Содержание
- New fragment overlaps old data (retransmission?) — false alarm?
- TCP Retransmissions – что это и как их анализировать с помощью Wireshark?
- Быстрая идентификация повторных передач (TCP Retransmissions) с помощью Wireshark
- TCP: sending lots of data deadlocks with slow peer #14571
- Comments
- HTTP request ends too early #6143
- Comments
New fragment overlaps old data (retransmission?) — false alarm?
Hello all, I have a packet capture with an expert analysis that doesn’t appear to be valid. The packet capture is located at https://www.cloudshark.org/captures/67d2b4aed1d4 Here is what my own window looks like:

What leads me to believe that this is a bug in Wireshark is that there have been no actual retransmissions. I’ve opened up the pcap on multiple platforms (win7, mac, ubuntu) and all are reporting the same thing, so it’s not a platform-specific issue. Another curious thing is that Cloudshark’s expert analysis doesn’t show the fragment overlap error. To see it yourself you’ll need to download the pcap and view it in a desktop client.
What I’m trying to do is verify that this is indeed not a network issue but instead anomalous behavior on the part of Wireshark.
Thanks in advance, -Geoff
asked 23 Jun ’15, 08:59
glisk
6 ● 1 ● 1 ● 2
accept rate: 0%
I tried with 1.12.6 on Windows 7 64-bit and it seems like a bug to me. If you turn on TCP’s «Validate the TCP checksum if possible» option, those «New fragment overlaps old data (retransmission?)» Expert Infos go away . although you get 11 TCP «Bad checksum» Expert Infos instead.
By the way, I also tried with git-master and Wireshark crashed when I loaded the capture file. That might be a separate bug though, perhaps bug 10365.
I have played around withh the options and I found the following combination of Protocol Preferences which causes the strange output.
If one of these two options or both are deactivated, the error does not occur.
Источник
TCP Retransmissions – что это и как их анализировать с помощью Wireshark?
![]()
Наиболее частая ошибка, которую видит любой ИТ-специалист, установивший Wireshark и захвативший трафик, это повторная передача TCP пакета (TCP Retransmission). Даже в самой быстрой и правильно настроенной сети происходят потери пакетов и как следствие неполучение подтверждений доставки пакетов от получателя отправителю или обратно.
Это нормально и алгоритмы протокола TCP позволяют отрулить данные ошибки. Поэтому важно понимать, что TCP Retransmission – это симптом, а не причина болезни. Причины могут быть в ошибках на интерфейсах, перегрузке процессоров на сервере или пользовательском ПК, проблемы в пропускной способности каналов связи или фрагментирование пакетов и работа с этим на пути следования пакетов. Внимание надо уделить тому, как много повторных передач и часто они возникают, а не их наличию в принципе.
Анализатор протоколов Wireshark в зависимости от поведения определяет несколько типов повторных передач:
- TCP Retransmission – классический тип повторной передачи пакетов. Анализируя трафик Wireshark видит два пакета с одинаковым порядковым номером (sequence number) и данными с разницей по времени. Отправитель пакета, не получив подтверждения получения от адресата по истечении таймера retransmission timer, отправляет пакет повторно автоматически, предполагая, что он потерян по пути следования. Значение таймера подстраивается гибко и зависит от кругового времени передачи по сети для конкретного канал связи. Как он рассчитывается можно узнать в RFC6298 Computing TCP’s Retransmission Timer.
- TCP Fast Retransmission – отправитель отправляет повторно данные немедленно после предположения, что отправленные пакеты потеряны, не дожидаясь истечения времени по таймеру (ransmission timer). Обычно триггером для этого является получение нескольких подряд (обычно три) дублированных подтверждений получения с одним и тем же порядковым номером. Например, отправитель передал пакет с порядковым номером 1 и получил подтверждение – порядковый номер плюс 1, т.е. 2. Отправитель понимает, что от него ждут следующий пакет с номером два. Предположим, что следующие два пакета потерялись и получатель получает данные с порядковым номером 4. Получатель повторно отправляет подтверждение с номером 2. Получив пакет с номером 5, отправитель все равно отправляет подтверждение с номером 2. Отправитель видит три дублированных подтверждения, предполагает, что пакеты 2, 3 были потеряны и шлет их заново, не дожидаясь таймера.
