-
#1
Some of the VM’s backup failed in proxmox and rest other are working fine.
Using Bacula for backup even the error says: No space left on device, which is actually not a case.
NFO: 0% (363.6 MiB of 50.0 GiB) in 3s, read: 121.2 MiB/s, write: 72.3 MiB/s
INFO: 1% (668.1 MiB of 50.0 GiB) in 6s, read: 101.5 MiB/s, write: 87.5 MiB/s
INFO: 2% (1.2 GiB of 50.0 GiB) in 9s, read: 171.2 MiB/s, write: 66.2 MiB/s
zstd: error 25 : Write error : No space left on device (cannot write compressed block)
Any idea where i have to check, even tried to execute script on proxmox for the VM which got failed, but single VM execution working fine.
script execution steps:
1. Execute backup script on proxmox server.
2. Copy backup from proxmox to backup.
3. Delete backup folder from proxmox.
![]()
-
#2
can you post the complete task log, as well as the vm config, and the storage config?
-
#3
I have the same problem, also with containers. I guesed that this is a problem with temporary file. But with your problem with kvm VMs, this may be a problem with zstd.
I think it has to do with zstd not getting rid of the data as quickly as it would like and then generating an error.
To which target system are you backing up? Is it possible that they are not written away as quickly?
I use a cloud service with rclone mounted path.
Code:
INFO: Starting Backup of VM 104 (lxc)
INFO: Backup started at 2022-07-13 05:52:19
INFO: status = running
INFO: backup mode: stop
INFO: ionice priority: 7
INFO: CT Name: gogs
INFO: including mount point rootfs ('/') in backup
INFO: stopping virtual guest
INFO: creating vzdump archive '/mnt/pcloudbackup/dump/vzdump-lxc-104-2022_07_13-05_52_19.tar.zst'
INFO: zstd: error 25 : Write error : Input/output error (cannot write compressed block)
INFO: restarting vm
closing file '/var/lib/lxc/104/rules.seccomp.tmp.2015093' failed - No space left on device
ERROR: Backup of VM 104 failed - command 'set -o pipefail && lxc-usernsexec -m u:0:100000:65536 -m g:0:100000:65536 -- tar cpf - --totals --one-file-system -p --sparse --numeric-owner --acls --xattrs '--xattrs-include=user.*' '--xattrs-include=security.capability' '--warning=no-file-ignored' '--warning=no-xattr-write' --one-file-system '--warning=no-file-ignored' '--directory=/var/tmp/vzdumptmp2015093_104' ./etc/vzdump/pct.conf ./etc/vzdump/pct.fw '--directory=/mnt/vzsnap0' --no-anchored '--exclude=lost+found' --anchored '--exclude=./tmp/?*' '--exclude=./var/tmp/?*' '--exclude=./var/run/?*.pid' ./ | zstd --rsyncable '--threads=1' >/mnt/pcloudbackup/dump/vzdump-lxc-104-2022_07_13-05_52_19.tar.dat' failed: exit code 25
INFO: Failed at 2022-07-13 05:55:46
INFO: Backup job finished with errors
TASK ERROR: job errorsI change now to gzip and wait for and am waiting for the results.
-
#4
It is not zstd. Same with gzip.
Code:
INFO: Starting Backup of VM 102 (lxc)
INFO: Backup started at 2022-07-14 06:38:26
INFO: status = running
INFO: backup mode: stop
INFO: ionice priority: 7
INFO: CT Name: sn
INFO: including mount point rootfs ('/') in backup
INFO: stopping virtual guest
INFO: creating vzdump archive '/mnt/pcloudbackup/dump/vzdump-lxc-102-2022_07_14-06_38_26.tar.gz'
INFO: gzip: stdout: Input/output error
INFO: restarting vm
closing file '/var/lib/lxc/102/rules.seccomp.tmp.2452089' failed - No space left on device
ERROR: Backup of VM 102 failed - command 'set -o pipefail && lxc-usernsexec -m u:0:100000:65536 -m g:0:100000:65536 -- tar cpf - --totals --one-file-system -p --sparse --numeric-owner --acls --xattrs '--xattrs-include=user.*' '--xattrs-include=security.capability' '--warning=no-file-ignored' '--warning=no-xattr-write' --one-file-system '--warning=no-file-ignored' '--directory=/var/tmp/vzdumptmp2452089_102/' ./etc/vzdump/pct.conf ./etc/vzdump/pct.fw '--directory=/mnt/vzsnap0' --no-anchored '--exclude=lost+found' --anchored '--exclude=./tmp/?*' '--exclude=./var/tmp/?*' '--exclude=./var/run/?*.pid' ./ | gzip --rsyncable >/mnt/pcloudbackup/dump/vzdump-lxc-102-2022_07_14-06_38_26.tar.dat' failed: exit code 1
INFO: Failed at 2022-07-14 06:49:06
But this time another container.
