When the token pattern does not match the prefix of the remaining input, the lexical analyzer gets stuck and has to recover from this state to analyze the remaining input. In simple words, a lexical error occurs when a sequence of characters does not match the pattern of any token. It typically happens during the execution of a program.
Types of Lexical Error:
Types of lexical error that can occur in a lexical analyzer are as follows:
1. Exceeding length of identifier or numeric constants.
Example:
C++
#include <iostream>
using namespace std;
int main() {
int a=2147483647 +1;
return 0;
}
This is a lexical error since signed integer lies between −2,147,483,648 and 2,147,483,647
2. Appearance of illegal characters
Example:
C++
#include <iostream>
using namespace std;
int main() {
printf("Geeksforgeeks");$
return 0;
}
This is a lexical error since an illegal character $ appears at the end of the statement.
3. Unmatched string
Example:
C++
#include <iostream>
using namespace std;
int main() {
/* comment
cout<<"GFG!";
return 0;
}
This is a lexical error since the ending of comment “*/” is not present but the beginning is present.
4. Spelling Error
C++
#include <iostream>
using namespace std;
int main() {
int 3num= 1234;
return 0;
}
5. Replacing a character with an incorrect character.
C++
#include <iostream>
using namespace std;
int main() {
int x = 12$34;
return 0;
}
Other lexical errors include
6. Removal of the character that should be present.
C++
#include <iostream> /*missing 'o' character
hence lexical error*/
using namespace std;
int main() {
cout<<"GFG!";
return 0;
}
7. Transposition of two characters.
C++
#include <iostream>
using namespace std;
int main()
{
cout << "GFG!";
return 0;
}
Error Recovery Technique
When a situation arises in which the lexical analyzer is unable to proceed because none of the patterns for tokens matches any prefix of the remaining input. The simplest recovery strategy is “panic mode” recovery. We delete successive characters from the remaining input until the lexical analyzer can identify a well-formed token at the beginning of what input is left.
Error-recovery actions are:
- Transpose of two adjacent characters.
- Insert a missing character into the remaining input.
- Replace a character with another character.
- Delete one character from the remaining input.
В статье рассмотрены частые лексические ошибки в текстах на сайтах и указано несколько полезных ресурсов, которые помогут от них избавиться. Однако какими бы ни были сервисы проверок, они не могут мыслить как живой человек. Наш небольшой тест определит, насколько хорошо вы помните правила лексики русского языка.
- Примеры распространённых лексических ошибок
- Нарушение лексической сочетаемости слов
- Ошибки в похожих словах
- Ошибки в словах, выражающих отношение друг к другу
- Ошибки из-за невнимательности
- Онлайн-сервисы для проверки на лексические ошибки
- Словари сочетаемости
- 1. Gufo
- 2. КартаСлов.ру
- 3. Грамота.ру
- Сервисы поиска и исправления ошибок в тексте
- 4. Орфограммка
- 5. Текст.ру
- 6. LanguageTool
- 7. Тургенев
- 8. Главред
- Небольшой тест
- Выводы
Лексическая ошибка — это нарушение норм употребления слов, когда слова в предложении не согласуются по смыслу, стилистике или происхождению. Чаще всего такие ошибки связаны с неразграничением паронимов (например, представить/предоставить должность), синонимов (мне было печально/грустно) и близких по значению слов (обратно/снова прочитать книгу).
В среднем лексикон человека составляет 6000 слов. Причины их неправильного употребления часто кроются в отсутствии конкретного слова в активном словарном запасе автора или банальной невнимательности. Сегодня мы рассмотрим на примерах распространённые лексические ошибки в текстах на сайтах и приведём парочку полезных ресурсов. А в конце статьи желающие смогут пройти небольшую тестовую проверку на знание правил написания некоторых слов русского языка.
Примеры распространённых лексических ошибок
На изображении ниже представлены основные виды лексических речевых ошибок в русском языке и их типичные примеры.

Теперь разберём детальнее самые популярные из них.
Нарушение лексической сочетаемости слов
Русский язык богат на слова и словосочетания со схожими значениями, в которых легко запутаться. Употребление одного компонента в составе другой фразы и приводит к речевым ошибкам, связанным с нарушением лексической сочетаемости слов.
Типичным примером таких ошибок являются фразы:
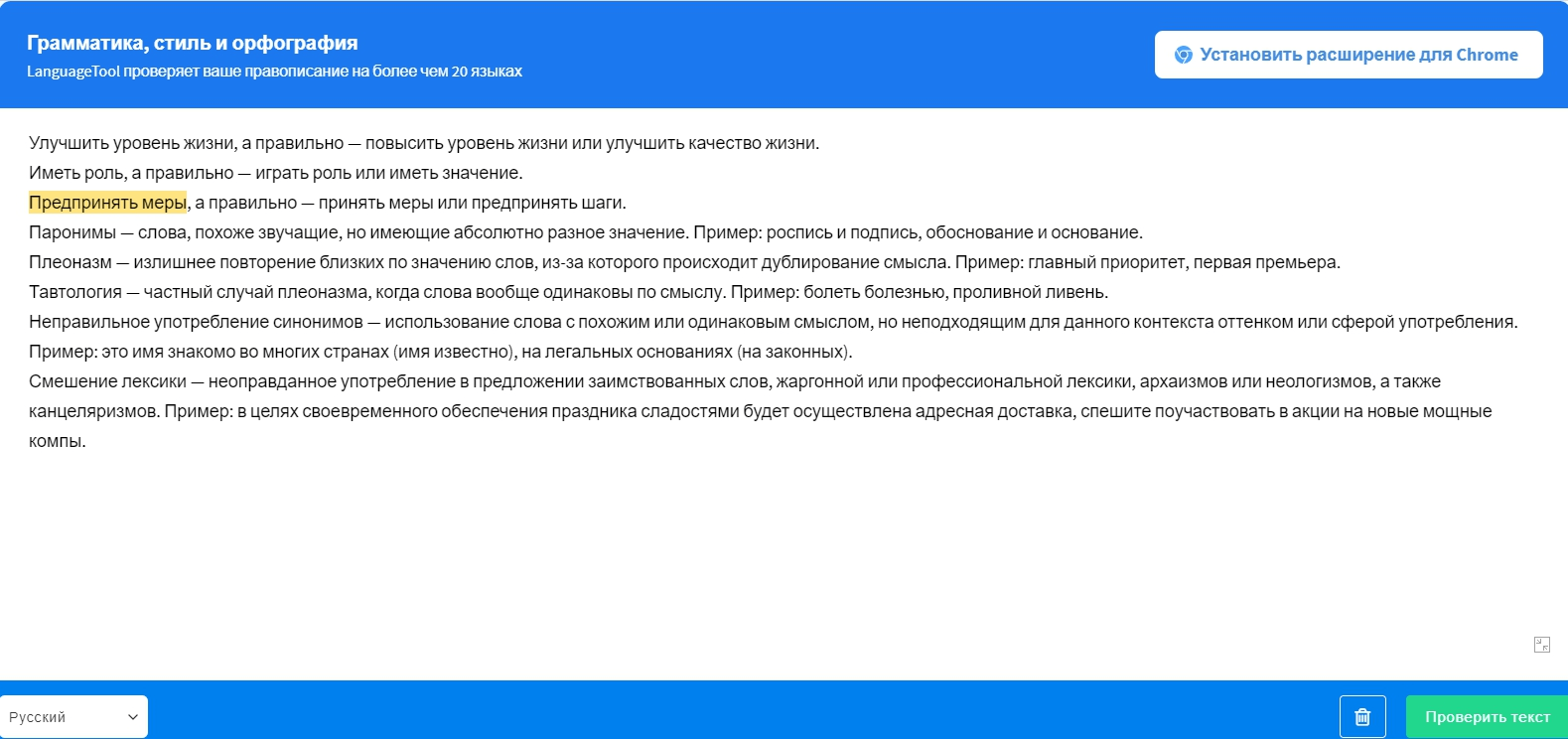
- Улучшить уровень жизни, а правильно — повысить уровень жизни или улучшить качество жизни.
- Иметь роль, а правильно — играть роль или иметь значение.
- Предпринять меры, а правильно — принять меры или предпринять шаги.
Что касается практики, то часто на сайтах интернет-магазинов можно встретить словосочетания, значение которых противоречит общей логике повествования. Приведём несколько примеров:
- Слово «прейскурант» уже содержит понятие стоимости услуг, слово «цен» лишнее.
![]()
- Глагол «одолжить» обозначает «дать в долг», а не «занять».

