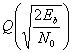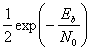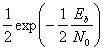При
оценке энергетического выигрыша
кодирования кодов, различающихся длиной
блока и кодовой скоростью, более удобной
оказывается характеристика
помехоустойчивости, выражаемая через
вероятность ошибки на двоичный символ
(бит).
Соотношение
между вероятностями ошибки декодирования
слова и ошибки на бит определяется
структурой порождающей матрицы
конкретного кода. Однако для обобщенного
анализа могут быть получены простые
границы для вероятности ошибки на бит.
Пусть длительность сеанса связи
составляет 1с. Тогда за сеанс связи может
быть передано 1/TW
кодовых слов, которые содержат k/TW
информационных символов. Количество
ошибочно принятых кодовых слов равно
PWk/TW.
Если через k0
обозначить количество ошибочно
принятых информационных символов при
каждом ошибочно принятом кодовом слове,
то вероятность ошибки на бит будет равна
![]()
. (3.19)
Проблема
заключается в определении величины k0.
В наихудшем случае ошибочный прием
кодового слова сопровождается ошибочным
приемом всех k
информационных символов. Тогда
получаем верхнюю границу
![]()
. (3.20)
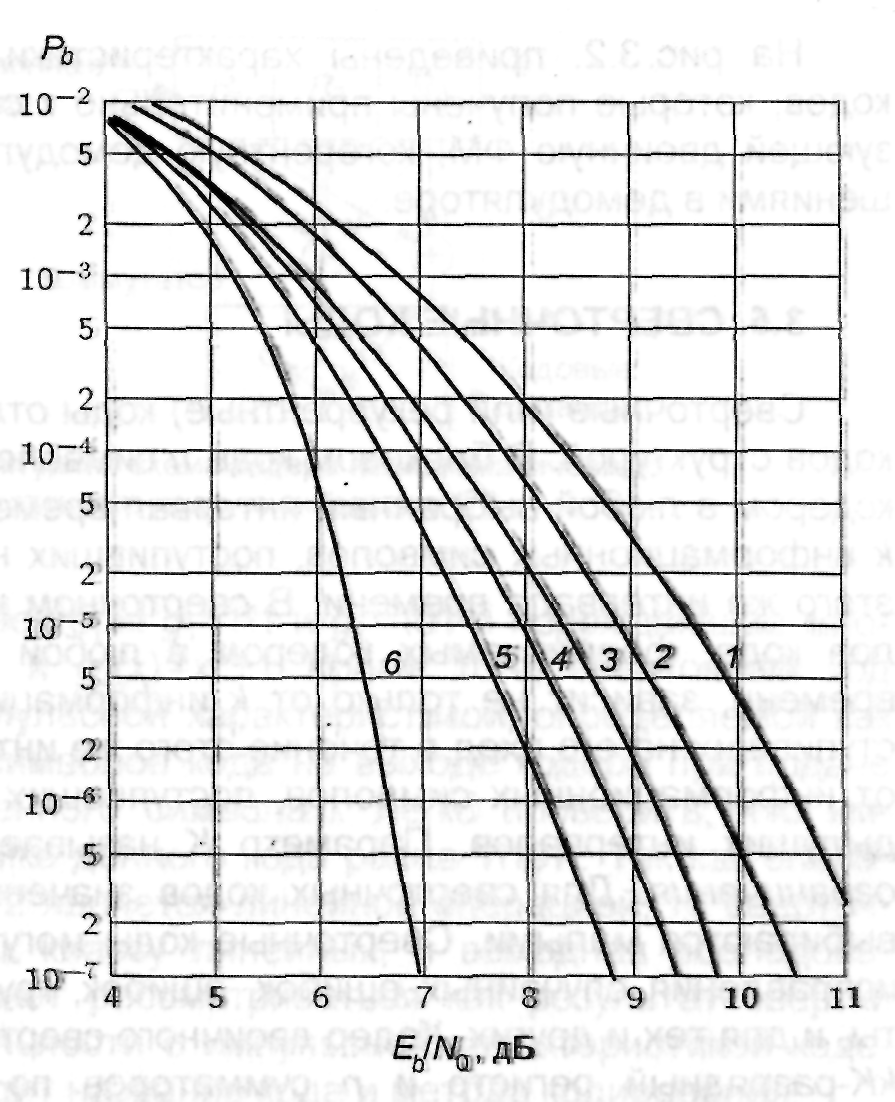
Рис.3.2.
Характеристики помехоустойчивости
блоковых кодов: 1 – без кодирования; 2 –
код Хэмминга (7, 4); 3 – код Хэмминга
(15, 11); 4 – код Хэмминга (31, 26); 5 – код
Голея (24, 12); 6 – код БЧХ (127, 64)
В
лучшем случае ошибочный прием кодового
слова приводит к единственной ошибке
в информационных символах. Поэтому для
нижней границы имеем k0=1
и
![]()
. (3.21)
Для
малых значений k
верхняя и нижняя границы становятся
строгими, и для оценки вероятности
ошибки на бит может быть использована
вероятность ошибочного приема слова.
Для высоких значений Eb/N0
вероятность ошибки на символ оказывается
чрезвычайно малой и ошибки при
декодировании кодовых слов с большой
вероятностью возникают при появлении
(t+1) ошибочных символов.
Из этих (t+1) ошибочных
символов в среднем (t+1)/n
относится к информационным. В результате
![]()
, (3.22)
![]()
. (3.23)
На
рис. 3.2. приведены характеристики
некоторых блоковых кодов, которые
получены применительно к системе связи,
использующей двоичную ФМ, когерентную
демодуляцию с жесткими решениями в
демодуляторе.
3.5. Сверточные коды
Сверточные
(или рекуррентные) коды отличаются от
блоковых кодов структурой. В блоковом
коде n символов кода, формируемых
кодером в любой выбранный интервал
времени, зависят только от k
информационных символов, поступивших
на его вход в течение этого же интервала
времени. В сверточном коде блок из n
символов кода, формируемых кодером
в любой выбранный интервал времени,
зависит не только от k
информационных символов, поступивших
на его вход в течение этого же интервала
времени, но и от информационных символов,
поступивших в течение (K–1)
предыдущих интервалов. Параметр K
называется длиной кодового
ограничения. Для сверточных кодов
значение параметров n и k
выбираются малыми. Сверточные коды
могут использоваться для исправления
случайных ошибок, ошибок, группирующихся
в пакеты, и для тех и других. Кодер
двоичного сверточиого кода содержит
kK-разрядный регистр
и n сумматоров по mod
2. Обобщенная структурная схема кодера
сверточного кода приведена на рис.3.3.
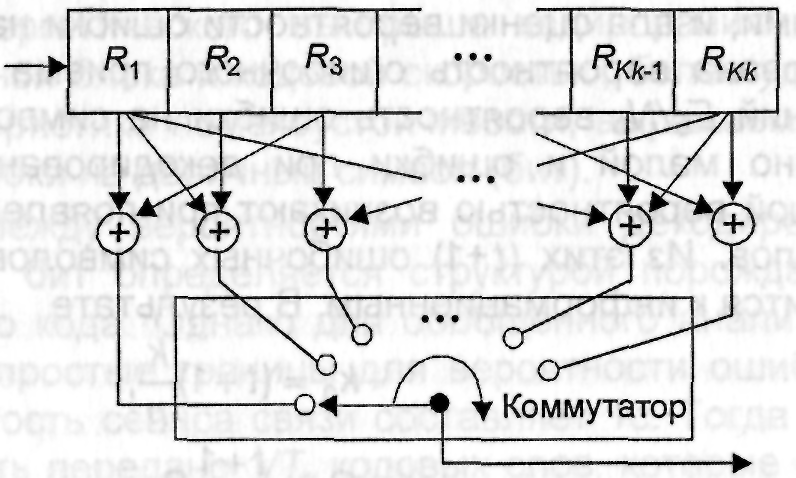
Рис.
3.3. Обобщенная структурная схема
кодера сверточного кода
На
рис. 3.4 приведены пример кодера сверточного
кода с параметрами k =1,
n = 2,
K = 3,
Rk = 1/2.
Информационные символы поступают на
вход регистра, а символы кода формируются
на выходе коммутатора. Коммутатор (КМ)
последовательно опрашивает выходы
сумматоров по mod 2 в течение
интервала времени, равного длительности
информационного символа (бита).