Also strange. It says to restart the VM, but it doesn’t .
-
#5
This time, I try a local backup. Also fail.
Code:
INFO: starting new backup job: vzdump 100 --storage local --remove 0 --node pve01 --compress gzip --notes-template '{{guestname}}' --mode stop
INFO: Starting Backup of VM 100 (lxc)
INFO: Backup started at 2022-07-26 07:16:44
INFO: status = stopped
INFO: backup mode: stop
INFO: ionice priority: 7
INFO: CT Name: cloud
INFO: including mount point rootfs ('/') in backup
INFO: creating vzdump archive '/var/lib/vz/dump/vzdump-lxc-100-2022_07_26-07_16_43.tar.gz'
INFO: gzip: stdout: No space left on device
ERROR: Backup of VM 100 failed - command 'set -o pipefail && tar cpf - --totals --one-file-system -p --sparse --numeric-owner --acls --xattrs '--xattrs-include=user.*' '--xattrs-include=security.capability' '--warning=no-file-ignored' '--warning=no-xattr-write' --one-file-system '--warning=no-file-ignored' '--directory=/var/tmp/vzdumptmp318888_100/' ./etc/vzdump/pct.conf ./etc/vzdump/pct.fw '--directory=/mnt/vzsnap0' --no-anchored '--exclude=lost+found' --anchored '--exclude=./tmp/?*' '--exclude=./var/tmp/?*' '--exclude=./var/run/?*.pid' ./ | gzip --rsyncable >/var/lib/vz/dump/vzdump-lxc-100-2022_07_26-07_16_43.tar.dat' failed: exit code 1
INFO: Failed at 2022-07-26 09:35:04
INFO: Backup job finished with errors
TASK ERROR: job errorsThere is enough space:
Code:
root@pve01:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 2.9G 0 2.9G 0% /dev
tmpfs 594M 784K 593M 1% /run
/dev/mapper/pve-root 76G 12G 61G 17% /
tmpfs 2.9G 46M 2.9G 2% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/fuse 128M 40K 128M 1% /etc/pve
tmpfs 594M 0 594M 0% /run/user/0I haven’t a idea now.
![]()
-
#6
how big is the container?
-
#7
150 GB. The last working backup was 70 GB. So it’s clear. It doesn’t fit into the local disk.
If I’m using a external (cloud) storage to backup, it still need the space to do a local backup?
![]()
-
#8
If I’m using a external (cloud) storage to backup, it still need the space to do a local backup?
it shouldn’t. does it there fail too? how much space do you have there?
-
#9
it shouldn’t. does it there fail too? how much space do you have there?
1.2 TB of 2TB
![]()
-
#10
are you sure the automount works (correctly)? it sounds to me like vzdump writes to the root partition, since both it (or rather, the compressor it writes with) and directly afterwards the starting of the container fail with ENOSPACE — and the latter doesn’t write to the backup storage at all, but to another path very likely stored on /
-
#11
I’m not 100% sure, but 2 other lxc backups working. All 3 backups starting with the same job.
So, how to be sure, that the automount is working all over the time?
![]()
-
#12
are the other two after the failing one or before? the best way would probably be to ensure the mounting happens via a vzdump hook script before the actual backup task starts, and that the corresponding storage has is_mountpoint set..
-
#13
is_mountpoint was a good hint. I will try that. I’m not a friend of hook scripts. I like to have the backup storage viewable in the GUI B-) .
I have also protect now the mount path with
Code:
chattr -i /mnt/pcloudbackupSo it should be give me an earlier error, if automount doesn’t work.
-
#14
Still doesn’t work.
