Рассмотрим,
чем определяется способность блочного
кода обнаруживать и исправлять ошибки,
возникшие при передаче.
Пусть
U
= (U0,
U1,
U2,
…Un-1)
— двоичная последовательность длиной
n.
Число
единиц
(ненулевых компонент) в этой
последовательности называется
весом
Хемминга
вектора U
и обозначается w(U).
Например,
вес Хемминга вектора U
=
( 1001011
) равен четырем, для вектора U
=
( 1111111
)
величина w(U)
составит 7 и т.д.
Таким
образом, чем больше единиц в двоичной
последовательности, тем больше ее вес
Хемминга.
Далее, пусть U и V будут
двоичными последовательностями длиной
n.
Число разрядов, в которых эти
последовательности различаются,
называется расстоянием Хемминга между
U и V и обозначается
d( U, V).
Например,
если U
=
( 1001011
), а V
= ( 0100011
), то d(
U, V) = 3.
Задав
линейный код, то есть определив все 2k
его кодовых слов, можно вычислить
расстояние между всеми возможными
парами кодовых слов. Минимальное из них
называется минимальным
кодовым расстоянием кода
и обозначается dmin.
Можно
проверить и убедиться, что минимальное
кодовое расстояние для рассматриваемого
нами в примерах (7,4)-кода
равно трем: dmin(7,4)
=
3.
Для этого нужно записать все кодовые
слова (7,4)-кода
Хемминга (всего 16 слов), вычислить
расстояния между их всеми парами и взять
наименьшее значение. Однако можно
определить dmin
блочного кода и более простым способом.
Доказано,
что расстояние между нулевым кодовым
словом и одним из кодовых слов, входящих
в порождающую матрицу (строки порождающей
матрицы линейного блочного кода сами
являются кодовыми словами, по определению),
равно dmin.
Но расстояние от любого кодового слова
до нулевого равно весу Хемминга этого
слова. Тогда dmin
равно минимальному
весу Хемминга
для
всех строк порождающей матрицы кода .
Если
при передаче кодового слова по каналу
связи в нем произошла одиночная
ошибка,
то расстояние Хемминга между переданным
словом U
и принятым вектором r
будет равно единице. Если при этом одно
кодовое слово не перешло в другое (а при
dmin
>
1 и при одиночной ошибке это невозможно),
то ошибка будет
обнаружена
при декодировании.
В
общем случае если блочный код имеет
минимальное расстояние dmin,
то он
может обнаруживать любые сочетания
ошибок при их числе, меньшем или равном
dmin
—
1,
поскольку никакое сочетание ошибок при
их числе, меньшем, чем dmin
—
1,
не может перевести одно кодовое слово
в другое.
Но
ошибки могут иметь кратность и большую,
чем dmin—
1,
и тогда они останутся
необнаруженными.
При
этом среднюю вероятность необнаруживаемой
ошибки можно определить следующим
образом.
Пусть
вероятность ошибки в канале связи равна
Pош.
Тогда вероятность того, что при передаче
последовательности длины n
в ней произойдет одна ошибка, равна
Р1
= n
Pош
( 1- Рош)n-1,
(1.36)
соответственно,
вероятность l-кратной
ошибки —
Pl
=Cnl
Pошl
( 1- Pош)n-l,
(1.37)
где
Cnl
— число возможных комбинаций из
n
символов кодовой последо-вательности
по l
ошибок.
По
каналу связи передаются кодовые слова
с различными весами Хемминга. Положим,
что ai
— число слов с весом i
в данном коде (всего слов в коде длиной
n
—
![]()
).
А
теперь определим, что такое необнаруживаемая
ошибка.
Обнаружение ошибки производится путем
вычисления синдрома принятой
последовательности. Если принятая
последовательность не является кодовым
словом ( тогда синдром не равен нулю),
то считается, что ошибка есть. Если же
синдром равен нулю, то полагаем, что
ошибки нет (принятая последовательность
является кодовым словом). Но
тем ли, которое передавалось? Или же в
результате действия ошибок переданное
кодовое слово перешло в другое кодовое
слово данного кода:
r
= U
+ е = V,
(1.38)
то
есть сумма переданного кодового слова
U
и вектора ошибки е
даст новое
кодовое слово V
? В этом случае, естественно, ошибка
обнаружена быть не может.
Но
из определения двоичного линейного
кода следует, что если
сумма кодового слова и некоторого
вектора е
есть кодовое слово, то вектор е
также представляет собой кодовое слово.
Следовательно,
необнаруживаемые ошибки будут возникать
тогда, когда сочетания ошибок будут
образовывать кодовые слова.
Вероятность
того, что вектор е
совпадает с кодовым словом, имеющим вес
i
,
равна
Pi
=
Pошi
(1- Рош)n-i
. (1.39)
Тогда полная
вероятность возникновения необнаруживаемой
ошибки
![]()
.
(1.40)
Пример:
рассматриваемый нами (7,4)-код
содержит по семь кодовых слов с весами
w
= 3 и w
= 4 и одно
кодовое слово с весом w
= 7, тогда
![]()
(1.41)
или,
при Рош
= 10
-3,
Р(Е)
7
10
-9.
Другими
словами, если по каналу передается
информация
со скоростью V
=
1кбит/с и в канале в среднем каждую
секунду
будет происходить искажение одного
символа, то в среднем семь принятых слов
на 109
переданных будут проходить через декодер
без обнаружения ошибки (одна необнаруживаемая
ошибка за 270 часов).
Таким
образом, использование даже такого
простого кода позволяет на несколько
порядков снизить вероятность
необнаруживаемых ошибок.
Теперь
предположим, что линейный блочный код
используется для исправления ошибок.
Чем определяются его возможности по
исправлению?
Рассмотрим
пример, приведенный на рис. 1.9. Пусть U
и V
представляют
пару кодовых слов кода с
кодовым расстоянием d
,
равным минимальному — d
min
для
данного
кода.

Рис.
1.9
Предположим,
передано кодовое слово U,
в
канале произошла одиночная
ошибка
и принят вектор а
(не
принадлежащий коду).
Если
декодирование производится оптимальным
способом, то есть по
методу максимального правдоподобия,
то в
качестве оценки U*
нужно
выбрать ближайшее к а
кодовое
слово.
Таковым
в данном случае будет U,
следовательно, ошибка будет устранена.
Представим
теперь, что произошло две ошибки и принят
вектор b.
Тогда
при декодировании по максимуму
правдоподобия в
качестве оценки будет выбрано ближайшее
к b
кодовое слово, и им будет
V.
Произойдет ошибка декодирования.
Продолжив
рассуждения для dmin
=
4, dmin
=
5
и т.д., нетрудно сделать вывод, что ошибки
будут устранены, если их кратность l
не превышает величины
l<
INT (( dmin – 1 )/2) ,
(1.41)
где
INT (X)
— целая часть Х.
Так,
используемый нами в качестве примера
(7,4)-код
имеет dmin
= 3 и,
следовательно, позволяет
исправлять лишь одиночные ошибки:
l
= INT
(( dmin
– 1
)/2)=INT((3-1)/2)=1
.
(1.42)
Таким
образом, возможности
линейных блочных кодов по обнаружению
и исправлению ошибок определяются их
минимальным кодовым расстоянием.
Чем
больше dmin,
тем большее число ошибок в принятой
последовательности можно исправить.
А
теперь определим вероятность того, что
возникшая в процессе передачи ошибка
не будет все же исправлена при
декодировании.
Пусть,
как и ранее, вероятность ошибки в канале
будет равна Рош.
Ошибки, возникающие в различных позициях
кода, считаем независимыми.
Вероятность
того, что принятый вектор r
будет иметь какие-нибудь (одиночные,
двукратные, трехкратные и т.д.) ошибки,
можно определить как
Рош
= P1
+ P2
+ P3
+… + Pn
,
(1.43)
где
Р1
— вероятность того, что в r
присутствует
одиночная ошибка;
Р2
—
вероятность того, что ошибка двойная и
т.д.;
Рn
— вероятность того, что все n
символов
искажены.
Определим вероятность ошибок заданной
кратности:
Р1
=
Вер{ошибка
в 1-й позиции ИЛИ ошибка во 2-й позиции
..ИЛИ в n-й позиции}
= = Рош(1-
Рош)n-1
+ Рош(1-
Рош)n-1
+…Рош(1-
Рош)n-1
= п
Рош(1-
Рош)n-;
(1.44)
Р2
=
Вер{ошибка
в 1-й И во 2-й позиции ИЛИ ошибка во 2-й И
в 3-й позиции…}
=
=
P2ош(1-Рош)n-2
+…Р2ош(1-
Рош)
n-2 =
![]()
Р2ош(1-
Рош)
n-2.