Схема
подключения сумматоров по mod
2, значения k, n и K
полностью описывают сверточный код. Их
можно определить с помощью генераторных
векторов или многочленов. Например,
сверточный код, формируемый кодером,
изображенным на рис.3.4,
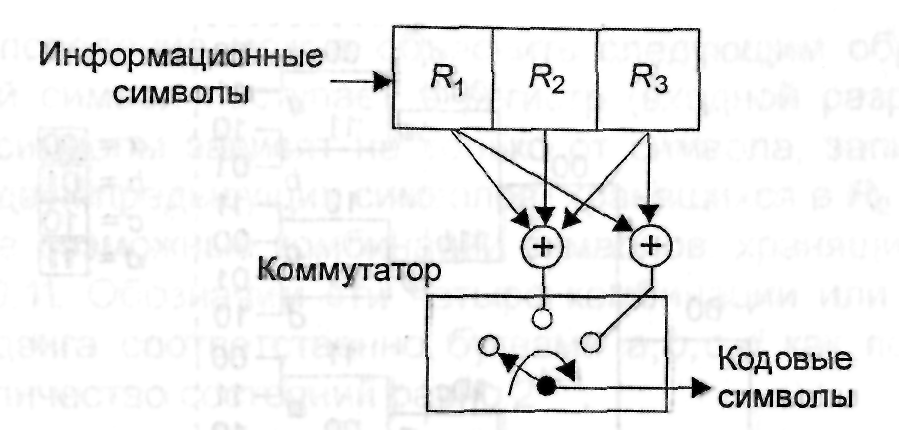
Рис.
3.4. Структурная
схема кодера несистематического
сверточного кода со скоростью 1/2
Информационные
символы имеет порождающие векторы
g1 = 111
и g2 = 101
и порождающие многочлены g1(х) = х2+х+1
и g2(х)=х2+1.
Кроме того, сверточный код может быть
задан импульсной характеристикой,
определяемой как последовательность
символов кода на выходе кодера при
подаче на его вход единственного символа
1. Легко проверить, что импульсная
характеристика данного кода равна
111011. Так как операция сложения по mod
2 является линейной операцией, то
сверточные коды относятся к классу
линейных, и выходная последовательность
кодера может рассматриваться как
результат свертки входной последовательности
с импульсной характеристикой кодера.
Отсюда и происходит название кода и
метода кодирования.
Процедуры
кодирования и декодирования удобно
описывать с помощью так называемого
кодового дерева, которое отображает
последовательности на выходе кодера
для любой возможной входной
последовательности. На рис. 3.5 приведено
кодовое дерево кодера, изображенного
на рис. 3.4, для блока из пяти информационных
символов. Если первый символ принимает
значение 0, то на выходе кодера формируется
пара символов 00. Если первый символ
принимает значение 1, то на выходе кодера
формируется пара символов 11. Это показано
с помощью двух ветвей, которые выходят
из начального узла. Верхняя ветвь
соответствует 0, нижняя – 1. В каждом из
последующих узлов ветвление происходит
аналогичным образом: из каждого узла
исходит две ветви, причем верхняя ветвь
соответствует 0, а нижняя – 1. Ветвление
будет происходить вплоть до последнего
символа входного блока. Вслед за ним
все входные символы принимают значение
0, и образуется только одна обрывающаяся
ветвь. Таким образом, каждой из возможных
входных комбинаций информационных
символов соответствует своя вершина
на кодовом дереве. В данном случае
имеется 32 вершины. С помощью кодового
дерева легко построить выходную
последовательность символов кода,
соответствующую определенной входной
последовательности. Например, входной
последовательности 11010 соответствует
выходная последовательность, лежащая
на пути, изображенном пунктирной линией.

Рис.3.5.
Кодовое дерево для кодера, изображенного
на рис. 3.4
Анализируя
структуру кодового дерева на рис. 3.5,
можно заметить, что, начиная с узлов
третьего уровня, она носит повторяющийся
характер. Действительно, группа ветвей,
заключенных в прямоугольники, изображенные
пунктирными линиями, полностью совпадают.
Это означает, что при поступлении на
вход четвертого символа выходной символ
кода будет одним и тем же, независимо
от того, каким был первый входной символ:
0 или 1. Другими словами, после первых
трех групп выходных символов кода
входные последовательности 1x1x2x3x4…
и 0x1x2x3x4…
будут порождать один и тот же выходной
символ.
Обозначим
четыре узла третьего уровня, т.е. узлы,
в которых происходит третье ветвление,
буквами a,b,c,d.
Повторяющаяся структура ветвей имеет
место и для узлов четвертого и пятого
уровней, поэтому их также можно обозначить
этими же буквами. Для узлов пятого уровня
любой из четырех комбинаций (11,10,01, 00)
первых двух входных символов будет
соответствовать один и тот же выходной
символ.
Такое
поведение можно объяснить следующим
образом. Когда входной символ поступает
в регистр (входной разряд R1),
то выходные символы зависят не только
от символа, записанного в R1,
но и от двух предыдущих символов,
хранящихся в R2
и R3.
Имеется четыре возможные комбинации
символов, хранящихся в R2
и R3:
00, 01, 10, 11. Обозначим эти четыре комбинации
или состояния регистра сдвига
соответственно буквами a,
b, c,
d как показано на
рис. 3.5. Количество состояний равно 2K–1.
Входные
символы 0 и 1 будут формировать четыре
различные комбинации выходных символов
в зависимости от состояния кодера. Если
входной символ 0, то на выходе декодера
будут формироваться 00, 10, 11 или 01 в
зависимости от того, в каком состоянии
находился кодер: a, b,
c или d.
To же самое правило можно
применить относительно символа 1.
Таким
образом, поведение кодера можно полностью
описать с помощью диаграммы состояний,
изображенной на рис. 3.6, а или
направленного графа с четырьмя состояниями
(рис. 3.6, б) который устанавливает
однозначное соответствие между входными
и выходными символами кодера. На графе
сплошные линии соответствуют входному
символу 0, а пунктирные – символу 1.
Например, если кодер находится в состоянии
а и на вход поступает 1, то на выходе
декодера будет формироваться комбинация
11 (пунктирная линия) и декодер перейдет
в состояние b,
соответствующее R3 = 0
и R2 = 1
– Аналогичным образом при поступлении
0 декодер останется в состоянии а
(сплошная линия) и на выходе будет
формироваться комбинация 00.
Заметим,
что прямой переход из состояния а в
состояние с или d
невозможен, причем из любого состояния
прямой переход возможен только в одно
из двух состояний. Диаграмма состояний
содержит исчерпывающую информацию о
структуре кодового дерева.
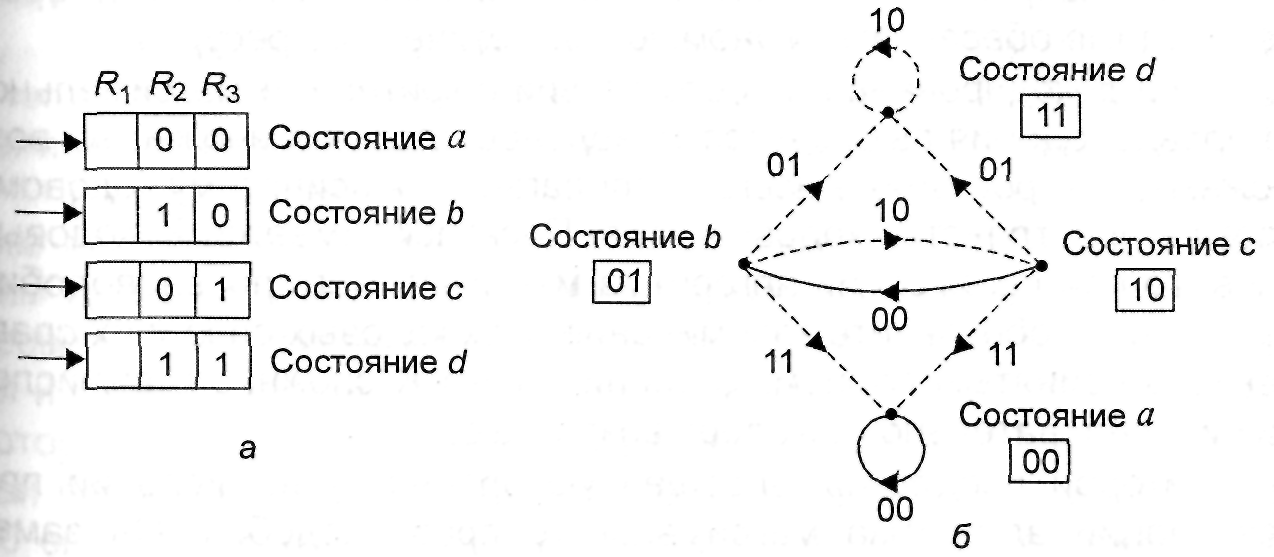
Рис.