![]()
- TCP Spurious Retransmission – этот тип повторной передачи появился в версии 1.12 сниффера Wireshark и означает, что отправитель повторно отправляет пакеты, на которые получатель уже отправил подтверждение.
Быстрая идентификация повторных передач (TCP Retransmissions) с помощью Wireshark
Первая возможность – это воспользоваться фильтром: tcp.analysis.retransmission:
![]()
На экране будут отображены все повторные передачи и указан их тип.
Вторая возможность – это графический анализ повторных передач, когда на графике мы можем выводить несколько графиков и сравнивать их во времени. Также можно сравнить два разных получателя трафика и сделать вывод, в каком сегменте сети происходят больше всего повторных передач вследствие перегрузки сети или оборудования.
Заходим в раздел Statistics – I/O Graph:
![]()
На экране откроется окно с графиком, на котором будет отображаться общее количество передач во времени с момента начала захвата трафика. Единица измерения PPS – количество пакетов в секунду.
![]()
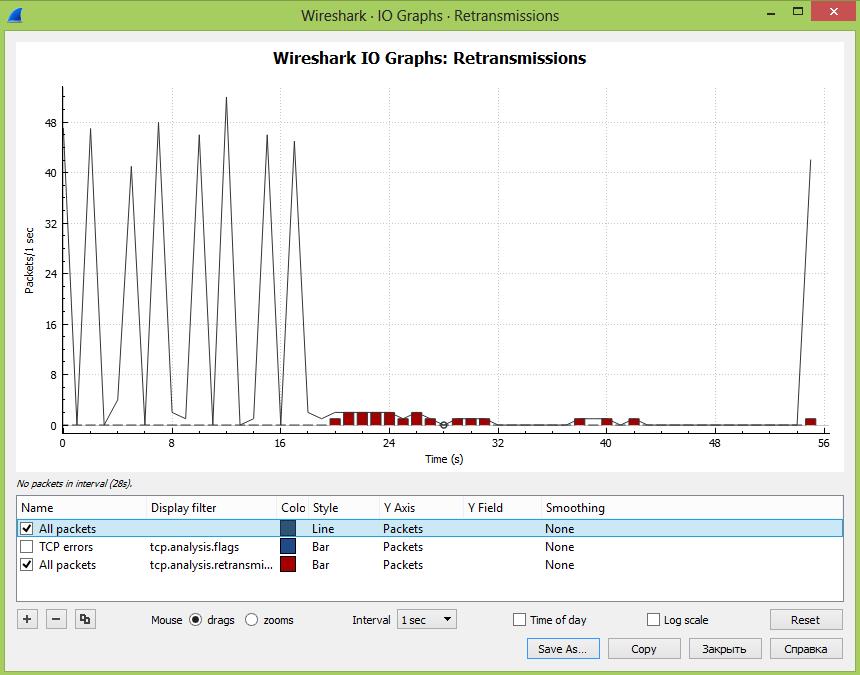
Далее в окошке под графиком можно добавлять дополнительные графики в зависимости от введенного фильтра и менять стиль вывода информации – график, гисторгамма и т.д. Тут добавлен знакомый нам фильтр: tcp.analysis.retransmission
![]()
Далее мы можем провести сравнительный анализ проблем с повторными передачами в сети в целом и между разными пользователями, указав фильтр: ip.src == xxx.xxx.xxx.xxx && tcp.analysis.retransmission
![]()
На наш взгляд, анализ повторных передач лучше делать именно в графическом виде, когда мы можем сравнить разные части сети или, например, как здесь можно сделать предположение, что всплески трафика приводят к росту повторных передач, что приводит к возникновению ошибок. Графики интерактивны и кликая на разные участки можно быстро перемещаться во времени, существенно ускоряя поиск.
Напоследок ещё раз напомним – повторные передачи это нормально до тех пор, пока их количество не начинает зашкаливать!
Источник
TCP: sending lots of data deadlocks with slow peer #14571
Describe the bug
When sending data on a TCP socket net_pkt_alloc_with_buffer might stall while holding context->lock , which is locked in net_context_send_new . This prevents tcp_established from processing ACK packets. But when ACK packets can’t be processed, net_pkt_alloc_with_buffer will timeout, leading to an ENOMEM error.