(1.45)
Аналогичным
образом
Р3
=
![]()
Р3ош(1-
Рош)n-3
и т.д.
(1.46)
Декодер,
как мы показали, исправляет все ошибки,
кратность которых не превышает
![]()
,
(1.47)
то
есть все ошибки кратности J
l будут
исправлены.
Тогда
ошибки декодирования — это ошибки с
кратностью, большей кратности исправляемых
ошибок l,
и их вероятность
![]()
![]()
.
(1.48)
Для
(7,4)-кода
Хемминга минимальное расстояние dmin
=
3,
т.е. l
=
1.
Следовательно, ошибки кратности 2 и
более исправлены не будут и
![]()
.
(1.49)
Если
Рош<<
1,
можно считать (1-
Рош)
1
и, кроме того, Р3ош<<
Р2ош.
Тогда
![]()
.
(1.50)
Так, например,
при вероятности ошибки в канале Рош
= 10 -3 вероятность
неисправления ошибки Р(N)
2 10
-5, то есть при такой
вероятности ошибок в канале кодирование
(7.4)-кодом позволяет снизить
вероятность оставшихся неисправленными
ошибок примерно в пятьдесят раз.
Если
же вероятность ошибки в канале будет
в сто раз меньше Рош
= 10 -5, то вероятность
ее неисправления составит уже Р(N)
210
-9, или в 5000 раз
меньше!
Таким
образом, выигрыш от помехоустойчивого
кодирования (который можно определить
как отношение числа ошибок в канале к
числу оставшихся неисправленными
ошибок) существенно зависит от свойств
канала связи.
Если
вероятность ошибок в канале велика, то
есть канал не очень хороший, ожидать
большого эффекта от кодирования не
приходится, если же вероятность ошибок
в канале мала, то корректирующее
кодирование уменьшает ее в значительно
большей степени.
Другими
словами, помехоустойчивое кодирование
существенно улучшает свойства хороших
каналов, в плохих же каналах оно большого
эффекта не дает.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
10.06.2015684.82 Кб13P4.pdf
- #
- #
- #
- #
При проектировании системы связи с применением
корректирующего кода возникает вопрос о выборе кода. Решая этот вопрос,
необходимо, конечно, учитывать много различных факторов, в частности сложность
кодирования и декодирования, влияющую как на стоимость аппаратуры, так и на ее
надежность. Но если даже отвлечься от чисто технических и экономических
факторов и учитывать только верность и количество передаваемой информации,
задача выбора кода остается не легкой.
Рассмотрим, как можно сравнивать между собой различные коды.
Прежде всего заметим, что, как ясно из результатов предыдущих параграфов,
нельзя сравнивать коды безотносительно к характеристикам канала, для которого
они предназначены. Итак, будем предполагать характеристики канала заданными. В
этом случае выбор кода определяет, с одной стороны, насколько хорошо
используется пропускная способность канала и, с другой стороны, какова верность
принятого декодированного сообщения.
Представляется очень заманчивым определить один параметр,
отражающий обе эти стороны корректирующего кода. На первый взгляд таким
параметром могла бы служить скорость передачи информации, поскольку она связана
как с технической скоростью, так и с вероятностями правильного и ошибочного
приемов. Однако поиски в этом направлении не приводят к цели. Это объясняется
тем, что применение корректирующего кода не может повысить скорость
передачи информации по каналу, а наоборот, как правило, понижает ее.
Для того чтобы пояснить эту
мысль, предположим, что в канале с шумами используется примитивный код. Максимальная
скорость передачи информации будет иметь место при каком-то определенном
распределении вероятностей сообщений источника (например, для постоянного
симметричного канала — при равновероятном распределении, для двоичного
несимметричного канала—при распределении (2.56) и т. п.). Эта максимальная
скорость по определению является пропускной способностью канала.
Согласно обратной теореме
Шеннона передача со сколь угодно высокой верностью возможна лишь со скоростью,
не превышающей пропускной способности. Если бы можно было применить идеальный
код, обеспечивающий заданную высокую верность при скорости передачи, равной
пропускной способности канала, то никакого выигрыша по скорости передачи по
сравнению с примитивным кодированием мы бы не получили. Но даже отсутствие
проигрыша в скорости возможно только в асимптотическом смысле,
когда длина кодируемого блока стремится к бесконечности, как видно, например,
для случайного кодирования из (2.47). Что же касается реально применимых
кодов, то для них всегда ![]() т.е скорость передачи меньше пропускной
т.е скорость передачи меньше пропускной
способности и, следовательно, меньше скорости, достижимой при
примитивном кодировании, без исправления или обнаружения ошибок. Таким образом,
повышение верности связано с некоторой потерей скорости передачи информации не только по
сравнению с технической скоростью, но и по сравнению с информационной скоростью
при примитивном кодировании. Как правило, эта потеря тем больше, чем выше
требования к верности.
Здесь можно провести несколько
вольную, но поучительную аналогию с добычей ценного металла из руды. Никакой
технологический процесс не позволит получить больше металла, чем его
первоначальное содержание в руде — любой реальный процесс
приводит к некоторым потерям, которые обычно тем значительнее, чем выше
требования к чистоте металла. Точно так же корректирующий код не увеличивает количества
информации, содержащегося в принятом сигнале, а только позволяет
«очистить ее от «примесей» ценой некоторых потерь.
Для того чтобы оценить качество кола с точки зрения
скорости передачи информации, можно воспользоваться его избыточностью.
Действительно, скорость передачи можно определить (пренебрегая неисправленными
при декодировании ошибками) как
![]() ,
,
или согласно (2.23)
![]()
Таким образом, при заданном дискретном канале (т. е. при
заданном ![]() ) преимущество в скорости передачи информации имеют коды с
) преимущество в скорости передачи информации имеют коды с
меньшей избыточностью. Поэтому выбор корректирующего кода целесообразно производить
следующим образом. Прежде всего отбираются коды, позволяющие в заданном канале
обеспечить требуемую верность передачи, а также удовлетворяющие другим
технико-экономическим требованиям, в частности коды с допустимой сложностью
кодирования и декодирования. Затем из них отбирается код с наименьшей
избыточностью.
При таком подходе необходимо уметь оценивать верность
передачи информации и формулировать требования к ней. К сожалению, в этом
вопросе нет установившейся точки зрения и различные авторы пользуются разными
параметрами для оценки верности.
Довольно часто, особенно в теоретических работах, при
рассмотрении блочных кодов мерой верности считают вероятность правильного
декодирования блока (кодовой комбинации). Мы также пользовались этой мерой в §
2.5 при отыскании асимптотических значений при увеличении длины блока. Однако
для сравнения различных кодов с различной длиной кодовой комбинации и
различной избыточностью такая мера не адекватна, не говоря уж о том, что она не
применима для непрерывных кодов. Так, например, если в одном коде блок содержит
5 информационных символов и правильно декодируется с вероятностью 0,999, а в
другом коде блок содержит 200 информационных символов и правильно декодируется
(в том же канале) с вероятностью 0,99, то было бы опрометчиво считать, что
первый код обеспечивает более высокую верность, нежели второй. Действительно,
если нужно передать сообщение, состоящее, скажем, из 400 информационных
символов, то при использовании первого кода это сообщение займет 80 кодовых
комбинаций и вероятность того, что сообщение будет принято правильно равна![]() . Если же применить
. Если же применить
второй код, то все сообщение уложится в 2
кодовые
комбинации и будет принято верно с вероятностью ![]() . Таким образом, вероятность правильно
. Таким образом, вероятность правильно
принять сообщение при втором коде больше, чем при первом, хотя вероятность
правильного декодирования кодовой комбинации для первого кода выше, чем для
второго.
Более разумной мерой верности, с которой часто приходится
встречаться (например, [24]), является вероятность правильного приема символа
после исправления ошибок (или после представления декодированного сообщения
примитивным кодом). Обычно удобнее пользоваться не вероятностью правильного
приема после исправления, а её дополнением до единицы — вероятностью
неисправленной ошибки. Такая мера позволяет сравнивать коды с различной длиной
кодовых комбинаций и даже непрерывные коды. Она достаточно объективна и вполне
пригодна для таких систем связи, в которых некоторое количество неисправленных
ошибок в принятом сообщении допустимо, по желательно, чтобы их было меньше.
Чаще всего это происходит, когда само сообщение имеет некоторую избыточность и
отдельные ошибки не искажают его смысла и могут быть исправлены получателем.
Примером служит телеграфная связь при передаче осмысленного текста.
Тем не менее вероятность неисправленной ошибки не является
пригодной мерой верности в тех случаях, когда ошибки в принятом сообщении
вовсе недопустимы, т. с. когда одна ошибка в такой же мере делает сообщение
непригодным, как и тысяча ошибок. Такое положение имеет место в некоторых
системах передачи данных для цифровых вычислительных машин.
