshot creation[23.01.2017 14:50:13] <07> Info [CHvSnapshotHolder] Non shared snapshot created[23.01.2017 14:50:13] <07> Info [CHvSnapshotWrapper] Try dispose snapshot for task 'b64a1cd3-a12d-4132-b5b7-658688ac0c74'[23.01.2017 14:50:13] <07> Info [CHvSnapshotWrapper] Remaining tasks count: '0'[23.01.2017 14:50:13] <07> Info [CHvSnapshotWrapper] Closing snapshot[23.01.2017 14:50:13] <07> Warning [RTS] Marking snapshot 'e17e7bad-629f-43b2-a124-b824a9151032' deletion: snapshot was not taken[23.01.2017 14:50:13] <07> Warning [COTESS-MEL-FS1] Marking snapshot 'e17e7bad-629f-43b2-a124-b824a9151032' deletion: snapshot was not taken[23.01.2017 14:50:13] <07> Info [CHvSnapshotCreationLocker] Trying to lock snapshot creation[23.01.2017 14:50:13] <07> Info [hv-'VMHMEL02'] Closing snapshot '43dfddaf-7ad2-4131-85a2-e76a64f1a6e5'.[23.01.2017 14:50:13] <07> Info [CHvSnapshotCreationLocker] Unlocking snapshot creation[23.01.2017 14:50:13] <07> Info CVeeamHvAsyncOp dispose...[23.01.2017 14:50:13] <07> Info [RTS] Removing '0' temp CT files...[23.01.2017 14:50:13] <07> Info [CProxyRpcInvoker] RpcInvoker HashCode:18611865 was disposed[23.01.2017 14:50:13] <07> Info [CHvSnapshotHolder] Non shared snapshot created[23.01.2017 14:50:13] <07> Info Reschedule task limit check is active, current try: 0, limit: 5[23.01.2017 14:50:23] <07> Info Disposing CBackupClient [0x13aa24e][23.01.2017 14:50:23] <07> Info [AP] Disposing client from thread 7[23.01.2017 14:50:23] <07> Info Disposing BaseAgentProtocol [0x8eec24][23.01.2017 14:50:23] <07> Info Disposing CSocketAgentService [0x26c70bb], sessionId [345d][23.01.2017 14:50:23] <07> Info [SocketAgentService] Closing connection to agent 'VMHMEL02', id 345d[23.01.2017 14:50:23] <07> Info [ReconnectableSocket] Stop request was sent on [cd149deb-d238-4ccc-84c5-29d3b3058ef8].[23.01.2017 14:50:23] <14> Info [ReconnectableSocket][StopCondition] Stop confirmation was received on [cd149deb-d238-4ccc-84c5-29d3b3058ef8].[23.01.2017 14:50:23] <14> Info [ReconnectableSocket] Stop confirmation was sent on [cd149deb-d238-4ccc-84c5-29d3b3058ef8].[23.01.2017 14:50:23] <14> Info [ReconnectableSocket][StopCondition] Stop request was received on [cd149deb-d238-4ccc-84c5-29d3b3058ef8].[23.01.2017 14:50:23] <07> Info Disposing CProxyAgent [0x3fa8822], agent id def0ce75-ca6e-4167-8916-174ede201414[23.01.2017 14:50:23] <18> Info [AP] (33e8) command: 'Invoke: Generic.AbortReconnectsn'[23.01.2017 14:50:23] <14> Info [AP] (33e8) output: <VCPCommandResult result="true" exception="" />[23.01.2017 14:50:23] <14> Info [AP] (33e8) output: <VCPCommandArgs />[23.01.2017 14:50:23] <14> Info [AP] (33e8) output: >[23.01.2017 14:50:23] <18> Info [RemoteAgentSystemSession] Keep-alive thread operation is canceled.[23.01.2017 14:50:23] <07> Info Disposing CBackupClient [0x34b8c69][23.01.2017 14:50:23] <07> Info [AP] Disposing client from thread 7[23.01.2017 14:50:23] <07> Info Disposing BaseAgentProtocol [0xbd19a1][23.01.2017 14:50:23] <07> Info Disposing CSocketAgentService [0x604dda], sessionId [33e8][23.01.2017 14:50:23] <07> Info [SocketAgentService] Closing connection to agent 'VMHMEL02', id 33e8[23.01.2017 14:50:24] <07> Info [AgentMngr] Stopping agent, id 'def0ce75-ca6e-4167-8916-174ede201414'[23.01.2017 14:50:24] <07> Info [AgentMngr] Sending signal to stop agent, id 'def0ce75-ca6e-4167-8916-174ede201414'. Host: 'VMHMEL02'.