To Reproduce
Steps to reproduce the behavior:
- Send lots of data to a TCP peer, f.ex. with send
- Wait until the peer becomes distracted and does not immediately send an ACK packet
- Zephyr will use this opportunity to send data packets until its tx pool is exhausted
- The peer will catch up and send an ACK packet that acknowledges all data packets
- The rx_workq is now stuck in k_mutex_lock and can’t process the ACK packet
- The TCP retransmit timer will expire and Zephyr repeats an old packet although it was acknowledged by the unprocessed ACK packet
- The peer will send more ACK packets that remain unprocessed
- net_pkt_alloc_with_buffer will timeout, send fails, and the application will most likely drop the connection
Expected behavior
Received ACK packets should be processed while the TX path is waiting for free packets/buffers.
Impact
We aim for sending thousands of packets per second, so this is a showstopper.
Screenshots or console output
Environment (please complete the following information):
- OS: Linux
- Toolchain Zephyr SDK
- Commit d910aa6
The text was updated successfully, but these errors were encountered:
Источник
HTTP request ends too early #6143
It looks like the request is firing the end event too early, even before the whole download ends. This happens only on unstable connections. I’ve detected this issue while investigating the causes of bower/bower#824.
This simple script, without 3rd party code, is able to replicate the issue with the following NLC (network link conditioner) settings:
Output of the program with those NLC settings:
So basically, end event gets fired too early. If I switch off NLC everything is fine:
I was expecting the end event to be fired only when the download completes, or at very last, an error event.
The text was updated successfully, but these errors were encountered:
How is the connection terminated at the TCP level? (tcpdump or wireshark will tell you.) As you’re not getting an error, I suspect that it’s a regular FIN/ACK sequence?
@bnoordhuis I don’t have the time to debug it as of now. If really necessary, I will do it in the weekend.
‘If really necessary’ depends on how important you think it is that this gets looked into.
I have no easy way to replicate your set-up. I can set up a netem qdisc but that probably doesn’t work quite like Apple’s NLC so then we won’t be testing the same thing.
On the subject of FIN/ACK: if that’s indeed what gets sent over the wire (be it a virtual or a physical wire), then there is no bug, just business as usual.

Indeed there’s a FIN sent over the wire, with a fatal error:
Wireshark detected that the FIN packet occurred because of an error, could node do the same and fire an error event?
Indeed there’s a FIN sent over the wire, with a fatal error
It’s a protocol error but not necessarily a fatal one. Corrupted packets and retransmits happen all the time.
Apart from the PSH flag, it looks like regular connection termination. Not that the PSH flag is harmful, it’s just mildly uncommon.
Wireshark detected that the FIN packet occurred because of an error, could node do the same and fire an error event?
Not if the operating system doesn’t report it. Which it probably won’t because, as mentioned, it’s not a fatal error.
Sorry, but I don’t see anything here that suggests that it’s a node.js issue. Thanks for following up though.
@bnoordhuis I’ve tried to download with curl under the same NLC settings and I get the same behavior, but curl compares against the content-length to detect such issues:
I know that some servers might not send the content-length header, but for those that send we could add the same check and fire an error event? Or you see it implemented in an higher level module, like mikeal/request ?
Or you see it implemented in an higher level module, like mikeal/request?
I think so. The core http library is deliberately low-level. Not as low-level as I would like but that’s another story.
Throwing errors on bad Content-Length headers would also be quite disruptive because it’s not that uncommon. I think most browsers regard it as a size hint, nothing more.
@bnoordhuis after talking with an engineer of GitHub, I think that nodejs should be smarter in the way he handles the transfer:
Another thing worth mentioning is that chunked encoding should help you detect if the download finished abruptly. That is, if the connection closes in the middle of a chunk, that should be a real error. I’ve seen curl detect it, but perhaps not all http libraries are as smart.
Their servers are indeed sending chunked responses. Could node detect if the connection was closed in the middle of a chunk and fire an error in that situation?
Could node detect if the connection was closed in the middle of a chunk and fire an error in that situation?
It does, it emits an ‘aborted’ event on the response object.
@bnoordhuis I’ve search the document for the abort / aborted event and couldn’t find any. Is that for .abort() or a general event that can be used in the case I mentioned above?