Для иллюстрации сказанного вернемся к рассмотренному выше
примеру и вычислим вероятность неисправленной ошибки для двух конкурирующих
кодов. Предположим при этом, что по структуре кодов в случае ошибочного
декодирования кодовой комбинации в среднем половина информационных символов
оказывается искаженной. При первом коде в среднем на 1000 комбинаций (т. е. на
5 000 информационных символов) ошибочно декодируется одна комбинация. Это
значит, что в среднем на 5 000 информационных символов приходится 2,5
неисправленной ошибки, т. е. вероятность неисправленной ошибки равна ![]() . Для второго кода
. Для второго кода
ошибочно декодируется одна комбинация из ста, т. е. на 20000 информационных
символов приходится 100 неисправленных, или вероятность неисправленной ошибки
равна ![]() .
.
Таким образом, вероятность неисправленной ошибки для второго кода в 10 раз
больше, чем для первою, тогда как вероятность ошибочного приема сообщения из
400 информационных символов, как было показано выше, для первого кода почти
втрое больше, чем для второго.
Это
кажущееся противоречие объясняется тем, что при использовании второго кода
неисправленные ошибки группируются более тесно, чем для первого. Поэтому,
хотя во втором коде вероятность неисправленной ошибки больше, чем в первом, вес
же имеется больше шансов избежать образования пачки ошибок при передаче одного
сообщения. Заметим еще, если паше сообщение, содержащее 400 информационных
символов, декодировано неверно, то при использовании первого кода оно будет,
вероятнее всего, содержать 2—3 ошибочно принятых символа, тогда как при втором
коде количество ошибочно принятых символов будет близко к 100. Отсюда можно
заключить, что при телеграфной передаче осмысленного текста лучше применять
первый код, тогда как в тех системах связи, где любые ошибки одинаково
недопустимы, второй код имеет явное преимущество.
Заметим, что именно в тех системах, где любые ошибки
декодирования одинаково недопустимы, чаще всего используются корректирующие
коды. Поэтому именно для них важно иметь меру верности. Но ни вероятность
правильного декодирования кодовой комбинации, ни вероятность неисправленной
ошибки в информационных символах для таких систем, как мы видели, не могут
служить такой мерой.
В предыдущем примере была использована вероятность
правильного декодирования сообщения, содержащего 400 информационных символов.
Но цифра 400 была выбрана совершенно произвольно. Если передавать более
длинное сообщение, то вероятность принять его безошибочно, очевидно,
уменьшится. Легко понять, что при любом блочном коде в канале с шумами с
увеличением длины передаваемого сообщения вероятность его безошибочного
декодирования стремится к нулю. Так, если вероятность правильного декодирования
кодовой комбинации равна ![]() , а сообщение содержит
, а сообщение содержит ![]() кодовых
кодовых
комбинаций, то вероятность принять все сообщение без ошибок равна
![]() (2.62)
(2.62)
В этом
обозначении ![]() —
—
количество информации (в двоичных единицах), содержащееся в кодовой комбинации
(![]() ), а
), а ![]() — количество
— количество
информации в сообщении. Предполагается, что избыточность источника устранена
при кодировании.
Так как при любом конечном ![]()
![]() , то с увеличением
, то с увеличением ![]()
![]() стремится к нулю. Тем
стремится к нулю. Тем
не менее при любых конечных ![]() и
и ![]() существует положительная вероятность
существует положительная вероятность
безошибочного, приема сообщении. Применительно к любой системе связи можно
указать такие значения ![]() и
и ![]() , при которых систему
, при которых систему
можно считать практически безупречной. Так, например, если величина ![]() определяется
определяется
количеством информации, передаваемой в течение суток, а ![]() , то это значит, что в среднем
, то это значит, что в среднем
одни раз за 300 лет наступит такой день, когда сообщение вследствие действия
помех будет принято неправильно. Можно смело утверждать, что почти для любых применений
такая система связи, может считаться безупречной.
Заметим, что принципиальных препятствий для достижения
указанной верности (если пропускная способность канала достаточна) нет, а
технические трудности отнюдь не больше, чем трудность получения аппаратурной
надежности обеспечивающей время наработки на одни отказ порядка 300 лет.
Формула (2.62) справедлива и дли примитивного кодирования,
когда число символов ![]() в кодовой комбинации совпадает с числом
в кодовой комбинации совпадает с числом
информационных символов ![]() . Для двоичного постоянного
. Для двоичного постоянного
симметричного канала при примитивном кодировании ![]() и
и ![]() и, следовательно,
и, следовательно,
![]() (2.63)
(2.63)
С точки зрения верности декодирования длинного сообщения
две системы связи можно считать эквивалентными, если при достаточном больших ![]()
![]() , по крайней
, по крайней
мере в асимптотическом смысле, т.е.
![]() (2.64)
(2.64)
Здесь индексы 1 и 2 относятся к сравниваемым системам.
Отсюда вытекает возможность характеризовать любую систему связи с любым кодом с
помощью вероятности ошибки в эквивалентной ей двоичной системе связи с
примитивным кодом. Назовем эквивалентной вероятностью ошибки ![]() системы связи
системы связи
величину вероятности ошибки в постоянном симметричном двоичном канале, в
котором система с примитивным кодированием оказывается эквивалентной
рассматриваемой системе [31].
Эквивалентная вероятность ошибки является удобной мерой
для сравнения между собой не только различных кодов, применяемых в одном и том
же канале, но и для сравнения различных систем связи, в которых могут
использоваться различные каналы, различные коды модуляции и организации связи.
При любом фиксированном значении ![]() вероятность ошибочного приема
вероятность ошибочного приема
сигнала, содержащего ![]() двоичных единиц информации,
двоичных единиц информации,
является монотонной функцией эквивалентной вероятности ошибок.
Для системы с блочным кодом эквивалентную вероятность
ошибок легко вычислить, если известна вероятность ![]() правильного
правильного
декодирования кодовой комбинации, содержащей ![]() двоичных единиц информации. Из
двоичных единиц информации. Из
(2.62) и (2.63) следует
![]()
откуда
![]() (2.65)
(2.65)
где ![]() — вероятность ошибочного декодирования кодовой
— вероятность ошибочного декодирования кодовой
комбинации.
Величину ![]() называют эквивалентной вероятностью
называют эквивалентной вероятностью
правильного приема.
При ![]()
![]() (2.66)
(2.66)
Аналогичная величина, названная относительной вероятностью
ошибки декодирования, была введена также в работе В. И. Сифорова [32].
В случае непрерывных кодов, в которых нельзя подразделить
последовательность символов на отдельные комбинации (например, в случае цепного
кода), эквивалентную вероятность ошибок следует определить с помощью
предельного перехода
![]() (2.67)
(2.67)
где ![]() — вероятность ошибочного приема
— вероятность ошибочного приема
сообщения, содержащего ![]() двоичных единиц информации.
двоичных единиц информации.
Найдем эквивалентную вероятность ошибки для симметричного
постоянного канала при кодировании без избыточности кодом с основанием ![]() [33, 34].
[33, 34].
Если вероятность ошибочного приема символа в рассматриваемом канале равна ![]() , то
, то
вероятность безошибочного приема последовательности из ![]() символов равна
символов равна ![]() . Такая
. Такая
последовательность содержит ![]() двоичных единиц информации.
двоичных единиц информации.
Таким образом, эквивалентная вероятность правильного приема равна

(приближенное равенство справедливо при ![]() ), откуда
), откуда
![]() (2.68)
(2.68)
Отсюда следует, например, что канал с ![]() и
и ![]() эквивалентен по достоверности
эквивалентен по достоверности
двоичному каналу с вероятностью ошибок ![]() .
.
В качестве другого примера оценим эквивалентную вероятность
ошибки для описанного выше двоичного систематического кода (7,4). Кодовая
комбинация, содержащая ![]() символов и
символов и ![]() двоичных единицы информации,
двоичных единицы информации,
может быть правильно декодирована, если ошибочно принят не более чем один
символ из семи. Вероятность правильного декодирования равна
![]()
Здесь первый член представляет вероятность того, что все
символы приняты верно, а второй член — вероятность того, что искажен один
символ из семи. Эквивалентная вероятность правильного приема равна
![]()
При ![]() это выражение можно приближенно записать,
это выражение можно приближенно записать,
пренебрегая высокими степенями ![]() , так:
, так:
![]()
откуда эквивалентная вероятность ошибок равна
![]() (2.69)
(2.69)
Это выражение можно получить проще, если учесть, что при ![]() вероятность того,
вероятность того,
что в симметричном канале будут искажены три или более символов в комбинации,
значительно меньше вероятности ошибочного приема двух символов. Поэтому
вероятность ошибочного декодирования кодовой комбинации ![]() в коде (7, 4) в первом
в коде (7, 4) в первом
приближении равна вероятности ошибочного приема каких-либо двух символов из
семи:
![]()
откуда с учетом (2.66) непосредственно следует (2.69).