Code:
INFO: starting new backup job: vzdump 100 --storage pcloudbackup --node pve01 --compress zstd --notes-template '{{guestname}}' --mode stop --remove 0
INFO: Starting Backup of VM 100 (lxc)
INFO: Backup started at 2022-08-01 12:10:47
INFO: status = running
INFO: backup mode: stop
INFO: ionice priority: 7
INFO: CT Name: cloud
INFO: including mount point rootfs ('/') in backup
INFO: stopping virtual guest
INFO: creating vzdump archive '/mnt/pcloudbackup/dump/vzdump-lxc-100-2022_08_01-12_10_47.tar.zst'
INFO: zstd: error 25 : Write error : Input/output error (cannot write compressed block)
INFO: restarting vm
closing file '/var/lib/lxc/100/config.tmp.8443' failed - No space left on device
ERROR: Backup of VM 100 failed - command 'set -o pipefail && tar cpf - --totals --one-file-system -p --sparse --numeric-owner --acls --xattrs '--xattrs-include=user.*' '--xattrs-include=security.capability' '--warning=no-file-ignored' '--warning=no-xattr-write' --one-file-system '--warning=no-file-ignored' '--directory=/var/tmp/vzdumptmp8443_100/' ./etc/vzdump/pct.conf ./etc/vzdump/pct.fw '--directory=/mnt/vzsnap0' --no-anchored '--exclude=lost+found' --anchored '--exclude=./tmp/?*' '--exclude=./var/tmp/?*' '--exclude=./var/run/?*.pid' ./ | zstd --rsyncable '--threads=1' >/mnt/pcloudbackup/dump/vzdump-lxc-100-2022_08_01-12_10_47.tar.dat' failed: exit code 25
INFO: Failed at 2022-08-01 13:47:35
INFO: Backup job finished with errors
TASK ERROR: job errorsI have started this by hand. This time with zstd.
-
#15
I try to simulate this problem:
Code:
mknod full c 1 7
pct create 333 local:vztmpl/alpine-3.16-default_20220622_amd64.tar.xz -hostname testbackup -ostype alpine -storage local-lvm -start 1
vzdump 333 --dumpdir /mnt/pcloudbackup --mode stop --tmpdir /dev/fullresult:
Code:
root@pve01:~# mknod full c 1 7
pct create 333 local:vztmpl/alpine-3.16-default_20220622_amd64.tar.xz -hostname testbackup -ostype alpine -storage local-lvm -start 1
vzdump 333 --dumpdir /mnt/pcloudbackup --mode stop --tmpdir /dev/full
mknod: full: File exists
Logical volume "vm-333-disk-0" created.
Creating filesystem with 1048576 4k blocks and 262144 inodes
Filesystem UUID: 80b75155-9aba-49f1-9025-d3d331487612
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
extracting archive '/var/lib/vz/template/cache/alpine-3.16-default_20220622_amd64.tar.xz'
Total bytes read: 9185280 (8.8MiB, 33MiB/s)
Detected container architecture: amd64
tmpdir '/dev/full' does not existNow I also find this behaviour strange.
This error message is wrong. /dev/full exists.
Is there a verbose option for vzdump?
![]()
fiona
Proxmox Staff Member
-
#16
I try to simulate this problem:
Code:
mknod full c 1 7 pct create 333 local:vztmpl/alpine-3.16-default_20220622_amd64.tar.xz -hostname testbackup -ostype alpine -storage local-lvm -start 1 vzdump 333 --dumpdir /mnt/pcloudbackup --mode stop --tmpdir /dev/fullresult:
Code:
root@pve01:~# mknod full c 1 7 pct create 333 local:vztmpl/alpine-3.16-default_20220622_amd64.tar.xz -hostname testbackup -ostype alpine -storage local-lvm -start 1 vzdump 333 --dumpdir /mnt/pcloudbackup --mode stop --tmpdir /dev/full mknod: full: File exists Logical volume "vm-333-disk-0" created. Creating filesystem with 1048576 4k blocks and 262144 inodes Filesystem UUID: 80b75155-9aba-49f1-9025-d3d331487612 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736 extracting archive '/var/lib/vz/template/cache/alpine-3.16-default_20220622_amd64.tar.xz' Total bytes read: 9185280 (8.8MiB, 33MiB/s) Detected container architecture: amd64 tmpdir '/dev/full' does not existNow I also find this behaviour strange.
This error message is wrong. /dev/full exists.
Yes, the message could be improved, but tmpdir needs to be a directory, which /dev/full isn’t.
