Обновлено 01.04.2019
Ошибка vsphere ha virtual machine monitoring error
Всем привет сегодня расскажу, как решается и из-за чего выскакивает ошибка vsphere ha virtual machine monitoring error и vsphere ha virtual machine monitoring action. Данная ошибка вполне может перезагрузить виртуальную машину, нештатно завершив все рабочие процессы, ладно если это случиться в вечернее время, с минимальными последствиями для клиентов, а если в самый час пик, это очень сильно ударит по репутации компании и может повлечь денежные убытки.
Вот более наглядное представление этих ошибок в VMware vCenter 5.5.
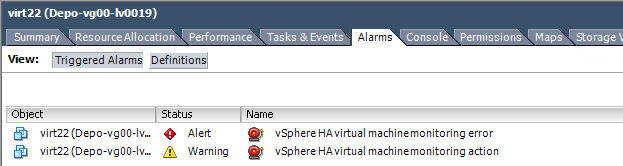
Ошибка vsphere ha virtual machine monitoring error-02
Видим сначала идет предупреждение и потом alert
vsphere ha virtual machine monitoring error
vsphere ha virtual machine monitoring action
Анализ log файла
Сначала нужно проанализировать лог файл виртуальной машины, для этого щелкаем правым кликом по datastore и выбираем browse datastore
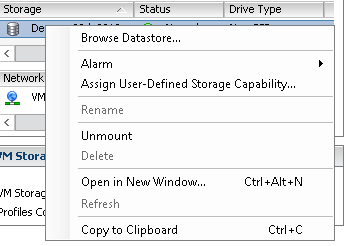
browse datastore vmware
Переходим в нужную папку виртуальной машины и находим там файл vmware.log
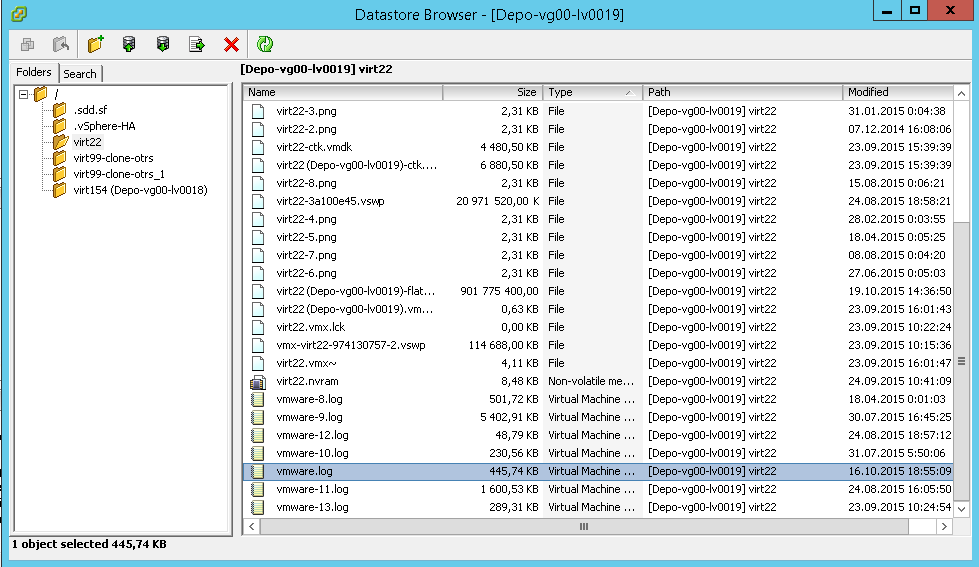
ищем vmware.log
Этот файл vmware.log, нам нужно скачать, сделать это можно к сожалению только на выключенной виртуальной машине, щелкаем по нему правым кликом и выбираем Download
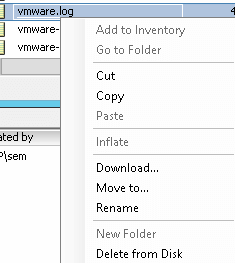
скачиваем лог файл
Указываем место куда нужно закачать ваш файл, для дальнейшего изучения. Все ошибки в данном файле в большинстве случаев сводятся к необходимости обновить vmware tools
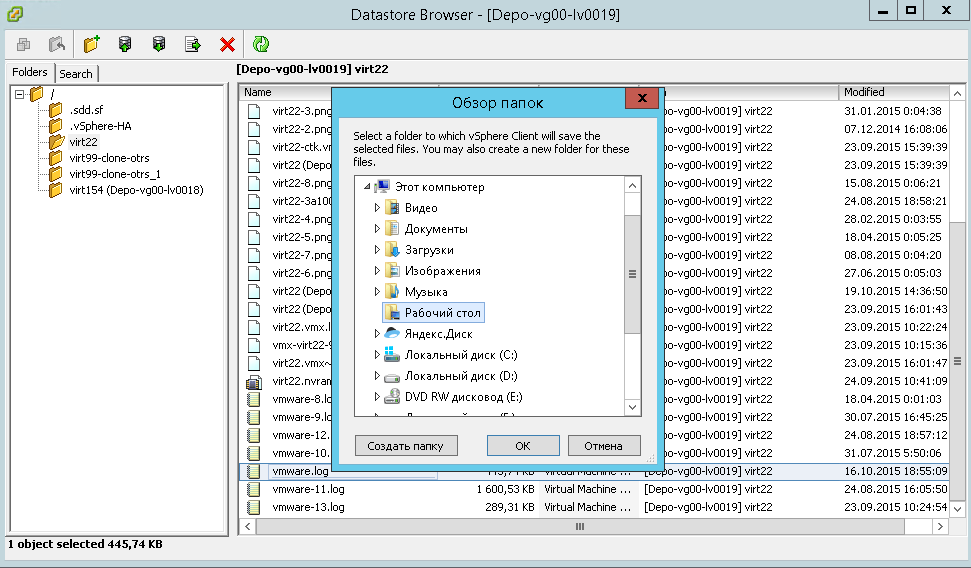
сохранение vmware.log
То же самое вы можете увидеть и на Vmware ESXI 6.5. (VMware Tools is not installed on this virtual machine)
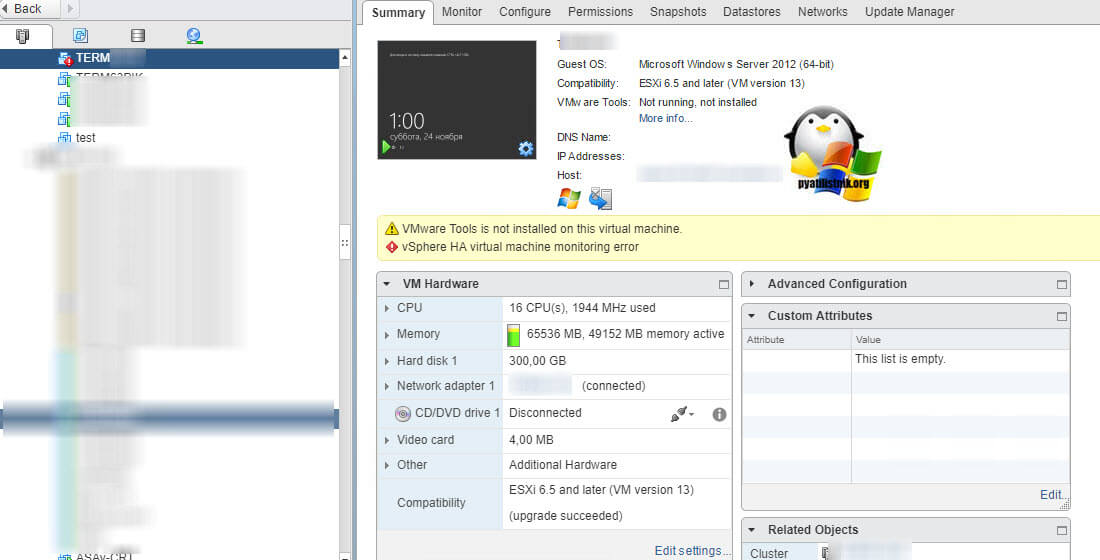
Обновление vmware tools
Напомню vmware tools это пакет драйверов который устанавливается внутри виртуальной машины для лучшей интеграции и расширения функционала. Как обновить vmware tools в VMware ESXI 5.5 я рассказывал ранее. Еще отмечу, что вначале вам придется удалить Vmware Tools из гостевой операционной системы, так как смонтировать диск с дистрибутивом для обновления вы не сможете, так как поле будет не активно.
Так же если вы будите медлить с решением данной проблемы, вы будите постоянно ловить синий экран с кодом 0x00000050. При его анализе он будет ругаться на драйвера.
Надеюсь что вы теперь поняли из за чего происходит alert vsphere ha virtual machine monitoring error. Материал сайта pyatilistnik.org
Содержание
- Vsphere ha virtual machine monitoring error
- Анализ log файла
- Обновление vmware tools
- vSphere HA virtual machine monitoring error on VM
- Leave a Reply Cancel reply
- vSphere HA virtual machine monitoring action alarm
