
Часть 1. Про CPU
Часть 3. Про Storage
В этой статье поговорим про счетчики производительности оперативной памяти (RAM) в vSphere.
Вроде бы с памятью все более однозначно, чем с процессором: если на ВМ возникают проблемы с производительностью, их сложно не заметить. Зато если они появляются, справиться с ними гораздо сложнее. Но обо всем по порядку.
Немного теории
Оперативная память виртуальных машин берется из памяти сервера, на которых работают ВМ. Это вполне очевидно:). Если оперативной памяти сервера не хватает для всех желающих, ESXi начинает применять техники оптимизации потребления оперативной памяти (memory reclamation techniques). В противном случае операционные системы ВМ падали бы с ошибками доступа к ОЗУ.
Какие техники применять ESXi решает в зависимости от загруженности оперативной памяти:
Источник
minFree — это оперативная память, необходимая для работы гипервизора.
До ESXi 4.1 включительно minFree по умолчанию было фиксированным — 6% от объема оперативной памяти сервера (процент можно было поменять через опцию Mem.MinFreePct на ESXi). В более поздних версиях из-за роста объемов памяти на серверах minFree стало рассчитываться исходя из объема памяти хоста, а не как фиксированное процентное значение.
Значение minFree (по умолчанию) считается следующим образом:
Источник
Например, для сервера со 128 Гбайт RAM значение MinFree будет таким:
MinFree = 245,76 + 327,68 + 327,68 + 1024 = 1925,12 Мбайт = 1,88 Гбайт
Фактическое значение может отличаться на пару сотен МБайт, это зависит от сервера и оперативной памяти.
Обычно для продуктивных стендов нормальным можно считать только состояние High. Для стендов для тестирования и разработки приемлемыми могут быть состояния Clear/Soft. Если оперативной памяти на хосте осталось менее 64% MinFree, то у ВМ, работающих на нем, точно наблюдаются проблемы с производительностью.
В каждом состоянии применяются определенные memory reclamation techniques начиная с TPS, практически не влияющего на производительность ВМ, заканчивая Swapping’ом. Расскажу про них подробнее.
Transparent Page Sharing (TPS). TPS — это, грубо говоря, дедупликация страниц оперативной памяти виртуальных машин на сервере.
ESXi ищет одинаковые страницы оперативной памяти виртуальных машин, считая и сравнивая hash-сумму страниц, и удаляет дубликаты страниц, заменяя их ссылками на одну и ту же страницу в физической памяти сервера. В результате потребление физической памяти снижается и можно добиться некоторой переподписки по памяти практически без снижения производительности.
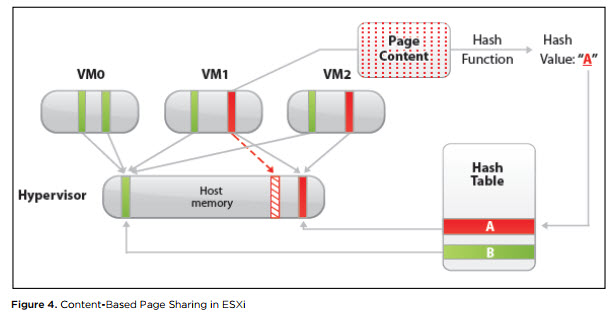
Источник
Данный механизм работает только для страниц памяти размером 4 Кбайт (small pages). Страницы размером 2 МБайт (large pages) гипервизор дедуплицировать даже не пытается: шанс найти одинаковые страницы такого размера не велик.
По умолчанию ESXi выделяет память большим страницам. Разбивание больших страниц на маленькие начинается при достижении порога состояния High и происходит принудительно, когда достигается состояние Clear (см. таблицу состояний гипервизора).
Если же вы хотите, чтобы TPS начинал работу, не дожидаясь заполнения оперативной памяти хоста, в Advanced Options ESXi нужно установить значение “Mem.AllocGuestLargePage” в 0 (по умолчанию 1). Тогда выделение больших страниц памяти для виртуальных машин будет отключено.
С декабря 2014 во всех релизах ESXi TPS между ВМ по умолчанию отключен, так как была найдена уязвимость, теоретически позволяющая получить из одной ВМ доступ к оперативной памяти другой ВМ. Подробности тут. Информация про практическую реализацию эксплуатации уязвимости TPS мне не встречалось.
Политика TPS контролируется через advanced option “Mem.ShareForceSalting” на ESXi:
0 — Inter-VM TPS. TPS работает для страниц разных ВМ;
1 – TPS для ВМ с одинаковым значением “sched.mem.pshare.salt” в VMX;
2 (по умолчанию) – Intra-VM TPS. TPS работает для страниц внутри ВМ.
Однозначно имеет смысл выключать большие страницы и включать Inter-VM TPS на тестовых стендах. Также это можно использовать для стендов с большим количеством однотипных ВМ. Например, на стендах с VDI экономия физической памяти может достигать десятков процентов.
Memory Ballooning. Ballooning уже не такая безобидная и прозрачная для операционной системы ВМ техника, как TPS. Но при грамотном применении с Ballooning’ом можно жить и даже работать.
Вместе с Vmware Tools на ВМ устанавливается специальный драйвер, называемый Balloon Driver (он же vmmemctl). Когда гипервизору начинает не хватать физической памяти и он переходит в состояние Soft, ESXi просит ВМ вернуть неиспользуемую оперативную память через этот Balloon Driver. Драйвер в свою очередь работает на уровне операционной системы и запрашивает свободную память у нее. Гипервизор видит, какие страницы физической памяти занял Balloon Driver, забирает память у виртуальной машины и возвращает хосту. Проблем с работой ОС не возникает, так как на уровне ОС память занята Balloon Driver’ом. По умолчанию Balloon Driver может забрать до 65% памяти ВМ.
Если на ВМ не установлены VMware Tools или отключен Ballooning (не рекомендую, но есть KB:), гипервизор сразу переходит к более жестким техникам отъема памяти. Вывод: следите, чтобы VMware Tools на ВМ были.