[23.01.2017 14:50:24] <07> Info [AgentMngr] Checking whether agent 'def0ce75-ca6e-4167-8916-174ede201414' is alive on host 'VMHMEL02'.[23.01.2017 14:50:25] <07> Info [AgentMngr] Checking whether agent 'def0ce75-ca6e-4167-8916-174ede201414' is alive on host 'VMHMEL02'.[23.01.2017 14:50:25] <07> Info [AgentMngr] Agent has been stopped, id 'def0ce75-ca6e-4167-8916-174ede201414'[23.01.2017 14:50:25] <07> Info [CProxyRpcInvoker] RpcInvoker HashCode:6949155 was disposed[23.01.2017 14:51:26] <06> Info [AP] (1fb0) command: 'Invoke: Generic.AbortReconnectsn'[23.01.2017 14:51:26] <22> Info [AP] (1fb0) output: <VCPCommandResult result="true" exception="" />[23.01.2017 14:51:26] <24> Info [AP] (1fb0) output: <VCPCommandArgs />[23.01.2017 14:51:26] <24> Info [AP] (1fb0) output: >[23.01.2017 14:51:26] <06> Info [RemoteAgentSystemSession] Keep-alive thread operation is canceled.
When attempting a backup with Veeam, this is the error in Server-B event log:
(In fact, this error appears in Server-B’s event log every ~4.0 Hrs)
Text
Server-B 12294 Error VSS Application23/01/2017 2:50:05 PM
Volume Shadow Copy Service error: Error calling a routine on the Shadow Copy Provider {b5946137-7b9f-4925-af80-51abd60b20d5}. Routine returned E_INVALIDARG. Routine details EndPrepareSnapshots({c5ca6ae8-b5fc-4361-a13a-f004fccbc910}).
Operation:
Executing Asynchronous Operation
Context:
Current State: DoSnapshotSet
Job progress displayed on Veeam when a backup is attempted:
Text
1/24/2017 11:25:24 AM :: Job started at 1/24/2017 11:25:23 AM 1/24/2017 11:25:24 AM :: Building VMs list 1/24/2017 11:25:32 AM :: VM size: 127.0 GB (30.4 GB used) 1/24/2017 11:25:32 AM :: Changed block tracking is disabled 1/24/2017 11:25:32 AM :: Waiting for the next task 1/24/2017 11:25:38 AM :: Waiting for the next task 1/24/2017 11:27:10 AM :: Job finished with error at 1/24/2017 11:27:10 AM
There is no corresponding error on the VM being backed up, but there are VSS errors registered at non-corresponding times:
Text
VM-B 8193 Error VSS Application 23/01/2017 3:12:56 PM Volume Shadow Copy Service error: Unexpected error calling routine GetVolumeNameForVolumeMountPoint is now failing on the volume, winerror 0x00000001. . hr = 0x80070001, Incorrect function. .
I have noticed that issuing this command on Server-B:
vssadmin list writers
Will show all writers in a «Stable, No Error» condition until I attempt a Veeam backup. After the attempt:
Microsoft Hyper-V VSS Writer will show a «State: [7] Failed, Last Error: Timed Out» condition. (Easy fixed by restarting the vmms service). All other writers not affected.
Any advice will be greatly appreciated.
Cheers, Andrew.
Hey all we have a new client that had some issues with previuos provider so we rolled out our datto and ran into errors where it has predictive failed drives (despite apparantely being replaced with brand new drives) and it cannot run.
While I hunt and troubleshoot that main issue I’m loking to get veeam agent running just so we have a set of good backups (as we have NONE) right now.
However we’re unable to run due to vss errors:
C:Windowssystem32>vssadmin list writers
vssadmin 1.1 - Volume Shadow Copy Service administrative command-line tool
(C) Copyright 2001-2012 Microsoft Corp.
