Содержание
- 82. Ошибка репрезентативности, методика расчета ошибки средней и относительной величины
- 83. Определение доверительных границ средних и относительных величин.
- Representativeness — what is this process? Representation error
- Representativeness — what is it?
- Other definitions
- Representative sample
- Probabilistic sampling
- Probabilistic Samples
- The sample of consumers
- Sample size
- The concept of the error of representativeness
- Types of errors
- Intentional and unintentional errors of representativeness
- Validity, reliability, representativeness. Calculation of errors
- Representative systems
82. Ошибка репрезентативности, методика расчета ошибки средней и относительной величины
В статистике выделяют два основных метода исследования — сплошной и выборочный. При проведении выборочного исследования обязательным является соблюдение следующих требований: репрезентативность выборочной совокупности и достаточное число единиц наблюдений. При выборе единиц наблюдения возможны ошибки смещения, т.е. такие события, появление которых не может быть точно предсказуемым. Эти ошибки являются объективными и закономерными. При определении степени точности выборочного исследования оценивается величина ошибки, которая может произойти в процессе выборки — случайная ошибка репрезентативности (m) — является фактической разностью между средними или относительными величинами, полученными при проведении выборочного исследования и аналогичными величинами, которые были бы получены при проведении исследования на генеральной совокупности.
Оценка достоверности результатов исследования предусматривает определение:
1. ошибки репрезентативности
2. доверительных границ средних (или относительных) величин в генеральной совокупности
3. достоверности разности средних (или относительных) величин (по критерию t)
Расчет ошибки репрезентативности (mм) средней арифметической величины (М):

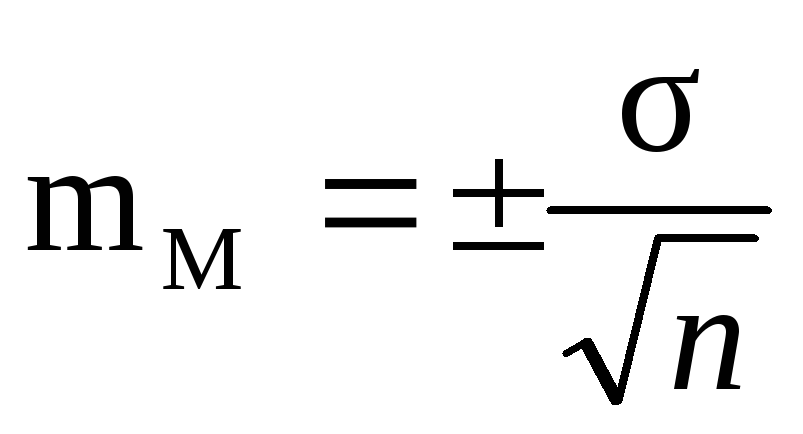 , где σ — среднее квадратическое отклонение; n — численность выборки (>30).
, где σ — среднее квадратическое отклонение; n — численность выборки (>30).
Расчет ошибки репрезентативности (mР) относительной величины (Р):
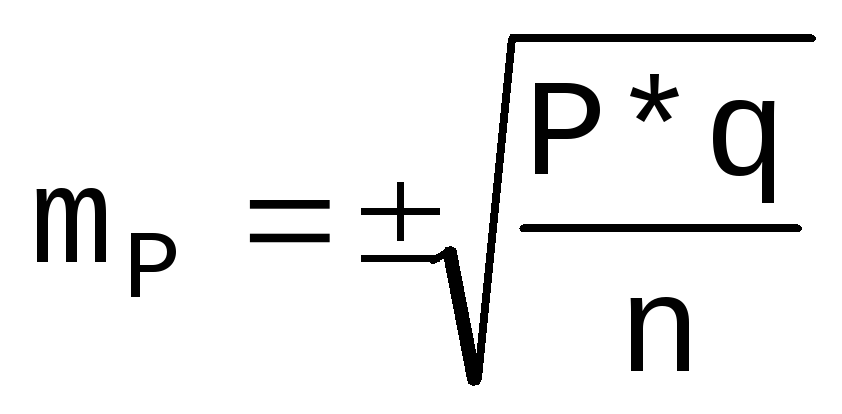 , где Р — соответствующая относительная величина (рассчитанная, например, в %);
, где Р — соответствующая относительная величина (рассчитанная, например, в %);
q =100 — Ρ% — величина, обратная Р; n — численность выборки (n>30)
В клинических и экспериментальных работах довольно часто приходится использовать малую выборку, когда число наблюдений меньше или равно 30. При малой выборке для расчета ошибок репрезентативности, как средних, так и относительных величин, число наблюдений уменьшается на единицу, т.е.
