Ошибки I и II рода при проверке гипотез, мощность
Общий обзор
Принятие неправильного решения
Мощность и связанные факторы
Проверка множественных гипотез
Общий обзор
Большинство проверяемых гипотез сравнивают между собой группы объектов, которые испытывают влияние различных факторов.
Например, можно сравнить эффективность двух видов лечения, чтобы сократить 5-летнюю смертность от рака молочной железы. Для данного исхода (например, смерть) сравнение, представляющее интерес (например, различные показатели смертности через 5 лет), называют эффектом или, если уместно, эффектом лечения.
Нулевую гипотезу выражают как отсутствие эффекта (например 5-летняя смертность от рака молочной железы одинаковая в двух группах, получающих разное лечение); двусторонняя альтернативная гипотеза будет означать, что различие эффектов не равно нулю.
Критериальная проверка гипотезы дает возможность определить, достаточно ли аргументов, чтобы отвергнуть нулевую гипотезу. Можно принять только одно из двух решений:
- отвергнуть нулевую гипотезу и принять альтернативную гипотезу
- остаться в рамках нулевой гипотезы
Важно: В литературе достаточно часто встречается понятие «принять нулевую гипотезу». Хотелось бы внести ясность, что со статистической точки зрения принять нулевую гипотезу невозможно, т.к. нулевая гипотеза представляет собой достаточно строгое утверждение (например, средние значения в сравниваемых группах равны ![]() ).
).
Поэтому фразу о принятии нулевой гипотезы следует понимать как то, что мы просто остаемся в рамках гипотезы.
Принятие неправильного решения
Возможно неправильное решение, когда отвергают/не отвергают нулевую гипотезу, потому что есть только выборочная информация.
| |
Верная гипотеза | ||
|---|---|---|---|
| H0 | H1 | ||
| Результат применения критерия |
H0 | H0 верно принята | H0 неверно принята (Ошибка второго рода) |
| H1 | H0 неверно отвергнута (Ошибка первого рода) |
H0 верно отвергнута |
Ошибка 1-го рода: нулевую гипотезу отвергают, когда она истинна, и делают вывод, что имеется эффект, когда в действительности его нет. Максимальный шанс (вероятность) допустить ошибку 1-го рода обозначается α (альфа). Это уровень значимости критерия; нулевую гипотезу отвергают, если наше значение p ниже уровня значимости, т. е., если p < α.
Следует принять решение относительно значения а прежде, чем будут собраны данные; обычно назначают условное значение 0,05, хотя можно выбрать более ограничивающее значение, например 0,01.
Шанс допустить ошибку 1-го рода никогда не превысит выбранного уровня значимости, скажем α = 0,05, так как нулевую гипотезу отвергают только тогда, когда p< 0,05. Если обнаружено, что p > 0,05, то нулевую гипотезу не отвергнут и, следовательно, не допустят ошибки 1-го рода.
Ошибка 2-го рода: не отвергают нулевую гипотезу, когда она ложна, и делают вывод, что нет эффекта, тогда как в действительности он существует. Шанс возникновения ошибки 2-го рода обозначается β (бета); а величина (1-β) называется мощностью критерия.
Следовательно, мощность — это вероятность отклонения нулевой гипотезы, когда она ложна, т.е. это шанс (обычно выраженный в процентах) обнаружить реальный эффект лечения в выборке данного объема как статистически значимый.
В идеале хотелось бы, чтобы мощность критерия составляла 100%; однако это невозможно, так как всегда остается шанс, хотя и незначительный, допустить ошибку 2-го рода.
К счастью, известно, какие факторы влияют на мощность и, таким образом, можно контролировать мощность критерия, рассматривая их.
Мощность и связанные факторы
Планируя исследование, необходимо знать мощность предложенного критерия. Очевидно, можно начинать исследование, если есть «хороший» шанс обнаружить уместный эффект, если таковой существует (под «хорошим» мы подразумеваем, что мощность должна быть по крайней мере 70-80%).
Этически безответственно начинать исследование, у которого, скажем, только 40% вероятности обнаружить реальный эффект лечения; это бесполезная трата времени и денежных средств.
Ряд факторов имеют прямое отношение к мощности критерия.
Объем выборки: мощность критерия увеличивается по мере увеличения объема выборки. Это означает, что у большей выборки больше возможностей, чем у незначительной, обнаружить важный эффект, если он существует.
Когда объем выборки небольшой, у критерия может быть недостаточно мощности, чтобы обнаружить отдельный эффект. Эти методы также можно использовать для оценки мощности критерия для точно установленного объема выборки.
Вариабельность наблюдений: мощность увеличивается по мере того, как вариабельность наблюдений уменьшается.
Интересующий исследователя эффект: мощность критерия больше для более высоких эффектов. Критерий проверки гипотез имеет больше шансов обнаружить значительный реальный эффект, чем незначительный.
Уровень значимости: мощность будет больше, если уровень значимости выше (это эквивалентно увеличению допущения ошибки 1-го рода, α, а допущение ошибки 2-го рода, β, уменьшается).
Таким образом, вероятнее всего, исследователь обнаружит реальный эффект, если на стадии планирования решит, что будет рассматривать значение р как значимое, если оно скорее будет меньше 0,05, чем меньше 0,01.
Обратите внимание, что проверка ДИ для интересующего эффекта указывает на то, была ли мощность адекватной. Большой доверительный интервал следует из небольшой выборки и/или набора данных с существенной вариабельностью и указывает на недостаточную мощность.
Проверка множественных гипотез
Часто нужно выполнить критериальную проверку значимости множественных гипотез на наборе данных с многими переменными или существует более двух видов лечения.
Ошибка 1-го рода драматически увеличивается по мере увеличения числа сравнений, что приводит к ложным выводам относительно гипотез. Следовательно, следует проверить только небольшое число гипотез, выбранных для достижения первоначальной цели исследования и точно установленных априорно.
Можно использовать какую-нибудь форму апостериорного уточнения значения р, принимая во внимание число выполненных проверок гипотез.
Например, при подходе Бонферрони (его часто считают довольно консервативным) умножают каждое значение р на число выполненных проверок; тогда любые решения относительно значимости будут основываться на этом уточненном значении р.
Связанные определения:
p-уровень
Альтернативная гипотеза, альтернатива
Альфа-уровень
Бета-уровень
Гипотеза
Двусторонний критерий
Критерий для проверки гипотезы
Критическая область проверки гипотезы
Мощность
Мощность исследования
Мощность статистического критерия
Нулевая гипотеза
Односторонний критерий
Ошибка I рода
Ошибка II рода
Статистика критерия
Эквивалентные статистические критерии
В начало
Содержание портала
При
проверке гипотезы экспериментальные
данные могут противоречить
гипотезе
![]() ,
,
тогда эта гипотезаотклоняется.
В
противном случае, если экспериментальные
данные согласуются
с
гипотезой
![]() ,
,
то онане
отклоняется.
Значит,
статистическая проверка гипотез,
основанная на экспериментальных данных,
неизбежно связанно с риском
принять ложное решение.
Тогда
в терминах правильности или ошибочности
принятия H0
и
![]() можно
можно
указать четыре потенциально возможных
результата применения критерия к
выборке. При
этом возможны ошибки двух родов.
Ошибкой первого
рода
называется
ошибка отклонения правильной гипотезы.
Вероятность
ошибки первого рода равна
уровню значимости,
т.е.
![]() .
.
Эта
формула означает, что гипотеза
![]() отклоняется с вероятностью
отклоняется с вероятностью![]() ,
,
хотя эта гипотеза верна. Название
«уровень значимости» в терминах «сходства
и различия» — это вероятность того, что
мы сочли различия существенными (приняли![]() ),
),
а они на самом деле случайны (верна
гипотеза![]() ).
).
Для того чтобы
проверяемая гипотеза была достаточно
обоснованно отвергнута, уровень
значимости выбирают достаточно малым,
в практике: 0,01; 0,001.
Ошибкой второго
рода
называется ошибка принятия неверной
гипотезы. Вероятность
ошибки второго рода обозначается
![]() :
:
![]() .
.
Эта
формула означает, что гипотеза
![]() принимается с вероятностью
принимается с вероятностью![]() ,
,
хотя верна альтернативная гипотеза![]() .
.
Чем
меньше уровень значимости, тем меньше
вероятность забраковать верную гипотезу,
т.е. совершить ошибку первого рода, но
при этом увеличивается вероятность
принятия неверной гипотезы, т.е. совершения
ошибки второго рода.
|
Принята гипотеза |
|||
|
H0 |
H1 |
||
|
Верна гипотеза |
H0 |
|
|
|
H1 |
|
|
Возможны
два
статистических правильных решения
по выборочным данным:
1) Принять верную гипотезу . Вероятность этого решения называетсяуровнем доверия;
2)
принять
верную гипотезу
![]() .
.
Вероятность![]() такого решения называетсямощностью
такого решения называетсямощностью
критерия.
Мощность критерия в терминах
«сходство-различие» — это его способность
выявлять различия, если они есть.
4.
Односторонний и двусторонний критерии
По
виду альтернативной (конкурирующей)
гипотезы
![]() определяется вид критической области,
определяется вид критической области,
в которой результаты выборочного
наблюдения выглядят менее правдоподобными
в отношении нулевой гипотезы![]() .
.
Если
конкурирующая гипотеза имеет вид
![]() :
:![]() ,
,
то критическая область![]() — правосторонняя и соответствующийкритерий
— правосторонняя и соответствующийкритерий
называется правосторонним,
а в случае
![]() :
:![]() —критерий
—критерий
называется левосторонним.