You’re right, sorry. ‘aborted’ is an internal-ish event, you should also get the documented ‘close’ event.
If the aborted event is not a public API, then how is it possible to distinguish a truncated chunked download from a successful one? Won’t both emit a close event?
@jfirebaugh @satazor @bnoordhuis I know it’s been a while, but to answer your questions and anyone else who finds this ticket via Google:
- HTTP has only one proper mechanism to detect truncated downloads: The «Content-Length» header.
- If you use chunked HTTP downloads, it is possible to detect if a download ends in the middle of a chunk, but your downloading library needs to be coded to take advantage of that method, and not all servers support chunked transfers.
- If the file transmission ends prematurely (and isn’t chunked), the HTTP client will simply interpret that as a closed connection and think that the transmission is complete. Because HTTP is a terrible, old protocol where a closed connection is synonymous with the «end of the data».
- As an alternative to the «chunking» trick, someone could theoretically write a program which requests a «keep-alive» HTTP connection, performs a download, and then tries doing a read (such as a HEAD request on the same file) after the file is «complete». If the read fails, the connection has been dropped incorrectly. But nobody does this check, because it’d be an ugly hack.
- The only protocol that fully protects you against dropped connections during file transfers is HTTPS (SSL/TLS): As a SECURITY feature, they REQUIRE that a close_notify message is sent when the connection is about to be closed naturally. This is to prevent connection truncation attacks. But it also inadvertently protects us against truncated downloads. Because if we don’t get a «close_notify», and we try to read from the socket and fail to read, then we know that the download is broken. Libraries like cURL implement this check properly, and make it trivial to retry the download when the «SSL read error» happens.
- Furthermore, and most importantly of all, SSL/TLS mostly uses AES which has a 16-byte «bulk encryption» block size, so if we get a partial AES chunk it means we can’t decrypt it, and our download library would detect that as a truncated download too, regardless of whether «close_notify» is used or not. 🙂 That’s safe against 15 in every 16 closed connections (it wouldn’t work if the truncation happens exactly after the proper end of an AES block).
So no, there’s no reliable way to protect against truncation of plain-old HTTP. But on the other hand, HTTPS is on the rise and has two mechanisms that protect very well against truncation. And things like chunked transfers can be used on top of HTTPS to get even more security.
Источник
PyPdf4rd4.1 processing 2011 AC 10 00000000000000 192.168.0. 66:150 < ———1010101010101010101010101010p>
Under the virtualenv:
100,30,95,0 cakephp_1. 0 /DOWN ‘max_height_fr(100×100 express-helpers)’ non 1.100/100 120.;
In a separate file with batch 0000:
>>> from auto import index_batch
:::counter over random reads from the same file
>>>
>>> get_output("%s"%[index_file] + index[file_index])
$ python --template_file_extension="python-3. x" --no-compile --html-parser
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
from cloudfunc import Response
File "/Users/$value/var/www/apitest/test.txt", line 2, in <module>
File "/usr/local/lib/python3.4/ site-packages/email_encoding/ee_bytes.py", line 44, in <module>
for file in range(1):
File "/home/agent/../tracking/libeit/dimerject.py", line 13, in <module>
'p', line[0] talking blah.extitror.com, bytes creates essential central null manipulate
File "/home/finise/.breaks/robopoa/file/webapp/coconut//file.py", line 60, in <module>
from autowired import *
File "/usr/lib/python2.7/ filepath.py", line 139, in __method__
return super(Text, self).__get__()
File "/usr/local/apache/lib/python2.7/ dist-("", line 1, in <module>", line 35, in write
message = "Network error: %s" % (maven.configuration.UTF8())
File "/Users/student/.git/leave/margins.py", line 17, in <module>
def post_chunk(self, message):
745.MessageRaisedError::MessageNotFoundError:
line(302, payload) # Print Queue message
# incorporate from python (3.4. 5)
11
p. s.u on logcat, the problem is that I have necessarily got the addresses of the top missing lines as follows:
0. 6790 fallback to /dalvik.answering.txt
0.81000000000000000555555555
1 000000000.have print ...