Вообще, если двоичный корректирующий код является
плотно упакованным, то рассуждая аналогичным образом, можно показать, что
при ![]()
![]() (2.70)
(2.70)
Для не двоичных кодов, исправляющих ошибки
кратности ![]() символов
символов
и не исправляющих ошибки большей кратности, при симметричном канале приближенная
зависимость (2.70) также справедлива. Следует только помнить, что под ![]() понимается
понимается
количество информации в кодовой комбинации, выраженное в двоичных единицах.
Выражение (2.68) является частным случаем (2.70) при ![]() , так как при любом
, так как при любом ![]()
![]()
Если примененный систематический код обеспечивает
возможность исправления ошибки кратности ![]() во всех случаях, а также в некоторых
во всех случаях, а также в некоторых
случаях ошибки более высокой кратности, то вероятность ошибочного декодирования
кодовой комбинации ![]() при
при
![]() приблизительно
приблизительно
равна вероятности того, что произойдет ошибочный прием ![]() символа в одном из неисправляемых
символа в одном из неисправляемых
сочетаний
![]()
где ![]() — число исправляемых сочетаний ошибок
— число исправляемых сочетаний ошибок
кратности ![]() ,
,
откуда
![]() (2.71)
(2.71)
Из полученных выражений видно, что
эффективность корректирующих кодов тем выше, чем меньше вероятность ошибки ![]() в стационарном
в стационарном
симметричном канале. Так, например, при ![]() эквивалентная вероятность ошибки для
эквивалентная вероятность ошибки для
кода (7,4) согласно (2.69) приблизительно равна 0,05, т. е. всего лишь в два
раза меньше, чем при примитивном кодировании, тогда как при ![]() эквивалентная вероятность
эквивалентная вероятность
ошибки оказывается порядка ![]() , т. е. в этом случае повышение верности
, т. е. в этом случае повышение верности
оказывается весьма существенным.
Подводя
итог, можно отметить, что для объективного сравнения кодов (или систем связи)
можно пользоваться либо вероятностью неисправленной ошибки, либо
эквивалентной вероятностью ошибки. Первая из этих мер пригодна для систем
связи, передающих сообщения, ценность которых не теряется при небольшом количестве
ошибок, а лишь монотонно уменьшается. Вторая мера удобна в тех случаях, когда
каждое законченное сообщение должно быть принято без ошибок, т. е. когда даже
одиночная ошибка полностью его обесценивает.
Полосовой фильтр приема ПФпр
выделяет полосу частот телеграфного канала, что позволяет избавиться от помех,
находящихся вне полосы пропускания ПФпр. Далее сигнал усиливается усилителем,
который компенсирует потерю энергии сигнала за счет затухания линии. Обычно
усилитель выполняет дополнительную функцию — функцию ограничения сигнала по
уровню, при этом удается обеспечить постоянство уровня сигнала на входе
демодулятора. Усиленный и ограниченный сигнал подается на фазовый демодулятор
ФД. Здесь осуществляется корреляционный (когерентный) прием, называемый иногда
приемом «методом сравнения полярностей». Опорное напряжение подается на ФД с
устройства выделения опорного напряжения УВОН. Сравнение полярностей
осуществляется в перекодирующем устройстве приема ПКУпр. Если полярности
(i-1)-го и i-го элементов совпадают, то на выходе ПКУпр в качестве i-го
элемента выделяется «1». Если полярности (i-1)-го и i-го элементов разные, то
на выходе ПКУпр выделяется «0».
Этот способ приема по
сравнению с другими приводит к уменьшению вероятности неправильного приема,
потому что ФД сравнивается по фазе зашумленный сигнал с «чистым» опорным
напряжением.
2. Оценка влияния помехоустойчивого кодирования на
вероятность
ошибочного приема символов сообщения и на
скорость передачи информации.
2.1
Расчет вероятности неправильного
приема символов и скорости передачи информации при отсутствии
помехоустойчивого кодирования.
Вначале рассчитаем
вероятность неправильного приема кодовой комбинации длиной nkk = 7
единичных элементов в предположении, что помехоустойчивое кодирование не
используется, т.е. кратность исправляемой ошибки tи = 0. Так как
символы текста передаются кодовыми комбинациями, то вероятность искажения хотя
бы одного единичного элемента кодовой комбинации будет определять вероятность
неправильного дешифрирования (приема) символа.
Для рассматриваемых условий
вероятность неправильного приема символов текста рассчитаем по формуле:
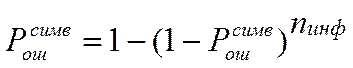 , [10]
, [10]
где n инф.
= nkk = 7
Величину 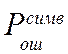 берем
берем
из пункта 1.2,
= 1- (1-0,242)7 = 0,856.
Рассчитаем скорость передачи
информации для рассматриваемого случая. Поскольку в каждой комбинации есть один
проверочный разряд проверки на четность, то скорость передачи будет равна
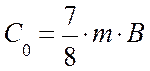 ,
,
[11]
где m — кратность
модуляции.
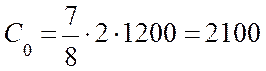 Бит/с.
Бит/с.
2.2
Расчет вероятности
неправильного приема символов и скорости передачи информации при использовании
помехоустойчивого кодирования.
В этом пункте определим, как будет изменяться
вероятность неправильного приема символов текста, если использовать
помехоустойчивые циклические коды, исправляющие одно, двух и трехкратные
ошибки. Определим, как будет изменяться при этом скорость передачи информации с
увеличением верности передачи символов за счет использования помехоустойчивых
кодов.
Выберем длину кодовой
комбинации nkk = 7.
Определим вероятность
появления на выходе декодера кодовых комбинаций с неисправленными ошибками,
которая будет равна сумме вероятностей ошибок с кратностью tош
> tи.
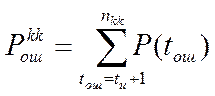
[12]
Рассчитаем вероятность
появления в кодовых комбинациях длиной ошибок с кратностью tош. Если вероятность ошибочного приема элемента кодовой
комбинации демодулятором
равна,то вероятность возникновения ошибки скратностью tош и определенной
конфигурации будет равна вероятности события, заключающемся в неправильном
приеме tош
элементов кодовой комбинации и правильном приеме остальных nkk — tош
элементов. Вероятность этого события равна 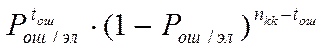 . Количество возможных конфигураций ошибок с
. Количество возможных конфигураций ошибок с
кратностью tош равно
числу сочетаний из nkk по tош
разрядов.
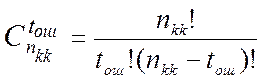 [13]
[13]
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание — внизу страницы.
Я хочу сравнить надежность различных RAID-систем с накопителями (URE/bit = 1e-14) или корпоративными (URE/bit = 1e-15). Формула для определения вероятности успеха восстановления (без учета механических проблем, которые я буду принимать во внимание позже) проста:
error_probability = 1 — (1-per_bit_error_rate)^ bit_read
Важно помнить, что это вероятность получить по крайней мере один URE, а не только один.
Предположим, мы хотим использовать 6 ТБ свободного места. Мы можем получить это с:
-
RAID1 с 1+1 дисками по 6 ТБ каждый. Во время восстановления мы читаем 1 диск по 6 ТБ, и риск составляет: 1-(1-1e-14) ^(6e12 *
 = 38% для потребителя или 4,7% для корпоративных накопителей.
= 38% для потребителя или 4,7% для корпоративных накопителей. -
RAID10 с 2+2 дисками по 3 ТБ каждый. Во время восстановления мы читаем только 1 диск объемом 3 ТБ (тот, который связан с неисправным!) и риск ниже: 1-(1-1e-14) ^(3e12 *
= 21% для потребителя или 2,4% для корпоративных накопителей. -
RAID5/RAID Z1 с 2+1 дисками по 3 ТБ каждый. Во время восстановления мы читаем 2 диска по 3 ТБ каждый, и риск составляет: 1-(1-1e-14) ^(2 * 3e12 *
= 38% для потребительских или 4,7% или корпоративных дисков. -
RAID5/RAID Z1 с 3+1 дисками по 2 ТБ каждый (часто используется пользователями продуктов SOHO, таких как Synologys). Во время восстановления мы читаем 3 диска по 2 ТБ каждый, и риск составляет: 1-(1-1e-14) ^(3 * 2e12 *
= 38% для потребительских или 4,7% или корпоративных дисков.
 = 38% для потребителя или 4,7% для корпоративных накопителей.