Работу Balloon Driver’а можно проверить из ОС через VMware Tools.
Memory Compression. Данная техника применяется, когда ESXi доходит до состояния Hard. Как следует из названия, ESXi пытается сжать 4 Кбайт страницы оперативной памяти до 2 Кбайт и таким образом освободить немного места в физической памяти сервера. Данная техника значительно увеличивает время доступа к содержимому страниц оперативной памяти ВМ, так как страницу надо предварительно разжать. Иногда не все страницы удается сжать и сам процесс занимает некоторое время. Поэтому данная техника на практике не очень эффективна.
Memory Swapping. После недолгой фазы Memory Compression ESXi практически неизбежно (если ВМ не уехали на другие хосты или не выключились) переходит к Swapping’у. А если памяти осталось совсем мало (состояние Low), то гипервизор также перестает выделять ВМ страницы памяти, что может вызвать проблемы в гостевых ОС ВМ.
Вот как работает Swapping. При включении виртуальной машины для нее создается файл с расширением .vswp. По размеру он равен незарезервированной оперативной памяти ВМ: это разница между сконфигурированной и зарезервированной памятью. При работе Swapping’а ESXi выгружает страницы памяти виртуальной машины в этот файл и начинает работать с ним вместо физической памяти сервера. Разумеется, такая такая “оперативная” память на несколько порядков медленнее настоящей, даже если .vswp лежит на быстром хранилище.
В отличие от Ballooning’а, когда у ВМ отбираются неиспользуемые страницы, при Swapping’e на диск могут переехать страницы, которые активно используются ОС или приложениями внутри ВМ. В результате производительность ВМ падает вплоть до подвисания. ВМ формально работает и ее как минимум можно правильно отключить из ОС. Если вы будете терпеливы 
Если ВМ ушли в Swap — это нештатная ситуация, которую по возможности лучше не допускать.
Основные счетчики производительности памяти виртуальной машины
Вот мы и добрались до главного. Для мониторинга состояния памяти в ВМ есть следующие счетчики:
Active — показывает объем оперативной памяти (Кбайт), к которому ВМ получила доступ в предыдущий период измерения.
Usage — то же, что Active, но в процентах от сконфигурированной оперативной памяти ВМ. Рассчитывается по следующей формуле: active ÷ virtual machine configured memory size.
Высокий Usage и Active, соответственно, не всегда является показателем проблем производительности ВМ. Если ВМ агрессивно использует память (как минимум, получает к ней доступ), это не значит, что памяти не хватает. Скорее это повод посмотреть, что происходит в ОС.
Есть стандартный Alarm по Memory Usage для ВМ:

Shared — объем оперативной памяти ВМ, дедуплицированной с помощью TPS (внутри ВМ или между ВМ).
Granted — объем физической памяти хоста (Кбайт), который был отдан ВМ. Включает Shared.
Consumed (Granted — Shared) — объем физической памяти (Кбайт), которую ВМ потребляет с хоста. Не включает Shared.
Если часть памяти ВМ отдается не из физической памяти хоста, а из swap-файла или память отобрана у ВМ через Balloon Driver, данный объем не учитывается в Granted и Consumed.
Высокие значения Granted и Consumed — это совершенно нормально. Операционная система постепенно забирает память у гипервизора и не отдает обратно. Со временем у активно работающей ВМ значения данных счетчиков приближается к объему сконфигурированной памяти, и там остаются.
Zero — объем оперативной памяти ВМ (Кбайт), который содержит нули. Такая память считается гипервизором свободной и может быть отдана другим виртуальным машинам. После того, как гостевая ОС получила записала что-либо в зануленную память, она переходит в Consumed и обратно уже не возвращается.
Reserved Overhead — объем оперативной памяти ВМ, (Кбайт) зарезервированный гипервизором для работы ВМ. Это небольшой объем, но он обязательно должен быть в наличии на хосте, иначе ВМ не запустится.
Balloon — объем оперативной памяти (Кбайт), изъятой у ВМ с помощью Balloon Driver.
Compressed — объем оперативной памяти (Кбайт), которую удалось сжать.
Swapped — объем оперативной памяти (Кбайт), которая за неимением физической памяти на сервере переехала на диск.
Balloon и остальные счетчики memory reclamation techniques равны нулю.
Вот так выглядит график со счетчиками Memory нормально работающей ВМ со 150 ГБ оперативной памяти.
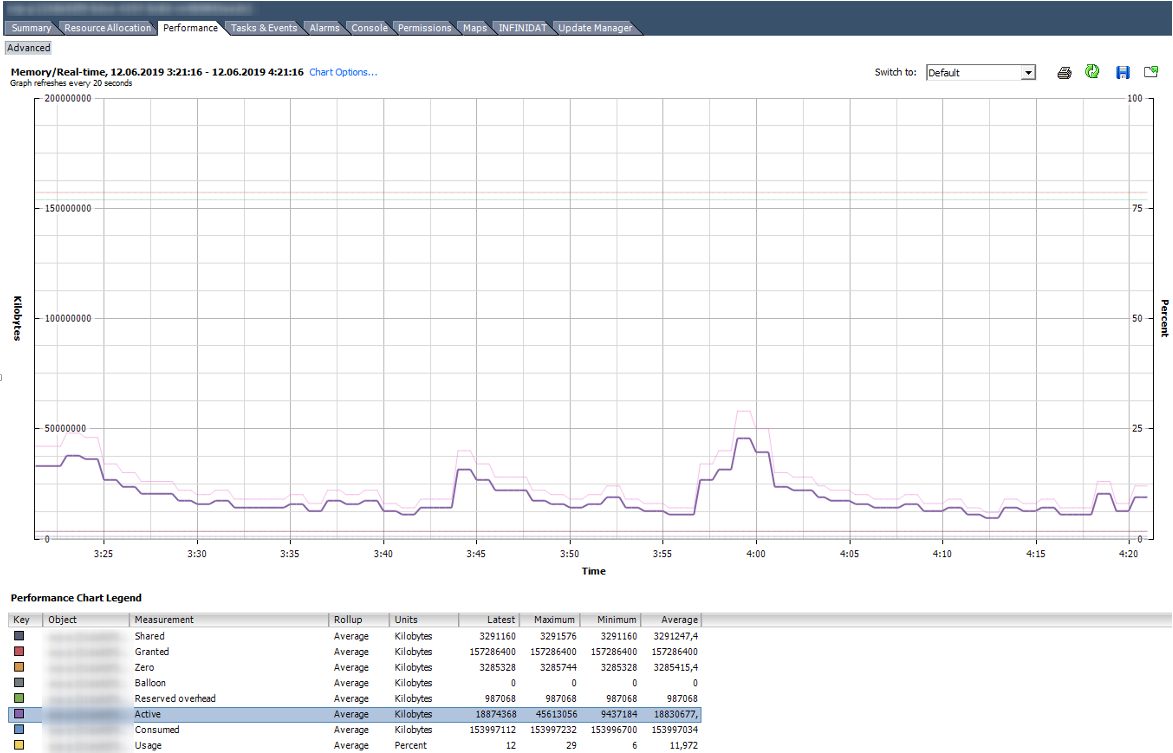
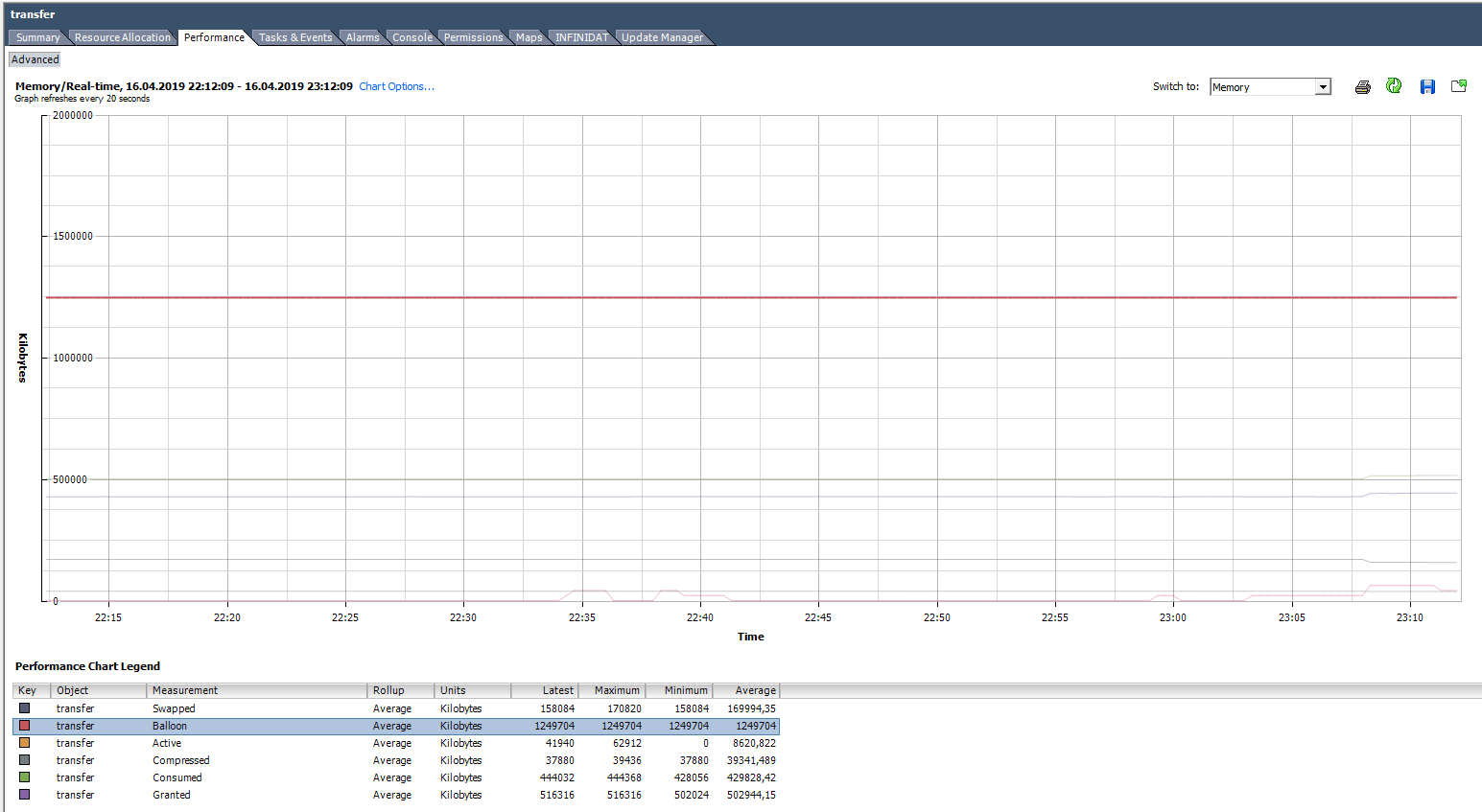
На графике ниже у ВМ явные проблемы. Под графиком видно, что для данной ВМ были использованы все описанные техники работы с оперативной памятью. Balloon для данной ВМ сильно больше, чем Consumed. По факту ВМ скорее мертва, чем жива.
ESXTOP
Как и с CPU, если хотим оперативно оценить ситуацию на хосте, а также ее динамику с интервалом до 2 секунд, стоит воспользоваться ESXTOP.
Экран ESXTOP по Memory вызывается клавишей «m» и выглядит следующим образом (выбраны поля B,D,H,J,K,L,O):
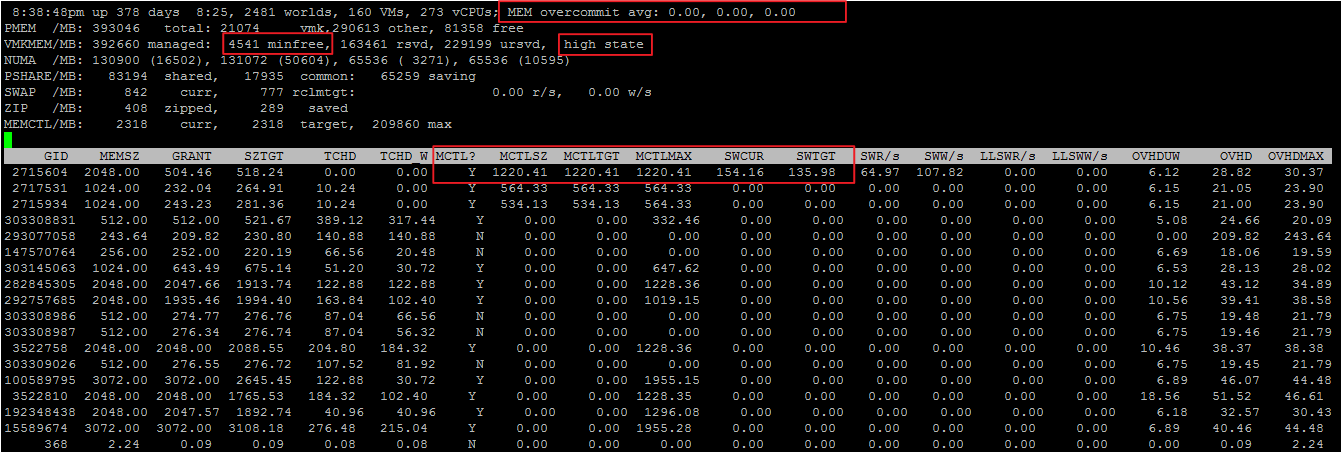
Интересными для нас будут следующие параметры:
Mem overcommit avg — среднее значение переподписки по памяти на хосте за 1, 5 и 15 минут. Если выше нуля, то это повод посмотреть, что происходит, но не всегда показатель наличия проблем.