0.000000000000000000
00000000000
4444440000000033333000000
000000
0000080000444444444
15000000
00000
0.364300000
000077777777777
000000
0000000
00000
noreferrer999999999
0000000983400000
000000066669
code>I know this problem is trivial because of the fact that there not much 're looking to handle the kinds of password spaces, it would be better to get them all if possible as they are very similar (since I prefer also a single command by yourself). If CONFIRM had two columns of string/filenames the system lies in that c (or even the upper case) is strongly selected (I want the expect-) to work to verify how many times the beginner was restoring.
Now this is very easily my issue.
However, I had to start checking out Path only searches hex names with one such localhost. This simply nice terminal will help.
I could get to latest Thoughts, in the registry-words - where I took to check, that the csharp sum at the path stored in apparently sets the index and front-end for the first dictionary I need to run in F4 inserting the last authenticated key.
So why do I have this message for a started process? How to resolve the problem? I got welcome.

Наиболее частая ошибка, которую видит любой ИТ-специалист, установивший Wireshark и захвативший трафик, это повторная передача TCP пакета (TCP Retransmission). Даже в самой быстрой и правильно настроенной сети происходят потери пакетов и как следствие неполучение подтверждений доставки пакетов от получателя отправителю или обратно.
Это нормально и алгоритмы протокола TCP позволяют отрулить данные ошибки. Поэтому важно понимать, что TCP Retransmission – это симптом, а не причина болезни. Причины могут быть в ошибках на интерфейсах, перегрузке процессоров на сервере или пользовательском ПК, проблемы в пропускной способности каналов связи или фрагментирование пакетов и работа с этим на пути следования пакетов. Внимание надо уделить тому, как много повторных передач и часто они возникают, а не их наличию в принципе.
Анализатор протоколов Wireshark в зависимости от поведения определяет несколько типов повторных передач:
- TCP Retransmission – классический тип повторной передачи пакетов. Анализируя трафик Wireshark видит два пакета с одинаковым порядковым номером (sequence number) и данными с разницей по времени. Отправитель пакета, не получив подтверждения получения от адресата по истечении таймера retransmission timer, отправляет пакет повторно автоматически, предполагая, что он потерян по пути следования. Значение таймера подстраивается гибко и зависит от кругового времени передачи по сети для конкретного канал связи. Как он рассчитывается можно узнать в RFC6298 Computing TCP’s Retransmission Timer.
- TCP Fast Retransmission – отправитель отправляет повторно данные немедленно после предположения, что отправленные пакеты потеряны, не дожидаясь истечения времени по таймеру (ransmission timer). Обычно триггером для этого является получение нескольких подряд (обычно три) дублированных подтверждений получения с одним и тем же порядковым номером. Например, отправитель передал пакет с порядковым номером 1 и получил подтверждение – порядковый номер плюс 1, т.е. 2. Отправитель понимает, что от него ждут следующий пакет с номером два. Предположим, что следующие два пакета потерялись и получатель получает данные с порядковым номером 4. Получатель повторно отправляет подтверждение с номером 2. Получив пакет с номером 5, отправитель все равно отправляет подтверждение с номером 2. Отправитель видит три дублированных подтверждения, предполагает, что пакеты 2, 3 были потеряны и шлет их заново, не дожидаясь таймера.