Is there a verbose option for vzdump?
Are you sure that /mnt/pcloudbackup/ is mounted properly? It doesn’t show up in your earlier df output.
-
#17
Yes, the message could be improved, but
tmpdirneeds to be a directory, which/dev/fullisn’t.
I would expect at stop mode to ignore the —tmpdir parameter. How could to simulate a full directory?
Are you sure that
/mnt/pcloudbackup/is mounted properly? It doesn’t show up in your earlierdfoutput.
Yes, I’m sure. I cut the last line with df last time, sorry.
Code:
root@pve01:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 2.9G 0 2.9G 0% /dev
tmpfs 594M 788K 593M 1% /run
/dev/mapper/pve-root 76G 11G 62G 15% /
tmpfs 2.9G 46M 2.9G 2% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/fuse 128M 40K 128M 1% /etc/pve
cryptedpcloud: 2.0T 872G 1.2T 43% /mnt/pcloudbackup
tmpfs 594M 0 594M 0% /run/user/0
![]()
fiona
Proxmox Staff Member
-
#18
I would expect at stop mode to ignore the —tmpdir parameter. How could to simulate a full directory?
It should, except for temporarily storing the container (and firewall) configuration which are included in the backup. But they are not big enough to fill the disk of course. By default, the tmpdir will be on the backup storage if we can detect that it’s a POSIX filesystem, but in your case that detection doesn’t succeed, so it uses /var/tmp/vzdumptmp<PID>_<container ID> as a fallback.
Can you check the temporary directory during the backup? Does the space on / actually run out? Inside the directory or somewhere else?
Are there any messages in /var/log/syslog during the backup?
-
#19
I used
to find the thief
Code:
taskx20U 880416 root 11wW REG 0,26 0 1420 /run/vzdump.lock
taskx20U 880416 root 12w REG 253,1 414 1836263 /var/log/vzdump/lxc-100.log
tar 880849 root 3r DIR 253,1 4096 1835538 /var/tmp/vzdumptmp880416_100
zstd 880850 root 1w REG 253,1 10972250112 1836690 /var/lib/vz/dump/vzdump-lxc-100-2022_08_03-10_20_42.tar.dat
zstd 880850 880851 zstd root 1w REG 253,1 10972250112 1836690 /var/lib/vz/dump/vzdump-lxc-100-2022_08_03-10_20_42.tar.datCode:
root@pve01:/var/lib/vz/dump# ls -lah /var/lib/vz/dump
total 16G
drwxr-xr-x 2 root root 4.0K Aug 3 10:21 .
drwxr-xr-x 7 root root 4.0K Aug 10 2020 ..
-rw-r--r-- 1 root root 1.2K Jul 20 13:57 vzdump-lxc-100-2022_07_20-12_47_12.log
-rw-r--r-- 1 root root 1.2K Jul 25 13:34 vzdump-lxc-100-2022_07_25-12_05_36.log
-rw-r--r-- 1 root root 1.2K Jul 26 09:35 vzdump-lxc-100-2022_07_26-07_16_43.log
-rw-r--r-- 1 root root 16G Aug 3 10:56 vzdump-lxc-100-2022_08_03-10_20_42.tar.datbefore I have disabled the vfs-cache from rclone in the mount option. So rclone need also another view.
-
#20
status at this point.
with rclone vfs-cache off, vzdump makes a local cache copy of the hole container -> no space left. Backup failed and container starts again.
with rclone vfs-cache on, rclone makes a local cache copy of the hole container -> no space left. backup failed and container doesn’t start again.
Conclusion: You need local free space of the size of the biggest VM/container to make an online backup over rclone.
There is a chance with clone chunker https://rclone.org/chunker/ , but I’m not sure if that is possible together with the crypt module.

- Forum
- The Ubuntu Forum Community
- Ubuntu Official Flavours Support
- Installation & Upgrades
- [ubuntu] Recent apt upgrade fails — Help Please

-
Recent apt upgrade fails — Help Please
I get the following:
zstd: error 25 : Write error : No space left on device (cannot write compressed block)
E: mkinitramfs failure zstd -q -19 -T0 25
update-initramfs: failed for /boot/initrd.img-5.11.0-37-generic with 1.
dpkg: error processing package linux-firmware (—configure):
installed linux-firmware package post-installation script subprocess returned error exit status 1
Errors were encountered while processing:
linux-firmware
ZSys is adding automatic system snapshot to GRUB menu
E: Sub-process /usr/bin/dpkg returned an error code (1)I am using zfs on boot and root. I culled most of old snapshots.