- Цены могут быть низкими или высокими, товары – дорогими или дешёвыми.
![]()
- «Изобрести» – это открыть то, чего не было ранее. Употреблять это слово следует лишь для обозначения чего-либо нового.

Ошибки в похожих словах
Один из самых частых типов лексических речевых ошибок — неправильное употребление похожих по смыслу или звучанию слов. Среди них встречаются:
- Паронимы — слова, похоже звучащие, но имеющие абсолютно разное значение. Пример: роспись и подпись, обоснование и основание.
- Плеоназм — избыточное повторение близких по значению слов, из-за которого происходит дублирование смысла. Пример: главный приоритет, первая премьера.
- Тавтология — частный случай плеоназма, когда слова вообще одинаковы по смыслу. Пример: болеть болезнью, проливной ливень.
- Неправильное употребление синонимов — использование слова с похожим или одинаковым смыслом, но неподходящим для данного контекста оттенком или сферой употребления. Пример: это имя знакомо во многих странах (имя известно), на легальных основаниях (на законных).
- Смешение лексики — неоправданное употребление в предложении заимствованных слов, жаргонной или профессиональной лексики, архаизмов или неологизмов, а также канцеляризмов. Пример: в целях своевременного обеспечения праздника сладостями будет осуществлена адресная доставка, спешите поучаствовать в акции на новые мощные компы.
Некоторые из этих нарушений встречаются так часто, что даже стали мемами.
- Одна из самых распространённых пар – слова «одеть» и «надеть».
Не запутаться помогает поговорка «Надевают одежду, одевают Надежду»: одевать правильно кого-то, а надевать – что-то.

Неправильно:

Правильно:


- Неправильное употребление также часто встречается в паре «эффектный/эффективный».
«Эффектный» – производящий впечатление, а «эффективный» – приводящий к нужному результату.
Неправильно:

Правильно:

Ошибки в словах, выражающих отношение друг к другу
Лексические единицы, отображающие отношение слов друг к другу, называют гиперонимами (обозначают более общее родовое понятие) и гипонимами (когда говорят о более частном понятии). Например, гиперонимом по отношению к слову «стол» будет «мебель», к слову «роза» – «цветок».
![]()
С точки зрения логики, это предложение построено неправильно, т. к. туфли – это и есть обувь.
Ошибки из-за невнимательности
Часто авторы попросту не перечитывают написанное, и в результате получается нелепица. Вот два забавных примера:
- «Здесь службы ЖКХ для обеспечения безопасного движения обрабатывают лёд специальными химиками» – Вот он, секрет безопасного движения.
- «В этом случае сайт может по долгу быть за пределами ТОПа» – Наверное, по долгу чести.
Онлайн-сервисы для проверки на лексические ошибки
Приведённые сервисы не новы – они лишь популярнее других ресурсов, используемых нами. Ниже вкратце расскажем почему.
Словари сочетаемости
По словарям обычно проверяется сочетаемость слов и подбираются более подходящие синонимы.
1. Gufo
Gufo.me — на этом ресурсе можно быстро найти любой словарь, в том числе и словарь синонимов.
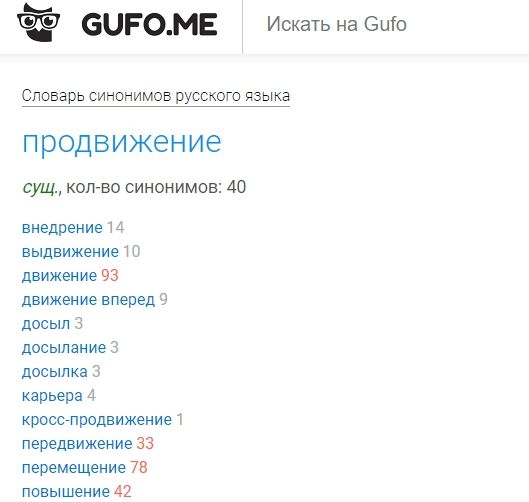
Основное достоинство – выбрав, например, слово в том же словаре синонимов, ресурс сразу покажет это слово и в других словарях:

2. КартаСлов.ру
Kartaslov.ru — онлайн-словарь связей слов и выражений, в том числе есть ассоциации, синонимы и лексическая сочетаемость слов русского языка. В нём удобно проверять устойчивые фразы.

Сервис, кроме традиционных источников информации в виде словарей, использует алгоритмы машинного обучения и искусственный интеллект. Есть достаточно обширная база контекстов употребления слов.