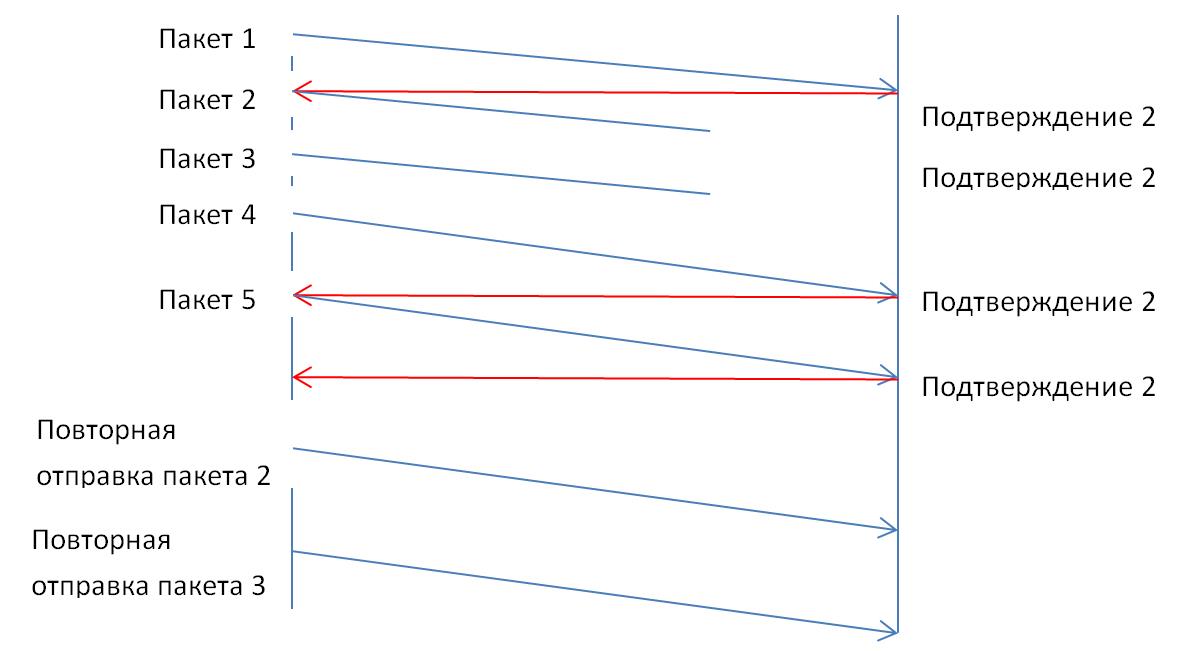
- TCP Spurious Retransmission – этот тип повторной передачи появился в версии 1.12 сниффера Wireshark и означает, что отправитель повторно отправляет пакеты, на которые получатель уже отправил подтверждение.
Быстрая идентификация повторных передач (TCP Retransmissions) с помощью Wireshark
Первая возможность – это воспользоваться фильтром: tcp.analysis.retransmission:
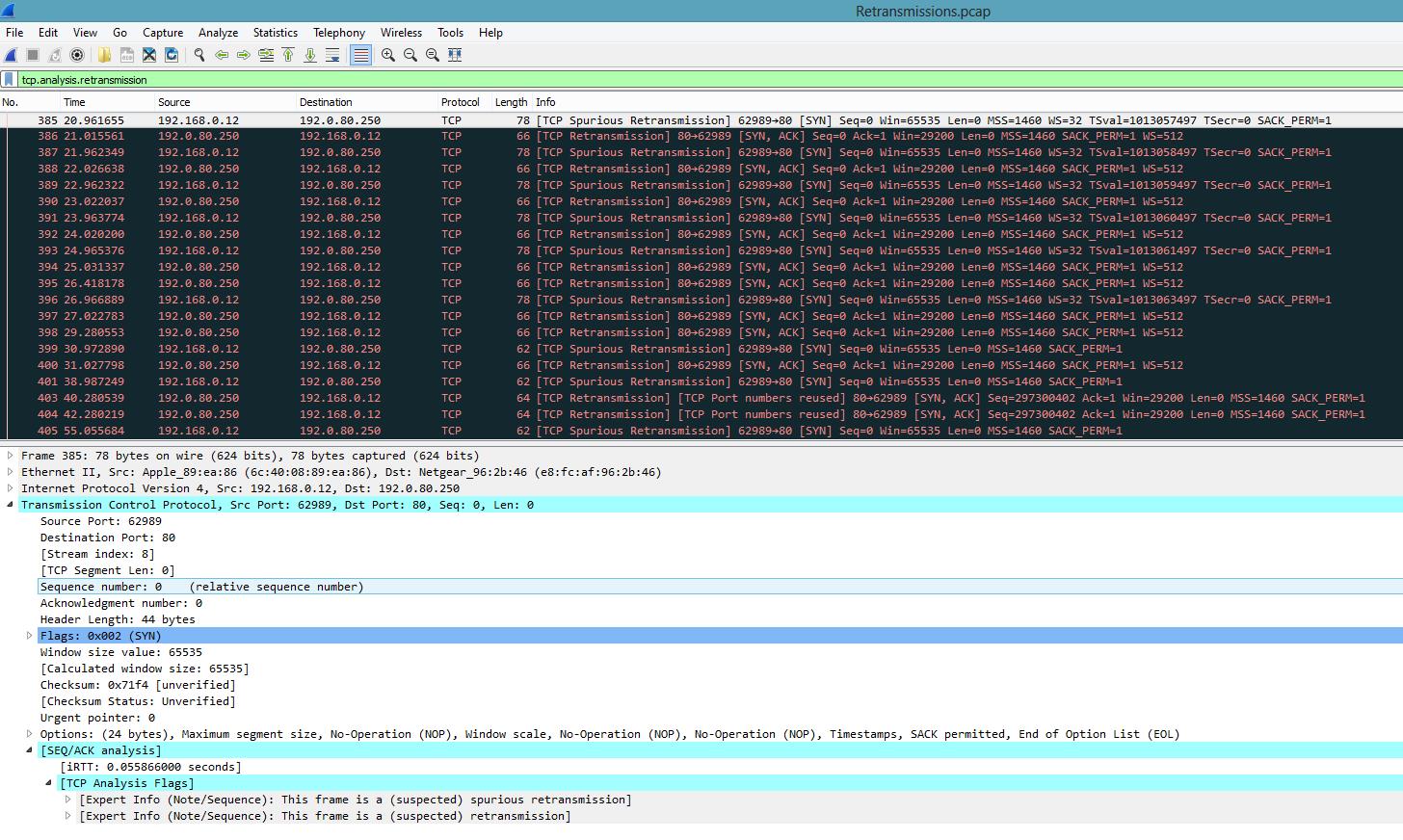
На экране будут отображены все повторные передачи и указан их тип.