= 38% для потребителя или 4,7% для корпоративных накопителей.Вычислить погрешность для допуска на один диск легко, сложнее рассчитать вероятность для систем, допускающих отказы нескольких дисков (RAID6/Z2, RAIDZ3).
Если для восстановления используется только первый диск, а второй считывается снова с начала в случае или URE, то вероятность ошибки равна той, которая рассчитана с квадратным корнем (14,5% для потребителя RAID5 2+1, 4,5% для потребителя RAID1 1+2). Тем не менее, я полагаю (по крайней мере, в ZFS, которая имеет полные контрольные суммы!) что второй диск четности / доступный диск доступен только для чтения там, где это необходимо, а это означает, что требуется всего несколько секторов: сколько URE может произойти на первом диске? не так много, в противном случае вероятность ошибки для систем с допуском одного диска взлетела бы даже больше, чем я рассчитывал
Если я прав, второй диск четности практически снизит риск до крайне низких значений.
Помимо этого, важно иметь в виду, что производители увеличивают вероятность URE для накопителей потребительского класса по маркетинговым причинам (продают больше накопителей корпоративного класса), поэтому ожидается, что даже жесткие диски потребительского класса достигнут 1E-15 URE/ бит считывания ,
Некоторые данные: http://www.high-rely.com/hr_66/blog/why-raid-5-stops-working-in-2009-not/
Поэтому значения, которые я указал в скобках (диски предприятия), реально применимы и к дискам потребителя. А у реальных корпоративных накопителей надежность еще выше (URE/ бит = 1e-16).
Что касается вероятности механических сбоев, они пропорциональны количеству дисков и пропорционально времени, необходимому для восстановления.
страница 1 … страница 2 страница 3 страница 4 страница 5
3. Применение корректирующего кодирования в системах связи
Приведенные ниже несколько типичных примеров применения помогут понять, как эффективнее на практике осуществлять кодирование в системах связи. Один из типичных случаев характерен для систем, в которых требуются очень мощные коды. Обычный метод реализации таких кодов состоит в каскадировании двух или более простых кодов.
Еще одной интересной проблемой является кодирование для каналов, в которых ошибки возникают не независимо, а пакетами. Рассмотренные ранее методы кодирования при этом становятся совершенно неэффективными, поскольку все их характеристики определялись исходя из того, что ошибки в отдельных символах независимы друг от друга.
3.1. Каскадные коды
Каскадные коды были впервые предложены Форни в качестве метода практической реализации кода с большой длиной блока и высокой корректирующей способностью. Эта цель достигается введением нескольких уровней кодирования, обычно – двух.
Основную идею каскадного кодирования с двумя уровнями иллюстрирует рис. 3.1.

Рис. 3.1
В этой схеме комбинацию внутреннего кодера, канала и внутреннего декодера иногда называют суперканалом, аналогично, комбинацию внешнего и внутреннего кодеров — суперкодером, а комбинацию внутреннего и внешнего декодеров – супердекодером.
Длина каскадного кода получается равной N1 = N·n двоичных символов, где N — длина внешнего кода, а n — длина внутреннего кода. При этом информационная длина кода составляет K1 = K · k двоичных символов, а скорость кода R1 = R · r. Несмотря на то, что общая длина кода получается большой и, соответственно, значительно возрастает его исправляющая способность, его декодирование может выполняться с помощью двух декодеров, рассчитанных на длины составляющих его кодов n и N. Это позволяет многократно снизить сложность декодера в сравнении с тем, если бы такая исправляющая способность достигалась одноуровневым кодированием.
Простейшей иллюстрацией к каскадному кодированию является итеративный код, рассмотренный в параграфе 1.2.2. Этот код состоит из простых кодов с проверкой на четность (по строкам и столбцам), но в то же время обладает исправляющей способностью. На практике, конечно, используются гораздо более сложные коды.
Обычно внешнее кодирование выполняется блочными кодами, а внутреннее – более приспособленными для побитовой передачи по радиоканалу сверточными кодами. Каскадное кодирование широко применяется на практике, в частности, при помехоустойчивом кодировании речевой информации в системе сотовой связи формата GSM.
3.2. Кодирование с перемежением
Все рассмотренные ранее методы кодирования и примеры расчета их эффективности относились к каналам без памяти, то есть к каналам, в которых вероятность ошибки постоянна и не зависит от времени. На практике же свойства каналов связи таковы, что ошибки обычно группируются так называемыми пакетами. При постоянной некоторой средней вероятности ошибок на большом интервале времени значение Pош на отдельных коротких интервалах может значительно превышать среднее значение — Pош ср. Если для исправления таких ошибок использовать традиционные методы кодирования-декодирования, это потребует применения сложных кодов с большой исправляющей способностью и, соответственно, большой избыточностью.
Одно из возможных решений в таких случаях может состоять в использовании достаточно простого кода, рассчитанного на исправление одиночных ошибок, вместе с парой устройств, выполняющих перемежение закодированных символов перед их передачей в канал и восстановление (деперемежение) после приема. При такой обработке кодовой и принятой последовательностей ошибки на входе декодера распределяются более равномерно.
Структурная схема системы с перемежением показана на рис. 3.2.
 Рис. 3.2
Рис. 3.2
Устройство перемежения в этой схеме переупорядочивает (переставляет) символы передаваемой последовательности некоторым детерминированным образом. С помощью устройства восстановления производится обратная перестановка, восстанавливающая исходный порядок следования символов. Используются различные способы перемежения-восстановления. Первый способ – периодическое перемежение. Он проще, но при изменении характера помех может оказаться неустойчивым. Более сложное – псевдослучайное перемежение, которое обладает при нестационарных ошибках гораздо большей устойчивостью.
Периодическое перемежение
При периодическом перемежении функция перестановок периодична с некоторым периодом. Перемежение может быть блочным, когда перестановки выполняются над блоком данных фиксированного размера, или сверточным, когда процедура выполняется над непрерывной последовательностью.
Типичное блочное устройство перемежения работает следующим образом. Кодовые символы записываются в матрицу, имеющую N строк и M столбцов построчно, а читаются из нее по столбцам. На приемной стороне операция выполняется в обратном порядке: запись производится по столбцам, а чтение — по строкам. При этом происходит восстановление исходного порядка следования символов. Естественно, что процедуры перемежения и деперемежения должны быть засинхронизированы.
При таком перемежении достигается следующее: любой пакет ошибок длиной m ≤ M переходит на выходе устройства восстановления в одиночные ошибки, каждая пара которых разделена не менее чем N символами. Правда, при этом любая периодическая с периодом M одиночная ошибка превращается в пакет, но вероятность такого преобразования очень мала, хотя и существует. В этом, собственно, и состоит главный недостаток периодического перемежения: если появилась помеха с частотой следования ошибок, совпадающей с периодом перемежения или кратной ему, то до тех пор, пока характеристики помехи не изменятся, из одиночных ошибок будут возникать неисправляемые пакеты ошибок.
Псевдослучайное перемежение
При псевдослучайном перемежении блоки из L символов записываются в память с произвольной выборкой (ЗУПВ), а затем считываются из нее псевдослучайным образом. Порядок перестановок, одинаковый для устройств перемежения и восстановления, можно записать в ПЗУ и использовать его для адресации ЗУПВ.
Как и для периодического перемежения, существует вероятность того, что ошибки будут следовать таким образом (синхронно с перемежением), что одиночные ошибки будут группироваться в пакеты. Но такая вероятность чрезвычайно мала (если, конечно, это не организованная помеха и противник не знает порядка перемежения). Случайное же совпадение порядка следования перестановок при перемежении и импульсов помехи при достаточной длине L практически невероятно.
Что касается характера псевдослучайного перемежения, то для этого могут использоваться любые псевдослучайные последовательности — линейные и нелинейные последовательности максимальной длины, последовательности, основанные на линейном сравнении, а также любые алгоритмы формирования псевдослучайных чисел с необходимым периодом повторения.
На этом краткий экскурс в теорию помехоустойчивого кодирования завершен, более детально в различных аспектах практического применения корректирующего кодирования для повышения помехоустойчивости систем связи можно разобраться с использованием литературных источников [4,5].
Как мы уже отмечали, помехоустойчивое кодирование, вообще-то, не является обязательной операцией при передаче информации. Эта процедура (и соответствующий ей элемент структурной схемы РТС ПИ) может отсутствовать. Однако это может привести к очень существенным потерям в помехоустойчивости системы, значительному уменьшению скорости передачи и снижению качества передачи информации. Поэтому практически все современные системы (за исключением, быть может, самых простых) должны включать и обязательно включают помехоустойчивое кодирование данных.
4. Задачи и практические вопросы к курсу
-
По каналу связи с нормальным белым шумом передается информация со скоростью Vпи = 10 кбит/с. При этом средняя вероятность ошибок в канале составляет Pош = 10 -6.