Writer name: 'Task Scheduler Writer'
Writer Id: {d61d61c8-d73a-4eee-8cdd-f6f9786b7124}
Writer Instance Id: {1bddd48e-5052-49db-9b07-b96f96727e6b}
State: [1] Stable
Last error: No error
Writer name: 'VSS Metadata Store Writer'
Writer Id: {75dfb225-e2e4-4d39-9ac9-ffaff65ddf06}
Writer Instance Id: {088e7a7d-09a8-4cc6-a609-ad90e75ddc93}
State: [1] Stable
Last error: No error
Writer name: 'Performance Counters Writer'
Writer Id: {0bada1de-01a9-4625-8278-69e735f39dd2}
Writer Instance Id: {f0086dda-9efc-47c5-8eb6-a944c3d09381}
State: [1] Stable
Last error: No error
Writer name: 'System Writer'
Writer Id: {e8132975-6f93-4464-a53e-1050253ae220}
Writer Instance Id: {4d1cb600-5f51-49a1-a1d8-c241a4710a13}
State: [1] Stable
Last error: No error
Writer name: 'SqlServerWriter'
Writer Id: {a65faa63-5ea8-4ebc-9dbd-a0c4db26912a}
Writer Instance Id: {f52c837c-5a3f-420b-9acf-4037544e51f9}
State: [10] Failed
Last error: Timed out
Writer name: 'ASR Writer'
Writer Id: {be000cbe-11fe-4426-9c58-531aa6355fc4}
Writer Instance Id: {905bd48d-ff68-42f6-9a8b-962cfcf82b92}
State: [10] Failed
Last error: Timed out
Writer name: 'FSRM Writer'
Writer Id: {12ce4370-5bb7-4c58-a76a-e5d5097e3674}
Writer Instance Id: {fc877ca8-0c41-4750-a424-606332a956bd}
State: [10] Failed
Last error: Timed out
Writer name: 'MSSearch Service Writer'
Writer Id: {cd3f2362-8bef-46c7-9181-d62844cdc0b2}
Writer Instance Id: {41131c1f-94d8-4754-ab85-f5a8faa8cb63}
State: [10] Failed
Last error: Timed out
Writer name: 'Shadow Copy Optimization Writer'
Writer Id: {4dc3bdd4-ab48-4d07-adb0-3bee2926fd7f}
Writer Instance Id: {bfab825e-4857-4528-8b63-7175036d92fc}
State: [10] Failed
Last error: Timed out
Writer name: 'Registry Writer'
Writer Id: {afbab4a2-367d-4d15-a586-71dbb18f8485}
Writer Instance Id: {c5618d95-c3a5-48a8-a093-df03c8c0641d}
State: [10] Failed
Last error: Timed out
Writer name: 'DFS Replication service writer'
Writer Id: {2707761b-2324-473d-88eb-eb007a359533}
Writer Instance Id: {761c5b7a-1c8d-4ecc-8c6c-76f50ed740d9}
State: [10] Failed
Last error: Timed out
Writer name: 'IIS Config Writer'
Writer Id: {2a40fd15-dfca-4aa8-a654-1f8c654603f6}
Writer Instance Id: {4d53d7a8-a879-4e50-9455-a6985fd50605}
State: [10] Failed
Last error: Timed out
Writer name: 'BITS Writer'
Writer Id: {4969d978-be47-48b0-b100-f328f07ac1e0}
Writer Instance Id: {2e40e857-d5ec-434b-b28e-0fd7e0cc8846}
State: [1] Stable
Last error: No error
Writer name: 'WMI Writer'
Writer Id: {a6ad56c2-b509-4e6c-bb19-49d8f43532f0}
Writer Instance Id: {f643506c-d78b-44a5-bdf5-f71e461a8c87}
State: [10] Failed
Last error: Timed out
Writer name: 'COM+ REGDB Writer'
Writer Id: {542da469-d3e1-473c-9f4f-7847f01fc64f}
Writer Instance Id: {a4373d26-bb05-449f-978b-4373bdf49241}
State: [10] Failed
Last error: Timed out
Writer name: 'Windows Server Storage VSS Writer'
Writer Id: {e376ebb9-f0fe-4e1a-adaa-bfbdaf3ab488}
Writer Instance Id: {8b48118f-7886-43fb-b782-5ba06ddd03ec}
State: [10] Failed
Last error: Timed out
Writer name: 'NTDS'
Writer Id: {b2014c9e-8711-4c5c-a5a9-3cf384484757}
Writer Instance Id: {84582b86-1a67-4ebd-8f3b-a9d2765cdfa0}
State: [10] Failed
Last error: Non-retryable error
C:Windowssystem32>
Veeam errors:
2019-10-29 8:03:08 PM :: Creating VSS snapshot Error: Failed to create snapshot: Backup job failed.