3. Грамота.ру
Gramota.ru — главный интернет-просветитель по русскому языку.
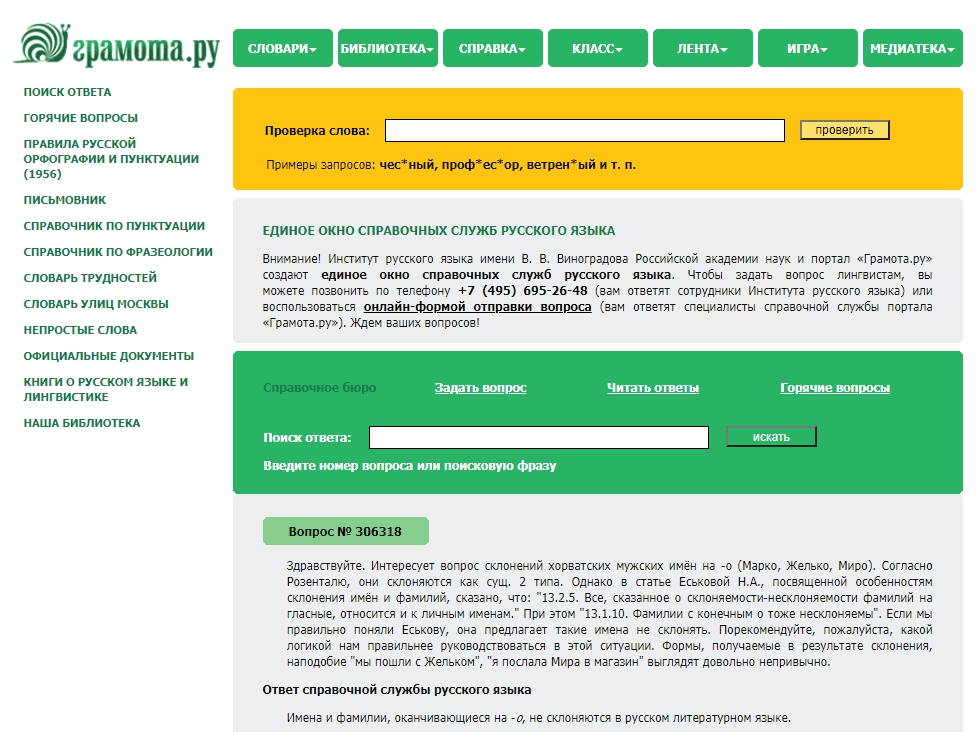
Наряду с официальными учебными пособиями, здесь есть ответы на тысячи вопросов от «справочной службы русского языка», а также задания для тренировки грамотности.
Сервисы поиска и исправления ошибок в тексте
Далее перечислим непосредственно программы, с помощью которых можно найти лексические ошибки в готовом тексте. Для этого протестируем их на примерах, упомянутых выше, а также специально составленном с лексическими ошибками проверочном тексте:
Костёр всё больше и больше распалялся, пылал. Туристы были заняты своими занятиями. Благодаря пожару, вспыхнувшему от костра, сгорел большой участок леса. Всё, что осталось от могучих деревьев — тлеющие головашки. Пожарный подошёл к одинокому мальчику, он был невысокого роста, и вручил свежую одежду. Мальчик сразу же одел новую рубашку и штаны. В октябре месяце уже обычно холодно, но сейчас раскалённая земля ещё держала зной.
4. Орфограммка
Orfogrammka.ru — по нашему опыту, лучший онлайн-сервис для исправления ошибок в тексте (особенно лексических), так как он находит больше всего несоответствий и даёт подробные пояснения к каждому из них.
Сервис платный, минимальный пакет — 100 рублей за 100 000 знаков.
