From Wikipedia, the free encyclopedia
The mean absolute percentage error (MAPE), also known as mean absolute percentage deviation (MAPD), is a measure of prediction accuracy of a forecasting method in statistics. It usually expresses the accuracy as a ratio defined by the formula:

where At is the actual value and Ft is the forecast value. Their difference is divided by the actual value At. The absolute value of this ratio is summed for every forecasted point in time and divided by the number of fitted points n.
MAPE in regression problems[edit]
Mean absolute percentage error is commonly used as a loss function for regression problems and in model evaluation, because of its very intuitive interpretation in terms of relative error.
Definition[edit]
Consider a standard regression setting in which the data are fully described by a random pair  with values in
with values in  , and n i.i.d. copies
, and n i.i.d. copies  of
of  . Regression models aims at finding a good model for the pair, that is a measurable function g from
. Regression models aims at finding a good model for the pair, that is a measurable function g from  to
to  such that
such that  is close to Y.
is close to Y.
In the classical regression setting, the closeness of to Y is measured via the L2 risk, also called the mean squared error (MSE). In the MAPE regression context,[1] the closeness of to Y is measured via the MAPE, and the aim of MAPE regressions is to find a model  such that:
such that:
![{displaystyle g_{text{MAPE}}(x)=arg min _{gin {mathcal {G}}}mathbb {E} left[left|{frac {g(X)-Y}{Y}}right||X=xright]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bfd980e3610438e202798e285c882e02dfe21d37)
where  is the class of models considered (e.g. linear models).
is the class of models considered (e.g. linear models).
In practice
In practice  can be estimated by the empirical risk minimization strategy, leading to
can be estimated by the empirical risk minimization strategy, leading to

From a practical point of view, the use of the MAPE as a quality function for regression model is equivalent to doing weighted mean absolute error (MAE) regression, also known as quantile regression. This property is trivial since

As a consequence, the use of the MAPE is very easy in practice, for example using existing libraries for quantile regression allowing weights.
Consistency[edit]
The use of the MAPE as a loss function for regression analysis is feasible both on a practical point of view and on a theoretical one, since the existence of an optimal model and the consistency of the empirical risk minimization can be proved.[1]
WMAPE[edit]
WMAPE (sometimes spelled wMAPE) stands for weighted mean absolute percentage error.[2] It is a measure used to evaluate the performance of regression or forecasting models. It is a variant of MAPE in which the mean absolute percent errors is treated as a weighted arithmetic mean. Most commonly the absolute percent errors are weighted by the actuals (e.g. in case of sales forecasting, errors are weighted by sales volume).[3]. Effectively, this overcomes the ‘infinite error’ issue.[4]
Its formula is:[4]

Where  is the weight,
is the weight,  is a vector of the actual data and
is a vector of the actual data and  is the forecast or prediction.
is the forecast or prediction.
However, this effectively simplifies to a much simpler formula:

Confusingly, sometimes when people refer to wMAPE they are talking about a different model in which the numerator and denominator of the wMAPE formula above are weighted again by another set of custom weights . Perhaps it would be more accurate to call this the double weighted MAPE (wwMAPE). Its formula is:

Issues[edit]
Although the concept of MAPE sounds very simple and convincing, it has major drawbacks in practical application,[5] and there are many studies on shortcomings and misleading results from MAPE.[6][7]
To overcome these issues with MAPE, there are some other measures proposed in literature:
- Mean Absolute Scaled Error (MASE)
- Symmetric Mean Absolute Percentage Error (sMAPE)
- Mean Directional Accuracy (MDA)
- Mean Arctangent Absolute Percentage Error (MAAPE): MAAPE can be considered a slope as an angle, while MAPE is a slope as a ratio.[7]
See also[edit]
- Least absolute deviations
- Mean absolute error
- Mean percentage error
- Symmetric mean absolute percentage error
External links[edit]
- Mean Absolute Percentage Error for Regression Models
- Mean Absolute Percentage Error (MAPE)
- Errors on percentage errors — variants of MAPE
- Mean Arctangent Absolute Percentage Error (MAAPE)
References[edit]
- ^ a b de Myttenaere, B Golden, B Le Grand, F Rossi (2015). «Mean absolute percentage error for regression models», Neurocomputing 2016 arXiv:1605.02541
- ^ Forecast Accuracy: MAPE, WAPE, WMAPE https://www.baeldung.com/cs/mape-vs-wape-vs-wmape%7Ctitle=Understanding Forecast Accuracy: MAPE, WAPE, WMAPE. ;
- ^ Weighted Mean Absolute Percentage Error https://ibf.org/knowledge/glossary/weighted-mean-absolute-percentage-error-wmape-299%7Ctitle=WMAPE: Weighted Mean Absolute Percentage Error. ;
- ^ a b «Statistical Forecast Errors».
- ^ a b Tofallis (2015). «A Better Measure of Relative Prediction Accuracy for Model Selection and Model Estimation», Journal of the Operational Research Society, 66(8):1352-1362. archived preprint
- ^ Hyndman, Rob J., and Anne B. Koehler (2006). «Another look at measures of forecast accuracy.» International Journal of Forecasting, 22(4):679-688 doi:10.1016/j.ijforecast.2006.03.001.
- ^ a b Kim, Sungil and Heeyoung Kim (2016). «A new metric of absolute percentage error for intermittent demand forecasts.» International Journal of Forecasting, 32(3):669-679 doi:10.1016/j.ijforecast.2015.12.003.
- ^ Kim, Sungil; Kim, Heeyoung (1 July 2016). «A new metric of absolute percentage error for intermittent demand forecasts». International Journal of Forecasting. 32 (3): 669–679. doi:10.1016/j.ijforecast.2015.12.003.
- ^ Makridakis, Spyros (1993) «Accuracy measures: theoretical and practical concerns.» International Journal of Forecasting, 9(4):527-529 doi:10.1016/0169-2070(93)90079-3
Гораздо легче что-то измерить, чем понять, что именно вы измеряете
Джон Уильям Салливан
Задачи машинного обучения с учителем как правило состоят в восстановлении зависимости между парами (признаковое описание, целевая переменная) по данным, доступным нам для анализа. Алгоритмы машинного обучения (learning algorithm), со многими из которых вы уже успели познакомиться, позволяют построить модель, аппроксимирующую эту зависимость. Но как понять, насколько качественной получилась аппроксимация?
Почти наверняка наша модель будет ошибаться на некоторых объектах: будь она даже идеальной, шум или выбросы в тестовых данных всё испортят. При этом разные модели будут ошибаться на разных объектах и в разной степени. Задача специалиста по машинному обучению – подобрать подходящий критерий, который позволит сравнивать различные модели.
Перед чтением этой главы мы хотели бы ещё раз напомнить, что качество модели нельзя оценивать на обучающей выборке. Как минимум, это стоит делать на отложенной (тестовой) выборке, но, если вам это позволяют время и вычислительные ресурсы, стоит прибегнуть и к более надёжным способам проверки – например, кросс-валидации (о ней вы узнаете в отдельной главе).
Выбор метрик в реальных задачах
Возможно, вы уже участвовали в соревнованиях по анализу данных. На таких соревнованиях метрику (критерий качества модели) организатор выбирает за вас, и она, как правило, довольно понятным образом связана с результатами предсказаний. Но на практике всё бывает намного сложнее.
Например, мы хотим:
- решить, сколько коробок с бананами нужно завтра привезти в конкретный магазин, чтобы минимизировать количество товара, который не будет выкуплен и минимизировать ситуацию, когда покупатель к концу дня не находит желаемый продукт на полке;
- увеличить счастье пользователя от работы с нашим сервисом, чтобы он стал лояльным и обеспечивал тем самым стабильный прогнозируемый доход;
- решить, нужно ли направить человека на дополнительное обследование.
В каждом конкретном случае может возникать целая иерархия метрик. Представим, например, что речь идёт о стриминговом музыкальном сервисе, пользователей которого мы решили порадовать сгенерированными самодельной нейросетью треками – не защищёнными авторским правом, а потому совершенно бесплатными. Иерархия метрик могла бы иметь такой вид:
- Самый верхний уровень: будущий доход сервиса – невозможно измерить в моменте, сложным образом зависит от совокупности всех наших усилий;
- Медианная длина сессии, возможно, служащая оценкой радости пользователей, которая, как мы надеемся, повлияет на их желание продолжать платить за подписку – её нам придётся измерять в продакшене, ведь нас интересует реакция настоящих пользователей на новшество;
- Доля удовлетворённых качеством сгенерированной музыки асессоров, на которых мы потестируем её до того, как выставить на суд пользователей;
- Функция потерь, на которую мы будем обучать генеративную сеть.
На этом примере мы можем заметить сразу несколько общих закономерностей. Во-первых, метрики бывают offline и online (оффлайновыми и онлайновыми). Online метрики вычисляются по данным, собираемым с работающей системы (например, медианная длина сессии). Offline метрики могут быть измерены до введения модели в эксплуатацию, например, по историческим данным или с привлечением специальных людей, асессоров. Последнее часто применяется, когда метрикой является реакция живого человека: скажем, так поступают поисковые компании, которые предлагают людям оценить качество ранжирования экспериментальной системы еще до того, как рядовые пользователи увидят эти результаты в обычном порядке. На самом же нижнем этаже иерархии лежат оптимизируемые в ходе обучения функции потерь.
В данном разделе нас будут интересовать offline метрики, которые могут быть измерены без привлечения людей.
Функция потерь $neq$ метрика качества
Как мы узнали ранее, методы обучения реализуют разные подходы к обучению:
- обучение на основе прироста информации (как в деревьях решений)
- обучение на основе сходства (как в методах ближайших соседей)
- обучение на основе вероятностной модели данных (например, максимизацией правдоподобия)
- обучение на основе ошибок (минимизация эмпирического риска)
И в рамках обучения на основе минимизации ошибок мы уже отвечали на вопрос: как можно штрафовать модель за предсказание на обучающем объекте.
Во время сведения задачи о построении решающего правила к задаче численной оптимизации, мы вводили понятие функции потерь и, обычно, объявляли целевой функцией сумму потерь от предсказаний на всех объектах обучающей выборке.
Важно понимать разницу между функцией потерь и метрикой качества. Её можно сформулировать следующим образом:
-
Функция потерь возникает в тот момент, когда мы сводим задачу построения модели к задаче оптимизации. Обычно требуется, чтобы она обладала хорошими свойствами (например, дифференцируемостью).
-
Метрика – внешний, объективный критерий качества, обычно зависящий не от параметров модели, а только от предсказанных меток.
В некоторых случаях метрика может совпадать с функцией потерь. Например, в задаче регрессии MSE играет роль как функции потерь, так и метрики. Но, скажем, в задаче бинарной классификации они почти всегда различаются: в качестве функции потерь может выступать кросс-энтропия, а в качестве метрики – число верно угаданных меток (accuracy). Отметим, что в последнем примере у них различные аргументы: на вход кросс-энтропии нужно подавать логиты, а на вход accuracy – предсказанные метки (то есть по сути argmax логитов).
Бинарная классификация: метки классов
Перейдём к обзору метрик и начнём с самой простой разновидности классификации – бинарной, а затем постепенно будем наращивать сложность.
Напомним постановку задачи бинарной классификации: нам нужно по обучающей выборке ${(x_i, y_i)}_{i=1}^N$, где $y_iin{0, 1}$ построить модель, которая по объекту $x$ предсказывает метку класса $f(x)in{0, 1}$.
Первым критерием качества, который приходит в голову, является accuracy – доля объектов, для которых мы правильно предсказали класс:
$$ color{#348FEA}{text{Accuracy}(y, y^{pred}) = frac{1}{N} sum_{i=1}^N mathbb{I}[y_i = f(x_i)]} $$
Или же сопряженная ей метрика – доля ошибочных классификаций (error rate):
$$text{Error rate} = 1 — text{Accuracy}$$
Познакомившись чуть внимательнее с этой метрикой, можно заметить, что у неё есть несколько недостатков:
- она не учитывает дисбаланс классов. Например, в задаче диагностики редких заболеваний классификатор, предсказывающий всем пациентам отсутствие болезни будет иметь достаточно высокую accuracy просто потому, что больных людей в выборке намного меньше;
- она также не учитывает цену ошибки на объектах разных классов. Для примера снова можно привести задачу медицинской диагностики: если ошибочный положительный диагноз для здорового больного обернётся лишь ещё одним обследованием, то ошибочно отрицательный вердикт может повлечь роковые последствия.
Confusion matrix (матрица ошибок)
Исторически задача бинарной классификации – это задача об обнаружении чего-то редкого в большом потоке объектов, например, поиск человека, больного туберкулёзом, по флюорографии. Или задача признания пятна на экране приёмника радиолокационной станции бомбардировщиком, представляющем угрозу охраняемому объекту (в противовес стае гусей).
Поэтому класс, который представляет для нас интерес, называется «положительным», а оставшийся – «отрицательным».
Заметим, что для каждого объекта в выборке возможно 4 ситуации:
- мы предсказали положительную метку и угадали. Будет относить такие объекты к true positive (TP) группе (true – потому что предсказали мы правильно, а positive – потому что предсказали положительную метку);
- мы предсказали положительную метку, но ошиблись в своём предсказании – false positive (FP) (false, потому что предсказание было неправильным);
- мы предсказали отрицательную метку и угадали – true negative (TN);
- и наконец, мы предсказали отрицательную метку, но ошиблись – false negative (FN). Для удобства все эти 4 числа изображают в виде таблицы, которую называют confusion matrix (матрицей ошибок):
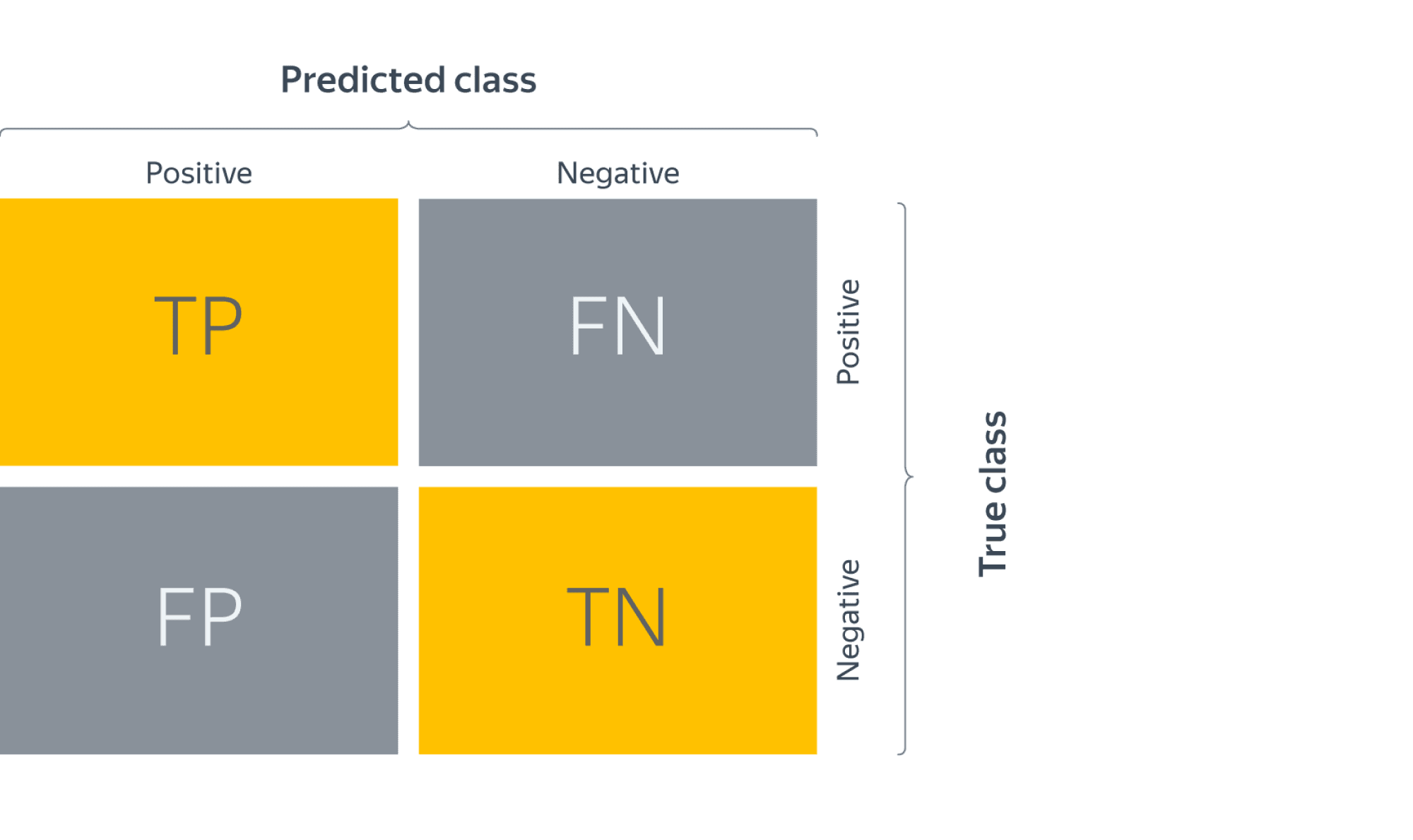
Не волнуйтесь, если первое время эти обозначения будут сводить вас с ума (будем откровенны, даже профи со стажем в них порой путаются), однако логика за ними достаточно простая: первая часть названия группы показывает угадали ли мы с классом, а вторая – какой класс мы предсказали.