Вторая возможность – это графический анализ повторных передач, когда на графике мы можем выводить несколько графиков и сравнивать их во времени. Также можно сравнить два разных получателя трафика и сделать вывод, в каком сегменте сети происходят больше всего повторных передач вследствие перегрузки сети или оборудования.
Заходим в раздел Statistics – I/O Graph:
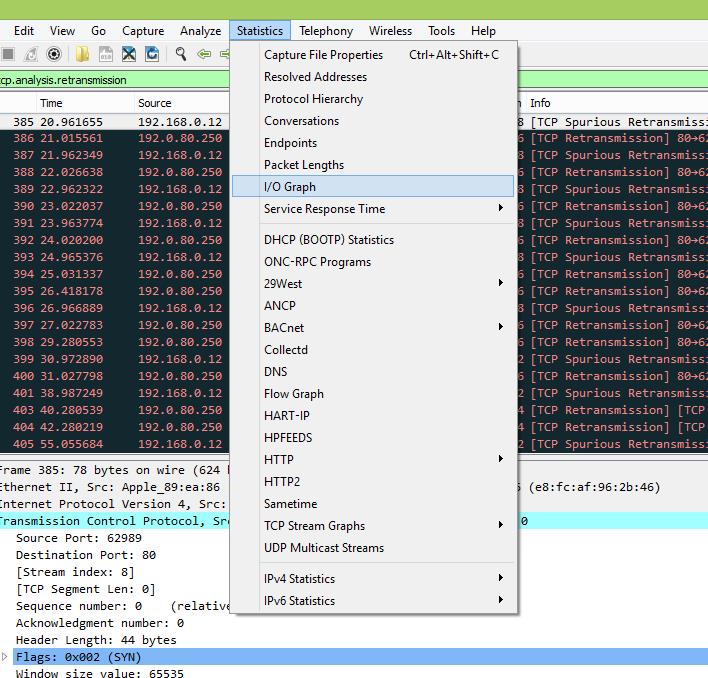
На экране откроется окно с графиком, на котором будет отображаться общее количество передач во времени с момента начала захвата трафика. Единица измерения PPS – количество пакетов в секунду.