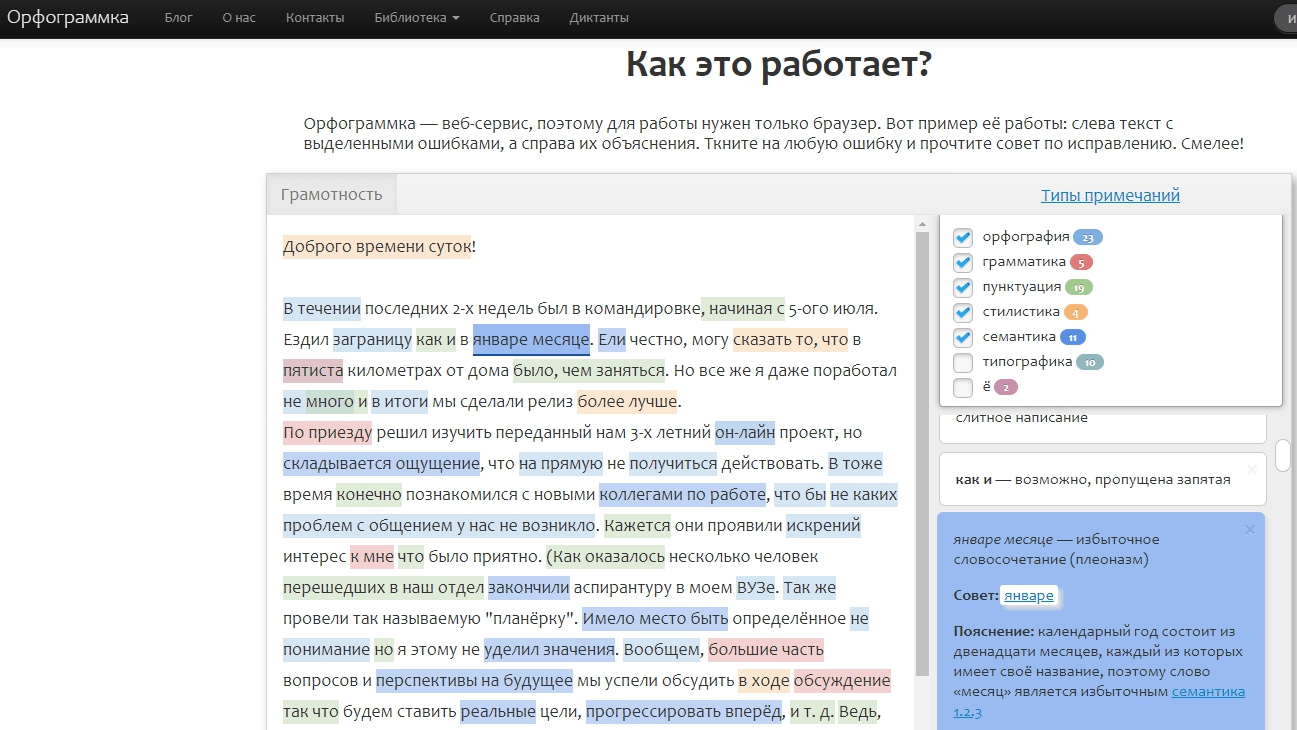
Он экономит много времени редакторам и имеет широкий функционал для проверки текста по многим направлениям:
- Грамотность — для исправления всех видов ошибок.
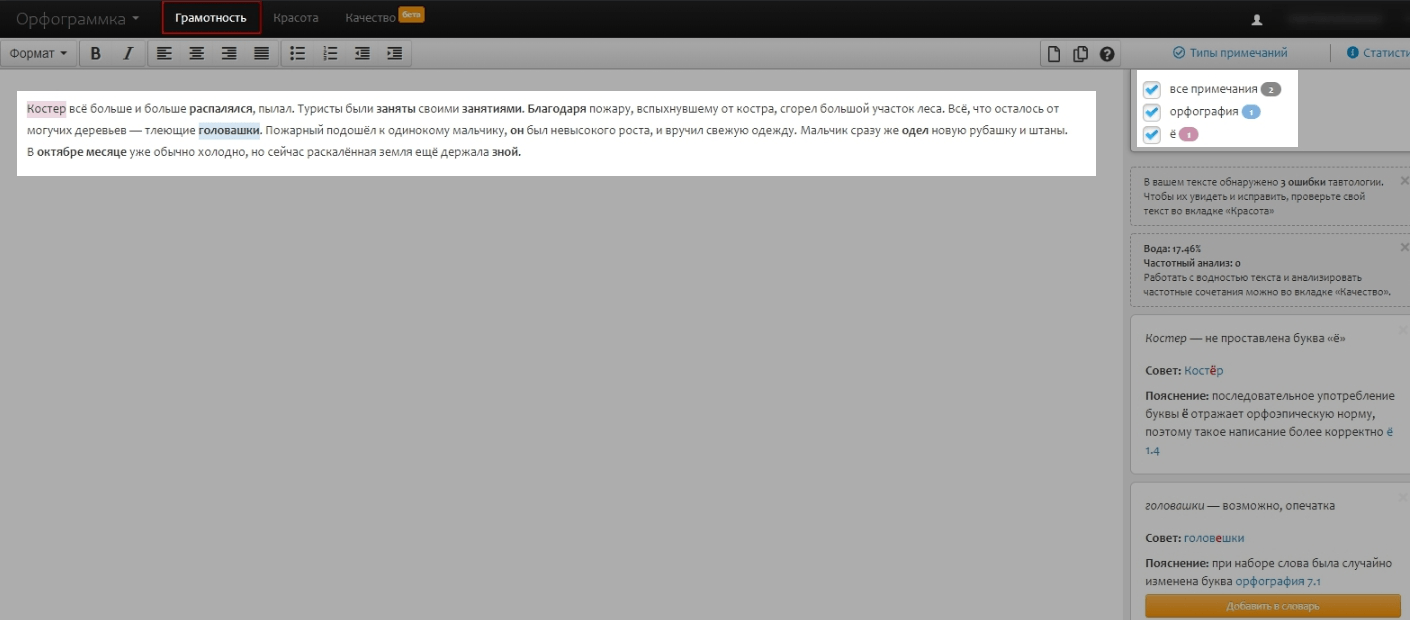
- Красота — для подбора благозвучных слов, синонимов и эпитетов. На этой вкладке устраняется тавтология, так что можно считать её наиболее подходящей для проверки лексики.
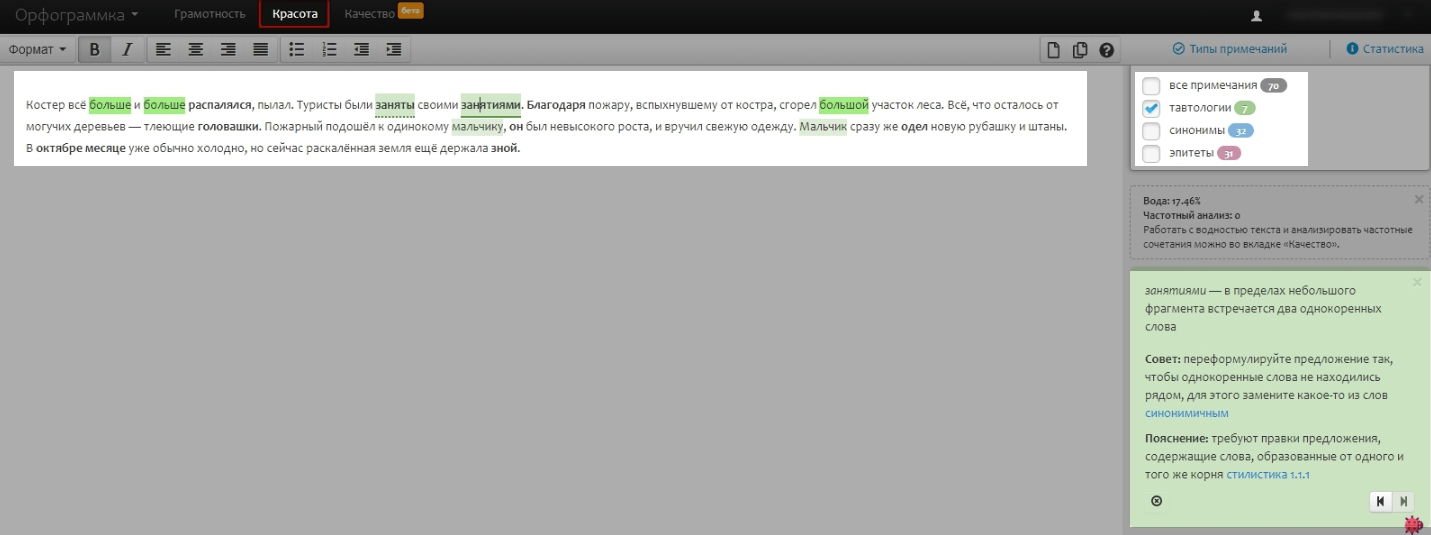
- Качество — оценивает SEO-параметры: воду, частотные и неестественные сочетания.
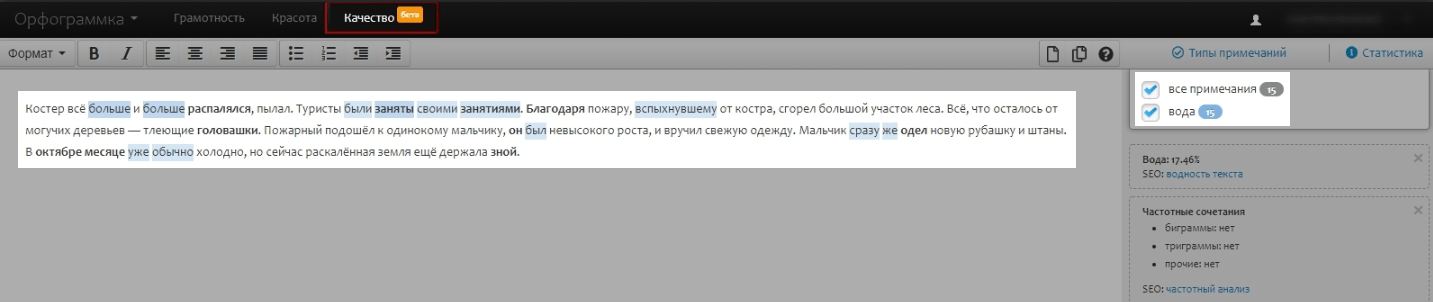
В нашем хитром тексте Орфограммка нашла только 2 лексические ошибки из 9, но при проверке примеров, которые мы упоминали выше, сервис обнаружил 7 ошибок — в целом он неплохо умеет с ними справляться.
5. Текст.ру
Text.ru — условно-бесплатный сервис для онлайн-проверки, придёт на помощь не только в лексике. Позволяет найти орфографические, пунктуационные и некоторые лексические ошибки в предложениях.
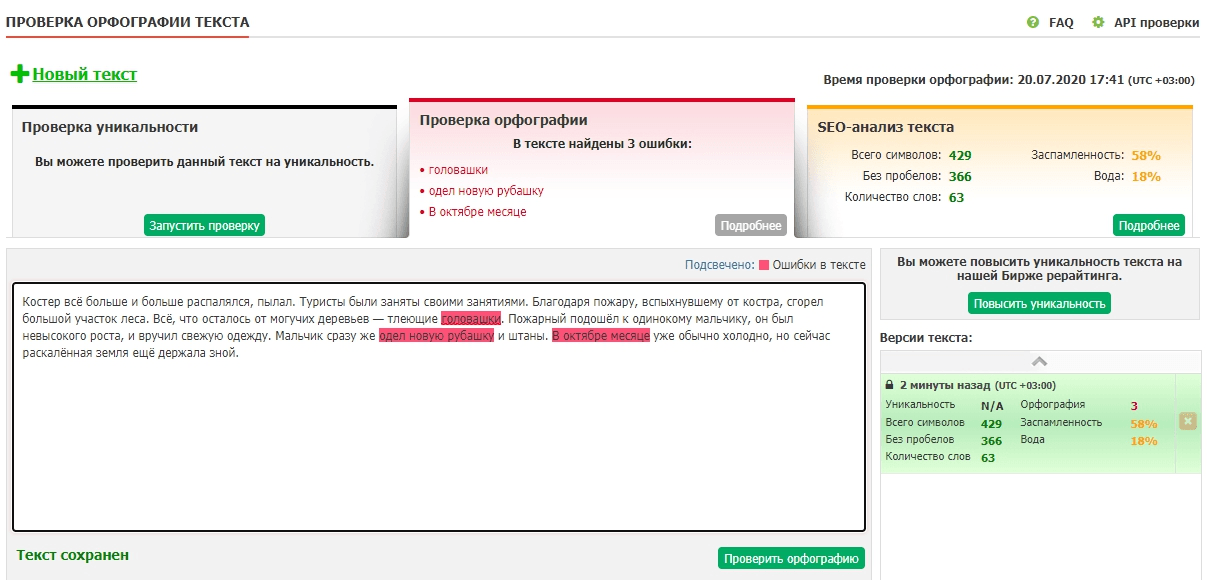
В проверочном тексте найдено 3 из 9 — что уже лучше, но всё-таки сервис заточен на орфографию. В других предложениях text.ru нашёл только одно нарушение.
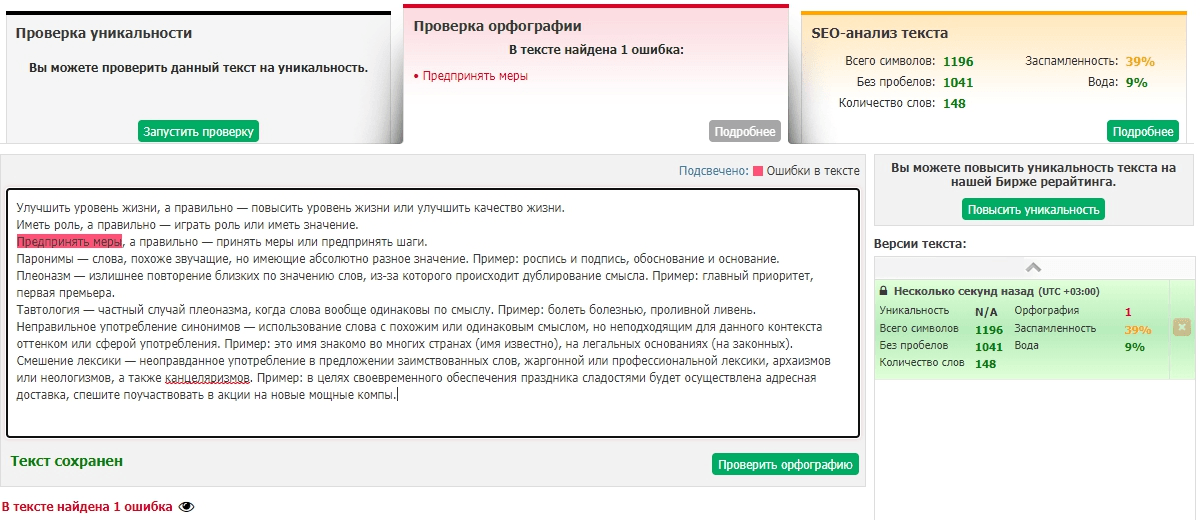
Зато иногда Word ошибается в пунктуации:

А Advego – в согласовании числительного и существительного:
У text.ru таких грехов нет.

В целом для проверки лексики его применять можно, но с осторожностью. Мы его чаще всего используем, когда нужно узнать уникальность текста.
6. LanguageTool
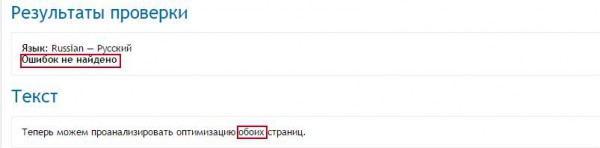
Languagetool.org — многоязыковой бесплатный онлайн-сервис для исправления грамматики, орфографии и речевых ошибок в тексте. Есть расширение для Chrome, которое позволяет находить ошибки в текстах прямо на сайте.
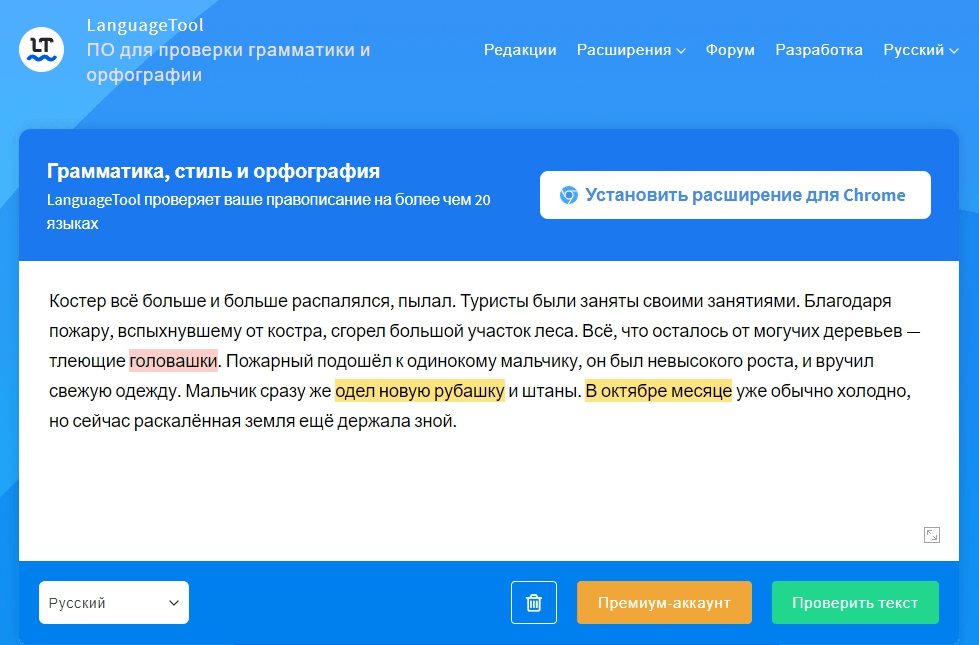
Данный сервис определил 3 из 9 лексических ошибок в первом примере, а во втором — лишь одну. Результат такой же, как у text.ru.
Но LanguageTool удобен тем, что к каждому выделению есть комментарии, примеры, а также возможность настройки под себя.
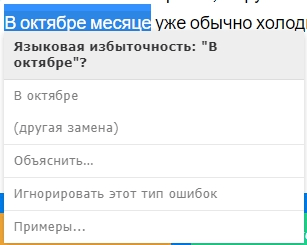
7. Тургенев
Turgenev.ashmanov.com — сервис, известный SEO-специалистам, так как умеет проверять текст на «Баден-Баден» (хотя если страница всё же просела, то нет более верного способа, чем проверка вручную).
Но Тургенев также неплохо показывает стилистические ошибки в предложениях, тем более что вкладка «стилистика» бесплатна.
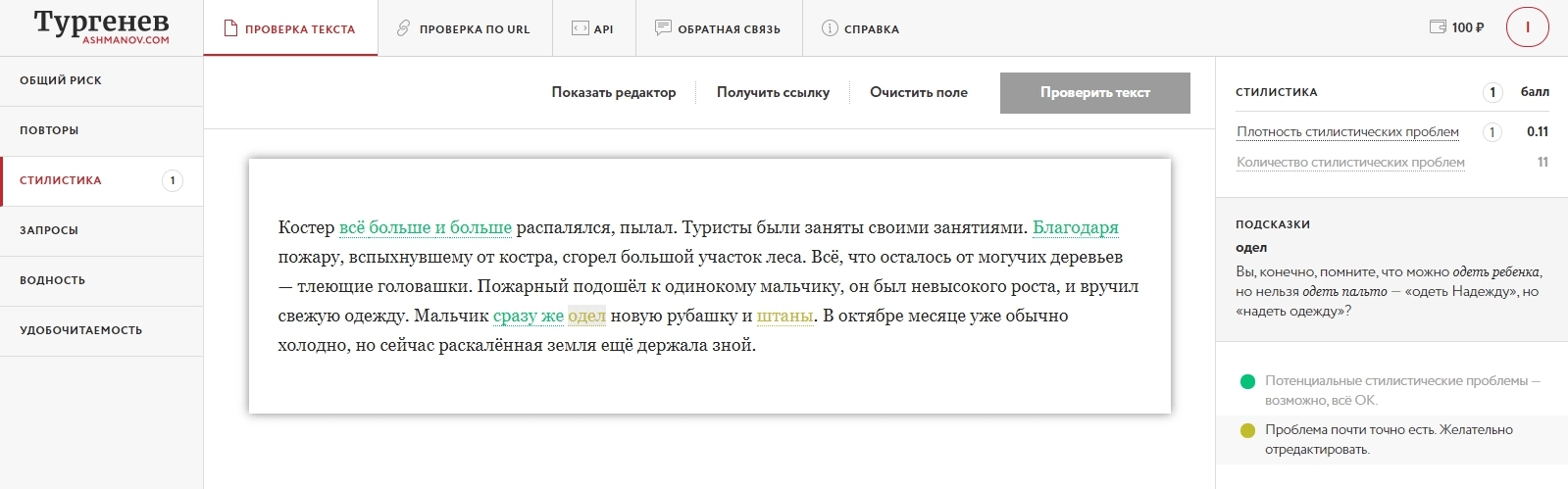
В нашем проверочном тексте Тургенев распознал 2 нарушения лексических норм из 9, а в других примерах предложений тоже 2 (одна из которых канцеляризм).