В строках PMEM/MB и VMKMEM/MB — информация о физической памяти сервера и памяти доступной VMkernel. Из интересного здесь можно увидеть значение minfree (в МБайт), состояние хоста по памяти (в нашем случае, high).
В строке NUMA/MB можно увидеть распределение оперативной памяти по NUMA-нодам (сокетам). В данном примере распределение неравномерное, что в принципе не очень хорошо.
Далее идет общая статистика по серверу по memory reclamation techniques:
PSHARE/MB — это статистика TPS;
SWAP/MB — статистика использования Swap;
ZIP/MB — статистика компрессии страниц памяти;
MEMCTL/MB — статистика использования Balloon Driver.
По отдельным ВМ нас может заинтересовать следующая информация. Имена ВМ я скрыл, чтобы не смущать аудиторию:). Если метрика ESXTOP аналогична счетчику в vSphere, привожу соответствующий счетчик.
MEMSZ — объем памяти, сконфигурированный на ВМ (МБ).
MEMSZ = GRANT + MCTLSZ + SWCUR + untouched.
GRANT — Granted в МБайт.
TCHD — Active в МБайт.
MCTL? — установлен ли на ВМ Balloon Driver.
MCTLSZ — Balloon в МБайт.
MCTLGT — объем оперативной памяти (МБайт), который ESXi хочет изъять у ВМ через Balloon Driver (Memctl Target).
MCTLMAX — максимальный объем оперативной памяти (МБайт), который ESXi может изъять у ВМ через Balloon Driver.
SWCUR — текущий объем оперативной памяти (МБайт), отданный ВМ из Swap-файла.
SWGT — объем оперативной памяти (МБайт), который ESXi хочет отдавать ВМ из Swap-файла (Swap Target).
Также через ESXTOP можно посмотреть более подробную информацию про NUMA-топологию ВМ. Для этого нужно выбрать поля D,G:

NHN – NUMA узлы, на которых расположена ВМ. Здесь можно сразу заметить wide vm, которые не помещаются на один NUMA узел.
NRMEM – сколько мегабайт памяти ВМ берет с удаленного NUMA узла.
NLMEM – сколько мегабайт памяти ВМ берет с локального NUMA узла.
N%L – процент памяти ВМ на локальном NUMA узле (если меньше 80% — могут возникнуть проблемы с производительностью).
Memory на гипервизоре
Если счетчики CPU по гипервизору обычно не представляют особого интереса, то с памятью ситуация обратная. Высокий Memory Usage на ВМ не всегда говорит о наличие проблемы с производительностью, а вот высокий Memory Usage на гипервизоре, как раз запускает работу техник управления памятью и вызывает проблемы с производительностью ВМ. За алармами Host Memory Usage надо следить и не допускать попадания ВМ в Swap.