Область
допустимых
Правосторонняя
значений
критическая
область
(принятия
гипотезы
![]() )
)
(отклонения![]() и принятия
и принятия![]() )
)
![]()
![]()
Если конкурирующая гипотеза имеет вид
![]() :
:![]() ,
,
т.е.![]() ,
,
то критическая область![]() является объединением полубесконечных
является объединением полубесконечных
промежутков: — двусторонняя.

Область
Критическая допустимых
Критическая
область значений область
![]()
![]()
![]()
Важное замечание.В психологии часто
эмпирическое значение![]() сравнивается одновременно с двумя
сравнивается одновременно с двумя
критическими![]() (0,05)
(0,05)
и![]() (0,01),
(0,01),
которые соответствуют уровням значимости
в 5% и 1% и находятся по соответствующим
таблицам. Все три числа![]() ,
,![]() (0,05),
(0,05),![]() (0,01)
(0,01)
располагают на «оси значимости». Число![]() может попасть в одну из трех областей:
может попасть в одну из трех областей:
незначимости различий, значимости
различий, неопределенности.

Область Область
Область
незначимости неопределенности
значимости
различий различий
![]()
![]() К
К
![]()
![]()
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
This article is about erroneous outcomes of statistical tests. For closely related concepts in binary classification and testing generally, see false positives and false negatives.
In statistical hypothesis testing, a type I error is the mistaken rejection of an actually true null hypothesis (also known as a «false positive» finding or conclusion; example: «an innocent person is convicted»), while a type II error is the failure to reject a null hypothesis that is actually false (also known as a «false negative» finding or conclusion; example: «a guilty person is not convicted»).[1] Much of statistical theory revolves around the minimization of one or both of these errors, though the complete elimination of either is a statistical impossibility if the outcome is not determined by a known, observable causal process.
By selecting a low threshold (cut-off) value and modifying the alpha (α) level, the quality of the hypothesis test can be increased.[2] The knowledge of type I errors and type II errors is widely used in medical science, biometrics and computer science.[clarification needed]
Intuitively, type I errors can be thought of as errors of commission, i.e. the researcher unluckily concludes that something is the fact. For instance, consider a study where researchers compare a drug with a placebo. If the patients who are given the drug get better than the patients given the placebo by chance, it may appear that the drug is effective, but in fact the conclusion is incorrect.
In reverse, type II errors are errors of omission. In the example above, if the patients who got the drug did not get better at a higher rate than the ones who got the placebo, but this was a random fluke, that would be a type II error. The consequence of a type II error depends on the size and direction of the missed determination and the circumstances. An expensive cure for one in a million patients may be inconsequential even if it truly is a cure.
Definition[edit]
Statistical background[edit]
In statistical test theory, the notion of a statistical error is an integral part of hypothesis testing. The test goes about choosing about two competing propositions called null hypothesis, denoted by H0 and alternative hypothesis, denoted by H1. This is conceptually similar to the judgement in a court trial. The null hypothesis corresponds to the position of the defendant: just as he is presumed to be innocent until proven guilty, so is the null hypothesis presumed to be true until the data provide convincing evidence against it. The alternative hypothesis corresponds to the position against the defendant. Specifically, the null hypothesis also involves the absence of a difference or the absence of an association. Thus, the null hypothesis can never be that there is a difference or an association.
If the result of the test corresponds with reality, then a correct decision has been made. However, if the result of the test does not correspond with reality, then an error has occurred. There are two situations in which the decision is wrong. The null hypothesis may be true, whereas we reject H0. On the other hand, the alternative hypothesis H1 may be true, whereas we do not reject H0. Two types of error are distinguished: type I error and type II error.[3]
Type I error[edit]
The first kind of error is the mistaken rejection of a null hypothesis as the result of a test procedure. This kind of error is called a type I error (false positive) and is sometimes called an error of the first kind. In terms of the courtroom example, a type I error corresponds to convicting an innocent defendant.
Type II error[edit]
The second kind of error is the mistaken failure to reject the null hypothesis as the result of a test procedure. This sort of error is called a type II error (false negative) and is also referred to as an error of the second kind. In terms of the courtroom example, a type II error corresponds to acquitting a criminal.[4]
Crossover error rate[edit]
The crossover error rate (CER) is the point at which type I errors and type II errors are equal. A system with a lower CER value provides more accuracy than a system with a higher CER value.
False positive and false negative[edit]
In terms of false positives and false negatives, a positive result corresponds to rejecting the null hypothesis, while a negative result corresponds to failing to reject the null hypothesis; «false» means the conclusion drawn is incorrect. Thus, a type I error is equivalent to a false positive, and a type II error is equivalent to a false negative.
Table of error types[edit]
Tabularised relations between truth/falseness of the null hypothesis and outcomes of the test:[5]
| Table of error types | Null hypothesis (H0) is |
||
|---|---|---|---|
| True | False | ||
| Decision about null hypothesis (H0) |
Don’t reject |
Correct inference (true negative) (probability = 1−α) |
Type II error (false negative) (probability = β) |
| Reject | Type I error (false positive) (probability = α) |
Correct inference (true positive) (probability = 1−β) |
Error rate[edit]

The results obtained from negative sample (left curve) overlap with the results obtained from positive samples (right curve). By moving the result cutoff value (vertical bar), the rate of false positives (FP) can be decreased, at the cost of raising the number of false negatives (FN), or vice versa (TP = True Positives, TPR = True Positive Rate, FPR = False Positive Rate, TN = True Negatives).
A perfect test would have zero false positives and zero false negatives. However, statistical methods are probabilistic, and it cannot be known for certain whether statistical conclusions are correct. Whenever there is uncertainty, there is the possibility of making an error. Considering this nature of statistics science, all statistical hypothesis tests have a probability of making type I and type II errors.[6]
- The type I error rate is the probability of rejecting the null hypothesis given that it is true. The test is designed to keep the type I error rate below a prespecified bound called the significance level, usually denoted by the Greek letter α (alpha) and is also called the alpha level. Usually, the significance level is set to 0.05 (5%), implying that it is acceptable to have a 5% probability of incorrectly rejecting the true null hypothesis.[7]
- The rate of the type II error is denoted by the Greek letter β (beta) and related to the power of a test, which equals 1−β.[8]
These two types of error rates are traded off against each other: for any given sample set, the effort to reduce one type of error generally results in increasing the other type of error.[9]
The quality of hypothesis test[edit]
The same idea can be expressed in terms of the rate of correct results and therefore used to minimize error rates and improve the quality of hypothesis test. To reduce the probability of committing a type I error, making the alpha value more stringent is quite simple and efficient. To decrease the probability of committing a type II error, which is closely associated with analyses’ power, either increasing the test’s sample size or relaxing the alpha level could increase the analyses’ power.[10] A test statistic is robust if the type I error rate is controlled.
Varying different threshold (cut-off) value could also be used to make the test either more specific or more sensitive, which in turn elevates the test quality. For example, imagine a medical test, in which an experimenter might measure the concentration of a certain protein in the blood sample. The experimenter could adjust the threshold (black vertical line in the figure) and people would be diagnosed as having diseases if any number is detected above this certain threshold. According to the image, changing the threshold would result in changes in false positives and false negatives, corresponding to movement on the curve.[11]
Example[edit]
Since in a real experiment it is impossible to avoid all type I and type II errors, it is important to consider the amount of risk one is willing to take to falsely reject H0 or accept H0. The solution to this question would be to report the p-value or significance level α of the statistic. For example, if the p-value of a test statistic result is estimated at 0.0596, then there is a probability of 5.96% that we falsely reject H0. Or, if we say, the statistic is performed at level α, like 0.05, then we allow to falsely reject H0 at 5%. A significance level α of 0.05 is relatively common, but there is no general rule that fits all scenarios.
Vehicle speed measuring[edit]
The speed limit of a freeway in the United States is 120 kilometers per hour. A device is set to measure the speed of passing vehicles. Suppose that the device will conduct three measurements of the speed of a passing vehicle, recording as a random sample X1, X2, X3. The traffic police will or will not fine the drivers depending on the average speed  . That is to say, the test statistic
. That is to say, the test statistic

In addition, we suppose that the measurements X1, X2, X3 are modeled as normal distribution N(μ,4). Then, T should follow N(μ,4/3) and the parameter μ represents the true speed of passing vehicle. In this experiment, the null hypothesis H0 and the alternative hypothesis H1 should be
H0: μ=120 against H1: μ>120.
If we perform the statistic level at α=0.05, then a critical value c should be calculated to solve

According to change-of-units rule for the normal distribution. Referring to Z-table, we can get

Here, the critical region. That is to say, if the recorded speed of a vehicle is greater than critical value 121.9, the driver will be fined. However, there are still 5% of the drivers are falsely fined since the recorded average speed is greater than 121.9 but the true speed does not pass 120, which we say, a type I error.
The type II error corresponds to the case that the true speed of a vehicle is over 120 kilometers per hour but the driver is not fined. For example, if the true speed of a vehicle μ=125, the probability that the driver is not fined can be calculated as

which means, if the true speed of a vehicle is 125, the driver has the probability of 0.36% to avoid the fine when the statistic is performed at level 125 since the recorded average speed is lower than 121.9. If the true speed is closer to 121.9 than 125, then the probability of avoiding the fine will also be higher.
The tradeoffs between type I error and type II error should also be considered. That is, in this case, if the traffic police do not want to falsely fine innocent drivers, the level α can be set to a smaller value, like 0.01. However, if that is the case, more drivers whose true speed is over 120 kilometers per hour, like 125, would be more likely to avoid the fine.
Etymology[edit]
In 1928, Jerzy Neyman (1894–1981) and Egon Pearson (1895–1980), both eminent statisticians, discussed the problems associated with «deciding whether or not a particular sample may be judged as likely to have been randomly drawn from a certain population»:[12] and, as Florence Nightingale David remarked, «it is necessary to remember the adjective ‘random’ [in the term ‘random sample’] should apply to the method of drawing the sample and not to the sample itself».[13]
They identified «two sources of error», namely:
- (a) the error of rejecting a hypothesis that should have not been rejected, and
- (b) the error of failing to reject a hypothesis that should have been rejected.