3.6. Диаграмма состояний для кодера,
изображенного на рис. 3.4
Другим
полезным способом описания кодового
дерева является решетчатая диаграмма,
изображенная на рис. 3.7. Диаграмма берет
начало из состояния а и на ней
отображаются все возможные переходы
при поступлении на вход очередного
символа. Сплошным линиям соответствуют
переходы, происходящие при поступлении
символа 1 пунктирным – символа 0. При
поступлении на вход двух символов кодер
оказывается в одном из четырех состояний:
a, b,
c или d.
Заметим, что решетчатая диаграмма имеет
повторяющийся характер и может быть
легко построена с помощью диаграммы
состояний.
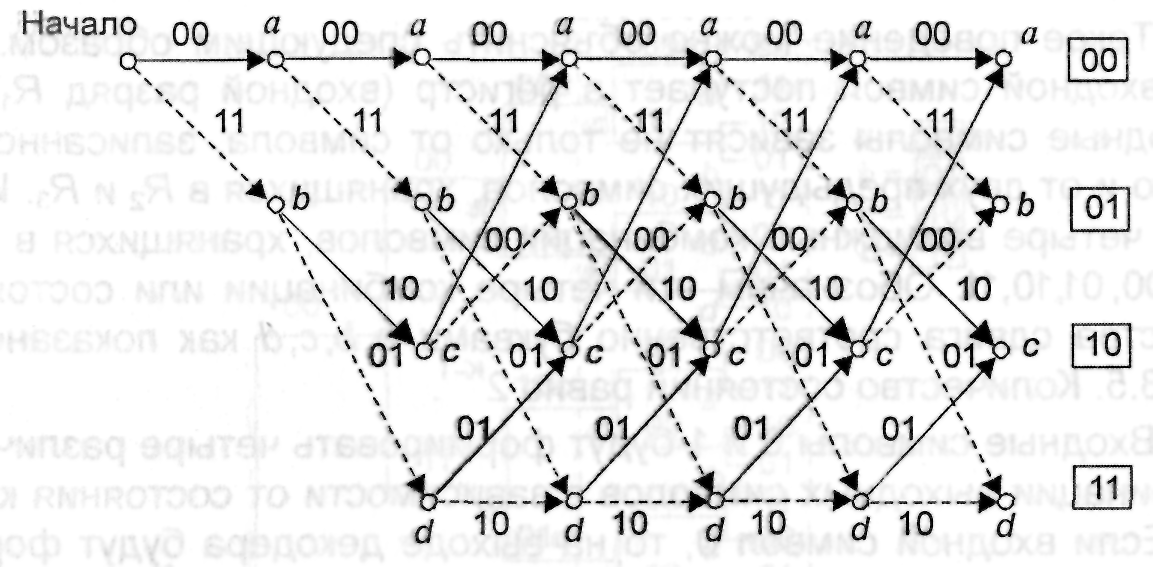
Рис.
3.7. Решетчатая диаграмма для кодера,
изображенного на рис.3.4
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
26.02.2016541.64 Кб16Сертификат Реконструкция жизни.PDF
- #
- #
- #
- #
- #
- #
Что такое BER — Bit Error Rate?
Date:2016/4/5 15:56:57 Hits:
«Коэффициент ошибок по битам, BER используется для количественной оценки канала, несущего данные, путем подсчета частоты ошибок в строке данных. Он используется в телекоммуникациях, сетях и радиосистемах.Коэффициент битовых ошибок, BER — ключевой параметр, который используется при оценке систем, передающих цифровые данные из одного места в другое «. — Fmuser

Системы, для которых коэффициент битовых ошибок, BER применима включают ссылки радио данных, а также информационных систем волоконно-оптические, Ethernet, или любую систему, которая передает данные по сети той или иной форме, где шум, помехи, и дрожание фазы может вызвать ухудшение цифрового сигнал.Хотя есть некоторые различия в том, как эти системы работают и каким образом влияет скорость передачи в битах ошибки, основы скорости битовых ошибок сама по-прежнему то же самое.
Когда данные передаются по каналу передачи данных, существует вероятность ошибок, вводимых в систему. Если ошибки вводятся в данных, то целостность системы может быть поставлена под угрозу. В результате, необходимо оценить производительность системы, и коэффициент ошибок в битах, BER, обеспечивает идеальный способ, в котором это может быть достигнуто.
В отличие от многих других форм оценки, частота ошибок по битам, КОБ оценивает полный впритык производительность системы, включающей передатчик, приемник и среды между ними. Таким образом, частота появления ошибочных битов, КОБ позволяет реальная производительность системы в эксплуатацию, подлежащих испытанию, а не проверки составных частей и в надежде, что они будут работать удовлетворительно, когда на месте.
Бит ошибки скорости определения BER и основы
Как следует из названия, частота ошибочных битов определяется как скорость, при которой возникают ошибки в системе передачи. Это может быть непосредственно переведены в число ошибок, возникающих в строке заявленным количеством битов. Определение частоты появления ошибочных битов может быть переведена в простую формулу:
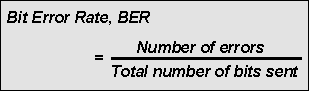
Если среда между передатчиком и приемником хорошо и соотношение сигнал-шум является высоким, то скорость битовых ошибок будет очень мала — возможно, незначительны и не имеющие какого-либо заметного влияния на общую систему Однако, если шум может быть обнаружен, то есть вероятность того, что частота появления ошибочных битов нужно будет рассмотреть.
Основными причинами деградации канала передачи данных и соответствующей частоты ошибок передачи в битах, BER шум и изменения в пути распространения (где используются сигнальные пути радио). Оба эффекта имеют случайный элемент к ним, шум следующий гауссовой функции вероятности в то время как модель распространения следует модели Рэлея. Это означает, что анализ характеристик канала, как правило, проводится с использованием методов статистического анализа.
Для волоконно-оптических систем, битовых ошибок в основном являются результатом несовершенства используемых компонентов, чтобы сделать ссылку. Они включают в себя оптический драйвер, приемник, разъемы и самого волокна. Ошибки в битах также могут быть введены в результате оптической дисперсии и затухания, которые могут присутствовать. Также шум может быть введен в самом оптическом приемнике. Как правило, они могут быть фотодиоды и усилители, которые должны реагировать на очень маленьких изменений, и в результате может быть высокий уровень шума, который присутствует.
Другим фактором, способствующим для битовых ошибок является любой Дрожание фазы, которые могут присутствовать в системе, так как это может изменить выборку данных Теа.
BER и Eb / No
Отношение сигнал-шум и Eb / No цифры не являются параметрами, которые в большей степени связаны с радиолиний и систем радиосвязи. С точки зрения этого, частота появления ошибочных битов, BER, также может быть определена в терминах вероятности ошибки или POE. Определения этого используются три других переменных. Они являются функция ошибки, ERF, энергия в один бит, ЭБ, и спектральная плотность мощности шума (что мощность шума в полосе частот Гц 1), №
Следует отметить, что каждый тип модуляции имеет свое собственное значение функции ошибки. Это происходит потому, что каждый тип модуляции выполняет по-разному в присутствии шума. В частности, схемы более высокого порядка модуляции (к примеру 64QAM и т.д.), которые способны переносить более высокие скорости передачи данных, не столь надежными в присутствии шума. Меньшие форматы модуляции порядка (например, BPSK, QPSK и т.д.) предлагают более низкие скорости передачи данных, но являются более надежными.
Энергии на бит, ЭБ, может быть определена путем деления мощности несущей на скорости передачи данных и является мерой энергии с размерами джоулей. Нет это мощность на герц, и поэтому это имеет размерность мощности (джоулей в секунду), разделенное на секунды). Не Глядя на размеры отношение Eb / No все размеры компенсируют дать безразмерное отношение. Важно отметить, что РОЕ пропорционально Eb / No и является формой сигнала к шуму.
Факторы, влияющие на частоту появления ошибочных битов BER,
Это можно видеть из использования Eb / No, что частоты появления ошибочных битов, КОБ может зависеть от ряда факторов. Изменяя переменные, которыми можно управлять, можно оптимизировать систему, чтобы обеспечить уровень производительности, которые необходимы. Это, как правило, проводится в стадии проектирования системы передачи данных таким образом, что рабочие параметры могут быть скорректированы на начальных этапах проектирования концепции.