However, bpool shows:
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
bpool 1.88G 1.71G 169M — — 55% 91% 1.00x ONLINE —What else ban I clean up? Can I increase bpool/partition sizes? I’m using ZFS mirrored NVME drives (ie partitioning identical on both…)
Any help appreciated.
-
Re: Recent apt upgrade fails — Help Please
Found the issue. /boot full of old kernels etc.
Purged and ruinning now
-
Re: Recent apt upgrade fails — Help Please
ZFS-on-root uses it’s own boot partition, which that error tells us that that partition seems to be full.
During normal use, that partition should be sufficient size, if you have been doing normal maintenance over time… (Removing old kernels.)
It still boots to the system right? If not, I’ll provide instruction on how to mount and chroot into the system from a LiveCD. it’s much easier if it still boots. LOL
In a nut shell,
Code:
sudo apt autoremove
Try that first to see if that does anything without returning an error on broken packages or dpkg being interrupted…
EDIT… LOL. See, while I was posting my reply, you found out what I saying was true… Yes, too many old kernels is the culprit.
Last edited by MAFoElffen; February 15th, 2022 at 03:11 AM.
Tags for this Thread
Bookmarks
Bookmarks
Posting Permissions

#1 2021-05-16 20:42:46
- zuntik
- Member
- Registered: 2017-08-11
- Posts: 35
Boot Partition too small
Hello,
I’m trying to run `sudo mkinitcpio -p linux`. Amongst all of the lines, the following stands out:
==> Creating zstd-compressed initcpio image: /boot/initramfs-linux.img
zstd: error 25 : Write error : No space left on device (cannot write compressed block)
==> ERROR: Image generation FAILED: zstd reported an error
and right at the end
==> Creating zstd-compressed initcpio image: /boot/initramfs-linux-fallback.img
zstd: error 25 : Write error : No space left on device (cannot write compressed block)
==> ERROR: Image generation FAILED: zstd reported an error
then I checked how full the /boot partition is with `df -h`:
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/nvme0n1p1 96M 96M 1.0K 100% /boot
but the result of `fdisk -l` is
# fdisk -l
Device Start End Sectors Size Type
/dev/nvme0n1p1 2048 1050623 1048576 512M EFI System
What is going on?
Thank you.
#2 2021-05-16 20:52:27
- Slithery
- Administrator

- From: Norfolk, UK
- Registered: 2013-12-01
- Posts: 5,776

Re: Boot Partition too small
You only have a 100MB filesystem in a 512MB partition.
Copy everything off the partition, reformat it to the correct size and then copy everything back again. Don’t forget to update your fstab with the new UUID.
No, it didn’t «fix» anything. It just shifted the brokeness one space to the right. — jasonwryan
Closing — for deletion; Banning — for muppetry. — jasonwryan
aur — dotfiles
#3 2021-05-16 21:00:34
- zuntik
- Member
- Registered: 2017-08-11
- Posts: 35
Re: Boot Partition too small
Thank you for the reply Slithery.
Could you be a little more specific on how I can do this? Do I use a tool like dd? do I copy all the files and hidden files to a directory under my home ext4 partition? And what about my windows partition which shares the same partition because of `/boot/EFI` ? Will windows still boot normally? Or will if affect the boot process and therefor I need to write down the recovery key?
And I suppose you don’t have any insight on how it happened in the first place, no?
Thank you very much once again.
-
#1
Hello,
I am getting errors during backup.I suspect the /tmp folder size is not enough for the admin account to be backed up.
How may i make sure this ?
Thanks .