- Popular Topics in VMware
- 7 Replies
- Read these next.
- poor wifi, school’s third floor
- Need help crafting a job posting for an IT Pro
- Snap! — AI Eye Contact, Mine Batteries, Headset-free Metaverse, D&D Betrayal
- Spark! Pro series – 13th January 2023
- Vsphere ha virtual machine monitoring error
- Vsphere ha virtual machine monitoring error
Vsphere ha virtual machine monitoring error
Ошибка vsphere ha virtual machine monitoring error
Всем привет сегодня расскажу, как решается и из-за чего выскакивает ошибка vsphere ha virtual machine monitoring error и vsphere ha virtual machine monitoring action. Данная ошибка вполне может перезагрузить виртуальную машину, нештатно завершив все рабочие процессы, ладно если это случиться в вечернее время, с минимальными последствиями для клиентов, а если в самый час пик, это очень сильно ударит по репутации компании и может повлечь денежные убытки.
Вот более наглядное представление этих ошибок в VMware vCenter 5.5.
Ошибка vsphere ha virtual machine monitoring error-02
Видим сначала идет предупреждение и потом alert
vsphere ha virtual machine monitoring action
Анализ log файла
Сначала нужно проанализировать лог файл виртуальной машины, для этого щелкаем правым кликом по datastore и выбираем browse datastore
browse datastore vmware
Переходим в нужную папку виртуальной машины и находим там файл vmware.log
Этот файл vmware.log, нам нужно скачать, сделать это можно к сожалению только на выключенной виртуальной машине, щелкаем по нему правым кликом и выбираем Download
скачиваем лог файл
Указываем место куда нужно закачать ваш файл, для дальнейшего изучения. Все ошибки в данном файле в большинстве случаев сводятся к необходимости обновить vmware tools
То же самое вы можете увидеть и на Vmware ESXI 6.5. (VMware Tools is not installed on this virtual machine)
Обновление vmware tools
Напомню vmware tools это пакет драйверов который устанавливается внутри виртуальной машины для лучшей интеграции и расширения функционала. Как обновить vmware tools в VMware ESXI 5.5 я рассказывал ранее. Еще отмечу, что вначале вам придется удалить Vmware Tools из гостевой операционной системы, так как смонтировать диск с дистрибутивом для обновления вы не сможете, так как поле будет не активно.
Так же если вы будите медлить с решением данной проблемы, вы будите постоянно ловить синий экран с кодом 0x00000050. При его анализе он будет ругаться на драйвера.
Источник
vSphere HA virtual machine monitoring error on VM
Today I found a couple of VMs in a cluster, that had HA with VM monitoring enabled, that were showing a “vSphere HA virtual machine monitoring error” with a couple of different dates.
Looking into the event log of the VM via vCenter I could see the following events about every 20 seconds:

This indicated that HA VM monitoring wanted to reset the VM but failed. I tried searching for answers on first Google but with no luck. I remembered that the setup had vRealize Log Insight installed and collecting data so perhaps Log Insight had more logs to look at.
Made a simple filter on the VM name and found repeating logs starting with this error from “fdm” which is the HA component on the ESXi host.

This error looks bad to me. Not being able to find the MoRef of a running VM? Hmm. I asked out on Twitter if anyone had seen this before with out much luck. Think about it over lunch I figured that maybe it was the host that was running the VM that had gotten into some silly state about the VM and not knowing it’s MoRef. So the quick fix I tried was to simply do a compute and storage migration of the VM to a different host and a different datastore to clean up any stale references to files or the VM world running. The event log of the VM immediately stopped spamming the HA message and returned to normal after migration.
I cannot say for sure what caused the issue and what the root cause is but that at least solved it.
Leave a Reply Cancel reply
This site uses Akismet to reduce spam. Learn how your comment data is processed.
Источник
vSphere HA virtual machine monitoring action alarm
vmware vSphere client is reading an error on one of our virtual servers and I can’t find any information on what it means.
«vSphere HA virtual machine monitoring action alarm»
Anyone run into this before?

Popular Topics in VMware

Do you have a HA cluster setup?
Any chance of a screenshot of the alarm?

check the uptime of the Guest OS of the VM with that triggered alert. Very probably the VM was restarted by HA VM Monitoring since there was no heartbeat from VMtools and there was not disk/network activity on the VM.
You can also check the VM’s folder in the datastore browser. Before resetting the VM the ESXi host should have taken the screenshot of the VM’s console, and quite often it is a picture of BSOD.

Did you ever get this one resolved? Do you have vCenter to use to try and get more details on the error / at least provide a screenshot as Gary suggested?
I cleared the alarm and have been waiting for it to reappear but it hasn’t yet. Once it does (and it will) I’ll post screenshots. Thank you everyone!
The alarm came back.
Here is the screenshot you asked for.


We just had one of these too. Windows Server 2008 R2 VM, it has BSOD’s and rebooted unexpectedly. Fairly sure that was what caused the VMware warning.

This topic has been locked by an administrator and is no longer open for commenting.
To continue this discussion, please ask a new question.
Read these next.

poor wifi, school’s third floor
I work as a help desk technician at a high school for a school district. Teachers/students on the building’s third floor have been reporting poor wifi, with their Chromebooks/laptops etc experiencing slow connectivity and random disconnections. We hav.

Need help crafting a job posting for an IT Pro
I’d really appreciate some thoughts and advice. I’m looking to hire an IT pro to be our resident go-to for all things IT (device support, SQL Server, network admin, etc) but who also is interested in learning — or even has some experience in — the.

Snap! — AI Eye Contact, Mine Batteries, Headset-free Metaverse, D&D Betrayal
Your daily dose of tech news, in brief. Welcome to the Snap! Flashback: January 13, 1874: Adding Machine Patented (Read more HERE.) Bonus Flashback: January 13, 1990: Astronauts awakened to the song Attack of the Killer Tomatoes (Read mor.

Spark! Pro series – 13th January 2023
Happy Friday the 13th! This day has a reputation for being unlucky, but I hope that you’ll be able to turn that around and have a great day full of good luck and good fortune. Whether you’re superstitious or not, .
Источник
Vsphere ha virtual machine monitoring error
Anyone tell me what is the process behind this .
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
What you may check is whether the VM for which the alarm was triggered has VMware Tools installed (i.e. VM heartbeat is working) and/or whether the VM stops responding (e.g. BSOD in case of Windows, panic in case of Linux, Sleep Mode/Power Saving enabled in the VM, . ) for any reason.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I have checked the vm , thats working fine and vmware tools also running . no problem related to vm , any other reason for that , expecting your valuable comments.
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Maybe the VM’s vmware .log as well as the host’s log files (see e.g. http://kb.vmware.com/kb/1027734) contain information!?