• Помехи: Уровни помех, присутствующих в системе, как правило, установлены под воздействием внешних факторов и не может быть изменен с помощью конструкции системы. Тем не менее, можно установить ширину полосы пропускания системы. За счет снижения пропускной способности уровень помех может быть уменьшено. Однако уменьшение полосы пропускания ограничивает пропускную способность данных, что может быть достигнуто.
• Увеличьте мощность передатчика: Кроме того, можно повысить уровень мощности системы таким образом, чтобы мощность на бит увеличивается. Это должно быть сбалансировано против факторов, включая уровни помех другим пользователям и влияние увеличения выходной мощности от размера усилителя мощности и общее энергопотребление и время автономной работы и т.д.
• Модуляция низшего порядка: схемы модуляции Низшие порядка могут быть использованы, но это за счет скорости передачи данных.
• Уменьшите пропускную способность: Другой подход, который может быть принят, чтобы уменьшить частоту появления ошибочных битов, чтобы уменьшить ширину полосы частот. Более низкие уровни шума будут получены, и, следовательно, соотношение сигнал-шум улучшится. Опять же это приводит к уменьшению пропускной способности данных достижимым.
Необходимо сбалансировать все имеющиеся факторы для достижения удовлетворительной скорости появления ошибочных битов. Обычно это не представляется возможным достичь всех требований и некоторые компромиссы необходимы. Тем не менее, даже с битовой частотой ошибок ниже того, что в идеале требуется, дополнительные компромиссы могут быть сделаны с точки зрения уровней коррекции ошибок, которые вводятся в передаваемые данные. Хотя более избыточные данные должны быть отправлены с более высокими уровнями коррекции ошибок, это может помочь замаскировать последствия любых битовых ошибок, которые возникают, тем самым улучшая общую частоту появления ошибок в битах.
Частота появления ошибочных битов BER является параметром, который дает прекрасную индикацию производительности линии передачи данных, таких как радио или волоконно-оптической системы. В качестве одного из основных параметров, представляющих интерес в любой линии передачи данных является количество ошибок, которые возникают, то коэффициент ошибок в битах является ключевым параметром. Знание BER также позволяет использовать другие особенности ссылки, такие как мощность и пропускную способность, и т.д., чтобы быть адаптированы для того, чтобы требуемые эксплуатационные характеристики, которые будут получены.
Оставить сообщение
Список сообщений
В цифровой передаче, количество битовых ошибок является количеством принятых бит одного потока данных над каналом связи, которые были изменены из — за шум, помехи, искажений или битой синхронизацию ошибок.
Коэффициент битовых ошибок ( BER ) — это количество битовых ошибок в единицу времени. Коэффициент битовых ошибок (также BER ) — это количество битовых ошибок, деленное на общее количество переданных битов за исследуемый интервал времени. Коэффициент битовых ошибок — это безразмерная мера производительности, часто выражаемая в процентах .
Бита вероятность ошибка р е является ожидаемым значением коэффициента ошибок по битам. Коэффициент битовых ошибок можно рассматривать как приблизительную оценку вероятности битовых ошибок. Эта оценка точна для длительного интервала времени и большого количества битовых ошибок.
Пример
В качестве примера предположим, что эта переданная битовая последовательность:
0 1 1 0 0 0 1 0 1 1
и следующая полученная битовая последовательность:
0 0 1 0 1 0 1 0 0 1,
Количество битовых ошибок (подчеркнутые биты) в этом случае равно 3. BER — это 3 неверных бита, разделенных на 10 переданных битов, в результате чего BER составляет 0,3 или 30%.
Коэффициент ошибок пакета
Коэффициент ошибок пакетов (PER) — это количество неправильно принятых пакетов данных, деленное на общее количество принятых пакетов. Пакет объявляется некорректным, если хотя бы один бит ошибочен. Ожидаемое значение PER обозначается вероятностью ошибки пакета p p, которая для длины пакета данных N бит может быть выражена как
-
 ,
,

предполагая, что битовые ошибки не зависят друг от друга. Для малых вероятностей битовых ошибок и больших пакетов данных это примерно

Подобные измерения могут быть выполнены для передачи кадров, блоков или символов .
Факторы, влияющие на BER
В системе связи на BER на стороне приемника могут влиять шум канала передачи, помехи, искажения, проблемы битовой синхронизации, затухание, замирания из-за многолучевого распространения беспроводной связи и т. Д.
BER может быть улучшен путем выбора сильного уровня сигнала (если это не вызывает перекрестных помех и большего количества битовых ошибок), путем выбора медленной и надежной схемы модуляции или схемы линейного кодирования, а также путем применения схем канального кодирования, таких как избыточные коды прямого исправления ошибок. .
КОБ передачи является количество обнаруженных битов, которые являются неправильными до коррекции ошибок, разделенных на общее количество переданных битов ( в том числе избыточных кодов ошибок). Информация КОБ, примерно равна вероятности ошибки декодирования, это число декодированных битов, которые остаются неправильно после коррекции ошибок, деленное на общее число декодированных битов (полезная информация). Обычно BER передачи больше, чем BER информации. На информационный BER влияет сила кода прямого исправления ошибок.
Анализ BER
BER можно оценить с помощью стохастического ( Монте-Карло ) компьютерного моделирования. Если предполагается простая модель канала передачи и модель источника данных, BER также может быть вычислен аналитически. Примером такой модели источника данных является источник Бернулли .
Примеры простых моделей каналов, используемых в теории информации :
- Двоичный симметричный канал (используется при анализе вероятности ошибки декодирования в случае непакетных битовых ошибок в канале передачи)
- Канал аддитивного белого гауссова шума (AWGN) без замирания.
Наихудший сценарий — это полностью случайный канал, в котором шум полностью преобладает над полезным сигналом. Это приводит к BER передачи 50% (при условии, что предполагается источник двоичных данных Бернулли и двоичный симметричный канал, см. Ниже).
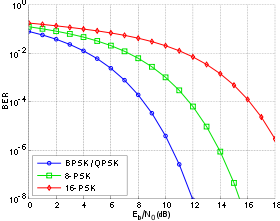

В канале с шумом BER часто выражается как функция нормированного показателя отношения несущей к шуму, обозначаемого Eb / N0 (отношение энергии на бит к спектральной плотности мощности шума) или Es / N0 (энергия на символ модуляции для спектральная плотность шума).
Например, в случае QPSK модуляции и канал АБГШ, КОБ в зависимости от Eb / N0 определяется по формуле:
.

Люди обычно строят кривые BER для описания производительности цифровой системы связи. В оптической связи обычно используется зависимость BER (дБ) от принимаемой мощности (дБм); в то время как в беспроводной связи используется BER (дБ) по сравнению с SNR (дБ).
Измерение коэффициента ошибок по битам помогает людям выбрать подходящие коды прямого исправления ошибок. Поскольку большинство таких кодов исправляют только перевороты битов, но не вставки или удаления битов, метрика расстояния Хэмминга является подходящим способом измерения количества битовых ошибок. Многие кодеры FEC также непрерывно измеряют текущий BER.
Более общий способ измерения количества битовых ошибок — это расстояние Левенштейна . Измерение расстояния Левенштейна больше подходит для измерения характеристик сырого канала перед кадровой синхронизацией, а также при использовании кодов коррекции ошибок, предназначенных для исправления вставки и удаления битов, таких как коды маркеров и коды водяных знаков.
Математический проект
BER — это вероятность неправильной интерпретации из-за электрического шума . Рассматривая биполярную передачу NRZ, мы имеем

 для «1» и для «0». Каждый из и имеет период .
для «1» и для «0». Каждый из и имеет период .




Зная, что шум имеет двустороннюю спектральную плотность ,

является 
и есть .

Возвращаясь к BER, у нас есть вероятность неправильного толкования .

 и
и 
где — порог принятия решения, установленный в 0, когда .


Мы можем использовать среднюю энергию сигнала, чтобы найти окончательное выражение:


± §
Проверка коэффициента битовых ошибок
BERT или тест на частоту ошибок по битам — это метод тестирования схем цифровой связи, в котором используются заранее определенные шаблоны нагрузки, состоящие из последовательности логических единиц и нулей, сгенерированных генератором тестовых шаблонов.