Пример
Попробуем воспользоваться введёнными метриками в боевом примере: сравним работу нескольких моделей классификации на Breast cancer wisconsin (diagnostic) dataset.
Объектами выборки являются фотографии биопсии грудных опухолей. С их помощью было сформировано признаковое описание, которое заключается в характеристиках ядер клеток (таких как радиус ядра, его текстура, симметричность). Положительным классом в такой постановке будут злокачественные опухоли, а отрицательным – доброкачественные.
Модель 1. Константное предсказание.
Решение задачи начнём с самого простого классификатора, который выдаёт на каждом объекте константное предсказание – самый часто встречающийся класс.
Зачем вообще замерять качество на такой модели?При разработке модели машинного обучения для проекта всегда желательно иметь некоторую baseline модель. Так нам будет легче проконтролировать, что наша более сложная модель действительно дает нам прирост качества.
from sklearn.datasets
import load_breast_cancer
the_data = load_breast_cancer()
# 0 – "доброкачественный"
# 1 – "злокачественный"
relabeled_target = 1 - the_data["target"]
from sklearn.model_selection import train_test_split
X = the_data["data"]
y = relabeled_target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
from sklearn.dummy import DummyClassifier
dc_mf = DummyClassifier(strategy="most_frequent")
dc_mf.fit(X_train, y_train)
from sklearn.metrics import confusion_matrix
y_true = y_test y_pred = dc_mf.predict(X_test)
dc_mf_tn, dc_mf_fp, dc_mf_fn, dc_mf_tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 0 | FN = 53 |
| Истинный класс — | FP = 0 | TN = 90 |
Обучающие данные таковы, что наш dummy-классификатор все объекты записывает в отрицательный класс, то есть признаёт все опухоли доброкачественными. Такой наивный подход позволяет нам получить минимальный штраф за FP (действительно, нельзя ошибиться в предсказании, если положительный класс вообще не предсказывается), но и максимальный штраф за FN (в эту группу попадут все злокачественные опухоли).
Модель 2. Случайный лес.
Настало время воспользоваться всем арсеналом моделей машинного обучения, и начнём мы со случайного леса.
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
y_true = y_test
y_pred = rfc.predict(X_test)
rfc_tn, rfc_fp, rfc_fn, rfc_tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 52 | FN = 1 |
| Истинный класс — | FP = 4 | TN = 86 |
Можно сказать, что этот классификатор чему-то научился, т.к. главная диагональ матрицы стала содержать все объекты из отложенной выборки, за исключением 4 + 1 = 5 объектов (сравните с 0 + 53 объектами dummy-классификатора, все опухоли объявляющего доброкачественными).
Отметим, что вычисляя долю недиагональных элементов, мы приходим к метрике error rate, о которой мы говорили в самом начале:
$$text{Error rate} = frac{FP + FN}{ TP + TN + FP + FN}$$
тогда как доля объектов, попавших на главную диагональ – это как раз таки accuracy:
$$text{Accuracy} = frac{TP + TN}{ TP + TN + FP + FN}$$
Модель 3. Метод опорных векторов.
Давайте построим еще один классификатор на основе линейного метода опорных векторов.
Не забудьте привести признаки к единому масштабу, иначе численный алгоритм не сойдется к решению и мы получим гораздо более плохо работающее решающее правило. Попробуйте проделать это упражнение.
from sklearn.svm import LinearSVC
from sklearn.preprocessing import StandardScaler
ss = StandardScaler() ss.fit(X_train)
scaled_linsvc = LinearSVC(C=0.01,random_state=42)
scaled_linsvc.fit(ss.transform(X_train), y_train)
y_true = y_test
y_pred = scaled_linsvc.predict(ss.transform(X_test))
tn, fp, fn, tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 50 | FN = 3 |
| Истинный класс — | FP = 1 | TN = 89 |
Сравним результаты
Легко заметить, что каждая из двух моделей лучше классификатора-пустышки, однако давайте попробуем сравнить их между собой. С точки зрения error rate модели практически одинаковы: 5/143 для леса против 4/143 для SVM.
Посмотрим на структуру ошибок чуть более внимательно: лес – (FP = 4, FN = 1), SVM – (FP = 1, FN = 3). Какая из моделей предпочтительнее?
Замечание: Мы сравниваем несколько классификаторов на основании их предсказаний на отложенной выборке. Насколько ошибки данных классификаторов зависят от разбиения исходного набора данных? Иногда в процессе оценки качества мы будем получать модели, чьи показатели эффективности будут статистически неразличимыми.
Пусть мы учли предыдущее замечание и эти модели действительно статистически значимо ошибаются в разную сторону. Мы встретились с очевидной вещью: на матрицах нет отношения порядка. Когда мы сравнивали dummy-классификатор и случайный лес с помощью Accuracy, мы всю сложную структуру ошибок свели к одному числу, т.к. на вещественных числах отношение порядка есть. Сводить оценку модели к одному числу очень удобно, однако не стоит забывать, что у вашей модели есть много аспектов качества.
Что же всё-таки важнее уменьшить: FP или FN? Вернёмся к задаче: FP – доля доброкачественных опухолей, которым ошибочно присваивается метка злокачественной, а FN – доля злокачественных опухолей, которые классификатор пропускает. В такой постановке становится понятно, что при сравнении выиграет модель с меньшим FN (то есть лес в нашем примере), ведь каждая не обнаруженная опухоль может стоить человеческой жизни.
Рассмотрим теперь другую задачу: по данным о погоде предсказать, будет ли успешным запуск спутника. FN в такой постановке – это ошибочное предсказание неуспеха, то есть не более, чем упущенный шанс (если вас, конечно не уволят за срыв сроков). С FP всё серьёзней: если вы предскажете удачный запуск спутника, а на деле он потерпит крушение из-за погодных условий, то ваши потери будут в разы существеннее.
Итак, из примеров мы видим, что в текущем виде введенная нами доля ошибочных классификаций не даст нам возможности учесть неравную важность FP и FN. Поэтому введем две новые метрики: точность и полноту.
Точность и полнота
Accuracy — это метрика, которая характеризует качество модели, агрегированное по всем классам. Это полезно, когда классы для нас имеют одинаковое значение. В случае, если это не так, accuracy может быть обманчивой.
Рассмотрим ситуацию, когда положительный класс это событие редкое. Возьмем в качестве примера поисковую систему — в нашем хранилище хранятся миллиарды документов, а релевантных к конкретному поисковому запросу на несколько порядков меньше.
Пусть мы хотим решить задачу бинарной классификации «документ d релевантен по запросу q». Благодаря большому дисбалансу, Accuracy dummy-классификатора, объявляющего все документы нерелевантными, будет близка к единице. Напомним, что $text{Accuracy} = frac{TP + TN}{TP + TN + FP + FN}$, и в нашем случае высокое значение метрики будет обеспечено членом TN, в то время для пользователей более важен высокий TP.
Поэтому в случае ассиметрии классов, можно использовать метрики, которые не учитывают TN и ориентируются на TP.
Если мы рассмотрим долю правильно предсказанных положительных объектов среди всех объектов, предсказанных положительным классом, то мы получим метрику, которая называется точностью (precision)
$$color{#348FEA}{text{Precision} = frac{TP}{TP + FP}}$$
Интуитивно метрика показывает долю релевантных документов среди всех найденных классификатором. Чем меньше ложноположительных срабатываний будет допускать модель, тем больше будет её Precision.
Если же мы рассмотрим долю правильно найденных положительных объектов среди всех объектов положительного класса, то мы получим метрику, которая называется полнотой (recall)
$$color{#348FEA}{text{Recall} = frac{TP}{TP + FN}}$$
Интуитивно метрика показывает долю найденных документов из всех релевантных. Чем меньше ложно отрицательных срабатываний, тем выше recall модели.
Например, в задаче предсказания злокачественности опухоли точность показывает, сколько из определённых нами как злокачественные опухолей действительно являются злокачественными, а полнота – какую долю злокачественных опухолей нам удалось выявить.
Хорошее понимание происходящего даёт следующая картинка: 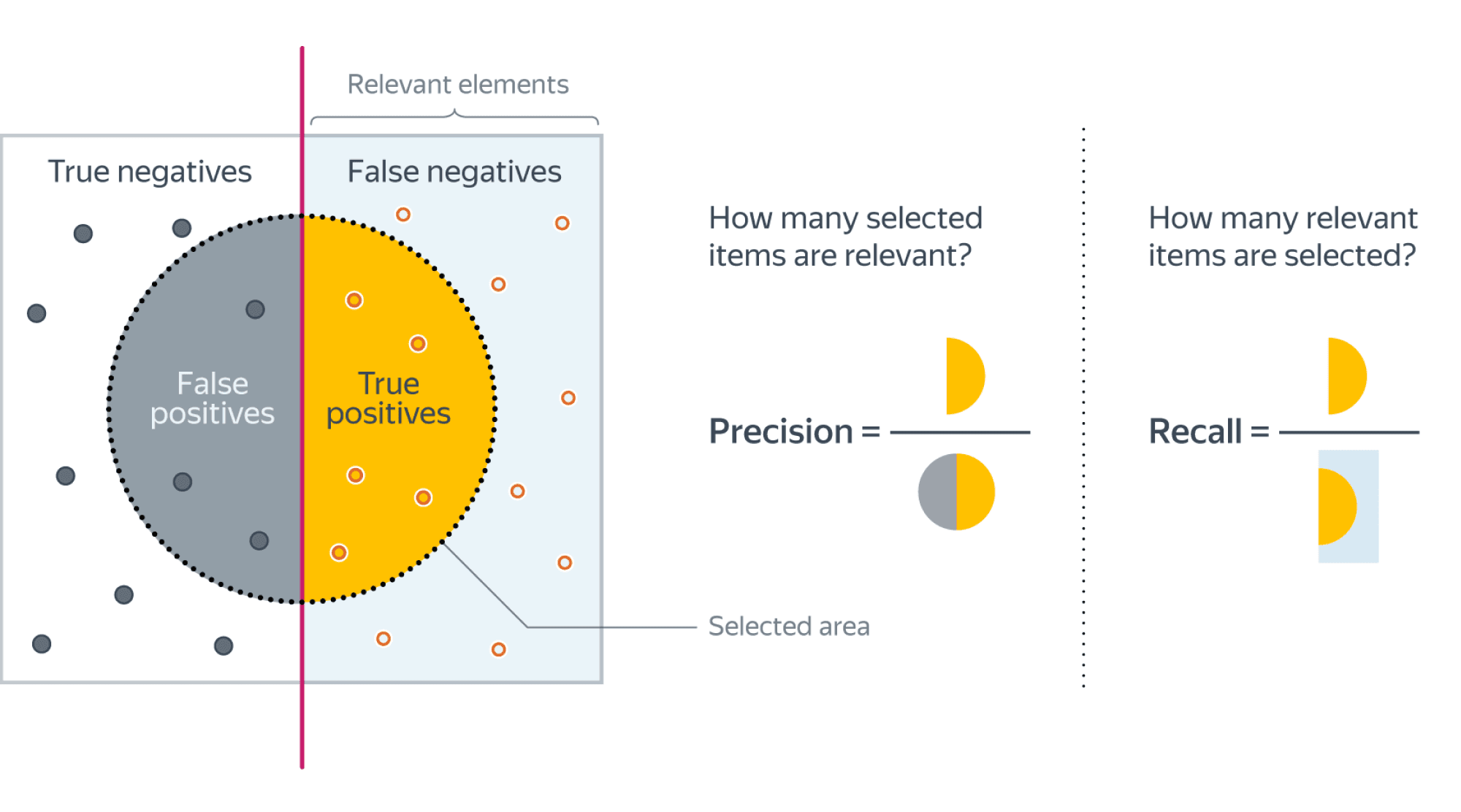 (источник картинки)
(источник картинки)
Recall@k, Precision@k
Метрики Recall и Precision хорошо подходят для задачи поиска «документ d релевантен запросу q», когда из списка рекомендованных алгоритмом документов нас интересует только первый. Но не всегда алгоритм машинного обучения вынужден работать в таких жестких условиях. Может быть такое, что вполне достаточно, что релевантный документ попал в первые k рекомендованных. Например, в интерфейсе выдачи первые три подсказки видны всегда одновременно и вообще не очень понятно, какой у них порядок. Тогда более честной оценкой качества алгоритма будет «в выдаче D размера k по запросу q нашлись релевантные документы». Для расчёта метрики по всей выборке объединим все выдачи и рассчитаем precision, recall как обычно подокументно.
F1-мера
Как мы уже отмечали ранее, модели очень удобно сравнивать, когда их качество выражено одним числом. В случае пары Precision-Recall существует популярный способ скомпоновать их в одну метрику — взять их среднее гармоническое. Данный показатель эффективности исторически носит название F1-меры (F1-measure).
$$
color{#348FEA}{F_1 = frac{2}{frac{1}{Recall} + frac{1}{Precision}}} = $$
$$ = 2 frac{Recall cdot Precision }{Recall + Precision} = frac
{TP} {TP + frac{FP + FN}{2}}
$$
Стоит иметь в виду, что F1-мера предполагает одинаковую важность Precision и Recall, если одна из этих метрик для вас приоритетнее, то можно воспользоваться $F_{beta}$ мерой:
$$
F_{beta} = (beta^2 + 1) frac{Recall cdot Precision }{Recall + beta^2Precision}
$$
Бинарная классификация: вероятности классов
Многие модели бинарной классификации устроены так, что класс объекта получается бинаризацией выхода классификатора по некоторому фиксированному порогу:
$$fleft(x ; w, w_{0}right)=mathbb{I}left[g(x, w) > w_{0}right].$$
Например, модель логистической регрессии возвращает оценку вероятности принадлежности примера к положительному классу. Другие модели бинарной классификации обычно возвращают произвольные вещественные значения, но существуют техники, называемые калибровкой классификатора, которые позволяют преобразовать предсказания в более или менее корректную оценку вероятности принадлежности к положительному классу.
Как оценить качество предсказываемых вероятностей, если именно они являются нашей конечной целью? Общепринятой мерой является логистическая функция потерь, которую мы изучали раньше, когда говорили об устройстве некоторых методов классификации (например уже упоминавшейся логистической регрессии).
Если же нашей целью является построение прогноза в терминах метки класса, то нам нужно учесть, что в зависимости от порога мы будем получать разные предсказания и разное качество на отложенной выборке. Так, чем ниже порог отсечения, тем больше объектов модель будет относить к положительному классу. Как в этом случае оценить качество модели?
AUC
Пусть мы хотим учитывать ошибки на объектах обоих классов. При уменьшении порога отсечения мы будем находить (правильно предсказывать) всё большее число положительных объектов, но также и неправильно предсказывать положительную метку на всё большем числе отрицательных объектов. Естественным кажется ввести две метрики TPR и FPR:
TPR (true positive rate) – это полнота, доля положительных объектов, правильно предсказанных положительными:
$$ TPR = frac{TP}{P} = frac{TP}{TP + FN} $$
FPR (false positive rate) – это доля отрицательных объектов, неправильно предсказанных положительными:
$$FPR = frac{FP}{N} = frac{FP}{FP + TN}$$
Обе эти величины растут при уменьшении порога. Кривая в осях TPR/FPR, которая получается при варьировании порога, исторически называется ROC-кривой (receiver operating characteristics curve, сокращённо ROC curve). Следующий график поможет вам понять поведение ROC-кривой.
Желтая и синяя кривые показывают распределение предсказаний классификатора на объектах положительного и отрицательного классов соответственно. То есть значения на оси X (на графике с двумя гауссианами) мы получаем из классификатора. Если классификатор идеальный (две кривые разделимы по оси X), то на правом графике мы получаем ROC-кривую (0,0)->(0,1)->(1,1) (убедитесь сами!), площадь под которой равна 1. Если классификатор случайный (предсказывает одинаковые метки положительным и отрицательным объектам), то мы получаем ROC-кривую (0,0)->(1,1), площадь под которой равна 0.5. Поэкспериментируйте с разными вариантами распределения предсказаний по классам и посмотрите, как меняется ROC-кривая.
Чем лучше классификатор разделяет два класса, тем больше площадь (area under curve) под ROC-кривой – и мы можем использовать её в качестве метрики. Эта метрика называется AUC и она работает благодаря следующему свойству ROC-кривой:
AUC равен доле пар объектов вида (объект класса 1, объект класса 0), которые алгоритм верно упорядочил, т.е. предсказание классификатора на первом объекте больше:
$$
color{#348FEA}{operatorname{AUC} = frac{sumlimits_{i = 1}^{N} sumlimits_{j = 1}^{N}mathbb{I}[y_i < y_j] I^{prime}[f(x_{i}) < f(x_{j})]}{sumlimits_{i = 1}^{N} sumlimits_{j = 1}^{N}mathbb{I}[y_i < y_j]}}
$$
$$
I^{prime}left[f(x_{i}) < f(x_{j})right]=
left{
begin{array}{ll}
0, & f(x_{i}) > f(x_{j}) \
0.5 & f(x_{i}) = f(x_{j}) \
1, & f(x_{i}) < f(x_{j})
end{array}
right.
$$
$$
Ileft[y_{i}< y_{j}right]=
left{
begin{array}{ll}
0, & y_{i} geq y_{j} \
1, & y_{i} < y_{j}
end{array}
right.
$$
Чтобы детальнее разобраться, почему это так, советуем вам обратиться к материалам А.Г.Дьяконова.
В каких случаях лучше отдать предпочтение этой метрике? Рассмотрим следующую задачу: некоторый сотовый оператор хочет научиться предсказывать, будет ли клиент пользоваться его услугами через месяц. На первый взгляд кажется, что задача сводится к бинарной классификации с метками 1, если клиент останется с компанией и $0$ – иначе.
Однако если копнуть глубже в процессы компании, то окажется, что такие метки практически бесполезны. Компании скорее интересно упорядочить клиентов по вероятности прекращения обслуживания и в зависимости от этого применять разные варианты удержания: кому-то прислать скидочный купон от партнёра, кому-то предложить скидку на следующий месяц, а кому-то и новый тариф на особых условиях.
Таким образом, в любой задаче, где нам важна не метка сама по себе, а правильный порядок на объектах, имеет смысл применять AUC.
Утверждение выше может вызывать у вас желание использовать AUC в качестве метрики в задачах ранжирования, но мы призываем вас быть аккуратными.
ПодробнееУтверждение выше может вызывать у вас желание использовать AUC в качестве метрики в задачах ранжирования, но мы призываем вас быть аккуратными.» details=»Продемонстрируем это на следующем примере: пусть наша выборка состоит из $9100$ объектов класса $0$ и $10$ объектов класса $1$, и модель расположила их следующим образом:
$$underbrace{0 dots 0}_{9000} ~ underbrace{1 dots 1}_{10} ~ underbrace{0 dots 0}_{100}$$
Тогда AUC будет близка к единице: количество пар правильно расположенных объектов будет порядка $90000$, в то время как общее количество пар порядка $91000$.
Однако самыми высокими по вероятности положительного класса будут совсем не те объекты, которые мы ожидаем.
Average Precision
Будем постепенно уменьшать порог бинаризации. При этом полнота будет расти от $0$ до $1$, так как будет увеличиваться количество объектов, которым мы приписываем положительный класс (а количество объектов, на самом деле относящихся к положительному классу, очевидно, меняться не будет). Про точность же нельзя сказать ничего определённого, но мы понимаем, что скорее всего она будет выше при более высоком пороге отсечения (мы оставим только объекты, в которых модель «уверена» больше всего). Варьируя порог и пересчитывая значения Precision и Recall на каждом пороге, мы получим некоторую кривую примерно следующего вида:
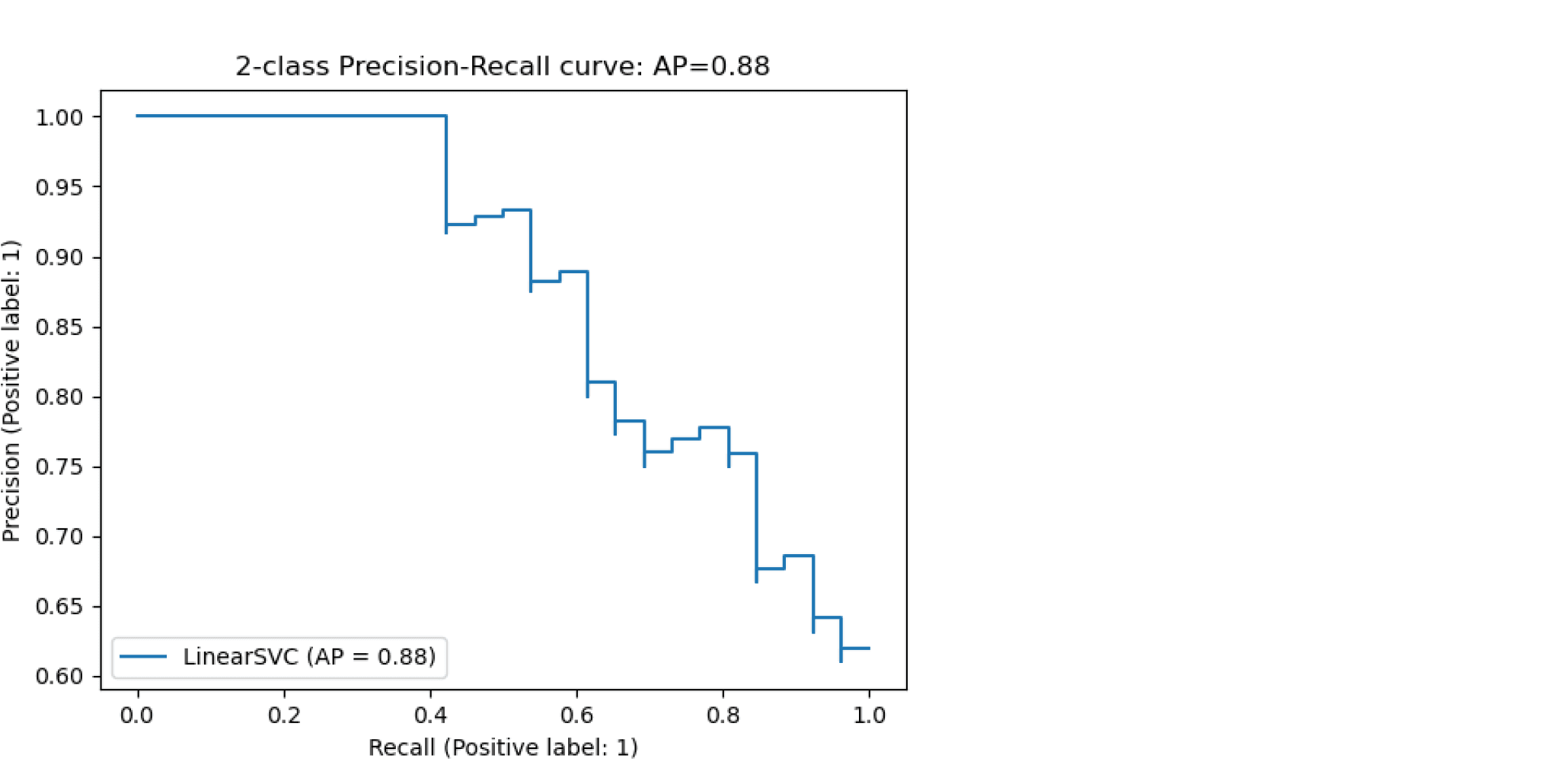 (источник картинки)
(источник картинки)
Рассмотрим среднее значение точности (оно равно площади под кривой точность-полнота):
$$ text { AP }=int_{0}^{1} p(r) d r$$
Получим показатель эффективности, который называется average precision. Как в случае матрицы ошибок мы переходили к скалярным показателям эффективности, так и в случае с кривой точность-полнота мы охарактеризовали ее в виде числа.
Многоклассовая классификация
Если классов становится больше двух, расчёт метрик усложняется. Если задача классификации на $K$ классов ставится как $K$ задач об отделении класса $i$ от остальных ($i=1,ldots,K$), то для каждой из них можно посчитать свою матрицу ошибок. Затем есть два варианта получения итогового значения метрики из $K$ матриц ошибок:
- Усредняем элементы матрицы ошибок (TP, FP, TN, FN) между бинарными классификаторами, например $TP = frac{1}{K}sum_{i=1}^{K}TP_i$. Затем по одной усреднённой матрице ошибок считаем Precision, Recall, F-меру. Это называют микроусреднением.
- Считаем Precision, Recall для каждого классификатора отдельно, а потом усредняем. Это называют макроусреднением.
Порядок усреднения влияет на результат в случае дисбаланса классов. Показатели TP, FP, FN — это счётчики объектов. Пусть некоторый класс обладает маленькой мощностью (обозначим её $M$). Тогда значения TP и FN при классификации этого класса против остальных будут не больше $M$, то есть тоже маленькие. Про FP мы ничего уверенно сказать не можем, но скорее всего при дисбалансе классов классификатор не будет предсказывать редкий класс слишком часто, потому что есть большая вероятность ошибиться. Так что FP тоже мало. Поэтому усреднение первым способом сделает вклад маленького класса в общую метрику незаметным. А при усреднении вторым способом среднее считается уже для нормированных величин, так что вклад каждого класса будет одинаковым.
Рассмотрим пример. Пусть есть датасет из объектов трёх цветов: желтого, зелёного и синего. Желтого и зелёного цветов почти поровну — 21 и 20 объектов соответственно, а синих объектов всего 4.
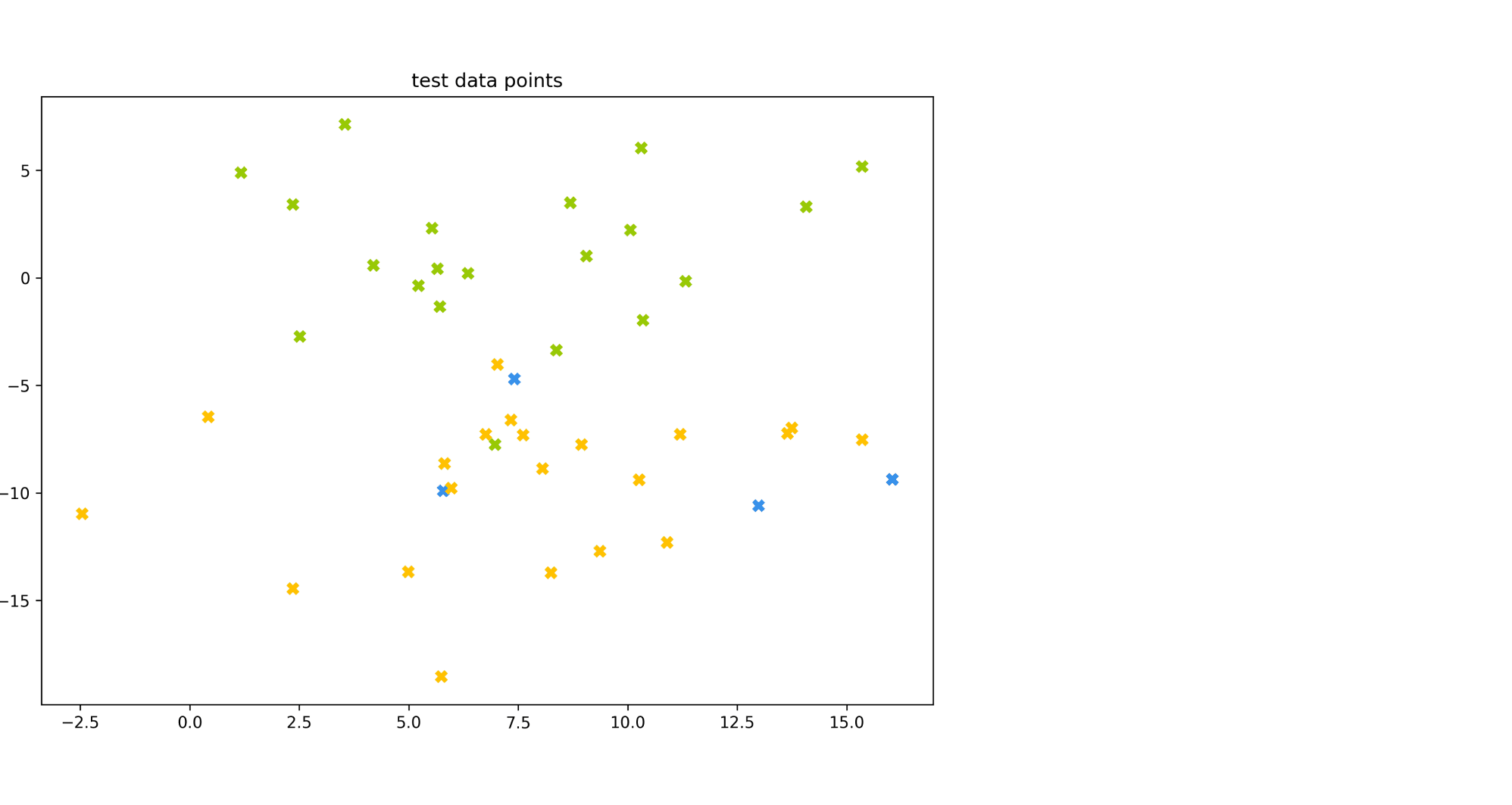
Модель по очереди для каждого цвета пытается отделить объекты этого цвета от объектов оставшихся двух цветов. Результаты классификации проиллюстрированы матрицей ошибок. Модель «покрасила» в жёлтый 25 объектов, 20 из которых были действительно жёлтыми (левый столбец матрицы). В синий был «покрашен» только один объект, который на самом деле жёлтый (средний столбец матрицы). В зелёный — 19 объектов, все на самом деле зелёные (правый столбец матрицы).
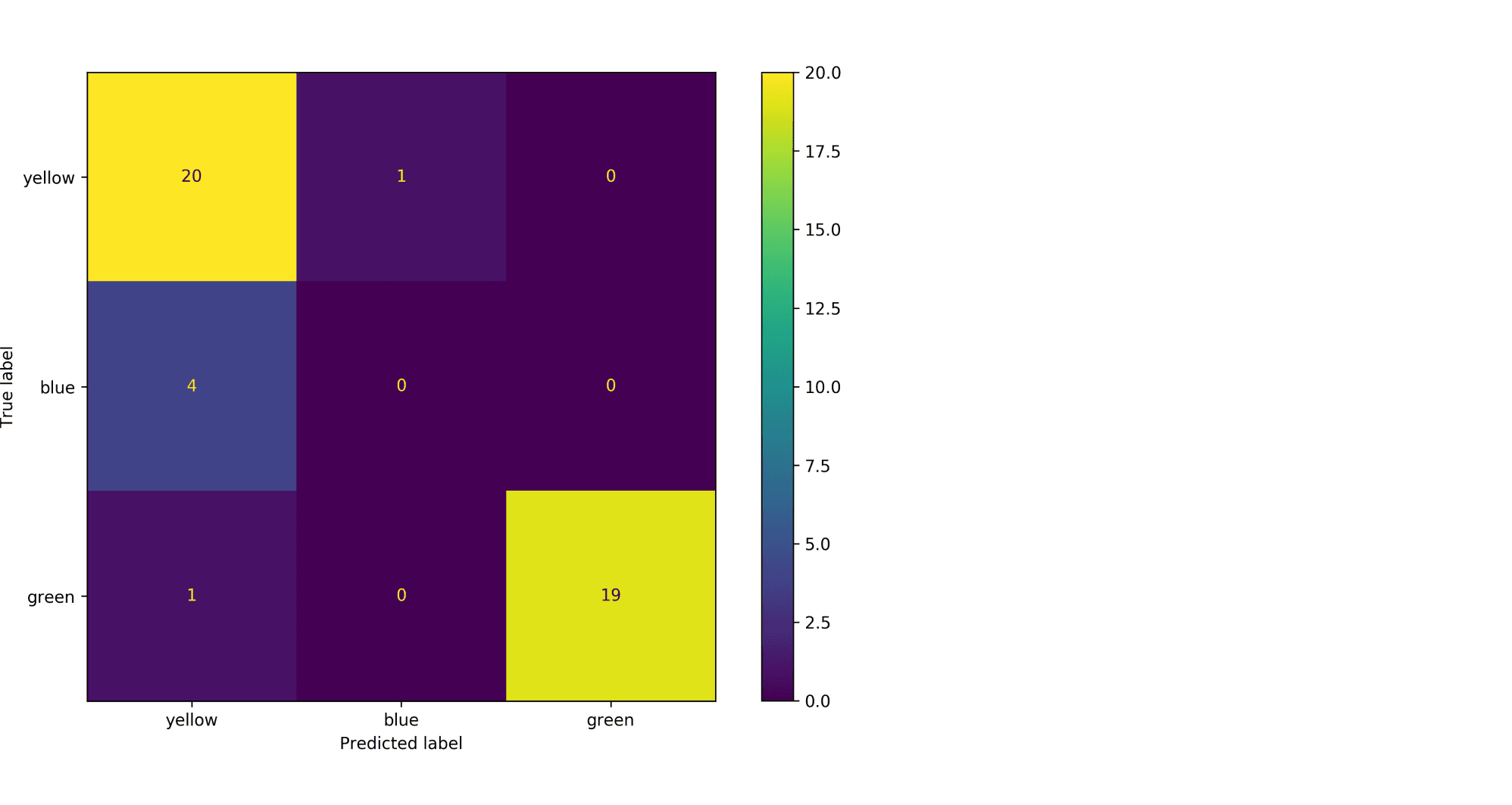
Посчитаем Precision классификации двумя способами:
- С помощью микроусреднения получаем $$
text{Precision} = frac{dfrac{1}{3}left(20 + 0 + 19right)}{dfrac{1}{3}left(20 + 0 + 19right) + dfrac{1}{3}left(5 + 1 + 0right)} = 0.87
$$ - С помощью макроусреднения получаем $$
text{Precision} = dfrac{1}{3}left( frac{20}{20 + 5} + frac{0}{0 + 1} + frac{19}{19 + 0}right) = 0.6
$$
Видим, что макроусреднение лучше отражает тот факт, что синий цвет, которого в датасете было совсем мало, модель практически игнорирует.
Как оптимизировать метрики классификации?
Пусть мы выбрали, что метрика качества алгоритма будет $F(a(X), Y)$. Тогда мы хотим обучить модель так, чтобы $F$ на валидационной выборке была минимальная/максимальная. Лучший способ добиться минимизации метрики $F$ — оптимизировать её напрямую, то есть выбрать в качестве функции потерь ту же $F(a(X), Y)$. К сожалению, это не всегда возможно. Рассмотрим, как оптимизировать метрики иначе.
Метрики precision и recall невозможно оптимизировать напрямую, потому что эти метрики нельзя рассчитать на одном объекте, а затем усреднить. Они зависят от того, какими были правильная метка класса и ответ алгоритма на всех объектах. Чтобы понять, как оптимизировать precision, recall, рассмотрим, как расчитать эти метрики на отложенной выборке. Пусть модель обучена на стандартную для классификации функцию потерь (LogLoss). Для получения меток класса специалист по машинному обучению сначала применяет на объектах модель и получает вещественные предсказания модели ($p_i in left(0, 1right)$). Затем предсказания бинаризуются по порогу, выбранному специалистом: если предсказание на объекте больше порога, то метка класса 1 (или «положительная»), если меньше — 0 (или «отрицательная»). Рассмотрим, что будет с метриками precision, recall в крайних положениях порога.
- Пусть порог равен нулю. Тогда всем объектам будет присвоена положительная метка. Следовательно, все объекты будут либо TP, либо FP, потому что отрицательных предсказаний нет, $TP + FP = N$, где $N$ — размер выборки. Также все объекты, у которых метка на самом деле 1, попадут в TP. По формуле точность $text{Precision} = frac{TP}{TP + FP} = frac1N sum_{i = 1}^N mathbb{I} left[ y_i = 1 right]$ равна среднему таргету в выборке. А полнота $text{Recall} = frac{TP}{TP + FN} = frac{TP}{TP + 0} = 1$ равна единице.
- Пусть теперь порог равен единице. Тогда ни один объект не будет назван положительным, $TP = FP = 0$. Все объекты с меткой класса 1 попадут в FN. Если есть хотя бы один такой объект, то есть $FN ne 0$, будет верна формула $text{Recall} = frac{TP}{TP + FN} = frac{0}{0+ FN} = 0$. То есть при пороге единица, полнота равна нулю. Теперь посмотрим на точность. Формула для Precision состоит только из счётчиков положительных ответов модели (TP, FP). При единичном пороге они оба равны нулю, $text{Precision} = frac{TP}{TP + FP} = frac{0}{0 + 0}$то есть при единичном пороге точность неопределена. Пусть мы отступили чуть-чуть назад по порогу, чтобы хотя бы несколько объектов были названы моделью положительными. Скорее всего это будут самые «простые» объекты, которые модель распознает хорошо, потому что её предсказание близко к единице. В этом предположении $FP approx 0$. Тогда точность $text{Precision} = frac{TP}{TP + FP} approx frac{TP}{TP + 0} approx 1$ будет близка к единице.
Изменяя порог, между крайними положениями, получим графики Precision и Recall, которые выглядят как-то так:
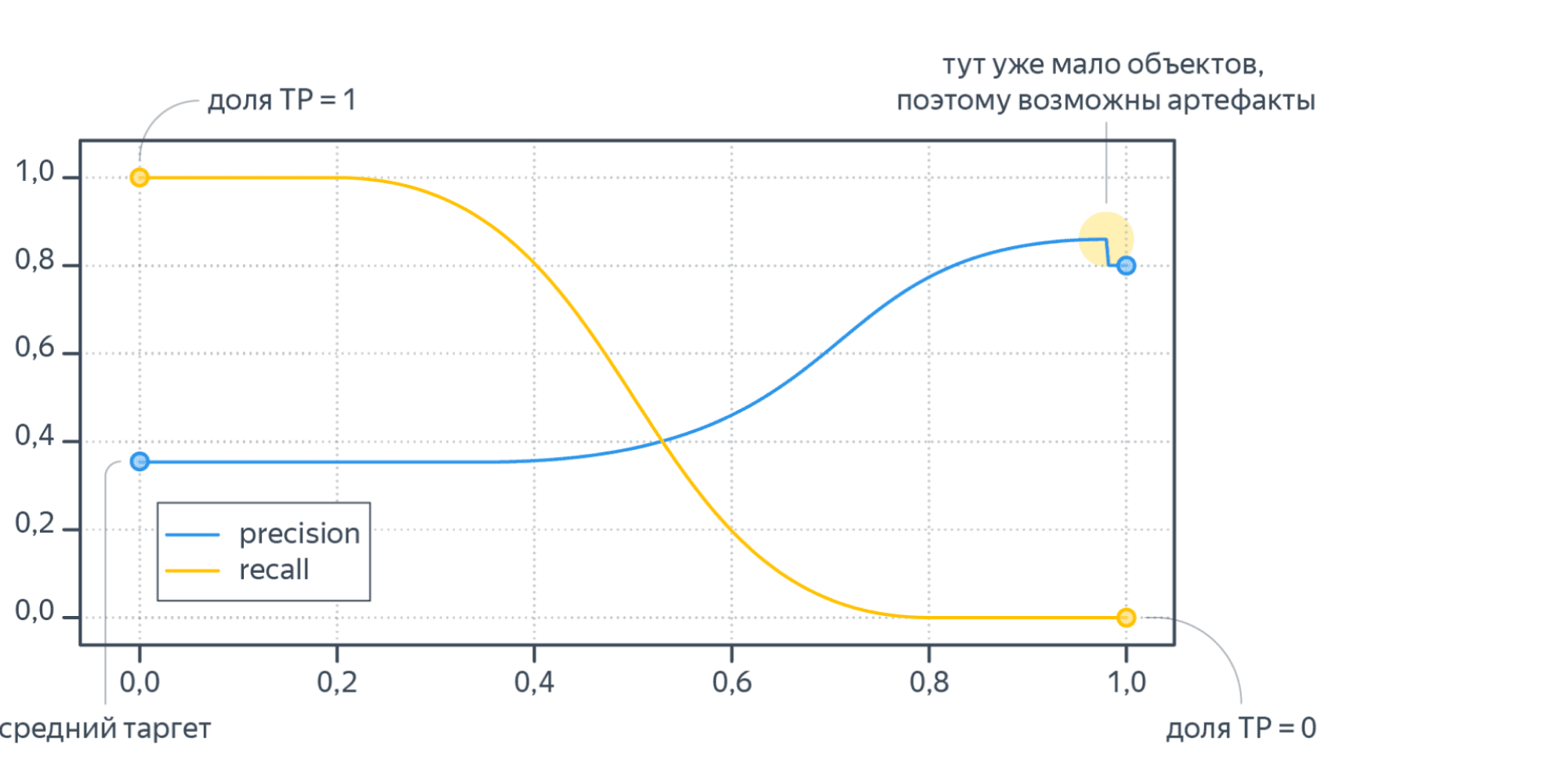
Recall меняется от единицы до нуля, а Precision от среднего тагрета до какого-то другого значения (нет гарантий, что график монотонный).
Итого оптимизация precision и recall происходит так:
- Модель обучается на стандартную функцию потерь (например, LogLoss).
- Используя вещественные предсказания на валидационной выборке, перебирая разные пороги от 0 до 1, получаем графики метрик в зависимости от порога.
- Выбираем нужное сочетание точности и полноты.
Пусть теперь мы хотим максимизировать метрику AUC. Стандартный метод оптимизации, градиентный спуск, предполагает, что функция потерь дифференцируема. AUC этим качеством не обладает, то есть мы не можем оптимизировать её напрямую. Поэтому для метрики AUC приходится изменять оптимизационную задачу. Метрика AUC считает долю верно упорядоченных пар. Значит от исходной выборки можно перейти к выборке упорядоченных пар объектов. На этой выборке ставится задача классификации: метка класса 1 соответствует правильно упорядоченной паре, 0 — неправильно. Новой метрикой становится accuracy — доля правильно классифицированных объектов, то есть доля правильно упорядоченных пар. Оптимизировать accuracy можно по той же схеме, что и precision, recall: обучаем модель на LogLoss и предсказываем вероятности положительной метки у объекта выборки, считаем accuracy для разных порогов по вероятности и выбираем понравившийся.
Регрессия
В задачах регрессии целевая метка у нас имеет потенциально бесконечное число значений. И природа этих значений, обычно, связана с каким-то процессом измерений:
- величина температуры в определенный момент времени на метеостанции
- количество прочтений статьи на сайте
- количество проданных бананов в конкретном магазине, сети магазинов или стране
- дебит добывающей скважины на нефтегазовом месторождении за месяц и т.п.
Мы видим, что иногда метка это целое число, а иногда произвольное вещественное число. Обычно случаи целочисленных меток моделируют так, словно это просто обычное вещественное число. При таком подходе может оказаться так, что модель A лучше модели B по некоторой метрике, но при этом предсказания у модели A могут быть не целыми. Если в бизнес-задаче ожидается именно целочисленный ответ, то и оценивать нужно огрубление.
Общая рекомендация такова: оценивайте весь каскад решающих правил: и те «внутренние», которые вы получаете в результате обучения, и те «итоговые», которые вы отдаёте бизнес-заказчику.