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
We had also enabled this parameter in our environment and we started getting too many alerts however the vm’s were just fine.
We then disabled it
any slight change in the vm can trigger it. Not necessary the vm has to be down. This is just a warning.
Enable the error setting and talk/discuss to colleagues to disable it
Источник
Vsphere ha virtual machine monitoring error
I have a linux guest vm that was reset early 1 morning because of the above HA message after coming out of a VDP backup snapshot but I was wondering if it should have been and what if anything I should do to make sure either my HA settings are appropriate for the cluster or vm or whether I need to make other changes to avoid the issue happening when least appropriate
Below are the events as listed on vSphere for the vm in question. It is very large and there could have been alot of guest disk i/o during the snap to consolidate
The guest doesn’t appear to be showing any ill effects I’m just not sure why it was reset
| Time | Event Description | Type | My Notes |
|---|---|---|---|
| 01:23:14 am | Task Create virtual machine snapshot | info | Within VDP backup window |
| 05:31:49 am | Task Remove snapshot | info | |
| 06:22:37 am | vSphere HA cannot reset this virtual machine | warning | |
| 06:22:38 am | Alarm vSphere HA virtual machine monitoring error changed from Gray to Red | info | |
| 06.22:38 am | Alarm vSphere HA virtual machine monitoring error on GUESTVM triggered an action | info | |
| 06.22:38 am | Alarm vSphere HA virtual machine monitoring error an SNMP trap was sent | info | GUEST VM in DMZ and on different vlan to vCenter or hosts |
| 06.23:16 am | vSphere HA cannot reset this virtual machine | warning | |
| 06.23.52 am | Virtual machine disks consolidated successded | info | |
| 06.23.59 am | Message from ESXiHost: Install the VMware tools package inside this virutal machine | info | vmware tools was already installed and matches host |
| 06.23.59 am | This virtual machine reset by vSphere HA: VMware Tools heartbeat failure: A screen shot is saved in /datastore/vm/vm-1.png | info | Guest OS was still running in the image, no screen of death |
| 06.23.59 am | Alarm vSphere HA virtual machine monitoring action changed from Green to Yellow | info |
» jive-data-header=»<«color»:»#FFFFFF»,»backgroundColor»:»#6690BC»,»textAlign»:»center»,»padding»:»2″,»fontFamily»:»arial,helvetica,sans-serif»,»verticalAlign»:»baseline»>» style=»border: 1px solid rgb(0, 0, 0); width: 838px; height: 378px;»>
Given HA & the vm are set up as follows
- HA Cluster Settings:
- cluster default vm restart priority: Medium
- Guest restart priority: High
- Datastore heartbeat: 2 datastores (1 hosting the guest vm the other hosting the vdp appliance)
- VM Settings
- Linux Guest
- vmxnet 3 vNic connected to DMZ vlan
- vm version 7:
There was some disk latency warnings before the backup snapshots were created but no loss of paths to either the guest vm datastore or the backup destination was reported
Am I right in thinking that HA shouldn’t have been triggered due to the disk I/O from the consolidation of the snapshot even if it was taking a long time?
Источник
Posted by ITsPhil 2016-06-27T14:11:02Z
vmware vSphere client is reading an error on one of our virtual servers and I can’t find any information on what it means.
«vSphere HA virtual machine monitoring action alarm»
Anyone run into this before?
7 Replies
-
Do you have a HA cluster setup?
Any chance of a screenshot of the alarm?
Was this post helpful?
thumb_up
thumb_down
-

check the uptime of the Guest OS of the VM with that triggered alert. Very probably the VM was restarted by HA VM Monitoring since there was no heartbeat from VMtools and there was not disk/network activity on the VM.
You can also check the VM’s folder in the datastore browser. Before resetting the VM the ESXi host should have taken the screenshot of the VM’s console, and quite often it is a picture of BSOD.
1 found this helpful
thumb_up
thumb_down
-
Did you ever get this one resolved? Do you have vCenter to use to try and get more details on the error / at least provide a screenshot as Gary suggested?
Was this post helpful?
thumb_up
thumb_down
-
I cleared the alarm and have been waiting for it to reappear but it hasn’t yet. Once it does (and it will) I’ll post screenshots. Thank you everyone!
Was this post helpful?
thumb_up
thumb_down
-
The alarm came back.
Here is the screenshot you asked for.
Was this post helpful?
thumb_up
thumb_down
-
We just had one of these too. Windows Server 2008 R2 VM, it has BSOD’s and rebooted unexpectedly. Fairly sure that was what caused the VMware warning.
Was this post helpful?
thumb_up
thumb_down
-
one of my VM’s just did this after going from 2008 to 2012 server. Shut down the VM, cleared the error and turned VM back on. All good now. VMNOMAD answer was sort of spot on.
Was this post helpful?
thumb_up
thumb_down
You can monitor your cluster for HA related issues by setting up alarms. The are a number of default alarms, including these cluster alarms:
- Cannot find master – Default alarm to alert when vCenter Server has been unable to connect to a vSphere HA master agent for a prolonged period
- Insufficient failover resources – Default alarm to alert when there are insufficient cluster resources for vSphere HA to guarantee failover
- Failover in progress – Default alarm to alert when vSphere HA is in the process of failing over virtual machines
There are also these virtual machine alarms:
- VM monitoring error – Default alarm to alert when vSphere HA failed to reset a virtual machine
- VM monitoring action – Default alarm to alert when vSphere HA reset a virtual machine
- Failover failed – Default alarm to alert when vSphere HA failed to failover a virtual machine
And there is the following host related alarm:
- HA status – Default alarm to monitor health of a host as reported by vSphere HA
To configure these default alarms, using the vSphere client, highlight the vCenter server object, then click onto the Alarms tab:

As with other alarms, you can configure it so a notification email or snmp trap is sent if the alarm is triggered, or you can have it take one of these other actions:
- Run a command
- Power on VM
- Power off VM
- Suspend VM
- Reset VM
- Migrate VM
- Reboot Guest VM
- Shutdown Guest VM

Sending Notification Emails and SNMP Traps
Remember that if you are choosing the send notification emails or SNMP traps then you need to configure the appropriate vCenter server settings. For email:
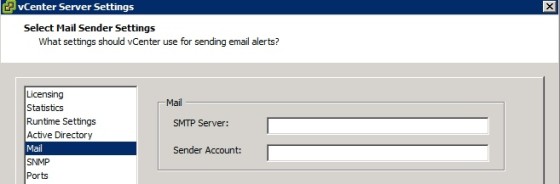
And for SNMP:
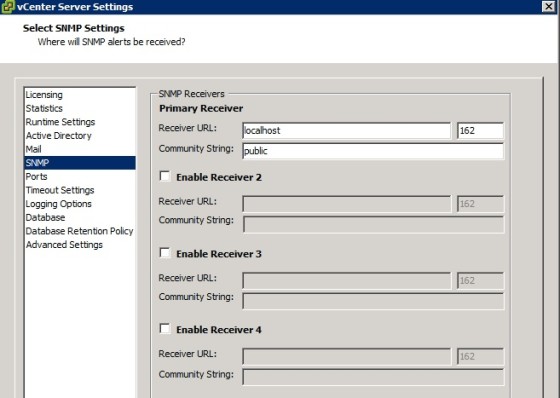
Monitoring a HA Cluster
Along with the alarms you can configure, there are a few other ways in which you can monitor your cluster. The cluster summary tab has a lot of information regarding the health of the cluster:

The ‘Cluster Status’ link will show any current issues with the cluster’s hosts, it will show how many VMs are protected by HA and will show which hosts are using which datastores for their datastore heartbeating:

The ‘Configuration Issues’ link will display any current configuration issues with the cluster:

Here we are at the end of Section 7, Objective 7.5 – Troubleshoot HA and DRS Configurations and Fault Tolerance. Sorry for the delay in getting these together, I was actually sitting a vSphere 6.5 ICM course for the past week.
As always, this article is linked to from the main VCP6.5-DCV Blueprint.
Happy Revision
Simon
Objective 7.5 – Troubleshoot HA and DRS Configurations and Fault Tolerance
Troubleshoot issues with:
DRS workload balancing
Load Imbalance on Cluster
A cluster has a load imbalance of resources.
A cluster might become unbalanced because of uneven resource demands from virtual machines and unequal capacities of hosts.
The following are possible reasons why the cluster has a load imbalance:
- The migration threshold is too high.
A higher threshold makes the cluster a more likely candidate for load imbalance.
- VM/VM or VM/Host DRS rules prevent virtual machines from being moved.
- DRS is disabled for one or more virtual machines.
- A device is mounted to one or more virtual machines preventing DRS from moving the virtual machine in order to balance the load.
- Virtual machines are not compatible with the hosts to which DRS would move them. That is, at least one of the hosts in the cluster is incompatible for the virtual machines that would be migrated. For example, if host A’s CPU is not vMotion-compatible with host B’s CPU, then host A becomes incompatible for powered-on virtual machines running on host B.
- It would be more detrimental for the virtual machine’s performance to move it than for it to run where it is currently located. This may occur when loads are unstable or the migration cost is high compared to the benefit gained from moving the virtual machine.
- vMotion is not enabled or set up for the hosts in the cluster.
DRS Seldom or Never Performs vMotion Migrations
DRS seldom or never performs vMotion migrations.
DRS does not perform vMotion migrations.
DRS never performs vMotion migrations when one or more of the following issues is present on the cluster.
- DRS is disabled on the cluster.
- The hosts do not have shared storage.
- The hosts in the cluster do not contain a vMotion network.
- DRS is manual and no one has approved the migration.
DRS seldom performs vMotion when one or more of the following issues is present on the cluster:
- Loads are unstable, or vMotion takes a long time, or both. A move is not appropriate.
- DRS seldom or never migrates virtual machines.
- DRS migration threshold is set too high.
DRS moves virtual machines for the following reasons:
- Evacuation of host that a user requested enter maintenance or standby mode.
- VM/Host DRS rules or VM/VM DRS rules.
- Reservation violations.
- Load imbalance.
- Power management.
HA failover/redundancy, capacity and network configuration
HA/DRS cluster configuration
Best Practices for Networking
Observe the following best practices for the configuration of host NICs and network topology for vSphere HA. Best Practices include recommendations for your ESXi hosts, and for cabling, switches, routers, and firewalls.
Network Configuration and Maintenance
The following network maintenance suggestions can help you avoid the accidental detection of failed hosts and network isolation because of dropped vSphere HA heartbeats.
- When changing the networks that your clustered ESXi hosts are on, suspend the Host Monitoring feature. Changing your network hardware or networking settings can interrupt the heartbeats that vSphere HA uses to detect host failures, which might result in unwanted attempts to fail over virtual machines.
- When you change the networking configuration on the ESXi hosts themselves, for example, adding port groups, or removing vSwitches, suspend Host Monitoring. After you have made the networking configuration changes, you must reconfigure vSphere HA on all hosts in the cluster, which causes the network information to be reinspected. Then re-enable Host Monitoring.
Networks Used for vSphere HA Communications
To identify which network operations might disrupt the functioning of vSphere HA, you must know which management networks are being used for heart beating and other vSphere HA communications.
- On legacy ESX hosts in the cluster, vSphere HA communications travel over all networks that are designated as service console networks. VMkernel networks are not used by these hosts for vSphere HA communications. To contain vSphere HA traffic to a subset of the ESX console networks, use the allowedNetworks advanced option.
- On ESXi hosts in the cluster, vSphere HA communications, by default, travel over VMkernel networks. With an ESXi host, if you want to use a network other than the one vCenter Server uses to communicate with the host for vSphere HA, you must explicitly enable the Management traffic check box.
To keep vSphere HA agent traffic on the networks you have specified, configure hosts so vmkNICs used by vSphere HA do not share subnets with vmkNICs used for other purposes. vSphere HA agents send packets using any pNIC that is associated with a given subnet when there is also at least one vmkNIC configured for vSphere HA management traffic. Therefore, to ensure network flow separation, the vmkNICs used by vSphere HA and by other features must be on different subnets.
Network Isolation Addresses
A network isolation address is an IP address that is pinged to determine whether a host is isolated from the network. This address is pinged only when a host has stopped receiving heartbeats from all other hosts in the cluster. If a host can ping its network isolation address, the host is not network isolated, and the other hosts in the cluster have either failed or are network partitioned. However, if the host cannot ping its isolation address, it is likely that the host has become isolated from the network and no failover action is taken.
By default, the network isolation address is the default gateway for the host. Only one default gateway is specified, regardless of how many management networks have been defined. Use the das.isolationaddress[…]advanced option to add isolation addresses for additional networks.
Network Path Redundancy