In 1930, they elaborated on these two sources of error, remarking that:
…in testing hypotheses two considerations must be kept in view, we must be able to reduce the chance of rejecting a true hypothesis to as low a value as desired; the test must be so devised that it will reject the hypothesis tested when it is likely to be false.
In 1933, they observed that these «problems are rarely presented in such a form that we can discriminate with certainty between the true and false hypothesis» . They also noted that, in deciding whether to fail to reject, or reject a particular hypothesis amongst a «set of alternative hypotheses», H1, H2…, it was easy to make an error:
…[and] these errors will be of two kinds:
- (I) we reject H0 [i.e., the hypothesis to be tested] when it is true,[14]
- (II) we fail to reject H0 when some alternative hypothesis HA or H1 is true. (There are various notations for the alternative).
In all of the papers co-written by Neyman and Pearson the expression H0 always signifies «the hypothesis to be tested».
In the same paper they call these two sources of error, errors of type I and errors of type II respectively.[15]
[edit]
Null hypothesis[edit]
It is standard practice for statisticians to conduct tests in order to determine whether or not a «speculative hypothesis» concerning the observed phenomena of the world (or its inhabitants) can be supported. The results of such testing determine whether a particular set of results agrees reasonably (or does not agree) with the speculated hypothesis.
On the basis that it is always assumed, by statistical convention, that the speculated hypothesis is wrong, and the so-called «null hypothesis» that the observed phenomena simply occur by chance (and that, as a consequence, the speculated agent has no effect) – the test will determine whether this hypothesis is right or wrong. This is why the hypothesis under test is often called the null hypothesis (most likely, coined by Fisher (1935, p. 19)), because it is this hypothesis that is to be either nullified or not nullified by the test. When the null hypothesis is nullified, it is possible to conclude that data support the «alternative hypothesis» (which is the original speculated one).
The consistent application by statisticians of Neyman and Pearson’s convention of representing «the hypothesis to be tested» (or «the hypothesis to be nullified») with the expression H0 has led to circumstances where many understand the term «the null hypothesis» as meaning «the nil hypothesis» – a statement that the results in question have arisen through chance. This is not necessarily the case – the key restriction, as per Fisher (1966), is that «the null hypothesis must be exact, that is free from vagueness and ambiguity, because it must supply the basis of the ‘problem of distribution,’ of which the test of significance is the solution.»[16] As a consequence of this, in experimental science the null hypothesis is generally a statement that a particular treatment has no effect; in observational science, it is that there is no difference between the value of a particular measured variable, and that of an experimental prediction.[citation needed]
Statistical significance[edit]
If the probability of obtaining a result as extreme as the one obtained, supposing that the null hypothesis were true, is lower than a pre-specified cut-off probability (for example, 5%), then the result is said to be statistically significant and the null hypothesis is rejected.
British statistician Sir Ronald Aylmer Fisher (1890–1962) stressed that the «null hypothesis»:
… is never proved or established, but is possibly disproved, in the course of experimentation. Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis.
— Fisher, 1935, p.19
Application domains[edit]
Medicine[edit]
In the practice of medicine, the differences between the applications of screening and testing are considerable.
Medical screening[edit]
Screening involves relatively cheap tests that are given to large populations, none of whom manifest any clinical indication of disease (e.g., Pap smears).
Testing involves far more expensive, often invasive, procedures that are given only to those who manifest some clinical indication of disease, and are most often applied to confirm a suspected diagnosis.
For example, most states in the USA require newborns to be screened for phenylketonuria and hypothyroidism, among other congenital disorders.
Hypothesis: «The newborns have phenylketonuria and hypothyroidism»
Null Hypothesis (H0): «The newborns do not have phenylketonuria and hypothyroidism»,
Type I error (false positive): The true fact is that the newborns do not have phenylketonuria and hypothyroidism but we consider they have the disorders according to the data.
Type II error (false negative): The true fact is that the newborns have phenylketonuria and hypothyroidism but we consider they do not have the disorders according to the data.
Although they display a high rate of false positives, the screening tests are considered valuable because they greatly increase the likelihood of detecting these disorders at a far earlier stage.
The simple blood tests used to screen possible blood donors for HIV and hepatitis have a significant rate of false positives; however, physicians use much more expensive and far more precise tests to determine whether a person is actually infected with either of these viruses.
Perhaps the most widely discussed false positives in medical screening come from the breast cancer screening procedure mammography. The US rate of false positive mammograms is up to 15%, the highest in world. One consequence of the high false positive rate in the US is that, in any 10-year period, half of the American women screened receive a false positive mammogram. False positive mammograms are costly, with over $100 million spent annually in the U.S. on follow-up testing and treatment. They also cause women unneeded anxiety. As a result of the high false positive rate in the US, as many as 90–95% of women who get a positive mammogram do not have the condition. The lowest rate in the world is in the Netherlands, 1%. The lowest rates are generally in Northern Europe where mammography films are read twice and a high threshold for additional testing is set (the high threshold decreases the power of the test).
The ideal population screening test would be cheap, easy to administer, and produce zero false-negatives, if possible. Such tests usually produce more false-positives, which can subsequently be sorted out by more sophisticated (and expensive) testing.
Medical testing[edit]
False negatives and false positives are significant issues in medical testing.
Hypothesis: «The patients have the specific disease».
Null hypothesis (H0): «The patients do not have the specific disease».
Type I error (false positive): «The true fact is that the patients do not have a specific disease but the physicians judges the patients was ill according to the test reports».
False positives can also produce serious and counter-intuitive problems when the condition being searched for is rare, as in screening. If a test has a false positive rate of one in ten thousand, but only one in a million samples (or people) is a true positive, most of the positives detected by that test will be false. The probability that an observed positive result is a false positive may be calculated using Bayes’ theorem.
Type II error (false negative): «The true fact is that the disease is actually present but the test reports provide a falsely reassuring message to patients and physicians that the disease is absent».
False negatives produce serious and counter-intuitive problems, especially when the condition being searched for is common. If a test with a false negative rate of only 10% is used to test a population with a true occurrence rate of 70%, many of the negatives detected by the test will be false.
This sometimes leads to inappropriate or inadequate treatment of both the patient and their disease. A common example is relying on cardiac stress tests to detect coronary atherosclerosis, even though cardiac stress tests are known to only detect limitations of coronary artery blood flow due to advanced stenosis.
Biometrics[edit]
Biometric matching, such as for fingerprint recognition, facial recognition or iris recognition, is susceptible to type I and type II errors.
Hypothesis: «The input does not identify someone in the searched list of people»
Null hypothesis: «The input does identify someone in the searched list of people»
Type I error (false reject rate): «The true fact is that the person is someone in the searched list but the system concludes that the person is not according to the data».
Type II error (false match rate): «The true fact is that the person is not someone in the searched list but the system concludes that the person is someone whom we are looking for according to the data».
The probability of type I errors is called the «false reject rate» (FRR) or false non-match rate (FNMR), while the probability of type II errors is called the «false accept rate» (FAR) or false match rate (FMR).
If the system is designed to rarely match suspects then the probability of type II errors can be called the «false alarm rate». On the other hand, if the system is used for validation (and acceptance is the norm) then the FAR is a measure of system security, while the FRR measures user inconvenience level.
Security screening[edit]
False positives are routinely found every day in airport security screening, which are ultimately visual inspection systems. The installed security alarms are intended to prevent weapons being brought onto aircraft; yet they are often set to such high sensitivity that they alarm many times a day for minor items, such as keys, belt buckles, loose change, mobile phones, and tacks in shoes.
Here, the null hypothesis is that the item is not a weapon, while the alternative hypothesis is that the item is a weapon.
A type I error (false positive): «The true fact is that the item is not a weapon but the system still alarms».
Type II error (false negative) «The true fact is that the item is a weapon but the system keeps silent at this time».
The ratio of false positives (identifying an innocent traveler as a terrorist) to true positives (detecting a would-be terrorist) is, therefore, very high; and because almost every alarm is a false positive, the positive predictive value of these screening tests is very low.
The relative cost of false results determines the likelihood that test creators allow these events to occur. As the cost of a false negative in this scenario is extremely high (not detecting a bomb being brought onto a plane could result in hundreds of deaths) whilst the cost of a false positive is relatively low (a reasonably simple further inspection) the most appropriate test is one with a low statistical specificity but high statistical sensitivity (one that allows a high rate of false positives in return for minimal false negatives).
Computers[edit]
The notions of false positives and false negatives have a wide currency in the realm of computers and computer applications, including computer security, spam filtering, Malware, Optical character recognition and many others.
For example, in the case of spam filtering the hypothesis here is that the message is a spam.
Thus, null hypothesis: «The message is not a spam».
Type I error (false positive): «Spam filtering or spam blocking techniques wrongly classify a legitimate email message as spam and, as a result, interferes with its delivery».
While most anti-spam tactics can block or filter a high percentage of unwanted emails, doing so without creating significant false-positive results is a much more demanding task.
Type II error (false negative): «Spam email is not detected as spam, but is classified as non-spam». A low number of false negatives is an indicator of the efficiency of spam filtering.