Например, вы можете быть удовлетворены, что стали ошибаться не во втором, а только в третьем знаке после запятой при предсказании погоды. Но сами погодные данные измеряются с точностью до десятых долей градуса, а пользователь и вовсе может интересоваться лишь целым числом градусов.
Итак, напомним постановку задачи регрессии: нам нужно по обучающей выборке ${(x_i, y_i)}_{i=1}^N$, где $y_i in mathbb{R}$ построить модель f(x).
Величину $ e_i = f(x_i) — y_i $ называют ошибкой на объекте i или регрессионным остатком.
Весь набор ошибок на отложенной выборке может служить аналогом матрицы ошибок из задачи классификации. А именно, когда мы рассматриваем две разные модели, то, глядя на то, как и на каких объектах они ошиблись, мы можем прийти к выводу, что для решения бизнес-задачи нам выгоднее взять ту или иную модель. И, аналогично со случаем бинарной классификации, мы можем начать строить агрегаты от вектора ошибок, получая тем самым разные метрики.
MSE, RMSE, $R^2$
MSE – одна из самых популярных метрик в задаче регрессии. Она уже знакома вам, т.к. применяется в качестве функции потерь (или входит в ее состав) во многих ранее рассмотренных методах.
$$ MSE(y^{true}, y^{pred}) = frac1Nsum_{i=1}^{N} (y_i — f(x_i))^2 $$
Иногда для того, чтобы показатель эффективности MSE имел размерность исходных данных, из него извлекают квадратный корень и получают показатель эффективности RMSE.
MSE неограничен сверху, и может быть нелегко понять, насколько «хорошим» или «плохим» является то или иное его значение. Чтобы появились какие-то ориентиры, делают следующее:
-
Берут наилучшее константное предсказание с точки зрения MSE — среднее арифметическое меток $bar{y}$. При этом чтобы не было подглядывания в test, среднее нужно вычислять по обучающей выборке
-
Рассматривают в качестве показателя ошибки:
$$ R^2 = 1 — frac{sum_{i=1}^{N} (y_i — f(x_i))^2}{sum_{i=1}^{N} (y_i — bar{y})^2}.$$
У идеального решающего правила $R^2$ равен $1$, у наилучшего константного предсказания он равен $0$ на обучающей выборке. Можно заметить, что $R^2$ показывает, какая доля дисперсии таргетов (знаменатель) объяснена моделью.
MSE квадратично штрафует за большие ошибки на объектах. Мы уже видели проявление этого при обучении моделей методом минимизации квадратичных ошибок – там это проявлялось в том, что модель старалась хорошо подстроиться под выбросы.
Пусть теперь мы хотим использовать MSE для оценки наших регрессионных моделей. Если большие ошибки для нас действительно неприемлемы, то квадратичный штраф за них — очень полезное свойство (и его даже можно усиливать, повышая степень, в которую мы возводим ошибку на объекте). Однако если в наших тестовых данных присутствуют выбросы, то нам будет сложно объективно сравнить модели между собой: ошибки на выбросах будет маскировать различия в ошибках на основном множестве объектов.
Таким образом, если мы будем сравнивать две модели при помощи MSE, у нас будет выигрывать та модель, у которой меньше ошибка на объектах-выбросах, а это, скорее всего, не то, чего требует от нас наша бизнес-задача.
История из жизни про бананы и квадратичный штраф за ошибкуИз-за неверно введенных данных метка одного из объектов оказалась в 100 раз больше реального значения. Моделировалась величина при помощи градиентного бустинга над деревьями решений. Функция потерь была MSE.
Однажды уже во время эксплуатации случилось ч.п.: у нас появились предсказания, в 100 раз превышающие допустимые из соображений физического смысла значения. Представьте себе, например, что вместо обычных 4 ящиков бананов система предлагала поставить в магазин 400. Были распечатаны все деревья из ансамбля, и мы увидели, что постепенно число ящиков действительно увеличивалось до прогнозных 400.
Было решено проверить гипотезу, что был выброс в данных для обучения. Так оно и оказалось: всего одна точка давала такую потерю на объекте, что алгоритм обучения решил, что лучше переобучиться под этот выброс, чем смириться с большим штрафом на этом объекте. А в эксплуатации у нас возникли точки, которые плюс-минус попадали в такие же листья ансамбля, что и объект-выброс.
Избежать такого рода проблем можно двумя способами: внимательнее контролируя качество данных или адаптировав функцию потерь.
Аналогично, можно поступать и в случае, когда мы разрабатываем метрику качества: менее жёстко штрафовать за большие отклонения от истинного таргета.
MAE
Использовать RMSE для сравнения моделей на выборках с большим количеством выбросов может быть неудобно. В таких случаях прибегают к также знакомой вам в качестве функции потери метрике MAE (mean absolute error):
$$ MAE(y^{true}, y^{pred}) = frac{1}{N}sum_{i=1}^{N} left|y_i — f(x_i)right| $$
Метрики, учитывающие относительные ошибки
И MSE и MAE считаются как сумма абсолютных ошибок на объектах.
Рассмотрим следующую задачу: мы хотим спрогнозировать спрос товаров на следующий месяц. Пусть у нас есть два продукта: продукт A продаётся в количестве 100 штук, а продукт В в количестве 10 штук. И пусть базовая модель предсказывает количество продаж продукта A как 98 штук, а продукта B как 8 штук. Ошибки на этих объектах добавляют 4 штрафных единицы в MAE.
И есть 2 модели-кандидата на улучшение. Первая предсказывает товар А 99 штук, а товар B 8 штук. Вторая предсказывает товар А 98 штук, а товар B 9 штук.
Обе модели улучшают MAE базовой модели на 1 единицу. Однако, с точки зрения бизнес-заказчика вторая модель может оказаться предпочтительнее, т.к. предсказание продажи редких товаров может быть приоритетнее. Один из способов учесть такое требование – рассматривать не абсолютную, а относительную ошибку на объектах.
MAPE, SMAPE
Когда речь заходит об относительных ошибках, сразу возникает вопрос: что мы будем ставить в знаменатель?
В метрике MAPE (mean absolute percentage error) в знаменатель помещают целевое значение:
$$ MAPE(y^{true}, y^{pred}) = frac{1}{N} sum_{i=1}^{N} frac{ left|y_i — f(x_i)right|}{left|y_iright|} $$
С особым случаем, когда в знаменателе оказывается $0$, обычно поступают «инженерным» способом: или выдают за непредсказание $0$ на таком объекте большой, но фиксированный штраф, или пытаются застраховаться от подобного на уровне формулы и переходят к метрике SMAPE (symmetric mean absolute percentage error):
$$ SMAPE(y^{true}, y^{pred}) = frac{1}{N} sum_{i=1}^{N} frac{ 2 left|y_i — f(x_i)right|}{y_i + f(x_i)} $$
Если же предсказывается ноль, штраф считаем нулевым.
Таким переходом от абсолютных ошибок на объекте к относительным мы сделали объекты в тестовой выборке равнозначными: даже если мы делаем абсурдно большое предсказание, на фоне которого истинная метка теряется, мы получаем штраф за этот объект порядка 1 в случае MAPE и 2 в случае SMAPE.
WAPE
Как и любая другая метрика, MAPE имеет свои границы применимости: например, она плохо справляется с прогнозом спроса на товары с прерывистыми продажами. Рассмотрим такой пример:
| Понедельник | Вторник | Среда | |
|---|---|---|---|
| Прогноз | 55 | 2 | 50 |
| Продажи | 50 | 1 | 50 |
| MAPE | 10% | 100% | 0% |
Среднее MAPE – 36.7%, что не очень отражает реальную ситуацию, ведь два дня мы предсказывали с хорошей точностью. В таких ситуациях помогает WAPE (weighted average percentage error):
$$ WAPE(y^{true}, y^{pred}) = frac{sum_{i=1}^{N} left|y_i — f(x_i)right|}{sum_{i=1}^{N} left|y_iright|} $$
Если мы предсказываем идеально, то WAPE = 0, если все предсказания отдаём нулевыми, то WAPE = 1.
В нашем примере получим WAPE = 5.9%
RMSLE
Альтернативный способ уйти от абсолютных ошибок к относительным предлагает метрика RMSLE (root mean squared logarithmic error):
$$ RMSLE(y^{true}, y^{pred}| c) = sqrt{ frac{1}{N} sum_{i=1}^N left(vphantom{frac12}log{left(y_i + c right)} — log{left(f(x_i) + c right)}right)^2 } $$
где нормировочная константа $c$ вводится искусственно, чтобы не брать логарифм от нуля. Также по построению видно, что метрика пригодна лишь для неотрицательных меток.
Веса в метриках
Все вышеописанные метрики легко допускают введение весов для объектов. Если мы из каких-то соображений можем определить стоимость ошибки на объекте, можно брать эту величину в качестве веса. Например, в задаче предсказания спроса в качестве веса можно использовать стоимость объекта.
Доля предсказаний с абсолютными ошибками больше, чем d
Еще одним способом охарактеризовать качество модели в задаче регрессии является доля предсказаний с абсолютными ошибками больше заданного порога $d$:
$$frac{1}{N} sum_{i=1}^{N} mathbb{I}left[ left| y_i — f(x_i) right| > d right] $$
Например, можно считать, что прогноз погоды сбылся, если ошибка предсказания составила меньше 1/2/3 градусов. Тогда рассматриваемая метрика покажет, в какой доле случаев прогноз не сбылся.
Как оптимизировать метрики регрессии?
Пусть мы выбрали, что метрика качества алгоритма будет $F(a(X), Y)$. Тогда мы хотим обучить модель так, чтобы F на валидационной выборке была минимальная/максимальная. Аналогично задачам классификации лучший способ добиться минимизации метрики $F$ — выбрать в качестве функции потерь ту же $F(a(X), Y)$. К счастью, основные метрики для регрессии: MSE, RMSE, MAE можно оптимизировать напрямую. С формальной точки зрения MAE не дифференцируема, так как там присутствует модуль, чья производная не определена в нуле. На практике для этого выколотого случая в коде можно возвращать ноль.
Для оптимизации MAPE придётся изменять оптимизационную задачу. Оптимизацию MAPE можно представить как оптимизацию MAE, где объектам выборки присвоен вес $frac{1}{vert y_ivert}$.
Диагностика систем машинного обучения
115 мин на чтение
(169.722 символов)
Что такое метрики эффективности?
Для того, чтобы эффективно проводить обучение моделей необходимо иметь способ оценки, насколько хорошо та или иная модель выполняет свою работу — предсказывает значение целевой переменной. Кажется, мы уже что-то подобное изучали. У каждой модели есть функция ошибки, которая показывает, на сколько модель соответствует эмпирическим значениям. Однако, использование функции ошибки не очень удобно для оценки именно “качества” уже построенных моделей. Ведь эта функция специально создается для единственной цели — организации процесса обучения. Поэтому для оценки уже построенных моделей используется не функция ошибки, а так называемые метрики эффективности — специальные функции, которые показывают, насколько эффективна уже готовая, обученная модель.
Метрики эффективности на первый взгляд очень похожи на функции ошибки, ведь у них одна цель — отличать хорошие модели от плохих. Но делают они это по-разному, по-разному и применяются. К метрикам эффективности предъявляются совершенно другие требования, нежели к функциям ошибки. Поэтому давайте рассмотрим, для чего нужны и те и другие.
Функция ошибки нужна в первую очередь для формализации процесса обучения модели. То есть для того, чтобы подбирать параметры модели именно такими, чтобы модель как можно больше соответствовала реальным данным в обучающей выборке. Да, значение этой функции можно использовать как некоторую оценку качества модели уже после того, как она обучена, но это не удобно.
Функция ошибки нужна, чтобы формализовать отклонения предсказанных моделью значений от реальных. Например, в методе линейной регрессии функция ошибки (среднеквадратическое отклонение) используется для метода градиентного спуска. Поэтому функция ошибки обязательно должна быть везде дифференцируемой, мы это отдельно отмечали, когда говорили про метод градиентного спуска. Это требование — дифференцируемость — нужно исключительно для метода оптимизации, то есть для обучения модели.
Зато функция, которая используется для оценки качества модели совершенно не должна быть аналитической и гладкой. Ведь мы не будем вычислять ее производную, мы только вычислим ее один раз для того, чтобы понять, насколько хорошая модель получилась. Так что не любую метрику эффективности вообще физически возможно использовать как функцию ошибки — метод обучения может просто не сработать.
Кроме того, функция ошибки должна быть вычислительно простой, ведь ее придется считать много раз в процессе обучения — тысячи или миллионы раз. Это еще одно требование, которое совершенно необязательно для метрики эффективности. Она как раз может считаться довольно сложно, ведь вычислять ее приходится всего несколько раз.
Зато метрика эффективности должна быть понятной и интерпретируемой, в отличие от функции ошибки. Раньше мы подчеркивали, что само абсолютное значение функции ошибки ничего не показывает. Важно лишь, снижается ли оно в процессе обучения. И разные значения функции ошибки имеет смысл сравнивать только на одних и тех же данных. Что значит, если значение функции ошибки модели равно 35 000? Да ничего, только то, что эта модель хуже, чем та, у которой ошибка 32 000.
Для того, чтобы значение было более понятно, метрики эффективности зачастую выражаются в каких-то определенных единицах измерения — чеще всего в натуральных или в процентах. Натуральные единицы — это единицы измерения целевой переменной. Допустим, целевая переменная выражается в рублях. То есть, мы предсказываем некоторую стоимость. В таком случае будет вполне понятно, если качество этой модели мы тоже выразим в рублях. Например, так: модель в среднем ошибается на 500 рублей. И сразу становится ясно, насколько эта модель применима на практике.
Еще одно важное отличие. Как мы сказали, требования к функции ошибки определяются алгоритмом оптимизации. Который, в свою очередь зависит от типа модели. У линейной регрессии будет один алгоритм (и одна функция ошибки), а у, например, решающего дерева — другой алгоритм и совершенно другая функция ошибки. Это в частности значит, что функцию ошибки невозможно применять для сравнения нескольких разных моделей, обученных на одной и той же задаче.
И вот для этого как раз и нужны метрики эффективности. Они не зависят от типа модели, а выбираются исходя из задачи и тех вопросов, ответы на которые мы хотим получить. Например, в одной задаче качество модели лучше измерять через среднеквадратическую логарифмическую ошибку, а в другой — через медианную ошибку. Как раз в этом разделе мы посмотрим на примеры разных метрик эффективности, на их особенности и сферы применения.
Кстати, это еще означает, что в каждой конкретной задаче вы можете применять сразу несколько метрик эффективности, для более глубокого понимания работы модели. Зачастую так и поступают, ведь одна метрика не может дать полной информации о сильных и слабых сторонах модели. Тут исследователи ничем не ограничены. А вот функция ошибки обязательно должна быть только одна, ведь нельзя одновременно находить минимум сразу нескольких разных функций (на самом деле можно, но многокритериальная оптимизация — это гораздо сложнее и не используется для обучения моделей).
| Функция ошибки | Метрика эффективности |
|---|---|
| Используется для организации процесса обучения | Используется для оценки качества полученной модели |
| Используется для нахождения оптимума | Используется для сравнения моделей между собой |
| Должна быть быстро вычислимой | Должна быть понятной |
| Должна конструироваться исходя их типа модели | Должна выбираться исходя из задачи |
| Может быть только одна | Может быть несколько |
Еще раз определим, эффективность — это свойство модели машинного обучения давать предсказания значения целевой переменной, как можно ближе к реальным данным. Это самая главная характеристика модели. Но надо помнить, что исходя из задачи и ее условий, к моделям могут предъявляться и другие требования, как сказали бы в программной инженерии — нефункциональные. Типичный пример — скорость работы. Иногда маленький выигрыш в эффективности не стоит того, что модель стала работать в десять раз меньше. Другой пример — интерпретируемость модели. В некоторых областях важно не только сделать точное предсказание, но и иметь возможность обосновать его, провести анализ, выработать рекомендации по улучшению ситуации и так далее. Все эти нефункциональные требования — скорость обучения, скорость предсказания, надежность, робастность, федеративность, интерпретируемость — выходят за рамки данного пособия. Здесь мы сконцентрируемся на измерении именно эффективности модели.
Обратите внимание, что мы старательно избегаем употребления слова “точность” при описании качества работы модели. Хотя казалось бы, оно подходит как нельзя лучше. Дело в том, что “точностью” называют одну из метрик эффективности моделей классификации. Поэтому мы не хотим внести путаницу в термины.
Как мы говорили, метрики эффективности не зависят от самого типа модели. Для их вычисления обычно используется два вектора — вектор эмпирических значений целевой переменной (то есть тех, которые даны в датасете) и вектор теоретических значений (то есть тех, которые выдала модель). Естественно, эти вектора должны быть сопоставимы — на соответствующих местах должны быть значения целевой переменной, соответствующие одном у и тому же объекту. И, конечно, у них должна быть одинаковая длина. То есть метрика зависит от самих предсказаний, но не от модели, которая их выдала. Причем, большинство метрик устроены симметрично — если поменять местами эти два вектора, результат не изменится.
При рассмотрении метрик надо помнить следующее — чем выше эффективность модели, тем лучше. Но некоторые метрики устроены как измерение ошибки модели. В таком случае, конечно, тем ниже, тем лучше. Так что эффективность и ошибка модели — это по сути противоположные понятия. Так сложилось, что метрики регрессии чаще устроены именно как ошибки, а метрики классификации — как метрики именно эффективности. При использовании конкретной метрики на это надо обращать внимание.
Выводы:
- Метрики эффективности — это способ показать, насколько точно модель отражает реальный мир.
- Метрики эффективность должны выбираться исходя из задачи, которую решает модель.
- Функция ошибки и метрика эффективности — это разные вещи, к ним предъявляются разные требования.
- В задаче можно (и, зачастую, нужно) применять несколько метрик эффективности.
- Наряду с метриками эффективности есть и другие характеристики моделей — скорость обучения, скорость работы, надежность, робастность, интерпретируемость.
- Метрики эффективности вычисляются как правило из двух векторов — предсказанных (теоретических) значений целевой переменной и эмпирических (реальных) значений.
- Обычно метрики устроены таким образом, что чем выше значение, тем модель лучше.
Метрики эффективности для регрессии
Как мы говорили в предыдущем пункте, метрики зависят от конкретной задачи. А все задачи обучения с учителем разделяются на регрессию и классификацию. Совершенно естественно, что метрики для регрессии и для классификации будут разными.
Метрики эффективности для регрессии оценивают отклонение (расстояние) между предсказанными значениями и реальными. Кажется, что это очевидно, но метрики эффективности классификации устроены по-другому. Предполагается, что чем меньше каждое конкретное отклонение, тем лучше. Разница между разными метриками в том, как учитывать индивидуальные отклонения в общей метрике и в том, как агрегировать ряд значений в один интегральный показатель.
Все метрики эффективности моделей регрессии покажутся вам знакомыми, если вы изучали математическую статистику, ведь именно статистические методы легли в основу измерения эффективности моделей машинного обучения. Причем, метрики эффективности — это лишь самые простые статистические показатели, которые можно использовать для анализа качества модели. При желании можно и нужно задействовать более мощные статистические методы исследования данных. Например, можно проанализировать вид распределения отклонений, и сделать из этого вывод о необходимость корректировки моделей. Но в 99% случаев можно обойтись простым вычислением одной или двух рассматриваемых ниже метрик.
Так как метрики эффективности позволяют интерпретировать оценку качества модели, они зачастую неявно сравнивают данную модель с некоторой тривиальной. Тривиальна модель — это очень простая, даже примитивная модель, которая выдает предсказания оценки целевой переменной абсолютно без оглядки на эффективность и вообще соответствие реальным данным. Тривиальной моделью может выступать, например, предсказание для любого объекта среднего значения целевой переменной из обучающей выборки. Такие тривиальные модели нужны, чтобы оценить, насколько данная модель лучше или хуже них.
Естественно, мы хотим получить модель, которая лучше тривиальной. Причем, у нас есть некоторый идеал — модель, которая никогда не ошибается, то есть чьи предсказания всегда совпадают с реальными значениями. Поэтому реальная модель может быть лучше тривиальной только до этого предела. У такой идеальной модели, говорят, 100% эффективность или нулевая ошибка.
Но надо помнить, что в задачах регрессии модель предсказывает непрерывное значение. Это значит, что величина отклонения может быть неограниченно большой. Так что не бывает нижнего предела качества модели. Модель регрессии может быть бесконечно далекой от идеала, бесконечно хуже даже тривиальной модели. Поэтому ошибки моделей регрессии не ограничиваются сверху (или, что то же самое, эффективность моделей регрессии не ограничивается снизу).
Поэтому в задачах регрессии
Выводы:
- Метрики эффективности для регрессий обычно анализируют отклонения предсказанных значений от реальных.
- Большинство метрик пришло в машинное обучение из математической статистики.
- Результаты работы модели можно исследовать более продвинутыми статистическими методами.
- Обычно метрики сравнивают данную модель с тривиальной — моделью, которая всегда предсказывает среднее реальное значение целевой переменной.
- Модель могут быть точны на 100%, но плохи они могут быть без ограничений.
Коэффициент детерминации (r-квадрат)
Те, кто раньше хотя бы немного изучал математическую статистику, без труда узнают первую метрику эффективности моделей регрессии. Это так называемый коэффициент детерминации. Это доля дисперсии (вариации) целевой переменной, объясненная данной моделью. Данная метрика вычисляется по такой формуле:
[R^2(y, hat{y}) = 1 — frac
{sum_{i=1}^n (y_i — hat{y_i})^2}
{sum_{i=1}^n (y_i — bar{y_i})^2}]
где
$y$ — вектор эмпирических (истинных) значений целевой переменной,
$hat{y}$ — вектор теоретических (предсказанных) значений целевой переменной,
$y_i$ — эмпирическое значение целевой переменной для $i$-го объекта,
$hat{y_i}$ — теоретическое значение целевой переменной для $i$-го объекта,
$bar{y_i}$ — среднее из эмпирических значений целевой переменной для $i$-го объекта.
Если модель всегда предсказывает идеально (то есть ее предсказания всегда совпадают с реальностью, другими словами, теоретические значения — с эмпирическими), то числитель дроби в формуле будет равен 0, а значит, вся метрика будет равна 1. Если же мы рассмотрим тривиальную модель, которая всегда предсказывает среднее значение, то числитель будет равен знаменателю, дробь будет равна 1, а метрика — 0. Если модель хуже идеальной, но лучше тривиальной, то метрика будет в диапазоне от 0 до 1, причем чем ближе к 1 — тем лучше.
Если же модель предсказывает такие значения, что отклонения их от теоретических получаются больше, чем от среднего значения, то числитель будет больше знаменателя, а значит, что метрика будет принимать отрицательные значения. Запомните, что отрицательные значения коэффициента детерминации означают, что модель хуже, чем тривиальная.
В целом эта метрика показывает силу линейной связи между двумя случайными величинами. В нашем случае этими величинами выступают теоретические и эмпирические значения целевой переменной (то есть предсказанные и реальные). Если модель дает точные предсказания, то будет наблюдаться сильная связь (зависимость) между теоретическим значением и реальным, то есть высокая детерминация, близкая к 1. Если эе модель дает случайные предсказания, никак не связанные с реальными значениями, то связь будет отсутствовать.
Причем так как нас интересует, насколько значения совпадают, нам достаточно использовать именно линейную связь. Ведь когда мы оцениваем связь, например, одного из факторов в целевой переменной, то связь может быть нелинейной, и линейный коэффициент детерминации ее не покажет, то есть пропустит. Но в данному случае это не важно, так как наличие нелинейной связи означает, что предсказанные значения все-таки отклоняются от реальных. Такую линейную связь можно увидеть на графике, если построить диаграмму рассеяния между теоретическими и эмпирическими значениями, вот так:
1
2
3
4
5
6
from sklearn.linear_model import LinearRegression
reg = LinearRegression().fit(X, Y)
Y_ = reg.predict(X)
plt.scatter(Y, Y_)
plt.plot(Y, Y)
Здесь мы еще строим прямую $y = y$. Она нужна только для удобства. Вот как может выглядеть этот график:

Здесь мы видим, что точки немного отклоняются от центральной линии, но в целом ей следуют. Такая картина характерна для высокого коэффициента детерминации. А вот как может выглядеть менее точная модель:

И в целом, чем точки ближе к центральной линии, тем лучше модель и тем ближе коэффициент детерминации к 1.
В англоязычной литература эта метрика называется $R^2$, так как в определенных случаях она равна квадрату коэффициента корреляции. Пусть это название не вводит вас в заблуждение. Некоторые думаю, что раз метрика в квадрате, то она не может быть отрицательной. Это лишь условное название.
Пару слов об использовании метрик эффективности в библиотеке sklearn. Именно коэффициент детерминации чаще всего используется как метрика по умолчанию, которую можно посмотреть при помощи метода score() у модели регрессии. Обратите внимание, что этот метод принимает на вход саму обучающую выборку. Это сделано для единообразия с методами наподобие fit().
Но более универсально будет использовать эту метрику независимо от модели. Все метрики эффективности собраны в отдельный пакет metrics. Данная метрика называется r2_score. Обратите внимание, что при использовании этой функции ей надо передавать два вектора целевой переменной — сначала эмпирический, а вторым аргументом — теоретический.
1
2
3
4
5
6
7
8
from sklearn.metrics import r2_score
def r2(y, y_):
return 1 - ((y - y_)**2).sum() / ((y - y.mean())**2).sum()
print(reg.score(X, Y))
print(r2_score(Y, Y_))
print(r2(Y, Y_))
В данном коде мы еще реализовали самостоятельный расчет данной метрики, чтобы пояснить применение формулы выше. Можете самостоятельно убедиться, что три этих вызова напечатают одинаковые значения.
Коэффициент детерминации, или $R^2$ — это одна из немногих метрик эффективности для моделей регрессии, значение которой чем больше, тем лучше. Почти все остальные измеряют именно ошибку, что мы и увидим ниже. Еще это одна из немногих несимметричных метрик. Ведь если в формуле поменять теоретические и эмпирические значения, ее смысл и значение могут поменяться. Поэтому при использовании этой метрики нужно обязательно следить за порядком передачи аргументов.
При использовании этой метрики есть один небольшой подводный камень. Так как в знаменатели у этой формулы стоит вариация реального значения целевой переменной, важно следить, чтобы эта вариация присутствовала. Ведь если реальное значение целевой переменной будет одинаковым для всех объектов выборки, то вариация этой переменной будет равна 0. А значит, метрика будет не определена. Причем это единственная причина, почему эта метрика может быть неопределена. Надо понимать, что отсутствие вариации целевой переменной ставит под сомнение вообще целесообразность машинного обучения и моделирования в целом. Ведь что нам предсказывать если $y$ всегда один и тот же? С другой стороны, такая ситуация может случиться, например, при случайном разбиении выборки на обучающую и тестовую. Но об этом мы поговорим дальше.
Выводы:
- Коэффициент детерминации показывает силу связи между двумя случайными величинами.
- Если модель всегда предсказывает точно, метрика равна 1. Для тривиальной модели — 0.
- Значение метрики может быть отрицательно, если модель предсказывает хуже, чем тривиальная.
- Это одна из немногих несимметричных метрик эффективности.
- Эта метрика не определена, если $y=const$. Надо следить, чтобы в выборке присутствовали разные значения целевой переменной.
Средняя абсолютная ошибка (MAE)
Коэффициент детерминации — не единственная возможная характеристика эффективности моделей регрессии. Иногда полезно оценить отклонения предсказаний от истинных значений более явно. Как раз для этого служат сразу несколько метрик ошибок моделей регрессии. Самая простая из них — средняя абсолютная ошибка (mean absolute error, MAE). Она вычисляется по формуле:
[MAE(y, _hat{y}) = frac{1}{n} sum_{i=0}^{n-1} |y_i — hat{y_i}|]
Данная метрика действительно очень проста: это средняя величина разницы между предсказанными и реальными значениями целевой переменной. Причем эта разница берется по модулю, чтобы компенсировать возможные отрицательные отклонения. Мы уже рассматривали похожую функцию, когда говорили о конструировании функции ошибки для градиентного спуска. Но тогда мы отмели использование абсолютного значения, так как эта функция не везде дифференцируема. Но вот для метрики эффективности такого требования нет и MAE вполне можно использовать.
Если модель предсказывает идеально, то, естественно, все отклонения равны 0 и MAE в целом равна нулю. Но эта метрика не учитывает явно сравнение с тривиальной моделью — она просто тем хуже, чем больше. Ниже нуля она быть, конечно, не может.
Данная метрика выражается в натуральных единицах и имеет очень простой и понятный смысл — средняя ошибка модели. Степень применимости модели в таком случае можно очень просто понять исходя из предметной области. Например, наша модель ошибается в среднем на 500 рублей. Хорошо это или плохо? Зависит от размерности исходных данных. Если мы предсказываем цены на недвижимость — то модель прекрасно справляется с задачей. Если же мы моделируем цены на спички — то такая модель скорее всего очень неэффективна.
Использование данной метрики в пакете sklearn очень похоже на любую другую метрику, меняется только название:
1
2
3
4
5
>>> from sklearn.metrics import mean_absolute_error
>>> y_true = [3, -0.5, 2, 7]
>>> y_pred = [2.5, 0.0, 2, 8]
>>> mean_absolute_error(y_true, y_pred)
0.5
Выводы:
- MAE показывает среднее абсолютное отклонение предсказанных значений от реальных.
- Чем выше значение MAE, тем модель хуже. У идеальной модели $MAE=0$
- MAE очень легко интерпретировать — на сколько в среднем ошибается модель.
Средний квадрат ошибки (MSE)
Средний квадрат ошибки (mean squared error, MSE) очень похож на предыдущую метрику, но вместо абсолютного значения (модуля) используется квадрат:
[MSE(y, _hat{y}) = frac{1}{n} sum_{i=0}^{n-1} (y_i — hat{y_i})^2]
Граничные случаи у этой метрики такие же, как у предыдущей — 0 у идеальной модели, а в остальном — чем больше, тем хуже. MSE у тривиальной модели будет равна дисперсии целевой переменной. Но это не то, чтобы очень полезно на практике.
Эта метрика используется во многих моделях регрессии как функция ошибки. Но вот как метрику эффективности ее применяют довольно редко. Дело в ее интерпретируемости. Ведь она измеряется в квадратах натуральной величины. А какой физический смысл имеют, например, рубли в квадрате? На самом деле никакого. Поэтому несмотря на то, что математически MAE и MSE в общем-то эквивалентны, первая более проста и понятна, и используется гораздо чаще.
Единственное существенное отличие данной метрики от предыдущей состоит в том, что она чуть больший “вес” в общей ошибке придает большим значениям отклонений. То есть чем больше значение отклонения, тем сильнее оно будет вкладываться в значение MSE. Это иногда бывает полезно, когда исходя из задачи стоит штрафовать сильные отклонения предсказанных значений от реальных. Но с другой стороны это свойство делает эту метрику чувствительной к аномалиям.
Пример расчета метрики MSE:
1
2
3
4
5
>>> from sklearn.metrics import mean_squared_error
>>> y_true = [3, -0.5, 2, 7]
>>> y_pred = [2.5, 0.0, 2, 8]
>>> mean_squared_error(y_true, y_pred, squared=False)
0.612...
Выводы:
- MAE показывает средний квадрат отклонений предсказанных значений от реальных.
- Чем выше значение MSE, тем модель хуже. У идеальной модели $MSE=0$
- MSE больше учитывает сильные отклонения, но хуже интерпретируется, чем MAE.
Среднеквадратичная ошибка (RMSE)
Если главная проблема метрики MSE в том, что она измеряется в квадратах натуральных величин, что что будет, если мы возьмем от нее квадратный корень? Тогда мы получим среднеквадратичную ошибку (root mean squared error, RMSE):
[RMSE(y, _hat{y}) = sqrt{frac{1}{n} sum_{i=0}^{n-1} (y_i — hat{y_i})^2}]
Использование данной метрики достаточно привычно при статистическом анализе данных. Однако, для интерпретации результатов машинного обучения она имеет те же недостатки, что и MSE. Главный из них — чувствительность к аномалиям. Поэтому при интерпретации эффективности моделей регрессии чаще рекомендуется применять метрику MAE.
Пример использования:
1
2
3
4
5
>>> from sklearn.metrics import mean_squared_error
>>> y_true = [3, -0.5, 2, 7]
>>> y_pred = [2.5, 0.0, 2, 8]
>>> mean_squared_error(y_true, y_pred)
0.375
Выводы:
- RMSE — это по сути корень из MSE. Выражается в тех же единицах, что и целевая переменная.
- Чаще применяется при статистическом анализа данных.
- Данная метрика очень чувствительна к аномалиям и выбросам.
Среднеквадратичная логарифмическая ошибка (MSLE)
Еще одна довольно редкая метрика — среднеквадратическая логарифмическая ошибка (mean squared logarithmic error, MSLE). Она очень похожа на MSE, но квадрат вычисляется не от самих отклонений, а от разницы логарифмов (про то, зачем там +1 поговорим позднее):
[MSLE(y, _hat{y}) = frac{1}{n} sum_{i=0}^{n-1} (
ln(1 + y_i) — ln(1 + hat{y_i})
)^2]
Данная материка имеет специфическую, но довольно полезную сферу применения. Она применяется в тех случаях, когда значения целевой переменной простираются на несколько порядков величины. Например, если мы анализируем доходы физических лиц, они могут измеряться от тысяч до сотен миллионов. Понятно, что при использовании более привычных метрик, таких как MSE, RMSE и даже MAE, отклонения в больших значениях, даже небольшие относительно, будут полностью доминировать над отклонениями в малых значениях.
Это приведет к тому, что оценка моделей в подобных задачах классическими метриками будет давать преимущество моделям, которые более точны в одной части выборки, но почти не будут учитывать ошибки в других частях выборки. Это может привести к несправедливой оценке моделей. А вот использование логарифма поможет сгладить это противоречие.
Чаще всего, величины с таким больших размахом, что имеет смысл использовать логарифмическую ошибку, возникают в тех задачах, которые моделируют некоторые естественные процессы, характеризующиеся экспоненциальным ростом. Например, моделирование популяций, эпидемий, финансов. Такие процессы часто порождают величины, распределенные по экспоненциальному закону. А они чаще всего имеют область значений от нуля до плюс бесконечности, то есть иногда могут обращаться в ноль.
Проблема в том, что логарифм от нуля не определен. Именно поэтому в формуле данной метрики присутствует +1. Это искусственный способ избежать неопределенности. Конечно, если вы имеете дело с величиной, которая может принимать значение -1, то у вас опять будут проблемы. Но на практике такие особые распределения не встречаются почти никогда.
Использование данной метрике в коде полностью аналогично другим:
1
2
3
4
5
>>> from sklearn.metrics import mean_squared_log_error
>>> y_true = [3, 5, 2.5, 7]
>>> y_pred = [2.5, 5, 4, 8]
>>> mean_squared_log_error(y_true, y_pred)
0.039...
Выводы:
- MSLE это среднее отклонение логарифмов реальных и предсказанных данных.
- Так же, идеальная модель имеет $MSLE = 0$.
- Данная метрика используется, когда целевая переменная простирается на несколько порядков величины.
- Еще эта метрика может быть полезна, если моделируется процесс в экспоненциальным ростом.
Среднее процентное отклонение (MAPE)
Все метрики, которые мы рассматривали до этого рассчитывали абсолютную величину отклонения. Но ведь отклонение в 5 единиц при истинном значении 5 и при значении в 100 — разные вещи. В первом случае мы имеем ошибку в 100%, а во втором — только в 5%. Очевидно, что первый и второй случай должны по-разному учитываться в ошибке. Для этого придумана средняя абсолютная процентная ошибка (mean absolute percentage error, MAPE). В ней каждое отклонение оценивается в процентах от истинного значения целевой переменной:
[MAPE(y, _hat{y}) = frac{1}{n} sum_{i=0}^{n-1}
frac{|y_i — hat{y_i}|}{max(epsilon, |y_i|)}]
Эта метрика имеет одно критическое преимущество над остальными — с ее помощью можно сравнивать эффективность моделей на разных обучающих выборках. Ведь если мы возьмем классические метрики (например, MAE), то размер отклонений будет очевидно зависеть от самих данных. А в двух разных выборках и средняя величина скорее всего будет разная. Поэтому метрики MAE, MSE, RMSE, MSLE не сопоставимы при сравнении предсказаний, сделанных на разных выборках.
А вот по метрике MAPE можно сравнивать разные модели, которые были обучены на разных данных. Это очень полезно, например, в научных публикациях, где метрика MAPE (и ее вариации) практически обязательны для описания эффективности моделей регрессии.Ведь если одна модель ошибается в среднем на 3,9%, а другая — на 3,5%, очевидно, что вторая более точна. А вот если оперировать той же MAE, так сказать нельзя. Ведь если одна модель ошибается в среднем на 500 рублей, а вторая — на 490, очевидно ли, что вторая лучше? Может, она даже хуже, просто в исходных данных величина целевой переменной во втором случае была чуть меньше.
При этом у метрики MAPE есть пара недостатков. Во-первых, она не определена, если истинное значение целевой переменной равно 0. Именно для преодоления этого в знаменателе формулы этой метрики присутствует $max(epsilon, |y_i|)$. $epsilon$ — это некоторое очень маленькое значение. Оно нужно только для того, чтобы избежать деления на ноль. Это, конечно, настоящий математический костыль, но позволяет без опаски применять эту метрику на практике.
Во-вторых, данная метрика дает преимущество более низким предсказаниям. Ведь если предсказание ниже, чем реальное значение, процентное отклонение может быть от 0% до 100%. В это же время если предсказание выше реального, то верхней границы нет, предсказание может быть больше и на 200%, и на 1000%.
В-третьих, эта метрика несимметрична. Ведь в этой формуле $y$ и $hat{y}$ не взаимозаменяемы. Это не большая проблема и может быть исправлена использованием симметричного варианта этой метрики, который называется SMAPE (symmetric mean absolute percentage error):
[MAPE(y, _hat{y}) = frac{1}{n} sum_{i=0}^{n-1}
frac{|y_i — hat{y_i}|}{max(epsilon, (|hat{y_i}|, |y_i|) / 2)}]
В русскоязычной литературе данная метрика часто называется относительной ошибкой, так как она учитывает отклонение относительно целевого значения. В английском названии метрики она называется абсолютной. Тут нет никакого противоречия, так как “абсолютный” здесь значит просто взятие по модулю.
С точки зрения использования в коде, все полностью аналогично:
1
2
3
4
5
>>> from sklearn.metrics import mean_absolute_percentage_error
>>> y_true = [1, 10, 1e6]
>>> y_pred = [0.9, 15, 1.2e6]
>>> mean_absolute_percentage_error(y_true, y_pred)
0.2666...
Выводы:
- Идея этой метрики — это чувствительность к относительным отклонениям.
- Данная модель выражается в процентах и имеет хорошую интерпретируемость.
- Идеальная модель имеет $MAPE = 0$. Верхний предел — не ограничен.
- Данная метрика отдает предпочтение предсказанию меньших значений.
Абсолютная медианная ошибка
Практически во всех ранее рассмотренных метриках используется среднее арифметическое для агрегации частных отклонений в общую величину ошибки. Иногда это может быть не очень уместно, если в выборке присутствует очень неравномерное распределение по целевой переменной. В таких случаях может быть целесообразно использование медианной ошибки:
[MedAE(y, _hat{y}) = frac{1}{n} median_{i=0}^{n-1}
|y_i — hat{y_i}|]
Эта метрика полностью аналогична MAE за одним исключением: вместо среднего арифметического подсчитывается медианное значение. Медиана — это такое значение в выборке, больше которого и меньше которого примерно половина объектов выборки (с точностью до одного объекта).
Эта метрика чаще всего применяется при анализе демографических и экономических данных. Ее особенность в том, что она не так чувствительна к выбросам и аномальным значениям, ведь они практически не влияют на медианное значение выборки, что делает эту метрику более надежной и робастной, чем абсолютная ошибка.
Пример использования:
1
2
3
4
5
>>> from sklearn.metrics import median_absolute_error
>>> y_true = [3, -0.5, 2, 7]
>>> y_pred = [2.5, 0.0, 2, 8]
>>> median_absolute_error(y_true, y_pred)
0.5
Выводы:
- Медианная абсолютная ошибка похожа на среднюю абсолютную, но более устойчива к аномалиям.
- Применяется в задачах, когда известно, что в данных присутствуют выбросы, аномальные , непоказательные значения.
- Эта метрика более робастная, нежели MAE.
Максимальная ошибка
Еще одна достаточно экзотическая, но очень простая метрика эффективности регрессии — максимальная ошибка:
[ME(y, _hat{y}) = max_{i=0}^{n-1}
|y_i — hat{y_i}|]
Как следует из названия, это просто величина максимального абсолютного отклонения предсказанных значений от теоретических. Особенность этой метрики в том, что она вообще не характеризует распределение отклонений в целом. Поэтому она практически никогда не применяется самостоятельно, в качестве единственной метрики.
Эта метрика именно вспомогательная. В сочетании с другими метриками, она может дополнительно охарактеризовать, насколько сильно модель может ошибаться в самом худшем случае. Опять же, в зависимости от задачи, это может быть важно. В некоторых задачах модель, которая в среднем ошибается пусть чуть больше, но при этом не допускает очень больших “промахов”, может быть предпочтительнее, чем более точная модель в среднем, но у которой встречаются сильные отклонения.
Применение этой метрики та же просто, как и других:
1
2
3
4
5
>>> from sklearn.metrics import max_error
>>> y_true = [3, 2, 7, 1]
>>> y_pred = [9, 2, 7, 1]
>>> max_error(y_true, y_pred)
6
Выводы:
- Максимальная ошибка показывает наихудший случай предсказания модели.
- В некоторых задачах важно, чтобы модель не ошибалась сильно, а небольшие отклонения не критичны.
- Зачастую эта метрика используется как вспомогательная совместно с другими.
Метрики эффективности для классификации
Приступим к рассмотрению метрик эффективности, которые применяются для оценки моделей классификации. Для начала ответим на вопрос, почему для них нельзя использовать те метрики, которые мы уже рассмотрели в предыдущей части? Дело в том, что метрики эффективности регрессии так или иначе оценивают расстояние от предсказанного значения до реального. Это подразумевает, что в значениях целевой переменной существует определенный порядок. Формально говоря, предполагается, что целевая переменная измеряется по относительной шкале. Это значит, что разница между значениями имеет какой-то смысл. Например, если мы ошиблись в предполагаемой цене товара на 10 рублей, это лучше, чем ошибка на 20 рублей. Причем, можно сказать, что это в два раза лучше.
Но вот целевые переменные, которые существуют в задачах классификации обычно не обладают таким свойством. Да, метки классов часто обозначают числами (класс 0, класс 1, класс 5 и так далее). И мы используем эти числа в качестве значения переменных в программе. Но это ничего не значит. Представим объект, принадлежащий 0 классу, что бы этот класс не значил. Допустим, мы предсказали 1 класс. Было бы хуже, если бы мы предсказали 2 класс. Можно ли сказать, что во втором случае модель ошиблась в два раза сильнее? В общем случае, нельзя. Что в первом, что во втором случае модель просто ошиблась. Имеет значение только разница между правильным предсказанием и неправильным. Отклонение в задачах классификации не играет роли.
Поэтому метрики эффективности для классификации оценивают количество правильно и неправильно классифицированных (иногда еще говорят, распознанных) объектов. При этом разные метрики, как мы увидим, концентрируются на разных соотношениях этих количеств, особенно в случае, когда классов больше двух, то есть имеет место задача множественной классификации.
Причем метрики эффективности классификации тоже нельзя применять для оценки регрессионных моделей. Дело в том, что в задачах регрессии почти никогда не встречается полное совпадение предсказанного и реального значения. Так как мы работам с непрерывным континуумом значений, вероятность такого совпадения равна, буквально, нулю. Поэтому по метрикам для классификации практически любая регрессионная модель будет иметь нулевую эффективность, даже очень хорошая и точная модель. Именно потому, что для метрик классификации даже самая небольшая ошибка уже считается как промах.
Как мы говорили ранее,для оценки конкретной модели можно использовать несколько метрик одновременно. Это хорошая практика для задач регрессии, но для классификации — это практически необходимость. Дело в том, что метрики классификации гораздо легче “обмануть” с помощью тривиальных моделей, особенно в случае несбалансированных классов (об этом мы поговорим чуть позже). Тривиальной моделью в задачах классификации может выступать модель, которая предсказывает случайный класс (такая используется чаще всего), либо которая предсказывает всегда какой-то определенный класс.
Надо обратить внимание, что по многим метрикам, ожидаемая эффективность моделей классификации сильно зависит от количества классов в задаче. Чем больше классов, тем на меньшую эффективность в среднем можно рассчитывать.Поэтому метрики эффективности классификации не позволяют сопоставить задачи, состоящие из разного количества классов. Это следует помнить при анализе моделей. Если точность бинарной классификации составляет 50%, это значит, что модель работает не лучше случайного угадывания. Но в модели множественной классификации из, допустим, 10 000 классов, точность 50% — это существенно лучше случайного гадания.
Еще обратим внимание, что некоторые метрики учитывают только само предсказание, в то время, как другие — степень уверенности модели в предсказании. Вообще, все модели классификации разделяются на логические и метрические. Логические методы классификации выдают конкретное значение класса, без дополнительной информации. Типичные примеры — дерево решений, метод ближайших соседей. Метрические же методы выдают степень уверенности (принадлежности) объекта к одному или, чаще, ко всем классам. Так, например, работает метод логистической регрессии в сочетании с алгоритмом “один против всех”. Так вот, в зависимости, от того, какую модель классификации вы используете, вам могут быть доступны разные метрики. Те метрики, которые оценивают эффективность классификации в зависимости от выбранной величины порога не могут работать с логическими методами. Поэтому, например, нет смысла строить PR-кривую для метода ближайших соседей. Остальные метрики, которые не используют порог, могут работать с любыми методами классификации.
Выводы:
- Метрики эффективности классификации подсчитывают количество правильно распознанных объектов.
- В задачах классификации почти всегда надо применять несколько метрик одновременно.
- Тривиальной моделью в задачах классификации считается та, которая предсказывает случайный класс, либо самый популярный класс.
- Качество бинарной классификации при прочих равных почти всегда будет сильно выше, чем для множественной.
- Вообще, чем больше в задаче классов, тем ниже ожидаемые значения эффективности.
- Некоторые метрики работают с метрическими методами, другие — со всеми.
Доля правильных ответов (accuracy)
Если попробовать самостоятельно придумать способ оценить качество модели классификации, ничего не зная о существующих метриках, скорее всего получится именно метрика точности (accuracy). Это самая простая и естественная метрика эффективности классификации. Она подсчитывается как количество объектов в выборке, которые были классифицированы правильно (то есть, для которых теоретическое и эмпирическое значение метки класса — целевой переменной — совпадает), разделенное на общее количество объектов выборки. Вот формула для вычисления точности классификации:
[acc(y, hat{y}) = frac{1}{n} sum_{i=0}^{n} 1(hat{y_i} = y_i)]
В этой формуле используется так называемая индикаторная функция $1()$. Эта функция равна 1 тогда, когда ее аргумент — истинное выражение, и 0 — если ложное. В данном случае она равна единице для всех объектов, у которых предсказанное значение равно реальному ($hat{y_i} = y_i$). Суммируя по всем объектам мы получим количество объектов, классифицированных верно. Перед суммой стоит множитель $frac{1}{n}$, где $n$ — количество объектов в выборке. То есть в итоге мы получаем долю правильных ответов исследуемой модели.
Значение данной метрики может быть выражено в долях единицы, либо в процентах, домножив значение на 100%. Чем выше значение accuracy, тем лучше модель классифицирует выборку, то есть тем лучше ответы модели соответствуют значениям целевой переменной, присутствующим в выборке. Если модель всегда дает правильные предсказания, то ее accuracy будет равн 1 (или 100%). Худшая модель, которая всегда предсказывает неверно будет иметь accuracy, равную нулю, причем это нижняя граница, хуже быть не может.
В дальнейшем, для обозначения названий метрик эффективности я буду использовать именно английские названия — accuracy, precision, recall. У каждого из этих слов есть перевод на русский, но так случилось, что в русскоязычных терминах существует путаница. Дело в том, что и accuracy и precision чаще всего переводятся словом “точность”. А это разные метрики, имеющие разный смысл и разные формулы. Accuracy еще называют “правильность”, precision — “прецизионность”. Причем у последнего термина есть несколько другое значение в метрологии. Поэтому, пока будем обозначать эти метрики изначальными названиями.
А вот accuracy тривиальной модели будет как раз зависеть от количества классов. Если мы имеем дело с бинарной классификацией, то модель будет ошибаться примерно в половине случаев. То есть ее accuracy будет 0,5. В общем же случае, если есть $m$ классов, то тривиальная модель, которая предсказывает случайный класс будет иметь accuracy в среднем около $frac{1}{m}$.
Но это в случае, если в выборке объекты разных классов встречаются примерно поровну. В реальности же часто встречаются несбалансированные выборки, в которых распределение объектов по классам очень неравномерно. Например, может быть такое, что объектов одного класса в десять раз больше, чем другого. В таком случае, accuracy тривиальной модели может быть как выше, так и ниже $1/m$. Вообще, метрика accuracy очень чувствительна к соотношению классов в выборке. И именно поэтому мы рассматриваем другие способы оценки качества моделей классификации.
Использование метрики accuracy в библиотеке sklearn ничем принципиальным не отличается от использования других численных метрик эффективности:
1
2
3
4
5
6
>>> import numpy as np
>>> from sklearn.metrics import accuracy_score
>>> y_pred = [0, 2, 1, 3]
>>> y_true = [0, 1, 2, 3]
>>> accuracy_score(y_true, y_pred)
0.5
В данном примере в задаче 4 класса (0, 1, 2, 3) и столько же объектов, по одному на каждый класс. Модель правильно классифицировала первый и третий объект, то есть половину. Поэтому ее accuracy составляет 0,5 или 50%.
Выводы:
- Точность (accuracy) — самая простая метрика качества классификации, доля правильных ответов.
- Может быть выражена в процентах и в долях единицы.
- Идеальная модель дает точность 1.0, тривиальная — 0.5, самая худшая — 0.0.
- Тривиальная модель в множественной сбалансированной задаче классификации дает точность 1/m.
- Метрика точности очень чувствительная к несбалансированности классов.
Метрики классификации для неравных классов (precision, recall, F1)
Как мы говорили ранее, метрика accuracy может быть чувствительна к несбалансированности классов. Рассмотрим типичный пример — диагностика заболевания. Допустим, в случайной выборке людей заболевание встречается один раз на 100 человек. То есть в выборке у нас может быть всего 1% объектов, принадлежащих положительному классу и 99% — отрицательному, то есть почти в 100 раз больше. Какая accuracy будет у абсолютно тривиальной модели, которая всегда предсказывает отрицательный класс? Такая модель будет права в 99% случаев и ошибаться только в 1%. То есть иметь accuracy 0,99. Естественно, ценность такой модели минимальна, несмотря на высокий показатель метрики. Поэтому в случае с сильно несбалансированными классами метрика accuracy не то, чтобы неверна, она непоказательна, то есть не дает хорошего представления о качественных характеристиках модели.
Для более полного описания модели используется ряд других метрик. Для того, чтобы понять, как они устроены и что показывают нужно разобраться с понятием ошибок первого и второго рода. Пока будем рассматривать случай бинарной классификации, а о том, как эти метрики обобщаются на множественные задачи, поговорим позднее. Итак, у нас есть задача бинарной классификации, объекты положительного и отрицательного класса. Идеальным примером для этого будет все та же медицинская диагностика.
По отношению к модели бинарной классификации все объекты выборки можно разделить на четыре непересекающихся множества. Истинноположительные (true positive, TP) — это те объекты, которые отнесены моделью к положительному классу и действительно ему принадлежат. Истинноотрицательные (true negative, TN) — соответственно те, которые правильно распознаны моделью как принадлежащие отрицательному классу. Ложноположительные объекты (FP, false positive) — это те, которые модель распознала как положительные, хотя на самом деле они отрицательные. В математической статистике такая ситуация называется ошибкой первого рода. И, наконец, ложноотрицательные значения (false negative, FN) — это те, которые ошибочно отнесены моделью к отрицательному классу, хотя на самом деле они принадлежат положительному.
В примере с медицинско диагностикой, ложноположительные объекты или ошибки первого рода — это здоровые пациенты, которых при диагностике ошибочно назвали больными. Ложноотрицательные, или ошибки второго рода, — это больные пациенты, которых диагностическая модель “пропустила”, ошибочно приняв за здоровых. Очевидно, что в этой задаче, как и во многих других, ошибки первого и второго рода не равнозначны. В медицинской диагностике, например, гораздо важнее распознать всех здоровых пациентов, то есть не допустить ложноотрицательных объектов или ошибок второго рода. Ошибки же первого рода, или ложноположительные предсказания, тоже нежелательны, но значительно меньше, чем ложноотрицательные.
Так вот, метрика accuracy учитывает и те и другие ошибки одинаково, абсолютно симметрично. В терминах наших четырех классов она может выражаться такой формулой:
[A = frac{TP + TN}{TP + TN + FP + FN}]
Обратите внимание, что если в модели переименовать положительный класс в отрицательный и наоборот, то это никак не повлияет на accuracy. Так вот, в зависимости от решаемой задачи, нам может быть необходимо воспользоваться другими метриками. Вообще, их существует большое количество, но на практике чаще других применяются метрики precision и recall.
Precision (чаще переводится как “точность”, “прецизионность”) — это доля объектов, плавильно распознанных как положительные из всех, распознанных как положительные. Считается этот показатель по следующей формуле: $P = frac{TP}{TP + FP}$. Как можно видеть, precision будет равен 1, если модель не делает ошибок первого рода, то есть не дает ложноположительных предсказаний. Причем ошибки второго рода (ложноотрицательные) вообще не влияют на величину precision, так как эта метрика рассматривает только объекты, отнесенные моделью к положительным.
Precision характеризует способность модели отличать положительный класс от отрицательного, не делать ложноположительных предсказаний. Ведь если мы будем всегда предсказывать отрицательный класс, precision будет не определен. А вот если модель будет всегда предсказывать положительный класс, то precision будет равен доли объектов этого класса в выборке. В нашем примере с медицинской диагностикой, модель, всех пациентов записывающая в больные даст precision всего 0,01.
Метрика recall (обычно переводится как “полнота” или “правильность”) — это доля положительных объектов выборки, распознанных моделью. То есть это отношение все тех же истинноположительных объектов к числу всех положительных объектов выборки: $R = frac{TP}{TP + FN}$. Recall будет равен 1 только в том случае, если модель не делает ошибок второго рода, то есть не дает ложноотрицательных предсказаний. А вот ошибки первого рода (ложноположительные) не влияют на эту метрику, так как она рассматривает только объекты, которые на самом деле принадлежат положительному классу.
Recall характеризует способность модели обнаруживать все объекты положительного класса. Если мы будем всегда предсказывать отрицательный класс, то данная метрика будет равна 0, а если всегда положительный — то 1. Метрика Recall еще называется полнотой, так как она характеризует полноту распознавания положительного класса моделью.
В примере с медицинской диагностикой нам гораздо важнее, как мы говорили, не делать ложноотрицательных предсказаний. Поэтому метрика recall будет для нас важнее, чем precision и даже accuracy. Однако, как видно из примеров, каждый из этих метрик легко можно максимизировать довольно тривиальной моделью. Если мы будет ориентироваться на recall, то наилучшей моделью будет считаться та, которая всегда предсказывает положительный класс. Если только на precision — то “выиграет” модель, которая всегда предсказывает наоборот, положительный. А если брать в расчет только accuracy, то при сильно несбалансированных классах модель, предсказывающая самый популярный класс. Поэтому эти метрики нелья использовать по отдельности, только сразу как минимум две из них.

Так как метрики precision и recall почти всегда используются совместно, часто возникает ситуация, когда есть две модели, у одной из которых выше precision, а у второй — recall. Возникает вопрос, как выбрать лучшую? Для такого случая можно посчитать среднее значение. Но для этих метрик больше подойдет среднее не арифметическое, а гармоническое, ведь оно равно 0, если хотя бы одно число равно 0. Эта метрика называется $F_1$:
[F_1 = frac{2 P R}{P + R} = frac{2 TP}{2 TP + FP + FN}]
Эта метрика полезна, если нужно одно число, которое в себе объединяет и precision и recall. Но эта формула подразумевает, что нам одинаково важны и то и другое. А как мы заметили раньше, часто одна из этих метрик важнее. Поэтому иногда используют обобщение метрики $F_1$, так называемое семейство F-метрик:
[F_{beta} = (1 + beta^2) frac{P R}{beta^2 P + R}]
Эта метрика имеет параметр $beta > 0$, который определяет, во сколько раз recall важнее precision. Если этот параметр больше единицы, то метрика будет полагать recall более важным. А если меньше — то важнее будет precision. Если же $beta = 1$, то мы получим уже известную нам метрику $F_1$. Все метрики из F-семейства измеряются от 0 до 1, причем чем значение больше, тем модель лучше.
1
2
3
4
5
6
7
8
9
>>> from sklearn import metrics
>>> y_pred = [0, 1, 0, 0]
>>> y_true = [0, 1, 0, 1]
>>> metrics.precision_score(y_true, y_pred)
1.0
>>> metrics.recall_score(y_true, y_pred)
0.5
>>> metrics.f1_score(y_true, y_pred)
0.66...
Выводы:
- Если классы в задаче не сбалансированы, то метрика точности не дает полного представления о качестве работы моделей.
- Для бинарной классификации подсчитывается количество истинно положительных, истинно отрицательных, ложно положительных и ложно отрицательных объектов.
- Precision — доля истинно положительных объектов во всех, распознанных как положительные.
- Precision характеризует способность модели не помечать положительные объекты как отрицательные (не делать ложно положительных прогнозов).
- Recall — для истинно положительных объектов во всех положительных.
- Recall характеризует способность модели выявлять все положительные объекты (не делать ложно отрицательных прогнозов).
- F1 — среднее гармоническое между этими двумя метриками. F1 — это частный случай. Вообще, семейство F-метрик — это взвешенное среднее гармоническое.
- Часто используют все вместе для более полной характеристики модели.
Матрица классификации
Матрица классификации — это не метрика сама по себе, но очень удобный способ “заглянуть” внутрь модели и посмотреть, насколько хорошо она классифицирует какую-то выборку объектов. Особенно удобна эта матрица в задачах множественной классификации, когда из-за большого количества классов численные метрики не всегда наглядно показывают, какие объекты к каким классам относятся.
С использованием библиотеки sklearn матрица классификации может быть сформирована всего одной строчкой кода:
1
2
3
4
5
6
7
>>> from sklearn.metrics import confusion_matrix
>>> y_true = [2, 0, 2, 2, 0, 1]
>>> y_pred = [0, 0, 2, 2, 0, 2]
>>> confusion_matrix(y_true, y_pred)
array([[2, 0, 0],
[0, 0, 1],
[1, 0, 2]])
В этой матрице по строкам располагаются истинные значения целевой переменной, то есть действительные значения классов. По столбцам же отмечены предсказанные классы. В самой матрице на пересечении строки и столбца отмечается число объектов, которые принадлежат данному действительному классу, но моделью были распознаны как объекты данного предсказанного класса.
Естественно, элементы, располагающиеся на главной диагонали, показывают объекты, которые были правильно распознаны моделью. Элементы же вне этой диагонали — это ошибки классификации. Поэтому чем лучше модель, тем выше должны быть значения по диагонали и тем меньше — вне ее. В идеале все элементы вне главной диагонали должны быть нулевыми.
Но гораздо удобнее представлять ее в графическом виде:

Источник: sklearn.
В таком виде матрица представляется в виде тепловой карты, в которой чем выше значение, тем насыщеннее оттенок цвета. Это позволяет при первом взгляде на матрицу понять, как часто она ошибается и в каких именно классах. В отличие от простых численных метрик, матрица классификации может дать информацию о паттернах распространенных ошибок, которые допускает данная модель.
Практически любое аномальное или тривиальное поведение модели будет иметь отражение в матрице классификации. Например, если модель чаще чем нужно предсказывает один класс, это сразу подсветит отдельный столбец в ней. Если же модель путает два класса, то есть не различает объекты этих классов, то в матрице будут подсвечены четыре элемента, располагающиеся в углах прямоугольника. Еще одно распространенное поведение модель — когда она распознает объекты одного класса, как объекты другого — подсветит один элемент вне главной диагонали.
Эта матрица очень наглядно показывает, как часто и в каких конкретно классах ошибается модель. Поэтому анализ этой матрицы может дать ценную информацию о путях увеличения эффективности моделей. Например, можно провести анализ ошибок на основе показаний данной матрицы — проанализировать объекты, на которых модель чаще всего ошибается. Может, будет выявлена какая-то закономерность, либо общая характеристика. Добавление информации о таких параметрах объектов к матрице атрибутов обычно очень сильно улучшает эффективность моделей.
Выводы:
- Матрица классификации, или матрица ошибок представляет собой количество объектов по двум осям — истинный класс и предсказанный класс.
- Обычно, истинный класс располагается по строкам, а предсказанный — по столбцам.
- Для идеальной модели матрица должна содержать ненулевые элементы только на главной диагонали.
- Матрица позволяет наглядно представить результаты классификации и увидеть, в каких случаях модель делает ошибки.
- Матрица незаменима при анализе ошибок, когда исследуется, какие объекты были неправильно классифицированы.
Метрики множественной классификации
Все метрики, о которых мы говорили выше рассчитываются в случае бинарной классификации, так как определяются через понятия ложноположительных, ложноотрицательных прогнозов. Но на практике чаще встречаются задачи множественной классификации. В них не определяется один положительный и один отрицательный класс, поэтому все рассуждения о precision и recall, казалось бы, не имеют смысла.
На самом деле, все рассмотренные метрики прекрасно обобщаются на случай множественных классов. Рассмотрим простой пример. У нас есть три класса — 0, 1 и 2. Есть пять объектов, каждый их которых принадлежит одному их этих трех классов. Истинные значения целевой переменной такие: $y = lbrace 0, 1, 2, 2, 0 rbrace$. Имеется модель, которая предсказывает классы этих объектов, соответственно так: $hat{y} = lbrace 0, 0, 2, 1, 0 rbrace$. Давайте рассчитаем известные нам метрики качества классификации.
С метрикой accuracy все просто. Модель правильно предсказала класс в трех случаях из пяти — первом, третьем и пятом. А в двух случаях — ошиблась. Поэтому метрика рассчитывается так: $A = 3 / 5 = 0.6$. То есть точность модели — 60%.
А вот precision и recall рассчитываются более сложно. В моделях множественной классификации эти метрики могут быть рассчитаны отдельно по каждому классу. Подход в этом случае очень похож на алгоритм “один против всех” — для каждого класса он предполагается положительным, а все остальные классы — отрицательными. Давайте рассчитаем эти метрики на нашем примере.
Возьмем нулевой класс. Его обозначим за 1, а все остальные — за 0. Тогда вектора эмпирических и теоретических значений целевой пременной станут выглядеть так:
$y = lbrace 1, 0, 0, 0, 1 rbrace$,
$hat{y} = lbrace 1, 1, 0, 0, 1 rbrace$.
Тогда $P = frac{TP}{TP + FP} = frac{2}{3} approx 0.67$, ведь у нас получается 2 истинноположительных предсказания (первый и пятый объекты) и одно ложноположительное (второй). $R = frac{TP}{TP + FN} = frac{2}{2} = 1$, ведь в модели нет ложноотрицательных прогнозов.
$F_1 = frac{2 P R}{P + R} = frac{2 TP}{2 TP + FP + FN} = frac{2 cdot 2}{2 cdot 2 + 1 + 0} = frac{4}{5} = 0.8$.
Аналогично рассчитываются метрики и по остальным классам. Например, для первого класса вектора целевой переменной будут такими:
$y = lbrace 0, 1, 0, 0, 0 rbrace$,
$hat{y} = lbrace 0, 0, 0, 1, 0 rbrace$. Обратите внимание, что в данном случае получается, что модель ни разу не угадала. Такое тоже бывает, и в таком случае, метрики будут нулевые. Для третьего класса попробуйте рассчитать метрики самостоятельно, а чуть ниже можно увидеть правильный ответ.
Конечно, при использовании библиотечный функций не придется рассчитывать все эти метрики вручную. В библиотеке sklearn для этого есть очень удобная функция — classification_report, отчет о классификации, которая как раз вычисляет все необходимые метрики и представляет результат в виде наглядной таблицы. Вот как будет выглядеть рассмотренный нами пример:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
>>> from sklearn.metrics import classification_report
>>> y_true = [0, 1, 2, 2, 0]
>>> y_pred = [0, 0, 2, 1, 0]
>>> target_names = ['class 0', 'class 1', 'class 2']
>>> print(classification_report(y_true, y_pred, target_names=target_names))
precision recall f1-score support
class 0 0.67 1.00 0.80 2
class 1 0.00 0.00 0.00 1
class 2 1.00 0.50 0.67 2
accuracy 0.60 5
macro avg 0.56 0.50 0.49 5
weighted avg 0.67 0.60 0.59 5
Здесь мы видим несколько строк, соответствующих классам в нашей задаче. По каждому классу рассчитаны метрики precision, recall и $F_1$. Последний столбец называется support — это количество объектов данного класса в используемой выборке. Это тоже важный показатель, так как чем меньше объектов какого-то класса, тем хуже он обычно распознается.
Ниже приведены интегральные, то есть общие метрики эффективности модели. Это три последние строки таблицы. В первую очередь это accuracy — она всегда рассчитывается один раз. Обратите внимание, что в столбце support здесь везде стоит 5 — это общее число объектов выборки. Ниже приведены средние значения по метрикам precision, recall и $F_1$. Почему же строк две? Дело в том, что усреднять эти метрики можно по-разному.
Во-первых, можно взять обычное среднее арифметическое из метрик всех классов. Это называется macro average. Это самый простой способ, но у него есть одна проблема. Почему метрики очень малочисленных классов должны давать тот же вклад в итоговый результат, что и метрики очень многочисленных? Можно усреднить метрики используя в качестве весов долю каждого класса в выборке. Такое усреднение называется weighted average. Обратите внимание, что при усреднении метрика $F_1$ может получиться не между precision и recall.
Отчет о классификации — очень полезная функция, использование которой практически обязательно при анализе эффективности моделей классификации. Особенно для задач множественной классификации. Эта таблица может дать важную информацию о том, какие классы распознаются моделью лучше, какие — хуже, как это связано в численностью классов в выборке. Анализ этой таблицы может навести на необходимость определенных действий по повышению эффективности модели. Например, можно понять, какие данные полезно будет добавить в модель.
Выводы:
- Метрики для каждого класса рассчитываются, полагая данный класс положительным, а все остальные — отрицательными.
- Каждую метрику можно усреднить арифметически или взвешенно по классам. Весами выступают объемы классов.
- В модуле sklearn реализовано несколько алгоритмов усреднения они выбираются исходя их задачи.
- В случае средневзвешенного, F1-метрика может получиться не между P и R.
- Отчет о классификации содержит всю необходимую информацию в стандартной форме.
- Отчет показывает метрики для каждого класса, а так же объем каждого класса.
- Также отчет показывает средние и средневзвешенные метрики для всей модели.
- Отчет о классификации — обязательный элемент представления результатов моделирования.
- По отчету можно понять сбалансированность задачи, какие классы определяются лучше, какие — хуже.
PR-AUC
При рассмотрении разных моделей классификации мы упоминали о том, что они подразделяются на метрические и логические методы. Логические методы (дерево решений, k ближайших соседей) выдают конкретную метку класса,без какой-либо дополнительной информации. Метрические методы (логистическая регрессия, перцептрон, SVM) выдают принадлежность данного объекта к разным классам, присутствующим в задаче. При рассмотрении модели логистической регрессии мы говорили, что предсказывается положительный класс, если значение логистической функции больше 0,5.
Но это пороговое значение можно поменять. Что будет, если мы измени его на 0,6? Тогда мы для некоторых объектовы выборки изменим предсказание с положительного класса на отрицательный. То есть без изменения модели можно менять ее предсказания. Это значит, что изменятся и метрики модели, то есть ее эффективность.
Чем больше мы установим порог, тем чаще будем предсказывать отрицательный класс. Это значит, что в среднем, у модели будет меньше ложноположительных предсказаний, но может стать больше ложноотрицательных. Значит, у модели может увеличится precision, то упадет recall. В крайнем случае, если мы возьмем порог равный 1, мы всегда будем предсказывать отрицательный класс. Тогда у модели будет $P = 1, R = 0$. Если же, наоборот, возьмем в качестве порога 0, то мы всегда будем предсказывать отрицательный класс, а значит у модели будет $P = 0, R = 1$, так как она не будет давать ложноположительных прогнозов, но будут встречаться ложноотрицательные.
Это означает, что эффективность моделей метрической классификации зависит не только от того, как модель соотносится с данными, но и от значения порога. Из этого следует, кстати, что было бы не совсем правильно вообще сравнивать метрики двух разных моделей между собой. Ведь значение этих метрик будет зависеть не только от самих моделей, но и от порогов, которые они используют. Может, первая модель будет лучше, если немного изменить ее пороговое значение? Может, одна из метрик второй модели станет выше, если изменить ее порог.
Это все сильно затрудняет анализ метрических моделей классификации. Для сравнения разных моделей необходим способ “убрать” влияние порога, сравнить модели вне зависимости от его значения. И такой способ есть. Достаточно просто взять все возможные значения порога, посчитать метрики в каждом из них и затем усреднить. Для этого служит PR-кривая или кривая “precision-recall”:

Каждая точка на этом графике представляет собой значение precision и recall для конкретного значения порога. Для построения этого графика выбирают все возможные значение порога и отмечают на графике. Давайте рассмотрим простой пример из 10 точек. Истинные значения классов этих точек равны, соответственно, $y = lbrace 0, 0, 0, 0, 0, 1, 1, 1, 1, 1 rbrace$. Модель (сейчас совершенно неважно, какая) выдает следующие предсказания для этих объектов: $h(x) = lbrace 0.1, 0.2, 0.3, 0.45, 0.6, 0.4, 0.55, 0.7, 0.8, 0.9 rbrace$. Заметим, что модель немного ошибается для средних объектов, то есть она не будет достигать стопроцентной точности. Построим таблицу, в которой переберем некоторые значения порога и вычислим, к какому классу будет относиться объект при каждом значении порога:
| y | h(x) | 0,1 | 0,15 | 0,2 | 0,3 | 0,4 | 0,5 | 0,6 | 0,7 | 0,8 | 0,9 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0,1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0,2 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0,3 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0,45 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0,6 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0,4 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0,55 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0,7 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
| 1 | 0,8 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| 1 | 0,9 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
Можно сразу заметить, что чем выше порог, тем чаще предсказывается отрицательный класс. В крайних случаях модель всегда предсказывает либо положительный класс (при малых значениях порога), либо отрицательный (при больших).
Далее, для каждого значения порога рассчитаем количество истинно положительных, истинно отрицательных, ложноположительных и ложноотрицательных предсказаний. На основе этих данных легко рассчитать и метрики precision и recall. Запишем это в таблицу:
| y | h(x) | 0,1 | 0,15 | 0,2 | 0,3 | 0,4 | 0,5 | 0,6 | 0,7 | 0,8 | 0,9 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TP | 5 | 5 | 5 | 5 | 5 | 4 | 3 | 3 | 2 | 1 | 0 | |
| TN | 0 | 0 | 1 | 2 | 3 | 4 | 4 | 5 | 5 | 5 | 5 | |
| FP | 5 | 5 | 4 | 3 | 2 | 1 | 1 | 0 | 0 | 0 | 0 | |
| FN | 0 | 0 | 0 | 0 | 0 | 1 | 2 | 2 | 3 | 4 | 5 | |
| P | 0,50 | 0,50 | 0,56 | 0,63 | 0,71 | 0,80 | 0,75 | 1,00 | 1,00 | 1,00 | 1,00 | |
| R | 1,00 | 1,00 | 1,00 | 1,00 | 1,00 | 0,80 | 0,60 | 0,60 | 0,40 | 0,20 | 0,00 |
При самом низком значении порога модель всегда предсказывает отрицательный класс, метрика recall равна 1, а метрика precision равна доли отрицательного класса в выборке. Причем ниже этого значения precision уже не опускается. Можно заметить, что в целом при повышении порога precision повышается, а recall понижается. В другом крайнем случае, когда порог равен 1, модель всегда предсказывает отрицательный класс, метрика recall равна 0, а precision — 1 (на самом деле эта метрика не определена, но считается равной именно 1, так как ее значение стремится к этому при повышении порога). За счет чего это происходит?
При повышении порога может произойти один из трех случаев. Первый заключается в том, что данное изменение может не влияет ни на одно предсказание. Так происходит, например, при повышении порога с 0,1 до 0,15. Оценка ни одного объекта не попадает в данный диапазон, поэтому ни одно предсказание не меняется. И, соответственно, не изменится ни одна метрика.
Если же повышение порога все-таки затрагивает один или несколько объектов, то изменение предсказания может произойти только с положительного на отрицательное. Допустим, для простоты, что повышение порога затрагивает только один объект. То есть мы изменяем предсказание по одному объекту с 1 на 0. Второй случай заключается в том, что это изменение правильное. То есть объект в действительности принадлежит отрицательному классу. Так происходит, например, при изменении порога с 0,15 до 0,2. В данном случае первый объект из ложноположительного стал истинно отрицательным. Такое изменение не влияет на recall, но повышает precision.
Третий случай заключается в том, что изменение предсказаные было неверным. То есть объект из истинно положительного стал ложноотрицательным. Это происходит, например, при изменении порога с 0,4 до 0,5 — в данном случае шестой объект становится классифицированным ошибочно. Уменьшение количества истинно положительных объектов снижает обе метрики — и precision и recall.
Таким образом можно заключить, что recall при повышении порога может оставаться неизменным или снижаться, а precision может как повышаться, так и понижаться, но в среднем будет повышаться за счет уменьшения доли ложноположительных предсказаний. Если изобразить рассмотренный пример на графике можно получить такую кривую:

PR-кривая не всегда монотонна, обе метрики могут изменяться как однонаправленно, так и разнонаправленно при изменении порогового значения. Но главный смысл этой кривой не в этом. При таком анализе очень просто обобщить эффективность модели вне зависимости от значения порога. Для этого нужно всего лишь найти площадь под графиком этой кривой. Эта метрика называется PR-AUC (area under the curve) или average precision (AP). Чем она выше, тем качественнее модель.
Давайте порассуждаем, ка будет вести себя идеальная модель. Крайние случаи, когда порога равны 0 и 1, значения метрик будут такими же, как и всегда. Но вот при любом другом значении порога модель будет классифицировать все объекты правильно. И обе метрики у нее будут равны 1. Таким образом, PR-кривая выродится в два отрезка, один из которых проходит из точки (0, 1) в точку (1, 1). и площадь под графиком будет равна 1. У самой худшей же модели метрики будут равны 0, так как она всегда будет предсказывать неверно. И площадь тоже будет равна 0.
У случайной модели, как можно догадаться, площадь под графиком будет равна 0,5. Поэтому метрика PR-AUC может использоваться для сравнения разных моделей метрической классификации вне зависимости от значения порога. Также эта метрика показывает соотношение данной модели и случайной. Если PR-AUC модели меньше 0,5, значит она хуже предсказывает класс, чем простое угадывание.
Выводы:
- Кривая precision-recall используется для методов метрической классификации, которые выдают вероятность принадлежности объекта данному классу.
- Дискретная классификации производится при помощи порогового значения.
- Чем больше порог, тем больше объектов модель будет относить к отрицательному классу.
- Повышение порога в среднем увеличивает precision модели, но понижает recall.
- PR-кривая используется чтобы выбрать оптимальное значение порога.
- PR-кривая нужна для того, чтобы сравнивать и оценивать модели вне зависимости от выбранного уровня порога.
- PR-AUC — площадь под PR-кривой, у лучшей модели — 1.0, у тривиальной — 0.5, у худшей — 0.0.
ROC_AUC
Помимо кривой PR есть еще один довольно популярный метод оценки эффективности метрических моделей классификации. Он использует тот же подход, что и PR-кривая, но немного другие координаты. ROC-кривая (receiver operating characteristic) — это график показывающий соотношение доли истинно положительных предсказаний и ложноположительных предсказаний в модели метрической классификации для разных значений порога.
В этой кривой используются два новых термина — доля истинно положительных и доля ложноположительных предсказаний. Доля истинно положительных предсказаний (TPR, true positive rate), как можно догадаться, это отношение количества объектов выборки, правильно распознанных как положительные, ко всем положительным объектам. Другими словами, это всего лишь иное название метрики recall.
А вот доля ложноположительных предсказаний (FPR, false positive rate) считается как отношение количества отрицательных объектов, неправильно распознанных как положительные, в общем количестве отрицательных объектов выборки:
[TPR = frac{TP}{TP + FN} = R \
FRP = frac{FP}{TN + FP} = 1 — S]
Обратите внимание, что FPR — мера ошибки модели. То есть, чем больше — тем хуже. У идеальной модели $FRP=0$, а у наихудшей — $FPR=1$. Для иллюстрации давайте рассчитаем эти метрики для нашего примера, который мы использовали выше (для дополнительной информации еще приведена метрика accuracy для каждого значения порога):
| y | h(x) | 0,1 | 0,2 | 0,3 | 0,4 | 0,5 | 0,6 | 0,7 | 0,8 | 0,9 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| TPR | 1,00 | 1,00 | 1,00 | 1,00 | 0,80 | 0,60 | 0,60 | 0,40 | 0,20 | 0,00 | |
| FPR | 1,00 | 0,80 | 0,60 | 0,40 | 0,20 | 0,20 | 0,00 | 0,00 | 0,00 | 0,00 | |
| A | 0,50 | 0,60 | 0,70 | 0,80 | 0,80 | 0,70 | 0,80 | 0,70 | 0,60 | 0,50 |
Можно заметить, что при увеличении порога обе эти метрики увеличиваются, начиная со значения 1 до нуля. Причем, движения этих двух показателей всегда однонаправленно. Давайте опять же разберемся, почему так. Если увеличение порога приводит к правильному изменению классификации, то есть изменению ложноположительного значения на истинно отрицательное, то это уменьшит FRP, но не затронет TRP. Если же изменение будет неверным, то есть истинно положительное значение поменялось на ложноотрицательное, это однозначно уменьшит TPR, при этом FRP либо уменьшится так же, либо останется неименным.
В итоге, кривая получается монотонной, причем она всегда проходит через центр координат и через точку (1, 1). В нашем примере кривая будет выглядеть так:

Более сложные данные могут выглядеть с большим количеством деталей, но общая форма и монотонность сохраняются:

Также, как и с кривой PR, важное значение имеет площадь под графиком. Эта метрика называется ROC-AUC и является одной из самых популярных метрик качества метрических моделей классификации. Ее главное преимущество перед другими метриками состоит в том, что она позволяет объективно сопоставить уровень качества разных моделей классификации, решающих одну и ту же задачу, но обученных на разных данных. Это приводит к частому использованию ROC-AUC, например, в научной литературе для представления результатов моделирования.
Существует множество споров, какая диагностическая кривая более адекватно измеряет качество классификации — ROC или PR. Считается, что PR-кривая больше ориентирована на задачи, в которых присутствует дисбаланс классов. Это задачи в которых объектов одного класса значительно больше чем другого, классы имеют разное толкование и, как следствие, ошибки первого и второго рода не равнозначны. Зачастую это модели бинарной классификации. ROC же дает более адекватную картину в задачах, где классов примерно поровну в выборке. Но для полного анализа модели все равно рекомендуется использовать оба метода.
В случае с множественной классификацией построение диагностических кривых происходит отдельно по каждому классу. Так же, как и при расчете метрик precision и recall, каждый класс поочередно полагается положительным, а остальные — отрицательными. Каждая такая частная кривая показывает качество распознавания конкретного класса. Поэтому кривые могут выглядеть примерно так:

Источник: sklearn.
На данном графике мы видим PR-кривую модели множественной классификации из 3 классов. Кроме отдельных значений precision и recall в каждой точке рассчитываются и усредненные значения. Так формируется кривая средних значений. Интегральная метрика качества модели классификации считается как площадь под кривой средних значений. Алгоритм построения ROC-кривой полностью аналогичен.
Выводы:
- ROC-кривая показывает качество бинарной классификации при разных значениях порога.
- В отличие от PR-кривой, ROC-кривая монотонна.
- Площадь под графиком ROC-кривой, ROC_AUC — одна из основных метрик качества классификационных моделей.
- ROC_AUC можно использовать для сравнения качества разных моделей, обученных на разных данных.
- ROC чаще используют для сбалансированных и множественных задач, PR — для несбалансированных.
- Кривые для множественной классификации строятся отдельно для каждого класса.
- Метрика AUC считается по кривой средних значений.
Топ k классов
Все метрики, которые мы обсуждали выше оперируют точным совпадением предсказанного класса с истинным. В некоторых особых задачах может быть полезно немного смягчить это условие. Как мы говорили, метрические методы классификации выдают больше информации — степень принадлежности объекта выборки каждому классу. Обычно, мы выбираем из них тот класс, который имеет наибольшую принадлежность. Но можно выбрать не один класс, а несколько. Таким образом можно рассматривать не единственный вариант класса для конкретного объекта, а 3, 5, 10 и так далее.
Другими словами можно говорить о том, находится ли истинный класс объекта среди 3, 5 или 10 классов, которые выбрала для него модель. Количество классов, которые мы рассматриваем, можно брать любым. В данной метрике оно обозначается k. Таким образом, можно построить метрику, которая оценивает долю объектов выборки, для которых истинный класс находится среди k лучших предсказаний модели:
[tka(y, hat{f}) = frac{1}{n} sum_{i=0}^{n-1}
sum_{j=1}^{k} 1(hat{f_{ij}} = y_i)]
где $hat{f_{ij}}$ — это j-й в порядке убывания уверенности модели класс i-го объекта.
Рассмотрим такой пример. Пусть у нас есть задача классификации из 3 классов. Мы оцениваем 4 объекта, которые имеют на самом деле такие классы:
$y = lbrace 0, 1, 2, 2 rbrace$.
1
2
3
>>> import numpy as np
>>> from sklearn.metrics import top_k_accuracy_score
>>> y_true = np.array([0, 1, 2, 2])
Модель предсказывает следующие вероятности для каждого объекта:
1
2
3
4
>>> y_score = np.array([[0.5, 0.2, 0.2],
... [0.4, 0.3, 0.2],
... [0.2, 0.4, 0.3],
... [0.7, 0.2, 0.1]])
То есть для первого объекта она выбирает первый класс, но немного предполагает и второй. А вот, например, последний, четвертый объект она уверенно относит тоже к первому классу. Давайте посчитаем метрику топ-2 для этой модели. Для этого для каждого объекта рассмотрим, какие 2 класса модель называет наиболее вероятными. Для первого — это 0 и 1, для второго — также 0 и 1, причем модель отдает предпочтение 0 классу, хотя на самом деле объект относится к 1 классу. Для третьего — уже 2 и 2 класс, причем класс 1 кажется модели более вероятным, для четвертого — так же наиболее вероятными модели кажутся 0 и 1 класс.
Если бы мы говорили об обычной accuracy, то для такой модели она была бы равна 0,25. Ведь только для первого объекта модель дала правильное предсказание наиболее вероятного класса. Но по метрике топ-2, для целых трех объектов истинный класс находится среди двух наиболее вероятных. Модель полностью ошибается только в последнем случае. Так что эта метрика равна 0,75. Это же подтверждают и автоматические расчеты:
1
2
>>> top_k_accuracy_score(y_true, y_score, k=2)
0.75
Как мы говорили, количество классов k можно взять любым. В частном случае $k=1$ эта метрика превращается в классическую accuracy. Чем больше возьмем k, тем выше будет значение данной метрики, но слабее условие. Так что брать очень большие k нет никакого смысла. В другом крайнем случае, когда k равно количеству классов, метрика будет равна 1 для любой модели.
Эта метрика имеет не очень много практического смысла. Ведь при прикладном применении моделей машинного обучения важен все-таки итоговый результат классификации. И если модель ошиблась, то модель ошиблась. Но эта метрика может пролить свет на внутреннее устройство модели, показать, насколько сильно она ошибается. Ведь одно дело, если модель иногда называет правильный ответ может и не наиболее вероятным, но в топ, скажем, 3. Совсем другое дело, если модель не находит правильный ответ и среди топ-10. Так что эта метрика может использоваться для диагностики моделей классификации и для поиска путей их совершенствования. Еще она бывает полезна, если две модели имеют равные значения метрики accuracy, но нужно понять, какая их них адекватнее имеющимся данным.
Такие проблемы часто возникают в задачах, где классов очень много. Например, в распознавании объектов на изображениях количество объектов может быть несколько тысяч. А в задачах обработки текста количество классов может определяться количеством слов в языке — сотни тысяч и миллионы (если учитывать разные формы слов). Естественно, что эффективность моделей классификации в таких задачах, измеренная обычными способами будет очень низкой. А данная метрика позволяет эффективно сравнивать и оценивать такие модели.
Выводы:
- Эта метрика — обобщение точности для случая, когда модель выдает вероятности отнесения к каждому классу.
- Вычисляется как доля объектов, для которых правильный класс попадает в список k лучших предсказанных классов.
- Чем больше k, тем выше метрика, но бесполезнее результат.
- Эта метрика часто применяется в задачах с большим количеством классов.
- Применимость этой метрики сильно зависит от характера задачи.
Проблема пере- и недообучения
Проблема Bias/Variance
При решении задачи методами машинного обучения всегда встает задача выбора вида модели. Как мы обсуждали в предыдущих главах, существует большое количество классов модели — достаточно вспомнить линейные модели, метод опорных векторов, перцептрон и другие. Каждая их этих моделей, будучи обученной на одном и том же наборе данных может давать разные результаты. Важно понимать, что мы не говорим о степени подстройки модели к данным. Даже если обучение прошло до конца, найдены оптимальные значения параметров, все равно модели могут и, скорее всего, будут различаться.
Причем многие классы моделей представляют собой не одно, а целое множество семейств функций. Например, та же логарифмическая регрессия — это не одна функция, а бесконечное количество — квадратичные, кубические, четвертой степени и так далее. Множество функций или моделей, имеющих единую форму, но различающуюся значениями параметров составляет так называемое параметрическое семейство функций. Так, все возможные линейные функции — это одно параметрическое семейство, все возможные квадратические — другое, а, например, множество всех возможных однослойных перцептронов с 5 нейронами во входном, 3 нейронами в скрытом и одном нейроне в выходном слое — третье семейство.
Таким образом можно говорить, что перед аналитиком стоит задача выбора параметрического семейства модели, которую он будет обучать на имеющихся данных. Причем разные семейства дадут модели разного уровня качества после обучения. К сожалению, очень сложно заранее предугадать, какое семейство моделей после завершения обучения даст наилучшее качество предсказания по данной выборке.
Что является главным фактором выбора этого семейства? Как показывает практика, самое существенное влияние на эффективность оказывает уровень сложности модели. Любое параметрическое семейство моделей имеет определенное количество степеней свободы, которое определяет то, насколько сложное и изменчивое поведение может демонстрировать получившаяся функция.
Сложность модели можно определять разными способами, но в контексте нашего рассуждения сложность однозначно ассоциируется с количеством параметров в модели. Чем больше параметров, тем больше у модели степеней свободы, возможности изменять свое поведение при разных значениях входных признаков. Конечно, это не означает полной эквивалентности разных типов моделей с одинаковым количеством параметров. Например, никто не говорит, что модель, скажем, регрессии по методу опорных векторов эквивалентна модели нейронной сети с тем же самым количеством весов. Главное, что модели со сходным уровнем сложности демонстрируют сходное поведение по отношению к конкретному набору данных.
Влияние уровня сложности на поведение модели относительно данных наиболее наглядно можно проследить на примере модели полиномиальной модели. Степень полинома — это очень показательная характеристика уровня сложности модели. Давайте рассмотрим три модели регрессии — линейную (которую можно рассматривать как полином первой степени), полином второй и восьмой степени. Мы обучили эти модели на одном и том же датасете и вот что получилось:

Следует отдельно заметить, что в каждом из представленных случаев модель обучалась до конца, то есть до схождения метода численной оптимизации параметров. То есть для каждой модели на графике представлены оптимальные значения параметров. Гладя на эти три графика и то, как эти линии ложатся в имеющиеся точки, можно заметить некоторое противоречие. Естественно предположить, что модель, изображенная на втором графике показывает наилучшее описание точек данных. Но по любой метрике качества третья модель будет показывать более высокий результат.
Человек, глядя на график третьей модели, сразу сделает вывод, что она “слишком” хорошо подстроилась под имеющиеся данные. Сравните это поведение с первым графиком, который демонстрирует самую низкую эффективность на имеющихся данных. Можно проследить, как именно сложность модели влияет на ее применимость. Если модель слишком простая, то она может не выявить имеющиеся сложные зависимости между признаками и целевой переменной. Говорят, что у простых моделей низкая вариативность (variance). Слишком же сложная модель имеет слишком высокую вариативность, что тоже не очень хорошо.
Те же самые рассуждения можно применить и к моделям классификации. Можно взглянуть на форму границы принятия решения для трех моделей разного уровня сложности, обученных на одних и тех же данных:

В данном случае мы видим ту же картину — слишком простая модель не может распознать сложную форму зависимости между факторами и целевой переменной. Такая ситуация называется недообучение. Обратите внимание, что недообучение не говорит о том, что модель не обучилась не до конца. Просто недостаток сложности, вариативности модели не дает ни одной возможной функции их этого параметрического семейства хорошо описывать данные.
Слишком сложные модели избыточно подстраиваются под малейшие выбросы в данных. Это увеличивает значение метрик эффективности, но снижает пригодность модели на практике, так как очевидно, что модель будет делать большие ошибки на новых данных из той же выборки. Такая ситуация называется переобучением. Переобучение — это очень коварная проблема моделей машинного обучения, ведь на “бумаге” все метрики показывают отличный результат.
Конечно, в общем случае не получится так наглядно увидеть то, как модель подстраивается под данные. Ведь в случае, когда данные имеют большую размерность, строить графики в проекции не даст представления об общей картине. Поэтому ситуацию пере- и недообучения довольно сложно обнаружить. Для этого нужно проводить отдельную диагностику.
Это происходит потому, что в практически любой выборке данных конкретное положение точек, их совместное распределение определяется как существенной зависимостью между признаками и целевой переменной, так и случайными отклонениями. Эти случайные отклонения, выбросы, аномалии не позволяют сделать однозначный вывод, что модель, которая лучше описывает имеющиеся данные, является лучшей в глобальном смысле.
Выводы:
- Прежде чем обучать модель, нужно выбрать ее вид (параметрическое семейство функций).
- Разные модели при своих оптимальных параметрах будут давать разный результат.
- Чем сложнее и вариативнее модель, тем больше у нее параметров.
- Простые модели быстрые, но им недостает вариативности, изменчивости, у них высокое смещение (bias).
- Сложные модели могут описывать больше зависимостей, но вычислительно более трудоемкие и имеют большую дисперсию (variance).
- Слишком вариативные (сложные) модели алгоритм может подстраиваться под случайный шум в данных — переобучение.
- Слишком смещенные (простые) модели алгоритм может пропустить связь признака и целевой переменной — недообучение.
- Не всегда модель, которая лучше подстраивается под данные (имеет более высокие метрики эффективности) лучше.
Обобщающая способность модели, тестовый набор
Как было показано выше, не всякая модель, которая показывает высокую эффективность на тех данных, на которых она обучалась, полезна на практике. Нужно всегда помнить, что модели машинного обучения строят не для того, чтобы точно описывать объекты из обучающего набора. На то он и обучающий набор, что мы уже знаем правильные ответы. Цель моделирования — создать модель, которая на примере этих данных формализует некоторые внутренние зависимости в данных для того, чтобы адекватно описывать новые объекты, которые модель не учитывала при обучении.
Полезность модели машинного обучения определяется именно способность описывать новые данные. Это называется обобщающей способностью модели. И как мы показали в предыдущей главе, эффективность модели на тех данных, на которых она обучается, не дает адекватного понимания этой самой обобщающей способности модели. Вместе с тем, обобщающая способность — это главный показатель качества модели машинного обучения и у нас должен быть способ ее измерять.
Конечно, мы не можем измерить эффективность модели на тех данных, которых у нас нет. Поэтому для того, чтобы иметь адекватное представление об уровне качества модели применяется следующий трюк: до начала обучения весь имеющийся датасет разбивают на две части. Первая часть носит название обучающая выборка (training set) и используется для подбора оптимальных параметров модели, то есть для ее обучения. Вторая часть — тестовый набор (test set) — используется только для оценки эффективности модели.
Такая эффективность, измеренная на “новых” данных — объектах, которые модель не видела при своем обучении — дает более объективную оценку обобщающей силы модели, то есть эффективности, которую модель будет показывать на неизвестных данных. В машинном обучении часто действует такое правило — никогда не оценивать эффективность модели на тех данных, на которых она обучалась. Не то, чтобы этого нельзя делать категорически (и в следующих главах мы это часто будем применять), просто нужно осознавать, что эффективность модели на обучающей выборки всегда будет завышенной, ведь модель подстроилась именно к этим данным, включая все их случайные колебания.
Надо помнить, что все рассуждения и выводы в этой и последующих главах носят чисто вероятностный характер. Так что в конкретном случае, тестовая эффективность вполне может оказаться даже выше, чем эффективность на обучающей выборке. Когда мы говорим о наборах данных и случайных процессах, все возможно. Но смысл в том, что распределение оценки эффективности модели, измеренное на обучающих данных имеет значимо более высокое математическое ожидание, чем “истинная” эффективность этой модели.
Для практического применения этого приема надо ответить на два вопроса: как делить выборку и сколько данных оставлять на тестовый датасет. Что касается способа деления, здесь чуть проще — практически всегда делят случайным образом. Случайное разбиение выгодно тем, что у каждого объекта датасета равная вероятность оказаться в обучающей или в тестовой выборке. Причем, эта вероятность независима для всех объектов выборки. Это делает все случайные ошибки выборки нормально распределенными, то есть их математическое ожидание равно нулю. Об этом мы еще поговорим в следующей главе.
Но этот способ не работает в случае со специальными наборами данных. Например с временными рядами. Ведь при разбиении выборки важно, чтобы сами объекты в тестовой выборке были независимы от объектов обучающей. В случае, если мы анализируем какое-то неупорядоченное множество объектов, это почти всегда выполняется. Но для временных рядов это не так. Объекты более позднего времени могут зависеть от предыдущих объектов. Так цена актива за текущий период однозначно зависит от цены актива за предыдущий. Поэтому нельзя допустить, чтобы в обучающей выборке оказались объекты более ранние, чем в обучающей. Поэтому такие временные ряды делят строго хронологически — в тестовую выборку попадает определенное количество последних по времени объектов. Но анализ временных рядов сам по себе довольно специфичен как статистическая дисциплина, и как раздел машинного обучения.