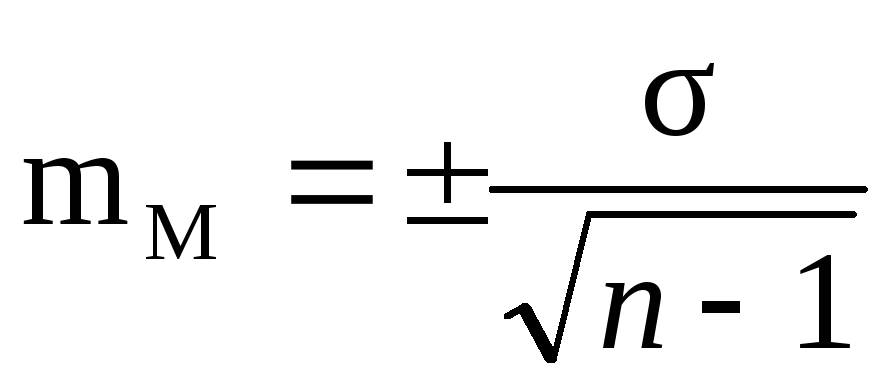 ;
; 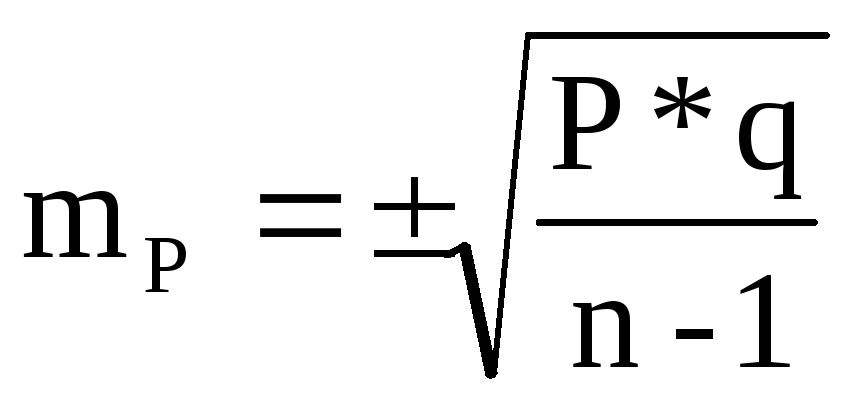 .
.
Величина ошибки репрезентативности зависит от объема выборки: чем больше число наблюдений, тем меньше ошибка. Для оценки достоверности выборочного показателя принят следующий подход: показатель (или средняя величина) должен в 3 раза превышать свою ошибку, в этом случае он считается достоверным.
83. Определение доверительных границ средних и относительных величин.