See also[edit]
- Binary classification
- Detection theory
- Egon Pearson
- Ethics in mathematics
- False positive paradox
- False discovery rate
- Family-wise error rate
- Information retrieval performance measures
- Neyman–Pearson lemma
- Null hypothesis
- Probability of a hypothesis for Bayesian inference
- Precision and recall
- Prosecutor’s fallacy
- Prozone phenomenon
- Receiver operating characteristic
- Sensitivity and specificity
- Statisticians’ and engineers’ cross-reference of statistical terms
- Testing hypotheses suggested by the data
- Type III error
References[edit]
- ^ «Type I Error and Type II Error». explorable.com. Retrieved 14 December 2019.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Sheskin, David (2004). Handbook of Parametric and Nonparametric Statistical Procedures. CRC Press. p. 54. ISBN 1584884401.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Lindenmayer, David. (2005). Practical conservation biology. Burgman, Mark A. Collingwood, Vic.: CSIRO Pub. ISBN 0-643-09310-9. OCLC 65216357.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Moroi, K.; Sato, T. (15 August 1975). «Comparison between procaine and isocarboxazid metabolism in vitro by a liver microsomal amidase-esterase». Biochemical Pharmacology. 24 (16): 1517–1521. doi:10.1016/0006-2952(75)90029-5. ISSN 1873-2968. PMID 8.
- ^ NEYMAN, J.; PEARSON, E. S. (1928). «On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference Part I». Biometrika. 20A (1–2): 175–240. doi:10.1093/biomet/20a.1-2.175. ISSN 0006-3444.
- ^ C.I.K.F. (July 1951). «Probability Theory for Statistical Methods. By F. N. David. [Pp. ix + 230. Cambridge University Press. 1949. Price 155.]». Journal of the Staple Inn Actuarial Society. 10 (3): 243–244. doi:10.1017/s0020269x00004564. ISSN 0020-269X.
- ^ Note that the subscript in the expression H0 is a zero (indicating null), and is not an «O» (indicating original).
- ^ Neyman, J.; Pearson, E. S. (30 October 1933). «The testing of statistical hypotheses in relation to probabilities a priori». Mathematical Proceedings of the Cambridge Philosophical Society. 29 (4): 492–510. Bibcode:1933PCPS…29..492N. doi:10.1017/s030500410001152x. ISSN 0305-0041. S2CID 119855116.
- ^ Fisher, R.A. (1966). The design of experiments. 8th edition. Hafner:Edinburgh.
Bibliography[edit]
- Betz, M.A. & Gabriel, K.R., «Type IV Errors and Analysis of Simple Effects», Journal of Educational Statistics, Vol.3, No.2, (Summer 1978), pp. 121–144.
- David, F.N., «A Power Function for Tests of Randomness in a Sequence of Alternatives», Biometrika, Vol.34, Nos.3/4, (December 1947), pp. 335–339.
- Fisher, R.A., The Design of Experiments, Oliver & Boyd (Edinburgh), 1935.
- Gambrill, W., «False Positives on Newborns’ Disease Tests Worry Parents», Health Day, (5 June 2006). [1] Archived 17 May 2018 at the Wayback Machine
- Kaiser, H.F., «Directional Statistical Decisions», Psychological Review, Vol.67, No.3, (May 1960), pp. 160–167.
- Kimball, A.W., «Errors of the Third Kind in Statistical Consulting», Journal of the American Statistical Association, Vol.52, No.278, (June 1957), pp. 133–142.
- Lubin, A., «The Interpretation of Significant Interaction», Educational and Psychological Measurement, Vol.21, No.4, (Winter 1961), pp. 807–817.
- Marascuilo, L.A. & Levin, J.R., «Appropriate Post Hoc Comparisons for Interaction and nested Hypotheses in Analysis of Variance Designs: The Elimination of Type-IV Errors», American Educational Research Journal, Vol.7., No.3, (May 1970), pp. 397–421.
- Mitroff, I.I. & Featheringham, T.R., «On Systemic Problem Solving and the Error of the Third Kind», Behavioral Science, Vol.19, No.6, (November 1974), pp. 383–393.
- Mosteller, F., «A k-Sample Slippage Test for an Extreme Population», The Annals of Mathematical Statistics, Vol.19, No.1, (March 1948), pp. 58–65.
- Moulton, R.T., «Network Security», Datamation, Vol.29, No.7, (July 1983), pp. 121–127.
- Raiffa, H., Decision Analysis: Introductory Lectures on Choices Under Uncertainty, Addison–Wesley, (Reading), 1968.
External links[edit]
- Bias and Confounding – presentation by Nigel Paneth, Graduate School of Public Health, University of Pittsburgh
This article is about erroneous outcomes of statistical tests. For closely related concepts in binary classification and testing generally, see false positives and false negatives.
In statistical hypothesis testing, a type I error is the mistaken rejection of an actually true null hypothesis (also known as a «false positive» finding or conclusion; example: «an innocent person is convicted»), while a type II error is the failure to reject a null hypothesis that is actually false (also known as a «false negative» finding or conclusion; example: «a guilty person is not convicted»).[1] Much of statistical theory revolves around the minimization of one or both of these errors, though the complete elimination of either is a statistical impossibility if the outcome is not determined by a known, observable causal process.
By selecting a low threshold (cut-off) value and modifying the alpha (α) level, the quality of the hypothesis test can be increased.[2] The knowledge of type I errors and type II errors is widely used in medical science, biometrics and computer science.[clarification needed]
Intuitively, type I errors can be thought of as errors of commission, i.e. the researcher unluckily concludes that something is the fact. For instance, consider a study where researchers compare a drug with a placebo. If the patients who are given the drug get better than the patients given the placebo by chance, it may appear that the drug is effective, but in fact the conclusion is incorrect.
In reverse, type II errors are errors of omission. In the example above, if the patients who got the drug did not get better at a higher rate than the ones who got the placebo, but this was a random fluke, that would be a type II error. The consequence of a type II error depends on the size and direction of the missed determination and the circumstances. An expensive cure for one in a million patients may be inconsequential even if it truly is a cure.
Definition[edit]
Statistical background[edit]
In statistical test theory, the notion of a statistical error is an integral part of hypothesis testing. The test goes about choosing about two competing propositions called null hypothesis, denoted by H0 and alternative hypothesis, denoted by H1. This is conceptually similar to the judgement in a court trial. The null hypothesis corresponds to the position of the defendant: just as he is presumed to be innocent until proven guilty, so is the null hypothesis presumed to be true until the data provide convincing evidence against it. The alternative hypothesis corresponds to the position against the defendant. Specifically, the null hypothesis also involves the absence of a difference or the absence of an association. Thus, the null hypothesis can never be that there is a difference or an association.
If the result of the test corresponds with reality, then a correct decision has been made. However, if the result of the test does not correspond with reality, then an error has occurred. There are two situations in which the decision is wrong. The null hypothesis may be true, whereas we reject H0. On the other hand, the alternative hypothesis H1 may be true, whereas we do not reject H0. Two types of error are distinguished: type I error and type II error.[3]
Type I error[edit]
The first kind of error is the mistaken rejection of a null hypothesis as the result of a test procedure. This kind of error is called a type I error (false positive) and is sometimes called an error of the first kind. In terms of the courtroom example, a type I error corresponds to convicting an innocent defendant.
Type II error[edit]
The second kind of error is the mistaken failure to reject the null hypothesis as the result of a test procedure. This sort of error is called a type II error (false negative) and is also referred to as an error of the second kind. In terms of the courtroom example, a type II error corresponds to acquitting a criminal.[4]
Crossover error rate[edit]
The crossover error rate (CER) is the point at which type I errors and type II errors are equal. A system with a lower CER value provides more accuracy than a system with a higher CER value.
False positive and false negative[edit]
In terms of false positives and false negatives, a positive result corresponds to rejecting the null hypothesis, while a negative result corresponds to failing to reject the null hypothesis; «false» means the conclusion drawn is incorrect. Thus, a type I error is equivalent to a false positive, and a type II error is equivalent to a false negative.
Table of error types[edit]
Tabularised relations between truth/falseness of the null hypothesis and outcomes of the test:[5]
| Table of error types | Null hypothesis (H0) is |
||
|---|---|---|---|
| True | False | ||
| Decision about null hypothesis (H0) |
Don’t reject |
Correct inference (true negative) (probability = 1−α) |
Type II error (false negative) (probability = β) |
| Reject | Type I error (false positive) (probability = α) |
Correct inference (true positive) (probability = 1−β) |
Error rate[edit]
The results obtained from negative sample (left curve) overlap with the results obtained from positive samples (right curve). By moving the result cutoff value (vertical bar), the rate of false positives (FP) can be decreased, at the cost of raising the number of false negatives (FN), or vice versa (TP = True Positives, TPR = True Positive Rate, FPR = False Positive Rate, TN = True Negatives).
A perfect test would have zero false positives and zero false negatives. However, statistical methods are probabilistic, and it cannot be known for certain whether statistical conclusions are correct. Whenever there is uncertainty, there is the possibility of making an error. Considering this nature of statistics science, all statistical hypothesis tests have a probability of making type I and type II errors.[6]
- The type I error rate is the probability of rejecting the null hypothesis given that it is true. The test is designed to keep the type I error rate below a prespecified bound called the significance level, usually denoted by the Greek letter α (alpha) and is also called the alpha level. Usually, the significance level is set to 0.05 (5%), implying that it is acceptable to have a 5% probability of incorrectly rejecting the true null hypothesis.[7]
- The rate of the type II error is denoted by the Greek letter β (beta) and related to the power of a test, which equals 1−β.[8]
These two types of error rates are traded off against each other: for any given sample set, the effort to reduce one type of error generally results in increasing the other type of error.[9]
The quality of hypothesis test[edit]
The same idea can be expressed in terms of the rate of correct results and therefore used to minimize error rates and improve the quality of hypothesis test. To reduce the probability of committing a type I error, making the alpha value more stringent is quite simple and efficient. To decrease the probability of committing a type II error, which is closely associated with analyses’ power, either increasing the test’s sample size or relaxing the alpha level could increase the analyses’ power.[10] A test statistic is robust if the type I error rate is controlled.