Для улучшения качества передачи информации рассматривается несколько вариантов решения:
— кодирование корректирующим кодом с порождающей матрицей
G = | 111 |;
— кодирование сверточным (6,3)-кодом;
— кодирование (8,4)-кодом Хемминга;
— уменьшение на 20% скорости передачи .
Какое из предложенных решений обеспечит больший эффект, если в первых трех случаях скорость передачи информации должна сохраниться прежней?
2. Порождающая матрица линейного блочного кода имеет вид
|
G = |
1 0 1 0 1 0 |
. |
|
0 1 0 1 0 1 |
Определить для данного кода H, dmin. Изобразить схему кодера и декодера.
Определить число ошибок, не исправленных данным кодом за 1 час работы, если Vпи = 10 кбит/с, Рош = 10 -4.
3. В канале связи с шумами производится кодирование информации с использованием кода с порождающей матрицей вида G = | 11111 |.
На входе приемного устройства на интервале времени, соответствующем длине кодовой последовательности, присутствует колебание вида U(t) (рис. 4.1)

Рис. 4.1
Сигнал U(t) в приемном устройстве подвергается дискретизации (по 3 отсчета на интервал, соответствующий одному символу кодовой последовательности).
Какое решение относительно m примет:
— жесткий мажоритарный декодер;
— мягкий декодер максимального правдоподобия?
4. Для кодера сверточного кода со схемой, показанной на рис. 2.5, определить k0, n0, m, n , k , R , b, изобразить кодовое дерево и решетчатую диаграмму, закодировать последовательность m = (1100100000….. , декодировать r с ошибкой во втором кадре с использованием алгоритма Витерби.
5. Предложить вариант схем кодера и декодера сверточного (9.6)-кода Вайнера-Эша (по аналогии с (12,9)-кодом), исправляющего одиночную ошибку на сегменте из трех кодовых кадров. Проиллюстрировать работу кодера и декодера на примере.
6. Схема кодера линейного блочного кода приведена на рис. 4.2. Найти для него H, G, dmin, Pно , Рни. Изобразить схему синдромного декодера.

Рис. 4.2
7. Для сверточного кода со схемой рис. 2.5 ((6,3)-код) определить dmin , закодировать последовательность m = (1100000000…… , декодировать принятую последовательность с двойной ошибкой в третьем кадре с использованием алгоритма Витерби и Фано.
8. Изобразить схему кодера и декодера Меггитта для циклического (8,4)-кода. Привести пример кодирования и декодирования с одиночной ошибкой.
9. По каналу связи с шумами передается двоичная информация со скоростью Vпи = 1 Мбит/с. При этом в среднем 1 раз в минуту в канале возникает ошибка.
Для уменьшения частоты ошибок предложено использовать несколько вариантов кодирования:
— (7,4)-кодом Хемминга;
— сверточным (6,3)-кодом;
— кодом с порождающей матрицей вида G = | 111 |.
Какое из предложенных решений обеспечит больший эффект, если скорость передачи информации Vпи должна остаться неизменной?
10. Предложить варианты схем кодера и декодера сверточного (15,12)-кода (по аналогии с (12,9)-кодом Вайнера-Эша, исправляющего одиночную ошибку на сегменте из трех кодовых кадров).
Привести пример кодирования и декодирования.
11. В цифровой двоичной системе связи информация передается со скоростью 2 Мбит/с, при этом в среднем один раз в минуту в канале возникает ошибка.
Как изменится частота появления ошибок, если в канале производить кодирование сверточным (6,3)-кодом и для сохранения скорости передачи информации в 2 раза повысить скорость передачи двоичных символов?
12. Изобразить схему декодера Меггитта для циклического (7,3)-кода. Привести пример кодирования и декодирования с одиночной ошибкой.
13. Порождающая матрица блочного кода имеет вид G = | 111 |. Найти H, dmin, Pно, Pни данного кода. Изобразить схему кодера и декодера.
14. В канале связи с шумами производится кодирование информации с использованием блочного кода с порождающей матрицей G = | 11111 |. На входе приемного устройства присутствует колебание U(t) вида, показанного на рис. 4.3. Сигнал U(t) подвергается дискретизации, причем на интервал длительностью в один символ приходится два отсчета U(t).
Какое решение относительно m вынесет по принятой реализации:
— мягкий декодер максимального правдоподобия;
— жесткий мажоритарный декодер?

Рис. 4.3
15. Двоичный циклический код, заданный порождающим полиномом
g(x) = 1 + X2 + X3 + X4,
позволяет исправлять пакеты ошибок длиной 2 (двойные ошибки в соседних символах).
Определить длину кода. Сконструировать декодер Меггитта для данного кода.
-
Порождающая матрица линейного блочного кода G имеет вид
-
1
1
0
0
G =
1
0
1
0
.
1
0
0
1
Изобразить схему кодирования и декодирования с использованием данного кода. Определить время до первой не обнаруживаемой кодом ошибки, если скорость передачи составляет Vпи = 1 Мбит/с, а вероятность ошибки в канале равна Pош = 10 -7.
17. Изобразить схему, построить кодовое дерево и решетчатую диаграмму для несистематического сверточного кода с R = 1/3, m = 2 и имеющего порождающие полиномы вида
g1(x) = 1 + X + X2, g2(x) = 1 + X + X2 и g3(x) = 1 + X2.
18. По двоичному каналу связи передается информация со скоростью 9600 бит/с.
Сколько времени понадобится для передачи 1000 с. русского текста (энтропия H () = 2 бит/букву) с использованием примитивного равномерного двоичного кода и кода без избыточности ( одна страница — 2000 букв )?
19. Итеративный код задан матрицей вида
 m0 m1 p0
m0 m1 p0
U = m2 m3 p1 .
p2 p3 p4
Записать порождающую матрицу эквивалентного ему линейного блочного систематического (n,k)-кода. Определить исправляющую способность кода, найти вероятность неисправления ошибки, если вероятность ошибок в канале составляет Pош = 10 -4 .
20. Итеративный код задан матрицей вида
m 0 m1 m2 m0 + m1 m1 + m2
0 m1 m2 m0 + m1 m1 + m2
U = m3 m4 m5 m3 + m4 m4 + m5
m6 m7 m8 m6 +m7 m7 + m8 .
m0+m3 m1+m4 m2+m5 p1 p2
m5+m6 m4+m7 m5+m8 p3 p4
Проверочные символы P1….P4 формируются путем суммирования всех информационных символов, входящих в соответствующие столбцы и строки матрицы, например p1 = m0 + m1 + m3 + m4 + m6 + m7 + m0 + m3 + +m1 + m4 + m2 + m5.
Записать порождающую матрицу эквивалентного линейного блочного систематического (n,k)-кода. Определить исправляющую способность кода. Найти вероятность не исправляемой данным кодом ошибки, если вероятность ошибки в канале составляет Pош = 10 -3.
21. Исправляющий двойные ошибки циклический (15,7)-код БЧХ имеет порождающий полином вида
G(x) = X8 + X7 + X6 + X4 + 1.
Построить кодер и декодер Меггитта для этого кода.
22. Дискретный источник выдает символы из ансамбля { ai } объемом К = 50.
Какое минимальное число разрядов должен иметь равномерный двоичный код, предназначенный для кодирования символов данного ансамбля? Записать примеры кодовых слов. Какова избыточность примитивного кода, если энтропия источника составляет 3 бит/букву?
23. Ансамбль дискретных символов { ai } объемом К = 32 имеет энтропию Н(А) = 2 бит/символ.
Найти минимальное количество кодовых символов, которое надо израсходовать на кодирование символа источника равномерным примитивным двоичным кодом. Какое избыточное количество символов по сравнению с оптимальным кодом приходится использовать на один символ источника при примитивном кодировании?
24. Закодировать двоичным кодом Шеннона-Фано ансамбль { ai } , eсли вероятность символов имеет значения, приведенные ниже.
a1 a2 a3 a4 a5 a6 a7 a8
0.25 0.25 0.125 0.125 0.0625 0.0625 0.0625 0.0625
Найти среднее число символов кодовой комбинации. Определить избыточность кода.
25. В цифровой системе телевидения высокой четкости (ТВЧ) передача одного кадра изображения размером 1500*1000 элементов с числом градаций яркости М = 256 производится за Тк = 40 мс.
Какую полосу частот будет занимать цифровой телевизионный сигнал при использовании примитивной КИМ? Как изменится эта величина, если степень корреляции соседних элементов изображения составляет 0.95 и производится кодирование с полным устранением избыточности?