Знание величины ошибки недостаточно для того, чтобы быть уверенным в результатах выборочного исследования, так как конкретная ошибка выборочного исследования может быть значительно больше (или меньше) величины средней ошибки репрезентативности. Для определения точности, с которой исследователь желает получить результат, в статистике используется такое понятие, как вероятность безошибочного прогноза, которая является характеристикой надежности результатов выборочных медико-биологических статистических исследований. Обычно, при проведении медико-биологических статистических исследований используют вероятность безошибочного прогноза 95% или 99%. В наиболее ответственных случаях, когда необходимо сделать особенно важные выводы в теоретическом или практическом отношении, используют вероятность безошибочного прогноза 99,7%
Определенной степени вероятности безошибочного прогноза соответствует определенная величина предельной ошибки случайной выборки (Δ — дельта), которая определяется по формуле:
Δ=t * m , где t — доверительный коэффициент, который при большой выборке при вероятности безошибочного прогноза 95% равен 2,6; при вероятности безошибочного прогноза 99% — 3,0; при вероятности безошибочного прогноза 99,7% — 3,3, а при малой выборке определяется по специальной таблице значений t Стьюдента.
Используя предельную ошибку выборки (Δ), можно определить доверительные границы, в которых с определенной вероятностью безошибочного прогноза заключено действительное значение статистической величины, характеризующей всю генеральную совокупность (средней или относительной).
Для определения доверительных границ используются следующие формулы:
Источник
Representativeness — what is this process? Representation error
The concept of representativeness is often found in statistical reports and in the preparation of speeches and reports. Perhaps, without it it is difficult to imagine any of the types of information provided for viewing.
Representativeness — what is it?
Representativeness reflects how selected objects or parts correspond to the content and meaning of the aggregate of data from which they were selected.
Other definitions
The concept of representativeness can be disclosed in different contexts. But in terms of its meaning, representativeness is the correspondence of features and properties of selected units from the total population, which accurately reflect the characteristics of the entire general database as a whole.
Also, the representativeness of information is defined as the ability of sample data to present parameters and properties of the population that are important from the point of view of the research being conducted.
Representative sample
The principle of sampling is to select the most important and accurately reflecting properties of a common set of data. For this, various methods are used that allow obtaining accurate results and a general idea of the population using only selective materials describing the qualities of all data.
Thus, there is no need to study all the material, but it is sufficient to consider selective representativeness. What is it? This is a sample of individual data in order to have an idea of the total mass of information.
Depending on the method, they are distinguished as probabilistic and improbable. Probabilistic is a sample that is produced by calculating the most important and interesting data, which are subsequently representatives of the general population. This is a deliberate choice or random sampling, however, based on its content.
Unbelievable — this is one of the varieties of random sampling, compiled according to the principle of the usual lottery. In this case, the opinion of who makes such a sample is not taken into account. Only blind lot is used.
Probabilistic sampling
Probabilistic samples can also be divided into several types:
- One of the simplest and most understandable principles is an unrepresentative sample. For example, this method is often used in conducting social surveys. In this case, the survey participants are not selected from the crowd for any specific characteristics, and the information is obtained from the first 50 people who took part in it.
- Intentional samples differ in that they have a number of requirements and conditions for selection, but still rely on coincidental coincidence, not aiming at the achievement of good statistics.
- Sampling based on quotas is another variation of the non-probabilistic sample, which is often used to study large sets of data. A lot of conditions and norms are used for it. The objects that should correspond to them are selected. That is, using the example of a social survey, we can assume that 100 people will be interviewed, but only the opinion of a certain number of people who meet the established requirements will be taken into account when compiling the statistical report.
Probabilistic Samples
For probabilistic samples, a number of parameters are calculated, to which the objects in the sample will correspond, and among them, the facts and data that can be represented as representativeness of the sampling data can be selected in different ways. Such ways of calculating the required data can be:
- Simple random sampling. It consists that among the chosen segment by absolutely random method of a lottery the necessary quantity of the data which will be a representative sample is chosen.
- Systematic and random sampling makes it possible to compile a system for calculating the necessary data based on a randomly selected segment. Thus, if the first random number that points to the sequence number of data selected from the total population is 5, then the subsequent data to be selected can become, for example, 15, 25, 35, and so on. This example clearly explains that even random selection can be based on systematic calculations of the necessary input data.