Varying different threshold (cut-off) value could also be used to make the test either more specific or more sensitive, which in turn elevates the test quality. For example, imagine a medical test, in which an experimenter might measure the concentration of a certain protein in the blood sample. The experimenter could adjust the threshold (black vertical line in the figure) and people would be diagnosed as having diseases if any number is detected above this certain threshold. According to the image, changing the threshold would result in changes in false positives and false negatives, corresponding to movement on the curve.[11]
Example[edit]
Since in a real experiment it is impossible to avoid all type I and type II errors, it is important to consider the amount of risk one is willing to take to falsely reject H0 or accept H0. The solution to this question would be to report the p-value or significance level α of the statistic. For example, if the p-value of a test statistic result is estimated at 0.0596, then there is a probability of 5.96% that we falsely reject H0. Or, if we say, the statistic is performed at level α, like 0.05, then we allow to falsely reject H0 at 5%. A significance level α of 0.05 is relatively common, but there is no general rule that fits all scenarios.
Vehicle speed measuring[edit]
The speed limit of a freeway in the United States is 120 kilometers per hour. A device is set to measure the speed of passing vehicles. Suppose that the device will conduct three measurements of the speed of a passing vehicle, recording as a random sample X1, X2, X3. The traffic police will or will not fine the drivers depending on the average speed . That is to say, the test statistic
In addition, we suppose that the measurements X1, X2, X3 are modeled as normal distribution N(μ,4). Then, T should follow N(μ,4/3) and the parameter μ represents the true speed of passing vehicle. In this experiment, the null hypothesis H0 and the alternative hypothesis H1 should be
H0: μ=120 against H1: μ>120.
If we perform the statistic level at α=0.05, then a critical value c should be calculated to solve
According to change-of-units rule for the normal distribution. Referring to Z-table, we can get
Here, the critical region. That is to say, if the recorded speed of a vehicle is greater than critical value 121.9, the driver will be fined. However, there are still 5% of the drivers are falsely fined since the recorded average speed is greater than 121.9 but the true speed does not pass 120, which we say, a type I error.
The type II error corresponds to the case that the true speed of a vehicle is over 120 kilometers per hour but the driver is not fined. For example, if the true speed of a vehicle μ=125, the probability that the driver is not fined can be calculated as
which means, if the true speed of a vehicle is 125, the driver has the probability of 0.36% to avoid the fine when the statistic is performed at level 125 since the recorded average speed is lower than 121.9. If the true speed is closer to 121.9 than 125, then the probability of avoiding the fine will also be higher.
The tradeoffs between type I error and type II error should also be considered. That is, in this case, if the traffic police do not want to falsely fine innocent drivers, the level α can be set to a smaller value, like 0.01. However, if that is the case, more drivers whose true speed is over 120 kilometers per hour, like 125, would be more likely to avoid the fine.
Etymology[edit]
In 1928, Jerzy Neyman (1894–1981) and Egon Pearson (1895–1980), both eminent statisticians, discussed the problems associated with «deciding whether or not a particular sample may be judged as likely to have been randomly drawn from a certain population»:[12] and, as Florence Nightingale David remarked, «it is necessary to remember the adjective ‘random’ [in the term ‘random sample’] should apply to the method of drawing the sample and not to the sample itself».[13]
They identified «two sources of error», namely:
- (a) the error of rejecting a hypothesis that should have not been rejected, and
- (b) the error of failing to reject a hypothesis that should have been rejected.
In 1930, they elaborated on these two sources of error, remarking that:
…in testing hypotheses two considerations must be kept in view, we must be able to reduce the chance of rejecting a true hypothesis to as low a value as desired; the test must be so devised that it will reject the hypothesis tested when it is likely to be false.
In 1933, they observed that these «problems are rarely presented in such a form that we can discriminate with certainty between the true and false hypothesis» . They also noted that, in deciding whether to fail to reject, or reject a particular hypothesis amongst a «set of alternative hypotheses», H1, H2…, it was easy to make an error:
…[and] these errors will be of two kinds:
- (I) we reject H0 [i.e., the hypothesis to be tested] when it is true,[14]
- (II) we fail to reject H0 when some alternative hypothesis HA or H1 is true. (There are various notations for the alternative).
In all of the papers co-written by Neyman and Pearson the expression H0 always signifies «the hypothesis to be tested».
In the same paper they call these two sources of error, errors of type I and errors of type II respectively.[15]
[edit]
Null hypothesis[edit]
It is standard practice for statisticians to conduct tests in order to determine whether or not a «speculative hypothesis» concerning the observed phenomena of the world (or its inhabitants) can be supported. The results of such testing determine whether a particular set of results agrees reasonably (or does not agree) with the speculated hypothesis.
On the basis that it is always assumed, by statistical convention, that the speculated hypothesis is wrong, and the so-called «null hypothesis» that the observed phenomena simply occur by chance (and that, as a consequence, the speculated agent has no effect) – the test will determine whether this hypothesis is right or wrong. This is why the hypothesis under test is often called the null hypothesis (most likely, coined by Fisher (1935, p. 19)), because it is this hypothesis that is to be either nullified or not nullified by the test. When the null hypothesis is nullified, it is possible to conclude that data support the «alternative hypothesis» (which is the original speculated one).
The consistent application by statisticians of Neyman and Pearson’s convention of representing «the hypothesis to be tested» (or «the hypothesis to be nullified») with the expression H0 has led to circumstances where many understand the term «the null hypothesis» as meaning «the nil hypothesis» – a statement that the results in question have arisen through chance. This is not necessarily the case – the key restriction, as per Fisher (1966), is that «the null hypothesis must be exact, that is free from vagueness and ambiguity, because it must supply the basis of the ‘problem of distribution,’ of which the test of significance is the solution.»[16] As a consequence of this, in experimental science the null hypothesis is generally a statement that a particular treatment has no effect; in observational science, it is that there is no difference between the value of a particular measured variable, and that of an experimental prediction.[citation needed]
Statistical significance[edit]
If the probability of obtaining a result as extreme as the one obtained, supposing that the null hypothesis were true, is lower than a pre-specified cut-off probability (for example, 5%), then the result is said to be statistically significant and the null hypothesis is rejected.
British statistician Sir Ronald Aylmer Fisher (1890–1962) stressed that the «null hypothesis»:
… is never proved or established, but is possibly disproved, in the course of experimentation. Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis.
— Fisher, 1935, p.19
Application domains[edit]
Medicine[edit]
In the practice of medicine, the differences between the applications of screening and testing are considerable.
Medical screening[edit]
Screening involves relatively cheap tests that are given to large populations, none of whom manifest any clinical indication of disease (e.g., Pap smears).
Testing involves far more expensive, often invasive, procedures that are given only to those who manifest some clinical indication of disease, and are most often applied to confirm a suspected diagnosis.
For example, most states in the USA require newborns to be screened for phenylketonuria and hypothyroidism, among other congenital disorders.
Hypothesis: «The newborns have phenylketonuria and hypothyroidism»
Null Hypothesis (H0): «The newborns do not have phenylketonuria and hypothyroidism»,
Type I error (false positive): The true fact is that the newborns do not have phenylketonuria and hypothyroidism but we consider they have the disorders according to the data.
Type II error (false negative): The true fact is that the newborns have phenylketonuria and hypothyroidism but we consider they do not have the disorders according to the data.
Although they display a high rate of false positives, the screening tests are considered valuable because they greatly increase the likelihood of detecting these disorders at a far earlier stage.
The simple blood tests used to screen possible blood donors for HIV and hepatitis have a significant rate of false positives; however, physicians use much more expensive and far more precise tests to determine whether a person is actually infected with either of these viruses.
Perhaps the most widely discussed false positives in medical screening come from the breast cancer screening procedure mammography. The US rate of false positive mammograms is up to 15%, the highest in world. One consequence of the high false positive rate in the US is that, in any 10-year period, half of the American women screened receive a false positive mammogram. False positive mammograms are costly, with over $100 million spent annually in the U.S. on follow-up testing and treatment. They also cause women unneeded anxiety. As a result of the high false positive rate in the US, as many as 90–95% of women who get a positive mammogram do not have the condition. The lowest rate in the world is in the Netherlands, 1%. The lowest rates are generally in Northern Europe where mammography films are read twice and a high threshold for additional testing is set (the high threshold decreases the power of the test).
The ideal population screening test would be cheap, easy to administer, and produce zero false-negatives, if possible. Such tests usually produce more false-positives, which can subsequently be sorted out by more sophisticated (and expensive) testing.
Medical testing[edit]
False negatives and false positives are significant issues in medical testing.
Hypothesis: «The patients have the specific disease».
Null hypothesis (H0): «The patients do not have the specific disease».
Type I error (false positive): «The true fact is that the patients do not have a specific disease but the physicians judges the patients was ill according to the test reports».
False positives can also produce serious and counter-intuitive problems when the condition being searched for is rare, as in screening. If a test has a false positive rate of one in ten thousand, but only one in a million samples (or people) is a true positive, most of the positives detected by that test will be false. The probability that an observed positive result is a false positive may be calculated using Bayes’ theorem.
Type II error (false negative): «The true fact is that the disease is actually present but the test reports provide a falsely reassuring message to patients and physicians that the disease is absent».
False negatives produce serious and counter-intuitive problems, especially when the condition being searched for is common. If a test with a false negative rate of only 10% is used to test a population with a true occurrence rate of 70%, many of the negatives detected by the test will be false.
This sometimes leads to inappropriate or inadequate treatment of both the patient and their disease. A common example is relying on cardiac stress tests to detect coronary atherosclerosis, even though cardiac stress tests are known to only detect limitations of coronary artery blood flow due to advanced stenosis.
Biometrics[edit]
Biometric matching, such as for fingerprint recognition, facial recognition or iris recognition, is susceptible to type I and type II errors.