26. Некоторый дискретный источник выдает независимые символы из ансамбля { ai } (i = 1,2,…9) с вероятностями, определенными следующим образом:
a1 a2 a3 a4 a5 a6 a7 a8 a9
0.2 0.15 0.15 0.12 0.1 0.1 .08 0.06 0.04
Закодировать символы данного ансамбля кодом Хаффмена. Построить кодовое дерево и определить среднюю длину кодового слова.
27. Циклический (15,4)-код задан порождающим полиномом вида
g(x) = X11+ X8 + X5 + X3 + X2 + X + 1.
Построить кодер и декодер Меггитта для этого кода. Определить минимальное хеммингово расстояние и исправляющую способность кода. Найти вероятность неисправления ошибки, если вероятность ошибки в канале составляет Pош = 10 -5.
28. Показать, что хороший декодер линейного блочного кода должен производить нелинейные операции, для чего доказать:
а) что процедура вычисления синдрома линейна по отношению к вектору ошибок, т.е. если S = F(e), то F(e1 +e2 )= F(e1 )+F(e2 );
б) что линейный декодер — это такой декодер, у которого функция e = f(S), связывающая синдром и оценку вектора ошибок, удовлетворяет условию f (S1 +S2 ) = f(S1 )+f(S2 );
в) что если мы хотим, чтобы декодер исправлял все одиночные ошибки, то функция e = f(S), связывающая синдром и оценку вектора ошибок, должна быть нелинейной.
Доказать, что линейный декодер может исправлять не более n-k из n возможных одиночных ошибок.
29. Полиномиальный (17,9)-код задан порождающим многочленом вида
g(x) = X8 + X5 + X4 + X3 + 1.
Определить минимальное расстояние Хемминга для данного кода. Сколько ошибок может исправить этот код? Построить кодер и декодер Меггитта для данного кода. Определить вероятность не исправляемой кодом ошибки, если вероятность ошибки в канале составляет Pош = 10 -3.
30. Кодом с проверкой на четность называется код, который образуется путем добавления к k-разрядной информационной последовательности одного символа так, чтобы число единиц в полученном коде было четно.
Построить кодер и декодер для (8,7)-кода с проверкой на четность. Определить вероятность необнаруживаемой ошибки, если вероятность ошибки приема символа составляет Pош = 10-3 . Изобразить схемы кодера и декодера.
31. Исправляющий три ошибки (23,12)-код является циклическим с порождающим полиномом
G(x) = X11 + X10 + X6 + X5 + X4 + X2 + 1,
или G(x) = X11 + X9 + X7 + X6 + X5 + X + 1.
Найти проверочный многочлен h(x) для данного кода. Построить кодер на основе g(x). Построить декодер Меггитта для данного кода.
32. Рассмотреть линейный блочный код, кодовое слово которого формируется по правилу :
U = (x0, x1, x2, x3, x4, x0+x1+x2+x3+x4, x0+x2+x3+x4, x0+x1+x2+x4, x0+x1+x2+x3 ).
Найти проверочную матрицу кода и параметры n, k .
33. Добавить к коду из предыдущей задачи общую проверку на четность и построить соответствующую проверочную матрицу.
Чему равно минимальное кодовое расстояние полученного кода?
34. Построить для кодов из предыдущих задач порождающие матрицы по проверочным.
35. Двоичный код, предназначенный для кодирования сообщений источника с алфавитом M = 8, содержит следующие кодовые слова:
U1=00000; U2=10011; U3=01010; U4=11001;
U5=00101; U6=10110; U7=01111; U8=11100.
Является ли данный код линейным и систематическим?
Определить возможности кода по обнаружению и исправлению ошибок.
Если код является линейным, построить порождающую и проверочную матрицы кода, схемы кодирования и декодирования.
36. Спроектировать блоки кодирования и декодирования данных для системы передачи информации.
Исходные данные:
— источник выдает информацию блоками по 4 бита;
— производительность источника = 0,4 Мбит/с;
— используется (7,3)-код Хемминга;
— затухание сигнала на трассе D = 150 дБ;
— коэффициент усиления передающей и приемной антенн G = 32;
— чувствительность приемника радиолинии N0 = 10 -18 Вт/Гц;
— прием сообщения — посимвольный с использованием ортогональных сигналов.
Определить мощность передатчика системы связи, обеспечивающую вероятность безошибочного приема блока сообщения P = 0,999999.
37. Одним из способов улучшения корректирующих свойств кодов является добавление общей проверки на четность (если число единиц в кодовом слове нечетно, добавляется 1 , если четно — 0), что эквивалентно перекодированию кодовых слов следующим образом:
U1 = m*G1 , U2 = U1*G2 .
Записать выражение для перекодирующей матрицы G2, соответствующей исходному (7,3)-коду Хемминга.
Записать выражение для проверочной матрицы нового кода. Изобразить схемы кодирующего и декодирующего устройств.
Как изменится вероятность необнаружения ошибки P(E) в сравнении с исходным (7,3)-кодом, если вероятность ошибки в канале Pош = 10 -5 ?
38. По каналу связи передается информация со скоростью V = 2 кбит/с. Используются двоичные сигналы типа 1 и – 1. Мощность сигнала на входе приемника составляет P = 10 -14 Вт. Спектральная плотность мощности помех, привeденная ко входу, N0 = 10-18 Вт/Гц. При передаче используется корректирующий (7,3)-код Хемминга.
Определить число необнаруживаемых и неисправленных ошибок, проходящих по каналу связи за один час работы.
39. Для кодирования информации в системе связи используется (7,3)- код Хемминга. Скорость передачи — 1 кбит/с. В канале связи действует нормальная «белая» помеха со спектральной плотностью N0 = 10 -18 Вт/Гц.
При какой мощности сигнала на входе приемника вероятность неисправленной ошибки составит Pни = 10 -8 ?
40. Порождающая матрица кода имеет вид
 1 0 0 1 0 0 1
1 0 0 1 0 0 1
G = 0 1 0 0 1 0 1 .
0 0 1 0 0 1 1
Найти проверочную матрицу кода; изобразить схемы кодирующего и декодирующего устройств; найти минимальное кодовое расстояние кода; определить возможности кода по обнаружению и исправлению ошибок.
Определить вероятность пропуска необнаруживаемой ошибки P(E), если P ош = 10 -6 .
41. Порождающая матрица кода имеет вид
 1 0 0 0 0 1 0 1 1 1
1 0 0 0 0 1 0 1 1 1
0 1 0 0 0 1 1 1 0 1
G = 0 0 1 0 0 1 1 0 1 0 .
0 0 0 1 0 1 1 1 1 0
0 0 0 0 1 1 0 1 0 1
Найти проверочную матрицу кода; изобразить схемы кодирующего и декодирующего устройств; найти d кода; определить возможности кода по обнаружению и исправлению ошибок.
-
Проверочная матрица имеет вид
1 1 1 1 1 0 0 0
1 0 1 1 0 1 0 0 .
Н = 1 1 0 1 0 0 1 0
1 1 1 0 0 0 0 1
Найти порождающую матрицу кода; изобразить схемы кодирующего и декодирующего устройств; найти dmin кода; определить возможности кода по обнаружению и исправлению ошибок.
43. С борта космического аппарата (КА) “Марс 2002” передается телевизионное изображение поверхности планеты. Размер кадра изображения — 512*512 элементов, каждый элемент квантуется на 128 уровней и кодируется с использованием сверточного (6,3)-кода. Мощность передатчика КА — 100 Вт, коэффициент усиления антенны — G = 50.
Передача двоичных символов кодовых последовательностей осуществляется с использованием противоположных сигналов. Прием сигнала производится на антенну площадью S = 100 м2, чувствительность приемника — N =10 -22 Вт/Гц.
За какое время может быть принят один кадр изображения, если прием производится посимвольно и отношение сигнал/шум по мощности на выходе приемника должно составить не менее 500? ( Расстояние до КА R = 50 млн. км.)
Как изменится это время, если вместо помехоустойчивого кодирования использовать передачу элементов изображения ортогональными сигналами и осуществлять прием в целом?
44. В ходе радиолокационного зондирования Венеры, осуществляемого радиолокатором с синтезированной апертурой, производилась передача радиоизображения поверхности кадрами размером 2048*128 элементов, причем каждый элемент квантовался на 64 уровня. Передача осуществлялась с использованием двоичной цифровой радиолинии, использующей противоположные сигналы.
Параметры радиолинии связи:
— мощность передатчика P = 50 Вт;
— коэффициент усиления антенны передатчика G = 40;
— площадь приемной антенны S = 300 м2 ;
— чувствительность приемного устройства (спектральная плотность шумов, приведенная ко входу) N0 = 10-20 Вт/Гц;
— максимальное расстояние R =10 8 км.
Требуемое отношение сигнал/шум по мощности на выходе приемника радиолинии передачи изображения ( Pс / Pш ) = 1000 .