BERT обычно состоит из генератора тестовых шаблонов и приемника, который может быть настроен на один и тот же шаблон. Их можно использовать парами, по одному на любом конце линии передачи, или по отдельности на одном конце с кольцевой проверкой на удаленном конце. BERT обычно представляют собой автономные специализированные инструменты, но могут быть основаны на персональном компьютере . При использовании количество ошибок, если таковые имеются, подсчитывается и представляется в виде отношения, например 1 на 1 000 000 или 1 на 1e06.
Распространенные типы стресс-паттернов BERT
- PRBS ( псевдослучайная двоичная последовательность ) — псевдослучайный двоичный секвенсор из N бит. Эти последовательности шаблонов используются для измерения джиттера и глаз-маски TX-данных в электрических и оптических каналах передачи данных.
- QRSS (квазислучайный источник сигнала) — псевдослучайный двоичный секвенсор, который генерирует каждую комбинацию 20-битного слова, повторяет каждые 1048 575 слов и подавляет последовательные нули не более чем до 14. Он содержит последовательности с высокой плотностью, последовательности с низкой плотностью, и последовательности, которые меняются от низкого к высокому и наоборот. Этот шаблон также является стандартным шаблоном, используемым для измерения джиттера.
- 3 из 24 — шаблон содержит самую длинную строку последовательных нулей (15) с самой низкой плотностью (12,5%). Этот шаблон одновременно подчеркивает минимальную плотность единиц и максимальное количество последовательных нулей. Формат кадра D4 3 из 24 может вызвать желтый аварийный сигнал D4 для цепей кадра в зависимости от выравнивания одного бита с кадром.
- 1: 7 — Также упоминается как 1 из 8 . Он имеет только один в восьмибитной повторяющейся последовательности. Этот шаблон подчеркивает минимальную плотность 12,5% и должен использоваться при тестировании средств, установленных для кодирования B8ZS, поскольку шаблон 3 из 24 увеличивается до 29,5% при преобразовании в B8ZS.
- Мин. / Макс. — последовательность быстрого перехода узора с низкой плотности на высокую. Наиболее полезно при усилении функции ALBO ретранслятора .
- Все единицы (или отметка) — шаблон, состоящий только из единиц. Этот шаблон заставляет повторитель потреблять максимальное количество энергии. Если постоянный ток к ретранслятору отрегулирован должным образом, ретранслятор не будет иметь проблем с передачей длинной последовательности. Этот образец следует использовать при измерении регулирования мощности диапазона. Шаблон «все единицы без рамки» используется для обозначения AIS (также известного как синий сигнал тревоги ).
- Все нули — шаблон, состоящий только из нулей. Это эффективно при поиске оборудования, неправильно настроенного для AMI, такого как низкоскоростные входы мультиплексного волокна / радио.
- Чередование нулей и единиц — шаблон, состоящий из чередующихся единиц и нулей.
- 2 из 8 — шаблон содержит не более четырех последовательных нулей. Он не вызовет последовательность B8ZS, потому что для подстановки B8ZS требуется восемь последовательных нулей. Схема эффективна при поиске оборудования, не использованного для B8ZS.
- Bridgetap — разветвления моста в пределах пролета можно обнаружить с помощью ряда тестовых шаблонов с различной плотностью единиц и нулей. Этот тест генерирует 21 тестовую таблицу и длится 15 минут. Если возникает ошибка сигнала, на участке может быть один или несколько ответвлений моста. Этот шаблон эффективен только для участков T1, которые передают необработанный сигнал. Модуляция, используемая в пролетах HDSL, сводит на нет способность шаблонов моста обнаруживать ответвления моста.
- Multipat — этот тест генерирует пять часто используемых тестовых шаблонов, позволяющих проводить тестирование диапазона DS1 без необходимости выбирать каждый тестовый шаблон отдельно. Шаблоны: все единицы, 1: 7, 2 из 8, 3 из 24 и QRSS.
- T1-DALY и 55 OCTET — Каждый из этих шаблонов содержит пятьдесят пять (55) восьмибитовых октетов данных в последовательности, которая быстро изменяется между низкой и высокой плотностью. Эти паттерны используются в основном для нагрузки на схему ALBO и эквалайзера, но они также усиливают восстановление синхронизации. 55 OCTET имеет пятнадцать (15) последовательных нулей и может использоваться только без рамки без нарушения требований к плотности. Для сигналов с фреймами следует использовать шаблон T1-DALY. Оба шаблона вызовут код B8ZS в схемах с опцией для B8ZS.
Тестер коэффициента битовых ошибок
Тестер коэффициента ошибок по битам (BERT), также известный как «тестер коэффициента ошибок по битам» или решение для тестирования коэффициента ошибок по битам (BERT), представляет собой электронное испытательное оборудование, используемое для проверки качества передачи сигнала отдельных компонентов или целых систем.
Основные строительные блоки BERT:
- Генератор шаблонов, который передает определенный тестовый шаблон в ИУ или тестовую систему.
- Детектор ошибок, подключенный к DUT или тестовой системе, для подсчета ошибок, генерируемых DUT или тестовой системой.
- Генератор тактовых сигналов для синхронизации генератора шаблонов и детектора ошибок
- Анализатор цифровой связи не является обязательным для отображения переданного или принятого сигнала.
- Электрооптический преобразователь и оптико-электрический преобразователь для проверки сигналов оптической связи.
Смотрите также
- Пакетная ошибка
- Код исправления ошибок
- Секунда с ошибкой
- Частота ошибок Витерби
использованная литература
![]() Эта статья включает материалы, являющиеся общественным достоянием, из документа Управления общих служб : «Федеральный стандарт 1037C» .(в поддержку MIL-STD-188 )
Эта статья включает материалы, являющиеся общественным достоянием, из документа Управления общих служб : «Федеральный стандарт 1037C» .(в поддержку MIL-STD-188 )
внешние ссылки
- QPSK BER для канала AWGN — онлайн-эксперимент
4.7.1. Вероятность появления ошибочного бита при когерентном обнаружении сигнала BPSK
4.7.2. Вероятность появления ошибочного бита при когерентном обнаружении сигнала в дифференциальной модуляции BPSK
4.7.3. Вероятность появления ошибочного бита при когерентном обнаружении сигнала в бинарной ортогональной модуляции FSK
4.7.4. Вероятность появления ошибочного бита при некогерентном обнаружении сигнала в бинарной ортогональной модуляции FSK
4.7.5. Вероятность появления ошибочного бита для бинарной модуляции DPSK
4.7.6. Вероятность ошибки для различных модуляций
4.7.1. Вероятность появления ошибочного бита при когерентном обнаружении сигнала BPSK
Важной мерой производительности, используемой для сравнения цифровых схем модуляции, является вероятность ошибки, РЕ Для коррелятора или согласованного фильтра вычисление РЕ можно представить геометрически (см. рис. 4.6). Расчет РЕ включает нахождение вероятности того, что при данном векторе переданного сигнала, скажем si вектор шума n выведет сигнал из области 1. Вероятность принятия детектором неверного решения называется вероятностью символьной ошибки, рE. Несмотря на то что решения принимаются на символьном уровне, производительность системы часто удобнее задавать через вероятность битовой ошибки (Ps). Связь РВ и РЕ рассмотрена в разделе 4.9.3 для ортогональной передачи сигналов и в разделе 4.9.4 для многофазной передачи сигналов.
Для удобства изложения в данном разделе мы ограничимся когерентным обнаружением сигналов BPSK. В этом случае вероятность символьной ошибки — это то же самое, что и вероятность битовой ошибки. Предположим, что сигналы равновероятны. Допустим также, что при передаче сигнала ![]() принятый сигнал r(t) равен
принятый сигнал r(t) равен ![]() , где n(t) — процесс AWGN; кроме того, мы пренебрегаем ухудшением качества вследствие введенной каналом или схемой межсимвольной интерференции. Как показывалось в разделе 4.4.1, антиподные сигналы
, где n(t) — процесс AWGN; кроме того, мы пренебрегаем ухудшением качества вследствие введенной каналом или схемой межсимвольной интерференции. Как показывалось в разделе 4.4.1, антиподные сигналы ![]() и
и ![]() можно описать в одномерном сигнальном пространстве, где
можно описать в одномерном сигнальном пространстве, где
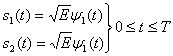 (4.74)
(4.74)
Детектор выбирает ![]() с наибольшим выходом коррелятора
с наибольшим выходом коррелятора ![]() ; или, в нашем случае антиподных сигналов с равными энергиями, детектор, используя формулу (4.20), принимает решение следующего вида.
; или, в нашем случае антиподных сигналов с равными энергиями, детектор, используя формулу (4.20), принимает решение следующего вида.