Network path redundancy between cluster nodes is important for vSphere HA reliability. A single management network ends up being a single point of failure and can result in failovers although only the network has failed. If you have only one management network, any failure between the host and the cluster can cause an unnecessary (or false) failover activity if heartbeat datastore connectivity is not retained during the networking failure. Possible failures include NIC failures, network cable failures, network cable removal, and switch resets. Consider these possible sources of failure between hosts and try to minimize them, typically by providing network redundancy.
The first way you can implement network redundancy is at the NIC level with NIC teaming. Using a team of two NICs connected to separate physical switches improves the reliability of a management network. Because servers connected through two NICs (and through separate switches) have two independent paths for sending and receiving heartbeats, the cluster is more resilient. To configure a NIC team for the management network, configure the vNICs in vSwitch configuration for Active or Standby configuration. The recommended parameter settings for the vNICs are:
- Default load balancing = route based on originating port ID
- Failback = No
After you have added a NIC to a host in your vSphere HA cluster, you must reconfigure vSphere HA on that host.
In most implementations, NIC teaming provides sufficient heartbeat redundancy, but as an alternative you can create a second management network connection attached to a separate virtual switch. Redundant management networking allows the reliable detection of failures and prevents isolation or partition conditions from occurring, because heartbeats can be sent over multiple networks. The original management network connection is used for network and management purposes. When the second management network connection is created, vSphere HA sends heartbeats over both management network connections. If one path fails, vSphere HA still sends and receives heartbeats over the other path.
Using IPv6 Network Configurations
Only one IPv6 address can be assigned to a given network interface used by your vSphere HA cluster. Assigning multiple IP addresses increases the number of heartbeat messages sent by the cluster’s master host with no corresponding benefit.
Best Practices for Interoperability
Observe the following best practices for allowing interoperability between vSphere HA and other features.
vSphere HA and Storage vMotion Interoperability in a Mixed Cluster
In clusters where ESXi 5.x hosts and ESX/ESXi 4.1 or earlier hosts are present and where Storage vMotion is used extensively or Storage DRS is enabled, do not deploy vSphere HA. vSphere HA might respond to a host failure by restarting a virtual machine on a host with an ESXi version different from the one on which the virtual machine was running before the failure. A problem can occur if, at the time of failure, the virtual machine was involved in a Storage vMotion action on an ESXi 5.x host, and vSphere HA restarts the virtual machine on a host with a version earlier than ESXi 5.0. While the virtual machine might power-on, any subsequent attempts at snapshot operations might corrupt the vdisk state and leave the virtual machine unusable.
Using Auto Deploy with vSphere HA
You can use vSphere HA and Auto Deploy together to improve the availability of your virtual machines. Auto Deploy provisions hosts when they power-on and you can also configure it to install the vSphere HA agent on hosts during the boot process. See the Auto Deploy documentation included in vSphere Installation and Setup for details.
Upgrading Hosts in a Cluster Using vSAN
If you are upgrading the ESXi hosts in your vSphere HA cluster to version 5.5 or later, and you also plan to use vSAN, follow this process.
- Upgrade all of the hosts.
- Disable vSphere HA.
- Enable vSAN.
- Re-enable vSphere HA.
Best Practices for Cluster Monitoring
Observe the following best practices for monitoring the status and validity of your vSphere HA cluster.
Setting Alarms to Monitor Cluster Changes
When vSphere HA or Fault Tolerance take action to maintain availability, for example, a virtual machine failover, you can be notified about such changes. Configure alarms in vCenter Server to be triggered when these actions occur, and have alerts, such as emails, sent to a specified set of administrators.
Several default vSphere HA alarms are available.
- Insufficient failover resources (a cluster alarm)
- Cannot find master (a cluster alarm)
- Failover in progress (a cluster alarm)
- Host HA status (a host alarm)
- VM monitoring error (a virtual machine alarm)
- VM monitoring action (a virtual machine alarm)
- Failover failed (a virtual machine alarm)
Creating a DRS Cluster
A cluster is a collection of ESXi hosts and associated virtual machines with shared resources and a shared management interface. Before you can obtain the benefits of cluster-level resource management you must create a cluster and enable DRS.
Admission Control and Initial Placement
When you attempt to power on a single virtual machine or a group of virtual machines in a DRS-enabled cluster, vCenter Server performs admission control. It checks that there are enough resources in the cluster to support the virtual machine(s).
Virtual Machine Migration
Although DRS performs initial placements so that load is balanced across the cluster, changes in virtual machine load and resource availability can cause the cluster to become unbalanced. To correct such imbalances, DRS generates migration recommendations.
DRS Cluster Requirements
Hosts that are added to a DRS cluster must meet certain requirements to use cluster features successfully.
Configuring DRS with Virtual Flash
DRS can manage virtual machines that have virtual flash reservations.
Create a Cluster
A cluster is a group of hosts. When a host is added to a cluster, the host’s resources become part of the cluster’s resources. The cluster manages the resources of all hosts within it. Clusters enable the vSphere High Availability (HA) and vSphere Distributed Resource Scheduler (DRS) solutions. You can also enable vSAN on a cluster.
Edit Cluster Settings
When you add a host to a DRS cluster, the host’s resources become part of the cluster’s resources. In addition to this aggregation of resources, with a DRS cluster you can support cluster-wide resource pools and enforce cluster-level resource allocation policies.
Set a Custom Automation Level for a Virtual Machine
After you create a DRS cluster, you can customize the automation level for individual virtual machines to override the cluster’s default automation level.
Disable DRS
You can turn off DRS for a cluster.