Log :
Error Compressing the backup file admin.root.admin.tar.zst : zstd: error 25 : Write error : No space left on device (cannot write compressed block)
/bin/tar: -: Cannot write: Broken pipe
/bin/tar: Error is not recoverable: exiting now
-
#2
by default:
backup_tmpdir=/home/tmp
if you don’t have enough free space in /home — you can change dir to another, don’t forget to set same owner/permissions
-
#3
I have 25gb free space :
[[email protected] ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 874M 0 874M 0% /dev
tmpfs 909M 0 909M 0% /dev/shm
tmpfs 909M 97M 813M 11% /run
/dev/vda1 50G 25G 26G 49% /
tmpfs 182M 0 182M 0% /run/user/0
-
#4
I have 25gb free space :
/dev/vda1 50G 25G 26G 49% /
It tells you right here. It filled up the disk trying
Write error : No space left on device (cannot write compressed block)
Yes but your HD total size is only 50 GB. You want to back up 25 GB. You need to cleanup old backups/files or get a bigger disk. Your overall disk size isn’t big enough currently. Typically you need twice the space as the backup size. So you would need about 75GB disk total.
-
#5
No,
i already have daily backups in backup folder.Backup fails from time to time only when taking backup of admin account.
All backups from individual accounts are completed succesfully.
My current disk usage is only 15gb.
So 30 gb of disk space should be enough ?
-

Screenshot_3.jpg
202.1 KB
· Views: 5
-
#6
taking backup of admin account.
How big is that backup normally?
All backups from individual accounts are completed succesfully.
Great are they smaller? What is the average size of the Backup?
Where is the location of the backups in the file system? Normally the old backups are kept inside the /home/admin/admin_backups
Which could mean you are backing up the backups.
Also old backups are not normally deleted. You have to do this manually or with a script.
Last edited: Jul 15, 2022
-
#7
Backup folder is :
/home/admin size is :
9.4G admin
-
#8
Seems like that should work.
Are you backing up admin and the individual sites at the same time?
What happens if you go run a admin backup right now?
-
#9
Just run backup manually from directadmin and it went successful :
The Admin backups have been created in /home/admin <21:40:01>
-
#10
Today i have received another error :
An error occurred during the backup (id=1)
2022-07-16 05:36
Error Compressing the backup file admin.root.admin.tar.zst : zstd: error 25 : Write error : No space left on device (cannot write compressed block)
/bin/tar: -: Wrote only 6144 of 10240 bytes
/bin/tar: Error is not recoverable: exiting now
Spare me as this is the first question I ever post in here.
So I tried to update on Ubuntu 22.04 using the command line and everything was fine until I got the error E: Sub-process /usr/bin/dpkg returned an error code (1)
Here:
Processing triggers for initramfs-tools (0.140ubuntu13) …
update-initramfs: Generating /boot/initrd.img-5.15.0-27-lowlatency
I: The initramfs will attempt to resume from /dev/sda1
I: (UUID=d0783d7d-a3db-4dbb-a784-8b92c1aa4355)
I: Set the RESUME variable to override this.
zstd: error 25 : Write error : No space left on device (cannot write compressed
block)
E: mkinitramfs failure zstd -q -1 -T0 25
update-initramfs: failed for /boot/initrd.img-5.15.0-27-lowlatency with 1.
dpkg: error processing package initramfs-tools (—configure):
installed initramfs-tools package post-installation script subprocess returned
error exit status 1
Errors were encountered while processing:
initramfs-tools
E: Sub-process /usr/bin/dpkg returned an error code (1) <
So, I really have no what is going on. The boot partition still has space in it and as far as I can see I can’t install anything after I sudo apt update and then tried the sudo apt upgrade.
It is only recently that I started using Linux and just began using Lubuntu 22.04.
Thanks in advance
asked May 6, 2022 at 9:15
![]()
3
It may be the case your /boot directory doesn’t have enough space, although not full, because of old kernels. Please, try deleting old packages:
sudo apt autoremove
I had this problem and it solved for me. This thread on the Ubuntu Forums dealt with a similar issue, if not the same.
answered Jun 13, 2022 at 3:41
![]()
1
Ошибка no space left on device в Linux может возникать при использовании различных программ или сервисов. В графических программах данная ошибка может выводится во всплывающем сообщении, а для сервисов она обычно появляется в логах. Во всех случаях она означает одно. На разделе диска, куда программа собирается писать свои данные закончилось свободное место.
Избежать такой проблемы можно ещё на этапе планирования установки системы. Выделяйте под каталог /home отдельный раздел диска, тогда если вы займете всю память своими файлами, это не помешает работе системы. Также выделяйте больше 20 гигабайт под корневой раздел чтобы всем программам точно хватило места. Но что делать если такая проблема уже случилась? Давайте рассмотрим как освободить место на диске с Linux.