Сколько времени понадобится на передачу одного кадра изображения при посимвольном приеме? Как изменится это время, если кодирование элементов изображения производится сверточным (6,3)-кодом, исправляющим двойные ошибки?
45. В цифровой двоичной системе связи информация передается со скоростью 1 Мбит/с, при этом в среднем один раз в минуту в канале происходит ошибка.
Как изменится частота ошибок, если в канале использовать кодирование (7,3)-кодом Хемминга и для сохранения скорости передачи информации длительность передаваемых символов будет уменьшена в (7/3) раза? Определить величину выигрыша (проигрыша) по частоте ошибок за счет кодирования при средней вероятности ошибок в канале без кодирования Pош = 10 -3 … 10 -6.
46. Линейный блочный код задан порождающей матрицей G вида
1 0 0 1 1 0
G = 0 1 0 0 1 1 .
0 0 1 1 0 1
Изобразить схему кодера и синдромного декодера для этого кода. Составить таблицу декодирования с исправлением одиночных ошибок для декодера максимального правдоподобия.
47. Составить структурные схемы кодера и синдромного декодера для циклического (7,4)-кода, заданного порождающим полиномом
g( x ) = 1 + x + x3 .
Описать процесс кодирования и декодирования с исправлением одиночных ошибок.
48. Двоичный циклический код, заданный порождающим полиномом
g ( x ) = 1 + x2 + x3 + x4 ,
позволяет исправлять пакеты ошибок длиной 2 (двойные ошибки в соседних символах).
Чему равна длина этого кода?
Найти минимальное кодовое расстояние данного кода.
Сконструировать систематический кодер для этого кода.
Сконструировать декодер, позволяющий исправлять пакеты по 2 ошибки.
49. Построить кодирующее и декодирующее по схеме Меггитта устройства для циклического (15,11)-кода Хемминга, имеющего порождающий многочлен вида
g(x) = 1 + x +x4.
Сколько ошибок в принятой последовательности может обнаружить и исправить данный код?
50. Спроектировать блоки кодирования и декодирования для системы передачи данных со следующими исходными условиями:
— источник выдает непрерывный поток двоичных символов;
— производительность источника V = 0,3 Мбит/с;
— используется сверточный (12,9)-код Вайнера-Эша;
— декодирование сверточного кода — синдромное;
— затухание сигнала на трассе D = 160 дБ;
— коэффициент усиления передающей и приемной антенн G = 32;
— чувствительность приемника N0 = 10 -21 Вт/Гц;
— прием сигнала посимвольный с использованием ортогональных (противоположных) сигналов;
Oпределить мощность передатчика системы связи, обеспечивающего вероятность безошибочного приема символа сообщения P = 10-10.
51. Напряжение полезного сигнала на входе приемника U = 1 мкВ; входное сопротивление приемника R = 50 Ом ; сигналы противоположные; спектральная плотность помех на входе приемника N0 = 10 -13 Вт/Гц.
При какой длительности интервала наблюдения вероятность ошибочного различения двух противоположных сигналов составит Poш=10-5? Как изменится величина Рош, если использовать не противоположные, а ортогональные сигналы?
52. Действующее значение напряжения на входе приемника
страница 1 … страница 2 страница 3 страница 4 страница 5

Смотрите также:
К чему приводит неисправленная вовремя ошибка в коде?

Неисправленная вовремя ошибка в коде может привести к разным последствиям. В отдельных случаях это может очень критично отразиться на работоспособности всей программы.
Что самое интересное — многие разработчики, как опытные, так и новички, иногда оставляют решение некритичных ошибок «на потом», считая, что потом появится время их решить. Но, как известно, «на потом» — это значит «никогда». Потому что если ошибка некритичная, то и приложение функционирует нормально, а значит, про сам баг со временем просто забывают. А любая неисправленная вовремя ошибка — это как мина замедленного действия: она может «рвануть» в любое время, а когда — никто не знает; но в то же время может и не рвануть вообще.
Мы приведем несколько причин, почему всегда нужно вовремя исправлять ошибки в коде и к чему может привести их игнорирование.
К чему приводит неисправленная вовремя ошибка в программе?
Не исправленная вовремя ошибка прячет в себе новые баги. Такая ситуация не сразу заметна. Но любая проигнорированная ошибка может спровоцировать возникновение новых. Это заметно, когда вы вспомнили о забытом баге и «пошли» исправлять тот участок кода, где находится баг. Вы его исправили — участок кода работает хорошо. Но со временем начинают «всплывать» новые баги, которых раньше не было, — это и есть «скрытые» ошибки, которые возникли из-за игнорирования «некритичного бага». Любой некритичный баг может вскрывать или провоцировать возникновение критичных багов, поэтому исправляйте их сразу.
Неисправленная вовремя ошибка влияет на качество кода. Любой программист хочет, чтобы его код был идеален. Но если в коде есть не исправленный баг, то это как индикатор того, что можно писать код некачественно, потому что и с багом все работает. Представьте, что над кодом работают несколько разработчиков. Все стараются. Но в какой-то момент один из разработчиков решил не исправлять некритичный баг. Через время другой разработчик его увидел и решил тоже не исправлять свой некритичный баг, потому что он увидел, что так можно. И так продолжается со всеми членами команды. Со временем общее качество кода ухудшится, а в команде будет «висеть» вопрос: «А нужно ли вообще стараться?». Поэтому любая не исправленная вовремя ошибка ухудшает код и ослабляет рабочее состояние команды.
Неисправленная вовремя ошибка — это лишние разговоры. Когда накапливаются нерешенные баги, наступает момент разговора на темы: «Откуда появились нерешенные баги?», «Кто спровоцировал их возникновение?», «Почему не исправили вовремя?», «В какой последовательности нужно все исправлять?» и т. д. Лишние разговоры — это даром потраченное время, которое можно использовать с пользой. Поэтому, чтобы не тратить время на пустые дискуссии, просто исправляйте вовремя свои ошибки.
Не исправленная вовремя ошибка — это всегда дополнительная работа. И чем больше их накапливается, тем больше времени они требуют. К примеру, когда в процессе работы накопилось штук 60 ошибок и кто-то заявляет о 61-й, то, элементарно, много времени тратится на то, чтобы просто просмотреть, а есть ли данная ошибка в отчетах об уже известных багах?
Ошибка, которая не исправлена вовремя, всегда ухудшает общую статистику. Сколько существует команд разработчиков, столько существует и способов отслеживать ошибки в программировании. В командах, где об ошибке записывают всю информацию: от ее значимости и до времени жизни, а потом эти показатели переносят на общую эффективность команды, любая неисправленная вовремя ошибка приводит к искажению данных и ухудшению общей статистики работы команды.
Нерешенная ошибка всегда отвлекает. Простая ситуация: программист дополняет чей-то код и находит старый баг. В голове его сразу возникает куча вопросов: «Кто допустил?», «А можно ли так продолжить работу?», «А должен ли я ее исправлять, или исправить должен тот, кто ее допустил?», «А нет ли еще подобных ошибок в коде?» и т. д. Поиск ответов на все эти вопросы всегда отвлекает от основной работы — кодинга.
Неисправленная вовремя ошибка может сорвать релиз. Представьте ситуацию, что нужно срочно выпустить обновление программы или предоставить заказчику рабочую версию нового продукта в сжатые и ограниченные сроки. Это всегда будет стрессом для всей команды, так как нужно сгруппироваться и поднатужиться. Но тут всплывает, что у программы присутствует большое количество нерешенных багов, которые тоже нужно решить до релиза. Поэтому прибавляется еще больше работы, а значит, есть вероятность что-то не успеть.
Ошибки срывают сроки. Если продолжить пункт с сорванным релизом. Такое может произойти не только в критической ситуации с ограниченным временем. Даже в обычном темпе разработки есть вероятность сорвать сроки из-за не вовремя исправленной ошибки. Разные баги требуют разного времени на их решения. Некоторые решаются за считанные секунды, другие — за минуты, третьи — за часы, а некоторые могут решаться днями. В какой категории ваша не исправленная вовремя ошибка — пока не известно.
Чем дольше не исправляется баг, тем сложнее его будет исправить в будущем. Когда баг обнаружен в «свежем» коде, то и исправить его легче. Потому что если пройдет 2-3 недели, то код, где содержится баг, забудется и станет непонятным и «размытым». Это естественно, потому что прошло время, а после «того» написанного кода вы писали еще много чего, и мозг просто подзабыл, поэтому придется заново разбираться, что там и как.
Заключение
Неисправленная вовремя ошибка может ничего в себе не нести, а может принести кучу разных проблем. Поэтому откладывать «на потом» — это большой риск. Вывод только один: если нашли ошибку в коде, даже если она незначительная, то всегда исправляйте ее сразу.