Cannot create a shadow copy of the volumes containing writer’s data. VSS asynchronous operation is not completed. Operation: [Shadow copies commit]. Code: [0x80042306].
I’ve already tried rebooting several times, restarting individual writers, removed the datto agent and created a p2 veeam ticket.
Knowledge Base
-
Home
-
Knowledge Base
-
Windows Agent Backups
-
Agent Job Errors
-
Troubleshooting: Job Errors
-
Home
-
Knowledge Base
-
Virtual Machine Backups
-
VM Job Errors
-
Troubleshooting: Job Errors
-
Home
-
Knowledge Base
-
Troubleshooting
-
Troubleshooting: Job Errors
General Troubleshooting: Veeam Backup Job Errors
Below are common host and backup job error messages you may encounter and what they mean.
This article is organized by Alarm Type:
- Backup Agent Job State Errors
- Job Session State Errors
- Job Status Errors
- Computer/VM Not Backed Up
- Miscellaneous
For Additional Errors Not Listed Below, Consult the Veeam Knowledge Base and/or Forums:
- Veeam Knowledge Base – https://www.veeam.com/kb_search_results.html
- Veeam Community Forums – https://forums.veeam.com/
1. Backup Agent Job State Errors
Error: write: An existing connection was forcibly closed by the remote host Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}.
What This Means
- The last backup job was unsuccessful because the remote host (machine backing up) closed the connection to eSilo while the backup was running.
Possible Causes
- The machine was powered down during the backup. Upon shutdown, the active snapshot taken at the start of the backup is lost.
Troubleshooting Steps
- No user intervention is typically required. When the computer is powered back on, a new snapshot will be taken at the next scheduled backup time, and a new backup job will begin. (Note: If the machine is put to Sleep or Standby during a backup, it should resume when it wakes up. It is only when the machine is completely powered down that this error happens).
Error: Task failed unexpectedly
What This Means
- The job was terminated suddenly, resulting in an incomplete backup and restore point.
Possible Causes
- Host rebooted during the backup, resulting in the loss of the active snapshot.
Troubleshooting Steps
- Check host’s Event Viewer Windows System logs to see if there was a reboot.
- Rerun the backup job.
Error: Root element missing
What This Means
- The VBM file associated with the backup job has become corrupted.
Possible Causes
- This may be caused by a connection issue during the backup job or the Veeam repository had an error.
Troubleshooting Steps
- Locate the VBM file associated with the backup job and rename the file, such as by adding “.old” to end of the file name.
- Start a new backup job to generate a new VBM file.
- After the new VBM file gets created, the old file can be safely deleted without waiting for the running job to complete.
Unable to allocate processing resources. Error: Job session with id [STRING] does not exist
What This Means
- Host requested but was not assigned processing resources by eSilo cloud connect. This happens because the maximum number of concurrent backup jobs was already reached.
Possible Causes
- eSilo limits the number of concurrent backup jobs from a single Company when their bandwidth is lower than recommended thresholds. This max limit ensures hosts queue their backup jobs sequentially (vs. all machines at once) and avoids network slowdowns for the customer.
- When the first few machines’ backup jobs run long, they can cause subsequent hosts’ jobs to time out while waiting for their turn to backup.
Troubleshooting Steps
- Hosts should automatically retry backups at their next scheduled interval. No user intervention is typically required.
- If this is a persistent issue, or if your hosts are connecting from multiple locations (and thus there is little concern that multiple backups may saturate a site’s connection), contact eSilo Support to request the concurrent task limit be increased for your Company.
Failed to start a backup job. Failed to perform the operation. Invalid job configuration: Connection over network is blocked by network throttling rules
What This Means
- Backup job was unable to complete due to network restrictions.
Possible Causes
- The host is on a metered connection (ex: hot spot), or on a WiFi connection that has “Set as a metered connection” toggled on in the properties for the currently active WiFi connection. By default, eSilo Backup Jobs are set to “Disable backups over a metered connection”.