Hypothesis: «The input does not identify someone in the searched list of people»
Null hypothesis: «The input does identify someone in the searched list of people»
Type I error (false reject rate): «The true fact is that the person is someone in the searched list but the system concludes that the person is not according to the data».
Type II error (false match rate): «The true fact is that the person is not someone in the searched list but the system concludes that the person is someone whom we are looking for according to the data».
The probability of type I errors is called the «false reject rate» (FRR) or false non-match rate (FNMR), while the probability of type II errors is called the «false accept rate» (FAR) or false match rate (FMR).
If the system is designed to rarely match suspects then the probability of type II errors can be called the «false alarm rate». On the other hand, if the system is used for validation (and acceptance is the norm) then the FAR is a measure of system security, while the FRR measures user inconvenience level.
Security screening[edit]
False positives are routinely found every day in airport security screening, which are ultimately visual inspection systems. The installed security alarms are intended to prevent weapons being brought onto aircraft; yet they are often set to such high sensitivity that they alarm many times a day for minor items, such as keys, belt buckles, loose change, mobile phones, and tacks in shoes.
Here, the null hypothesis is that the item is not a weapon, while the alternative hypothesis is that the item is a weapon.
A type I error (false positive): «The true fact is that the item is not a weapon but the system still alarms».
Type II error (false negative) «The true fact is that the item is a weapon but the system keeps silent at this time».
The ratio of false positives (identifying an innocent traveler as a terrorist) to true positives (detecting a would-be terrorist) is, therefore, very high; and because almost every alarm is a false positive, the positive predictive value of these screening tests is very low.
The relative cost of false results determines the likelihood that test creators allow these events to occur. As the cost of a false negative in this scenario is extremely high (not detecting a bomb being brought onto a plane could result in hundreds of deaths) whilst the cost of a false positive is relatively low (a reasonably simple further inspection) the most appropriate test is one with a low statistical specificity but high statistical sensitivity (one that allows a high rate of false positives in return for minimal false negatives).
Computers[edit]
The notions of false positives and false negatives have a wide currency in the realm of computers and computer applications, including computer security, spam filtering, Malware, Optical character recognition and many others.
For example, in the case of spam filtering the hypothesis here is that the message is a spam.
Thus, null hypothesis: «The message is not a spam».
Type I error (false positive): «Spam filtering or spam blocking techniques wrongly classify a legitimate email message as spam and, as a result, interferes with its delivery».
While most anti-spam tactics can block or filter a high percentage of unwanted emails, doing so without creating significant false-positive results is a much more demanding task.
Type II error (false negative): «Spam email is not detected as spam, but is classified as non-spam». A low number of false negatives is an indicator of the efficiency of spam filtering.
See also[edit]
- Binary classification
- Detection theory
- Egon Pearson
- Ethics in mathematics
- False positive paradox
- False discovery rate
- Family-wise error rate
- Information retrieval performance measures
- Neyman–Pearson lemma
- Null hypothesis
- Probability of a hypothesis for Bayesian inference
- Precision and recall
- Prosecutor’s fallacy
- Prozone phenomenon
- Receiver operating characteristic
- Sensitivity and specificity
- Statisticians’ and engineers’ cross-reference of statistical terms
- Testing hypotheses suggested by the data
- Type III error
References[edit]
- ^ «Type I Error and Type II Error». explorable.com. Retrieved 14 December 2019.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Sheskin, David (2004). Handbook of Parametric and Nonparametric Statistical Procedures. CRC Press. p. 54. ISBN 1584884401.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Lindenmayer, David. (2005). Practical conservation biology. Burgman, Mark A. Collingwood, Vic.: CSIRO Pub. ISBN 0-643-09310-9. OCLC 65216357.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Moroi, K.; Sato, T. (15 August 1975). «Comparison between procaine and isocarboxazid metabolism in vitro by a liver microsomal amidase-esterase». Biochemical Pharmacology. 24 (16): 1517–1521. doi:10.1016/0006-2952(75)90029-5. ISSN 1873-2968. PMID 8.
- ^ NEYMAN, J.; PEARSON, E. S. (1928). «On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference Part I». Biometrika. 20A (1–2): 175–240. doi:10.1093/biomet/20a.1-2.175. ISSN 0006-3444.
- ^ C.I.K.F. (July 1951). «Probability Theory for Statistical Methods. By F. N. David. [Pp. ix + 230. Cambridge University Press. 1949. Price 155.]». Journal of the Staple Inn Actuarial Society. 10 (3): 243–244. doi:10.1017/s0020269x00004564. ISSN 0020-269X.
- ^ Note that the subscript in the expression H0 is a zero (indicating null), and is not an «O» (indicating original).
- ^ Neyman, J.; Pearson, E. S. (30 October 1933). «The testing of statistical hypotheses in relation to probabilities a priori». Mathematical Proceedings of the Cambridge Philosophical Society. 29 (4): 492–510. Bibcode:1933PCPS…29..492N. doi:10.1017/s030500410001152x. ISSN 0305-0041. S2CID 119855116.
- ^ Fisher, R.A. (1966). The design of experiments. 8th edition. Hafner:Edinburgh.
Bibliography[edit]
- Betz, M.A. & Gabriel, K.R., «Type IV Errors and Analysis of Simple Effects», Journal of Educational Statistics, Vol.3, No.2, (Summer 1978), pp. 121–144.
- David, F.N., «A Power Function for Tests of Randomness in a Sequence of Alternatives», Biometrika, Vol.34, Nos.3/4, (December 1947), pp. 335–339.
- Fisher, R.A., The Design of Experiments, Oliver & Boyd (Edinburgh), 1935.
- Gambrill, W., «False Positives on Newborns’ Disease Tests Worry Parents», Health Day, (5 June 2006). [1] Archived 17 May 2018 at the Wayback Machine
- Kaiser, H.F., «Directional Statistical Decisions», Psychological Review, Vol.67, No.3, (May 1960), pp. 160–167.
- Kimball, A.W., «Errors of the Third Kind in Statistical Consulting», Journal of the American Statistical Association, Vol.52, No.278, (June 1957), pp. 133–142.
- Lubin, A., «The Interpretation of Significant Interaction», Educational and Psychological Measurement, Vol.21, No.4, (Winter 1961), pp. 807–817.
- Marascuilo, L.A. & Levin, J.R., «Appropriate Post Hoc Comparisons for Interaction and nested Hypotheses in Analysis of Variance Designs: The Elimination of Type-IV Errors», American Educational Research Journal, Vol.7., No.3, (May 1970), pp. 397–421.
- Mitroff, I.I. & Featheringham, T.R., «On Systemic Problem Solving and the Error of the Third Kind», Behavioral Science, Vol.19, No.6, (November 1974), pp. 383–393.
- Mosteller, F., «A k-Sample Slippage Test for an Extreme Population», The Annals of Mathematical Statistics, Vol.19, No.1, (March 1948), pp. 58–65.
- Moulton, R.T., «Network Security», Datamation, Vol.29, No.7, (July 1983), pp. 121–127.
- Raiffa, H., Decision Analysis: Introductory Lectures on Choices Under Uncertainty, Addison–Wesley, (Reading), 1968.
External links[edit]
- Bias and Confounding – presentation by Nigel Paneth, Graduate School of Public Health, University of Pittsburgh
Определим выражение для вычисления ошибки второго рода и мощности теста, построим в
MS
EXCEL
кривые оперативной характеристики (Operating-characteristic curves).
Тема этой статьи – вычисление
ошибки второго рода
(type II error) при
проверке гипотез
. Основная статья про
проверку гипотез
находится здесь
.
Напомним, что процедура
проверки гипотез
состоит из следующих шагов:
-
из исследуемого распределения берется
выборка
; -
на основании значений
выборки
вычисляется
тестовая статистика
; -
значение
тестовой статистики
сравнивается со значениями, соответствующим заданномууровню значимости (ошибке первого рода)
;
-
по результату сравнения делается вывод об отклонении (или не отклонении)
нулевой гипотезы
.
Обычно с
проверкой гипотез
связывают 2 типа ошибок. Если
нулевая гипотеза
отклоняется, когда она верна – это
ошибка первого рода
(обозначается α,
альфа
). Если нулевая гипотеза не отклоняется, когда она неверна, то это
ошибка второго рода
(обозначается β,
бета
).
Ошибка первого рода
часто называется риском производителя. Это осознанный риск, на который идет производитель продукции, т.к. он определяет вероятность того, что годная продукция может быть забракована, хотя на самом деле она таковой не является. Величина
ошибки первого рода
задается перед
проверкой гипотезы
, таким образом, она контролируется исследователем напрямую и может быть задана в соответствии с условиями решаемой задачи. После этого, процедура проверки гипотезы составляется таким образом, чтобы вероятность
ошибки второго рода
была как можно меньше.
Ошибка второго рода
β
зависит от размера
выборки
n и
уровня значимости α
, и поэтому контролируется косвенно. Чем больше размер
выборки
, тем меньше
ошибка второго рода
(при прочих равных).
Часто также используют величину
1-β
, которая называется
мощностью статистического критерия
(мощностью теста, мощностью исследования, англ. power of a statistical test).
Мощность статистического критерия
— это вероятность правильно отклонить нулевую гипотезу. Чем ближе эта величина к единице, тем меньше у нас шансов ошибиться при проверке гипотезы (тем лучше критерий различает гипотезы Н
0
и Н
1
).
Ошибку второго рода
вычисляют для каждого вида
проверки гипотез
по-разному. Получим выражение для вычисления
ошибки второго рода
для
проверки двусторонней гипотезы о равенстве среднего значения распределения некоторой величине (стандартное отклонение известно)
.
Для
проверки гипотезы
этого типа используется
тестовая статистика
Z
0
:
![]()
которая имеет
стандартное нормальное распределение
.