![]() (4.74)
(4.74)
Как видно из рис. 4.9, возможны ошибки двух типов: шум так искажает переданный сигнал ![]() , что измерения в детекторе дают отрицательную величину z(T), и детектор выбирает гипотезу H2, что был послан сигнал s2(t). Возможна также обратная ситуация: шум искажает переданный сигнал
, что измерения в детекторе дают отрицательную величину z(T), и детектор выбирает гипотезу H2, что был послан сигнал s2(t). Возможна также обратная ситуация: шум искажает переданный сигнал ![]() , измерения в детекторе дают положительную величину z(T), и детектор выбирает гипотезу Н1, соответствующую предположению о передаче сигнала
, измерения в детекторе дают положительную величину z(T), и детектор выбирает гипотезу Н1, соответствующую предположению о передаче сигнала ![]() .
.
В разделе 3.2.1.1 была выведена формула (3.42), описывающая вероятность битовой ошибки РB для детектора, работающего по принципу минимальной вероятности ошибки.
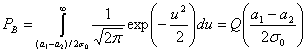 (4.76)
(4.76)
Здесь σ0 — среднеквадратическое отклонение шума вне коррелятора. Функция Q(x), называемая гауссовым интегралом ошибок, определяется следующим образом.
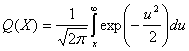 (4.77)
(4.77)
Эта функция подробно описывается в разделах 3.2 и Б.3.2.
Для передачи антиподных сигналов с равными энергиями, таких как сигналы в формате BPSK, приведенные в выражении (4.74), на выход приемника поступают следующие компоненты: ![]() , при переданном сигнале
, при переданном сигнале ![]() , и
, и ![]() , при переданном сигнале s2(t), где Еь — энергия сигнала, приходящаяся на двоичный символ. Для процесса AWGN дисперсию шума
, при переданном сигнале s2(t), где Еь — энергия сигнала, приходящаяся на двоичный символ. Для процесса AWGN дисперсию шума ![]() вне коррелятора можно заменить N0/2 (см. приложение В), так что формулу (4.76) можно переписать следующим образом.
вне коррелятора можно заменить N0/2 (см. приложение В), так что формулу (4.76) можно переписать следующим образом.
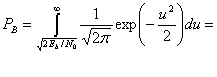 (4.78)
(4.78)
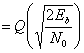 (4.79)
(4.79)
Данный результат для полосовой передачи антиподных сигналов BPSK совпадает с полученными ранее формулами для обнаружения антиподных сигналов с использованием согласованного фильтра (формула (3.70)) и обнаружения узкополосных антиподных сигналов с применением согласованного фильтра (формула (3.76)). Это является примером описанной ранее теоремы эквивалентности. Для линейных систем теорема эквивалентности утверждает, что на математическое описание процесса обнаружения не влияет сдвиг частоты. Как следствие, использование согласованных фильтров или корреляторов для обнаружения полосовых сигналов (рассмотренное в данной главе) дает те же соотношения, что были выведены ранее для сопоставимых узкополосных сигналов.
4.7.2. Вероятность появления ошибочного бита при когерентном обнаружении сигнала в дифференциальной модуляции BPSK
Сигналы в канале иногда инвертируются; например, при использовании когерентного опорного сигнала, генерируемого контуром ФАПЧ, фаза может быть неоднозначной. Если фаза несущей была инвертирована при использовании схемы DPSK, как это скажется на сообщении? Поскольку информация сообщения кодируется подобием или отличием соседних символов, единственным следствием может быть ошибка в бите, который инвертируется, или в бите, непосредственно следующим за инвертированным. Точность определения подобия или отличия символов не меняется при инвертировании несущей. Иногда сообщения (и кодирующие их сигналы) дифференциально кодируются и когерентно обнаруживаются, чтобы просто избежать неопределенности в определении фазы.
Вероятность появления ошибочного бита при когерентном обнаружении сигналов в дифференциальной модуляции PSK (DPSK) дается выражением [5].
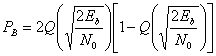 (4.80)
(4.80)
Это соотношение изображено на рис. 4.25. Отметим, что существует незначительное ухудшение достоверности обнаружения по сравнению с когерентным обнаружением сигналов в модуляции PSK. Это вызвано дифференциальным кодированием, поскольку любая отдельная ошибка обнаружения обычно приводит к принятию двух ошибочных решений. Подробно вероятность ошибки при использовании наиболее популярной схемы — когерентного обнаружения сигналов в модуляции DPSK — рассмотрена в разделе 4.7.5.
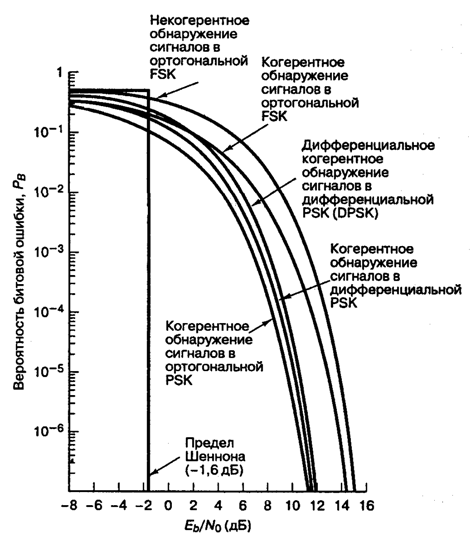
Рис. 4.25. Вероятность появления ошибочного бита для бинарных систем нескольких типов
4.7.3. Вероятность появления ошибочного бита при когерентном обнаружении сигнала в бинарной ортогональной модуляции FSK
Формулы (4.78) и (4.79) описывают вероятность появления ошибочного бита для когерентного обнаружения антиподных сигналов. Более общую трактовку для когерентного обнаружения бинарных сигналов (не ограничивающихся антиподными сигналами) дает следующее выражение для РВ [6].
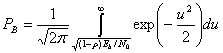 (4.81)
(4.81)
Из формулы (3.64,б) ![]() — временной коэффициент взаимной корреляций между
— временной коэффициент взаимной корреляций между ![]() и
и ![]() , где θ — угол между векторами сигналов
, где θ — угол между векторами сигналов ![]() и s2 (см. рис. 4.6). Для антиподных сигналов, таких как сигналы BPSK, θ = π, поэтому ρ = -1.
и s2 (см. рис. 4.6). Для антиподных сигналов, таких как сигналы BPSK, θ = π, поэтому ρ = -1.
Для ортогональных сигналов, таких как сигналы бинарной FSK (BFSK), θ = π/2, поскольку векторы ![]() и s2 перпендикулярны; следовательно, ρ = 0, что можно доказать с помощью формулы (3.64,а), поэтому выражение (4.81) можно переписать следующим образом.
и s2 перпендикулярны; следовательно, ρ = 0, что можно доказать с помощью формулы (3.64,а), поэтому выражение (4.81) можно переписать следующим образом.
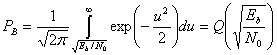 (4.82)
(4.82)
Здесь Q(x) — дополнительная функция ошибок, подробно описанная в разделах 3.2 и Б.3.2. Зависимость (4.82) для когерентного обнаружения ортогональных сигналов BFSK, показанная на рис. 4.25, аналогична зависимости, полученной для обнаружения ортогональных сигналов с помощью согласованного фильтра (формула (3.71)) и узкополосных ортогональных сигналов (униполярных импульсов) с использованием согласованного фильтра (формула (3.73)). В данной книге мы не рассматриваем амплитудную манипуляцию ООК (on-off keying), но соотношение (4.82 применимо к обнаружению с помощью согласованного фильтра сигналов ООК, так же как и к когерентному обнаружению любых ортогональных сигналов.
Справедливость соотношения (4.82) подтверждает и то, что разность энергий между ортогональными векторами сигналов ![]() и s2 с амплитудой
и s2 с амплитудой ![]() , как показано на рис. 3.10, б, равна квадрату расстояния между концами ортогональных векторов Ed = 2Eb. Подстановка этого результата в формулу (3.63) также дает формулу (4.82). Сравнивая формулы (4.82) и (4.79), видим, что, по сравнению со схемой BPSK, схема BFSK требует на 3 дБ большего отношения E/N0 для обеспечения аналогичной достоверности передачи. Этот результат не должен быть неожиданным, поскольку при данной мощности сигнала квадрат расстояния между ортогональными векторами вдвое (на 3 дБ) больше квадрата расстояния между антиподными векторами.