- Temporary network congestion may also cause this error.
- Firewall rules that limit or severely restrict certain types of traffic.
Troubleshooting Steps
- To check if the current WiFi connection is flagged as “metered” by Windows, the user can navigate to the Properties of their WiFi Network, and scroll to “Metered Connection” to verify if this is toggled ON. The preferred setting is to turn this OFF. Alternatively, if you don’t have remote access to the machine, uncheck the “Disable backups over metered connection” setting in the backup job and rerun it.

- Wait until the next scheduled backup run to see if the issue persists or was temporary.
- Contact the network or IT administrator for the site to investigate if there were recent firewall rule changes or upgrades that may have introduced new blocking or throttling settings.
Unable to allocate processing resources. Error: Authentication failed because the remote party has closed the transport stream.
What This Means
- The backup job failed due to an authentication error between the client machine backing up and the eSilo infrastructure.
Possible Causes
- Client machine is behind on Windows Updates which include authentication and security enhancements, or they have not checked the box in Windows Update Settings to include updates for other Microsoft Products, such as .NET Framework.
Troubleshooting Steps
- Apply latest Windows Security updates and .NET Framework updates
- Check if at the time of the above error on the tenant side, the eSilo Svc.VeeamCloudConnect.log log file displays the following error: “A call to SSPI failed, see inner exception“. If so, the issue may be related to a Windows Update enforcing a new .Net Framework security check. This check does not allow the client to establish a secure connection between their Veeam backup servers or agents and the eSilo Cloud Connect service, if there is a weak Diffie-Hellman Ephemeral (DHE) key. See this help article from Veeam on the steps needed to confirm and resolve. https://www.veeam.com/kb3208
- Subsequent job reattempts may complete successfully without user intervention, although this error may still sporadically cause jobs to fail.
Error: Failed to connect to the port [DNS_Name:Port].
What This Means
- Host unable to connect to eSilo cloud connect at the specified gateway and port address.
Possible Causes
- If this issue is occurring for only one or two machines (most common), and not all machines connecting to the eSilo cloud connect infrastructure, it may be indicative of a network issue on the client side.
Troubleshooting Steps
- The host should reattempt the job at the next scheduled interval. You can also manually start a backup to reattempt the job. No other user intervention is typically required.
Error: Insufficient quota to complete the requested service. Asynchronous read operation failed Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}. Exception from server: Insufficient quota to complete the requested service. Asynchronous read operation failed Unable to retrieve next block transmission command. Number of already processed blocks: [#]. Failed to download disk ‘[LONG_ID]’.
What This Means
- The error description may be misleading. We’ve observed this error previously, and it was unrelated to the Tenant’s Quota, which was well within limits.
Possible Causes
- When this was observed on an internal testing VM, the cause was that the source VM in the backup job was very low on memory (RAM) resources and was unresponsive. Restarting the VM brought it back online, and the next automatic job try was successful.
Troubleshooting Steps
- Verify the source machine is online and responsive. Ensure resource levels look good.
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: Invalid backup cache synchronization state.
What This Means
- Host is currently saving backups to Local Backup Cache. An attempt to sync cached backups to the eSilo cloud repository failed, due to a mismatch between what the Veeam Agent for Windows had in its local database for expected restore points and what was actually found in the repository and/or local backup cache.
Possible Causes
- If an in-progress backup is abruptly stopped, for example due to power failure, Veeam will discard any partially written restore points. However, if all references to those now discarded restore points are not cleared from the database (which should happen automatically), this can cause a job error on the next run, which highlights a mismatch between restore points expected on disk and what was found.
Troubleshooting Steps
- In most cases where this has been observed, the job will complete successfully the next time it is run, without any user intervention.
- If this error persists more than once, contact eSilo Support for assistance troubleshooting Backup Cache issues.
Job session for “[JOB_NAME]” finished with error. Job [JOB_NAME] cannot be started. SessionId: [ID], Timeout: [XX sec]
What This Means
- The Veeam job could not start due to too many active sessions or jobs running on the host consuming all available memory.
Possible Causes
- Too many running sessions causes Veeam services to be impacted by the host’s Desktop Heap limitation. This is because the Desktop Heap size for services is much smaller than that for applications.
Troubleshooting Steps
- To resolve this issue the Desktop Heap size must be increased via a registry modification.