8. Главред
Glvrd.ru — очень полезный ресурс, помогает избавить текст от водянистых конструкций и стилистических ошибок.
Однако будьте осторожны – порой он не распознаёт термины и ругается на ключевые слова (а они в некоторых нишах обязательны).
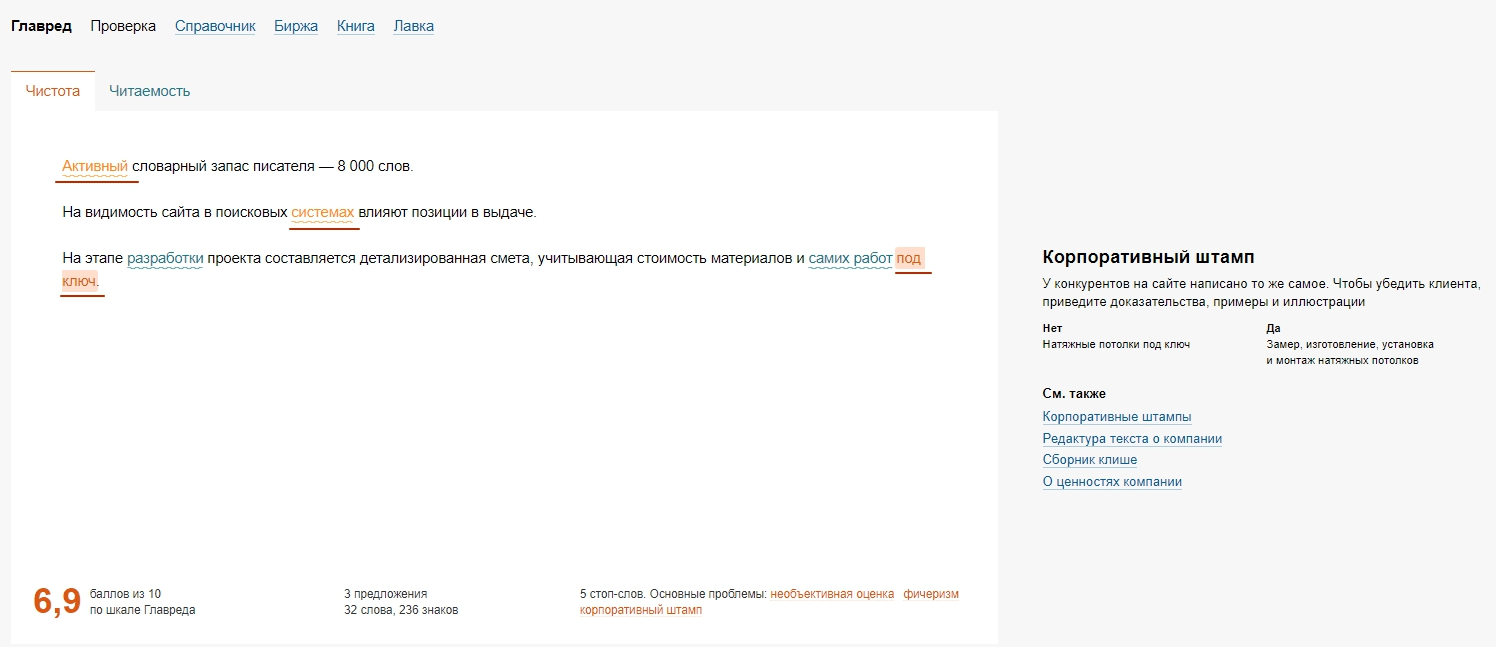
Он вовсе не распознал лексические ошибки в проверочном тексте.
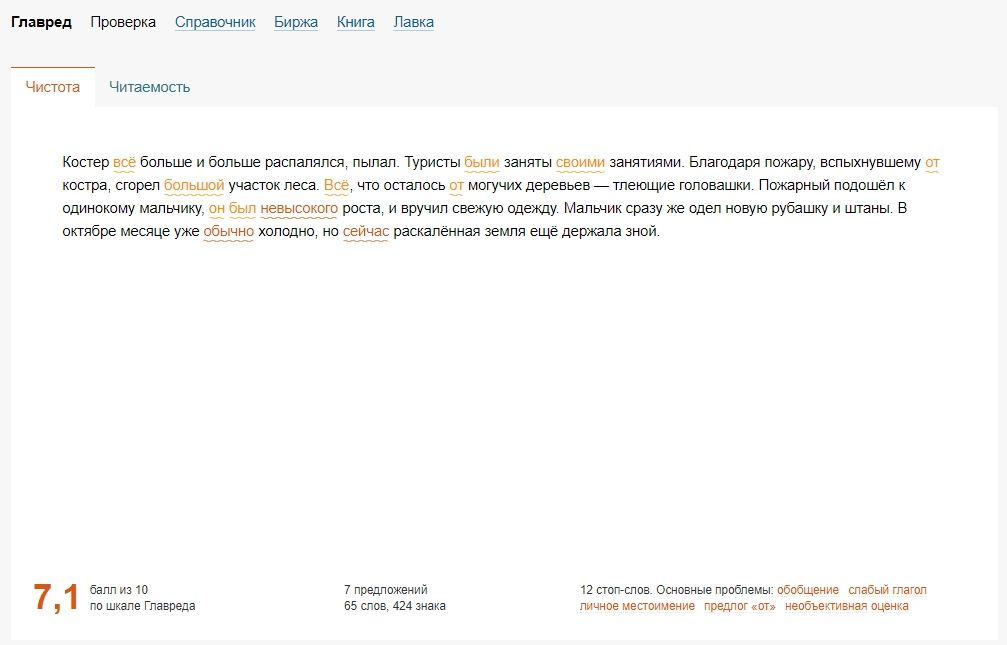
А в примерах предложений заметил только канцеляризм.
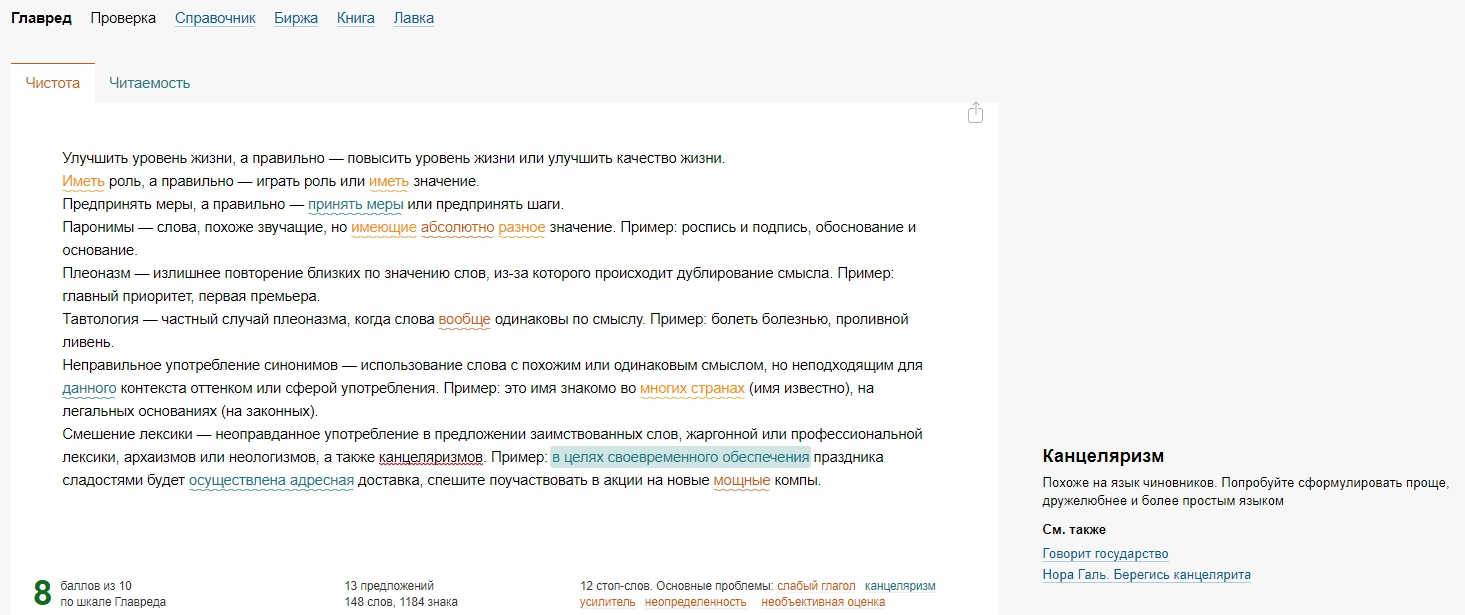
Хотя Главред больше подходит для улучшения читаемости и красоты текста, чем для поиска конкретных ошибок, его всё ещё полезно использовать для чистки лексики от лишних конструкций.
Небольшой тест
Наша маленькая тестовая проверка поможет узнать, насколько хорошо вы помните нормы русского языка.
Выводы
Используя онлайн-сервисы, помните о том, что каким бы ни был ресурс – это алгоритм, который не всегда правильно оценивает контекст и не может мыслить так, как мыслит человек. Вычитку текстов на сайтах лучше доверить живым людям.
Приведённые выше сервисы помогут вам с лексикой текстов на сайте – по ним можно узнать значение конкретного слова, проверить текст на «воду» и т. п.
Еще по теме:
- Как составить ТЗ копирайтеру? 7 ключевых пунктов
- Лето, тексты, вода: Как убрать из текста «воду» и чем ее заменить
- Как составить ТЗ копирайтеру, чтобы статья попала в ТОП без ссылок?
- Программа VS плагиат. Видят ли антиплагиаторы смысловую неуникальность?
- Как писать SEO-тексты для людей, которые полюбит Яндекс?
Текстовый контент на сайте – одна из важных составляющих успешного продвижения. Конечно, желательно писать тексты самостоятельно, но у одних нет времени, у других – желания,…
Мы часто говорим, что текст не должен содержать «воду», но не разбираем этот вопрос подробно. В этой статье на примерах конкретной тематики рассмотрим, что такое…
Вопрос о том, как готовить качественные статьи, приносящие позиции и поисковый трафик, уже давно волнует контент-проекты и коммерческие сайты с инфоразделами. Случаи, когда статьи по…
Сегодня текстовый контент на сайте в первую очередь ценится за смысловую уникальность. Могут ли программы и сервисы проверки текстов (антиплагиаторы) «увидеть» не только техническую неуникальность,…
SEO-тексты – тексты, ориентированные, в первую очередь, на поисковые алгоритмы, а не на людей. Обычно они малоинформативны, содержат неестественные речевые обороты, избыточные повторы ключевых фраз….
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.
for our compiler theory class, we are tasked with creating a simple interpreter for our own designed programming language. I am using jflex and cup as my generators but i’m a bit stuck with what a lexical error is. Also, is it recommended that i use the state feature of jflex? it feels wrong as it seems like the parser is better suited to handling that aspect. and do you recommend any other tools to create the language. I’m sorry if i’m impatient but it’s due on tuesday.
asked Aug 14, 2010 at 18:57
![]()
A lexical error is any input that can be rejected by the lexer. This generally results from token recognition falling off the end of the rules you’ve defined. For example (in no particular syntax):
[0-9]+ ===> NUMBER token
[a-zA-Z] ===> LETTERS token
anything else ===> error!
If you think about a lexer as a finite state machine that accepts valid input strings, then errors are going to be any input strings that do not result in that finite state machine reaching an accepting state.
The rest of your question was rather unclear to me. If you already have some tools you are using, then perhaps you’re best to learn how to achieve what you want to achieve using those tools (I have no experience with either of the tools you mentioned).
EDIT: Having re-read your question, there’s a second part I can answer. It is possible that a language could have no lexical errors — it’s the language in which any input string at all is valid input.
answered Aug 14, 2010 at 23:41
![]()
GianGian
13.6k44 silver badges51 bronze badges
A lexical error could be an invalid or unacceptable character by the language, like ‘@’ which is rejected as a lexical error for identifiers in Java (it’s reserved).
Lexical errors are the errors thrown by your lexer when unable to continue. Which means that there’s no way to recognise a lexeme as a valid token for you lexer. Syntax errors, on the other side, will be thrown by your scanner when a given set of already recognised valid tokens don’t match any of the right sides of your grammar rules.
it feels wrong as it seems like the
parser is better suited to handling
that aspect
No. It seems because context-free languages include regular languages (meaning than a parser can do the work of a lexer). But consider than a parser is a stack automata, and you will be employing extra computer resources (the stack) to recognise something that doesn’t require a stack to be recognised (a regular expression). That would be a suboptimal solution.
NOTE: by regular expression, I mean… regular expression in the Chomsky Hierarchy sense, not a java.util.regex.* class.
answered Oct 6, 2010 at 21:08
![]()
Martín SchonakerMartín Schonaker
7,2444 gold badges31 silver badges55 bronze badges
3
lexical error is when the input doesn’t belong to any of these lists:
key words: "if", "else", "main"...
symbols: '=','+',';'...
double symbols: ">=", "<=", "!=", "++"
variables: [a-z/A-Z]+[0-9]*
numbers: [0-9]*
examples: 9var: error, number before characters, not a variable and not a key word either.
$: error
what I don’t know is whether something like more than one symbol after each other is accepted, like «+-«
answered Nov 8, 2013 at 18:05
![]()
0
Compiler can catch an error when it has the grammar in it!
It will depend on the compiler itself whether it has the capacity (scope) of catching the lexical errors or not.
If is decided during the development of compiler what types of lexical error and how (according to the grammar) they are going to be handled.
Usually all famous and mostly used compiler has this capabilities.
answered Sep 27, 2014 at 2:55
![]()
Asked by: Mr. Emmanuel Ledner
Score: 4.4/5
(65 votes)
A lexical error is any input that can be rejected by the lexer
lexer
Tokenization is the process of demarcating and possibly classifying sections of a string of input characters. The resulting tokens are then passed on to some other form of processing. The process can be considered a sub-task of parsing input.
. This generally results from token recognition falling off the end of the rules you’ve defined.
What is a lexical error in grammar?
Lexical errors, on the other hand, are mistakes at the word level, which include, for example, choosing the wrong word for the meaning the user wants to express. Inappropriate lexical choices may lead to misunderstanding of the message.
What are examples of semantic error?
«Semantic error» is another term for «logic error», where you literally write the wrong code. For example, writing n3=n1*n2 when really you wanted to divide — the compiler has no way to tell that your algorithm should have divided instead of multiplying; you told it to multiply, so it does.
What are the syntactic errors?
Syntactic errors consisted of a violation of very basic grammatical rules such as number congruency between noun, adjective, and verb or changes in the appropriate word order (see Table 1). …
What is a Lexis error?
With regard to semantic errors in lexis, there are two main types: confusion of sense relations (a word being used in contexts where a similar word should be used) and collocational errors (the choice of a word to accompany another is inappropriate).
44 related questions found
What is syntactic error in English language?
The common syntactic errors are incomplete sentence structure, subject verb agreement error, improper use of conjunctions, prepositions, articles, etc. Researchers have identified that Arab university students’ lack the required English language proficiency that thwarts their academic progress.
What is the difference between lexical errors and syntax errors?
Answer: A lexical error occurs when the compiler does not recognize a sequence of characters as a proper lexical token. 2ab is not a valid C token. … A syntax error occurs when a sequence of tokens does not match a C construction: statement, expression, preprocessing directive…
What are lexical errors in linguistics?
Lexical errors are categorized under this type of error when a lexical item used in a sentence does not suit or collocate with another part of the sentence, these items sound unnatural or inappropriate.
What are syntactic and semantic errors?