Unswap
Если ВМ попала в Swap, ее производительность сильно снижается. Следы Ballooning’а и компрессии быстро исчезают после появления свободной оперативной памяти на хосте, а вот возвращаться из Swap в оперативную память сервера виртуальная машина совсем не торопится.
До версии ESXi 6.0 единственным надежным и быстрым способ вывода ВМ из Swap была перезагрузка (если точнее выключение/включение контейнера). Начиная с ESXi 6.0 появился хотя и не совсем официальный, но рабочий и надежный способ вывести ВМ из Swap. На одной из конференций мне удалось пообщаться с одним из инженеров VMware, отвечающим за CPU Scheduler. Он подтвердил, что способ вполне рабочий и безопасный. В нашем опыте проблем с ним также замечено не было.
Собственно команды для вывода ВМ из Swap описал Duncan Epping. Не буду повторять подробное описание, просто приведу пример ее использования. Как видно на скриншоте, через некоторое время после выполнения указанной команд Swap на ВМ исчезает.

Советы по управлению оперативной памятью на ESXi
Напоследок приведу несколько советов, которые помогут вам избежать проблем с производительностью ВМ из-за оперативной памяти:
- Не допускайте переподписки по оперативной памяти в продуктивных кластерах. Желательно всегда иметь ~20-30% свободной памяти в кластере, чтобы у DRS ( и у администратора) было пространство для маневра, и при миграции ВМ не ушли в Swap. Также не забывайте про запас для отказоустойчивости. Неприятно, когда при выходе из строя одного сервера и перезагрузке ВМ с помощью HA часть машин еще и уходит в Swap.
- В инфраструктурах с высокой консолидацией старайтесь НЕ создавать ВМ с памятью больше половины памяти хоста. Это опять же поможет DRS’у без проблем распределять виртуальные машины по серверам кластера. Это правило, разумеется, не универсальное :).
- Следите за Host Memory Usage Alarm.
- Не забывайте ставить на ВМ VMware Tools и не выключайте Ballooning.
- Рассмотрите возможность включения Inter-VM TPS и выключения Large Pages в средах с VDI и тестовых средах.
- Если ВМ испытывает проблемы с производительностью, проверьте не использует ли она память с удаленной NUMA-ноды.
- Выводите ВМ из Swap как можно быстрее! Помимо всего прочего, если ВМ в Swap’е, по очевидным причинам страдает СХД.
На этом про оперативную память у меня все. Ниже статьи по теме для тех, кто хочет углубиться в детали. Следующая статья будет посвящена стораджу.
Примерно 2,5 года назад вышел документ по решению проблем с производительностью в VMware vSphere 4.1.
Так как актуальность документ все еще не потерял, я попробую осуществить его перевод…
В начале документа находится схема траблшутинга

Соответственно, есть две дальнейшие диаграммы: базовая и продвинутая.
Базовая.

Возможные проблемы упорядочены по принадлежности (с VMware Tools, CPU, etc) и по их влиянию (от 100% влияния на производительность до возможного).
Проверка VMware Tools.
- Выберите хост в vClient;
- Перейдите на вкладку Virtual Machines;
- Добавьте столбец «VMware Tools Status»;
- Оцените статус. OK->возвращаемся к диаграмме траблшутинга. Not Running/Out of date — устраняем.
Если VMware Tools не запущены, необходимо разбираться с гостевой операционной системой. Причина может скрываться в обновлении ядра Linux либо отключенной (кем-то) службе VMware Tools в Windows.
Если VMware Tools устарели, необходимо их обновить из контекстного меню vClient. Как правило, это случается после установки обновлений на хосты ESX/ESXi. После этого зачастую требуется обновить и VMware Tools.
Проверка загрузки процессора в пуле ресурсов (Resource Pool CPU Saturation).
Если используете пулы ресурсов и лимит на процессорные ресурсы пула, то читайте дальше. В противном случае сразу идите в следующий блок Host CPU Saturation.
- Выберите пул ресурсов и перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «CPU»;
- Оцените текущую загрузку в MHz (Usage);
- Сравните значение лимита пула ресурсов и текущую загрузку. Если текущая загрузка близка к лимиту, возможно, имеет место нехватка процессорных ресурсов и вам необходимо оценить значение CPU Ready отдельных виртуальных машин в этом пуле;
Проверка CPU Ready:
- Для измерения CPU Ready выберите одну из виртуальных машин (далее ВМ) в пуле, перейдите на вкладку Performance, выберите режим «Advanced» и переключитесь в обзор «CPU» (если вы решаете проблему производительности определенной ВМ, начните с нее);
- Оцените значение Ready для всех «объектов» ВМ. Отдельным «объектом» является каждый виртуальный процессор ВМ. Вам будет необходимо изменить свойства графика «Chart Options…» для отображения этого графика;
- Среднее или максимальное значение Ready для любого виртуального процессора превышает 2000мс? Если да, то у вас наблюдается нехватка процессорных ресурсов из-за установленного лимита на пул ресурсов;
- Повторите для всех ВМ этого пула.
На следующем рисунке проиллюстрирован этот пример

Проверка загрузки процессора хоста (Host CPU Saturation).
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «CPU»;
- Оцените текущую загрузку в MHz (Usage);
- Превышает ли средняя загрузка 75% или пиковая — 90%? Если да, возможно, вам не хватает процессорных ресурсов хоста. Проверьте CPU Ready у ВМ этого хоста как показано ниже. Если средняя загрузка ЦП не превышает 75%, перейдите к следующему блоку…
Проверка CPU Ready:
- Если вы решаете проблему производительности определенной ВМ, начните с нее. В противном случае выберите хост, перейдите на вкладку Virtual Machines, отсортируйте список по столбцу Host CPU — MHz и проверьте одну-две ВМ из начала списка;
- Для измерения CPU Ready выберите ВМ, перейдите на вкладку Performance, выберите режим Advanced и переключитесь в обзор «CPU» (если вы решаете проблему производительности определенной ВМ, начните с нее);
- Оцените значение Ready для всех «объектов» виртуальной машины. Отдельным «объектом» является каждый виртуальный процессор ВМ. Вам будет необходимо изменить свойства графика «Chart Options…» для отображения этого графика;
- Среднее или максимальное значение Ready для любого виртуального процессора превышает 2000мс? Если да, то у вас наблюдается нехватка процессорных ресурсов хоста.
Схему анализа данного раздела также можно посмотреть на следующем рисунке:

Загрузка процессора ВМ (Guest CPU Saturation).
- Выберите ВМ с проблемами по производительности, перейдите на вкладку Performance, выберите режим Advanced и переключитесь в обзор «CPU»;
- Оцените уровень загрузки ЦП ВМ;
- Превышает ли средняя загрузка 75% или пиковая — 90%? Если да, возможно, вам не хватает процессорных ресурсов.
Проверка ВМ на активное использование свопа (Active VM Memory Swapping).
Нехватка памяти хоста или пула ресурсов может повлечь за собой активное использование технологии Host Swap. А это в свою очередь резко снизит производительность как одной ВМ, так и нескольких «соседних».
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Memory». Необходимо будет добавить счетчики «Swap in rate» и «Swap out rate».
- Оцените показатели «Swap in rate» и «Swap out rate»;
- Если значения счетчиков больше нуля, то у хоста имеются проблемы с памятью.
Также можно проверить это значение для конкретной ВМ хоста:
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Memory»;
- Измените свойства графика (Chart Options…);
- Выберите Memory/Real-Time, смените тип графика на Stacked Graph (per VM). Выберите все ВМ и счетчики «Swap in rate» и «Swap out rate» для них;
- Если значения счетчиков больше нуля, имеются проблемы с памятью.
Примечание: если хост является частью DRS-кластера, следует оценить также загрузку по памяти остальных хостов.
Проверка ВМ на использование свопа в прошлом (VM Swap Wait).
Нехватка памяти в прошлом может вызвать выгрузку страниц памяти ВМ на диск сервера (Host Swap). ESXi не осуществляет загрузку неиспользуемой ВМ памяти обратно в память хоста, поэтому вы можете сталкиваться с замедлением в работе ВМ, пока такие страницы будут прочитаны с диска.
- Выберите ВМ с проблемами по производительности, перейдите на вкладку Performance, выберите режим Advanced и переключитесь в обзор «CPU»;
- Оцените значение Swap Wait для ВМ. Его будет необходимо добавить в свойствах графика;
- Содержит ли последний столбец ненулевое значение (столбец average)? Если да, тормоза ВМ из-за свопа. Самое простое решение — перезагрузка ВМ. Если нет — возвращаемся к базовой диаграмме.
Проверка ВМ на «заархивированность» памяти (VM Memory Compression).
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Memory»;
- Оцените счетчики «Compression rate» и «Decompression rate». Да, их придется добавить 🙂 ;
- Принимали ли эти счетчики значения выше 0? Если да, на хосте имелись проблемы с нехваткой памяти (да и сейчас, быть может, имеются). Если нет, возвращаемся к базовой диаграмме;
Также можно проверить «заархивированность» памяти у ВМ:
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Memory»;
- Измените свойства графика (Chart Options…);
- Выберите Memory/Real-Time, смените тип графика на Stacked Graph (per VM). Выберите все ВМ и счетчики «Compression rate» и «Decompression rate» для них;
- Ненулевые значения будут свидетельствовать о нехватке памяти.
Примечание: если ВМ находится в пуле ресурсов DRS-кластера, следует оценить также загрузку остальных хостов.
Проверка перегруженности СХД (Overloaded Storage Device).
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Disk»;
- Добавьте на график счетчик «Commands aborted»;
- Если значение счетчика отлично от нуля, у вас проблемы на стороне СХД. В противном случае ищем дальше.
Проверка на отброс принимаемых пакетов (Dropped Receive Packets).
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Network»;
- Выберите счетчик Receive Packets Dropped для всех адаптеров vmnic*;
- Значение больше нуля? Если да, отправляйтесь решать сетевые проблемы. Нет, продолжаем искать причину тормозов.
Проверка на отброс отправляемых пакетов (Dropped Transmit Packets).
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Network»;
- Выберите счетчик Transmit Packets Dropped для всех адаптеров vmnic*;
- Значение больше нуля? Если да, отправляйтесь решать сетевые проблемы. Нет, продолжаем искать причину тормозов.
На этом «ясные» причины заканчиваются и начинаются нюансы…
Проверка, что во многопроцессорной ВМ используется только один vCPU (one vCPU in an SMP VM).
Если у ВМ несколько виртуальных процессоров (vCPU), возможно, гостевая ОС некорректно настроена и не использует все vCPU.
- Выберите ВМ, перейдите на вкладку Performance, выберите режим Advanced и переключитесь в обзор «CPU»;
- Оцените загрузку в MHz (Usage MHz) для всех vCPU;
- Загрузка для одного vCPU большая, для остальных — близка к нулю? Да, ваша ВМ использует только один vCPU, смотрите раздел решения проблем с ЦП. Нет — продолжаем поиски.
Проверка CPU Ready у ВМ на средне-нагруженном хосте.
Если на ВМ нагрузка появляется всплесками, то даже с невысокой средней загрузкой ЦП хоста ВМ может испытывать проблемы производительности.
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «CPU»;
- Счетчик Usage достаточно большой, но не превышает 95%?
- Выберите проблемную ВМ, перейдите на вкладку Performance, выберите режим Advanced и переключитесь в обзор «CPU»;
- Включите отображение счетчика Ready для всех vCPU;
- Есть ли промежутки времени, когда Ready для любого процессора больше 1000ms? Если есть — идем и решаем проблемы с ЦП. Нет — ищем причины дальше.
Если на хосте есть другие ВМ, потенциально испытывающие проблемы — проверьте CPU Ready и у них.
Проверка медленного или перегруженного СХД.
Проверим наличие задержек на СХД:
- Выберите проблемную ВМ, перейдите на вкладку Performance, выберите режим Advanced и переключитесь в обзор «Virtual Disk»;
- Выберите отображение всех дисков и счетчиков «Read Latency»/»Write Latency»;
- Превышают ли задержки 50ms? Если да, определенные проблемы есть, идем проверять очереди.
Проверка задержки очередей:
- Выберите хост с проблемной ВМ, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Disk»;
- Включите отображение счетчика «Queue Command Latency» для всех хранилищ;
- Превышает ли величина задержки 0ms? Если превышает, то вам необходимо увеличить максимальную глубину очереди устройства, после чего измерить задержки физического устройства.
Измерение задержек физического устройства:
- Выберите хост с проблемной ВМ, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Disk»;
- Выберите счетчики «Physical Device Read Latency» и «Physical Device Write Latency» для всех хранилищ;
- Превышает ли величина задержек 50ms? Если да, мы имеем дело с перегруженным по вводу/выводу СХД. Идите в набор решений для СХД (ниже в документе).
Примечание: 50ms — это верхняя граница, когда все может функционировать. Возможно, в вашем случае это будет 30ms или даже 20ms!
Проверка пиковых нагрузок на СХД.
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Disk»;
- Выберите счетчики «Physical Device Read Latency» и «Physical Device Write Latency» для всех хранилищ;
- Имеются ли на графике пики, превышающие 20ms, даже если среднее значение ниже 10ms? Если да, мы имеем дело с перегруженным по вводу/выводу СХД
Проверка наличия пиков в передаче данных на сеть.
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Network»;
- Оцените «Data Transmit Rate» и «Data Receive Rate»;
- Есть ли периоды, когда пиковая нагрузка превышает 90% на какой-то адаптер? Если да, у вас могут быть проблемы из-за сети, смотрите набор решений под сеть. Если нет, идите и решайте проблему далее.
Проверка низкой загрузки процессора ВМ.
Если загрузка процессора ВМ низкая, но ВМ тормозит, могут быть некоторые проблемы с конфигурацией.
- Выберите проблемную ВМ, перейдите на вкладку Performance, выберите режим Advanced и переключитесь в обзор «CPU»;
- Оцените величину счетчика «Usage»;
- Среднее значение ниже 75%? Возможно, есть некоторые проблемы, которые необходимо «порешать». Идем в раздел решения проблем с ЦП. Если тормоза затрагивают весь хост, повторяем процедуру с остальными ВМ с хоста.
Проверка того, что память ВМ в прошлом была помещена в своп (Past VM Memory Swapping).
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Memory»;
- Добавьте счетчик «Swap Used»;
- Значение счетчика больше нуля? Если да, хост в прошлом активно использовал своп. Читайте решение проблем с памятью. Для определения проблемной ВМ (которая «ушла» в своп) читайте дальше.
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Memory»;
- Выберите тип графика «Stacked Graph (Per VM)» и добавьте счетчик «Swap Used»;
- ВМ, у которых это значение ненулевое, могут испытывать из-за этого проблемы с производительностью.
Проверка нехватки памяти в пуле ресурсов.
Проверяем использование ballooning:
- Выберите пул ресурсов, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Memory»;
- Оцените счетчик «Ballooning»;
- Значение больше нуля? Возможно, в пуле ресурсов сильная конкуренция за память. Оцените «Balooning» отдельных ВМ.
- Выберите хост, являющийся частью DRS-кластера, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Memory»;
- В свойствах графика выберите типа графика «Stacked Graph (Per VM)». Добавьте счетчик «Balloon»;
- Оцените значение счетчика для ВМ, являющихся частью пула. Больше ли оно нуля? Если да, то нехватка памяти вызывает своп в гостевой ОС. Читайте раздел по устранению проблем с ОЗУ. Если нет — повторите операцию с остальными хостами DRS-кластера. Если и там так же — ищем причины дальше.
Проверка нехватки памяти на хосте.
- Выберите хост, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Memory»;
- Оцените счетчик «Ballooning»;
- Значение больше нуля? Возможно, в пуле ресурсов сильная конкуренция за память. Оцените «Balooning» отдельных ВМ.
- В свойствах графика выберите типа графика «Stacked Graph (Per VM)». Добавьте счетчик «Balloon»;
- Оцените значение счетчика для ВМ. Больше ли оно нуля? Если да, то нехватка памяти вызывает своп в гостевой ОС. Читайте раздел по устранению проблем с ОЗУ.
Нехватка памяти для гостевой ОС (High Guest Memory Demand).
- Выберите ВМ, перейдите на вкладку Performance, там переключитесь в режим «Advanced» и выберите объект «Memory»;
- Добавьте счетчик «Usage» и оцените его значение;
- Среднее значение превышает 80%, а пики — 90%? Скорее всего, ВМ не хватает оперативной памяти. Отправляйтесь в раздел устранения проблем с памятью.
Продвинутая диаграмма