- See this Veeam Knowledge Base article for detailed resolution steps: KB1909
Error: The system cannot find the file specified. Failed to open I/O device Failed to open emulated disk. Failed to open disk for read. Failed to upload disk. Agent failed to process method {DataTransfer.SyncDisk}
What This Means
- An expected disk on the client machine (machine to backup) was unable to be opened and read during the backup job.
Possible Causes
- Not known at this time.
Troubleshooting Steps
- The host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: Oib is complete and cannot be continued
What This Means
- The “oib” stands for “objects in backup” and is a unique identifier used by Veeam.
- The error indicates there is a discrepancy; a job is attempting to write to an oib that is already complete or finalized.
Possible Causes
- This may occur on a backup cache sync job that was interrupted right at very end, during the finalization stage. The error indicates that the oib was finalized by the previous job (“oib is complete”), however the current job is trying to modify or append to it, which is not allowed.
Troubleshooting Steps
- This error should resolve itself on next job run. If not, contact eSilo support.
Job session for “[JOB_NAME]” finished with error. Backup cache size has been exceeded
What This Means
- The size of the local backup cache has exceeded the maximum allowed size as configured in the backup job, preventing new restore points from being saved to the cache.
Possible Causes
- Persistent network disruptions may be preventing cached restore points from syncing, or uploading, to the eSilo Backup Cloud and thus they are not rotated out of the local backup cache. Restore points accumulate until the backup cache location is full.
- Service provider resources are busy or unable to be allocated to this host, preventing the syncing of cached restore points.
Troubleshooting Steps
- The Backup Cache Sync should resume in time, once the originating network or resource issues are resolved.
- The maximum Backup Cache size can be increased in the job settings, so long as there is sufficient local space.
- For more detail on advanced resolution steps, see this eSilo KB article: How to Resolve Backup Cache Size Exceeded Error
Error: Failed to create snapshot: Backup job failed. Cannot create a shadow copy of the volumes containing writer’s data. A VSS critical writer has failed. Writer name: [NAME]. Class ID: [ID]. Instance ID: [ID]. Writer’s state: [VSS_WS_FAILED_AT_PREPARE_SNAPSHOT]. Error code: [0x800423f0].
What This Means
- There is an issue with the built-in Windows VSS (Volume Shadow Copy service) on the host machine. Specifically, the VSS writer mentioned was not available at the time of the backup.
- eSilo Backups powered by Veeam use VSS writers to backup files that may be in-use, open or locked at the time of backup. This is particularly useful for databases, allowing backups to complete without downtime. If a writer is not in the proper state and functioning as expected, the backup snapshot will fail. VSS writer issues must be resolved on the host, and can usually be corrected by restarting the associated service.
Possible Causes
- The VSS service and/or the VSS Providers service is disabled
- The VSS writer is not in the Stable state, indicating it is ready and waiting to perform a backup. Below are alternative states:
- Failed or Unstable – the Writer encountered a problem, and must be reset .
- In-Progress or Waiting for Completion – the Writer is currently in use by a backup process. When the backup is finished, the Writer will revert to back to Stable state. However, if you see this state when no backups are running, the Writer needs to be reset.
Troubleshooting Options
- Verify the Volume Shadow Copy and Microsoft Software Shadow Copy Provider services are not disabled in services.msc.
- Check the state of VSS Writers using the following syntax in an admin command prompt. Also check the Windows Event Viewer for additional error information.
vssadmin list writers
-
- For the specified Writer in the error message, verify it is in a Stable state. If not, restart the respective Service related to that writer as mentioned in the table here. Then run the above command a second time to ensure the writer has returned to a stable state.
- Note that Services often have dependencies on one another. When one service is reset it may require others to be reset as well. Restarting a service will momentarily disrupt any application services that rely on it. For example, while resetting the MEIS service (Microsoft Exchange Information Store), MS Exchange will be unable to send and receive emails.
- A system reboot can also resolve most VSS writer problems, although it requires downtime.
- This Veeam KB article can also be useful in troubleshooting VSS issues for servers.
Job Session for [JOB_NAME] finished with error. Job [JOB_NAME] cannot be started. SessionID: [ID], Timeout: [VALUE]
What This Means:
- The job could not start, due to timeout waiting for required Veeam resources
Possible Causes:
- The Concurrent Task limit set at the Company level is too low for the number of hosts and disks schedule to be backup within a defined backup window.