Syntax errors and «semantic» errors are not the same. The syntax error is an incorrect construction of the source code, whereas a semantic error is erroneous logic that produces the wrong result when executed.
What are the three main syntactic error types?
No matter how smart or how careful you are, errors are your constant companion. With practice, you will get slightly better at not making errors, and much, much better at finding and correcting them. There are three kinds of errors: syntax errors, runtime errors, and logic errors.
What are examples of semantics?
semantics Add to list Share. Semantics is the study of meaning in language. It can be applied to entire texts or to single words. For example, «destination» and «last stop» technically mean the same thing, but students of semantics analyze their subtle shades of meaning.
What is logical error example?
A logic error (or logical error) is a mistake in a program’s source code that results in incorrect or unexpected behavior. … For example, assigning a value to the wrong variable may cause a series of unexpected program errors. Multiplying two numbers instead of adding them together may also produce unwanted results.
What is an example of a runtime error?
A runtime error is a program error that occurs while the program is running. … Crashes can be caused by memory leaks or other programming errors. Common examples include dividing by zero, referencing missing files, calling invalid functions, or not handling certain input correctly.
What Is syntax error example?
Syntax errors are mistakes in using the language. Examples of syntax errors are missing a comma or a quotation mark, or misspelling a word. MATLAB itself will flag syntax errors and give an error message. … Another common mistake is to spell a variable name incorrectly; MATLAB will also catch this error.
What are grammar errors?
Grammatical errors refer to the incorrect use of the normative rules for constructing a sentence. Common grammatical errors include word order, tense, point of view, and number. Explore the difference between grammar and mechanics, and how to avoid common grammatical errors.
What are structure errors in a sentence?
Students commonly make three kinds of sentence structure errors: fragments, run-ons, and comma splices. 1) Fragments: Fragments are incomplete sentences. Very often, they consist of a subject without the predicate. Example: The child who has a rash.
What is syntactic and semantic?
Syntactic & Semantic Analysis. … Syntax is the grammatical structure of the text, whereas semantics is the meaning being conveyed. A sentence that is syntactically correct, however, is not always semantically correct.
What are semantic errors in C++?
A semantic error occurs when a statement is syntactically valid, but does not do what the programmer intended.
What are semantic errors in speech?
make semantic errors or substitutions, e.g. calling a “dog” a “cat” or a “spoon” a “fork”; make phonological (sound) errors, e.g. “I want to play in the part” or “I don’t speak Fretch”; and. say “I don’t know” when they can’t think of a name, even if they probably know the answer.
What are the common types of errors encountered by the programmer?
Here are the 7 most commonly encountered programming errors:
- Runtime errors.
- Logic errors.
- Compilation errors.
- Syntax errors.
- Interface errors.
- Resource errors.
- Arithmetic errors.
What is an error in C++?
Error is an illegal operation performed by the user which results in abnormal working of the program. Programming errors often remain undetected until the program is compiled or executed. Some of the errors inhibit the program from getting compiled or executed.
What is syntactic error in compiler design?
In computer science, a syntax error is an error in the syntax of a sequence of characters or tokens that is intended to be written in compile-time. A program will not compile until all syntax errors are corrected. … A syntax error may also occur when an invalid equation is entered into a calculator.
What is the difference between semantic error and logical error?
Semantic error is related to the meaning of something. … and the logical error is that Errors that indicate the logic used when coding the program failed to solve the problem. The logic error will not cause the program to stop working but our desired result will not be get.
What is a static semantic error?
Static Semantics: Whether syntactically valid statements have any meaning. for example: “I are big”… the syntax is correct, but there’s a static semantic error that we know as grammatical error. Similarly 3/’three’ is a static semantic error in Python because int 3 is being divided by string ‘three’
What are the main syntactic error types?
Result of the study revealed that concord in auxiliaries, SVO pattern, articles, prepositions and tenses are the major types of syntactic errors, where as affixation and compound related errors, failure to use the marker (-er) and conversion related errors are the major types of morphological errors.
вернуться на страницу «Культура речи«, «Таблицы«, «Лексика в таблицах«, «Лексический разбор«, на главную
Лексические нормы языка – это нормы словоупотребления. Выбирая слова, мы должны обращать внимание на их значение, стилистическую окраску, употребительность, сочетаемость с другими словами. Игнорирование хотя бы одного из этих критериев может привести к нарушению точности речи.
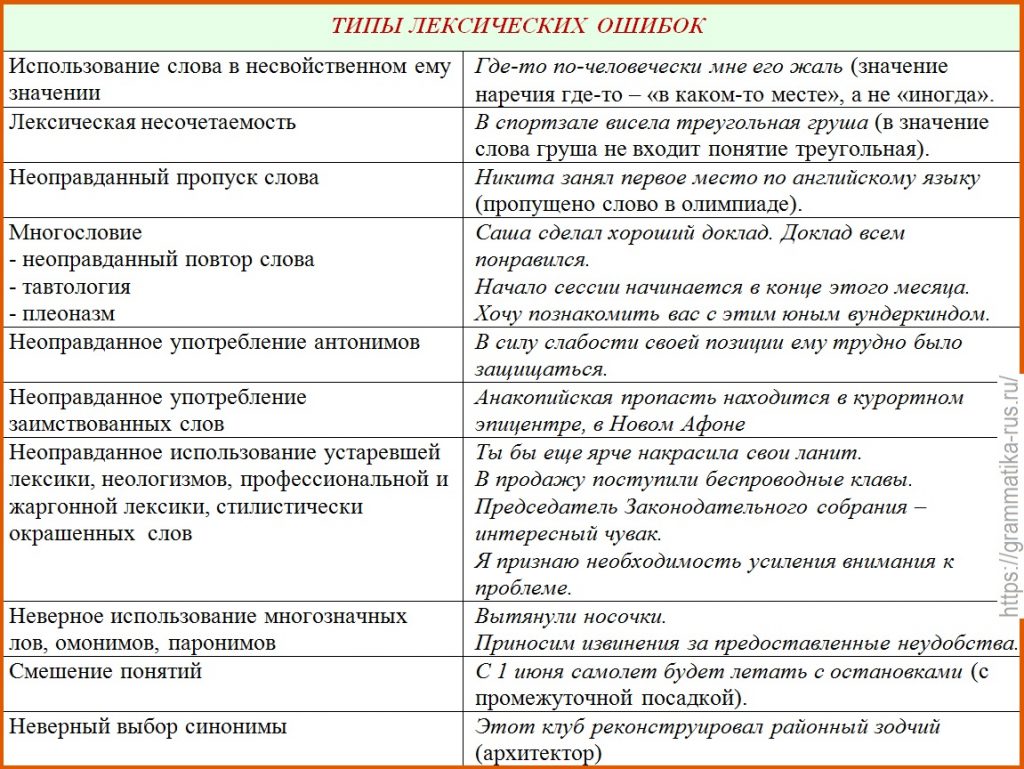
ВИДЫ ЛЕКСИЧЕСКИХ ОШИБОК
- Смешение слов, близких по значению: крайний и последний, любить и уважать, спать и отдыхать.
- Смешение слов, близких по звучанию: индейка – индианка.
- Смешение слов, близких по значению и по звучанию (паронимов):командировочный – командированный.
- Словосочинительство (словотворчество) – замена «законной» морфемы синонимичной «незаконной»: благородность(благородство), волнительный(волнующий).
- Нарушение правил семантического (смыслового) согласования слов: Я поднимаю тост (поднимать – «перемещать куда-либо наверх», тост – «застольное пожелание чего-либо, здравица»).
- Плеоназмы (от греческого pleonasmos – переизбыток) – словосочетания, в которых значение одного компонента (слова) полностью входит в значение другого (смысловое дублирование): март месяц, лично я (ты, он).
- Тавтология (от греческих tauto– то же самое и logos – слово) – крайняя форма, разновидность плеоназма, дублирование и на уровне содержания, и на уровне формы: проливной ливень, гостеприимно приняли. Тавтологию не следует смешивать с повторами. Тавтология – это словосочетание, состоящее из двух однокоренных слов (заданное задание), а повторы – это многократное использование на небольшом отрезке речи одного и того же слова, словоформы, фразеологизма: Язаписал задание. Придя домой, я стал выполнять задание.
- Неустраненная (неснятая) многозначность, порождающая двоякое осмысление высказывания: Ты ужеотходишь? (выздоравливаешь или умираешь?).
- Лексические анахронизмы – слова, не соответствующие изображаемой (описываемой) эпохе: Анна Павловна Шерер часто устраивала в своем доме дискотеки;
К лексическим ошибкам следует отнести и употребление в речи слов-сорняков (паразитов), поскольку они не несут никакой смысловой нагрузки, т.е. семантически опустошенных слов, засоряющих речь и затрудняющих ее понимание: как бы, ну, это, это самое, так сказать, как говорится и др.
РАСПРОСТРАНЕННЫЕ ЛЕКСИЧЕСКИЕ ОШИБКИ
Нарушение лексической сочетаемости слов: Снижается уровень жизни народа (а не ухудшается). Ухудшается состояние/ситуация, а уровень снижается/повышается.
Употребление «роспись и число» вместо «подпись и дата»: Вот такое письмо мы получили, а в конце его подпись и дата» (а не «роспись и число»). Роспись – это живопись на стенах. В документе фиксируется дата, то есть число, месяц и год его оформления.
Употребление слова «обратно» вместо «снова», «опять»: Рижский вокзал надо переименовать снова = опять (а не обратно = назад, в обратном направлении). Наречие «обратно» не является синонимом наречий «снова», «опять».
Лексическая избыточность: Отличившиеся в этой операции получили государственные награды (а не «награждены наградами»). Плеоназм и тавтология — повтор в иной форме ранее сказанного или повторение одного и того же определения другими словами.
Кроме нарушения лексической совместимости, к распространенным лексическим ошибкам относится
— смешение паронимов (роспись — подпись),
— использование слова в несвойственном ему значении («обратно» вместо «опять», «снова»)
— лексическая избыточность тавтология, плеоназм
— употребление слова иной стилевой окраски
— смешение лексики разных исторических эпох.