Что касается пропорции деления, то, опять же, как правило, выборку разделяют в соотношении 80/20. То есть если в исходном датасете, например, 1000 объектов, то случайно выбранные 800 из них образуют обучающую выборку, а оставшиеся 200 — тестовую. Но это соотношение “по умолчанию” в общем-то ничем не обосновано. Его можно изменять в любую сторону исходя из обстоятельств. Но для этого надо понимать, как вообще формируется эта пропорция и что на нее влияет.
Что будет, если на тестовую выборку оставить слишком много данных, скажем, 50% всего датасета? Очевидно, у нас останется мало данных для обучения. То есть модель будет обучена на всего лишь небольшой части объектов, которых может не хватить для того, чтобы модель “распознала” зависимости в данных. Вообще, чем больше данных для обучения, тем в целом лучше, так как на маленьком объеме большую роль играют те самые случайные колебания. Поэтому модель может переобучаться. И чем меньше данных, тем переобученнее и “случайнее” будет получившаяся модель. И это не проблема модели, это именно проблема нехватки данных. А чем больше точек данных, тем больше все эти случайные колебания будут усредняться и это сильно повысит качество обученной модели.
А что будет, если наоборот, слишком мало данных оставить на тестовую выборку? Скажем, всего 1% от имеющихся данных. Мы же сказали, что чем больше данных для обучения, тем лучше. Значит, но обучающую выборку надо оставить как можно большую часть датасета? Не совсем так. Да, обучение модели пройдет более полно. Но вот оценка ее эффективности будет не такой надежной. Ведь такие же случайные колебания будут присутствовать и в тестовой выборке. И если мы оценим эффективность модели на слишком маленьком количестве точек, случайные колебания этой оценки будут слишком большими. Другими словами мы получим оценку, в которой будет сильно не уверены. Истинная оценка эффективности может быть как сильно больше, так и сильно меньше получившегося уровня. То есть даже если модель обучается хорошо, мы этого никогда не узнаем с точностью.
То есть пропорция деления выборки на обучающуюся и тестовую является следствием компромисса между полнотой обучения и надежность оценки эффективности. Соотношение 80/20 является хорошим балансом — не сильно много, но и не сильно мало. Но это оптимально для среднего размера датасетов. Если у вас очень мало данных, то его можно немного увеличить в пользу тестовой выборки. Если же данных слишком много — то в пользу обучающей. Кроме того, при использовании кросс-валидации размер тестовой выборки тоже можно уменьшить.Но на практике очень редько используются соотношения больше, чем 70/30 или меньше чем 90/10 — такое значения уже считаются экстремальными.
Выводы:
- Цель разработки моделей машинного обучения — не описывать обучающий набор, а на его примере описывать другие объекты реального мира.
- Главное качество модели — описывать объекты, которых она не видела при обучении — обобщающая способность.
- Для того, чтобы оценить обобщающую способность модели нужно вычислить метрики эффективности на новых данных.
- Для этого исходный датасет разбивают на обучающую и тестовую выборки. Делить можно в любой пропорции, обычно 80-20.
- Чаще всего выборку делят случайным образом, но временные ряды — только в хронологической последовательности.
- Обучающая выборки используется для подбора параметров модели (обучения), а тестовая — для оценки ее эффективности.
- Никогда не оценивайте эффективность модели на тех же данных, на которых она училась — оценка получится слишком оптимистичная.
Кросс-валидация
Как мы говорили ранее, маленькая тестовая выборка проблемна тем, что большое влияние на результат оценки эффективности модели имеют случайные отклонения. Это становится меньше заметно при росте объема выборки, но полностью проблема не исчезает. Эта проблема состоит в том, что каждый раз разбивая датасет на две выборки, мы вносим случайные ошибки выборки. Эта случайная ошибка обоснована тем, что две получившиеся подвыборки наверняка будут демонстрировать немного разное распределение. Даже если взять простой пример. Возьмем группу людей и разделим ее случайным образом на две половины. В каждой половине посчитаем какую-нибудь статистику, например, средний рост. Будут ли в двух группах выборочные средние точно совпадать? Наверняка нет. Обосновано ли чем-то существенным такое различие? Тоже нет, это случайные отклонения, которые возникают при выборке объектов из какого-то множества.
Поэтому разбиение выборки на тестовую и обучающую вносит такие случайные колебания, из-за которых мы не можем быть полностью уверены в получившейся оценке эффективности модели. Допустим, мы получили тестовую эффективность 95% (непример, измеренную по метрике accuracy, но вообще это не важно). Можем ли мы быть уверены, что это абсолютно точный уровень эффективности? Нет, ведь как любая выборочная оценка, то есть статистика, рассчитанная на определенной выборке метрика эффективности представляет собой случайную величину с некоторым распределением. А у этого распределения есть математическое ожидание и дисперсия. Как мы говорили в предыдущей главе, случайное разделение выборки на тестовую и обучающую приводит к тому, что распределение этой величины имеет математическое ожидание, совпадающее с истинным уровнем эффективности модели. Но это именно математическое ожидание. И у этой случайной величины есть какая-то ненулевая дисперсия. Это значит, что при каждом измерении, выборочная оценка может отклоняться от матожидания, то есть быть произвольно больше или меньше.
Есть ли способ уменьшить эту дисперсию, то есть неопределенность при измерении эффективности модели? Да, очень простой. Нужно всего лишь повторить измерение несколько раз, а затем усреднить полученные значения. Так как математическое ожидание случайных отклонений всегда предполагается равным нулю, чем больше независимых оценок эффективности мы получим, тем ближе среднее этих оценок будет к математическом ожиданию распределения, то есть к истинному значению эффективности.
Проблема в том, что эти измерения должны быть независимы, то есть производиться на разных данных. Но кратное увеличение тестовой выборки имеет существенные недостатки — соответствующее уменьшение обучающей выборки. Поэтому так никогда не делают. Гораздо лучше повторить случайное разбиение датасета на обучающую и тестовую выборки еще раз и измерить метрику эффективности на другой тестовой выборки из того же изначального датасета.
К сожалению, это означает, что и обучающая выборка будет другая. То есть нам необходимо будет повторить обучение. Но зато после обучения мы получим новую, независимую оценку эффективности модели. Если мы повторим этот процесс несколько раз, мы сможем усреднить эти значения и получить гораздо более точную оценку эффективности модели.
Имейте в виду, что все, что мы говорим в этой части применимо к любой метрике эффективности или метрике ошибки модели. Чаще всего, на практике измеряют метрики accuracy для моделей классификации и $R^2$ для регрессии. Но вы можете использовать эти методики для оценки любых метрик качества моделей машинного обучения. Напомним, что они должны выбираться исходя из задачи.
Конечно, можно реализовать это случайное разбиение руками и повторить процедуру оценивания несколько раз, но на практике используют готовую схему, которая называется кросс-валидация или перекрестная проверка. Она заключается в том, что датасет заранее делят на несколько равных частей случайным образом. Затем каждая из этих частей выступает как тестовый набор, а остальные вместе взятые — как обучающий:

Источник: Towards Data Science.
На схеме части датасета изображены для наглядности непрерывными блоками, но на самом деле это именно случайные разбиения. Так что они буду в датасете “вперемешку”. Количество блоков, на которые делится выборка задает количество проходов или оценок. Это количество называется k. Обычно его берут равным 5 или трем. Это называется, 5-fold cross-validation. То есть на первом проходе блоки 1,2,3 и 4 в совокупность составляют обучающую выборку. Модель обучается на них, а затем ее эффективность измеряется на блоке 5. Во втором проходе та же модель заново обучается на данных их блоков 1,2,3 и 5, и ее эффективность измеряется на блоке 4. И таким образом мы получаем 5 независимых оценок эффективности модели. Они могут различаться из-за тех самых случайных оценок выборки. Но если посчитать их среднее, оно будет значительно ближе к истинному значению эффективности. Поэтому что статистика.
Количество проходов k еще определяет то, сколько раз будет повторяться обучение модели. Чем больше выбрать k, тем более надежными будут оценки, но вся процедура займет больше машинного времени. Это особенно актуально для моделей, которые сами по себе обучаются долго — например, глубокие нейронные сети. Надо помнить, что использование кросс-валидации сильно замедляет процесс обучения. Если же выбрать k слишком маленьким, то не будет главного эффекта кросс-валидации — усреднения индивидуальных оценок эффективности. Кроме того, чем больше k, тем меньшая часть выборки будет отводиться на тестовый набор. Поэтому k не стоит брать больше, скажем, 10, даже если у вас достаточно вычислительных мощностей.
Кросс-валидация никак не влияет на эффективность модели. Многие думают, что валидированные модели получаются более эффективными. Это не так, просто использование перекрестной проверки позволяет более точно и надежно измерить уже имеющуюся эффективность данной модели. И уж тем более кросс-валидация не может ускорить процесс обучения, совсем наоборот. Но несмотря на это, использование кросс-валидации с k равным 5 или, в крайнем случае, 3, совершенно обязательно в любом серьезном проекте по машинному обучению, ведь оценки, полученные без использования этой методики совершенно ненадежны.
В библиотеке sklearn, естественно, кросс-валидация реализована в виде готовых функций. Поэтому ее применение очень просто. В примере ниже используется кросс-валидация с количеством проходов по умолчанию для получения робастных оценок заранее выбранных метрик (precision и recall):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
>>> from sklearn.model_selection import cross_validate
>>> from sklearn.metrics import recall_score
>>> scoring = ['precision_macro','recall_macro']
>>> clf =
svm.SVC(kernel='linear', C=1, random_state=0)
>>> scores =
cross_validate(clf, X, y, scoring=scoring)
>>> sorted(scores.keys())
['fit_time', 'score_time',
'test_precision_macro', 'test_recall_macro']
>>> scores['test_recall_macro']
array([0.96..., 1. ..., 0.96..., 0.96..., 1. ])
Такой код просто оценивает значение метрик. Но обратите внимание, что он возвращает не просто одно значение метрики, но целый вектор. Это именно те индивидуальные оценки. Из них очень легко получить средние и выборочную дисперсию. Эта выборочная дисперсия как раз и показывает степень уверенности в данной оценке — чем она ниже, тем уверенность больше, как доверенный интервал в статистике. Кроме такого явного использования кросс-валидации для оценки метрик, она зачастую встроена в большое количество функций, которые используют ее неявно. О некоторых таких функциях, осуществляющих оптимизацию гиперпараметров модели, пойдет речь чуть позже.
Выводы:
- Разбиение выборки на обучающую и тестовую может внести случайные ошибки.
- Нужно повторить разбиение несколько раз, посчитать метрики и усреднить.
- Кросс-валидация разбивает выборку на $k$ блоков, каждый из которых используется по очереди как тестовый.
- Сколько задать $k$, столько и будет проходов. Обычно берут 3 или 5.
- Чем больше $k$ тем надежнее оценка, но дольше ее получение, так как модель каждый раз заново обучается.
- Использование кросс-валидации обязательно для получения робастных оценок.
- В библиотеке sklearn кросс-валидация (CV) встроена во многие функции.
Кривые обучения
Как мы говорили раньше, не следует ориентироваться на эффективность модели, измеренную на обучающей выборке, ведь она получается слишком оптимистичной. Но эта обучающая эффективность все равно может дать интересную информацию о работе модели. А именно с ее помощью можно оценить, переобучается модель или недообучается. В этой главе мы расскажем об одном из самых наглядных способов диагностики моделей машинного обучения — кривых обучения.
Построение кривых обучения может быть проведено после разделения датасета на обучающую и тестовую выборки. Происходит это следующим образом. Тестовый набор фиксируется и каждый раз используется один и тот же. Из обучающего набора же сначала берут малую часть, скажем 10% от общего количества точек в нем. Обучают модель на этой малой части, а затем измеряют ее эффективность на этой части и на постоянной тестовой выборке. Первая оценка называется обучающая эффективность (training score), а вторая — тестовая эффективность (test score). Затем повторяют процесс с чуть большей частью обучающей выборки, например, 20%, затем еще с большей и так, пока мы не дойдем до полной обучающей выборки.
На каждом этапе мы измеряем обучающую эффективность (измеренную именно на той части данных, на которых модель училась, не на полной обучающей выборке) и тестовую эффективность. Таким образом мы получаем зависимость эффективности модели от размера обучающей выборки. Эти данные можно построить на графике. Это график и называется кривой обучения (learning curve). Такой график может выглядеть, например, так:

В данном случае, на графике мы видим всего пять точек на каждой кривой. Верхняя кривая показывает обучающую эффективность, нижняя — тестовую. Значит, мы использовали всего пять делений обучающей выборки на подвыборки разного размера. Это размер как раз и отложен на горизонтальной оси. Сколько таких разбиений брать? Если взять слишком мало, то не будет понятна форма графика, а именно она нам важна для диагностики. Если же взять слишком много — то построение кривой обучения займет много времени, так как каждая точка на графике — это заново обученная модель.
Давайте объясним форму этого графика. Слева, когда обучающая выборка мала, обучающая эффективность довольно высока. Это вполне понятно, ведь чем меньше данных, тем проще модели к ним подстроиться. Помните, что через любые две точки можно провести линию (то есть линейную регрессию)? Это, конечно, крайний случай, но в общем, чем меньше обучающая выборка, тем большую эффективность одной и той же модели (параметрического семейства функций) можно на ней ожидать. А вот тестовая эффективность довольно маленькая. Это тоже понятно. Ведь на маленькой выборке модель не смогла обнаружить зависимости в данных так, чтобы эффективно предсказывать значение целевой переменной в новых данных. То есть она подстроилась под конкретные точки без какой-либо обобщающей способности.
Сперва отметим, что обычно кривые обучения демонстрируют некоторые общие тенденции. Например, при малых объемах обучающей выборки, обучающая эффективность модели может быть очень большой. Ведь чем меньше данных, тем проще подобрать параметры любой, пусть даже простой модели, так, чтобы эта модель ошибалась меньше. В самом предельном случае, вспомните, что через любые две точки можно провести прямую. Это значит, что линейная регрессия, обученная на двух точках, всегда будет давать нулевую ошибку или полную, 100%-ю эффективность. То же можно сказать и про квадратичную функцию, обученную на трех точках. Но и в целом, чем меньше данных, тем меньше можно ожидать суммарную ошибку любого рассматриваемого класса моделей на этих данных.
Тестовая же эффективность модели, обученной на малом объеме выборки, скорее всего будет очень невысокой. Это тоже естественно. Ведь модель видела всего малую часть примеров и не может подстроиться под какие-то глобальные зависимости в данных. Поэтому в левой части кривых обучения почти всегда будет большой зазор.
При повышении объема обучающей выборки обучающая же эффективность будет падать. Это связано в тем, что чем больше данных, тем больше пространства для ошибки для конкретной модели. Поэтому чем больше точек описывает модель, тем хуже она это делает в среднем. Это неизбежно и не страшно. Важно то, что тестовая эффективность наоборот, растет. Это происходит потому, что чем больше данных, тем больше вероятность того, что модель подстроится под существенные связи между признаками и целевой переменной, и таким образом, повысит обобщающую способность, свою предсказательную силу.
В итоге, кривая обучения показывает, как изменяется эффективность модели по сравнению к конкретному набору данных. В частности, именно с помощью кривых обучения можно предположить пере- и недообучение модели, что является главной целью диагностики моделей машинного обучения. Например, взглянув на график кривой обучения, приведенный выше, можно ответить на вопрос, хватает ли модели данных для обучения. Для этого можно спросить, улучшится ли тестовая эффективность модели, если добавить в датасет больше точек. Для этого можно мысленно продолжить кривую обучения вправо.
При построении кривых обучения обращайте внимание на деления вертикальной оси. Если вы строите графики с использованием библиотечных инструментов, то они автоматически масштабируются по осям. Имейте в виду, что одна и та же кривая обучения может выглядеть при разном масштабе совершенно по-разному. А навык сопоставления разных кривых очень важен при диагностике моделей. Лучше всего вручную задавать масштаб вертикальной оси и использовать один и тот же для всех графиков в одной задаче.
Обратите внимание, что на графике помимо самих кривых обучения присутствуют еще какие-то полосы. Что они значат? Дело в том, что при построении кривых обучения очень часто применяется кросс-валидация, о которой мы говорили в предыдущей главе. Ведь разбиение выборки на тестовую и обучающую вносит случайные ошибки. Поэтому для построения на кривых обучения более надежных оценок всех измеряемых оценок эффективности процесс повторяют несколько раз и усредняют полученные оценки. Каждая точка на графике — это не просто оценка эффективности, это среднее из всех кросс-валидированных оценок. Именно поэтому, кстати, в легенде нижняя линяя называется не test score, а cross-validation score. А ширина полосы вокруг точки определяется величиной дисперсии этих оценок. Чем шире полоса, тем больше разброс оценки на разных проходах кросс-валидации и тем меньше мы уверены в значении этой оценки. При построении кривых обучения эта неопределенность почти всегда выше при малых объемах обучающей выборки (слева на графике) и меньше — справа.
Выводы:
- Кривая обучения — это зависимость эффективности модели от размера обучающей выборки.
- Для построения кривых обучения модель обучают много раз, каждый раз с другим размером обучающей выборки (от одного элемента до всех, что есть).
- При малых объемах обучающая эффективность будет очень большой, а тестовая — очень маленькой.
- При увеличении объема обучающей выборки они будут сходиться, но обычно тестовая эффективность всегда ниже обучающей.
- Кривые обучения позволяют увидеть, как быстро модель учится, хватает ли ей данных, а также обнаруживать пере- и недообучение.
- Кривые обучения часто используют кросс-валидацию.
Обнаружение пере- и недообучения
Как мы говорили, построение кривых обучения — это исключительно диагностическая процедура. Именно они позволяют нам предполагать, к чему более склонна модель, обученная на конкретном наборе данных — к переобучению или к недообучению. Это важно, так как подходы у повышению эффективности в этих двух случаях будут совершенно противоположными. Давайте предположим, как будут вести себя на кривых обучения переобученные и недообученные модели.
Что будет, если модель слишком проста для имеющихся данных? При увеличении количества объектов в обучающей выборке, эффективность, измеренная на ней же будет вначале заметно падать по причинам, описанным выше. Но постепенно она будет выходить на плато и больше не будет уменьшаться. Это связано с тем, что начиная с какого-то объема выборки в ней будут превалировать нелинейные зависимости, слишком сложные для данной модели. С ростом объема обучающей выборки неизбежно растет тестовая эффективность, но так как модель слишком проста и не может ухватить этих сложных зависимостей в данных, то ее тестовая эффективность не будет повышаться сильно. Причем при достаточном объеме обучающей выборки тестовая и обучающая эффективности будут достаточно близкими. Другими словами, простые модели одинаково работают как на старых, так и на новых данных, но одинаково плохо.
А что будет происходить со слишком сложной моделью для существующих данных? Ее показатели в левой части графика будут аналогичны — высокая обучающая и низкая тестовая эффективности. Причины все те же. Но вот с ростом объема обучающей выборки, разрыв между этими двумя показателями не будет сокращаться так сильно. Модель, обученная на полном датасете покажет высокую эффективность на обучающей выборке, но гораздо более низкую — на тестовой. Это же практически определение переобучения — низкая ошибка, но отсутствие обобщающей способности. Это происходит, как мы уже обсуждали, за счет того, что слишком сложная модель имеет достаточный запас вариативности, чтобы подстроиться под случайные отклонения в данных.
Таким образом, недообученные и переобученные модели демонстрируют совершенно разное поведение на кривых обучения. А значит, недообучение и переобучения можно выявить, проанализировав поведение модели на графике. Типичное переобучение характеризуется большим разрывом между тестовой и обучающей эффективность. Признак типичного недообучения — низкая эффективность как на тестовой, так и на обучающей выборке. Но на практике, конечно, диагностика моделей машинного обучения не такая простая.

На данном графике представлены абстрактные картины, наиболее характерные для недообучения, переобучения, и ситуации, когда сложность модели оптимальна — мы назовем ее качественное обучение. Именно анализируя схожесть кривой обучения исследуемой модели с этими “идеальными” случаями, можно сделать обоснованный вывод о наличии недо- или переобучения модели.
Как вы могли заметить, мы нигде не говорим о четких критериях. Недо- и переобученность моделей — это вообще относительные понятия. И кривые обучения измеряют их только косвенно. Поэтому диагностика не сводится к оценке какой-либо метрики или статистики. Нам нужно оценить общую форму графика кривых обучения, что не является точной наукой. Возникает множество вопросов. Например, мы говорили, что большой зазор между тестовой и обучающей эффективностью — это признак переобучения. Но какой зазор считать большим? Это вопрос интерпретации. Точно так же, что считать низким уровнем эффективности? 50%? Может, 75%? Вообще это очень зависит от самой задачи. В некоторых задачах 80% accuracy — это выдающийся результат, а в других — даже 99% считается недостаточной точностью.
Поэтому рассматривая один график кривой обучения очень сложно понять, особенно без опыта анализа моделей машинного обучения, на что мы смотрим — на слишком простую недообученную модель, или на слишком сложную — переобученную. Вообще, строго говоря, большой зазор между эффективностями модели указывает на присутствующую в модели вариативность (variance), а низкий,не 100%-й уровень обучающей эффективности — на наличие в модели смещения (bias). А любые модели в той или иной степени обладают этими характеристиками. Вопрос в их соотношении друг к другу и к конкретному набору данных.
Чтобы облегчить задачу диагностики модели очень часто эффективность данной модели рассматривают не абстрактно, а сравнивают с аналогами. Практически всегда выбор моделей осуществляется от простого к сложному — сначала строят очень простые модели. Их тестовая эффективность может задать некоторых базовый уровень, планку, по сравнению к которой уже можно готовить об улучшении эффективности у данной, более сложной модели, насколько это улучшение существенно и так далее. Кроме того, строя кривые обучения нескольких моделей можно получить сравнительное представление о том, как эти модели соотносятся между собой, какие из них более недообученные, какие — наоборот.
Ситуация еще очень осложняется тем, что на практике вы никогда не получите таких красивых и однозначных кривых обучения, как в учебнике. Положение точек на кривых обучения зависит, в том числе и от тех самых случайных отклонений в данных, которые так портят нам жизнь. Поэтому в реальности графики могут произвольно искривляться, быть немонотонными. Тестовая эффективность вообще может быть выше обучающей. Что это начит для диагностики? Да в общем-то, ничего, это лишь свидетельствует об особом характере имеющихся данных. И, естественно, чем меньше данных, тем более явно проявляются эти случайности и тем менее показательными будут графики.
Достаточно сильно от этих случайных колебаний помогает применение кросс-валидации. Так как усреднение случайности — это и есть цель перекрестной проверки, она может быть полезна и для “сглаживания” кривых обучения. Еще надо помнить, что во многих библиотеках по умолчанию кривые обучения строятся на основе всего нескольких точек, то есть всего пяти-десяти вариантов размера обучающей выборки. Если такой график не дает достаточной информации, можно попробовать построить кривую по большему количеству точек. Но при этом и случайные колебания тоже могут проявиться сильнее.
Вообще, все факторы, которые улучшают “читаемость” кривых обучения, одновременно сильно замедляют их построение — кросс-валидация, использование большей выборки, построение большего количества точек. Помните, что это приводит к кратному увеличению количества циклов обучения модели.
Как мы говорили, поведение модели в целом не зависит от выбранной метрики, которую вы используете для построения кривых обучения. Поэтому зачастую используют не метрики эффективности, а метрики ошибок. Поэтому графики кривых обучения выглядят “перевернутыми” — тестовая ошибка больше, чем обучающая и так далее. Следует помнить, что все сказанное выше остается справедливым в этом случае, только следует помнить, где у модели высокая эффективность и малая ошибка.

На этом графике вы видите тоже идеальные случаи, но выраженные в терминах величины ошибки, а не эффективности. Можно проследить те же тенденции, но как бы “отраженные” по вертикальной оси.
Как мы говорили, реальные наборы данных, имеющие случайные колебания, ненадежные зависимости, случайные ошибки выборки могут существенно искажать кривые обучения. Рассмотри пример, приближенный к реальности. Возьмем датасет, содержащий рукописные цифры и обучим на нем классификатор по методу опорных векторов с гауссовым ядром. Для примера возьмем значение параметра “гамма”, который задает масштабирование функции расстояния в ядре, равным 0,008. Построив кривые обучения для этой модели мы получаем следующий график:

Данный график, несмотря на свою сложную форму достаточно легко интерпретируется. Мы видим, что обучающая эффективность равна 1 при любых объемах обучающей выборки. То есть модель разделяет классы полностью идеально. Но вот тестовая эффективность всегда остается гораздо ниже. И хотя она растет при увеличении объема обучающей выборки, все равно, даже при использовании полного набора данных, остается большой разрыв между тестовой и обучающей эффективностями модели. Налицо явное и типичное переобучение.
Теперь давайте уменьшим параметр “гамма” в четыре раза. В методе опорных векторов это может ограничить вариативность модели. Получаем следующий график кривых обучения:

Видно, что общее поведение модели значительно улучшилось. Обратите внимание на масштаб вертикальной оси. На первом графике мы говорили о разнице между тестовой и обучающей эффективностью в примерно 0,3. На этом же графике разница сократилась до примерно 0,025 — больше, чем в 10 раз. Это говорит о том, что модель очень сильно увеличила свою обобщающую способность. Давайте теперь уменьшим параметр еще в сто раз и посмотрим на кривую обучения:

Поведение модели явно не улучшилось. Хотя, итоговая эффективность тоже получается достаточно высокой (около 0,9), она все равно значительно меньше, чем в предыдущем случае. Другими словами, дальнейшее сокращение “гаммы” не пошло модели на пользу. Низкая тестовая эффективность и небольшая разница между тестовой и обучающей эффективностью — типичные признаки недообучения.
Обратите внимание, что интерпретация графика кривых обучения и, соответственно, диагностика модели, приобретает гораздо больше смысла к контексте сравнения нескольких моделей. Третья модель дает относительно неплохой результат с тестовой эффективностью в 0,9. Эту модель вполне можно признать валидной и качественно обученной, если бы мы не знали, что мы можем достичь точности в 0,975 (вторая модель).
Для сравнения рассмотрим результаты анализа еще одной модели на тех же самых данных — наивного байесовского классификатора с гауссовым распределением:

Хотя график сильно отличается от любого из трех предыдущих, самое главное, на что следует обратить внимание — низкое значение обучающей эффективности на полном наборе данных. Это показывает, что даже если мы продолжим добавлять данные в обучающую выборку, максимум, на который мы можем рассчитывать — это что тестовая эффективность приблизится к обучающей, которая все равно недостаточная (в данном примере меньше 0,9). Это свидетельствует о недообученности модели.
Как мы говорили, недообучение и переобучение — это условные понятия, которые называют распространенные ситуации при использовании моделей машинного обучения. Недообучение — это когда у модели низкая вариация и высокое смещение. Переобучение — это наоборот, когда низкое смещение и высокая вариация. На самом деле эти свойства в моделях присутствуют всегда. Более тщательный анализ может сделать вывод, что последняя модель имеет как высокую вариацию (что выражается в сильной разнице между эффективностями), так и высокое смещение (об этом говорит низкое значение обучающей эффективности).
Выводы:
- При недообучении тестовая и обучающая эффективности будут достаточно близкими, но недостаточными.
- При переобучении тестовая и обучающая эффективности будут сильно различаться — тестовая будет значительно ниже.
- Пере- и недообучение — это относительные понятия.
- Более простые модели склонны к недообучению, более сложные — к переобучению.
- Диагностика пере- и недообучения очень важна, так как для повышения эффективности предпринимаются противоположные меры.
- Для построения можно использовать функцию ошибки, метрику эффективности или метрику ошибки, важна только динамика этих показателей.
- Диагностика моделей машинного обучения — это не точная наука, здесь нужно принимать в расчет и задачу, и выбор признаков и многие другие факторы.
Методы повышения эффективности моделей
Регуляризация
Как мы говорили, диагностика моделей нужна для поиска путей повышения ее эффективности. И мы выяснили, что пере- и недообучение моделей напрямую связаны с уровнем сложности моделей. Можно рассмотреть гипотетический график, на котором показан уровень ошибок моделей на конкретном наборе данных в зависимости от уровня сложности этой модели. Пока мы не сталкивались с тем, как можно плавно менять уровень сложности модели в рамках одного параметрического класса. Но представим, что речь идет о полиномиальной модели, а по горизонтали отложена степень этого полинома.