Troubleshooting Options:
- Increase the number of concurrent tasks (e.g. disks that can be processed at once). This setting can be found in the eSilo Backup Portal under Companies >> Edit >> Bandwidth >> Max Concurrent Tasks. The minimum value should be 2, but greater numbers may be needed based on the timing and staggering of host backups.
Job session for “[JOB_NAME]” finished with error.
Error: Service provider side storage commander failed to perform an operation: CreateStorage
What this Means:
- eSilo was not able to allocate repository storage for the backup job.
Possible Causes:
- The assigned repository quota for this Tenant has been exceeded, thus preventing new backups from initiating.
Troubleshooting Options:
- Increase the Company’s repository quota.
- Remove existing backup chains or reduce the retention period to free space.
Job Status Warning: Unable to truncate SQL server transaction logs. Details: Failed to truncate SQL server transaction logs for instances: [MSSQLSERVER].
What this Means:
- Veeam was unable to truncate SQL server logs as specified in the job settings.
Possible Causes:
- This most commonly due to a permissions issue.
Troubleshooting Options:
- This Veeam Helpcenter article discusses the Log Truncation settings.
- You can confirm if this is a permissions issue by reviewing the Backup Job log for Warning items. Ex: Description = The server principal “[HOST][ACCOUNT]” is not able to access the database “[HOSTNAME]” under the current security context.
- Grant necessary permissions and rerun the job.
- Alternatively, you can modify the Backup Job settings to not truncate SQL Logs.
- Edit the Backup Job
- Under Guest Processing, click to “Customize application handling options for individual applications…”
- On the SQL tab, select the option for “Do not truncate logs”
2. Job Session State Errors (for VMs)
Host [LOCAL_IP] is not available. Error: Cannot complete login due to an incorrect user name or password. Virtual Machine [NAME] is unavailable and will be skipped from processing. Nothing to process. [#] machines were excluded from task list.
What This Means
- Veeam Backup and Replication was unable to access the Virtual Machine (VM) to perform the backup.
Possible Causes
- Incorrect user name or password specified to access the source VM. The password may have expired or the account credentials or permissions may have been changed.
Troubleshooting Steps
- Contact the IT Administrator for the VM to troubleshoot the credentials saved in the Backup Job.
3. Job Status Errors
SQL VSS Writer is missing: databases will be backed up in crash-consistent state and transaction log processing will be skipped
What This Means
- The SQL Writer for the Windows Volume Shadow Copy Service (VSS) is not available on the host machine, or is not configured with adequate permissions. This issue is related to the setup of the SQL database, and not specific to eSilo provided software or the backup itself.
Steps to Confirm the Issue
- Running ‘vssadmin list writers’ in an Administrator Command Prompt shows that SqlServerWriter is not in the list, or is in a State other than ‘Stable’.
Possible Causes
- The SQL instance has at least one database with name starting or ending in a space character
- The account under which SQL VSS Writer service is running doesn’t have sysadmin role on a SQL server – most frequently encountered
- SQL VSS Writer service is stuck in an invalid state, e.g. other than ‘Stable’
Troubleshooting Steps
- Depending on a particular cause:
- Rename the database to a new name (without a space in it). To check if your database has space in the name you can run the following query:
select name from sys.databases where name like '% '
If you notice any spaces in the database names, then you will need to remove the spaces from the database names.
- Grant the SQL VSS Writer service user a sysadmin role (Instructions in KB here: https://www.veeam.com/kb1978)
- Restart SQL VSS Writer service (Instructions in KB here: https://www.veeam.com/kb2041)
- In the case of SBS machines that are also Domain Controllers, ensure that the SQL Writer is running as a domain administrator and not local system.
- Allow the SQL Writer service account access to the Volume Shadow Copy service via the registry:
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServicesVSSVssAccessControl- If the DWORD value “NT SERVICESQLWriter” is present in this key, it must be set to 1.
- If the Volume Shadow Copy service is running, stop it after changing this registry value. Do not disable it.
For More Information
See this Veeam Knowledgebase article: https://www.veeam.com/kb2095
Microsoft documentation states that the SQL Writer service must run as Local System.
- In SQL Server 2008R2 and earlier, this means that the writer service account appears to SQL Server as “NT AUTHORITYSystem”.