, как показано на рис. 3.10, б, равна квадрату расстояния между концами ортогональных векторов Ed = 2Eb. Подстановка этого результата в формулу (3.63) также дает формулу (4.82). Сравнивая формулы (4.82) и (4.79), видим, что, по сравнению со схемой BPSK, схема BFSK требует на 3 дБ большего отношения E/N0 для обеспечения аналогичной достоверности передачи. Этот результат не должен быть неожиданным, поскольку при данной мощности сигнала квадрат расстояния между ортогональными векторами вдвое (на 3 дБ) больше квадрата расстояния между антиподными векторами.
4.7.4. Вероятность появления ошибочного бита при некогерентном обнаружении сигнала в бинарной ортогональной модуляции FSK
Рассмотрим бинарное ортогональное множество равновероятных сигналов FSK ![]() , определенное формулой (4.8).
, определенное формулой (4.8).
![]()
Фаза φ неизвестна и предполагается постоянной. Детектор описывается М = 2 каналами, состоящими, как показано на рис. 4.19, из полосовых фильтров и детекторов огибающей. На вход детектора поступает принятый сигнал r(t) = si(t) + n(t), где n(i) — гауссов шум с двусторонней спектральной плотностью мощности No/2. Предположим, что ![]() и
и ![]() достаточно разнесены по частоте, чтобы их перекрытием можно было пренебречь. Вычисление вероятности появления ошибочного бита для равновероятных сигналов
достаточно разнесены по частоте, чтобы их перекрытием можно было пренебречь. Вычисление вероятности появления ошибочного бита для равновероятных сигналов ![]() и
и ![]() начнем, как и в случае узкополосной передачи, с уравнения (3.38).
начнем, как и в случае узкополосной передачи, с уравнения (3.38).
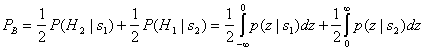 (4.83)
(4.83)
Для бинарного случая тестовая статистика z(T) определена как ![]() . Предположим, что полоса фильтра Wf равна 1/T, так что огибающая сигнала FSK (приблизительно) сохраняется на выходе фильтра. При отсутствии шума в приемнике значение z(T) равно
. Предположим, что полоса фильтра Wf равна 1/T, так что огибающая сигнала FSK (приблизительно) сохраняется на выходе фильтра. При отсутствии шума в приемнике значение z(T) равно ![]() при передаче s1(t) и —
при передаче s1(t) и —![]() — при передаче s2(t). Вследствие такой симметрии оптимальный порог γ0=0. Плотность вероятности
— при передаче s2(t). Вследствие такой симметрии оптимальный порог γ0=0. Плотность вероятности ![]() подобна плотности вероятности
подобна плотности вероятности ![]() .
.
![]() (4.84)
(4.84)
Таким образом, можем записать
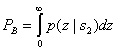 (4.85)
(4.85)
или
![]() (4.86)
(4.86)
где z1 и z2 обозначают выходы z1(T) и z2(T) детекторов огибающей, показанных на рис.4.19. При передаче тона ![]() , т.е. когда r(t) = s2(t) + n(t), выход z1(T) состоит исключительно из случайной переменной гауссового шума; он не содержит сигнального компонента. Распределение Гаусса в нелинейном детекторе огибающей дает распределение Релея на выходе [6], так что
, т.е. когда r(t) = s2(t) + n(t), выход z1(T) состоит исключительно из случайной переменной гауссового шума; он не содержит сигнального компонента. Распределение Гаусса в нелинейном детекторе огибающей дает распределение Релея на выходе [6], так что
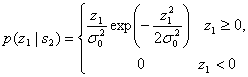 (4.87)
(4.87)
где ![]() — шум на выходе фильтра. С другой стороны, z2(T) имеет распределение Раиса, поскольку на вход нижнего детектора огибающей подается синусоида плюс шум [6]. Плотность вероятности p(z2s2) записывается как
— шум на выходе фильтра. С другой стороны, z2(T) имеет распределение Раиса, поскольку на вход нижнего детектора огибающей подается синусоида плюс шум [6]. Плотность вероятности p(z2s2) записывается как
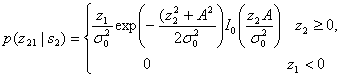 (4.88)
(4.88)
где ![]() и, как и ранее,
и, как и ранее, ![]() — шум на выходе фильтра. Функция 10(х), известная как модифицированная функция Бесселя первого рода нулевого порядка [7], определяется следующим образом.
— шум на выходе фильтра. Функция 10(х), известная как модифицированная функция Бесселя первого рода нулевого порядка [7], определяется следующим образом.
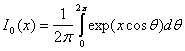 (4.89)
(4.89)
Ошибка при передаче s2(t) происходит, если выборка огибающей z1(T), полученная из верхнего канала (по которому проходит шум), больше выборки огибающей z2(T), полученной из нижнего канала (по которому проходит сигнал и шум). Таким образом, вероятность этой ошибки можно получить, проинтегрировав ![]() до бесконечности с последующим усреднением результата по всем возможным z2.
до бесконечности с последующим усреднением результата по всем возможным z2.
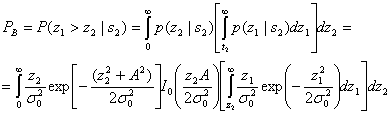 (4.91)
(4.91)
Здесь ![]() , внутренний интеграл — условная вероятность ошибки, при фиксированном значении z2, если был передан сигнал s2(1), а внешний интеграл усредняет условную вероятность по всем возможным значениям z2. Данный интеграл можно вычислить аналитически [8], и его значение равно следующему.
, внутренний интеграл — условная вероятность ошибки, при фиксированном значении z2, если был передан сигнал s2(1), а внешний интеграл усредняет условную вероятность по всем возможным значениям z2. Данный интеграл можно вычислить аналитически [8], и его значение равно следующему.
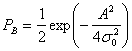 (4.92)
(4.92)
С помощью формулы (1.19) шум на выходе фильтра можно выразить как
![]() (4.93)
(4.93)
где ![]() a Wf — ширина полосы фильтра. Таким образом, формула (4.92) приобретает следующий вид.
a Wf — ширина полосы фильтра. Таким образом, формула (4.92) приобретает следующий вид.
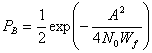 (4.94)
(4.94)
Выражение (4.94) показывает, что вероятность ошибки зависит от ширины полосы полосового фильтра и РB уменьшается при снижении Wf. Результат справедлив только при пренебрежении межсимвольной интерференцией (intersymbol interference — ISI). Минимальная разрешенная Wf (т.е. не дающая межсимвольной интерференции) получается из уравнения (3.81) при коэффициенте сглаживания г = 0. Следовательно, Wf= R бит/с =1/T, и выражение (4.94) можно переписать следующим образом.
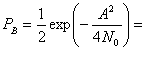 (4.95)
(4.95)
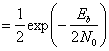 (4.96)
(4.96)
Здесь Еь= (1/2)А2Т — энергия одного бита. Если сравнить вероятность ошибки схем некогерентной и когерентной FSK (см. рис. 4.25), можно заметить, что при равных РB некогерентная FSK требует приблизительно на 1 дБ большего отношения Eb/N0, чем когерентная FSK (для РB < 10-4). При этом некогерентный приемник легче реализуется, поскольку не требуется генерировать когерентные опорные сигналы. По этой причине практически все приемники FSK используют некогерентное обнаружение. В следующем разделе будет показано, что при сравнении когерентной ортогональной схемы FSK с нёкогерентной схемой DPSK имеет место та же разница в 3 дБ, что и при сравнении когерентной ортогональной FSK и когерентной PSK. Как указывалось ранее, в данной книге не рассматривается амплитудная манипуляция ООК (on-off keying). Все же отметим, что вероятность появления ошибочного бита РB, выраженная в формуле (4.96), идентична РB для некогерентного обнаружения сигналов ООК.
4.7.5. Вероятность появления ошибочного бита для бинарной модуляции DPSK
Определим набор сигналов BPSK следующим образом.
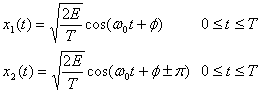 (4.97)
(4.97)
Особенностью схемы DPSK является отсутствие в сигнальном пространстве четко определенных областей решений. В данном случае решение основывается на разности фаз между принятыми сигналами. Таким образом, при передаче сигналов DPSK каждый бит в действительности передается парой двоичных сигналов.