The sample of consumers
A meaningful selection is a method that consists in considering each individual segment, and on the basis of its evaluation a population is constructed reflecting the characteristics and properties of the common database. In this way, more data is collected that meet the requirements of a representative sample. You can easily select a number of options that will not enter the total number, while not losing the quality of the selected data representing the total population. In this way, the representativeness of the results of the study is determined.
Sample size
Not the last question to be solved is the sample size for a representative representation of the general population. The size of the sample does not always depend on the number of sources in the population. However, the representativeness of the sample population directly depends on how many segments the result should be eventually divided into. The more such segments, the more data gets into the productive sample. If the results require a general notation and do not require specificity, then, accordingly, the sample becomes smaller, since without going into details, the information is presented more superficially, which means that its reading will be general.
The concept of the error of representativeness
The error of representativeness is the specific discrepancy between the characteristics of the general population and the sample data. In carrying out any sample research, it is impossible to obtain absolutely accurate data, as with a full study of populations and a sample represented only by a part of the data and parameters, whereas a more detailed study is possible only when studying the entire population. Thus, some errors and errors are inevitable.
Types of errors
There are some errors that arise in the design of a representative sample:
- Systematic.
- Random.
- Intentional.
- Unintentional.
- Standard.
- Limiting.
The basis for the appearance of random errors may be a discontinuous nature of the study of the total population. Usually the random error of representativity is of a minor size and character.
Systematic errors occur between violations of the rules for selecting data from a common population.
The average error is the difference between the average sample values and the main population. It does not depend on the number of units in the sample. It is inversely proportional to the sample size. Then the larger the volume, the smaller the value of the mean error.
The maximum error is the greatest possible difference between the average values of the sample made and the total population. Such an error is characterized as the maximum of possible errors under given conditions for their appearance.
Intentional and unintentional errors of representativeness
Errors of data bias are intentional and unintentional.
Then the reason for the appearance of intentional errors is the approach to the selection of data using the method of determining trends. Unintentional errors occur even at the stage of preparation of selective observation, the formation of a representative sample. To avoid such errors, it is necessary to create a good basis for sampling, which is a list of selection units. It must fully comply with the purposes of sampling, be reliable, covering all aspects of the study.
Validity, reliability, representativeness. Calculation of errors
Calculation of the representativeness error (Mm) of the arithmetic mean (M).
Mean square deviation: sample size (> 30).
Representation error (Mp) and relative value (P): sample size (n> 30).
In the case when it is necessary to study a population where the sample size is small and is less than 30 units, then the number of observations will be reduced by one unit.
The magnitude of the error is directly proportional to the sample size. The representativeness of the information and the calculation of the degree of possibility of compiling an accurate prediction reflects a certain magnitude of the marginal error.
Representative systems
Not only in the process of assessing the flow of information, a representative sample is used, but the person receiving the information also uses representative systems. Thus, the brain processes a certain amount of information, creating a representative sample of the entire information flow, in order to qualitatively and quickly evaluate the data submitted and understand the essence of the issue. To answer the question: «Representativeness — what is this?» — on the scale of human consciousness is quite simple. For this, the brain uses all the subordinate sensory organs, depending on what kind of information it is necessary to isolate from the general flow. Thus, distinguish:
- Visual representational system, which involves the organs of visual perception of the eye. People who often use a similar system are called visuals. With this system, a person processes information coming in the form of images.
- Audial representative system. The main organ that is used is a rumor. The information given in the form of audio files or speech is processed by this system. People who better perceive information by ear are called audials.
- Kinesthetic representational system is the processing of information flow, by perceiving it with the help of olfactory and tactile channels.
- A digital representative system is used together with others as a means of obtaining information from outside. This is a subjective-logical perception and comprehension of the received data.
So, representativeness — what is it? A simple sampling of a set or an integral procedure in the processing of information? One can say unambiguously that representativeness in many ways determines our perception of data flows, helping to isolate the most significant and significant from it.