Чтобы найти
Ошибку второго рода
необходимо предположить, что гипотеза Н
0
: μ=μ
0
не верна, и соответственно истинное
среднее значение распределения
μ=μ
0
+Δ, где Δ>0. В этом случае,
тестовая статистика
Z
0
будет иметь
нормальное распределение
N(Δ√n/σ;1), т.е. будет смещено вправо на Δ√n/σ (см.
файл примера на листе Бета
).
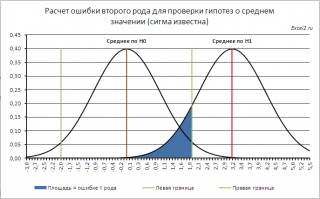
Согласно определения,
ошибка второго рода
равна вероятности, принять нулевую гипотезу, если на самом деле справедлива Н
1
. Эта вероятность соответствует выделенной на рисунке области.
Статистика
Z
0
, в этом случае, примет значение между -Z
α/2
и Z
α/2
(эти значения соответствуют границам
доверительного интервала
). Z
α/2
– это
верхний α/2-квантиль стандартного нормального распределения
.
Определим
ошибку второго рода
в терминах
стандартного нормального распределения
:
![]()
Это выражение будет работать и для Δ<0. Как видно из выражения,
ошибка второго рода
является функцией от α, Δ и n. В
файле примера на листе Бета
можно быстро рассчитать β и
мощность теста
в зависимости от этих параметров. Диаграмма, приведенная выше, будет автоматически перестроена.
Для заданного значения α часто строят семейство кривых, которые иллюстрируют зависимость
ошибки второго рода
от Δ и n. Такие кривые называются
операционными характеристиками
(Operating-characteristic curves).
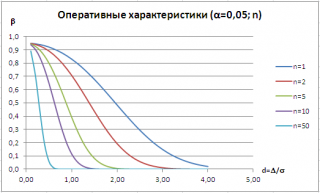
Как видно из рисунка, чем дальше истинное значение
среднего
от μ
0
, т.е. чем больше Δ, тем меньше
ошибка второго рода.
Таким образом, для заданных α и n, тест легче определит большие отклонения от
среднего
, чем малые (тест обладает, в данном случае, большей
мощностью
). При росте n
мощность теста
также растет.
Кривые
операционных характеристик
используются для оценки размера
выборки
, достаточного для определения заданной разницы между истинным значением
среднего
μ
от μ
0
с требуемой вероятностью.
В
файле примера на листе ОХ
создана форма для определения размера
выборки
, достаточного для обеспечения заданной
мощности теста
.
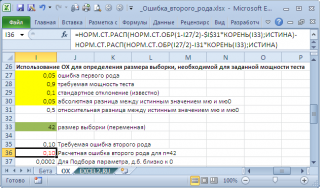
Например, Н
0
: μ
0
=20, истинное значение μ=20,05,
стандартное отклонение
=0,1, α=0,05. Чтобы вероятность правильно отклонить гипотезу H
0
была равна 0,9 (
мощность теста
), размер
выборки
должен быть 42 или более.
Примечание
:
Для нахождения размера
выборки
потребуется использование инструмента MS EXCEL
Подбор параметра
.
Ошибки первого рода (англ. type I errors, α errors, false positives) и ошибки второго рода (англ. type II errors, β errors, false negatives) в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее, данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Содержание
- 1 Определения
- 2 О смысле ошибок первого и второго рода
- 3 Вероятности ошибок (уровень значимости и мощность)
- 4 Примеры использования
- 4.1 Радиолокация
- 4.2 Компьютеры
- 4.2.1 Компьютерная безопасность
- 4.2.2 Фильтрация спама
- 4.2.3 Вредоносное программное обеспечение
- 4.2.4 Поиск в компьютерных базах данных
- 4.2.5 Оптическое распознавание текстов (OCR)
- 4.2.6 Досмотр пассажиров и багажа
- 4.2.7 Биометрия
- 4.3 Массовая медицинская диагностика (скрининг)
- 4.4 Медицинское тестирование
- 4.5 Исследования сверхъестественных явлений
- 5 См. также
- 6 Примечания
Определения
Пусть дана выборка  из неизвестного совместного распределения
из неизвестного совместного распределения  , и поставлена бинарная задача проверки статистических гипотез:
, и поставлена бинарная задача проверки статистических гипотез:

где  — нулевая гипотеза, а
— нулевая гипотеза, а  — альтернативная гипотеза. Предположим, что задан статистический критерий
— альтернативная гипотеза. Предположим, что задан статистический критерий
 ,
,
 ,
,сопоставляющий каждой реализации выборки  одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
- Распределение выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
 соответствует гипотезе
соответствует гипотезе  .
. .
.Во втором и четвертом случае говорят, что произошла статистическая ошибка, и её называют ошибкой первого и второго рода соответственно. [1][2]
| Верная гипотеза | |||
|---|---|---|---|
| |
|
||
| Результат применения критерия |
|
верно принята |
неверно принята (Ошибка второго рода) |
| |
неверно отвергнута (Ошибка первого рода) |
верно отвергнута |
О смысле ошибок первого и второго рода
Как видно из вышеприведённого определения, ошибки первого и второго рода являются взаимно-симметричными, то есть если поменять местами гипотезы и , то ошибки первого рода превратятся в ошибки второго рода и наоборот. Тем не менее, в большинстве практических ситуаций путаницы не происходит, поскольку принято считать, что нулевая гипотеза соответствует состоянию «по умолчанию» (естественному, наиболее ожидаемому положению вещей) — например, что обследуемый человек здоров, или что проходящий через рамку металлодетектора пассажир не имеет запрещённых металлических предметов. Соответственно, альтернативная гипотеза обозначает противоположную ситуацию, которая обычно трактуется как менее вероятная, неординарная, требующая какой-либо реакции.
С учётом этого ошибку первого рода часто называют ложной тревогой, ложным срабатыванием или ложноположительным срабатыванием — например, анализ крови показал наличие заболевания, хотя на самом деле человек здоров, или металлодетектор выдал сигнал тревоги, сработав на металлическую пряжку ремня. Слово «положительный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают положительный результат (т.е. показывают наличие заболевания у пациента), когда на самом деле пациент этим заболеванием не страдает. Такой результат называется ложноположительным.
В других областях обычно используют словосочетания со схожим смыслом, например, «ложное срабатывание», «ложная тревога» и т.п. В информационных технологиях часто используют английский термин false positive без перевода.
Из-за возможности ложных срабатываний не удаётся полностью автоматизировать борьбу со многими видами угроз. Как правило, вероятность ложного срабатывания коррелирует с вероятностью пропуска события (ошибки второго рода). То есть: чем более чувствительна система, тем больше опасных событий она детектирует и, следовательно, предотвращает. Но при повышении чувствительности неизбежно вырастает и вероятность ложных срабатываний. Поэтому чересчур чувствительно (параноидально) настроенная система защиты может выродиться в свою противоположность и привести к тому, что побочный вред от неё будет превышать пользу.
Соответственно, ошибку второго рода иногда называют пропуском события или ложноотрицательным срабатыванием — человек болен, но анализ крови этого не показал, или у пассажира имеется холодное оружие, но рамка металлодетектора его не обнаружила (например, из-за того, что чувствительность рамки отрегулирована на обнаружение только очень массивных металлических предметов).
Слово «отрицательный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают отрицательный результат (т.е. показывают отсутствие заболевания у пациента), когда на самом деле пациент страдает этим заболеванием. Такой результат называется ложноотрицательным.
В других областях обычно используют словосочетания со схожим смыслом, например, «пропуск события», и т.п. В информационных технологиях часто используют английский термин false negative без перевода.
Степень чувствительности системы защиты должна представлять собой компромисс между вероятностью ошибок первого и второго рода. Где именно находится точка баланса, зависит от оценки рисков обоих видов ошибок.
Вероятности ошибок (уровень значимости и мощность)
Вероятность ошибки первого рода при проверке статистических гипотез называют уровнем значимости и обычно обозначают греческой буквой  (отсюда название -errors).
(отсюда название -errors).
Вероятность ошибки второго рода не имеет какого-то особого общепринятого названия, на письме обозначается греческой буквой  (отсюда -errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле
(отсюда -errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле  . Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
. Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
Обе эти характеристики обычно вычисляются с помощью так называемой функции мощности критерия. В частности, вероятность ошибки первого рода есть функция мощности, вычисленная при нулевой гипотезе. Для критериев, основанных на выборке фиксированного объема, вероятность ошибки второго рода есть единица минус функция мощности, вычисленная в предположении, что распределение наблюдений соответствует альтернативной гипотезе. Для последовательных критериев это также верно, если критерий останавливается с вероятностью единица (при данном распределении из альтернативы).
В статистических тестах обычно приходится идти на компромисс между приемлемым уровнем ошибок первого и второго рода. Зачастую для принятия решения используется пороговое значение, которое может варьироваться с целью сделать тест более строгим или, наоборот, более мягким. Этим пороговым значением является уровень значимости, которым задаются при проверке статистических гипотез. Например, в случае металлодетектора повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная тревога), а понижение чувствительности — к увеличению риска ошибки второго рода (пропуск запрещённого предмета).
Примеры использования
Радиолокация
В задаче радиолокационного обнаружения воздушных целей, прежде всего, в системе ПВО ошибки первого и второго рода, с формулировкой «ложная тревога» и «пропуск цели» являются одним из основных элементов как теории, так и практики построения радиолокационных станций. Вероятно, это первый пример последовательного применения статистических методов в целой технической области.
Компьютеры
Понятия ошибок первого и второго рода широко используются в области компьютеров и программного обеспечения.