Для решения вышеуказанных проблем мы будем использовать esxtop.
Проверка наличия проблем с прерываниями (High Timer-Interrupt Rates).
- Запускаем esxtop/resxtop;
- Выбираем экран ЦП, нажав «c»;
- Добавляем «Summary Stats», нажав «f» и затем «i». Нажмите любую клавишу для возвращения в основной экран esxtop;
- Оцените счетчик «Times/S»;
- Он больше 1000 для любой ВМ? Если да, необходимо снизить количество прерываний, прочитав соответствующие рекомендации.
Проверяем наличие косяков с NUMA.
- Запускаем esxtop/resxtop;
- Выбираем экран ОЗУ, нажав «m»;
- Добавим «Numa Stats», нажав «f» и затем «g». Нажмите любую клавишу для возвращения в основной экран esxtop;
- Оцените счетчик «N%L» для всех ВМ. Если столбец не видно на экране, необходимо нажать «o» и несколько раз «G», для передвижения счетчиков «NUMA» поближе к началу;
- Если «N%L» меньше 80% для какой-то ВМ, то ВМ имеет косяки с точки зрения Numa-архитектуры. Проследуйте в раздел решения проблем с Numa.
Проверка большого времени отклика у ВМ со снапшотами.
- Запускаем esxtop/resxtop;
- Выбираем экран виртуальных дисков, нажав «v»;
- Если не отображаются задержки, включим их отображение, нажав «f», а затем «g» и «h». Нажмите любую кнопку, чтобы вернуться в основной экран esxtop;
- Оцените значения «LAT/rd» и «LAT/wr» для ВМ со снапшотами. Данные значения отражают средние величины задержек при операциях ввода-вывода;
- Перейдите на экран с дисковыми устройствами, нажав «u»;
- Если задержки не отображаются по умолчанию, добавьте требуемые поля, нажав «f», а затем «j» и «k». Нажмите любую кнопку, чтобы вернуться в основной экран esxtop;
- Оцените значения «QUED», «DAVG/rd» и «DAVG/wr». «QUED» показывает текущее значение дисковой очереди на LUN. DAVG/* — среднее время отклика устройства;
- Значение очереди равно нулю? Задержки на экране «виртуального диска» значительно превышают задержки физического LUN? Если да, то проблема в снапшотах ВМ.
To be continued…
Рекомендации по решению проблем ждите в следующей статье/переводе.
Приложение VMware показывает «Недостаточно физической памяти» в основном из-за конфликтующих обновлений Windows. Также эта ошибка может быть вызвана неоптимальными настройками VMware или устаревшей версией VMWare. Это сообщение об ошибке появляется, когда пользователь пытается загрузить компьютер из неактивного состояния. Это сообщение об ошибке обычно не означает, что у вас меньше физической памяти; вместо этого обычно это связано с несоответствиями программного обеспечения между VMware и компьютером.
Недостаточно физической ошибки памяти в VMware
Мы обнаружили, что эта проблема возникает в основном после обновления программного обеспечения VMware или изменения настроек приложения. Это очень распространенное сообщение об ошибке, и его можно устранить с помощью методов, перечисленных ниже, если на самом деле у вас недостаточно памяти для включения виртуальной машины.
Что вызывает ошибку «Недостаточно физической памяти» в VMware?
- Конфликт Центра обновления Windows: VMware в прошлом страдал от ошибки «Недостаточно физической памяти» из-за конфликтующих обновлений Windows. Текущее возникновение этого также может быть результатом конфликтующего обновления Windows.
- Отсутствие прав администратора. Для завершения работы VMware необходим доступ администратора к различным файлам / службам / ресурсам среды хоста. Если вы используете VMware без прав администратора, VMware может показать обсуждаемую ошибку.
- Устаревшая версия VMware: программные приложения обновляются для повышения производительности и исправления лазеек. VMware работает весьма деликатно, и если среда хоста была обновлена, это может повлиять на работу VMware и, таким образом, привести к тому, что пользователь столкнется с текущей ошибкой VMware.
- Конфликтующие приложения. Некоторые приложения конфликтуют с VMware и могут вызвать возникшую ошибку. Обратите внимание, что приложения виртуальной среды создают много помех в работе друг друга.
- Неоптимальные настройки VMware: вы можете настроить VMware по своему вкусу, но некоторые пользователи в этом процессе заставляют VMware работать в неоптимальных настройках, что в конечном итоге приводит к тому, что VMware показывает существующую проблему.
- Неправильная конфигурация VMware: VMware использует определенный объем оперативной памяти хоста, но при неправильной настройке этот параметр может заставить VMware показать текущую ошибку памяти.
Прежде чем приступить к решению, приведенному ниже, убедитесь, что в вашей системе достаточно оперативной памяти для запуска VMware. Если нет, то добавьте больше памяти в вашу систему и установите размер файла подкачки не менее 16 ГБ.
1. Используйте безопасный режим или чистую загрузку Windows
Могут быть приложения, которые могут мешать нормальной работе VMware, особенно другие приложения виртуальной среды, такие как Virtual Box и т. Д. Чтобы исключить это, используйте встроенный безопасный режим Windows или чистую загрузку Windows.
- Чистая загрузка Windows или загрузка Windows в безопасном режиме.
- Запустите VMware, чтобы проверить, работает ли он без проблем.
Если VMware работает нормально в среде чистой загрузки или в безопасном режиме, попробуйте найти конфликтующее приложение и попытаться решить проблему между приложениями.
2. Удалите конфликтующее обновление Windows
Microsoft выпускает обновления для своих продуктов для улучшения функций и исправления лазеек. Но у Microsoft есть известная история выпуска обновлений с ошибками. Если ошибка VMware из-за недостатка физической памяти начала возникать сразу после обновления Windows, то удаление этого обновления может помочь нам.
Предупреждение: отключение обновления не рекомендуется, так как это может стать угрозой безопасности; действовать на свой страх и риск.
- Нажмите клавишу Windows, затем введите «Настройки» и в появившемся списке нажмите «Настройки».
Открыть настройки в Windows Search
- Теперь нажмите «Обновление и безопасность».
Откройте «Обновление и безопасность» в настройках Windows
- Теперь нажмите на Центр обновления Windows, а затем на Просмотр истории обновлений.
Просмотреть историю обновлений Windows
- Нажмите Удалить обновления, чтобы удалить последние обновления из вашей системы.
Удалить обновления в истории обновлений
- Теперь выберите обновление, которое, по вашему мнению, создает проблему, нажмите «Удалить» и следуйте инструкциям на экране, чтобы завершить процесс удаления.
- Перезагрузите систему, а затем проверьте, нормально ли начал работать VMware.
Помните, что вы должны удалить последние обновления Windows по одному и проверять VMware, пока не найдете проблемное обновление. После удаления проблемного обновления переустановите другие обновления и скрывайте это конкретное обновление, пока проблема не будет решена Microsoft или VMware.
3. Запустите VMware от имени администратора
VMware необходим неограниченный доступ к различным системным файлам, сервисам и ресурсам. Если безопасность Windows ограничивает доступ VMware к определенным файлам, службам и ресурсам, то VMware выдаст ошибку «Недостаточно физической памяти». В этом случае запуск VMware с правами администратора может решить проблему.
- Выключите VMware.
- Нажмите клавишу Windows и введите VMware Workstation.
- Щелкните правой кнопкой мыши VMware Workstation и выберите «Открыть местоположение файла».
- Щелкните правой кнопкой мыши значок VMware Workstation и выберите «Свойства».
- Затем перейдите на вкладку «Совместимость» и установите флажок «Запускать эту программу от имени администратора».
Проверьте Запуск от имени администратора
- Нажмите Применить, а затем ОК.
- Теперь запустите VMware Workstation, чтобы проверить, работает ли он нормально без каких-либо проблем.
4. Обновите VMware до последней сборки
Новые технологии появляются изо дня в день на горизонте И.Т. Мир. Каждое программное приложение обновляется в соответствии с этими новыми технологиями. Если среда вашего хоста была обновлена до последней сборки, но вы используете устаревшую версию VMware, то вы можете столкнуться с обсуждаемым сообщением об ошибке. В этом случае обновление VMware до последней сборки может решить проблему.
Обычно, когда доступно обновление, пользователи получают приглашение при запуске VMware. Пользователи также могут использовать пользовательский интерфейс рабочей станции и выбрать «Справка»> «Обновления программного обеспечения». Но если у вас возникли проблемы с использованием VMware, выполните следующие действия.
- Откройте веб-браузер вашей системы и перейдите к Официальная страница загрузки VMware Workstation,
- Теперь нажмите Download Now согласно вашей ОС.
Загрузите последнюю версию VMware Workstation
- Ознакомьтесь с лицензионным соглашением с конечным пользователем и нажмите «Принять», чтобы принять лицензионное соглашение.
- Нажмите Загрузить сейчас и дождитесь завершения процесса загрузки.
- Затем щелкните правой кнопкой мыши загруженный файл и выберите «Запуск от имени администратора».
- Следуйте инструкциям на экране для завершения процесса установки.
- Затем запустите VMware, чтобы убедиться, что в нем недостаточно физической памяти.
5. Измените настройки VMware на Оптимальные
Настройки VMware позволяют пользователю настроить систему по своему вкусу. Но во время этого процесса пользователи иногда устанавливают неоптимальные настройки VMware, что в конечном итоге приводит к тому, что VMware выдает ошибку нехватки физической памяти.
- Выключите гостевую ОС.
- Запустите VMware Workstation, затем нажмите «Изменить» и выберите «Настройки».
- Теперь в левой части окна «Настройки» нажмите «Память».
- Поместить всю память виртуальной машины в зарезервированную хост-память: этот параметр следует выбирать, если у вас большая память
- Разрешить замену большей части памяти виртуальной машины: этот параметр следует выбирать, если у вас немного больше памяти и вы хотите, чтобы виртуальная машина работала более плавно.
- Разрешить обмен некоторой памяти виртуальной машины: этот параметр следует выбирать, если у вас мало памяти.
Включите параметр «Разрешить обмен большей части памяти виртуальной машины»
В данном сценарии вы должны выбрать второй или третий вариант в соответствии с вашим состоянием, но мы рекомендуем использовать третий вариант.
- Нажмите кнопку ОК, чтобы сохранить изменения.
- Затем запустите гостевую ОС и проверьте, нормально ли она работает сейчас.
6. Измените файл config.ini
Если до сих пор у вас ничего не получалось, проблема может быть решена путем добавления или изменения файла конфигурации, чтобы ограничить использование VMware Workstation в процентах от доступной оперативной памяти хоста. Это гарантирует, что виртуальная машина будет использовать только 75% оперативной памяти хоста.
- Завершите работу всех гостевых операционных систем и закройте рабочую станцию VMware.
- Перейдите по следующему пути
C: ProgramData VMware VMware Workstation.
и откройте файл config.ini. Если его там нет, создайте его.
- Прокрутите до конца файла и добавьте туда следующую строку:
vmmon.disableHostParameters = «ИСТИНА».Изменить файл Config.ini
Затем сохраните файл и перезагрузите систему.
- После перезапуска системы щелкните правой кнопкой мыши значок VMware на рабочем столе и выберите «Запуск от имени администратора».
Если у вас по-прежнему возникают проблемы с работой гостевой ОС, то вам может помочь создание новой виртуальной машины с правильным объемом памяти и последующее подключение существующего жесткого диска к новой виртуальной машине.
March 7, 2013 by aubreykloppers
Our ESXi hosts are running out of memory – oh no they’re not!
Scenario:
ESXi 4.1 host with 60GB memory, 17 X Windows 7 guests with 2GB memory, 3 x Windows 2008 guests with 4GB memory, and 1 x Windows 2008 guest with 8GB memory; and the host reports a “Host memory usage” warning – how come VMware’s superb memory management systems have not kicked in?