- In SQL Server 2012 and later, the writer service account appears to SQL Server as “NT ServiceSQLWriter”.
4. Computer/VM Not Backed Up Errors
Backup Agent ‘[HOSTNAME]’ has fallen out of the configured RPO interval ([#]days). Last backup: [#] days, [#] hours ago.
What This Means
- The host’s most recent eSilo cloud backup is greater than the specified RPO (Recovery Point Objective) interval.
Possible Causes
- Host has been powered off or offline.
- Backups are being saved to the host’s Local Backup Cache and all restore points in the cache have not yet synced to the eSilo Cloud Repository (e.g. eSilo has not yet received the backups).
- Veeam Backup Agent Service or Veeam Management Agent Service is not running on host.
- The backups and/or backup schedule have been manually disabled (uncommon).
Troubleshooting Steps
- Verify host is online and connected to network.
- Check Backup Job to determine if Backup Cache is enabled. View cache folder on host to see if populated with recent restore points (default location: C:VeeamCache).
- Verify ‘VeeamManagementAgentSvc’ service is running on host. Status should be ‘Running’ and Startup Type should be ‘Automatic (Delayed Start)’. If the service is ‘Stopped’, check the Event Viewer for possible error details. See this article for more troubleshooting steps.
- Verify ‘VeeamEndpointBackupSvc’ service is running on host. Status should be ‘Running’ and Startup Type should be ‘Automatic’. Restart or reinstall if necessary.
- Check Backup Job to verify schedule and ensure not ‘Disabled’
Other Errors – Full Details Coming Soon
Error: Reconnectable protocol device was closed. Agent failed to process method {FileBackup.SyncDirs}. Exception from server: Reconnectable protocol device was closed.
Troubleshooting Steps
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
Error: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond.
Troubleshooting Steps
- Host will reattempt job at the next scheduled interval. No user intervention is typically required.
[In Backup Job Log] Error: [CStorageLinksHelper] Link Id=[LONG_ID] doesn’t exist for storage [JOBNAME_SUBTENANTNAME]yyy-mm-ddTxxxxxx.vib
What This Means
- While the restore point exists on the repository, the Link ID to that restore point in the metadata (.vbm) file is missing.
- Note: If the Backup Job is configured to use Backup Cache, this error does not by itself trigger a Backup Job Failure, since the restore points are successfully written to local cache. You will notice it however, because the eSilo Backup Portal will warn that a new restore point has not been uploaded in X days (according to the RPO alarm thresholds set for this tenant).
Possible Causes
- This can be a symptom of a network drop, where a handshake was missed in the final stages of job completion for the last restore point uploaded to eSilo. The local Veeam Agent database (on the subtenant’s machine) saw the restore point created, but the finalization step didn’t update the metadata file on the repository side with eSilo.
Troubleshooting Steps
- In the repository, we will force the job to recreate the metadata file by editing the existing metadata file to append “.old” at the end. At the next job run, this will force a recheck of all restore points in the backup chain and recreate the metadata file from that chain.
[In Svc.VeeamEndpointBackup.log] Error: Warning [CertificateError] Validation complete with warnings, AND/OR Warning Remote certificate chain errors, AND/OR Warning WarningRevocationStatusUnknown (The revocation function was unable to check revocation for the certificate.
What This Means
- The subtenant was unable to validate the eSilo Cloud Connect server’s certificate.
Possible Causes
- If this is happening for only one tenant, as opposed to all tenants, it suggests an issue with how this specific subtenant is connecting to eSilo.
- If no firewall or other changes have been made recently, you can recheck the credentials used by the subtenant in the backup job.
- This Veeam KB article is also helpful for investigating common causes of certificate errors: https://www.veeam.com/kb2323
Troubleshooting Steps
- Verify the Management Agent status shows as Connected. You can force a reconnect by changing a property in the dialog box, then changing it back and clicking “Apply“.
- Pause and unpause sync of Backup Cache files by right-clicking on the Veeam Backup Agent icon in the taskbar.
- Edit the Backup Job to specify the correct sub-tenant login credentials. Save and rerun the job. Upon the next job run, you should see “Uploading cached restore points” when you hover over the Veeam Backup Agent icon in the taskbar.
Was this article helpful?
Related Articles
Page load link
Go to Top