Компьютерная безопасность
Наличие уязвимостей в вычислительных системах приводит к тому, что приходится, с одной стороны, решать задачу сохранения целостности компьютерных данных, а с другой стороны — обеспечивать нормальный доступ легальных пользователей к этим данным (см. компьютерная безопасность). Moulton (1983, с.125) отмечает, что в данном контексте возможны следующие нежелательные ситуации:
- когда нарушители классифицируются как авторизованные пользователи (ошибки первого рода)
- когда авторизованные пользователи классифицируются как нарушители (ошибки второго рода)
Фильтрация спама
Ошибка первого рода происходит, когда механизм блокировки/фильтрации спама ошибочно классифицирует легитимное email-сообщение как спам и препятствует его нормальной доставке. В то время как большинство «антиспам»-алгоритмов способны блокировать/фильтровать большой процент нежелательных email-сообщений, гораздо более важной задачей является минимизировать число «ложных тревог» (ошибочных блокировок нужных сообщений).
Ошибка второго рода происходит, когда антиспам-система ошибочно пропускает нежелательное сообщение, классифицируя его как «не спам». Низкий уровень таких ошибок является индикатором эффективности антиспам-алгоритма.
Пока не удалось создать антиспамовую систему без корреляции между вероятностью ошибок первого и второго рода. Вероятность пропустить спам у современных систем колеблется в пределах от 1% до 30%. Вероятность ошибочно отвергнуть валидное сообщение — от 0,001 % до 3 %. Выбор системы и её настроек зависит от условий конкретного получателя: для одних получателей риск потерять 1% хорошей почты оценивается как незначительный, для других же потеря даже 0,1% является недопустимой.
Вредоносное программное обеспечение
Понятие ошибки первого рода также используется, когда антивирусное программное обеспечение ошибочно классифицирует безвредный файл как вирус. Неверное обнаружение может быть вызвано особенностями эвристики, либо неправильной сигнатурой вируса в базе данных. Подобные проблемы могут происходить также и с антитроянскими и антишпионскими программами.
Поиск в компьютерных базах данных
При поиске в базе данных к ошибкам первого рода можно отнести документы, которые выдаются поиском, несмотря на их иррелевантность (несоответствие) поисковому запросу. Ошибочные срабатывания характерны для полнотекстового поиска, когда поисковый алгоритм анализирует полные тексты всех хранимых в базе данных документов и пытается найти соответствия одному или нескольким терминам, заданным пользователем в запросе.
Большинство ложных срабатываний обусловлены сложностью естественных языков, многозначностью слов: например, «home» может обозначать как «место проживания человека», так и «корневую страницу веб-сайта». Число подобных ошибок может быть снижено за счёт использования специального словаря. Однако это решение относительно дорогое, поскольку подобный словарь и разметка документов (индексирование) должны создаваться экспертом.
Оптическое распознавание текстов (OCR)
Разнообразные детектирующие алгоритмы нередко выдают ошибки первого рода. Программное обеспечение оптического распознавания текстов может распознать букву «a» в ситуации, когда на самом деле изображены несколько точек, которые используемый алгоритм расценил как «a».
Досмотр пассажиров и багажа
Ошибки первого рода регулярно встречаются каждый день в компьютерных системах предварительного досмотра пассажиров в аэропортах. Установленные в них детекторы предназначены для предотвращения проноса оружия на борт самолёта; тем не менее, уровень чувствительности в них зачастую настраивается настолько высоко, что много раз за день они срабатывают на незначительные предметы, такие как ключи, пряжки ремней, монеты, мобильные телефоны, гвозди в подошвах обуви и т.п. (см. обнаружение взрывчатых веществ, металлодетекторы).
Таким образом, соотношение числа ложных тревог (идентифицикация благопристойного пассажира как правонарушителя) к числу правильных срабатываний (обнаружение действительно запрещённых предметов) очень велико.
Биометрия
Ошибки первого и второго рода являются большой проблемой в системах биометрического сканирования, использующих распознавание радужной оболочки или сетчатки глаза, черт лица и т.д. Такие сканирующие системы могут ошибочно отождествить кого-то с другим, «известным» системе человеком, информация о котором хранится в базе данных (к примеру, это может быть лицо, имеющее право входа в систему, или подозреваемый преступник и т.п.). Противоположной ошибкой будет неспособность системы распознать легитимного зарегистрированного пользователя, или опознать подозреваемого в преступлении.[3]
Массовая медицинская диагностика (скрининг)
В медицинской практике есть существенное различие между скринингом и тестированием:
- Скрининг включает в себя относительно дешёвые тесты, которые проводятся для большой группы людей при отсутствии каких-либо клинических признаков болезни (например, мазок Папаниколау).
- Тестирование подразумевает гораздо более дорогие, зачастую инвазивные, процедуры, которые проводятся только для тех, у кого проявляются клинические признаки заболевания, и которые, в основном, применяются для подтверждения предполагаемого диагноза.
К примеру, в большинстве штатов в США обязательно прохождение новорожденными процедуры скрининга на оксифенилкетонурию и гипотиреоз, помимо других врождённых аномалий. Несмотря на высокий уровень ошибок первого рода, эти процедуры скрининга считаются целесообразными, поскольку они существенно увеличивают вероятность обнаружения этих расстройств на самой ранней стадии.[4]
Простые анализы крови, используемые для скрининга потенциальных доноров на ВИЧ и гепатит, имеют существенный уровень ошибок первого рода; однако в арсенале врачей есть гораздо более точные (и, соответственно, дорогие) тесты для проверки, действительно ли человек инфицирован каким-либо из этих вирусов.
Возможно, наиболее широкие дискуссии вызывают ошибки первого рода в процедурах скрининга на рак груди (маммография). В США уровень ошибок первого рода в маммограммах достигает 15%, это самый высокий показатель в мире.[5] Самый низкий уровень наблюдается в Нидерландах, 1%.[6]
Медицинское тестирование
Ошибки второго рода являются существенной проблемой в медицинском тестировании. Они дают пациенту и врачу ложное убеждение, что заболевание отсутствует, в то время как в действительности оно есть. Это зачастую приводит к неуместному или неадекватному лечению. Типичным примером является доверие результатам кардиотестирования при выявлении коронарного атеросклероза, хотя известно, что кардиотестирование выявляет только те затруднения кровотока в коронарной артерии, которые вызваны стенозом.
Ошибки второго рода вызывают серьёзные и трудные для понимания проблемы, особенно когда искомое условие является широкораспространённым. Если тест с 10%-ным уровнем ошибок второго рода используется для обследования группы, где вероятность «истинно-положительных» случаев составляет 70%, то многие отрицательные результаты теста окажутся ложными. (См. Теорему Байеса).
Ошибки первого рода также могут вызывать серьёзные и трудные для понимания проблемы. Это происходит, когда искомое условие является редким. Если уровень ошибок первого рода у теста составляет один случай на десять тысяч, но в тестируемой группе образцов (или людей) вероятность «истинно-положительных» случаев составляет в среднем один случай на миллион, то большинство положительных результатов этого теста будут ложными.[7]
Исследования сверхъестественных явлений
Термин ошибка первого рода был взят на вооружение исследователями в области паранормальных явлений и привидений для описания фотографии или записи или какого-либо другого свидетельства, которое ошибочно трактуется как имеющее паранормальное происхождение — в данном контексте ошибка первого рода — это какое-либо несостоятельное «медиасвидетельство» (изображение, видеозапись, аудиозапись и т.д.), которое имеет обычное объяснение.[8]
См. также
- Статистическая значимость
- Ложноположительный
- Атака второго рода
- Случаи ложного срабатывания систем предупреждения о ракетном нападении
- Receiver_operating_characteristic
Примечания
- ↑ ГОСТ Р 50779.10-2000. «Статистические методы. Вероятность и основы статистики. Термины и определения.». Стр. 26
- ↑ Valerie J. Easton, John H. McColl. Statistics Glossary: Hypothesis Testing.
- ↑ Данный пример как раз характеризует случай, когда классификация ошибок будет зависеть от назначения системы: если биометрическое сканирование используется для допуска сотрудников (нулевая гипотеза: «проходящий сканирование человек действительно является сотрудником»), то ошибочное отождествление будет ошибкой второго рода, а «неузнавание» — ошибкой первого рода; если же сканирование используется для опознания преступников (нулевая гипотеза: «проходящий сканирование человек не является преступником»), то ошибочное отождествление будет ошибкой первого рода, а «неузнавание» — ошибкой второго рода.
- ↑ Относительно скрининга новорожденных, последние исследования показали, что количество ошибок первого рода в 12 раз больше, чем количество верных обнаружений (Gambrill, 2006. [1])
- ↑ Одним из последствий такого высокого уровня ошибок первого рода в США является то, что за произвольный 10-летний период половина обследуемых американских женщин получают как минимум одну ложноположительную маммограмму. Такие ошибочные маммограммы обходятся дорого, приводя к ежегодным расходам в 100 миллионов долларов на последующее (ненужное) лечение. Кроме того, они вызывают излишнюю тревогу у женщин. В результате высокого уровня подобных ошибок первого рода в США, примерно у 90-95% женщин, получивших хотя бы раз в жизни положительную маммограмму, на самом деле заболевание отсутствует.
- ↑ Наиболее низкие уровни этих ошибок наблюдаются в северной Европе, где маммографические плёнки считываются дважды, и для дополнительного тестирования устанавливается повышенное пороговое значение (высокий порог снижает статистическую эффективность теста).
- ↑ Вероятность того, что выдаваемый тестом результат окажется ошибкой первого рода, может быть вычислена при помощи Теоремы Байеса.
- ↑ На некоторых сайтах приведены примеры ошибок первого рода, например: Атлантическое Сообщество Паранормальных явлений (The Atlantic Paranormal Society, TAPS) и Морстаунская организация по Исследованию Привидений (Moorestown Ghost Research).