Источник
Ошибка
репрезентативности
— расхождение между выборочной
характеристикой и характеристикой
генеральной совокупности.
Ошибки
репрезентативности
-
Систематические
— возникают в результате нарушения
научных принципов отбора единиц
совокупности (преднамеренные и
непреднамеренные). -
Случайные
возникают в результате несплошного
характера наблюдения (средняя и
предельная ошибки выбора).
Случайные
ошибки могут быть доведены до незначительных
размеров, а главное, их размеры и пределы
можно определить с достаточной точностью
на основании закона больших чисел.
Средняя
ошибка выборки
— такое расхождение между средними
выборочной и генеральной совокупностями,
которое не превышает ±.
В
математической статистике доказывается,
что значения средней ошибки выборки
определяются по формулам:
Формула
для определения величины средней ошибки
выборки для количественного признака:
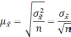
Формула
для определения величины средней ошибки
выборки для альтернативного признака:

Полученное
значение средней ошибки необходимо для
установления возможного значения 
 .
.
Которое определяется по формуле:
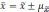
Но
такое суждение можно гарантировать не
с абсолютной
достоверностью, а лишь с определенной
степенью
вероятности.
В
математической статистике доказывается,
что пределы значений характеристик
генеральной совокупности отличаются
от характеристик выборочной совокупности
лишь с вероятностью, которая определена
числом 0,683.
Это
означает, что в 683 случаях из 1000 генеральная
средняя будет находиться в установленных
пределах, т.е. отклонение ГС от ВС не
превысит однократной средней ошибки
выборки. В остальных 317 случаях они могут
выйти за эти пределы. Вероятность можно
повысить, если расширить пределы
отклонений. Так, при удвоенном значении

 ,
,
вероятность достигает 0,954 (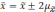
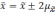 ).
).
Если утроить значение то вероятность
увеличится до 0,997 (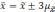
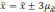 ).
).
|
Возможное |
Вероятность |
|
|
0,683 |
|
|
0,954 |
|
|
0,997 |
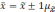
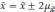
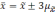
Если
обозначить значение увеличения 

за
t,
то можно записать в общем виде:
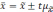
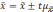
Множитель
t
называется коэффициентом
доверия.
Известный русский математик А.М.Ляпунов
дал выражение конкретных значений
множителя t
для различных степеней вероятности в
виде функции:
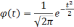
На
практике пользуются готовыми таблицами
этой функции.
|
t |
0 |
0,1 |
0,5 |
1 |
1,5 |
2 |
2,5 |
2,6 |
3 |
4 |
|
(t) |
0,1 |
0,0797 |
0,3829 |
0,6827 |
0,8664 |
0,9545 |
0,9876 |
0,9907 |
0,9973 |
0,99994 |
Из
вышесказанного следует, что лишь с
определенной степенью вероятности
можно утверждать, что показатели
генеральной совокупности и их отклонения
не превысят величину 
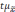 .
.
Полученную величину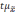
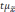 называетсяпредельной
называетсяпредельной
ошибкой выборки.
Предельная
ошибка выборки
—
максимально
возможное расхождение выборочной и
генеральной средних,
т.е.
максимум ошибки при заданной вероятности
ее появления.