Restore a Resource Pool Tree
You can restore a previously saved resource pool tree snapshot.
vMotion/Storage vMotion configuration and/or migration
vMotion
The following are the actions that take place during a vMotion, understanding these steps will help in any troubleshooting efforts.
vMotion request is sent to the vCenter Server
During this stage, a call is sent to vCenter Server requesting the live migration of a virtual machine to another host. This call may be issued through the VMware vSphere Web Client, VMware vSphere Client or through an API call.
vCenter Server sends the vMotion request to the destination ESXi host
During this stage, a request is sent to the destination ESXi host by vCenter Server to notify the host for an incoming vMotion. This step also validates if the host can receive a vMotion. If a vMotion is allowed on the host, the host replies to the request allowing the vMotion to continue. If the host is not configured for vMotion, the host replies to the request disallowing the vMotion, resulting in a vMotion failure.
Common issues:
- Ensure that vMotion is enabled on all ESX/ESXi hosts.
- Determine if resetting the Migrate.Enabled setting on both the source and destination ESX or ESXi hosts addresses the vMotion failure.
- Verify that VMkernel network connectivity exists using vmkping.
- Verify that VMkernel networking configuration is valid.
- Verify that Name Resolution is valid on the host.
- Verify if the ESXi/ESX host can be reconnected or if reconnecting the ESX/ESXi host resolves the issue.
- Verify that you do not have two or more virtual machine swap files in the virtual machine directory.
- If you are migrating a virtual machine to or from a host running VMware ESXi below version 5.5 Update 2.
vCenter Server computes the specifications of the virtual machine to migrate
During this stage, details of the virtual machine are queried to notify the source and destination hosts of the vMotion task details. This may include any Fault Tolerance settings, disk size, vMotion IP address streams, and the source and destination virtual machine configuration file locations.
Common issues during this stage are:
- Verify that the virtual machine is not configured to use a device that is not valid on the target host. For more information.
vCenter Server sends the vMotion request to the source ESXi host to prepare the virtual machine for migration
During this stage, a request is made to the source ESXi host by vCenter Server to notify the host for an incoming vMotion. This step validates if the host can send a vMotion. If a vMotion is allowed on the host, the host replies to the request allowing the vMotion to continue. If the host is not configured for vMotion, the host will reply to the request disallowing the vMotion, resulting in a vMotion failure.
Once the vMotion task has been validated, the configuration file for the virtual machine is placed into read-only mode and closed with a 90 second protection timer. This prevents changes to the virtual machine while the vMotion task is in progress.
Common issue during this stage are:
- Ensure that vMotion is enabled on all ESX/ESXi hosts.
- Determine if resetting the Migrate.Enabled setting on both the source and destination ESX or ESXi hosts addresses the vMotion failure. For more information.
- Verify that VMkernel network connectivity exists using vmkping. For more information.
- Verify that VMkernel networking configuration is valid. For more information.
- Verify that Name Resolution is valid on the host. For more information.
- Verify if the ESXi/ESX host can be reconnected or if reconnecting the ESX/ESXi host resolves the issue.
vCenter Server initiates the destination host virtual machine
During this stage, the destination host creates, registers and powers on a new virtual machine. The virtual machine is powered on to a state that allows the virtual machine to consume resources and prepares it to receive the virtual machine state from the source host. During this time a world ID is generated that is sent to the source host as the target virtual machine for the vMotion.
Common issues:
- Verify that the required disk space is available.
- Verify that time is synchronized across environment. For more information.
- Verify that hostd is not spiking the console. For more information.
- Verify that valid limits are set for the virtual machine being vMotioned. For more information.
- Verify if the ESXi/ESX host can be reconnected or if reconnecting the ESX/ESXi host resolves the issue. For more information.
vCenter Server initiates the source host virtual machine
During this stage, the source host begins to migrate the memory and running state of the source virtual machine to the destination virtual machine. This information is transferred using VMkernel ports configured for vMotion. Additional resources are allocated for the destination virtual machine and additional helper worlds are created. The memory of the source virtual machine is transferred using checkpoints.
After the memory and virtual machine state is completed, a stun of the source virtual machine occurs to copy any remaining changes that occurred during the last checkpoint copy. Once this is complete the destination virtual machine resume as the primary machine for the virtual machine that is being migrated.
Common issues:
- If Jumbo Frames are enabled (MTU of 9000) (9000 -8 bytes (ICMP header) -20 bytes (IP header) for a total of 8972), ensure that vmkping is using the command:
vmkping -d -s 8972 destinationIPaddress
You may experience problems with the trunk between two physical switches that have been misconfigured to an MTU of 1500.
- Verify that valid limits are set for the virtual machine being vMotioned. For more information.
- Verify the virtual hardware is not out of date. For more information.
- This issue may be caused by SAN configuration. Specifically, this issue may occur if zoning is set up differently on different servers in the same cluster.
- Verify and ensure that the log.rotateSize parameter in the virtual machine’s configuration file is not set to a very low value. For more information.
- If you are migrating a 64-bit virtual machine, verify that the VT option is enabled on both the source and destination host. For more information.
- Verify that there are no issues with the shared storage or networking.
- If you are using NFS storage, verify if the VMFS volume containing the VMDK file of a virtual machine being migrated is on an NFS datastore and the datastore is not mounted differently on both the source and destination.