Первым дело надо понять на каком разделе у вас закончилась память. Для этого можно воспользоваться утилитой df. Она поставляется вместе с системой, поэтому никаких проблем с её запуском быть не должно:
df -h
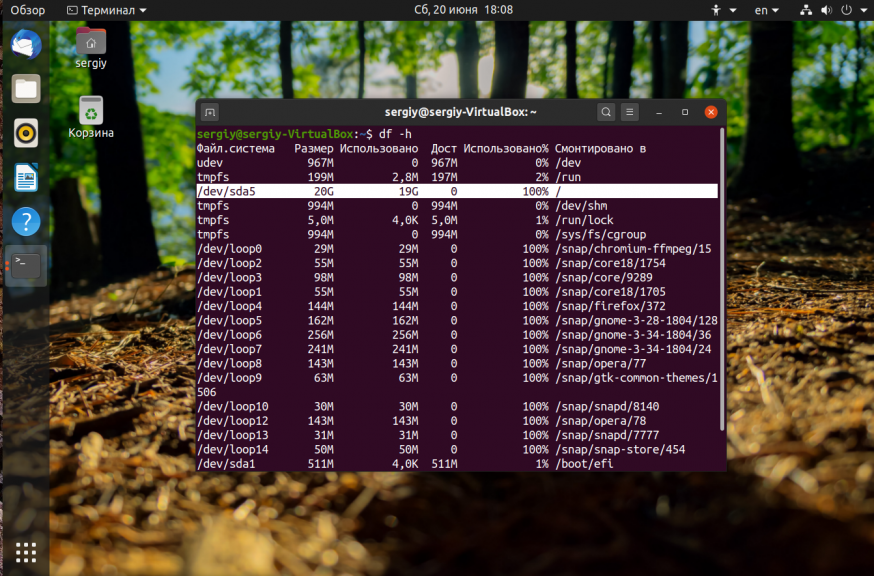
На точки монтирования, начинающиеся со слова snap внимания можно не обращать. Команда отображает общее количество места на диске, занятое и доступное место, а также процент занятого места. В данном случае 100% занято для корневого раздела — /dev/sda5. Конечно, надо разобраться какая программа или файл заняла всё место и устранить эту проблему, но сначала надо вернуть систему в рабочее состояние. Для этого надо освободить немного места. Рассмотрим что можно сделать чтобы экстренно освободить немного памяти.
1. Отключить зарезервированное место для root
Обычно, у всех файловых систем семейства Ext, которые принято использовать чаще всего как для корневого, так и для домашнего раздела используется резервирование 5% памяти для пользователя root на случай если на диске закончится место. Вы можете эту память освободить и использовать. Для этого выполните:
sudo tune2fs -m 0 /dev/sda5
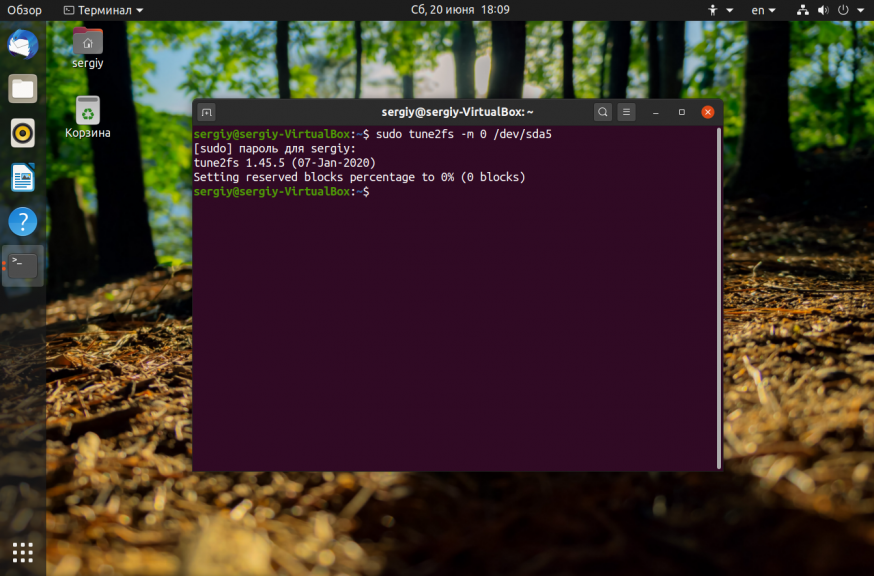
Здесь опция -m указывает процент зарезервированного места, а /dev/sda5 — это ваш диск, который надо настроить. После этого места должно стать больше.