Предельная
ошибка выборки для количественного
признака:
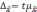
Предельная
ошибка выборки для альтернативного
признака:
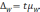
В
связи с тем, что существуют различные
методы, виды и способы отбора единиц из
генеральной совокупности формулы для
расчета средней ошибки выборки также
будут различаться:
|
Способ |
Оцениваемый |
Повторный |
Бесповторный |
|
Собственно случайный механический |
Средняя |
|
|
|
Доля |
|
|
|
|
Типический |
Средняя |
|
|
|
Доля |
|
|
|
|
Серийный |
Средняя |
|
|
|
Доля |
|
|
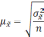
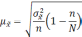
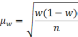
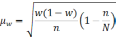
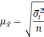
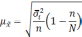
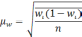
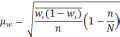
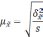
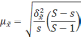

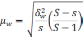
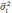
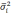
— средняя из групповых дисперсий;
wi
— доля
единиц совокупности, обладающих изучаемым
признаком в i-й
типической
группе;
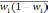
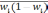
— средняя из групповых дисперсий для
доли. В табл. 6.6 представлены формулы
для исчисления средней ошибки выборки
при типическом отборе;
S
– общее число серий;
s
– число отобранных серий;

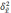 —
—
межгрупповая дисперсия средних,
определяемая по формуле:
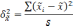
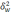
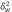 —
—
межгрупповая дисперсия доли, определяемая
по формуле:
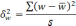
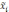
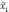
— средняя
i-й
серии;


—
средняя по всей выборочной совокупности;
w
— доля признака i-й
серии;


— общая доля признака во всей выборочной
совокупности.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Education, Colleges and Universities
Representativeness — what is this process? Representation error
The concept of representativeness is often found in statistical reports and in the preparation of speeches and reports. Perhaps, without it it is difficult to imagine any of the types of information provided for viewing.
Representativeness — what is it?
Representativeness reflects how selected objects or parts correspond to the content and meaning of the aggregate of data from which they were selected.
Other definitions
The concept of representativeness can be disclosed in different contexts. But in terms of its meaning, representativeness is the correspondence of features and properties of selected units from the total population, which accurately reflect the characteristics of the entire general database as a whole.
Also, the representativeness of information is defined as the ability of sample data to present parameters and properties of the population that are important from the point of view of the research being conducted.
Representative sample
The principle of sampling is to select the most important and accurately reflecting properties of a common set of data. For this, various methods are used that allow obtaining accurate results and a general idea of the population using only selective materials describing the qualities of all data.
Thus, there is no need to study all the material, but it is sufficient to consider selective representativeness. What is it? This is a sample of individual data in order to have an idea of the total mass of information.
Depending on the method, they are distinguished as probabilistic and improbable. Probabilistic is a sample that is produced by calculating the most important and interesting data, which are subsequently representatives of the general population. This is a deliberate choice or random sampling, however, based on its content.
Unbelievable — this is one of the varieties of random sampling, compiled according to the principle of the usual lottery. In this case, the opinion of who makes such a sample is not taken into account. Only blind lot is used.
Probabilistic sampling
Probabilistic samples can also be divided into several types:
- One of the simplest and most understandable principles is an unrepresentative sample. For example, this method is often used in conducting social surveys. In this case, the survey participants are not selected from the crowd for any specific characteristics, and the information is obtained from the first 50 people who took part in it.
- Intentional samples differ in that they have a number of requirements and conditions for selection, but still rely on coincidental coincidence, not aiming at the achievement of good statistics.
- Sampling based on quotas is another variation of the non-probabilistic sample, which is often used to study large sets of data. A lot of conditions and norms are used for it. The objects that should correspond to them are selected. That is, using the example of a social survey, we can assume that 100 people will be interviewed, but only the opinion of a certain number of people who meet the established requirements will be taken into account when compiling the statistical report.
Probabilistic Samples
For probabilistic samples, a number of parameters are calculated, to which the objects in the sample will correspond, and among them, the facts and data that can be represented as representativeness of the sampling data can be selected in different ways. Such ways of calculating the required data can be:
- Simple random sampling. It consists that among the chosen segment by absolutely random method of a lottery the necessary quantity of the data which will be a representative sample is chosen.
- Systematic and random sampling makes it possible to compile a system for calculating the necessary data based on a randomly selected segment. Thus, if the first random number that points to the sequence number of data selected from the total population is 5, then the subsequent data to be selected can become, for example, 15, 25, 35, and so on. This example clearly explains that even random selection can be based on systematic calculations of the necessary input data.