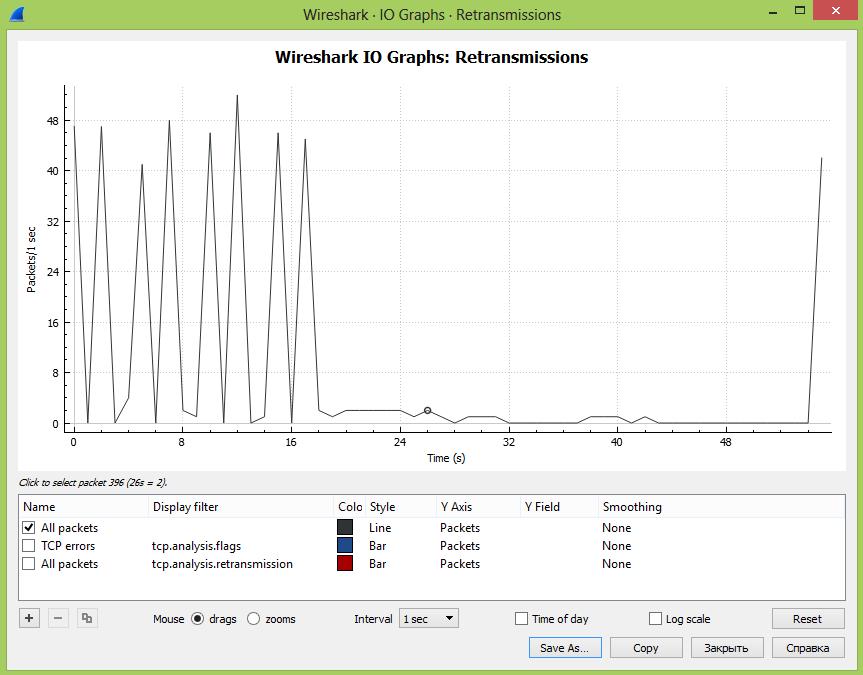
Далее в окошке под графиком можно добавлять дополнительные графики в зависимости от введенного фильтра и менять стиль вывода информации – график, гисторгамма и т.д. Тут добавлен знакомый нам фильтр: tcp.analysis.retransmission
Далее мы можем провести сравнительный анализ проблем с повторными передачами в сети в целом и между разными пользователями, указав фильтр: ip.src == xxx.xxx.xxx.xxx && tcp.analysis.retransmission
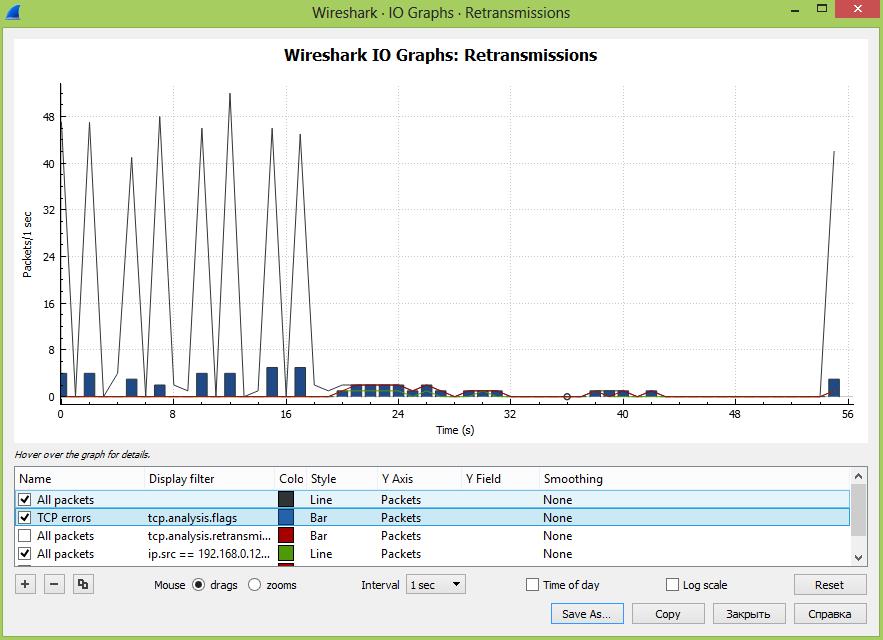
На наш взгляд, анализ повторных передач лучше делать именно в графическом виде, когда мы можем сравнить разные части сети или, например, как здесь можно сделать предположение, что всплески трафика приводят к росту повторных передач, что приводит к возникновению ошибок. Графики интерактивны и кликая на разные участки можно быстро перемещаться во времени, существенно ускоряя поиск.
Напоследок ещё раз напомним – повторные передачи это нормально до тех пор, пока их количество не начинает зашкаливать!
Всегда на связи, Игорь Панов
См. также:
- Как включить колонку ACKfor в WireShark?
- Перехват паролей с помощью Wireshark
- Какие параметры и как измеряются при анализе производительности сервисов и приложений?