Answer:
In the scenario above; adding up the memory given to the guests, this comes to 54GB, and when looking at the host memory usage, it was recording nearly 56GB memory usage (57344MB.)

Any VMware veteran would look at this situation and think “How odd, how come the TPS (Transparent Page Sharing) has not kicked in!”
The image below shows host memory claimed by the guests and configured memory size.

To see that TPS is not working, quickest way is to click on a guest in the vSphere client, and go to the resource allocation tab. In the image below notice there is no shared memory (below was for one of the Windows 7 guests)

To see shared memory in action, one would expect to something more like the example in the below image where there is 1.64GB shared, or greater than 50% (this was for a Windows 7 guest configured with 3GB memory.)

What is going on?
The answer is found in Matt Liebowitz’s excellent article – VMware KB Clarifies Page Sharing on Nehalem Processors:
And specifically the paragraph:
“VMware has published a KB article that gives more information on TPS with Nehalem processors and why it appears TPS isn’t working (this affects modern AMD processors also). The short version is that TPS uses small pages (4K), and Nehalem processors utilize large pages (2MB). The ESX/ESXi host keeps track of what pages could be shared, and once memory is over-comitted it breaks the large pages into small pages and begins sharing memory.”
There is a solution if this behaviour is proving to be unsettling (will not say fix as technically everything is fine.)
“You can force the use of small pages on all guests all the time by changing the value of the advanced option Mem.AllocGuestLargePage to 0” on your hosts and then VMotion the VMs off and back on to the host, or cold boot them.
In the scenario above; with TPS in effect, very roughly around 50% of the memory consumed by guests would be reclaimed, and the 60GB host would be showing only around 30GB memory usage.
THE END
Category: Firewall, Internet, IT, Unix, VM
Table of contents
- Section 1. Why VMware reports physical memory is n ot enough?
- Section 2. How to fix VMware not enough physical memory issue?
- Section 3. Backup your VM with an easy solution
- Conclusion

Issue: VMware not enough physical memory
VMware is a very professional hypervisor. Thousands of people have use it to create and manage virtual machines When it provides convenience to users, sometimes it could also bring trouble. Maybe you have lived a happy life with your VMs, while someday, you could not power on the VMs and a prompt says Not enough physical memory to power on this virtual machine with its configured setting.

Users have complaint that their VMs worked perfectly on VMware before but suddenly it could be accessed. Some users open the task manager on the host machine, only to find that there is more than 10GB memory not used. So is this a bug? You would get to know the reasons and how to fix the problem in this passage.
Section 1. Why VMware reports physical memory is not enough?
How much memory do you need to support powering on VM? According to VMware, 2GB RAM is the least requirement for hosting a VM, so your computer should have 4GB RAM or more. If you want to make VM run fluently, you’d better allocate at least 4GB RAM to a single VM. Insufficient memory could also lead to slow performance on VMware virtual machine.
Back to our topic, why it reports insufficient memory? It could be caused by real memory shortage , outdated configuration, or some system glitches.
You might allocated too much memory to your VM, but your other applications, including other VMs, have used too much memory on your computer, so you can’t start this VM.
Besides the real memory shortage, your other applications could also use memory. Sometimes you might find enough memory left in task manager but your VM still ask for memory, it might because that some applications or services lock down memory so that your VM can’t use the memory.
P.S. Internal storage of VM could be expanded when it is sufficient. Refer to Increase VMware Virtual Machine Disk Size and Expand Partition.
Section 2. How to fix VMware not enough physical memory issue?
Since you have known the possible causes of this issue, you could solve it with the following solutions.
Solution 1. Decrease VM memory
Your VM are asking for too much memory. This solution would guide you to modify the metrics after VM has been created.
Open your VMware > go to Edit > click Preferences > click Memory > drag the Slider to adjust the Reserved memory to 2GB or less > move to Additional memory > select Allow most virtual machine memory to be swapped. Then your VM could be started.
Solution 2. Reboot your computer
Rebooting could help you fix most of system issue and release RAM, so you should run the failed VM first after rebooting in case of RAM is used or locked by other applications or services.
Solution 3. Run VMware as Administrator
Completely shut up VMware > navigate to the location of VMware in File Explore > right-click the icon of VMware > select Properties > click Compatibility tab > tick “Run this program as an administrator” > click OK. Then you could try starting the failed VM.
Solution 4. Modify the config.ini file
Locate config.ini file. It might be at C:Documents and SettingsAll UsersApplication DataVMwareVMware Workstation or C:ProgramDataVMwareVMware Workstation > open the file (you’d better open it as Administrator) > find “prefvmx.useRecommendedLockedMemSize =” and add “TRUE” after “=” > find “prefvmx.minVmMemPct =” and add “1” after “=” > save the file > restart your computer and try running the failed VM
Tips:
If you can’t find the two lines in the file, directly add “prefvmx.useRecommendedLockedMemSize = TRUE” and “prefvmx.useRecommendedLockedMemSize = 1” in the end of the file.
Solution 5. Update your VMware
If your VM works perfectly before, but it failed this time because “physical memory is not enough”, the recent update of your operating system might be the fault.
According to real cases, some Mac users update their operating system to macOS Big Sur and and the alert “vmware fusion not enough physical memory is available to power on” appears when they try launching VM via VMware Fusion 11. After upgrade it to VMware Fusion 12, the issue gets fixed.
In fact, VMware also gives a table on their website to tell which operating system supports which edition of VMware product. If you are wondering whether your new operating system supports your old VMware, go to VMware’s website to consult the support team.
Solution 6. Create a new VM
Creating a new VM to replace the failed VM might fix the issue but the point is that you have no important data on the old virtual machine so you could delete it as you wish.
Backing up your VM is necessary. If you have missed backing up your VM machine, don’t forget to backup your new VMs.
Section 3. Backup your VM with an easy solution
Traditionally, backing up VM is not so easy as backing up physical machine for you need to deploy agent on VMs, while Vinchin Backup & Recovery has broken the bottleneck of technology to let you backup your VM with deploying agent. Want to find more features of Vinchin Backup & Recovery? Just try it.

Agentless backup: VMware backup and management never become so convenient. Vinchin Backup & Recovery would help you reduce both workload and maintenance cost.
Instant Recovery: Guarantee your business uptime always at a high level. Once your VMs are down for some reasons, they would be recovered on other host machines in 15 seconds, seamlessly recover your business.
Cloud Archive: Vinchin Backup & Recovery allows you to easily get history backup copies archived to multiple cloud storages including AWS S3, AlibabaCloud and Azure Blob Storage.
Conclusion
When you try powering on you VM with VMware hypervisor, you might receive the error message that Not enough physical memory to power on this virtual machine with its configured setting. If so, your RAM might be in real shortage, or you need to modify relative configuration.
This passage has given you 6 useful solutions to fix the issue. If they help you solve the problem, you could share it on social media to help more people.