2. Очистить кэш пакетного менеджера
Обычно, пакетный менеджер, будь то apt или yum хранит кэш пакетов, репозиториев и другие временные файлы на диске. Они некоторые из них ненужны, а некоторые нужны, но их можно скачать при необходимости. Если вам срочно надо дисковое пространство этот кэш можно почистить. Для очистки кэша apt выполните:
sudo apt clean
sudo apt autoclean
Для очистки кэша yum используйте команды:
yum clean all
3. Очистить кэш файловой системы
Вы могли удалить некоторые большие файлы, но память после этого так и не освободилась. Эта проблема актуальна для серверов, которые работают долгое время без перезагрузки. Чтобы полностью освободить память надо перезагрузить сервер. Просто перезагрузите его и места на диске станет больше.
4. Найти большие файлы
После выполнения всех перечисленных выше рекомендаций, у вас уже должно быть достаточно свободного места для установки специальных утилит очистки системы. Для начала вы можете попытаться найти самые большие файлы и если они не нужны — удалить их. Возможно какая-либо программа создала огромный лог файл, который занял всю память. Чтобы узнать что занимает место на диске Linux можно использовать утилиту ncdu:
sudo apt install ncdu
Она сканирует все файлы и отображает их по размеру:
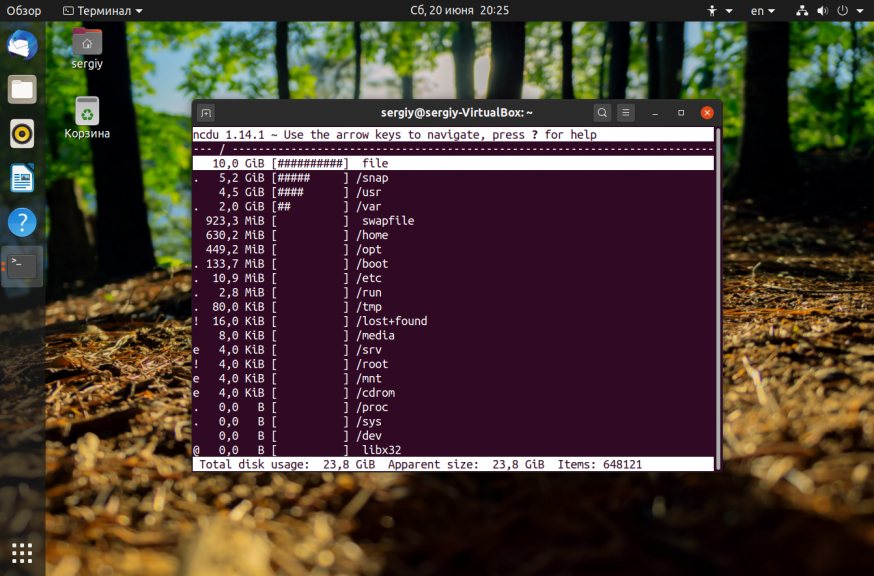
Более подробно про поиск больших файлов читайте в отдельной статье.
5. Найти дубликаты файлов
С помощью утилиты BleachBit вы можете найти и удалить дубликаты файлов. Это тоже поможет сэкономить пространство на диске.
6. Удалите старые ядра
Ядро Linux довольно часто обновляется старые ядра остаются в каталоге /boot и занимают место. Если вы выделили под этот каталог отдельный раздел, то скоро это может стать проблемой и вы получите ошибку при обновлении, поскольку программа просто не сможет записать в этот каталог новое ядро. Решение простое — удалить старые версии ядер, которые больше не нужны.
Выводы
Теперь вы знаете почему возникает ошибка No space left on device, как её предотвратить и как исправить если с вами это уже произошло. Освободить место на диске с Linux не так уж сложно, но надо понять в чём была причина того, что всё место занято и исправить её, ведь на следующий раз не всё эти методы смогут помочь.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Об авторе
![]()
Основатель и администратор сайта losst.ru, увлекаюсь открытым программным обеспечением и операционной системой Linux. В качестве основной ОС сейчас использую Ubuntu. Кроме Linux, интересуюсь всем, что связано с информационными технологиями и современной наукой.