The sample of consumers
A meaningful selection is a method that consists in considering each individual segment, and on the basis of its evaluation a population is constructed reflecting the characteristics and properties of the common database. In this way, more data is collected that meet the requirements of a representative sample. You can easily select a number of options that will not enter the total number, while not losing the quality of the selected data representing the total population. In this way, the representativeness of the results of the study is determined.
Sample size
Not the last question to be solved is the sample size for a representative representation of the general population. The size of the sample does not always depend on the number of sources in the population. However, the representativeness of the sample population directly depends on how many segments the result should be eventually divided into. The more such segments, the more data gets into the productive sample. If the results require a general notation and do not require specificity, then, accordingly, the sample becomes smaller, since without going into details, the information is presented more superficially, which means that its reading will be general.
The concept of the error of representativeness
The error of representativeness is the specific discrepancy between the characteristics of the general population and the sample data. In carrying out any sample research, it is impossible to obtain absolutely accurate data, as with a full study of populations and a sample represented only by a part of the data and parameters, whereas a more detailed study is possible only when studying the entire population. Thus, some errors and errors are inevitable.
Types of errors
There are some errors that arise in the design of a representative sample:
- Systematic.
- Random.
- Intentional.
- Unintentional.
- Standard.
- Limiting.
The basis for the appearance of random errors may be a discontinuous nature of the study of the total population. Usually the random error of representativity is of a minor size and character.
Systematic errors occur between violations of the rules for selecting data from a common population.
The average error is the difference between the average sample values and the main population. It does not depend on the number of units in the sample. It is inversely proportional to the sample size. Then the larger the volume, the smaller the value of the mean error.
The maximum error is the greatest possible difference between the average values of the sample made and the total population. Such an error is characterized as the maximum of possible errors under given conditions for their appearance.
Intentional and unintentional errors of representativeness
Errors of data bias are intentional and unintentional.
Then the reason for the appearance of intentional errors is the approach to the selection of data using the method of determining trends. Unintentional errors occur even at the stage of preparation of selective observation, the formation of a representative sample. To avoid such errors, it is necessary to create a good basis for sampling, which is a list of selection units. It must fully comply with the purposes of sampling, be reliable, covering all aspects of the study.
Validity, reliability, representativeness. Calculation of errors
Calculation of the representativeness error (Mm) of the arithmetic mean (M).
Mean square deviation: sample size (> 30).
Representation error (Mp) and relative value (P): sample size (n> 30).
In the case when it is necessary to study a population where the sample size is small and is less than 30 units, then the number of observations will be reduced by one unit.
The magnitude of the error is directly proportional to the sample size. The representativeness of the information and the calculation of the degree of possibility of compiling an accurate prediction reflects a certain magnitude of the marginal error.
Representative systems
Not only in the process of assessing the flow of information, a representative sample is used, but the person receiving the information also uses representative systems. Thus, the brain processes a certain amount of information, creating a representative sample of the entire information flow, in order to qualitatively and quickly evaluate the data submitted and understand the essence of the issue. To answer the question: «Representativeness — what is this?» — on the scale of human consciousness is quite simple. For this, the brain uses all the subordinate sensory organs, depending on what kind of information it is necessary to isolate from the general flow. Thus, distinguish:
- Visual representational system, which involves the organs of visual perception of the eye. People who often use a similar system are called visuals. With this system, a person processes information coming in the form of images.
- Audial representative system. The main organ that is used is a rumor. The information given in the form of audio files or speech is processed by this system. People who better perceive information by ear are called audials.
- Kinesthetic representational system is the processing of information flow, by perceiving it with the help of olfactory and tactile channels.
- A digital representative system is used together with others as a means of obtaining information from outside. This is a subjective-logical perception and comprehension of the received data.
So, representativeness — what is it? A simple sampling of a set or an integral procedure in the processing of information? One can say unambiguously that representativeness in many ways determines our perception of data flows, helping to isolate the most significant and significant from it.