Остались вопросы — задай в обсуждениях https://vk.com/board41801109
Усвоил тему — поделись с друзьями.
Тест на тему Лексические нормы
Тест на тему Использование слова в несвойственном ему значении
Тест на тему Ошибки в сочетаемости слов
Тест на тему Ошибки, связанные с употреблением паронимов
Тест на тему Ошибки тавтология и плеоназм
Тест на тему Ошибки при использовании фразеологизмов
#обсуждения_русский_язык_без_проблем
вернуться на страницу «Культура речи«, «Таблицы«, «Лексика в таблицах«, «Лексический разбор«, на главную
Виды лексических ошибок
1. Смешение слов,
близких по значению: крайний
и последний,
любить
и уважать,
спать
и отдыхать,
профессия и
специальность,
новорождённый
и именинник,
учитель
и преподаватель,
годовщина
и юбилей.
2. Смешение слов,
близких по звучанию:
индейка – индианка, одинарный –
ординарный, экскаватор – эскалатор,
декрет – кредит, фауна – флора, Австрия
– Австралия,
Швеция – Швейцария, нотариальная
(контора) – натуральная и
т.д.
3. Смешение слов,
близких по значению и по звучанию
(паронимов):
командировочный – командированный,
дипломат – дипломант, одеть – надеть,
представить – предоставить, главный –
заглавный, сытый – сытный, невежа –
невежда, туристский – туристический и
т.д.
4. Словосочинительство
(словотворчество) – замена «законной»
морфемы синонимичной «незаконной»:
грузинец
(грузин),
благородность
(благородство), волнительный
(волнующий), плагиаторство
(плагиат), нервенный
(нервный) и
т.д.
5. Нарушение правил
семантического (смыслового) согласования
слов: Я поднимаю
тост (поднимать
– «перемещать куда-либо наверх», тост
– «застольное пожелание чего-либо,
здравица»); Живописца поразила поза
её лица;
Базаров отрастил
длинные волосы и красные обветренные
руки;
большая
половина и
т.д.
6. Плеоназмы (от
греческого pleonasmos
– переизбыток)
– словосочетания, в которых значение
одного компонента (слова) полностью
входит в значение другого (смысловое
дублирование): март
месяц, лично я (ты, он), период времени,
прейскурант цен, адрес местожительства,
основной костяк, памятные сувениры,
мемориальный памятник, народный фольклор,
свободная вакансия, внутренний интерьер,
продолжай дальше, вдруг неожиданно,
очень сильно
и т.п.
7. Тавтология (от
греческих tauto
– то же самое и logos
– слово) – крайняя форма, разновидность
плеоназма – непреднамеренное употребление
в пределах фразы однокоренных слов;
более грубая ошибка, так как происходит
дублирование и на уровне содержания, и
на уровне формы: проливной
ливень, гостеприимно приняли, соединить
воедино, вновь возобновить, бездонная
бездна, заданное задание
и т.п. Тавтологию не следует смешивать
с повторами. Тавтология
– это
словосочетание, состоящее из двух
однокоренных слов (заданное
задание), а
повторы –
это многократное использование на
небольшом отрезке речи одного и того
же слова, словоформы, фразеологизма: Я
записал задание.
Придя домой, я
стал выполнять
задание. Я
легко справился с этим заданием.
Повторы создают однообразие речи, т.е.
делают ее бедной, следовательно, это не
лексическая, а стилистическая ошибка
– нарушение принципа богатства речи.
Далеко не все плеоназмы и тавтологии
являются нарушением нормы (см.: Аникин,
А.И. Употребление
однокоренных слов в предложении. – М.,
1965).
8. Неустраненная
(неснятая) многозначность, порождающая
двоякое осмысление высказывания: Это
предложение следует оставить
(сохранить или отбросить?); Ты уже
отходишь?
(выздоравливаешь или умираешь?); Студенты
разбирают книги
(перебирают или берут себе?) и т.п.
9. Лексические
анахронизмы – слова, не соответствующие
изображаемой (описываемой) эпохе: Анна
Павловна Шерер часто устраивала в своем
доме дискотеки;
Герасим
уволился по собственному желанию; Чацкий
вернулся из
командировки;
В Древней Руси выходила
газета «Русская
правда» и т.п.
К лексическим
ошибкам следует отнести и употребление
в речи слов-сорняков
(паразитов),
поскольку они не несут никакой смысловой
нагрузки, т.е. семантически опустошенных
слов, засоряющих речь и затрудняющих
ее понимание: как
бы, ну, это, это самое, так сказать, как
говорится
и др.
Соседние файлы в папке Русский
- #
- #
- #
- #
- #
- #
- #