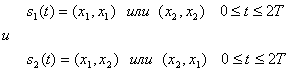 (4.98)
(4.98)
Здесь ![]() обозначает сигнал
обозначает сигнал ![]() , за которым следует сигнал
, за которым следует сигнал ![]() . Первые Т секунд каждого сигнала — это в действительности последние Т секунд предыдущего. Отметим, что оба сигнала s1(t) и s2(t) могут принимать любую из возможных форм и что
. Первые Т секунд каждого сигнала — это в действительности последние Т секунд предыдущего. Отметим, что оба сигнала s1(t) и s2(t) могут принимать любую из возможных форм и что ![]() и
и ![]() — это антиподные сигналы. Таким образом, корреляцию между
— это антиподные сигналы. Таким образом, корреляцию между ![]() и s2(t) для любой комбинации сигналов можно записать следующим образом.
и s2(t) для любой комбинации сигналов можно записать следующим образом.
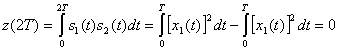 (4.99)
(4.99)
Следовательно, каждую пару сигналов DPSK можно представить как ортогональный сигнал длительностью 2Т секунд. Обнаружение может соответствовать некогерентному обнаружению огибающей с помощью четырех каналов, согласованных с каждым возможным выходом огибающей, как показано на рис. 4.26. Поскольку два детектора огибающей, представляющих каждый символ, обратны друг другу, выборки их огибающих будут совпадать. Значит, мы можем реализовать детектор как один канал для ![]() , согласовывающегося с
, согласовывающегося с ![]() или
или ![]() , и один канал для
, и один канал для ![]() , согласовывающегося с
, согласовывающегося с ![]() или
или ![]() , как показано на рис. 4.26. Следовательно, детектор DPSK сокращается до стандартного двухканального некогерентного детектора. В действительности фильтр может согласовываться с разностным сигналом; так что необходимым является всего один канал. На рис. 4.26 показаны фильтры, которые согласовываются с огибающими сигнала (в течение двух периодов передачи символа). Что это означает, если вспомнить, что DPSK — это схема передачи сигналов с постоянной огибающей? Это означает, что нам требуется реализовать детектор энергии, подобный квадратурному приемнику на рис. 4.18, где каждый сигнал в течение периода
, как показано на рис. 4.26. Следовательно, детектор DPSK сокращается до стандартного двухканального некогерентного детектора. В действительности фильтр может согласовываться с разностным сигналом; так что необходимым является всего один канал. На рис. 4.26 показаны фильтры, которые согласовываются с огибающими сигнала (в течение двух периодов передачи символа). Что это означает, если вспомнить, что DPSK — это схема передачи сигналов с постоянной огибающей? Это означает, что нам требуется реализовать детектор энергии, подобный квадратурному приемнику на рис. 4.18, где каждый сигнал в течение периода ![]() представляется синфазным и квадратурным опорными сигналами.
представляется синфазным и квадратурным опорными сигналами.
синфазный опорный сигнал ![]() квадратурный опорный сигнал
квадратурный опорный сигнал ![]() синфазный опорный сигнал
синфазный опорный сигнал ![]() квадратурный опорный сигнал
квадратурный опорный сигнал ![]()
Поскольку пары сигналов DPSK ортогональны, вероятность ошибки при подобном некогерентном обнаружении дается выражением (4.96). Впрочем, поскольку сигналы DPSK длятся 2Т секунд, энергия сигналов ![]() , определенных в формуле (4.98), равна удвоенной энергии сигнала, определенного в течение одного периода передачи символа.
, определенных в формуле (4.98), равна удвоенной энергии сигнала, определенного в течение одного периода передачи символа.
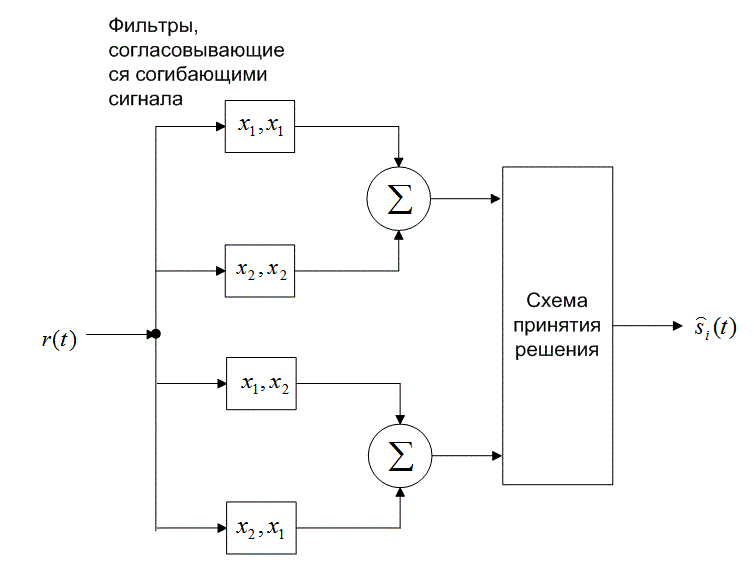
а)
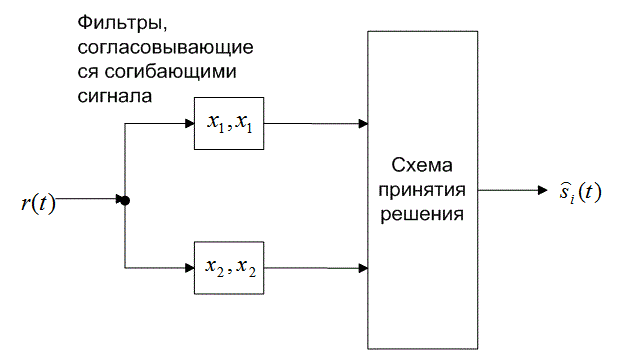
б)
Рис. 4.26. Обнаружение в схеме DPSK: а) четырехканальное дифференциально-когерентное обнаружение сигналов в бинарной модуляции DPSK; б) эквивалентный двухканальный детектор сигналов в бинарной модуляции DPSK
Таким образом, РВможно записать в следующем виде.
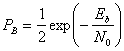 (4.100)
(4.100)
Зависимость (4.100), изображенная на рис. 4.25, представляет собой дифференциальное когерентное обнаружение сигналов в дифференциальной модуляции PSK, или просто DPSK. Выражение справедливо для оптимального детектора DPSK (рис. 4.17, в). Для детектора, показанного на рис. 4.17, б, вероятность ошибки будет несколько выше приведенной в выражении (4.100) [3]. Если сравнить вероятность ошибки, приведенную в формуле (4.100), с вероятностью ошибки когерентной схемы PSK (см. рис. 4.25), видно, что при равных РB схема DPSK требует приблизительно на 1 дБ большего отношения E^N0, чем схема BPSK (для ![]() ). Систему DPSK реализовать легче, чем систему PSK, поскольку приемник DPSK не требует фазовой синхронизации. По этой причине иногда предпочтительнее использовать менее эффективную схему DPSK, чем более сложную схему PSK.
). Систему DPSK реализовать легче, чем систему PSK, поскольку приемник DPSK не требует фазовой синхронизации. По этой причине иногда предпочтительнее использовать менее эффективную схему DPSK, чем более сложную схему PSK.
4.7.6. Вероятность ошибки для различных модуляций
В табл. 4.1 и на рис. 4.25 приведены аналитические выражения и графики РB для наиболее распространенных схем модуляции, описанных выше. Для РB = 10-4 можно видеть, что разница между лучшей (когерентной PSK) и худшей (некогерентной ортогональной FSK) из рассмотренных схем равна приблизительно 4 дБ. В некоторых случаях 4 дБ — это небольшая цена за простоту реализации, увеличивающуюся от когерентной схемы PSK до некогерентной FSK (рис. 4.25); впрочем, в других случаях ценным является даже выигрыш в 1 дБ. Помимо сложности реализации и вероятности РB существуют и другие факторы, влияющие на выбор модуляции; например, в некоторых случаях (в каналах со случайным затуханием) желательными являются некогерентные системы, поскольку иногда когерентные опорные сигналы затруднительно определять и использовать. В военных и космических приложениях весьма желательны сигналы, которые могут противостоять значительному ухудшению качества, сохраняя возможность обнаружения.
Таблица 4.1. Вероятность ошибки для различных бинарных модуляций
|
Модуляция |
PB |
|
PSK (когерентное обнаружение) |
|
|
DPSK (дифференциальное когерентное обнаружение) |
|
|
Ортогональная FSK (когерентное обнаружение) |
|
|
Ортогональная FSK (некогерентное обнаружение) |
|