- If you are using VMware vShield Endpoint, verify the vShield Endpoint LKM is installed on the ESX/ESXi hosts to which you are trying to vMotion the virtual machine.
vCenter Server switches the virtual machine’s ESXi host from the source to destination
During this stage, the virtual machine is running on the destination ESXi host. vCenter Server will update to reflect this change by changing the virtual machines host and pool to the destination host. The source virtual machine is powered down and unregistered from the source host. Any resources that were in use are released back to the host.
vCenter Server completes the vMotion task
During this stage, the vMotion task is marked as complete.
Common issues during this stage are:
- Verify that Console OS network connectivity exists.
Troubleshooting Storage DRS
The Storage DRS troubleshooting topics provide solutions to potential problems that you might encounter when using Storage DRS-enabled datastores in a datastore cluster.
Storage DRS is Disabled on a Virtual Disk
Even when Storage DRS is enabled for a datastore cluster, it might be disabled on some virtual disks in the datastore cluster.
Datastore Cannot Enter Maintenance Mode
You place a datastore in maintenance mode when you must take it out of usage to service it. A datastore enters or leaves maintenance mode only as a result of a user request.
Storage DRS Cannot Operate on a Datastore
Storage DRS generates an alarm to indicate that it cannot operate on the datastore.
Moving Multiple Virtual Machines into a Datastore Cluster Fails
Migrating more than one datastore into a datastore cluster fails with an error message after the first virtual machine has successfully moved into the datastore cluster.
Storage DRS Generates Fault During Virtual Machine Creation
When you create or clone a virtual machine on a datastore cluster, Storage DRS might generate a fault.
Storage DRS is Enabled on a Virtual Machine Deployed from an OVF Template
Storage DRS is enabled on a virtual machine that was deployed from an OVF template that has Storage DRS disabled. This can occur when you deploy an OVF template on a datastore cluster.
Storage DRS Rule Violation Fault Is Displayed Multiple Times
When you attempt to put a datastore into maintenance mode, the same affinity or anti-affinity rule violation fault might appear to be listed more than once in the Faults dialog box.
Storage DRS Rules Not Deleted from Datastore Cluster
Affinity or anti-affinity rules that apply to a virtual machine are not deleted when you remove the virtual machine from a datastore cluster.
Alternative Storage DRS Placement Recommendations Are Not Generated
When you create, clone, or relocate a virtual machine, Storage DRS generates only one placement recommendation.
Applying Storage DRS Recommendations Fails
Storage DRS generates space or I/O load balancing recommendations, but attempts to apply the recommendations fail.
Fault Tolerance configuration and failover issues
Troubleshooting Fault Tolerant Virtual Machines
To maintain a high level of performance and stability for your fault tolerant virtual machines and also to minimize failover rates, you should be aware of certain troubleshooting issues.
The troubleshooting topics discussed focus on problems that you might encounter when using the vSphere Fault Tolerance feature on your virtual machines. The topics also describe how to resolve problems.
Hardware Virtualization Not Enabled
You must enable Hardware Virtualization (HV) before you use vSphere Fault Tolerance.
Compatible Hosts Not Available for Secondary VM
If you power on a virtual machine with Fault Tolerance enabled and no compatible hosts are available for its Secondary VM, you might receive an error message.
Secondary VM on Overcommitted Host Degrades Performance of Primary VM
If a Primary VM appears to be executing slowly, even though its host is lightly loaded and retains idle CPU time, check the host where the Secondary VM is running to see if it is heavily loaded.
Increased Network Latency Observed in FT Virtual Machines
If your FT network is not optimally configured, you might experience latency problems with the FT VMs.
Some Hosts Are Overloaded with FT Virtual Machines
You might encounter performance problems if your cluster’s hosts have an imbalanced distribution of FT VMs.
Losing Access to FT Metadata Datastore
Access to the Fault Tolerance metadata datastore is essential for the proper functioning of an FT VM. Loss of this access can cause a variety of problems.
Turning On vSphere FT for Powered-On VM Fails
If you try to turn on vSphere Fault Tolerance for a powered-on VM, this operation can fail.
FT Virtual Machines not Placed or Evacuated by vSphere DRS
FT virtual machines in a cluster that is enabled with vSphere DRS do not function correctly if Enhanced vMotion Compatibility (EVC) is currently disabled.
Fault Tolerant Virtual Machine Failovers
A Primary or Secondary VM can fail over even though its ESXi host has not crashed. In such cases, virtual machine execution is not interrupted, but redundancy is temporarily lost. To avoid this type of failover, be aware of some of the situations when it can occur and take steps to avoid them.
Explain the DRS Resource Distribution Graph and Target/Current Host Load Deviation
The DRS resource distribution graph displays CPU or Memory metric for each of the host a cluster. The DRS cluster can be considered load balanced when each of the hosts’ level of consumed resources is equivalent to all the other nodes in the cluster. Having said that it isn’t too big a leap of faith to accept that when they are not the cluster is considered imbalanced.

Imbalance is part of life for a DRS cluster, the main objective for DRS is not to balance the load perfectly across every host. Rather, DRS monitors the resource demand and works to ensure that every VM is getting the resources entitled. When DRS determines that a better host exists for the VM, it make a recommendation to move that VM.
Explain vMotion Resource Maps
vMotion resource maps provide a visual representation of hosts, datastores, and networks associated with the selected virtual machine.
vMotion resource maps also indicate which hosts in the virtual machine’s cluster or datacenter are compatible with the virtual machine and are potential migration targets. For a host to be compatible, it must meet the following criteria.
- Connect to all the same datastores as the virtual machine.
- Connect to all the same networks as the virtual machine.
- Have compatible software with the virtual machine.
- Have a compatible CPU with the virtual machine.