Если модель слишком проста, то уровень тестовых и обучающих ошибок будет высок и достаточно близок друг к другу. Мы говорили об этом (правда другими словами, в терминах эффективности) в предыдущей главе. По мере увеличения сложности разрыв между этими уровнями ошибок будет в среднем увеличиваться. Это происходит за счет более глубокой подстройки модели именно к обучающей выборке. Причем уровень ошибок на обучающей выборке будет в среднем падать за счет повышения вариативности модели. Но уровень ошибок не может опуститься ниже нуля. Поэтому либо с какого-то момента он стабилизируется, либо будет асимптотически приближаться к 0. А это значит, что уровень тестовой ошибки неизбежно рано или поздно начнет повышаться с ростом сложности модели. Таким образом, у уровня тестовой ошибки есть некоторое оптимальное значение.
Другими словами, для любого конкретного датасета существует некоторый оптимальный уровень сложности модели, который дает наименьшую ошибку на тестовой выборке. Модели, имеющие более низкую сложность будут недообучаться, а более высокую — переобучаться. Поэтому существует задача нахождения этого оптимального уровня сложности. К сожалению, это не получится сделать методом обучения, или любой другой численной оптимизации, так как изменение уровня сложности модели требует запуска ее обучения заново. Мы не можем непрерывно менять уровень сложности, как какой-то дополнительный параметр модели.
Изучив несколько видов моделей обучения с учителем легко сделать вывод, что сложность модели — это некоторое “встроенное” свойство, которое определяется видом самой модели, то есть параметрическим классом функций, которые аппроксимируются этой моделью. Некоторые модели просто сложнее чем другие. Например, многослойный перцептрон гораздо сложнее линейной регрессии, а глубокое дерево решений сложнее более мелкого.
Выше мы определяли уровень сложности модели через количество ее параметров. Но стоит сказать, что численное значение этих параметров тоже имеет значение. Рассмотрим для примера две модели — линейную ($y = b_0 + b_1 x$) и квадратичную ($y = b_0 + b_1 x + b_2 x^2$). Очевидно, вторая модель сложнее, так как у нее больше параметров. Квадратичная функция имеет больше степеней свободы и демонстрирует нелинейное поведение — рост функции на разных участках может сильно отличаться.
Но что, если параметр $b_2$ у квадратичной модели будет очень маленьким, скажем, $b_2 = 0.0001$. Если у нас есть функция, например, $y = -8 + 15 x + 0.0001 x^2$, то взглянув на ее график мы не отличим ее от линейной. Да, формально она будет относиться к классу квадратичных функций, но на практике она будет почти прямой линией. Рост функции на разных участках будет отличаться, но очень незначительно. Тем более, что нас интересует поведение функции не на всей числовой прямой а в окрестностях имеющихся точек данных. Если на этом участке функция ведет себя как линейная, то для прикладной задачи она и эквивалентна линейной.
То есть чем ближе параметр $b_2$ к нулю, тем эффективно ближе квадратичная модель к линейной. Так можно сказать про любой параметр любой модели обучения с учителем. Только в более сложных моделях связь между конкретным параметром и уровнем сложности не так очевидна, так в случае с полиномиальными функциями. Но в любом случае, чем меньше в модели параметров, существенно отклоняющихся от нуля, тем она проще. Причем, это обычно не распространяется на свободный коэффициент $b_0$, у него особая роль — его значение смещает все предсказания модели (поэтому он часто называется параметром смещения). Его отличие от нуля несущественно. На этом эффекте основан один очень полезный и распространенный на практике математический прием, который позволяет гибко и очень удобно управлять сложностью параметрических моделей машинного обучения. Этот прием называется регуляризация.
Допустим, у нас есть набор данных и мы не знаем, модель какого вида подойдет к нему лучше — линейная или квадратичная. При прочих равных, квадратичная модель всегда даст меньшую величину ошибки и поэтому будет предпочтительнее. Но мы уже видели, что малая ошибка — не всегда показатель качества модели. Если обычная функция ошибки, основанная на суммарном отклонении значений данных от модели (которую мы рассматривали до этого), не дает адекватной оценки качества модели, может стоит ее как-нибудь изменить?
Функция ошибки — это по сути система штрафов. Каждый раз, когда модель ошибается, к значению ошибки прибавляется величина, пропорциональная отклонению. Это — штраф за ошибку модели. Но может быть, мы можем штрафовать что-нибудь еще? Например, уровень сложности модели. Представьте, что мы добавляем к ошибке некоторые штрафы за высокие значения параметров модели. Тогда алгоритм обучения, который минимизирует именно функцию ошибки будет не так сильно отдавать сложным переобученным моделям. Небольшие ошибки модели могут быть скомпенсированы тем, что модель становится более простой.
Причем эти штрафы очень легко выражаются математически. Если штраф за ошибки модели — это некоторое математическое выражение, основанное на отклонениях предсказанных значений от эмпирических, то штрафы за сложность модели — это выражение, основанное на отклонениях параметров самой модели от нуля. Существует несколько конкретных реализаций регуляризации и о них мы поговорим чуть далее. Кстати, регуляризация обычно не затрагивает свободный коэффициент. Причины этого мы только что обсуждали — он не влияет на сложность модели.
В этом и состоит идея регуляризации — модификация функции ошибки таким образом, чтобы штрафовать сложные модели в пользу более простых. Да, достаточно странно складывать отклонения целевой переменной (которые могут быть выражены в натуральных единицах) и безразмерные параметры модели. Это может выглядеть, как сложение метров с красным. Регуляризация — это именно математический трюк. У нее нет физического значения, какой-то внятной интерпретации в терминах предметной области.Это лишь способ отдавать предпочтение моделям с низкими значениями параметров, ведь такие модели ведут себя как более простые и поэтому менее склонны к переобучению.
Можно заметить, что регуляризация — это способ искусственно понизить сложность модели. То есть при использовании регуляризации берут модель более сложную, которая в “чистом” виде будет явно переобучаться на имеющихся данных. Но за счет этих дополнительных штрафов, ее сложность принижают. Причем, самое удобное в регуляризации то, что она параметрическая. То есть соотношением “силы” штрафа за ошибки и штрафа за сложность легко управлять, введя множитель — так называемый параметр регуляризации. Чем он больше, тем сильнее штрафуются сложные модели, то есть даже большие ошибки модели могут быть скомпенсированы небольшим понижением сложности. Таким образом, возвращаясь к графику в начале главы, именно параметр регуляризации может быть отложен на нем по горизонтали.
Регуляризация настолько удобна и универсальна, что большинство библиотечных реализаций тех моделей, которые мы проходили раньше, уже реализуют встроенную регуляризацию. Причем это относится равно как к моделям классификации, так и к моделям регрессии, это прием не зависит от типа задачи обучения с учителем. За счет способности уменьшить сложность любой модели регуляризация является одним их основных способов борьбы с переобучением.
Обратите внимание, что мы в основном говорим именно о борьбе с переобучением. Борьба с недообучением в основном сводится к использованию более сложной модели. В настоящее время разработаны настолько сложные модели, что узким местом современного машинного обучения становятся вычислительные мощности и доступность данных.
Выводы:
- Регуляризация — это способ искусственно ограничить вариативность моделей.
- При использовании регуляризации можно применять более сложные модели и снижать склонность к переобучению.
- Регуляризация модифицирует функцию ошибки модели, добавляя в нее штрафы за повышение сложности.
- Основная идея регуляризации — отдавать предпочтение низким значениям параметров в модели.
- Регуляризация обычно не затрагивает свободный коэффициент $b_0$.
- Регуляризация обычно параметрическая, можно управлять ее степенью.
Ridge
Зачастую переобучение модели, которое является следствием большого количества параметров в модели, появляется потому, что в наборе данных присутствует много “лишних” атрибутов. Количество параметров любой модели обучения с учителем зависит от количества признаков в данных. Для борьбы с этим явлением используется регуляризация. Как мы говорили, регуляризация “штрафует” отклонения параметров модели (за исключением свободного) от нуля. Совершенно естественно формализовать это отклонение так же, как и в самой функции ошибки — как сумму квадратов этих значений. Такая модель называется гребневой регрессией (ridge regression). В ней функция ошибки принимает такой вид:
[J(vec{b}) = frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2 + lambda sum_{j=1}^{n} b_j^2]
Как мы можем видеть, что функция ошибки аналогична обычной модели регрессии, но имеет одно дополнительное слагаемое — регуляризационный член. Это сумма квадратов значений параметров модели (начиная с первого). Эта сумма умножается на специальный параметр — параметр регуляризации $lambda$. Он как раз отвечает за “силу” регуляризации модели. В передельном случае, когда $lambda = 0$, мы имеем обычную нерегуляризованную регрессию. Чем больше этот параметр, тем сравнительно больший вклад в ошибку дают отклонения параметров модели. То есть, чем больше этот параметр, тем более простые модели мы будем получать после обучения, при достижении минимума этой функции. Естественно, параметр регуляризации не может быть отрицательным, так как в таком случае мы наоборот, будем отдавать предпочтение более сложным моделям. А сложность, как и ошибка могут возрастать неограниченно.
Но если мы модифицируем функцию ошибки, то это влечет изменение и метода градиентного спуска. На самом деле он меняется незначительно. Вспомним, что градиентный спуск основан на вычислении частной производной функции ошибки по параметрам модели. Если взять свободный параметр, то вообще ничего не меняется, так как регуляризационный член от него не зависит:
[frac{partial}{partial b_0} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x_i) — y^{(i)}) cdot frac{partial}{partial b_0} h_b(x_i)]
Если же рассматривать другие параметры модели, то в выражение производной добавится всего одно небольшое слагаемое:
[frac{partial}{partial b_i} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x_i) — y^{(i)}) cdot frac{partial}{partial b_i} h_b(x_i) + 2 lambda b_i]
Это слагаемое $2 lambda b_i$ как раз и будет учитывать значения параметров при выполнении шагов градиентного спуска в регуляризованной модели регрессии. В остальном метод обучения никак не меняется. Если мы рассматриваем линейную модель, то получается почти знакомое нам по предыдущим главам выражение:
[frac{partial}{partial b_i} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x_i) — y^{(i)}) cdot x_i + 2 lambda b_i]
Как мы уже говорили, этот прием может быть применен как к задачам классификации, так и к задачам регрессии. Но применяя регуляризованные модели на практике стоит быть внимательнее. Дело в том, что в некоторых моделях (например, в методе опорных векторов) регуляризация задается чуть иначе:
[J(vec{b}) = С frac{1}{m} sum_{i=1}^{m} cost(h_b(x_i) , y^{(i)}) + sum_{j=1}^{n} b_j^2]
Где $C$ — это тоже параметр регуляризации. Обратили внимание, что этот множитель стоит перед другим слагаемым — самой функцией ошибки? Численно, это эквивалентно предыдущей формализации, если полагать, что $C = frac{1}{lambda}$. Но стоит помнить, что в такой форме чем больше $C$, тем меньше регуляризации присутствует в модели.
Гребневую регрессию еще называют регрессией по L2-норме (L2 означает норма Лагранжа второго порядка) или регуляризацией Тихонова. Простыми словами это означает, что мы считаем сумму квадратов параметров.Гребневая регрессия полезна тем, что она может помочь повысить эффективность модели, если в данных присутствует большое количество мультиколлинеарных факторов, то есть атрибутов, которые очень сильно зависят друг от друга. Вообще, мультиколлинеарность в статистике — это в принципе не очень хорошее явление. В машинном обучении она опасна тем, что оптимальные параметры модели становятся гораздо менее устойчивыми, а значит обучение будет не очень надежным. Ну и вдобавок, большое количество признаков, как мы уже говорили, увеличивает количество параметров и порядок сложности модели, что приводит к переобучению. На практике мультиколлинеарные признаки можно обнаруживать и удалять из датасета руками, но гребневая регрессия может это делать автоматически.
Рассмотрим работу гребневой регрессии на примере. Для лучшего понимания того, как регуляризация влияет на получаемую модель, мы возьмем одни и те же данные и построим одну и ту же модель классификации с L2 регуляризацией, но с разными значениями параметра регуляризации. В качестве базовой модели мы используем полином пятой степени. Для начала классификация без регуляризации ($lambda=0$):

Мы видим достаточно сложную границу принятия решения и высокую точность модели — на этих данных эта модель показывает 0,91 accuracy. Давайте возьмем $lambda=2$:

За счет использования регуляризации точность модели немного снизилась и составила 0,89. Граница принятия решения тоже стала более гладкой и простой.
Обратите внимание, что расположение границы принятия решения полностью изменилось по сравнению с первой моделью. Ведь параметр регуляризации — это не то же самое, что и обычный параметр модели, коэффициент в функции. Один и тот же алгоритм, обученный с разными значениями параметра регуляризации даст две совершенно разные модели, не имеющие ничего общего. Поэтому нельзя, например, плавно менять параметр регуляризации и смотреть, как изменится граница принятия решения. И физического смысла параметр регуляризации никакого не несет. Это лишь численная переменная в алгоритме обучения, которая влияет на то, какая модель из определенного параметрического класса будет считаться оптимальной для данной задаче. В дальнейшем такие “сложные” параметры мы будем называть гиперпараметрами.
Увеличим регуляризацию еще больше и получим такую модель:

Точность снизилась еще больше — до 0,85. Очевидно, что точность регуляризованных моделей будет меньше, так как функция ошибки может “променять” точность на упрощение модели. Но в метриках эффективности сложность модели не учитывается, поэтому они падают. Ну и граница принятия решения тоже становится все более плоской.
Рассмотрим влияние регуляризации на модель регрессии. Для этого также возьмем один и тот же набор данных и будем строить на нем разные модели. Также будем использовать полиномиальные признаки пятой степени. Но на этот раз обратим внимание и на сами коэффициенты модели. Для начала посмотрим на модель практически без регуляризации ($lambda=0.1$):

Эта модель имеет точность 0,714 (по метрике r-квадрат) и следующие коэффициенты — 0, -2.84, -4.49, 8.03, -2.92, 0.34. Как видно, все полиномиальные признаки имеют влияние на модель, коэффициенты при них отличаются от нуля существенн. Теперь добавим регуляризацию ($lambda=1$):

Точность модели немного упала — до 0,712. Теперь взглянем на коэффициенты: 0, -2.51, -0.97, 4.48, -1.76, 0.22. Заметно, что все они сильно уменьшились (в абсолютном выражении), особенно третий и четвертый. Это как раз и есть влияние регуляризации — она стремится держать коэффициенты как можно более близкими к нулю, даже за счет понижения точности. А параметр регуляризации — это своего рода “обменный курс” между коэффициентами и точностью. Давайте поднимем его еще сильнее (до $lambda=100$):

Точность модели понизилась более существенно — до 0,698. А вот ее коэффициенты: 0, 0.13, 0.37, 0.49, -0.04, 0.01. По мере увеличения регуляризации ни один из коэффициентов не удалялся от нуля. А некоторые вплотную к нему приблизились. При этом заметим, что ни один коэффициент не стал нулем — гребневая регрессия даже с запредельным уровнем регуляризации стремится оставить в модели все имеющиеся признаки.
Выводы:
- $lambda > 0$ — параметр регуляризации.
- Чем он больше, тем сильнее штрафуются сложные модели.
- Этот прием может применяться как к классификации, так и к регрессии.
- Ridge еще называют регуляризацией по L2-норме. Она же — гребневая регрессия.
- Такая регуляризация делает параметры более робастными к мультиколлинеарности признаков.
Lasso
У гребневой регрессии есть один недостаток, проявляющий себя при работе с данным, в которых есть много “лишних” признаков — она всегда включает в модель все признаки. Но параметры у них могут быть близки к нулю, что затрудняет интерпретацию модели и не сокращает размерность задачи. На практике в данных могут присутствовать не просто мультиколлинеарные атрибуты, но и такие, которые имеют очень маленькое влияние на целевую переменную или не имеют его вообще. Включать их в модель не имеет никакого смысла.
Для решения этой проблемы существует так называемая лассо-регрессия. Она по своей формализации очень похожа на гребневую, но чуть по-другому учитывает значения параметров модели:
[J(vec{b}) = sum_{i=1}^{m} (h_b(x_i) — y_i)^2 + lambda sum_{j=1}^{n} mid b_j mid]
В данном случае говорят о регуляризации по L1-норме. За счет того, что функция абсолютного значения, которая используется здесь не везде дифференцируема, для обучения такой модели используется специальный метод координатного спуска (coordinate descent), а не градиентного. Но рассмотрение всех вариантов алгоритмов обучения выходит за рамки данного пособия. В остальном же использование лассо на практике абсолютно идентично другим моделям обучения с учителем.
Из-за своей специфической формализации, модель лассо стремиться обратить в ноль как можно больше параметров модели. Это значит, что если какой-то признак не оказывает сильного влияния на целевую переменную, то модель с L1-регуляризацией с большой долей вероятности “занулит” этот признак. Это бывает очень полезно в задачах, где в данных присутствует больше количество ненужной информации. Такие задачи еще часто называют разреженными. К ним часто относятся, например, задачи анализа текстов.
В таких задачах регрессия по методу лассо может использоваться для отбора признаков. Часто эта модель потом вообще не используется, а на оставшихся признаках строится какая-то другая модель обучения с учителем. Так лассо-регрессия может играть вспомогательную роль. Регрессию лассо поэтому часто называют методом понижения размерности — после ее применения в модели остаются (ненулевыми) только те признаки, которые действительно влияют на значение целевой переменной. Хотя это не совсем то, что называют понижением размерности в задачах обучения без учителя.
Также как и любая регуляризация, лассо управляет компромиссом между bias и variance модели за счет введения параметра регуляризации. Он имеет точно такой же смысл, как и в гребневой регрессии — чем он больше численно, тем более простые модели будет предпочитать этот алгоритм. Можно построить график зависимость обучающей и тестовой эффективностей модели от значения параметра регуляризации:
Здесь мы видим, что при малых значениях этого параметра наблюдается большая разница между эффективностями. ПО мере увеличения значения параметра регуляризации сложность, а следовательно и обучающая эффективность модели падают, а разница между ними сокращается. Тестовая же эффективность поначалу растет, но начиная в определенного значения параметра регуляризации (в районе $10^{-1}$) снова начинает снижаться. В левой части этого графика мы наблюдаем ситуацию переобучения, а в правой — недообучения. А примерно $10^{-1}$ — это оптимальное значение параметра регуляризации, при котором получается наиболее качественная модель линейной регрессии.
Давайте построим регрессию по методу лассо на тех же данных, на которых строили в предыдущей главе гребневую регрессию. На этот раз ограничимся одной моделью со средним уровнем регуляризации ($lambda=1$):

Обратим внимание на коэффициенты модели: 0, 0, 0, 0.55, 0, 0. Даже при таком небольшом значении параметра регуляризации модель оставила только один признак — признак третьей степени (что мы и видим на графике — это кубическая парабола, только масштабированная по вертикали). В этом и проявляется действие алгоритма лассо — он стремится как можно больше коэффициентов обратить в ноль.
Lasso, кстати, расшифровывается как least absolute shrinkage and selection operator, оператор наименьшего абсолютного сокращения и выбора.
В данном примере можно сделать вывод, что среди полиномиальных признаков только признак третьей степени оказывал сколь-нибудь существенное влияние на целевую переменную. Таким образом, регрессия по методу лассо работает как алгоритм отбора признаков. В дальнейшем можно используя только этот один признак строить и другие модели машинного обучения на данной задаче, или просто ввести его в датасет, таким образом лассо станет основой для инжиниринга признаков.
Выводы:
- Lasso еще называют регуляризацией по L1-норме.
- Lasso заставляет модель использовать меньше ненулевых коэффициентов.
- Фактически, эта регуляризация уменьшает количество признаков, от которых зависит модель.
- Может использоваться для отбора признаков.
- Полезна в задачах с разреженной матрицей признаков.
Elastic net
После прочтения двух предыдущих разделов может появиться вопрос: какой метод регуляризации лучше? Как всегда не существует универсального ответа. Это целиком зависит от данных. С разреженностью признаков лучше справляется лассо, а с мультиколлинеарностью — гребневая модель. Как всегда, когда есть два подхода, каждый со своими преимуществами, есть способ их скомбинировать. Рассмотрим модель, которая обычно называется elastic net или “эластичная сеть”:
[J(vec{b}) = frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2 +
lambda_1 sum_{j=1}^{n} | b_j | + lambda_2 sum_{j=1}^{n} b_j^2]
Как мы видим, функция ошибки такой модели комбинирует подходы гребневой и лассо-регрессии. То есть включает в себя регуляризацию и по L1 и по L2 нормам. Поэтому в этой модели присутствует целых два параметра регуляризации, причем они независимы друг от друга и задают не только соотношение регуляризации того или иного типа и классической функции ошибки, но и соотношение силы двух типов регуляризации между собой.
А между тем мы еще не говорили о том, как подбирать оптимальные значение параметров регуляризации. А ведь это достаточно серьезная проблема. Их не подберешь обычным методом обучения — это не просто параметры модели. Чуть позже мы назовем их гиперпараметрами. Но подбирать их можно только непосредственной проверкой, то есть подбором в классическом смысле. И это достаточно трудоемкий процесс, так как надо проверить потенциально бесконечное количество значений, причем еще хорошо бы использовать кросс-валидацию для надежности результатов.
А как быть с двумя гиперпараметрами. Обычно их значения подбираются “наивным” способом, в два прохода. Сначала находится оптимальный параметр $lambda_2$ для гребневой регрессии, а потом он фиксируется и подбирается наилучший параметр $lambda_1$ для лассо. Понятно, что они могут зависеть еще и друг от друга. И чуть позже мы изучим более вычислительно емкий, но правильный способ искать оптимальные значения гиперпараметров.
Давайте построим регрессию методом эластичной сети по уже известным нам данным из двух предыдущих глав. В данном случае используем $lambda_1 = lambda_2 = 10$:

Коэффициенты у модели следующие: 0, 0, 0, 0, 0.202, -0.016. Очень заметно совместное влияние двух регуляризаций. L1 выбирает только самые значимые признаки, оставляя у других коэффициенты равными нулю, а L2 еще приближает к нулю оставшиеся коэффициенты. В результате получается очень компактная модель, которая имеет только очень обоснованные коэффициенты.
Конечно, приведенные в данных главах модели не являются обязательно лучшими или оптимальными для решения данной задачи регрессии. Их цель — проиллюстрировать работу алгоритмов и для этого зачастую приходилось на максимум “выкручивать” регуляризацию. В реальности надо искать оптимальный уровень регуляризации, но об этом речь пойдет в следующих главах.
Выводы:
- По сути, это комбинация регуляризации по L1 и L2 нормам.
- Имеет два параметра, которые определяют соотношение соответствующих норм.
- Комбинирует достоинства предыдущих двух методов.
- Недостаток в необходимости задавать сразу два параметра регуляризации.
Методы борьбы с недообучением
В этой главе мы говорим о диагностике моделей машинного обучения в контексте диагностики недо- и переобучения. И мы много говорили о том, как обнаружить эти состояния модели. Так что же делать, если мы обнаружили, что наша модель недообучается. Сейчас поговорим о типичных путях повышения эффективности моделей. И начнем с более простого случая — недообучения.
В первую очередь напомним себе, что такое недообучение. Это ситуация, когда модель демонстрирует слишком большой bias по отношению к имеющимся данным. Модели не хватает вариативности, чтобы “ухватить” зависимости между признаками и целевой переменной. С точки зрения модели, их вообще нет. Простыми словами можно сказать, что модель слишком проста, примитивна для решения поставленной задачи. При этом может быть такое, что имеющиеся данные действительно не содержат необходимой информации, позволяющей надежно предсказать значение целевой переменной.
Поэтому при недообучении первое о чем нужно подумать: есть ли в датасете информация (признак или комбинация признаков), которые бы определяли значение целевой переменной. Если таких нет, то неважно, сколько точек данных, примеров мы соберем, модель всегда будет недообучаться. Неважно, насколько сложную модель мы будем использовать, она покажет случайных шум. Наиболее эффективный способ борьбы с недообучением — инжиниринг признаков. Необходимо ввести в модель признаки (или атрибуты, неважно, важно чтобы была нужная информация), которые позволят модели предсказать значение целевой переменной.
Помните, как мы решали задачу с полиномиальными признаками, как они превращали нерешаемую задачу классификации в линейно разделимую? Так может произойти в любой задаче. Может, одного свойства объекта нам и не хватает, чтобы превратить случайный перемешанный набор точек в многомерном пространстве в четкую и очевидную зависимость.
К сожалению, нет универсального алгоритма инжиниринга признаков. Это всегда творческая деятельность, которая требует, причем, глубокого знания предметной области. Иногда нужно просто вернуться на этап сбора данных и найти (или сгенерировать) больше информации. Иногда помогает вдумчивое и осмысленное преобразование имеющихся атрибутов. Главный вопрос, который надо себе задать: что в реальности влияет на целевую переменную? Затем собирать как можно больше информации об этом, добавлять ее в модель в виде признаков и надеяться, что это повысит эффективность моделей.
Если такой возможности нет, то очевидно, имеет смысл уменьшить степень регуляризации модели. Конечно, этот способ подходит только, если вы используете регуляризованные модели. Но как мы уже обсуждали выше, очень многие модели используют регуляризацию автоматически. А если она применяется, то можно легко манипулировать ее степенью. Понижение регуляризации приведет к тому, что после обучения мы получим более сложную и вариативную модель, что может исправить ситуацию с недообучением.
Другой очевидный способ — использование более сложных моделей в целом. Имеется в виду смена класса моделей. Если недообучается, например, модель линейной регрессии, стоит попробовать дерево решений. Если недообучилась логистическая — попробуйте многослойный перцептрон. Хотя, регуляризация обычно работает более эффективно, чем использование более сложной модели, она ограничена рамками одного параметрического класса функций.
Возможно стоит попытаться повторить обучение или увеличить количество итераций обучения. Возможна ситуация, когда существующего количества итераций недостаточно для схождения метода обучения к локальному минимуму функции ошибки. Это опять же может происходить вследствие того, что задача слишком сложна. В особо сложных случаях можно использовать предобученные модели. Это так называемое трансферное обучение — когда используют уже обученную модель на каком-то одном наборе данных для решения подобной задачи на другом датасете. Например, существуют так называемые глубокие языковые модели — огромные нейросети с миллиардами параметров, которые обучаются на гигантских корпусах текстов. Они используются для разнообразных задач текстовой аналитики. Конечно, каждый раз нецелесообразно обучать такую огромную модель с нуля — можно воспользоваться уже обученной и дообучить ее (или обучить, например, только последний слой нейронной сети) под собственную задачу. Трансферное обучение — отдельная и очень интересная дисциплина машинного обучения, но ее подробное рассмотрение выходит за рамки этого пособия.
Отдельно стоит сказать, что не поможет при недообучении. Вам вряд ли поможет увеличение объема выборки. Многие думают, что собрать больше данных — это универсальный рецепт эффективности. Это тоже не так. Хотя, большая по объему выборка особенно и не помешает, то есть не уменьшит эффективность модели, она увеличит вычислительную емкость. Другими словами, модель будет обучаться значительно дольше, но без видимого положительного эффекта по эффективности.
Обратите внимание, что мы здесь всегда имеем в виду эффективность, измеренную на тестовой выборке. А еще лучше — с использованием кросс-валидации. Эффективность на обучающей выборке нужна только для диагностики и анализа моделей.
Стоит помнить, что машинное обучение — это всегда итеративный процесс. Построив первую модель нужно ее исследовать и пытаться улучшить, увеличить эффективность. При этом возможно стоит попробовать множество разных видов моделей и способов обработки данных.
Выводы:
- Ввести в модель новые данные об объектах (атрибуты).
- Уменьшение степени регуляризации модели.
- Введение полиномиальных и других суррогатных признаков.
- В целом, инжиниринг признаков.
- Использование более сложных моделей.
- Увеличение количества итераций.
- Трансферное обучение.
Методы борьбы с переобучением
Переобучение на практике более частая и более коварная проблема потому, что несложно взять для решение конкретной задачи более сложную модель. Гораздо труднее заставить ее работать хорошо на новых данных. Проблему переобучения обнаружить сложнее и потому, что при этой ситуации модель работает вроде бы хорошо — дает низкую ошибку на данных. Но на других точках модель почему-то начинает ошибаться гораздо сильнее.
Опять же вспомним, что суть ситуации переобучения состоит в том, что модель оказывается слишком сложной для имеющихся данных и зависимостей в них. Поэтому вместо общих тенденций модель начинает обращать внимание на конкретное расположение точек в обучающей выборке, на случайные флуктуации, которые не несут смысловой нагрузки и не будут повторяться в новых данных.

Чем меньше данных присутствует в обучающей выборке, тем больше в них “шума” по отношению к полезному “сигналу” — информации о случайных колебаниях значений признаков по сравнению с информацией о тенденциях и реальных зависимостях. Поэтому неудивительно, что на малых объемах данных при прочих равных модели склонны к переобучению. Взгляните на график выше — даже человеку неочевидно, что точки выборки образуют линейную тенденцию — их просто слишком мало, чтобы показать эту тенденцию.
Самый действенный способ борьбы с переобучением — собрать больше обучающих примеров.
Если мы добавим больше точек, принадлежащих тому же распределению, мы неизбежно более четко увидим имеющуюся тенденцию. Все дело в том, что основное свойство случайных колебаний — их математическое ожидание равно нулю. То есть значение показателя может под воздействием неизвестных или неучтенных факторов отклоняться от “правильного” значения как в сторону увеличения, так и в сторону уменьшения. Причем вероятность этого примерно равна. И если мы рассматриваем одну точку данных, то сложно сказать, чем обосновано ее конкретное значение — существенными факторами или случайностью. Но если рассмотреть большое множество точек, можно увидеть, что они группируются вокруг некоторого среднего.
Другими словами, при увеличении количества точек обучающей выборки все случайные колебания будут усредняться — на каждое положительное отклонение найдется примерно равное отрицательное. А тенденция же будет, наоборот, усиливаться. В итоге и человеку и модели будет значительно легче эту тенденцию “ухватить”. Посмотрите, например, что будет, если к выборке, изображенной на рисунке выше добавить еще в 10 раз больше точек из того же распределения:

Теперь довольно очевидно, что на лицо линейная тенденция. И даже более сложная полиномиальная функция работает гораздо более эффективно на этих данных. Именно так добавление данных борется с переобучением моделей.
Причем необходимое количество данных зависит от вида тенденции и величины случайных отклонений. Чем более сложная, нелинейная тенденция в данных существует, чем тоньше зависимость целевой переменной от значения атрибутов, тем больше данных нужно для адекватной работы моделей. И чем больше по величине случайные отклонения, чем “сильнее” они размывают эту тенденцию, тем больше данных понадобится. Поэтому не существует какого-то оптимального объема данных, все зависит от конкретной задачи.
Как мы видели на примерах ранее, переобучение зачастую возникает вследствие того, что в модели присутствует большое количество параметров за счет большого количества лишних признаков в датасете. Именно для борьбы с этим используется регуляризация и в целом отбор признаков. Незначимые атрибуты лучше убирать из данных еще на этапе предварительного анализа и очистки данных. Чем меньше в данных будет лишних признаков, тем более четко и ясно будет прослеживаться та самая заветная тенденция.
Однако следует помнить, что регуляризация на практике работает лучше, чем ручное удаление признаков, так как подбор коэффициентов модели происходит автоматически. При этом регуляризация имеет свои недостатки — необходимость подбора параметра регуляризации. Поэтому стоит комбинировать эти способы — если какие-то признаки явно не влияют на целевую переменную — их стоит убрать при обработке данных, а если есть сомнения — то лучше оставить на усмотрение регуляризации.
Кроме того, следует помнить, что в других классах моделей могут применяться и иные способы управления сложностью модели, которые эффективно в чем-то похожи на регуляризацию. Например, в деревьях решений — это ограничение глубины дерева. Мы уже говорили об этом: чем больше слоев в дереве, тем сложнее получается модель. В нейронных сетях для подобного же используются Dropout-слои. Подробно мы не сможем рассказать про все эти способы, тем более что они специфичны для разных классов моделей. Но на практике они применяются примерно также, как и обычная регуляризация.
Как мы видим на втором графике даже после добавления большого количества точек более простая модель все равно описывает выборку лучше, так как полиномиальная модель имеет не очень понятные “хвосты” на концах распределения. Поэтому при обнаружении переобучения стоит задуматься об использовании более простого параметрического класса функций. Этот способ работает лучше в совокупности с увеличением объема выборки. Вообще, комбинация нескольких способов может быть более эффективной, чем применение только одного.
В глубоком обучении есть эмпирическое правило, которое гласит, что количество параметров модели должно быть в 2-3 раза меньше, чем количество примеров в обучающей выборке. Это ни в коем случае не универсальное правило и не гарантия от переобучения. Помните, вся зависит от задачи. Но можно помнить об этом ориентире. Если количество параметров больше, чем рекомендует это правило, вы практически точно получите переобученную модель.
Кроме того, не стоит забывать о ложных корреляциях в данных, которые тоже могут стать причиной переобучения. Хотя, ложные зависимости данных в силу их ограниченности — это явление несколько другой природы, на практике оно проявляет себя точно как переобучение — снижает обобщающую способность модели. Для устранения ложных корреляций необходимо хорошо разбираться в предметной области или привлекать для анализа данных экспертов.
Еще устраняют или сильно снижают переобучение так называемые ансамблевые модели, особенно основанные на методе бустинга. Ансамблевые модели это отдельная большая тема, которую мы не сможем рассмотреть в этой главе, про них можно написать отдельную книгу. Но если вкратце, ансамбль — это набор моделей, обученных на одном и том же наборе данных. Метод бустинга заключается в том, что каждая следующая модель в ансамбле исправляет или компенсирует ошибки предыдущей. В итоге мы получаем такую метамодель, которая может работать более эффективно, чем каждая модель ансамбля по отдельности.
Еще один способ избежать переобучения моделей — ранняя остановка обучения. Раньше мы говорили, что процесс обучения всегда продолжается до полной сходимости, то есть до нахождения оптимальных значений параметров по заданной функции ошибки. Но это не всегда так. В процессе обучения можно контролировать ту самую тестовую эффективность и остановить обучение тогда, когда она начнет падать. Этот способ часто применяется в обучении нейронных сетей, так как оно начинается с малых случайных значений весов (параметров) сети. Поэтому само обучение, то есть подбор весов, немного имеет эффект повышения значения коэффициентов, который противоположен регуляризации, то есть повышение степени сложности модели. Поэтому ранняя остановка обучения эффективно похожа на введение регуляризации в модель. Важно остановить обучение именно в тот момент, когда сложность модели начнет превышать оптимальное значение, после которого начинается переобучение. Это простой, но не очень универсальный способ.
Каждый способ борьбы с переобучением (впрочем как и с недообучением) имеет свои достоинства и недостатки. Не существует универсального алгоритма действий. Поэтому всегда надо исходить из поставленной задачи, а также руководствоваться всеми факторами: характер модели, нефункциональные требования, особенности набора данных, возможность собрать больше точек или атрибутов. При возможности стоит попробовать несколько разных способов увеличения эффективности моделей.
Выводы:
- Ввести в модель данные о новых объектах, использовать выборку большего объема.
- Убрать признаки из модели, использовать отбор признаков, устранить ложные корреляции.
- Увеличить степень регуляризации модели.
- Использовать более простые модели.
- Регуляризация обычно работает лучше уменьшения количества параметров.
- Можно использовать ансамблевые модели.
- Ранняя остановка обучения.
Анализ ошибок
Рассматривая алгоритмические и математические способы повышения эффективности работы моделей машинного обучения не стоит забывать и о самом простом, но в тоже время одном из самых эффективных — ручном анализе ошибок модели. После обучения модели, если она не достигает желаемого уровня эффективности стоит просто обратить внимание на те объекты, на которых она делает ошибки. Этот подход называется анализ ошибок и может дать достаточно неожиданную информацию о модели, данных и самой задаче.
В отдельных случаях анализ ошибок приводит к выводу, что модель работает хорошо. Например, очень известна задача по распознаванию рукописных цифр по картинке. Даже относительно простые модели справляются с ней очень хорошо, но могут не достигать стопроцентной эффективности. Вот пример картинки, которую простая модель может классифицировать неправильно:

Свидетельствует ли эта ошибка о том, что модель обучилась неправильно? Скорее нет, это свидетельствует о низком разрешении картинок и наличии некоторых двусмысленных объектов в обучающей выборке. Такую рукописную цифру и человек бы не распознал.
Кроме того, в данных могут присутствовать просто ошибки. Особенно это касается датасетов, размеченных вручную. Человек мог просто опечататься или ошибиться и в наборе данных появился объект с неправильным значением целевой переменной. На практике все случается и именно ручной анализ ошибок может выявить такую ситуацию.
Ручная проверка индивидуальных объектов, на которых модель работает неправильно часто подсказывает, какие общие характеристики имеют такие объекты или чем они отличаются от остальной выборки. Поняв эти особенности можно найти способы модифицировать признаки таким образом, чтобы лучше учитывать эти особенности. Например, анализируя модель распознавания человека по лицу можно придти к выводу о том, что такая модель значительно чаще ошибается на лицах с растительностью или на людях в очках. Это вполне объяснимо с логической точки зрения. Так что же делать в таком случае? Можно просто собрать больше точек данных, лиц с растительностью или очками. Это не только просто повысит эффективность модели, но и сделает ее более устойчивой к подобным особенностям в принципе.
При проведении анализа ошибок следует ориентироваться на ошибки, которые модель делает именно в тестовой выборке. В задачах классификации в первую очередь следует проанализировать ошибки в тех классах, в которых модель делает больше всего ошибок. Это очень заметно в отчете о классификации и в марице классификации. Обычно бывает, что модель постоянно относит объекты одного класса к какому-то другому. А в задачах регрессии очень логично обратить внимание на объекты, на которых модель ошибается сильнее всего в численном выражении.
Выводы:
- Анализ ошибок — это ручная проверка объектов, на которых модель делает ошибки.
- Анализ характеристик таких объектов может подсказать направление инжиниринга признаков.
- Можно сравнить эти объекты с остальной выборкой. Может, это аномалии.
- В задачах регрессии в первую очередь обращать внимание на объекты с самым высоким отклонением.
Выбор модели
Выводы:
- Задача выбора класса модели для решения определенной задачи.
- Очень сложно сказать априори какой класс модели будет работать лучше на конкретных данных.
- Следует учитывать нефункциональные требования к задаче.
- Обычно начинают с самых простых моделей — они быстро считаются и дают базовый уровень эффективности.
- По результатам диагностики простых моделей принимают решение о дальнейших действиях.
- Можно провести поиск по разным классам моделей для определения самых перспективных.
- Выбор модели — это творческий и исследовательский процесс.
- Есть подходы автоматизации выбора модели (AutoML), но они пока несовершенны.
- В исследовательских задачах модели сравниваются со state-of-the-art.
Гиперпараметры модели
Выводы:
- Гиперпараметр модели — это численное значение, которое влияет на работу модели, но не подбирается в процессе обучения.
- Примеры гиперпараметров — k в kNN, параметр регуляризации, степень полиномиальной регрессии, глубина дерева решения.
- У каждой модели множество гиперпараметров, которые можно посмотреть в документации.
- Гиперпараметры модели нужно задавать до начала обучения.
- Если значение гиперпараметра изменилось, то обучение надо начинать заново.
- Существуют скрытые гиперпараметры модели — степень полинома, количество нейронов и слоев, ядерная функция.
- Оптимизация гиперпараметров и задача выбора модели — одно и то же.
Поиск по сетке
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
tuned_parameters = [
{"kernel": ["rbf"],
"gamma": [1e-3, 1e-4],
"C": [1, 10, 100, 1000]},
{"kernel": ["linear"],
"C": [1, 10, 100, 1000]},
]
scores = ["precision", "recall"]
grid_search = GridSearchCV(SVC(), tuned_parameters,
scoring=scores).fit(X_train, y_train)
Выводы:
- Поиск по сетке — полный перебор всех комбинаций значений гиперпараметров для поиска оптимальных значений.
- Для его организации надо задать список гиперпараметров и их конкретных значений.
- Непрерывные гиперпараметры надо дискретизировать.
- Поиск по сетке имеет экспоненциальную сложность.
- Чем больше параметров и значений задать, тем лучше модель, но дольше поиск.
- Можно задать критерии поиска — целевые метрики.
Случайный поиск
1
2
3
4
5
6
7
8
9
10
11
12
clf = SGDClassifier(loss="hinge", penalty="elasticnet", fit_intercept=True)
param_dist = {
"average": [True, False],
"l1_ratio": stats.uniform(0, 1),
"alpha": loguniform(1e-2, 1e0),
}
n_iter_search = 15
random_search = RandomizedSearchCV(
clf, param_distributions=param_dist, n_iter=n_iter_search
).fit(X, y)
Выводы:
- Случайный поиск позволяет задать распределение гиперпараметра, в котором будет вестись поиск.
- Случайный поиск семплирует набор значений гиперпараметров из указанных распределений.
- Можно задать количество итераций поиска независимо от количества гиперпараметров.
- Добавление параметров не влияет на продолжительность поиска.
- Результат не гарантируется. Воспроизводимость можно настроить.
Сравнение эффективности моделей (валидационный набор)

Выводы:
- При сравнении нескольких моделей между собой возникает проблема оптимистичной оценки эффективности.
- Поэтому для исследования выбранной модели нужно использовать третью часть выборки — валидационную.
- В терминах существует путаница, главное — три непересекающиеся части выборки.
- Обучающая (train) используется для оптимизации параметров (обучения) модели.
- Валидационная (validation) — для оптимизации гиперпараметров и выбора модели.
- Тестовая (test, holdout) — для итоговой оценки качества, представления результатов.
- Во многих случаях использование кросс-валидации автоматически разбивает выборку. Поэтому тестовая играет роль валидационной.
- Есть проблема глобального переобучения моделей на известных датасетах.
Skip to content
![]()

Error Metrics: How to Evaluate Your Forecasts
When considering the performance of any forecasting model, the prediction values it produces must be evaluated. This is done by calculating suitable error metrics. An error metric is a way to quantify the performance of a model and provides a way for the forecaster to quantitatively compare different models1. They give us a way to more objectively gauge how well the model executes its tasks.
In this blog post we will cover some commonly used metrics for time series forecasting, how to interpret them, as well as the limitations of each metric. A friendly warning: This involves some math, which is necessary to explain how these metrics work. But the interpretation and limitations are clearly marked, so you can skip directly to the marked sections below the equations for straightforward explanations.
- Mean Absolute Error (MAE)
- Mean Absolute Percentage Error (MAPE)
- Mean Squared Error (MSE)
- Root Mean Squared Error (RMSE)
- Normalized Root Mean Squared Error (NRMSE)
- Weighted Absolute Percentage Error (WAPE)
- Weighted Mean Absolute Percentage Error (WMAPE)
- Range of Errors & Accuracies
- Conclusion
Mean Absolute Error (MAE)
MAE is defined as the average of absolute difference between forecasted values and true values.
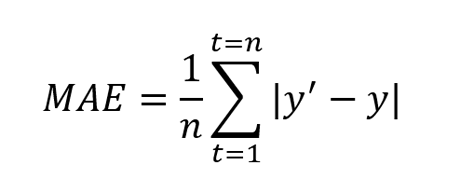
Where y’ is forecasted value and y is the true value. n is total number of values in the test set. MAE tells us how big of an error we can expect from the forecast on an average2. The error values are in the original units of forecasted values and MAE = 0 indicates that there is no error in the forecasted values.
The lower the MAE value, the better the model is; a value of zero means there is no error in the forecast. In other words, when comparing multiple models, the model with the lowest MAE is considered better.
However, MAE does not indicate the relative size of the error and it becomes difficult to differentiate big errors from small errors. It can be used with other metrics (see Root Mean Square Error below) to determine if the errors are larger. Additionally, MAE can gloss over problems to do with low data volume; see the last two metrics in this article to address that issue.
Mean Absolute Percentage Error (MAPE)
MAPE is defined as the percentage of the average of absolute difference between forecasted values and true values, divided by true value.
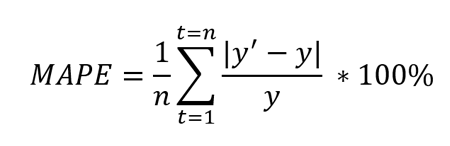
Where y’ is forecasted value and y is the true value. n is total number of values in the test set. Because of the in denominator, it works best with data without zeros and extreme values. If this value is extremely small or large, the MAPE value also takes an extreme value.
The lower the MAPE, the better the model is. Keep in mind that MAPE works best with data without zeros and extreme values. Like MAE, MAPE also understates the impact of large but infrequent errors due to extreme values. To deal with this problem, Mean Square Error can be used. This metric can gloss over problems to do with low data volume; see the last two metrics in this article to deal with that situation.
Mean Squared Error (MSE)
MSE is defined as the average of squares of the error3. It is also defined as the metric that assesses the quality of forecasting model or predictor. MSE also incorporates both the variance (the spread of predicted values from each other) and bias (the distance of predicted value from its true value).
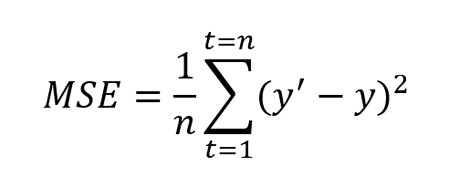
Where y’ is forecasted value and y is the true value. n is total number of values in the test set. MSE is almost always positive and values closer to zero are better. Because of the square term (as seen in the formula above), this metric penalizes large errors or outliers more compared to the small errors.
The closer to zero MSE is, the better. While it solves the extreme value and zero problem of MAE and MAPE, it might be disadvantageous in some cases. This metric can overlook issues when dealing with low data volume; see Weighted Absolute Percentage Error and Weighted Mean Absolute Percentage Error to deal with that.
Root Mean Squared Error (RMSE)
This metric is an extension of MSE and is defined as the square root of mean square error.
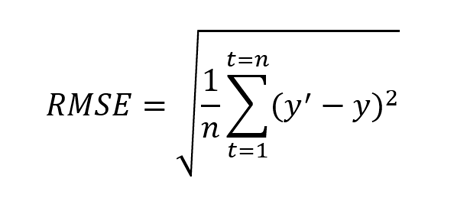
Where y’ is forecasted value and y is the true value. n is total number of values in the test set. Like MSE, this metric also penalizes larger errors more.
This metric is also always positive and lower values are better. One advantage of this calculation is that the RMSE value is in the same unit as the forecasted value. This makes it easier to understand compared to MSE.
RMSE can also be compared to MAE to determine whether the forecast contains large but infrequent errors. The larger the difference between RMSE and MAE the more inconsistent the error size.2 This metric can gloss over problems to do with low data volume; see the last two metrics in this article to address that issue.
Normalized Root Mean Squared Error (NRMSE)
NRMSE is an extension of RMSE and is calculated by normalizing RMSE. There are two popular methods for normalizing RMSE: using mean or using the range of the true values (difference of minimum and maximum values).
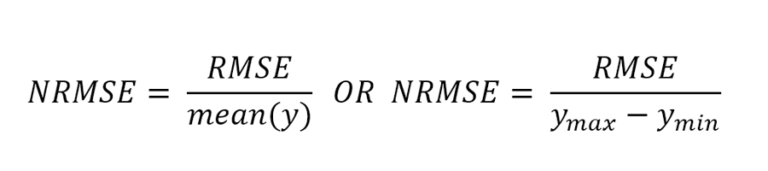
Where ymax is the maximum true value and ymin is the minimum true value.
NRMSE is often used to compare different datasets or forecasting models that have different scales (units and gross revenue, for example). The smaller the value is, the better the performance of the model. This metric can overlook issues when dealing with low data volume; see Weighted Absolute Percentage Error and Weighted Mean Absolute Percentage Error to address this.
Weighted Absolute Percentage Error (WAPE)
WAPE is defined as the weighted average of the mean absolute error.
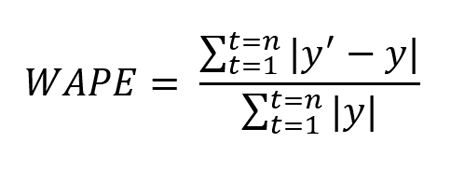
Where y’ is forecasted value and y is the true value. n is total number of values in the test set.
The error metrics mentioned above help us measure the performance of the forecasting model but can be deceiving when dealing with low volume data, for example, when the true value of some data points is very small compared to the rest of the data (e.g., intermittent demand/sales data). For such cases, WAPE can be used.
The lower the value of WAPE, the better the performance of the model. WAPE is helpful here because the “weighing” helps distinguish the smaller errors from larger errors. In other words, this metric prevents the small values from being considered as equal to or higher than larger values.4
Weighted Mean Absolute Percentage Error (WMAPE)
WMAPE is an extension of WAPE and is defined as the weighted mean absolute percentage error.
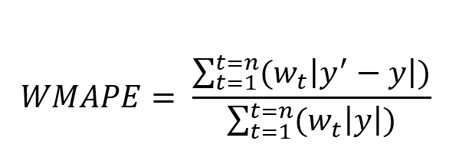
Where y’ is forecasted value and y is the true value. n is total number of values in the test set.
The lower the value of WMAPE, the better the performance of the model. This metric is helpful for low volume data where each observation has different priority when evaluating forecasting models. Observations with higher priority have a higher weight value. The larger the error in high priority forecast values, the larger the WMAPE value is.
Range of Errors & Accuracies
When using the error metrics mentioned above, the actual distribution of the error values is not known. However, this distribution can give further insights into the behavior of the forecasting model and help select the most suitable metric. In the Jedox AIssisted™ Planning Wizard, besides the aforementioned metrics, error distribution is also calculated, i.e., the value of the metric for each data point of the test set. A summary of the distribution, including other relevant values such as the minimum, maximum and median error values, is also provided.
Conclusion
Even though there are multiple metrics, each one provides specific information that may or may not be suitable for your specific use case. This means a metric should be chosen based on the use case and an understanding of the data involved in making the predictions.
Overview error metrics for forecasts
- MAE is useful when absolute error needs to be measured. It is easy to understand but it is not efficient when data has extreme values.
- MAPE is also easy to understand and is used when different forecast models or datasets need to be compared because this is a percentage value. MAPE suffers from the same disadvantage as MAE, i.e., it is not efficient when data has extreme values.
- MSE is useful when spread of the forecast values is important and larger values need to be penalized. However, this metrics is often difficult to interpret because it is a squared value.
- RMSE (NRMSE) is also useful when spread is of importance and larger values need to be penalized. RMSE is easier to interpret when compared to MSE because the RMSE value is of the same scale as the forecasted values.
- WAPE is useful when dealing with low volume data as it is calculated by weighting the error over total true values.
- WMAPE is also useful when dealing with low volume data. WMAPE helps to incorporate the priority by utilizing the weight (priority value) of each observation.
Jedox provides a comprehensive overview of forecast errors and their distribution in the AIssisted™ Planning Wizard, and also an unbiased view into the future with predictive forecasting.
References
1 Error Metrics
2 Absolute Error Forecast Accuracy
3 Mean Squared Error
4 MAPE vs. WAPE (DE)

Your ultimate guide to strategic sales planning
A pillar of modern sales performance management
Jedox
Jedox is the world’s most adaptable planning and performance management platform that empowers organisations to deliver plans that outperform expectations. Over 2,500 organisations in 140 countries trust Jedox to model any scenario, integrate data from any source and simplify cross-organisational plans across all business systems. Jedox enables a culture of decisiveness and confidence so teams can plan for opportunities, react quickly to changes, and uncover what they didn’t know was possible.
Related Articles
Page load link
Go to Top
Содержание
- Ошибка прогнозирования: виды, формулы, примеры
- sklearn.metrics .mean_absolute_percentage_error¶
- MAPE – Mean Absolute Percentage Error in Python
- What is MAPE?
- Mean Absolute Percentage Error with NumPy module
- Mean Absolute Percentage Error with Python scikit learn library
- Conclusion
- Методы оценки качества прогноза
- Остатки
- Суровые MSE и R 2
- MAPE и MAD для сравнения моделей
Ошибка прогнозирования: виды, формулы, примеры

Ошибка прогнозирования — это такая величина, которая показывает, как сильно прогнозное значение отклонилось от фактического. Она используется для расчета точности прогнозирования, что в свою очередь помогает нам оценивать как точно и корректно мы сформировали прогноз. В данной статье я расскажу про основные процентные «ошибки прогнозирования» с кратким описанием и формулой для расчета. А в конце статьи я приведу общий пример расчётов в Excel. Напомню, что в своих расчетах я в основном использую ошибку WAPE или MAD-Mean Ratio, о которой подробно я рассказал в статье про точность прогнозирования, здесь она также будет упомянута.
В каждой формуле буквой Ф обозначено фактическое значение, а буквой П — прогнозное. Каждая ошибка прогнозирования (кроме последней!), может использоваться для нахождения общей точности прогнозирования некоторого списка позиций, по типу того, что изображен ниже (либо для любого другого подобной детализации):
Алгоритм для нахождения любой из ошибок прогнозирования для такого списка примерно одинаковый: сначала находим ошибку прогнозирования по одной позиции, а затем рассчитываем общую. Итак, основные ошибки прогнозирования!
MPE — Mean Percent Error
MPE — средняя процентная ошибка прогнозирования. Основная проблема данной ошибки заключается в том, что в нестабильном числовом ряду с большими выбросами любое незначительное колебание факта или прогноза может значительно поменять показатель ошибки и, как следствие, точности прогнозирования. Помимо этого, ошибка является несимметричной: одинаковые отклонения в плюс и в минус по-разному влияют на показатель ошибки.

- Для каждой позиции рассчитывается ошибка прогноза (из факта вычитается прогноз) — Error
- Для каждой позиции рассчитывается процентная ошибка прогноза (ошибка прогноза делится на фактический показатель) — Percent Error
- Находится среднее арифметическое всех процентных ошибок прогноза (процентные ошибки суммируются и делятся на количество) — Mean Percent Error
MAPE — Mean Absolute Percent Error
MAPE — средняя абсолютная процентная ошибка прогнозирования. Основная проблема данной ошибки такая же, как и у MPE — нестабильность.

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта по модулю) — Absolute Error
- Для каждой позиции рассчитывается абсолютная процентная ошибка прогноза (абсолютная ошибка прогноза делится на фактический показатель) — Absolute Percent Error
- Находится среднее арифметическое всех абсолютных процентных ошибок прогноза (абсолютные процентные ошибки суммируются и делятся на количество) — Mean Absolute Percent Error
Вместо среднего арифметического всех абсолютных процентных ошибок прогноза можно использовать медиану числового ряда (MdAPE — Median Absolute Percent Error), она наиболее устойчива к выбросам.
WMAPE / MAD-Mean Ratio / WAPE — Weighted Absolute Percent Error
WAPE — взвешенная абсолютная процентная ошибка прогнозирования. Одна из «лучших ошибок» для расчета точности прогнозирования. Часто называется как MAD-Mean Ratio, то есть отношение MAD (Mean Absolute Deviation — среднее абсолютное отклонение/ошибка) к Mean (среднее арифметическое). После упрощения дроби получается искомая формула WAPE, которая очень проста в понимании:

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта, по модулю) — Absolute Error
- Находится сумма всех фактов по всем позициям (общий фактический объем)
- Сумма всех абсолютных ошибок делится на сумму всех фактов — WAPE
Данная ошибка прогнозирования является симметричной и наименее чувствительна к искажениям числового ряда.
Рекомендуется к использованию при расчете точности прогнозирования. Более подробно читать здесь.
RMSE (as %) / nRMSE — Root Mean Square Error
RMSE — среднеквадратичная ошибка прогнозирования. Примерно такая же проблема, как и в MPE и MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня. Но так как MSE дает расчетные единицы измерения в квадрате, то использовать данную ошибку будет немного неправильно.

- Для каждой позиции рассчитывается квадрат отклонений (разница между фактом и прогнозом, возведенная в квадрат) — Square Error
- Затем рассчитывается среднее арифметическое (сумма квадратов отклонений, деленное на количество) — MSE — Mean Square Error
- Извлекаем корень из полученного результат — RMSE
- Для перевода в процентную или в «нормализованную» среднеквадратичную ошибку необходимо:
- Разделить на разницу между максимальным и минимальным значением показателей
- Разделить на разницу между третьим и первым квартилем значений показателей
- Разделить на среднее арифметическое значений показателей (наиболее часто встречающийся вариант)
MASE — Mean Absolute Scaled Error
MASE — средняя абсолютная масштабированная ошибка прогнозирования. Согласно Википедии, является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Важно! Если предыдущие ошибки прогнозирования мы могли использовать для нахождения точности прогнозирования некого списка номенклатур, где каждой из которых соответствует фактическое и прогнозное значение (как было в примере в начале статьи), то данная ошибка для этого не предназначена: MASE используется для расчета точности прогнозирования одной единственной позиции, основываясь на предыдущих показателях факта и прогноза, и чем больше этих показателей, тем более точно мы сможем рассчитать показатель точности. Вероятно, из-за этого ошибка не получила широкого распространения.
Здесь данная формула представлена исключительно для ознакомления и не рекомендуется к использованию.
Суть формулы заключается в нахождении среднего арифметического всех масштабированных ошибок, что при упрощении даст нам следующую конечную формулу:

Также, хочу отметить, что существует ошибка RMMSE (Root Mean Square Scaled Error — Среднеквадратичная масштабированная ошибка), которая примерно похожа на MASE, с теми же преимуществами и недостатками.
Это основные ошибки прогнозирования, которые могут использоваться для расчета точности прогнозирования. Но не все! Их очень много и, возможно, чуть позже я добавлю еще немного информации о некоторых из них. А примеры расчетов уже описанных ошибок прогнозирования будут выложены через некоторое время, пока что я подготавливаю пример, ожидайте.
Источник
sklearn.metrics .mean_absolute_percentage_error¶
Mean absolute percentage error (MAPE) regression loss.
Note here that the output is not a percentage in the range [0, 100] and a value of 100 does not mean 100% but 1e2. Furthermore, the output can be arbitrarily high when y_true is small (which is specific to the metric) or when abs(y_true — y_pred) is large (which is common for most regression metrics). Read more in the User Guide .
New in version 0.24.
Ground truth (correct) target values.
y_pred array-like of shape (n_samples,) or (n_samples, n_outputs)
Estimated target values.
sample_weight array-like of shape (n_samples,), default=None
Defines aggregating of multiple output values. Array-like value defines weights used to average errors. If input is list then the shape must be (n_outputs,).
Returns a full set of errors in case of multioutput input.
Errors of all outputs are averaged with uniform weight.
Returns : loss float or ndarray of floats
If multioutput is ‘raw_values’, then mean absolute percentage error is returned for each output separately. If multioutput is ‘uniform_average’ or an ndarray of weights, then the weighted average of all output errors is returned.
MAPE output is non-negative floating point. The best value is 0.0. But note that bad predictions can lead to arbitrarily large MAPE values, especially if some y_true values are very close to zero. Note that we return a large value instead of inf when y_true is zero.
Источник
MAPE – Mean Absolute Percentage Error in Python

Hello, readers! In our series of Error Metrics, we have understood and implemented Root Mean Square Error.
Today, we will be focusing on another important error metric in model building — Mean Absolute Percentage Error (MAPE) in Python.
What is MAPE?
Mean Absolute Percentage Error (MAPE) is a statistical measure to define the accuracy of a machine learning algorithm on a particular dataset.
MAPE can be considered as a loss function to define the error termed by the model evaluation. Using MAPE, we can estimate the accuracy in terms of the differences in the actual v/s estimated values.
Let us have a look at the below interpretation of Mean Absolute Percentage Error–
As seen above, in MAPE, we initially calculate the absolute difference between the Actual Value (A) and the Estimated/Forecast value (F). Further, we apply the mean function on the result to get the MAPE value.
MAPE can also be expressed in terms of percentage. Lower the MAPE, better fit is the model.
Mean Absolute Percentage Error with NumPy module
Let us now implement MAPE using Python NumPy module.
At first, we have imported the dataset into the environment. You can find the dataset here.
Further, we have split the dataset into training and testing datasets using the Python train_test_split() function.
Then, we have defined a function to implement MAPE as follows–
- Calculate the difference between the actual and the predicted values.
- Then, use numpy.abs() function to find the absolute value of the above differences.
- Finally, apply numpy.mean() function to get the MAPE.
Example:
Now, we have implemented a Linear Regression to check the error rate of the model using MAPE.
Here, we have made use of LinearRegression() function to apply linear regression on the dataset. Further, we have used the predict() function to predict the values for the testing dataset.
At last, we have called the MAPE() function created above to estimate the error value in the predictions as shown below:
Output:
Mean Absolute Percentage Error with Python scikit learn library
In this example, we have implemented the concept of MAPE using Python sklearn library.
Python sklearn library offers us with mean_absolute_error() function to calculate the MAPE value as shown below–
Example:
Output:
Conclusion
By this, we have come to the end of this topic. Feel free to comment below, in case you come across any question.
For more such posts related to Python, Stay tuned here and till then, Happy Learning!! 🙂
Источник
Методы оценки качества прогноза
Часто при составлении любого прогноза — забывают про способы оценки его результатов. Потому как часто бывает, прогноз есть, а сравнение его с фактом отсутствует. Еще больше ошибок случается, когда существуют две (или больше) модели и не всегда очевидно — какая из них лучше, точнее. Как правило одной цифрой (R 2 ) сложно обойтись. Как если бы вам сказали — этот парень ходит в синей футболке. И вам сразу все стало про него ясно )
В статьях о методах прогнозирования при оценке полученной модели я постоянно использовал такие аббревиатуры или обозначения.
- R 2
- MSE
- MAPE
- MAD
- Bias
Попробую объяснить, что я имел в виду.
Остатки
Суровые MSE и R 2
Когда нам требуется подогнать кривую под наши данные, то точность этой подгонки будет оцениваться программой по среднеквадратической ошибке (mean squared error, MSE). Рассчитывается по незамысловатой формуле 
где n-количество наблюдений.
Соотвественно, программа, рассчитывая кривую подгонки, стремится минимизировать этот коэффициент. Квадраты остатков в числителе взяты именно по той причине, чтобы плюсы и минусы не взаимоуничтожились. Физического смысла MSE не имеет, но чем ближе к нулю, тем модель лучше.
Вторая абстрактная величина это R 2 — коэффициент детерминации. Характеризует степень сходства исходных данных и предсказанных. В отличии от MSE не зависит от единиц измерения данных, поэтому поддается сравнению. Рассчитывается коэффициент по следующей формуле: 
где Var(Y) — дисперсия исходных данных.
Безусловно коэффициент детерминации — важный критерий выбора модели. И если модель плохо коррелирует с исходными данными, она вряд ли будет иметь высокую предсказательную силу. 
MAPE и MAD для сравнения моделей
Статистические методы оценки моделей вроде MSE и R 2 , к сожалению, трудно интерпретировать, поэтому светлые головы придумали облегченные, но удобные для сравнения коэффициенты.
Среднее абсолютное отклонение (mean absolute deviation, MAD) определяется как частное от суммы остатков по модулю к числу наблюдений. То есть, средний остаток по модулю. Удобно? Вроде да, а вроде и не очень. В моем примере MAD=43. Выраженный в абсолютных единицах MAD показывает насколько единиц в среднем будет ошибаться прогноз.
MAPE призван придать модели еще более наглядный смысл. Расшифровывается выражение как средняя абсолютная ошибка в процентах (mean percentage absolute error, MAPE). 
где Y — значение исходного ряда.
Выражается MAPE в процентах, и в моем случае означает, что в модель может ошибаться в среднем на 16%. Что, согласитесь, вполне допустимо.
Наконец, последняя абсолютно синтетическая величина — это Bias, или просто смещение. Дело в том, что в реальном мире отклонения в одну сторону зачастую гораздо болезненнее, чем в другую. К примеру, при условно неограниченных складских помещениях, важнее учитывать скачки реального спроса вверх от спрогнозированных значений. Поэтому случаи, где остатки положительные относятся к общему числу наблюдений. В моем случае 44% спрогнозированных значений оказались ниже исходных. И можно пожертвовать другими критериями оценки, чтобы минимизировать этот Bias.
Можете попробовать это сами в  Excel и Numbers
Excel и Numbers
Интересно узнать — какие методы оценки качества прогнозирования вы используете в своей работе?
Источник